
Einführung
XLA ist ein hardware- und frameworkspezifischer Compiler für lineare Algebra, der eine erstklassige Leistung bietet. JAX, TF, PyTorch und andere verwenden XLA, indem sie die Nutzereingabe in den StableHLO-Vorgangssatz („High-Level-Operation“: eine Reihe von etwa 100 statisch geformten Anweisungen wie Addition, Subtraktion, Matmul usw.) konvertieren, aus dem XLA optimierten Code für eine Vielzahl von Back-Ends erzeugt:
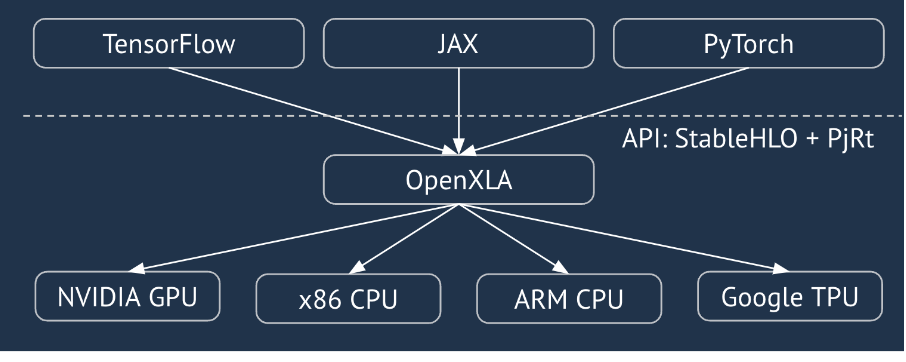
Während der Ausführung rufen die Frameworks die PJRT-Laufzeit-API auf, mit der die Frameworks den Vorgang „Die angegebenen Puffer mit einem bestimmten StableHLO-Programm auf einem bestimmten Gerät füllen“ ausführen können.
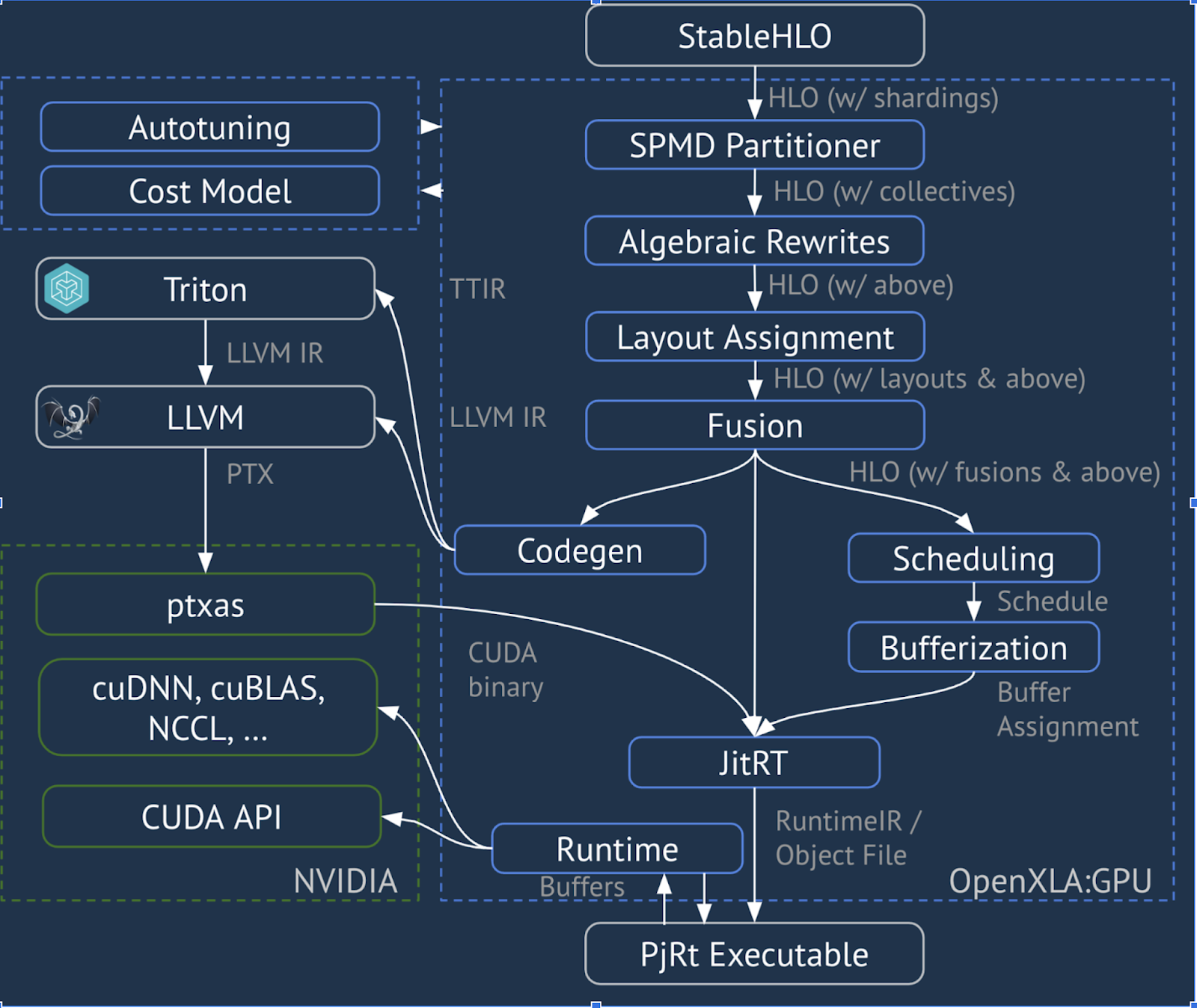
