
Introducción
XLA es un compilador específico del dominio de hardware y del framework para el álgebra lineal que ofrece el mejor rendimiento de su clase. JAX, TF, PyTorch y otros usan XLA convirtiendo la entrada del usuario en un conjunto de operaciones de StableHLO (“operación de alto nivel”: un conjunto de alrededor de 100 instrucciones con forma estática, como suma, resta, multiplicación de matrices, etc.), a partir del cual XLA produce código optimizado para una variedad de backends:
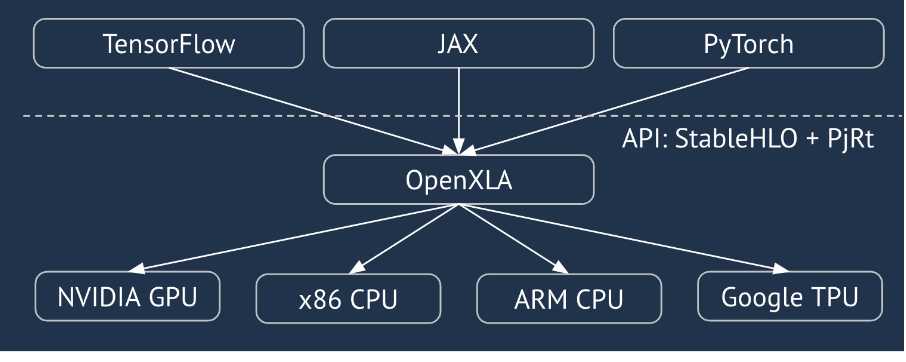
Durante la ejecución, los frameworks invocan la API del tiempo de ejecución de PJRT, que permite que los frameworks realicen la operación "propagar los búferes especificados con un programa StableHLO determinado en un dispositivo específico".
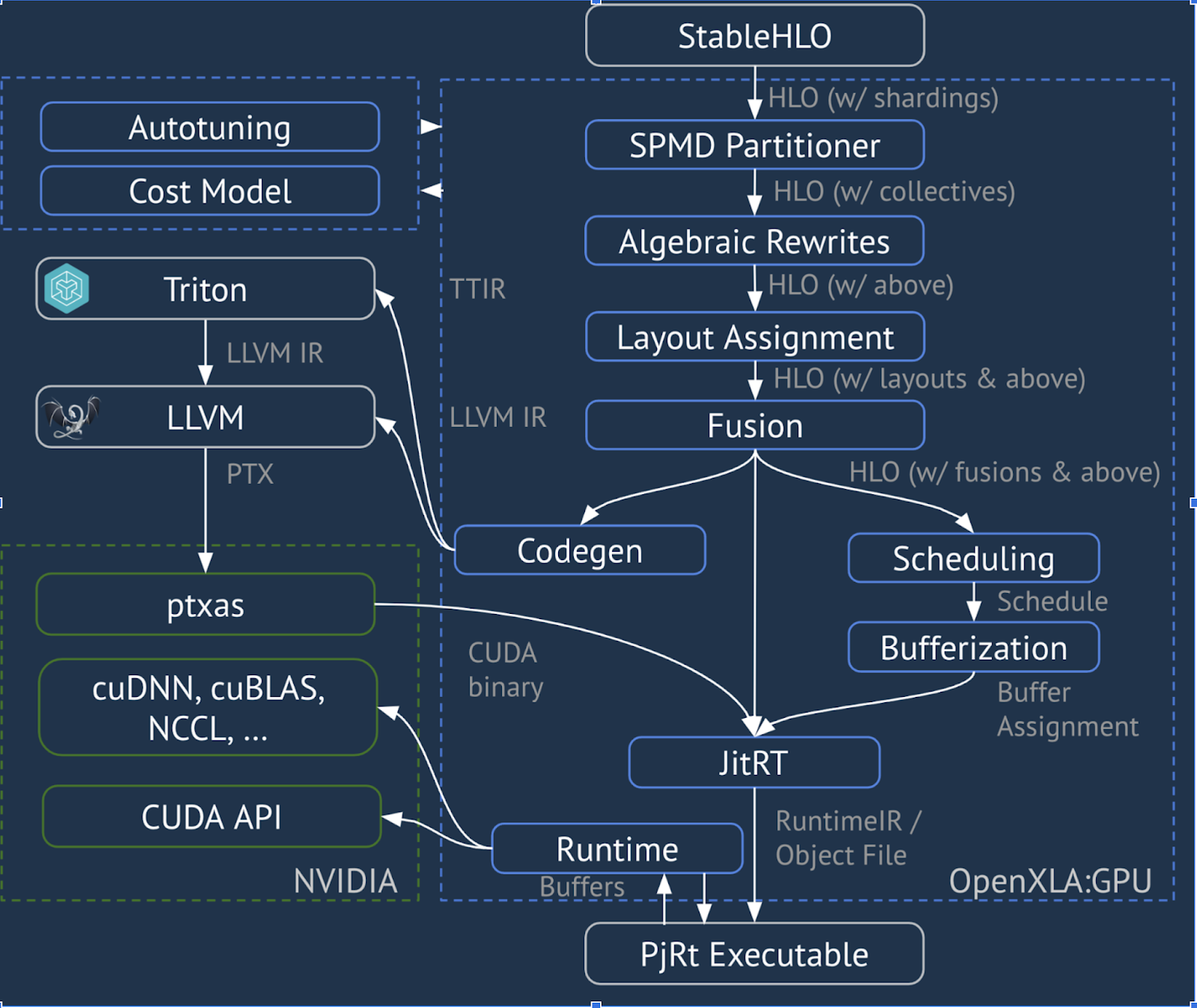
Canalización de XLA:GPU
