
Introduction
XLA est un compilateur d'algèbre linéaire spécifique au domaine du matériel et des frameworks, qui offre des performances de pointe. JAX, TF, PyTorch et d'autres utilisent XLA en convertissant l'entrée utilisateur en ensemble d'opérations StableHLO ("opération de haut niveau" : un ensemble d'environ 100 instructions de forme statique telles que l'addition, la soustraction, matmul, etc.), à partir duquel XLA produit du code optimisé pour différents backends :
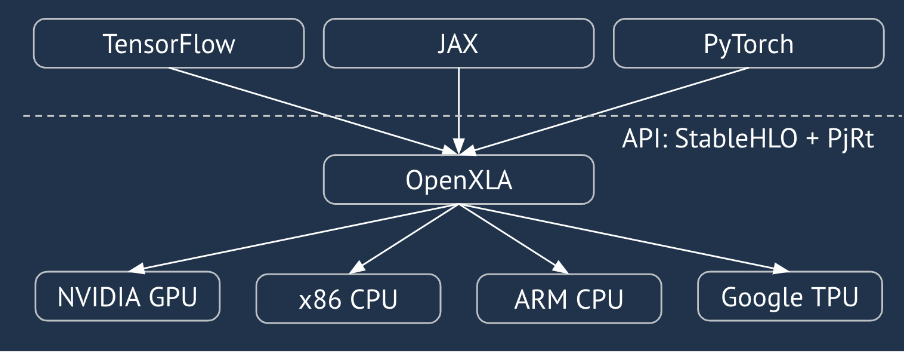
Lors de l'exécution, les frameworks appellent l'API PJRT runtime, qui leur permet d'effectuer l'opération "remplir les tampons spécifiés à l'aide d'un programme StableHLO donné sur un appareil spécifique".
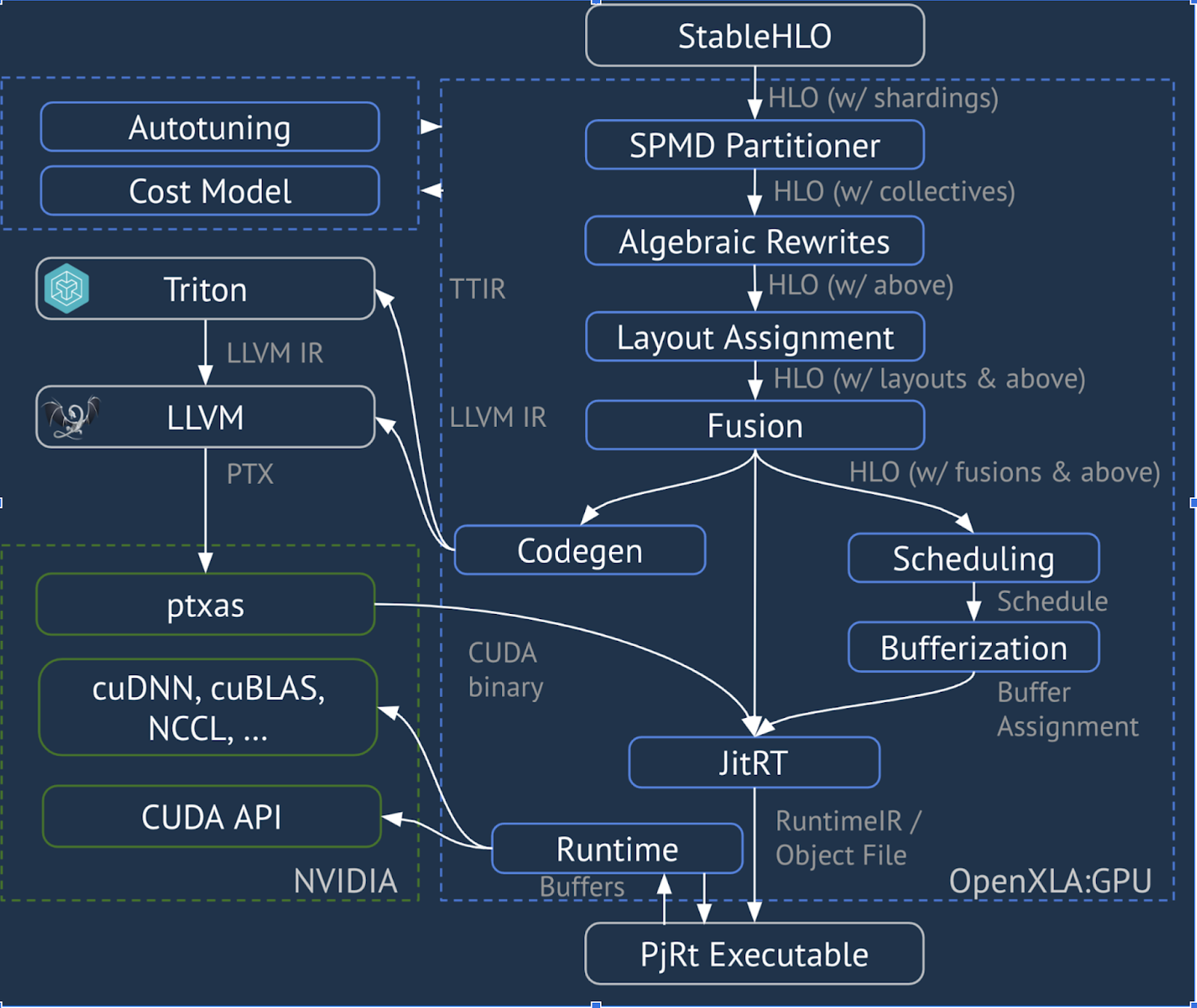
Pipeline XLA:GPU
XLA:GPU utilise une combinaison d'émetteurs "natifs" (PTX, via LLVM) et d'émetteurs TritonIR pour générer des noyaux GPU hautes performances (la couleur bleue indique les composants tiers) :
