
مقدمه
XLA یک کامپایلر سخت افزاری و فریم ورک مخصوص حوزه جبر خطی است که بهترین عملکرد را در کلاس خود ارائه می دهد. JAX، TF، Pytorch و دیگران از XLA با تبدیل ورودی کاربر به StableHLO ("عملیات سطح بالا": مجموعهای از 100 دستورالعمل استاتیکی مانند جمع، تفریق، matmul و غیره) استفاده میکنند که از آن XLA کد بهینهسازی شده را برای انواع پشتیبانها تولید میکند:
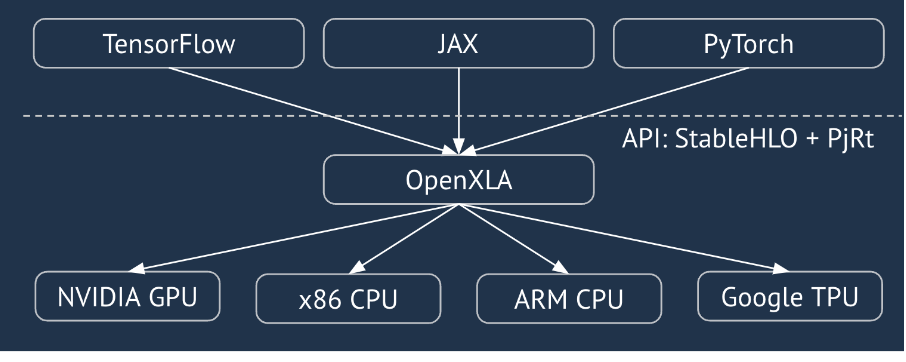
در طول اجرا، فریمورکها API زمان اجرا PJRT را فراخوانی میکنند، که به فریمورکها اجازه میدهد عملیات «پر کردن بافرهای مشخص شده با استفاده از یک برنامه StableHLO معین در یک دستگاه خاص» را انجام دهند.
XLA: خط لوله GPU
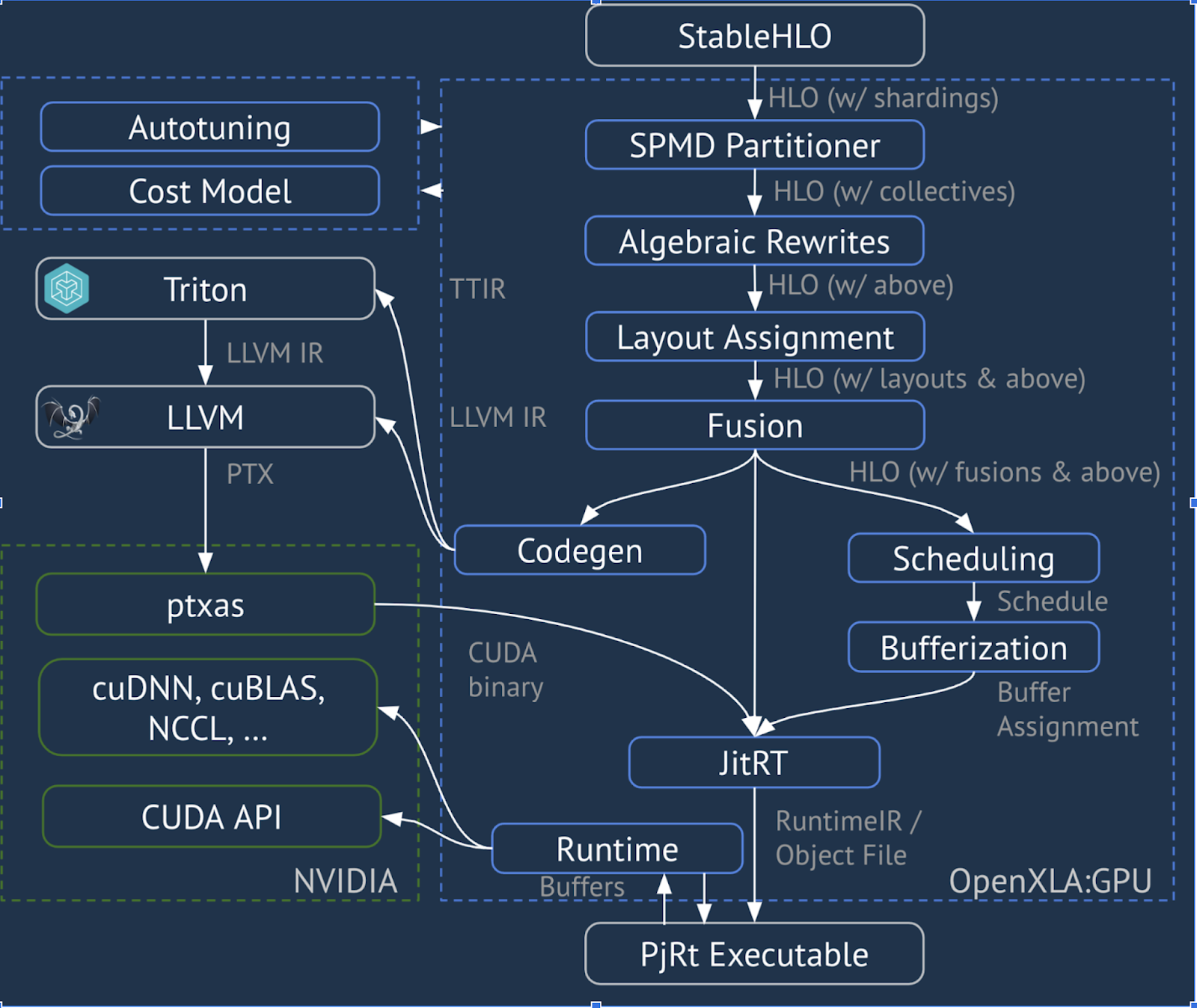
