
ভূমিকা
XLA হল একটি হার্ডওয়্যার- এবং ফ্রেমওয়ার্ক- রৈখিক বীজগণিতের জন্য ডোমেন-নির্দিষ্ট কম্পাইলার, যা সর্বোত্তম-শ্রেণীর কর্মক্ষমতা প্রদান করে। JAX, TF, Pytorch এবং অন্যান্যরা XLA ব্যবহার করে ব্যবহারকারীর ইনপুটকে StableHLO ("উচ্চ-স্তরের অপারেশন"-এ রূপান্তর করে: ~100 স্থিতিশীল আকৃতির নির্দেশাবলী যেমন যোগ, বিয়োগ, matmul, ইত্যাদি) অপারেশন সেট, যেখান থেকে XLA বিভিন্ন ব্যাকএন্ডের জন্য অপ্টিমাইজড কোড তৈরি করে:
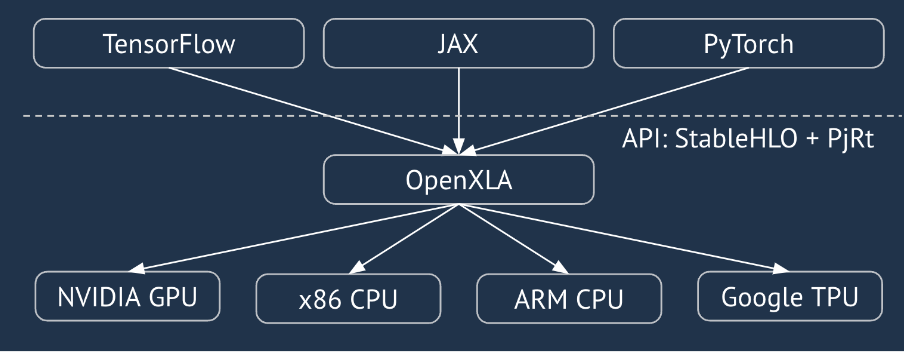
সঞ্চালনের সময়, ফ্রেমওয়ার্কগুলি PJRT রানটাইম API-কে আহ্বান করে, যা ফ্রেমওয়ার্কগুলিকে "একটি নির্দিষ্ট ডিভাইসে একটি প্রদত্ত StableHLO প্রোগ্রাম ব্যবহার করে নির্দিষ্ট বাফারগুলিকে পপুলেট করে" অপারেশন করতে দেয়।
XLA: GPU পাইপলাইন
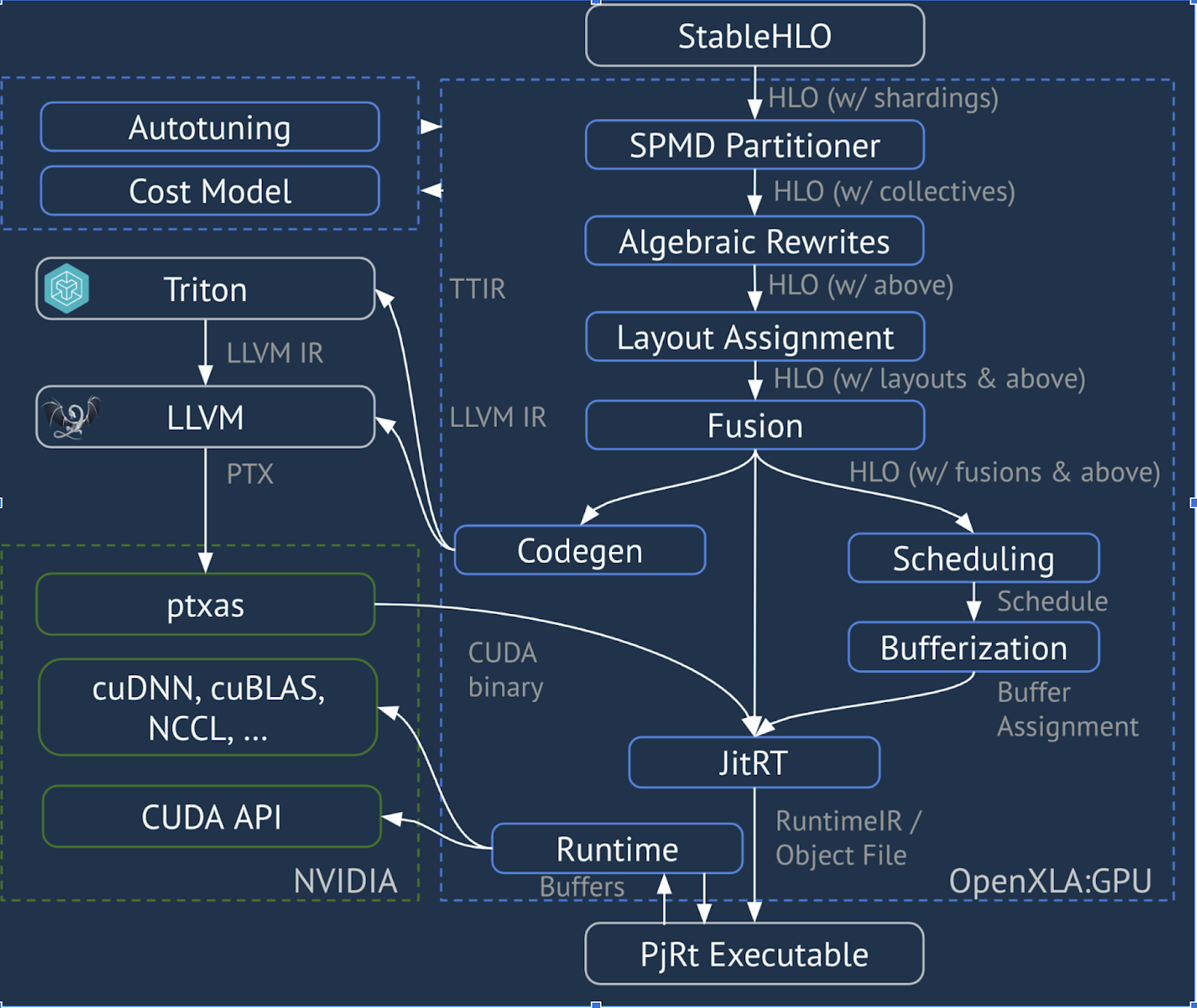
XLA:GPU উচ্চ-কার্যক্ষমতা সম্পন্ন GPU কার্নেল তৈরি করতে "নেটিভ" (PTX, LLVM এর মাধ্যমে) ইমিটার এবং TritonIR ইমিটারের সংমিশ্রণ ব্যবহার করে (নীল রঙ 3P উপাদান নির্দেশ করে):