Exécution de l'exemple : JAX
Pour illustrer le pipeline, commençons par un exemple d'exécution dans JAX, qui calcule un matmul combiné à une multiplication par une constante et à une négation :
def f(a, b):
return -((a @ b) * 0.125)
Nous pouvons inspecter le HLO généré par la fonction :
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
qui génère :
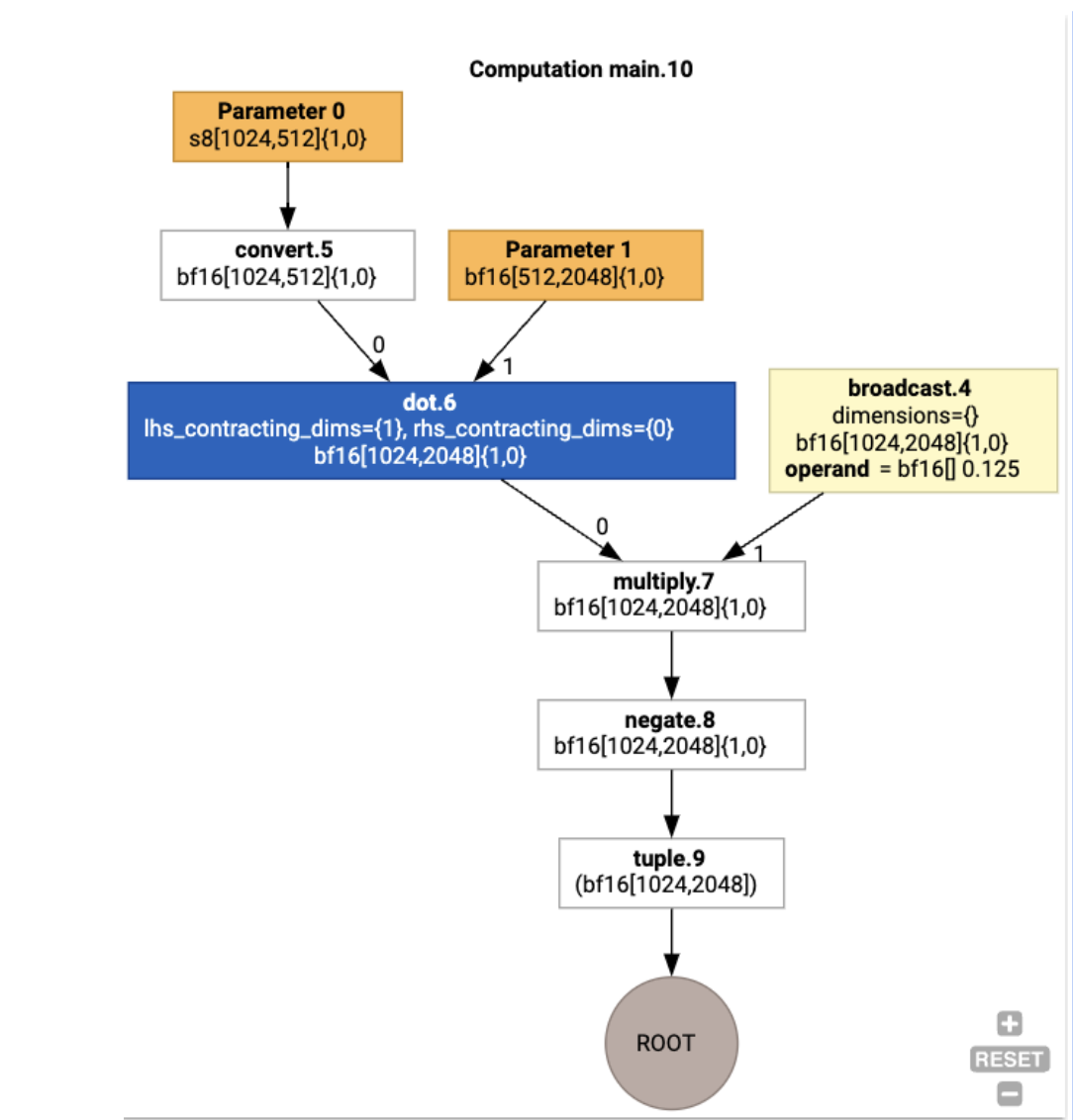
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
Nous pouvons également visualiser le calcul HLO d'entrée à l'aide de jax.xla_computation(f)(a, b).as_hlo_dot_graph() :
Optimisations sur HLO : composants clés
Un certain nombre de passes d'optimisation notables se produisent sur HLO, en tant que réécritures HLO->HLO.
Partitionneur SPMD