XLA:GPU از ترکیبی از امیترهای «بومی» (PTX، از طریق LLVM) و فرستندههای TritonIR برای تولید هستههای GPU با کارایی بالا استفاده میکند (رنگ آبی نشاندهنده مؤلفههای 3P است):
مثال در حال اجرا: JAX
برای نشان دادن خط لوله، اجازه دهید با یک مثال در حال اجرا در JAX شروع کنیم، که یک matmul ترکیب شده با ضرب در یک ثابت و نفی را محاسبه می کند:
def f(a, b):
return -((a @ b) * 0.125)
ما می توانیم HLO تولید شده توسط تابع را بررسی کنیم:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
که تولید می کند:
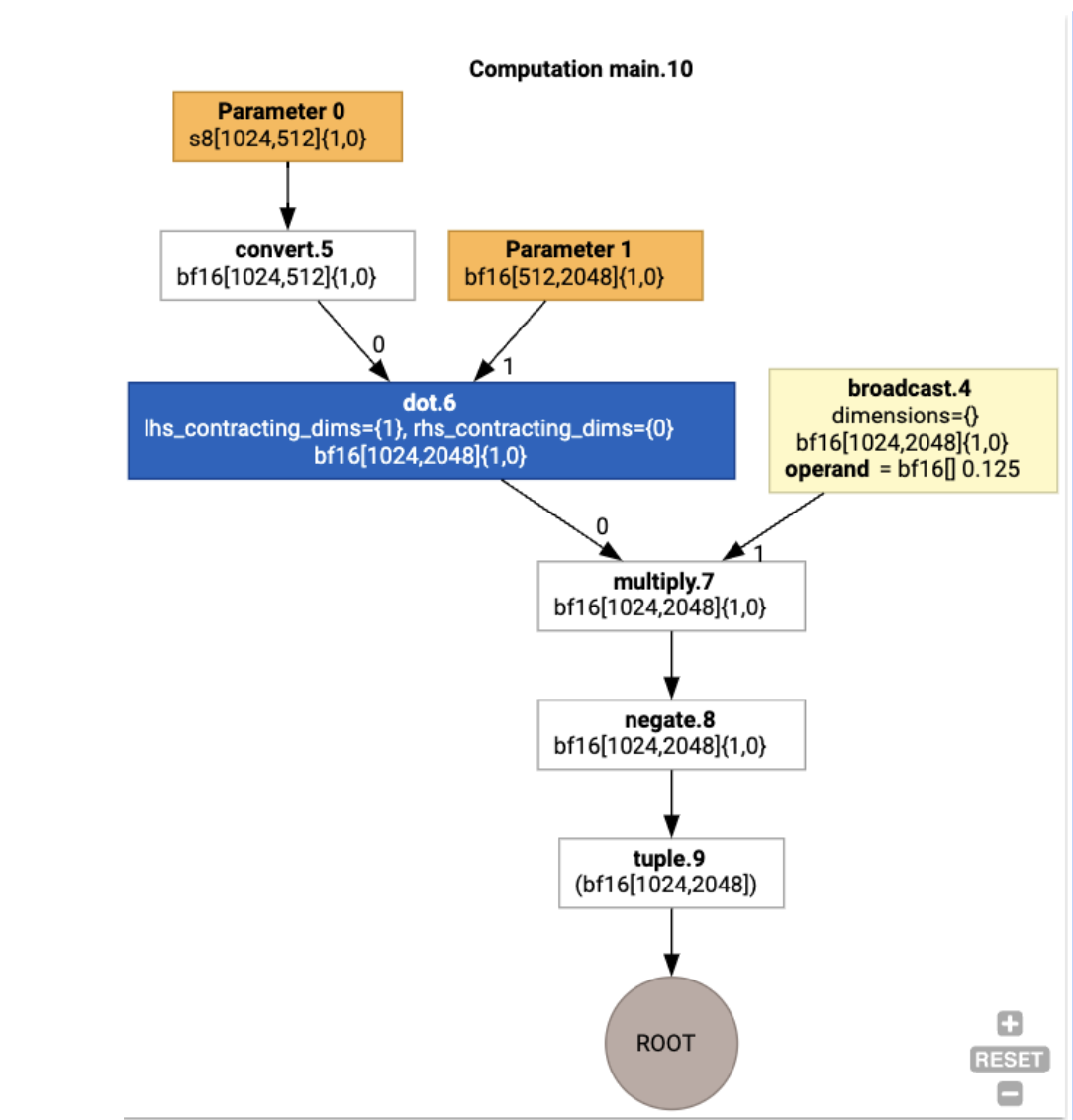
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
با استفاده از jax.xla_computation(f)(a, b).as_hlo_dot_graph() میتوانیم محاسبات HLO ورودی را نیز تجسم کنیم:
بهینه سازی در HLO: اجزای کلیدی
تعدادی از پاس های بهینه سازی قابل توجه در HLO اتفاق می افتد، همانطور که HLO->HLO بازنویسی می کند.
پارتیشن SPMD
پارتیشنکننده XLA SPMD، همانطور که در GSPMD: موازیسازی عمومی و مقیاسپذیر برای نمودارهای MLComputation توضیح داده شده است، HLO را با حاشیهنویسی به اشتراکگذاری (مثلاً توسط jax.pjit تولید میکند) مصرف میکند و یک HLO خرد شده تولید میکند که سپس میتواند روی تعدادی میزبان و دستگاه اجرا شود. جدا از پارتیشن بندی، SPMD تلاش می کند تا HLO را برای یک برنامه اجرای بهینه، محاسبات همپوشانی و ارتباط بین گره ها بهینه کند.