চলমান উদাহরণ: JAX
পাইপলাইনটি ব্যাখ্যা করার জন্য, চলুন JAX-এ একটি চলমান উদাহরণ দিয়ে শুরু করা যাক, যা একটি ধ্রুবক এবং নেগেশান দ্বারা গুণের সাথে মিলিত একটি ম্যাটমুল গণনা করে:
def f(a, b):
return -((a @ b) * 0.125)
আমরা ফাংশন দ্বারা উত্পন্ন HLO পরিদর্শন করতে পারি:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
যা উৎপন্ন করে:
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
আমরা jax.xla_computation(f)(a, b).as_hlo_dot_graph() ব্যবহার করে ইনপুট HLO কম্পিউটেশনকেও কল্পনা করতে পারি :
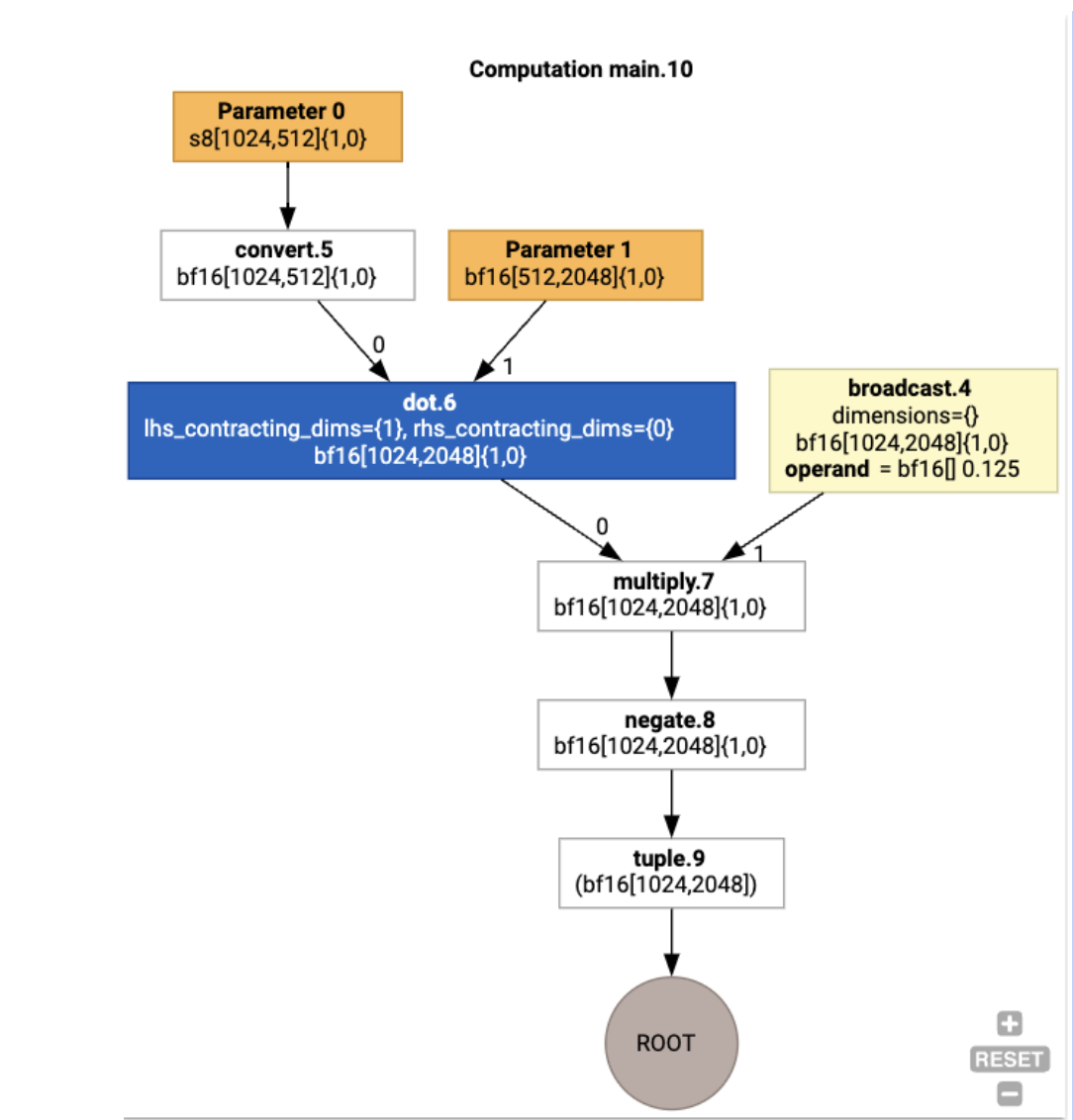
HLO-তে অপ্টিমাইজেশন: মূল উপাদান
HLO-তে HLO->HLO পুনঃলিখন হিসাবে বেশ কয়েকটি উল্লেখযোগ্য অপ্টিমাইজেশন পাস ঘটে।
SPMD পার্টিশনার