XLA:GPU-Pipeline
XLA:GPU verwendet eine Kombination aus „nativen“ (PTX, über LLVM) und TritonIR-Emittern, um leistungsstarke GPU-Kernel zu generieren (die blaue Farbe weist auf 3P-Komponenten hin):
Beispiel für die Ausführung: JAX
Zur Veranschaulichung der Pipeline beginnen wir mit einem laufenden Beispiel in JAX, das eine Matmul-Operation in Kombination mit der Multiplikation mit einer Konstanten und der Negation berechnet:
def f(a, b):
return -((a @ b) * 0.125)
Wir können das von der Funktion generierte HLO so prüfen:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
Dadurch wird Folgendes generiert:
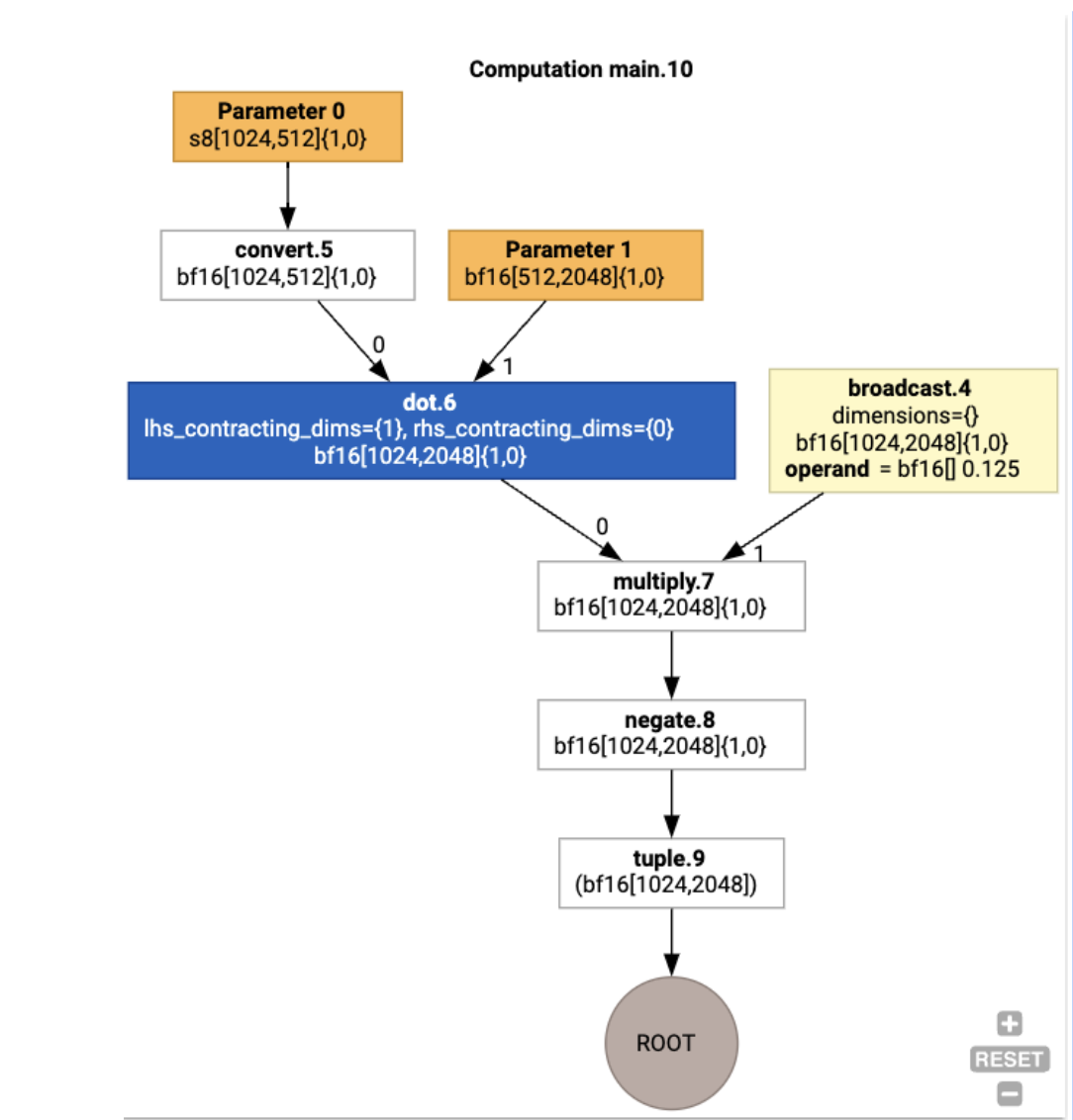
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
Wir können die HLO-Eingabeberechnung auch mit jax.xla_computation(f)(a, b).as_hlo_dot_graph() visualisieren:
Optimierungen auf HLO-Ebene: Wichtige Komponenten
Eine Reihe wichtiger Optimierungsdurchläufe erfolgt für HLO als HLO->HLO-Umschreibungen.
SPMD-Partitionierer
Der XLA SPMD-Partitionierer, wie in GSPMD: General and Scalable Parallelization for MLComputation Graphs beschrieben, verwendet HLO mit Sharding-Anmerkungen (z.B. von jax.pjit) und erzeugt ein geshardetes HLO, das dann auf einer Reihe von Hosts und Geräten ausgeführt werden kann.
Abgesehen von der Partitionierung versucht SPMD, HLO für einen optimalen Ausführungsplan zu optimieren, indem die Berechnung und Kommunikation zwischen den Knoten überlappt werden.