XLA:GPU usa una combinación de emisores "nativos" (PTX, a través de LLVM) y emisores de TritonIR para generar kernels de GPU de alto rendimiento (el color azul indica componentes de terceros):
Ejemplo de ejecución: JAX
Para ilustrar la canalización, comencemos con un ejemplo en ejecución en JAX, que calcula una multiplicación de matrices combinada con la multiplicación por una constante y la negación:
def f(a, b):
return -((a @ b) * 0.125)
Podemos inspeccionar el HLO que genera la función:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
que genera lo siguiente:
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
También podemos visualizar el cálculo de HLO de entrada con jax.xla_computation(f)(a, b).as_hlo_dot_graph():
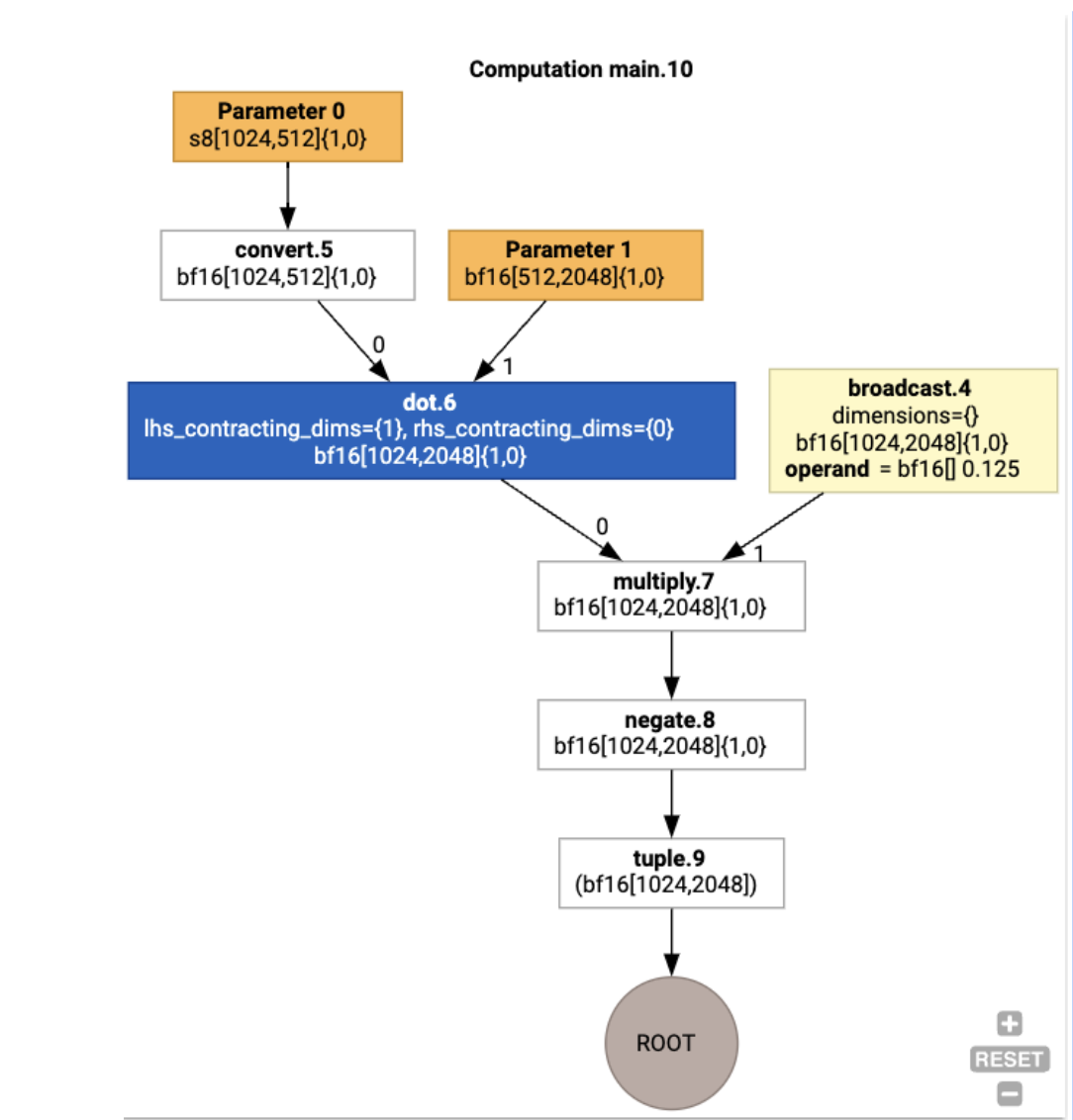
Optimizaciones en HLO: Componentes clave
En HLO, se realizan varias fases de optimización notables, como reescrituras de HLO->HLO.
Particionador SPMD