XLA SPMD বিভাজনকারী, যেমন GSPMD-এ বর্ণিত: MLCকম্পিউটেশন গ্রাফের জন্য সাধারণ এবং স্কেলযোগ্য সমান্তরালকরণ , শার্ডিং টীকা সহ HLO ব্যবহার করে (যেমন jax.pjit দ্বারা উত্পাদিত), এবং একটি শার্ডেড এইচএলও তৈরি করে যা পরে বেশ কয়েকটি হোস্ট এবং ডিভাইসে চলতে পারে। বিভাজন ছাড়াও, SPMD একটি সর্বোত্তম সম্পাদনের সময়সূচী, ওভারল্যাপিং গণনা এবং নোডের মধ্যে যোগাযোগের জন্য HLO-কে অপ্টিমাইজ করার চেষ্টা করে।
উদাহরণ
দুটি ডিভাইস জুড়ে একটি সাধারণ JAX প্রোগ্রাম থেকে শুরু করার কথা বিবেচনা করুন:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
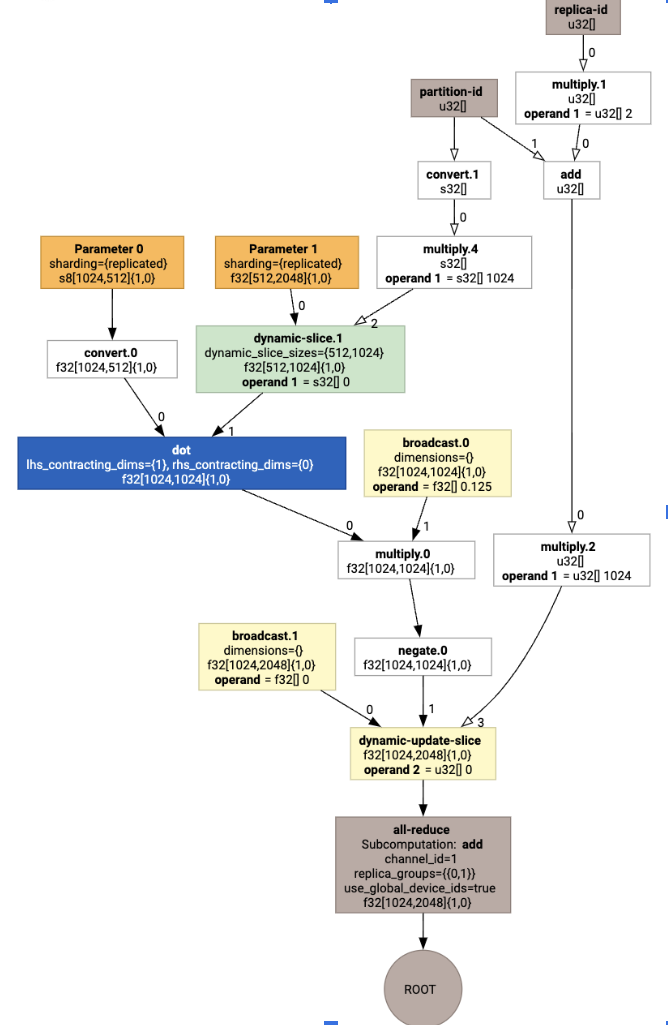
এটিকে ভিজ্যুয়ালাইজ করে, শার্ডিং টীকাগুলি কাস্টম কল হিসাবে উপস্থাপন করা হয়:
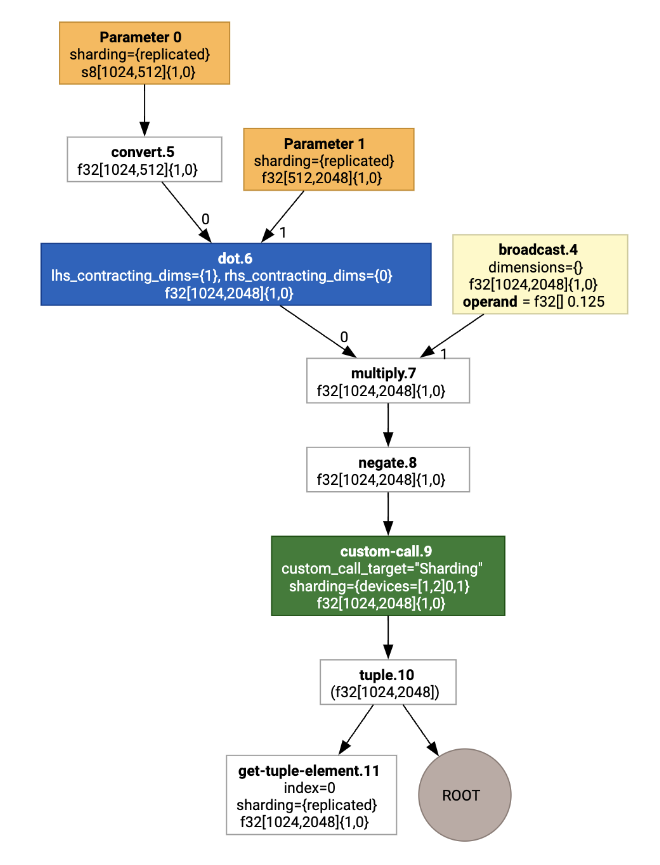
SPMD পার্টিশনার কাস্টম কলটি কীভাবে প্রসারিত করে তা পরীক্ষা করতে, আমরা অপ্টিমাইজেশনের পরে HLO দেখতে পারি:
print(f.lower(np.ones((8, 8)).compile().as_text())
যা একটি সমষ্টির সাথে HLO তৈরি করে:
লেআউট অ্যাসাইনমেন্ট