Beispiel
Beginnen Sie mit einem einfachen JAX-Programm, das auf zwei Geräte aufgeteilt ist:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
Die Sharding-Anmerkungen werden als benutzerdefinierte Aufrufe dargestellt:
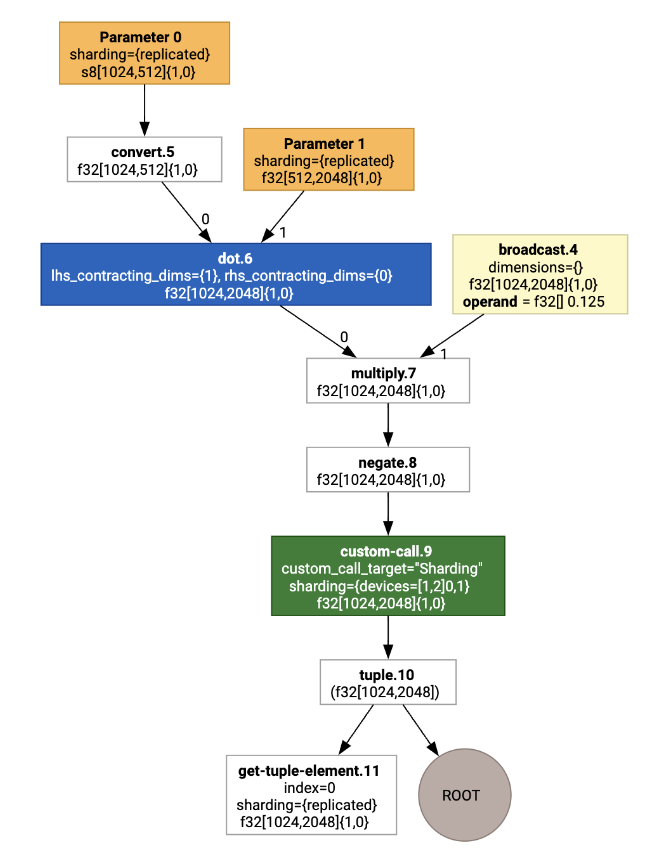
Um zu sehen, wie der SPMD-Partitionierer den benutzerdefinierten Aufruf erweitert, können wir uns das HLO nach den Optimierungen ansehen:
print(f.lower(np.ones((8, 8)).compile().as_text())
Dadurch wird HLO mit einem Kollektiv generiert:
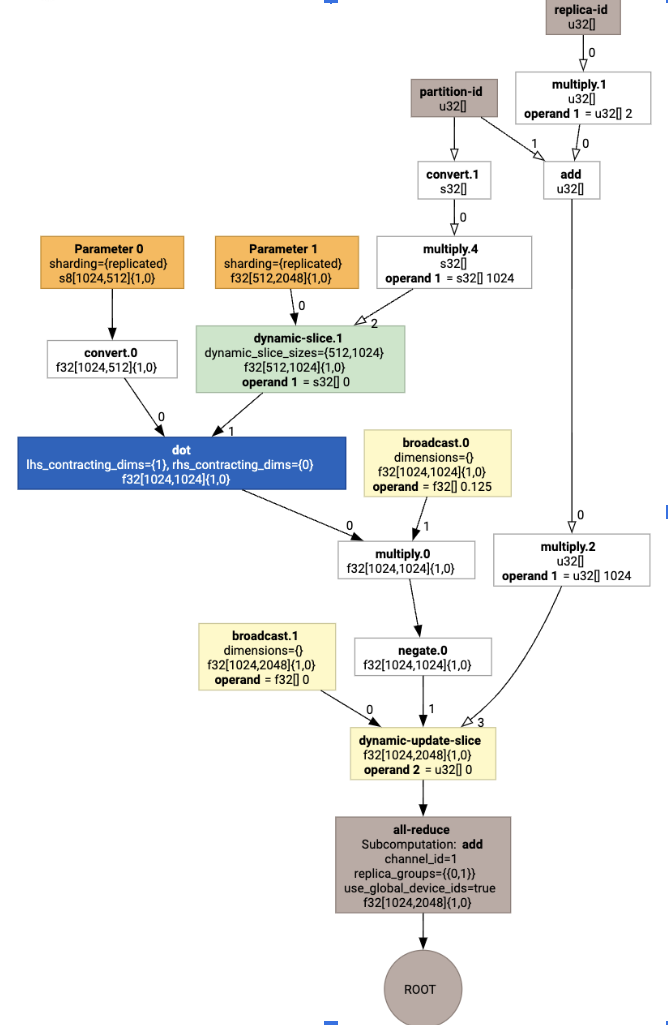
Layoutzuweisung
In HLO werden die logische Form und das physische Layout (wie Tensoren im Speicher angeordnet sind) entkoppelt. Eine Matrix f32[32, 64] kann beispielsweise entweder in zeilenweiser oder spaltenweiser Reihenfolge dargestellt werden, also als {1,0} bzw. {0,1}.