Le partitionneur SPMD XLA, tel que décrit dans GSPMD : General and Scalable Parallelization for MLComputation Graphs, consomme HLO avec des annotations de sharding (produites, par exemple, par jax.pjit) et produit un HLO fragmenté qui peut ensuite s'exécuter sur un certain nombre d'hôtes et d'appareils.
En plus du partitionnement, SPMD tente d'optimiser HLO pour un calendrier d'exécution optimal, un calcul chevauchant et une communication entre les nœuds.
Exemple
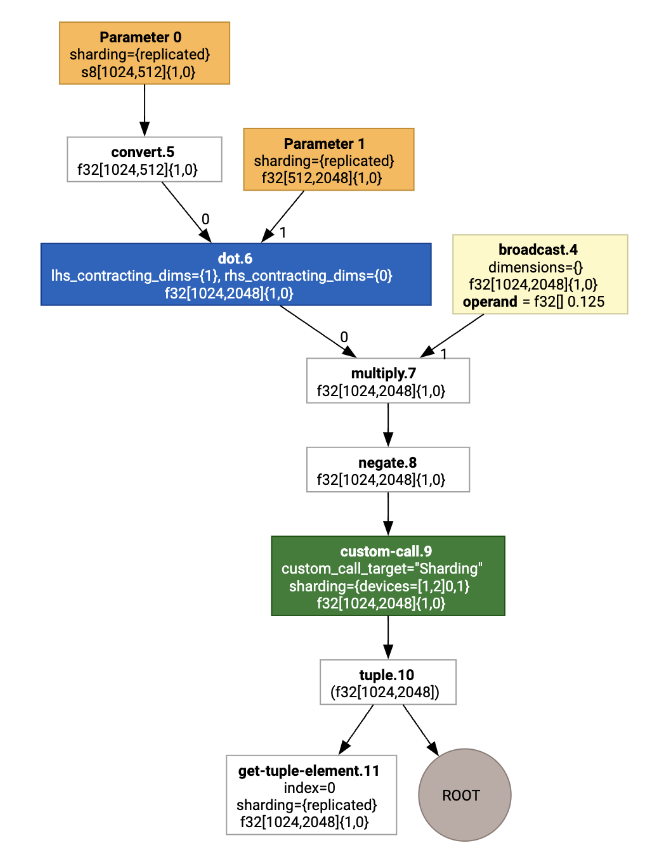
Prenons l'exemple d'un programme JAX simple partitionné sur deux appareils :
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
En le visualisant, les annotations de sharding se présentent sous forme d'appels personnalisés :
Pour vérifier comment le partitionneur SPMD développe l'appel personnalisé, nous pouvons examiner le HLO après les optimisations :
print(f.lower(np.ones((8, 8)).compile().as_text())
qui génère un HLO avec un collectif :