এইচএলও লজিক্যাল আকৃতি এবং ফিজিক্যাল লেআউটকে ডিকপল করে (মেমরিতে কীভাবে টেনসর বিছানো হয়)। উদাহরণস্বরূপ, একটি ম্যাট্রিক্স f32[32, 64] যথাক্রমে {1,0} বা {0,1} হিসাবে উপস্থাপিত সারি-মেজর বা কলাম-প্রধান ক্রম অনুসারে উপস্থাপন করা যেতে পারে। সাধারণভাবে, বিন্যাসকে আকৃতির একটি অংশ হিসাবে উপস্থাপন করা হয়, মেমরিতে শারীরিক বিন্যাস নির্দেশ করে মাত্রার সংখ্যার উপর একটি স্থানান্তর দেখায়।
এইচএলও-তে উপস্থিত প্রতিটি অপারেশনের জন্য, লেআউট অ্যাসাইনমেন্ট পাস একটি সর্বোত্তম লেআউট বেছে নেয় (যেমন অ্যাম্পিয়ারে কনভোল্যুশনের জন্য NHWC)। উদাহরণস্বরূপ, একটি int8xint8->int32 matmul অপারেশন গণনার RHS-এর জন্য {0,1} লেআউট পছন্দ করে। একইভাবে, ব্যবহারকারী দ্বারা ঢোকানো "ট্রান্সপোজ" উপেক্ষা করা হয় এবং লেআউট পরিবর্তন হিসাবে এনকোড করা হয়।
লেআউটগুলি তারপর গ্রাফের মাধ্যমে প্রচারিত হয়, এবং লেআউট বা গ্রাফ এন্ডপয়েন্টের মধ্যে দ্বন্দ্বগুলি copy অপারেশন হিসাবে বাস্তবায়িত হয়, যা শারীরিক স্থানান্তর সম্পাদন করে। উদাহরণস্বরূপ, গ্রাফ থেকে শুরু