El particionador SPMD de XLA, como se describe en GSPMD: General and Scalable Parallelization for ML Computation Graphs, consume HLO con anotaciones de fragmentación (producidas, p.ej., por jax.pjit) y produce un HLO fragmentado que luego se puede ejecutar en varios hosts y dispositivos.
Además de la partición, el SPMD intenta optimizar el HLO para lograr una programación de ejecución óptima, con superposición de la comunicación y el procesamiento entre los nodos.
Ejemplo
Considera comenzar con un programa de JAX simple que se divida en dos dispositivos:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
Si lo visualizamos, las anotaciones de fragmentación se presentan como llamadas personalizadas:
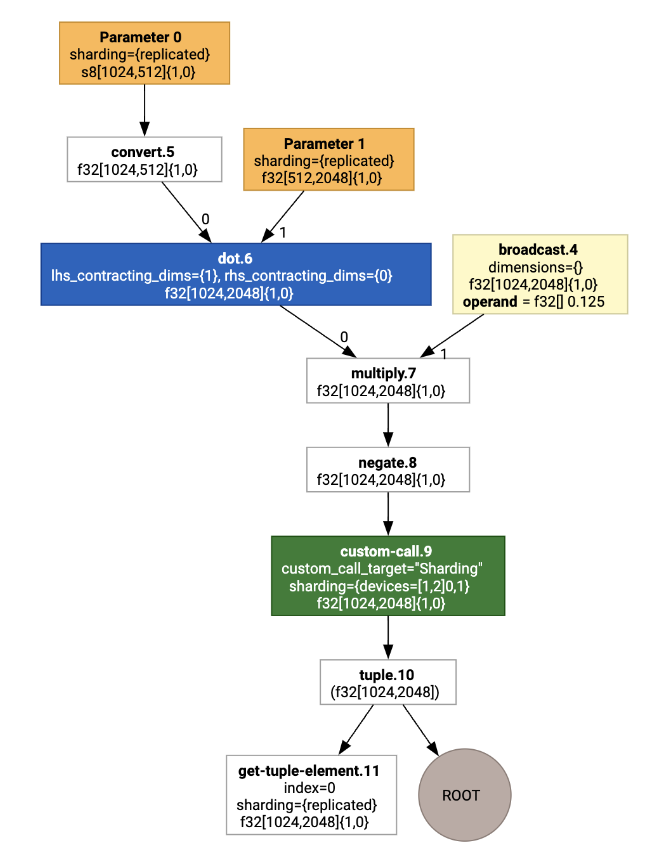
Para verificar cómo el particionador SPMD expande la llamada personalizada, podemos observar el HLO después de las optimizaciones:
print(f.lower(np.ones((8, 8)).compile().as_text())