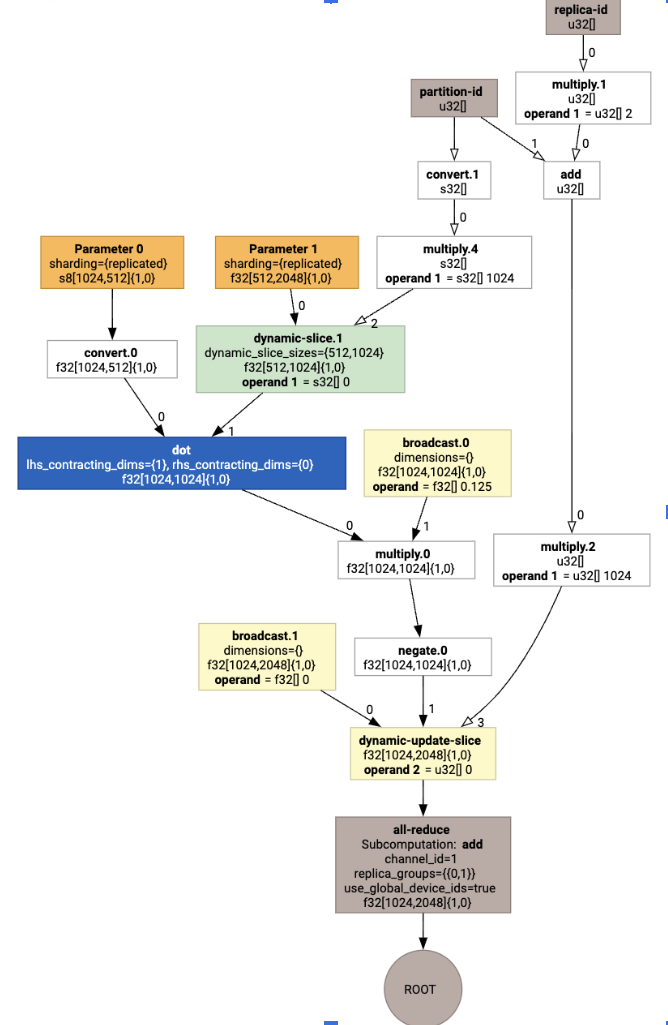
Attribution de la mise en page
HLO découple la forme logique et la disposition physique (la façon dont les Tensors sont disposés dans la mémoire). Par exemple, une matrice f32[32, 64] peut être représentée dans l'ordre des lignes ou des colonnes, respectivement {1,0} ou {0,1}.
En général, la mise en page est représentée par une partie de la forme, qui montre une permutation sur le nombre de dimensions indiquant la mise en page physique en mémoire.
Pour chaque opération présente dans le HLO, le pass d'attribution de mise en page choisit une mise en page optimale (par exemple, NHWC pour une convolution sur Ampere). Par exemple, une opération matmul int8xint8->int32 préfère la mise en page {0,1} pour le côté droit du calcul. De même, les transpositions insérées par l'utilisateur sont ignorées et encodées comme un changement de mise en page.