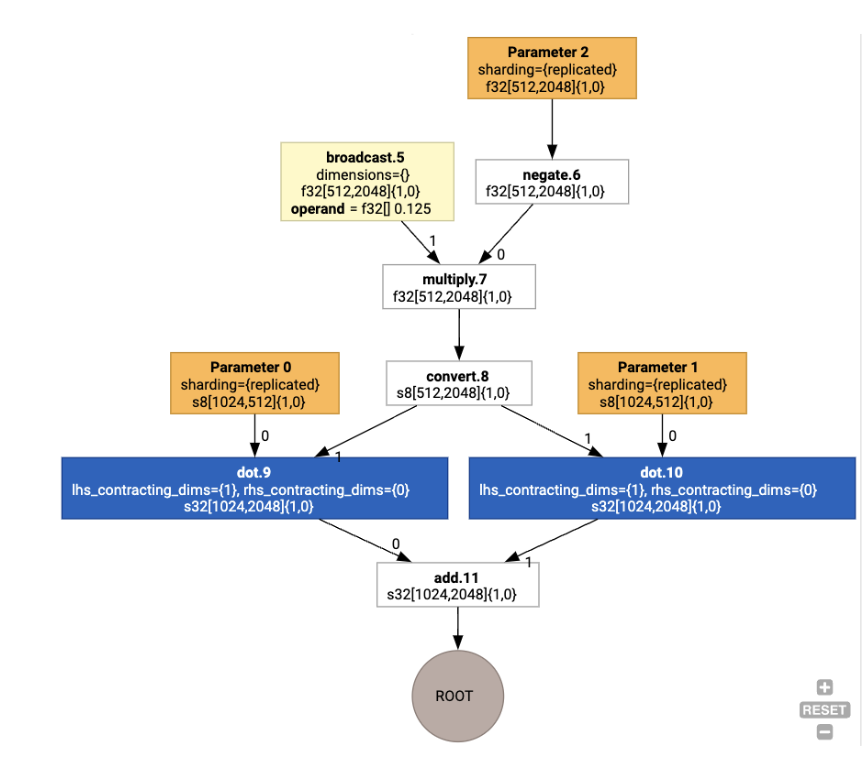
লেআউট অ্যাসাইনমেন্ট চালানোর সময় আমরা নিম্নলিখিত লেআউট এবং copy অপারেশন সন্নিবেশিত দেখতে পাই:
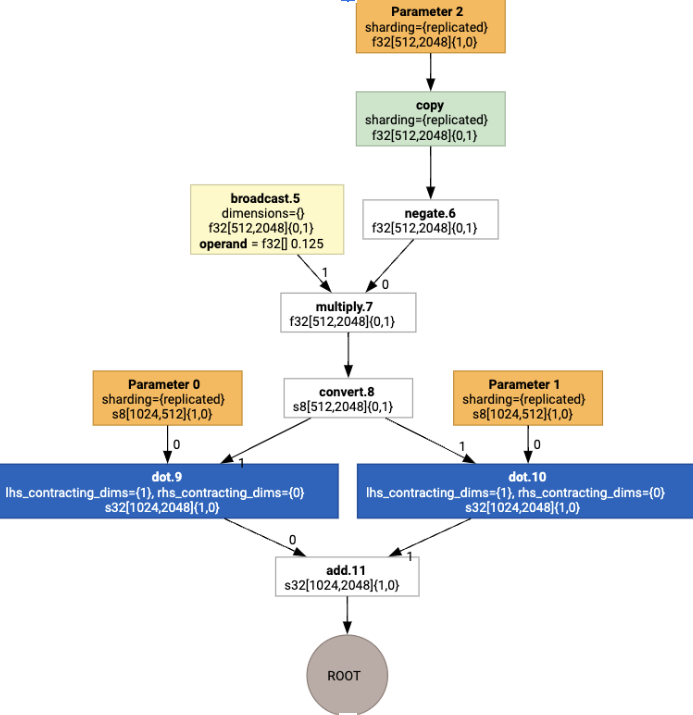
ফিউশন
ফিউশন হল XLA-এর একক সবচেয়ে গুরুত্বপূর্ণ অপ্টিমাইজেশান, যা একাধিক ক্রিয়াকলাপকে (যেমন matmul-এ exponentiation এ যোগ) একটি একক কার্নেলে গোষ্ঠীভুক্ত করে। যেহেতু অনেক জিপিইউ ওয়ার্কলোড মেমরি-বাউন্ড হওয়ার প্রবণতা থাকে, তাই ফিউশন নাটকীয়ভাবে এইচবিএম-এ মধ্যবর্তী টেনসর লেখা এড়িয়ে এবং তারপরে সেগুলিকে আবার পড়ে এবং পরিবর্তে রেজিস্টার বা শেয়ার করা মেমরিতে সেগুলিকে পাস করে।
ফিউজড এইচএলও নির্দেশাবলী একটি একক ফিউশন কম্পিউটেশনে একত্রে ব্লক করা হয়েছে, যা নিম্নলিখিত পরিবর্তনগুলিকে প্রতিষ্ঠা করে:
ফিউশনের অভ্যন্তরে কোনও মধ্যবর্তী সঞ্চয়স্থান HBM-এ বাস্তবায়িত হয় না (এটি সমস্ত রেজিস্টার বা শেয়ার্ড মেমরির মাধ্যমে পাস করতে হবে)।
একটি ফিউশন সবসময় ঠিক একটি GPU কার্নেলে সংকলিত হয়
চলমান উদাহরণে HLO অপ্টিমাইজেশান
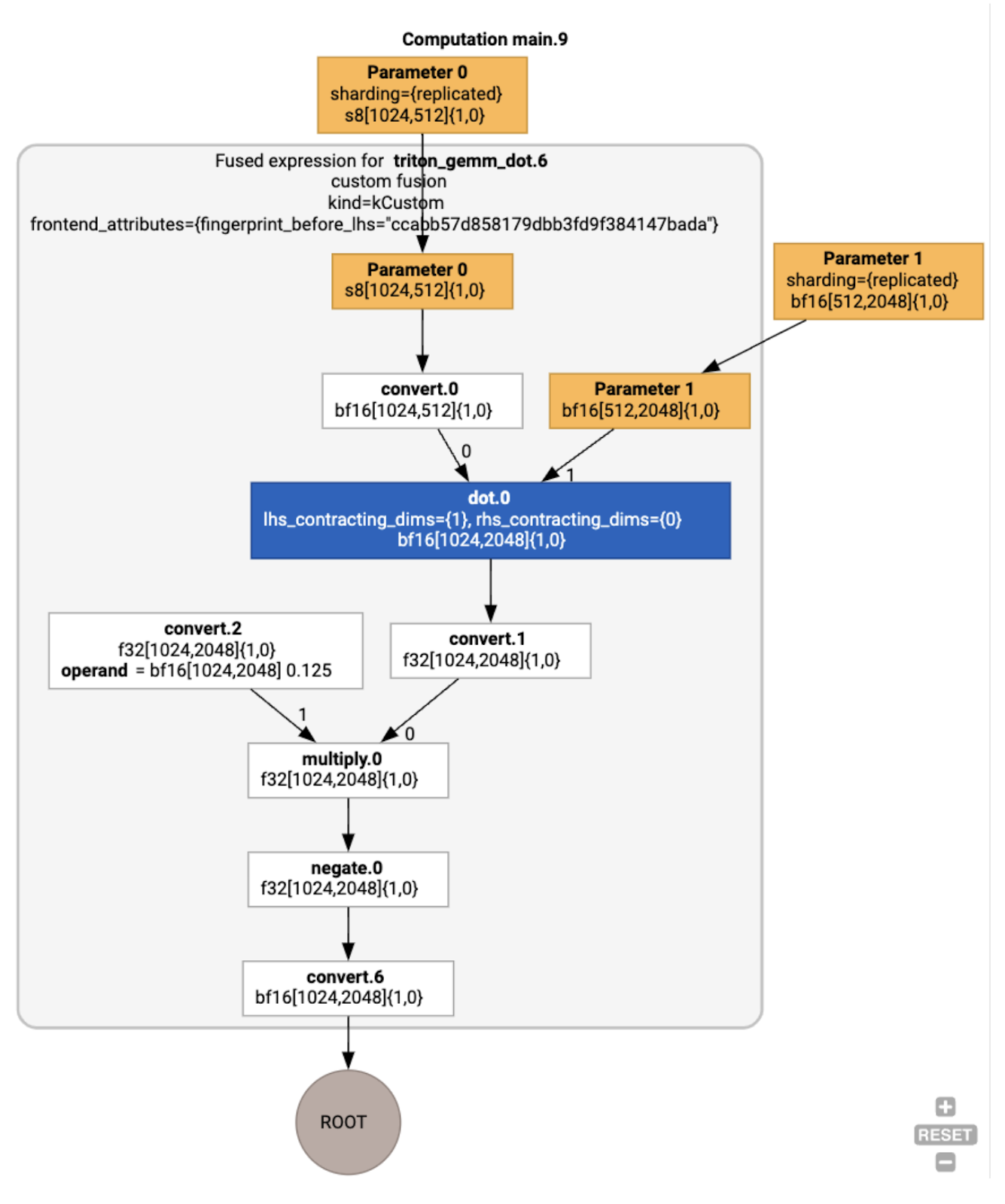
আমরা jax.jit(f).lower(a, b).compile().as_text() ব্যবহার করে পোস্ট-অপ্টিমাইজেশান HLO পরিদর্শন করতে পারি এবং যাচাই করতে পারি যে একটি একক ফিউশন তৈরি হয়েছে:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
মনে রাখবেন যে ফিউশন backend_config আমাদের বলে যে ট্রাইটন একটি কোড জেনারেশন কৌশল হিসাবে ব্যবহার করা হবে এবং এটি নির্বাচিত টাইলিং নির্দিষ্ট করে।
আমরা ফলাফল মডিউলটিও কল্পনা করতে পারি:
বাফার অ্যাসাইনমেন্ট এবং সময়সূচী
একটি বাফার অ্যাসাইনমেন্ট পাস আকৃতির তথ্য বিবেচনা করে এবং প্রোগ্রামের জন্য একটি সর্বোত্তম বাফার বরাদ্দ তৈরি করার লক্ষ্য রাখে, মধ্যবর্তী মেমরির পরিমাণ কমিয়ে দেয়। TF বা PyTorch ইমিডিয়েট-মোড (অ-সংকলিত) এক্সিকিউশনের