Im Allgemeinen wird das Layout als Teil der Form dargestellt. Es zeigt eine Permutation über die Anzahl der Dimensionen an, die das physische Layout im Arbeitsspeicher angibt.
Für jeden Vorgang im HLO wählt der Layout Assignment-Pass ein optimales Layout aus (z.B. NHWC für eine Faltung auf Ampere). Bei einer int8xint8->int32-matmul-Operation wird beispielsweise das {0,1}-Layout für die rechte Seite der Berechnung bevorzugt. Ebenso werden vom Nutzer eingefügte „Transponierungen“ ignoriert und als Layoutänderung codiert.
Die Layouts werden dann durch den Graphen weitergegeben und Konflikte zwischen Layouts oder an den Endpunkten des Graphen werden als copy-Vorgänge materialisiert, die die physische Transponierung ausführen. Ausgehend vom Diagramm
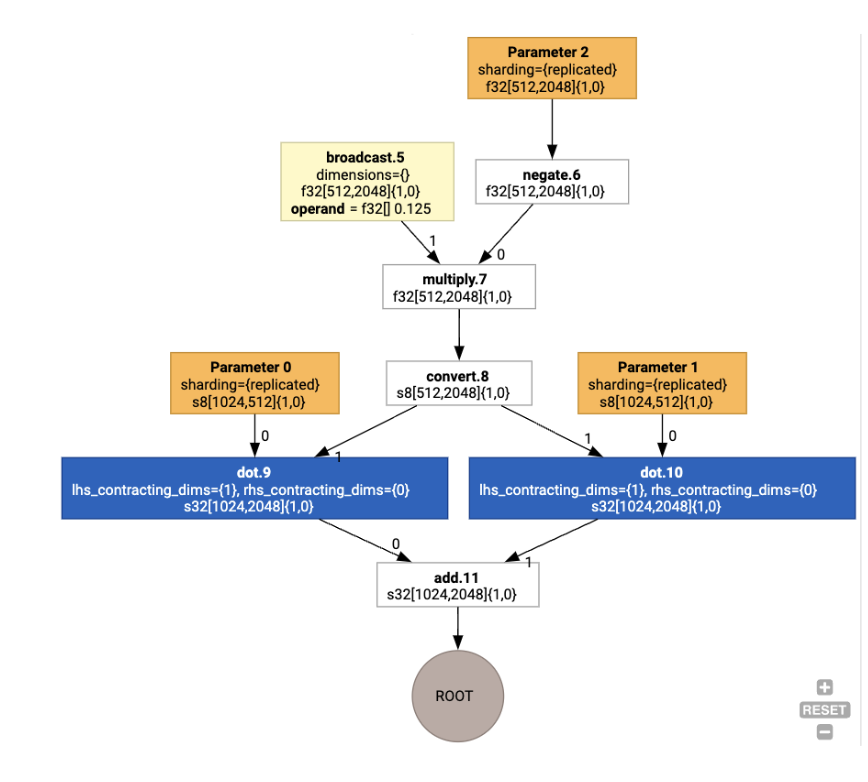
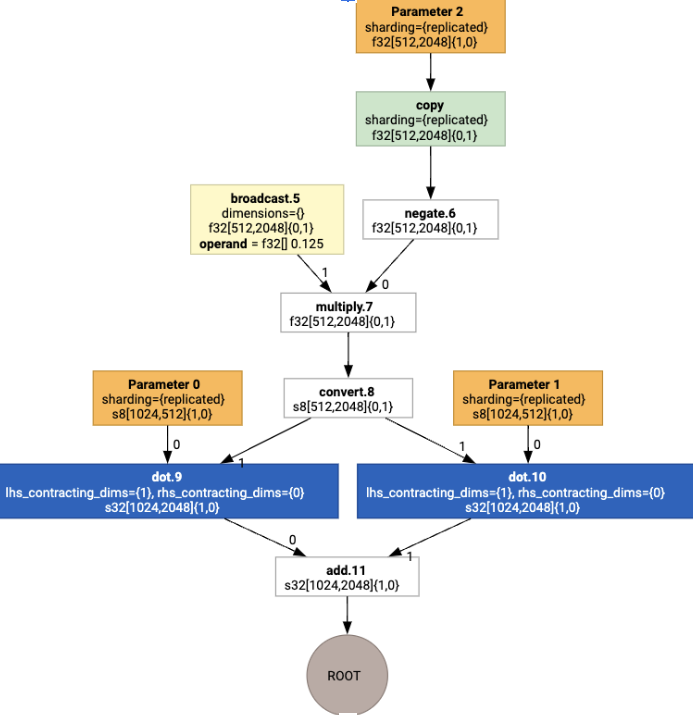
Wenn wir die Layoutzuweisung ausführen, sehen wir die folgenden Layouts und den eingefügten copy-Vorgang:
Fusion