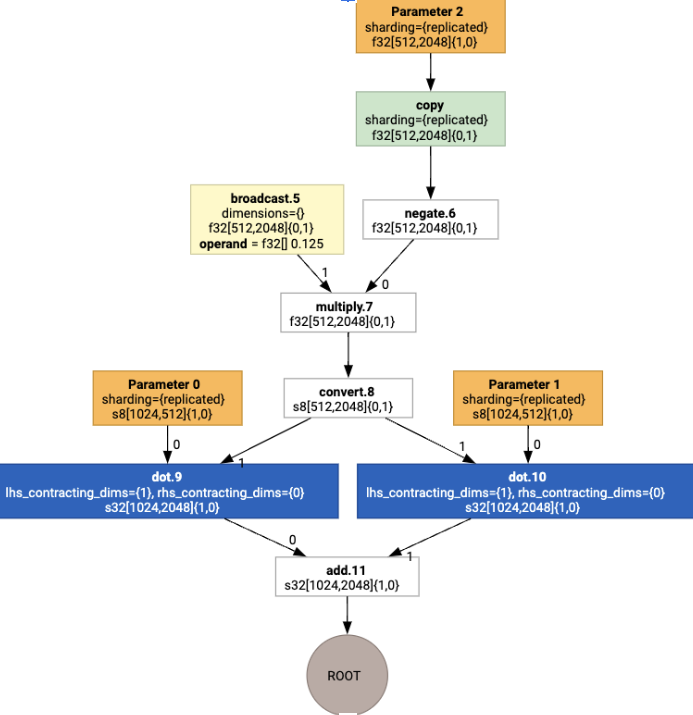
Les mises en page sont ensuite propagées dans le graphique, et les conflits entre les mises en page ou aux points de terminaison du graphique sont matérialisés sous forme d'opérations copy, qui effectuent la transposition physique. Par exemple, à partir du graphique
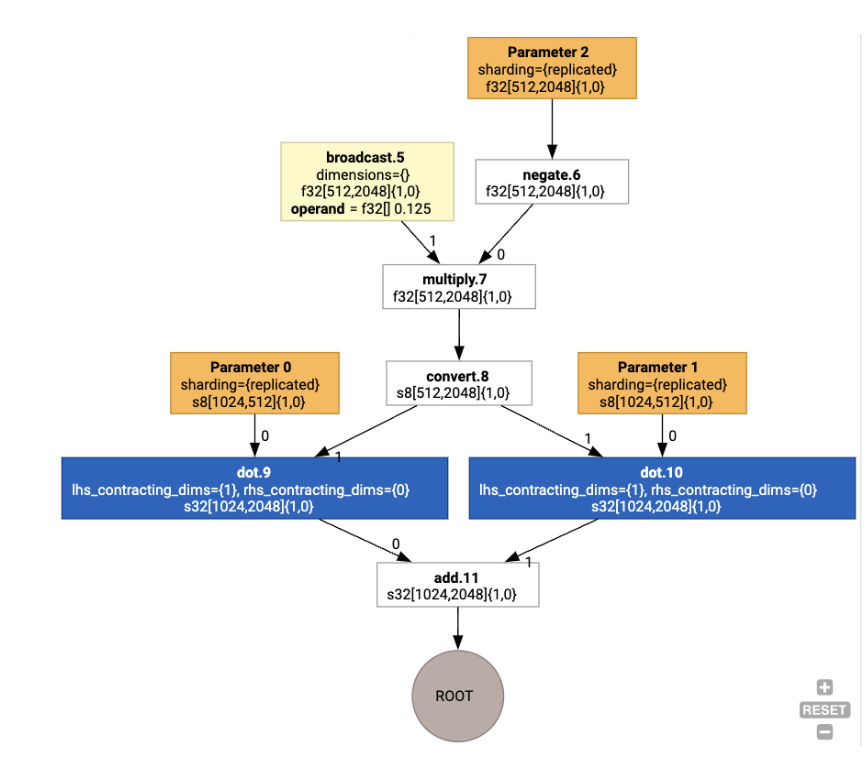
En exécutant l'attribution de mise en page, nous voyons les mises en page suivantes et l'opération copy insérée :
Fusion
La fusion est l'optimisation la plus importante de XLA. Elle regroupe plusieurs opérations (par exemple, l'addition dans l'exponentiation dans matmul) dans un seul noyau. Étant donné que de nombreuses charges de travail GPU ont tendance à être liées à la mémoire, la fusion accélère considérablement l'exécution en évitant l'écriture de Tensors intermédiaires dans HBM, puis leur lecture, et en les transmettant plutôt dans des registres ou une mémoire partagée.
Les instructions HLO fusionnées sont bloquées ensemble dans un seul calcul de fusion, ce qui établit les invariants suivants :
Aucun stockage intermédiaire à l'intérieur de la fusion n'est matérialisé dans HBM (tout doit être transmis par le biais de registres ou de mémoire partagée).
Une fusion est toujours compilée en un seul noyau de GPU.