مثال
شروع را از یک برنامه ساده JAX در دو دستگاه در نظر بگیرید:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
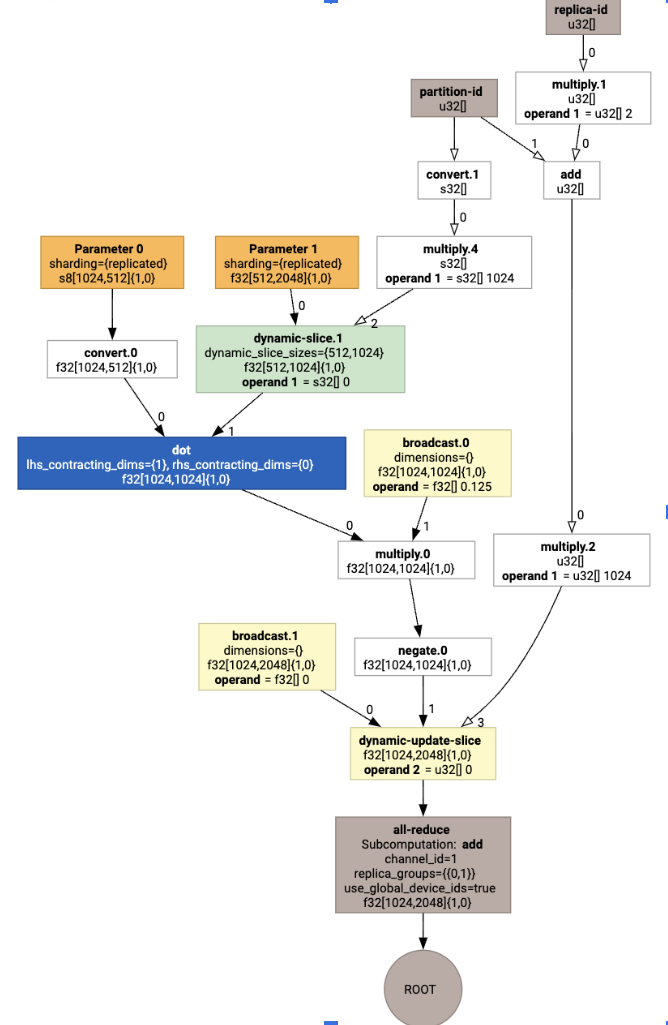
با تجسم آن، حاشیه نویسی های اشتراک گذاری به عنوان فراخوان های سفارشی ارائه می شوند:
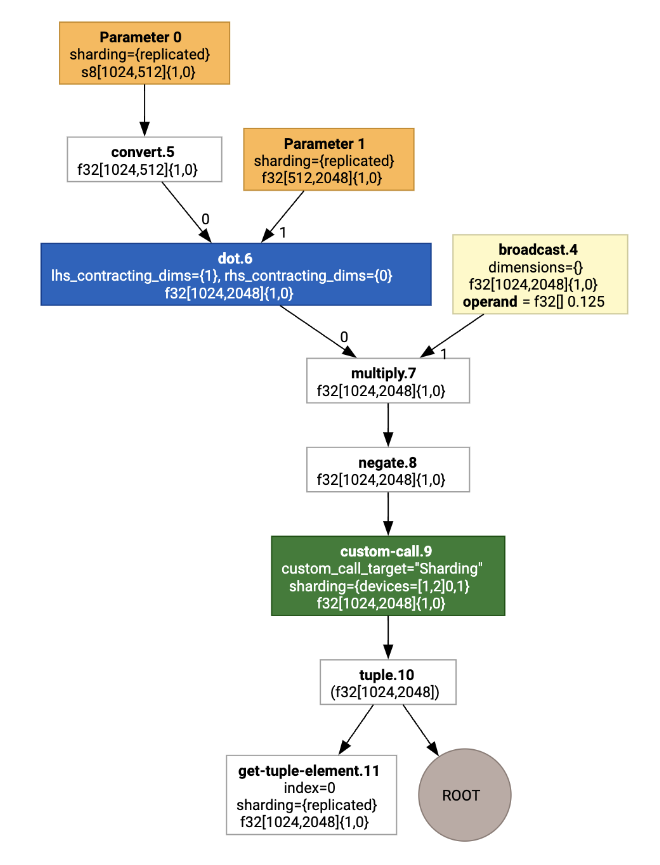
برای بررسی نحوه گسترش تماس سفارشی توسط پارتیشنکننده SPMD، میتوانیم بعد از بهینهسازی به HLO نگاه کنیم:
print(f.lower(np.ones((8, 8)).compile().as_text())
که HLO را با یک جمع تولید می کند:
تخصیص چیدمان
HLO شکل منطقی و طرح فیزیکی (نحوه قرارگیری تانسورها در حافظه) را جدا می کند. به عنوان مثال، یک ماتریس f32[32, 64] می توان به ترتیب به ترتیب ردیف اصلی یا ستون اصلی، به ترتیب به صورت {1,0} یا {0,1} نشان داد. به طور کلی، طرح به عنوان بخشی از شکل نشان داده می شود، که یک جایگشت بر تعداد ابعاد نشان می دهد که نشان دهنده چیدمان فیزیکی در حافظه است.