Esto genera HLO con un colectivo:
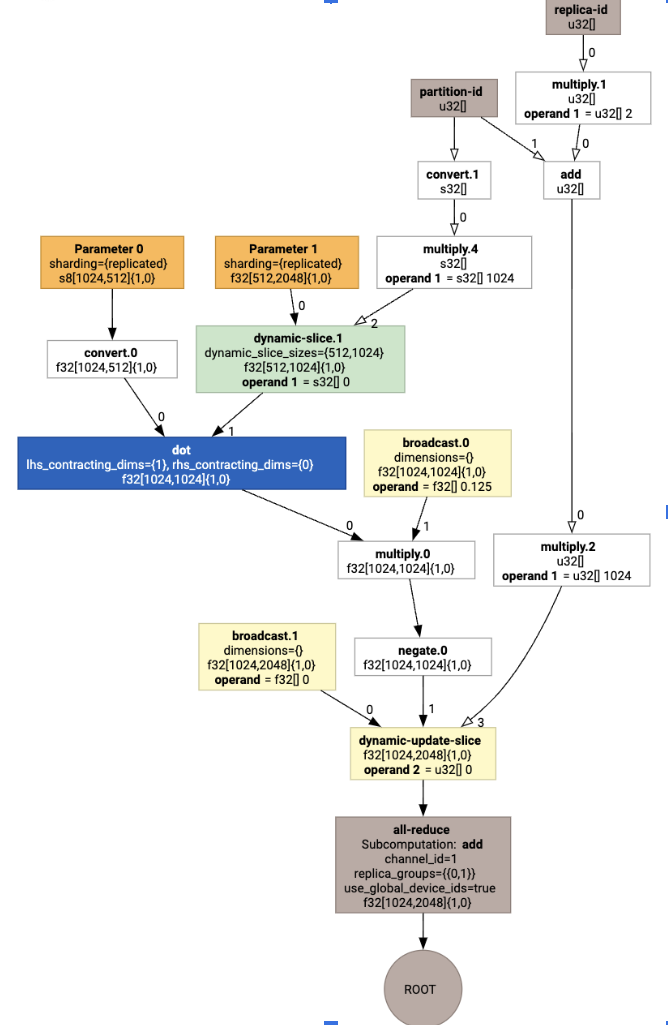
Asignación de diseño
El HLO desacopla la forma lógica y el diseño físico (cómo se disponen los tensores en la memoria). Por ejemplo, una matriz f32[32, 64] se puede representar en orden de fila principal o columna principal, como {1,0} o {0,1}, respectivamente.
En general, el diseño se representa como parte de la forma, lo que muestra una permutación sobre la cantidad de dimensiones que indican el diseño físico en la memoria.
Para cada operación presente en el HLO, el pase de Layout Assignment elige un diseño óptimo (p.ej., NHWC para una convolución en Ampere). Por ejemplo, una operación int8xint8->int32 matmul prefiere el diseño {0,1} para el lado derecho del cálculo. Del mismo modo, se ignoran las “transposiciones” insertadas por el usuario y se codifican como un cambio de diseño.