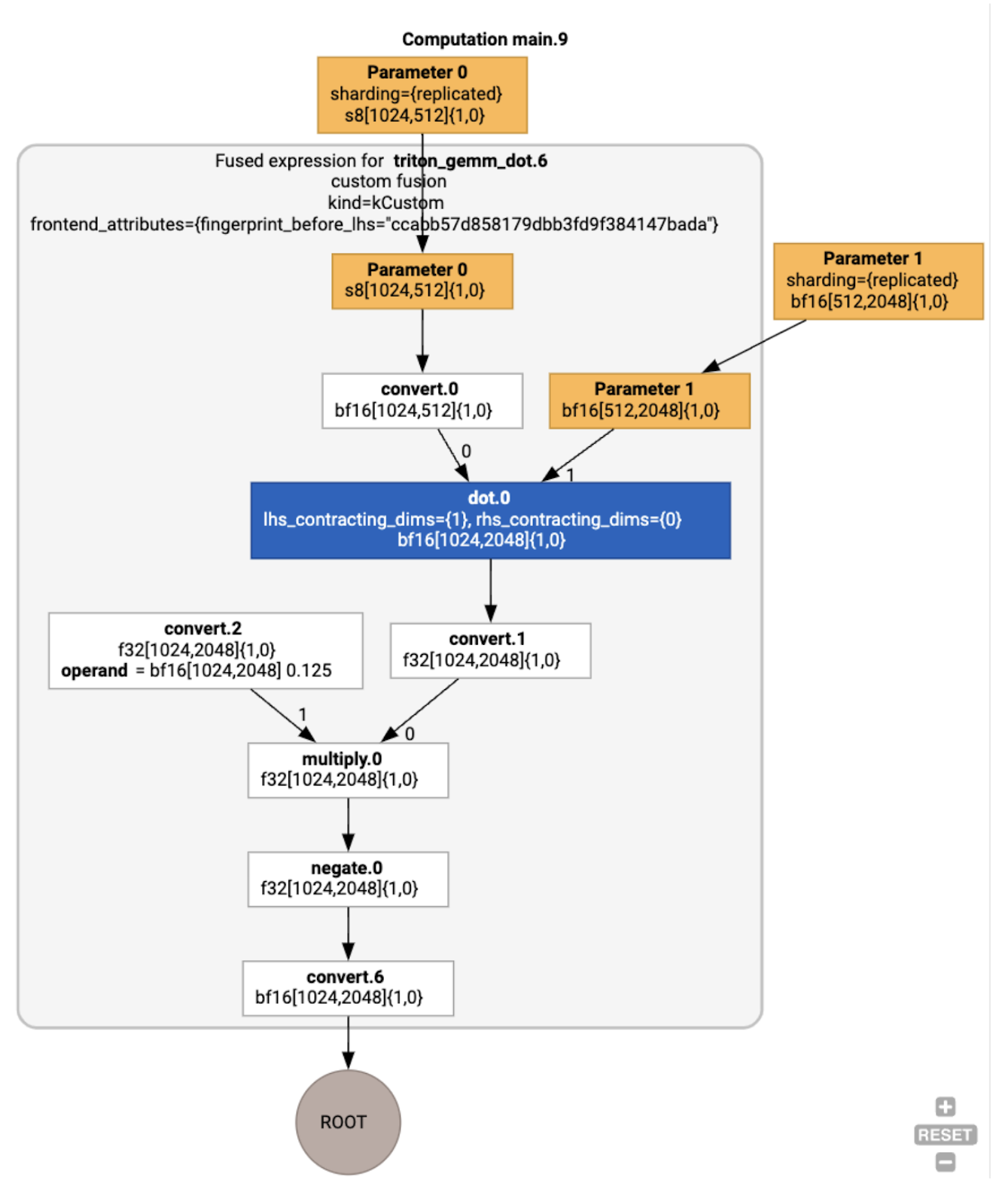
Optimisations HLO sur l'exemple d'exécution
Nous pouvons inspecter le HLO post-optimisation à l'aide de jax.jit(f).lower(a,
b).compile().as_text() et vérifier qu'une seule fusion a été générée :
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
Notez que la fusion backend_config nous indique que Triton sera utilisé comme stratégie de génération de code et spécifie le tiling choisi.
Nous pouvons également visualiser le module obtenu :
Attribution et planification des tampons
Une passe d'attribution de tampon prend en compte les informations de forme et vise à produire une allocation de tampon optimale pour le programme, en minimisant la quantité de mémoire intermédiaire consommée. Contrairement à l'exécution en mode immédiat (non compilé) de TF ou PyTorch, où l'allocateur de mémoire ne connaît pas le graphique à l'avance, le planificateur XLA peut "regarder dans l'avenir" et produire un calendrier de calcul optimal.