برای هر عملیات موجود در HLO، Layout Assignment pass یک طرح بندی بهینه را انتخاب می کند (مثلاً NHWC برای کانولوشن روی آمپر). برای مثال، یک عملیات matmul int8xint8->int32 طرحبندی {0,1} را برای RHS محاسبات ترجیح میدهد. به طور مشابه، "transposes" درج شده توسط کاربر نادیده گرفته می شود، و به عنوان یک تغییر طرح کدگذاری می شود.
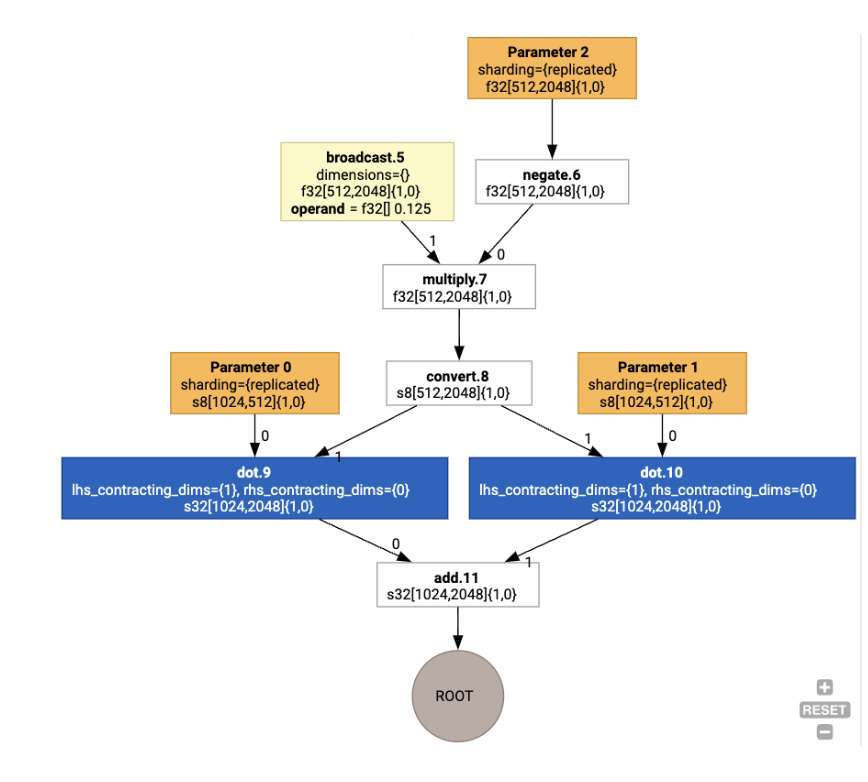
سپس طرحبندیها از طریق نمودار منتشر میشوند و تضاد بین طرحبندیها یا در نقاط پایانی نمودار به عنوان عملیات copy ، که جابجایی فیزیکی را انجام میدهند، تحقق مییابد. به عنوان مثال، از نمودار شروع کنید
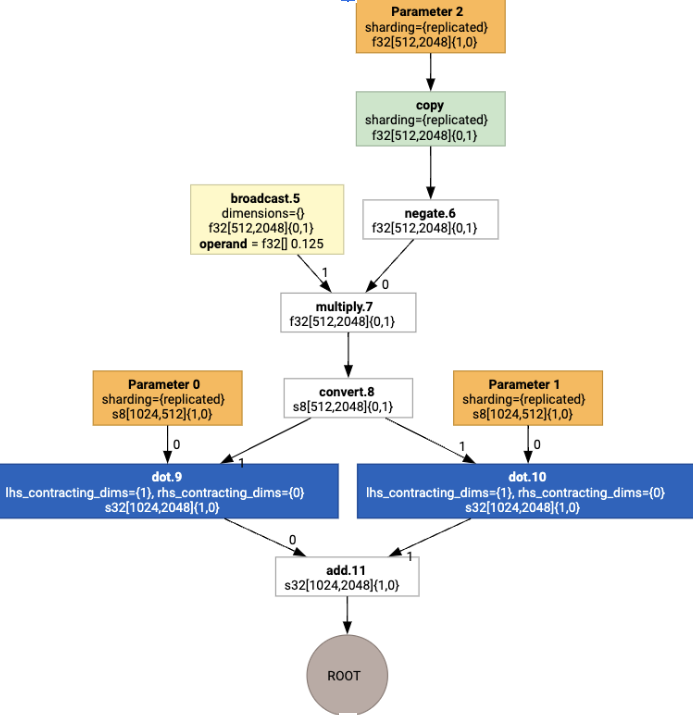
با اجرای تخصیص layout، می بینیم که طرح بندی ها و عملیات copy زیر درج شده است:
فیوژن
Fusion تنها مهم ترین بهینه سازی XLA است که چندین عملیات (مثلاً اضافه کردن به توان به matmul) را به یک هسته واحد گروه بندی می کند. از آنجایی که بسیاری از بارهای کاری GPU