বিপরীতে, যেখানে মেমরি বরাদ্দকারী গ্রাফটি আগে থেকে জানে না, XLA শিডিয়ুলার "ভবিষ্যতের দিকে তাকাতে" এবং একটি সর্বোত্তম গণনার সময়সূচী তৈরি করতে পারে।
কম্পাইলার ব্যাকএন্ড: কোডজেন এবং লাইব্রেরি নির্বাচন
কম্পিউটেশনের প্রতিটি HLO নির্দেশের জন্য, XLA এটিকে রানটাইমের সাথে লিঙ্ক করা একটি লাইব্রেরি ব্যবহার করে চালানোর জন্য বা PTX-এ কোডজেন করার জন্য বেছে নেয়।
লাইব্রেরি নির্বাচন
অনেক সাধারণ ক্রিয়াকলাপের জন্য, XLA:GPU NVIDIA থেকে দ্রুত-পারফরম্যান্স লাইব্রেরি ব্যবহার করে, যেমন cuBLAS, cuDNN, এবং NCCL। লাইব্রেরিগুলির যাচাইকৃত দ্রুত কর্মক্ষমতার একটি সুবিধা রয়েছে, তবে প্রায়শই জটিল ফিউশন সুযোগগুলিকে বাধা দেয়।
সরাসরি কোড প্রজন্ম
XLA:GPU ব্যাকএন্ড উচ্চ-কার্যক্ষমতা সম্পন্ন LLVM IR তৈরি করে বিভিন্ন অপারেশনের জন্য (হ্রাস, ট্রান্সপোজ ইত্যাদি)।
ট্রাইটন কোড প্রজন্ম