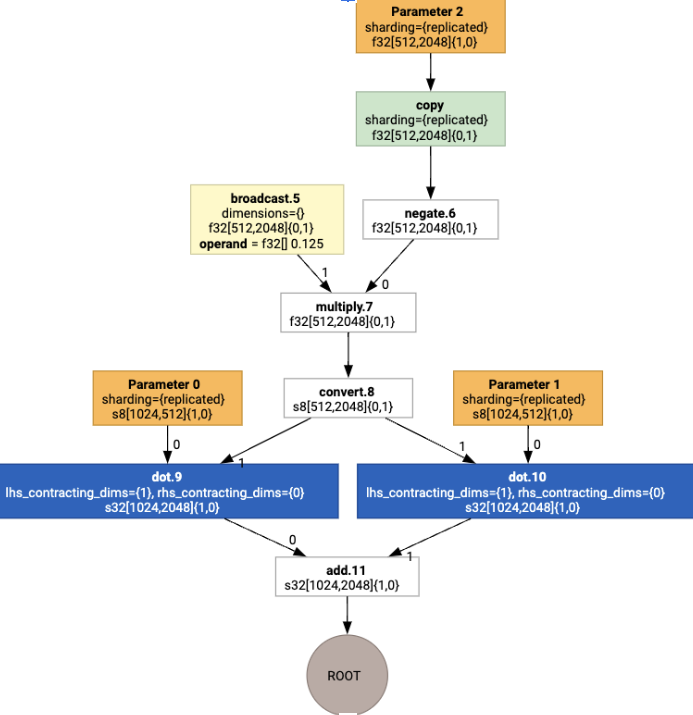
Luego, los diseños se propagan a través del grafo, y los conflictos entre diseños o en los extremos del grafo se materializan como operaciones copy, que realizan la transposición física. Por ejemplo, comenzando desde el gráfico
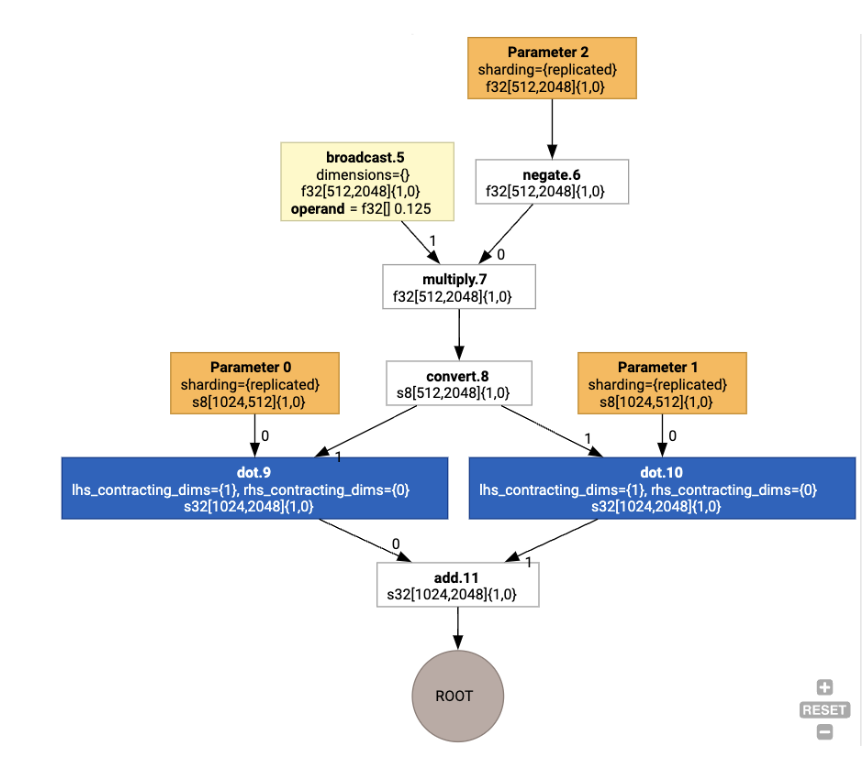
Si ejecutamos la asignación de diseño, veremos los siguientes diseños y la operación copy insertada:
Fusión
La fusión es la optimización más importante de XLA, que agrupa varias operaciones (p.ej., suma en exponenciación en matmul) en un solo kernel. Dado que muchas cargas de trabajo de GPU tienden a estar limitadas por la memoria, la fusión acelera drásticamente la ejecución, ya que evita la escritura de tensores intermedios en la HBM y, luego, su lectura, y, en cambio, los pasa a través de registros o memoria compartida.
Las instrucciones de HLO fusionadas se bloquean juntas en un solo cálculo de fusión, lo que establece las siguientes invariantes:
No se materializa ningún almacenamiento intermedio dentro de la fusión en HBM (todo debe pasar por registros o memoria compartida).
Una fusión siempre se compila en exactamente un kernel de GPU.