معمولاً به حافظه محدود می شوند، fusion با اجتناب از نوشتن تانسورهای میانی در HBM و سپس بازخوانی آنها، سرعت اجرا را به طور چشمگیری افزایش می دهد و در عوض آنها را در ثبات ها یا حافظه مشترک ارسال می کند.
دستورالعمل های HLO ذوب شده در یک محاسبات فیوژن با هم مسدود می شوند، که ثابت های زیر را ایجاد می کند:
هیچ ذخیرهسازی واسطهای در داخل همجوشی در HBM انجام نمیشود (همگی باید از طریق رجیسترها یا حافظه مشترک منتقل شوند).
یک تلفیقی همیشه دقیقاً به یک هسته GPU کامپایل می شود
بهینه سازی HLO در مثال در حال اجرا
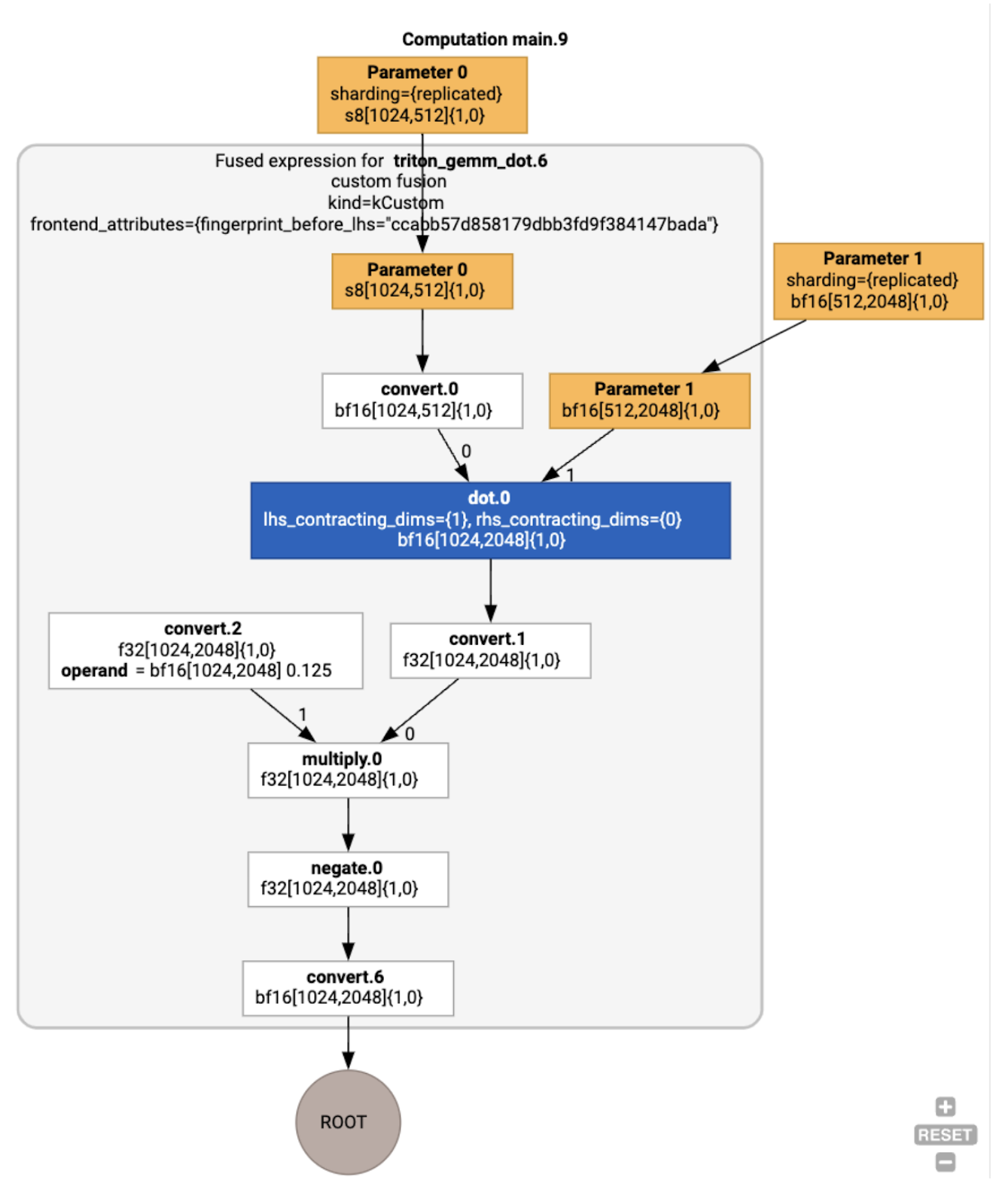
ما میتوانیم HLO پس از بهینهسازی را با استفاده از jax.jit(f).lower(a, b).compile().as_text() بررسی کنیم و بررسی کنیم که یک ترکیب واحد ایجاد شده است:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
توجه داشته باشید که fusion backend_config به ما می گوید که Triton به عنوان استراتژی تولید کد استفاده خواهد شد و کاشی کاری انتخابی را مشخص می کند.