Fusion ist die wichtigste Optimierung von XLA. Dabei werden mehrere Vorgänge (z. B. Addition, Potenzierung und Matmul) in einem einzigen Kernel zusammengefasst. Da viele GPU-Arbeitslasten tendenziell speichergebunden sind, wird die Ausführung durch die Zusammenführung erheblich beschleunigt, da das Schreiben von Zwischen-Tensoren in den HBM und das anschließende Zurücklesen vermieden wird. Stattdessen werden sie entweder in Registern oder im gemeinsam genutzten Speicher übergeben.
Zusammengeführte HLO-Anweisungen werden in einer einzigen Fusionsberechnung zusammengefasst, wodurch die folgenden Invarianten festgelegt werden:
Bei der Fusion wird kein Zwischenspeicher in HBM materialisiert. Alle Daten müssen entweder über Register oder gemeinsam genutzten Speicher übertragen werden.
Eine Fusion wird immer in genau einen GPU-Kernel kompiliert.
HLO-Optimierungen im Beispiel
Wir können das HLO nach der Optimierung mit jax.jit(f).lower(a,
b).compile().as_text() untersuchen und prüfen, ob eine einzelne Fusion generiert wurde:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
Die Fusion backend_config gibt an, dass Triton als Strategie zur Codegenerierung verwendet wird, und legt die ausgewählte Kachelung fest.