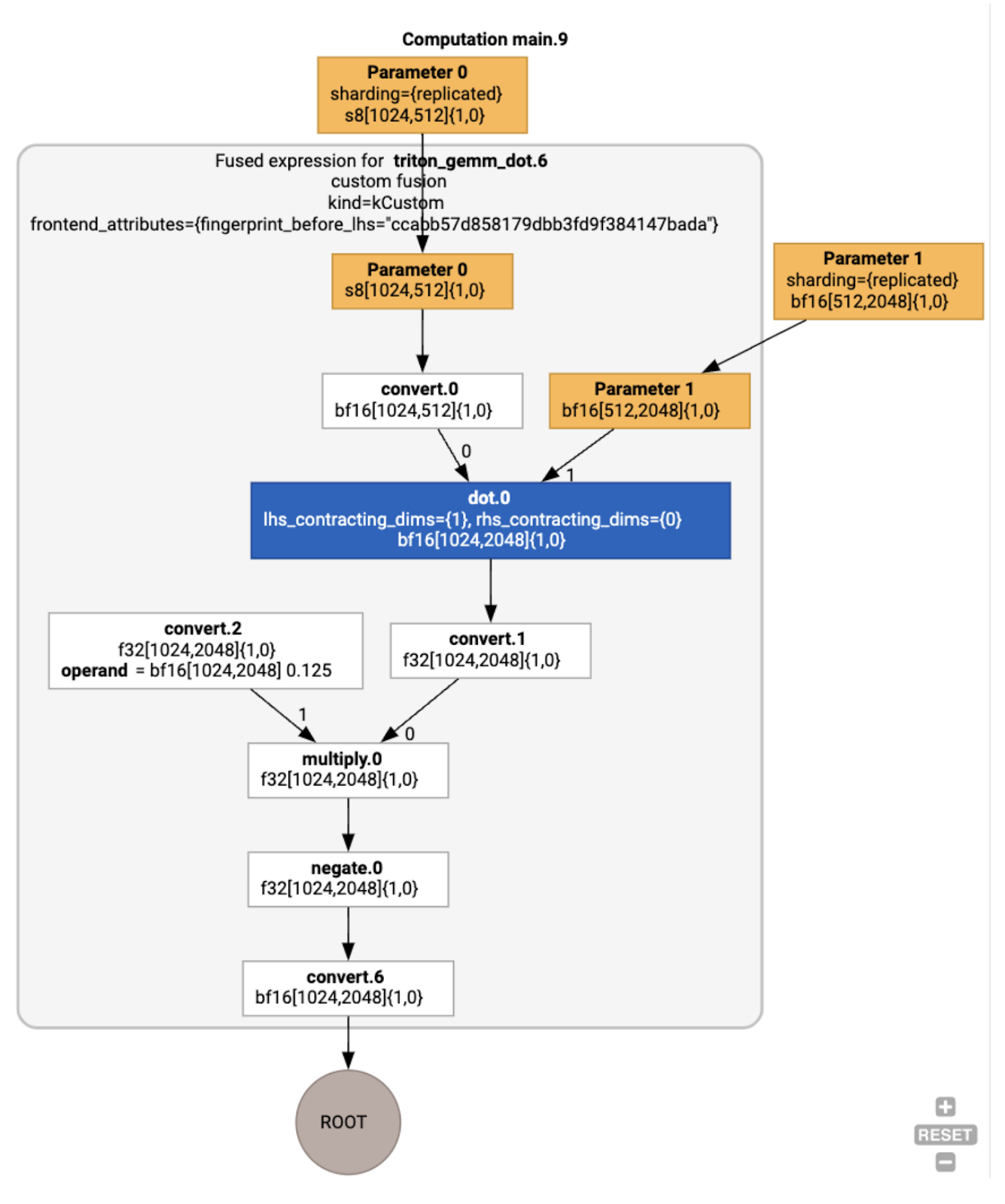
Optimizaciones de HLO en el ejemplo en ejecución
Podemos inspeccionar el HLO posterior a la optimización con jax.jit(f).lower(a,
b).compile().as_text() y verificar que se generó una sola fusión:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
Ten en cuenta que la fusión backend_config nos indica que Triton se usará como estrategia de generación de código y especifica la división en mosaicos elegida.
También podemos visualizar el módulo resultante:
Asignación y programación de búferes
Un paso de asignación de búferes tiene en cuenta la información de la forma y busca producir una asignación de búferes óptima para el programa, lo que minimiza la cantidad de memoria intermedia consumida. A diferencia de la ejecución en modo inmediato (sin compilar) de TF o PyTorch, en la que el asignador de memoria no conoce el gráfico de antemano, el programador de XLA puede "predecir el futuro" y producir un programa de cálculo óptimo.