Backend du compilateur : sélection de bibliothèque et génération de code
Pour chaque instruction HLO du calcul, XLA choisit de l'exécuter à l'aide d'une bibliothèque associée à un environnement d'exécution ou de la générer en code PTX.
Sélection de la bibliothèque
Pour de nombreuses opérations courantes, XLA:GPU utilise des bibliothèques hautes performances de NVIDIA, telles que cuBLAS, cuDNN et NCCL. Les bibliothèques offrent l'avantage de performances rapides et vérifiées, mais excluent souvent les opportunités de fusion complexes.
Génération directe de code
Le backend XLA:GPU génère des IR LLVM hautes performances directement pour un certain nombre d'opérations (réductions, transpositions, etc.).
Génération de code Triton
Pour les fusions plus avancées qui incluent la multiplication matricielle ou softmax, XLA:GPU utilise Triton comme couche de génération de code. Les fusions HLO sont converties en TritonIR (un dialecte MLIR qui sert d'entrée à Triton), sélectionnent les paramètres de tiling et appellent Triton pour la génération PTX :
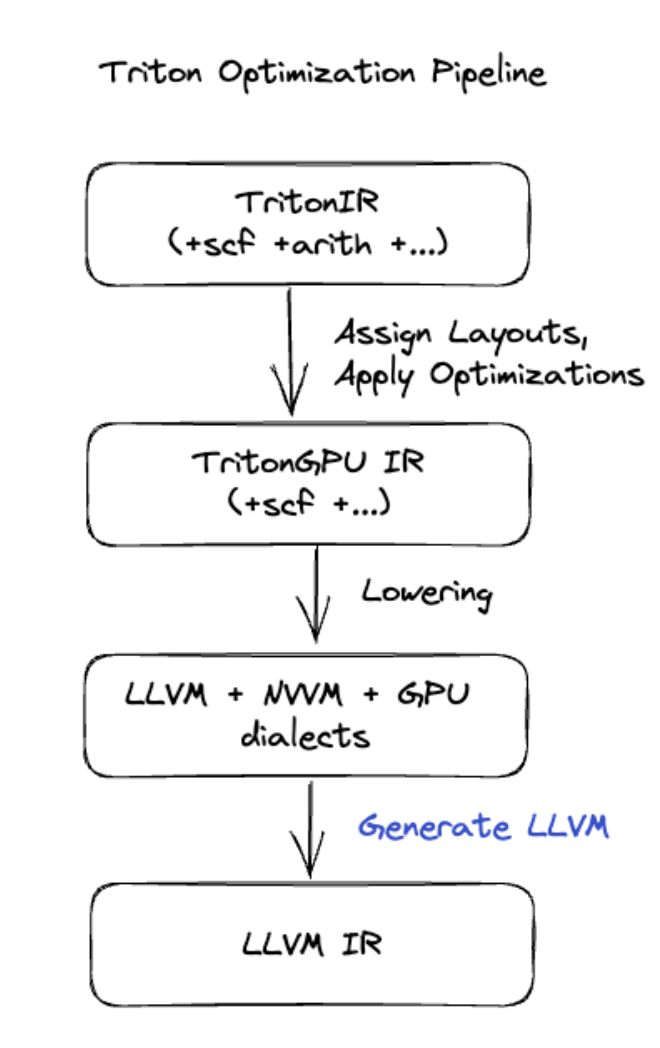
Nous avons observé que le code obtenu fonctionnait très bien sur Ampere, avec des performances proches de la limite théorique avec des tailles de blocs correctement ajustées.
Environnement d'exécution
Le runtime XLA convertit la séquence résultante d'appels de noyau CUDA et d'invocations de bibliothèque en RuntimeIR (un dialecte MLIR dans XLA), sur lequel l'extraction du graphique CUDA est effectuée. Le graphique CUDA est toujours en cours de développement. Seuls certains nœuds sont actuellement compatibles. Une fois les limites du graphique CUDA extraites, RuntimeIR est compilé via LLVM en un exécutable CPU, qui peut ensuite être stocké ou transféré pour la compilation Ahead-Of-Time.