Wir können das resultierende Modul auch visualisieren:
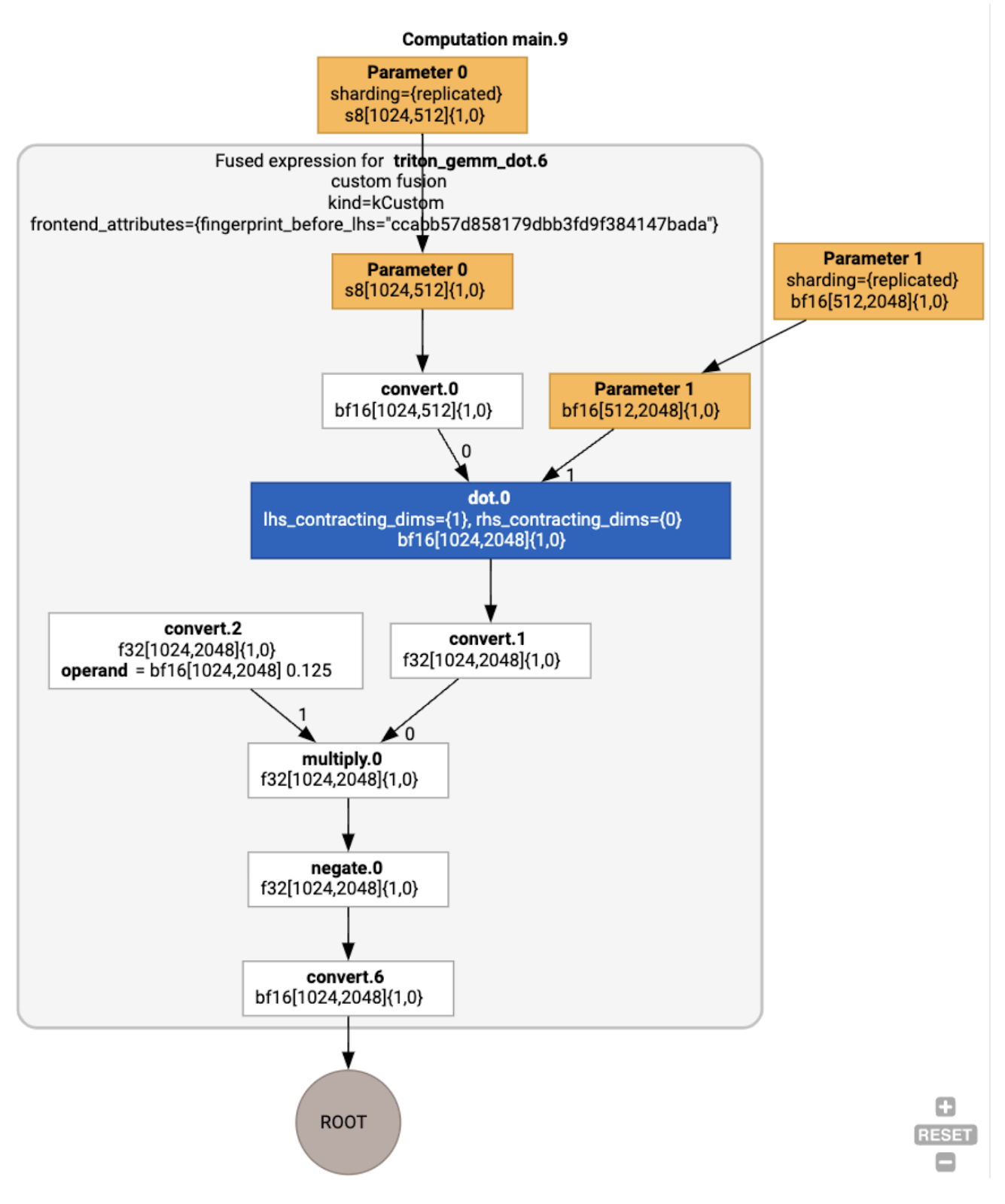
Zwischenspeicherzuweisung und ‑planung
Bei der Pufferzuweisung werden die Forminformationen berücksichtigt. Ziel ist es, eine optimale Pufferzuweisung für das Programm zu erstellen und die Menge des verbrauchten Zwischenspeichers zu minimieren. Anders als bei der sofortigen Ausführung (nicht kompiliert) in TF oder PyTorch, bei der der Speicher-Allocator den Graphen nicht im Voraus kennt, kann der XLA-Scheduler „in die Zukunft sehen“ und einen optimalen Berechnungsplan erstellen.
Compiler-Backend: Codegenerierung und Bibliothekauswahl
Für jede HLO-Anweisung in der Berechnung wählt XLA aus, ob sie mit einer in eine Laufzeitumgebung eingebundenen Bibliothek ausgeführt oder in PTX-Code generiert werden soll.