আরও উন্নত ফিউশনের জন্য যার মধ্যে রয়েছে ম্যাট্রিক্স গুণন বা সফটম্যাক্স, XLA:GPU ট্রাইটনকে কোড-জেনারেশন লেয়ার হিসেবে ব্যবহার করে। HLO ফিউশনগুলি TritonIR-এ রূপান্তরিত হয় (একটি MLIR উপভাষা যা Triton-এ একটি ইনপুট হিসাবে কাজ করে), টাইলিং প্যারামিটার নির্বাচন করে এবং PTX জেনারেশনের জন্য Triton আহ্বান করে:
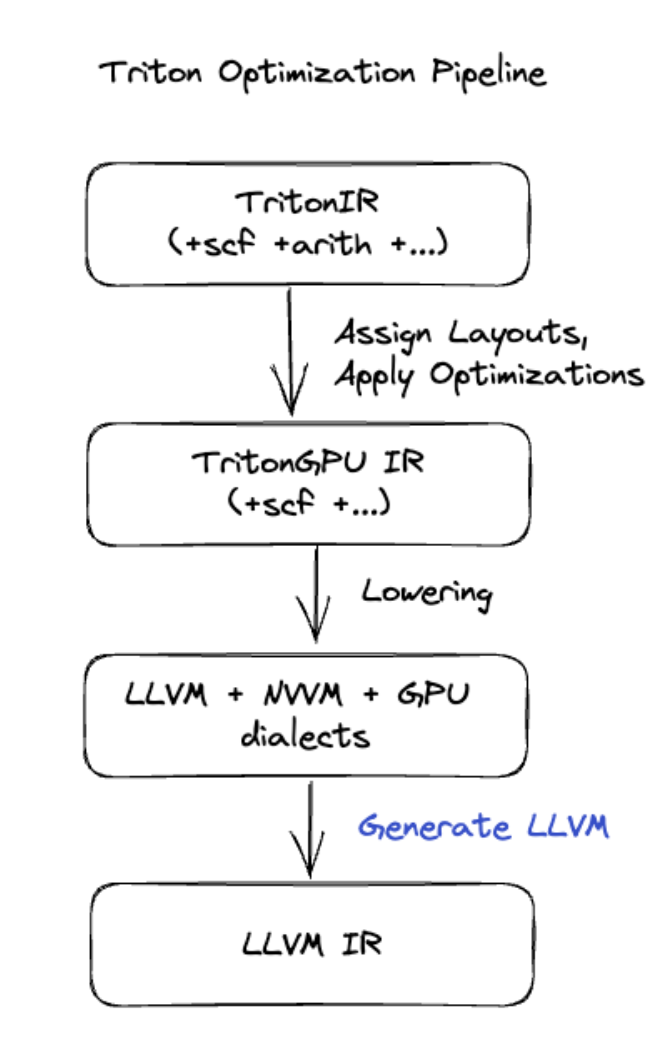
আমরা সঠিকভাবে টিউন করা টাইল আকারের সাথে কাছাকাছি-ছাদের পারফরম্যান্সে অ্যাম্পিয়ারে খুব ভাল পারফর্ম করার ফলস্বরূপ কোডটি পর্যবেক্ষণ করেছি।
রানটাইম
XLA রানটাইম CUDA কার্নেল কল এবং লাইব্রেরি আহ্বানের ফলস্বরূপ একটি RuntimeIR (XLA-তে একটি MLIR উপভাষা) তে রূপান্তরিত করে, যার উপর CUDA গ্রাফ নিষ্কাশন করা হয়। CUDA গ্রাফ এখনও কাজ চলছে, শুধুমাত্র কিছু নোড বর্তমানে সমর্থিত। একবার CUDA গ্রাফের সীমানা বের করা হয়ে গেলে, RuntimeIR LLVM-এর মাধ্যমে একটি CPU এক্সিকিউটেবলে কম্পাইল করা হয়, যা পরবর্তী সময়ে সংরক্ষিত বা স্থানান্তর করা যেতে পারে।