Backend del compilador: Selección de codegen y bibliotecas
Para cada instrucción HLO en el cálculo, XLA elige si ejecutarla con una biblioteca vinculada a un tiempo de ejecución o si generarla como código PTX.
Selección de la biblioteca
Para muchas operaciones comunes, XLA:GPU usa bibliotecas de alto rendimiento de NVIDIA, como cuBLAS, cuDNN y NCCL. Las bibliotecas tienen la ventaja de un rendimiento rápido verificado, pero a menudo impiden oportunidades de fusión complejas.
Generación de código directa
El backend de XLA:GPU genera un IR de LLVM de alto rendimiento directamente para varias operaciones (reducciones, transposiciones, etcétera).
Generación de código de Triton
Para las fusiones más avanzadas que incluyen la multiplicación de matrices o softmax, XLA:GPU usa Triton como capa de generación de código. Las fusiones de HLO se convierten en TritonIR (un dialecto de MLIR que sirve como entrada para Triton), se seleccionan los parámetros de segmentación y se invoca a Triton para la generación de PTX:
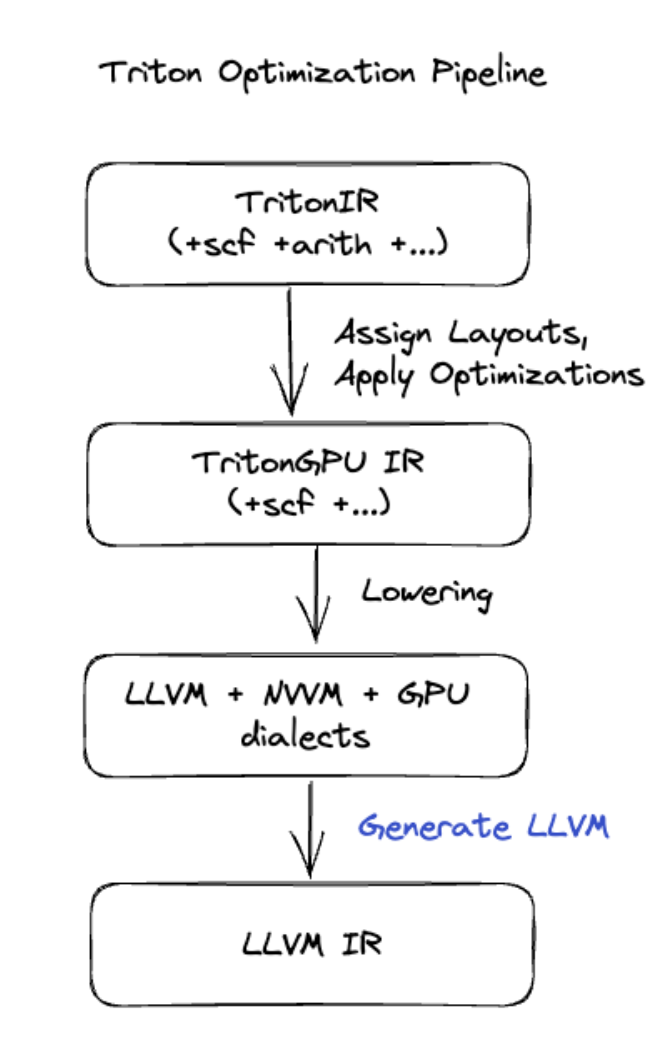
Observamos que el código resultante funciona muy bien en Ampere, con un rendimiento casi óptimo con tamaños de mosaico ajustados correctamente.
Entorno de ejecución
El tiempo de ejecución de XLA convierte la secuencia resultante de llamadas al kernel de CUDA y las invocaciones de la biblioteca en un RuntimeIR (un dialecto de MLIR en XLA), en el que se realiza la extracción del gráfico de CUDA. El gráfico de CUDA aún está en desarrollo y, actualmente, solo se admiten algunos nodos. Una vez que se extraen los límites del grafo de CUDA, RuntimeIR se compila a través de LLVM en un ejecutable de CPU, que luego se puede almacenar o transferir para la compilación Ahead-Of-Time.