ما همچنین می توانیم ماژول حاصل را تجسم کنیم:
تخصیص بافر و زمان بندی
یک پاس انتساب بافر اطلاعات شکل را در نظر می گیرد و هدف آن ایجاد یک تخصیص بهینه بافر برای برنامه است و مقدار حافظه میانی مصرف شده را به حداقل می رساند. برخلاف اجرای حالت فوری TF یا PyTorch (غیر کامپایلشده)، که در آن تخصیصدهنده حافظه از قبل نمودار را نمیداند، زمانبند XLA میتواند «به آینده نگاه کند» و یک برنامه محاسباتی بهینه تولید کند.
Backend کامپایلر: Codegen و انتخاب کتابخانه
برای هر دستور HLO در محاسبات، XLA انتخاب میکند که آیا آن را با استفاده از یک کتابخانه متصل به زمان اجرا اجرا کند یا آن را به PTX کدگن کند.
انتخاب کتابخانه
برای بسیاری از عملیات رایج، XLA:GPU از کتابخانههایی با عملکرد سریع NVIDIA مانند cuBLAS، cuDNN و NCCL استفاده میکند. کتابخانه ها از مزیت عملکرد سریع تأیید شده برخوردارند، اما اغلب فرصت های ترکیبی پیچیده را از بین می برند.