Bibliotheksauswahl
Für viele gängige Vorgänge verwendet XLA:GPU leistungsstarke Bibliotheken von NVIDIA, z. B. cuBLAS, cuDNN und NCCL. Die Bibliotheken bieten den Vorteil einer geprüften schnellen Leistung, schließen aber oft komplexe Fusionsmöglichkeiten aus.
Direkte Codegenerierung
Das XLA:GPU-Backend generiert direkt leistungsstarke LLVM-IR für eine Reihe von Vorgängen (Reduzierungen, Transponierungen usw.).
Triton-Codegenerierung
Für komplexere Fusions, die Matrixmultiplikation oder Softmax umfassen, verwendet XLA:GPU Triton als Code-Generierungsebene. HLO-Fusions werden in TritonIR (einen MLIR-Dialekt, der als Eingabe für Triton dient) konvertiert, es werden Kachelparameter ausgewählt und Triton wird für die PTX-Generierung aufgerufen:
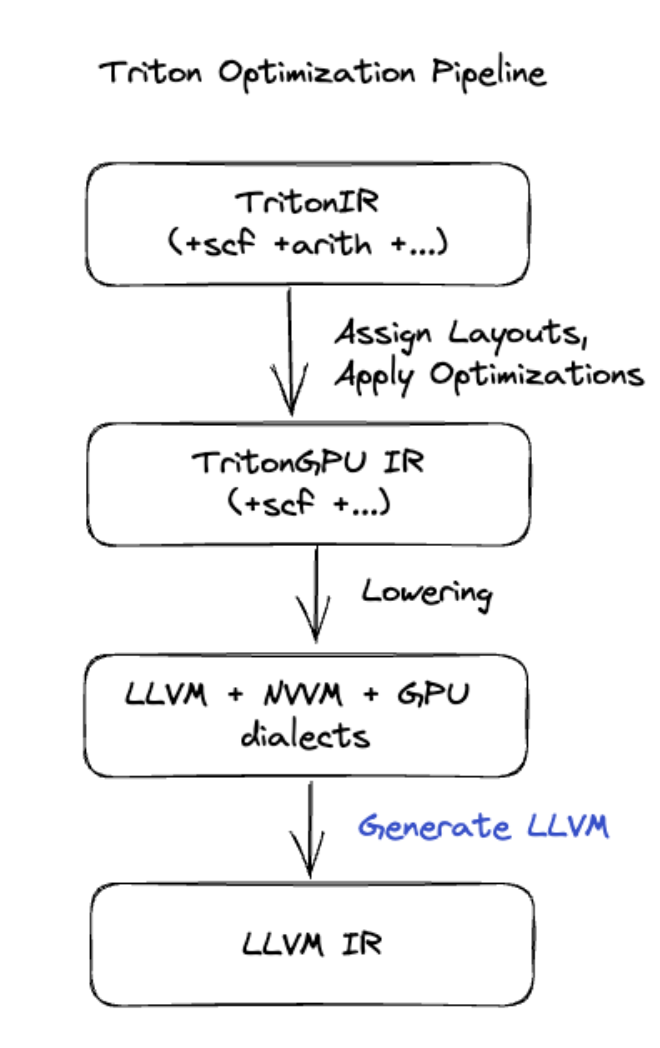
Der resultierende Code funktioniert auf Ampere sehr gut und erreicht mit richtig abgestimmten Kachelgrößen eine Leistung, die nahe am Dach liegt.
Laufzeit
Die XLA-Laufzeit konvertiert die resultierende Sequenz von CUDA-Kernelaufrufen und Bibliotheksaufrufen in RuntimeIR (einen MLIR-Dialekt in XLA), für die die CUDA-Grafik extrahiert wird. CUDA-Diagramme sind noch in der Entwicklung. Derzeit werden nur einige Knoten unterstützt. Sobald die CUDA-Grafikgrenzen extrahiert wurden, wird RuntimeIR über LLVM in eine CPU-Ausführungsdatei kompiliert, die dann für die Ahead-Of-Time-Kompilierung gespeichert oder übertragen werden kann.