تولید کد مستقیم
باطن XLA:GPU مستقیماً برای تعدادی از عملیات (کاهش، جابجایی و غیره) LLVM IR با کارایی بالا تولید می کند.
تولید کد تریتون
برای ترکیبهای پیشرفتهتر که شامل ضرب ماتریس یا softmax میشود، XLA:GPU از Triton به عنوان لایه تولید کد استفاده میکند. HLO Fusions به TritonIR (یک گویش MLIR که به عنوان ورودی Triton عمل میکند) تبدیل میشود، پارامترهای کاشی کاری را انتخاب میکند و Triton را برای تولید PTX فراخوانی میکند:
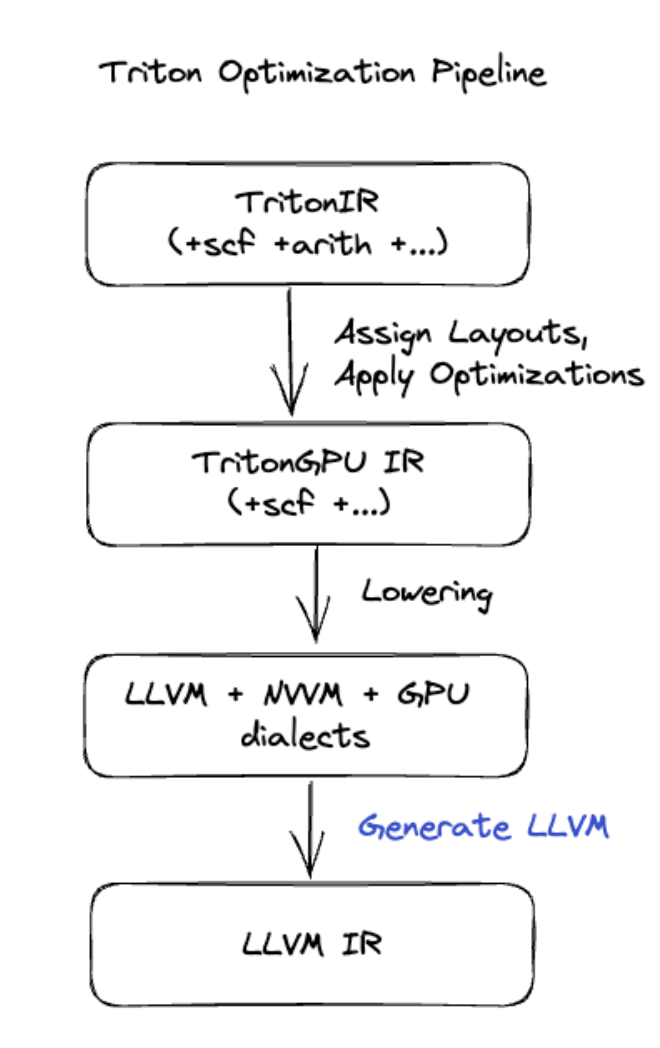
ما کد به دست آمده را مشاهده کردهایم که در Ampere، در عملکرد نزدیک به پشت بام با اندازههای کاشی بهدرستی تنظیم شده، عملکرد بسیار خوبی دارد.
زمان اجرا
XLA Runtime توالی حاصل از فراخوانیهای هسته CUDA و فراخوانیهای کتابخانه را به RuntimeIR (یک گویش MLIR در XLA) تبدیل میکند که استخراج نمودار CUDA روی آن انجام میشود. نمودار CUDA هنوز در حال انجام است، فقط برخی از گره ها در حال حاضر پشتیبانی می شوند. هنگامی که مرزهای نمودار CUDA استخراج شد، RuntimeIR از طریق LLVM به یک CPU اجرایی کامپایل میشود، که میتواند برای کامپایل Ahead-Of-Time ذخیره یا منتقل شود.