
מבוא
XLA הוא קומפיילר ספציפי לתחום של אלגברה לינארית, שמבוסס על חומרה ומסגרת, ומציע ביצועים מהטובים ביותר. JAX, TF, Pytorch ואחרים משתמשים ב-XLA על ידי המרת קלט המשתמש ל-StableHLO (פעולה ברמה גבוהה: קבוצה של כ-100 הוראות בצורה סטטית כמו חיבור, חיסור, matmul וכו'), שממנה XLA מייצר קוד מותאם למגוון של קצוות עורפיים:
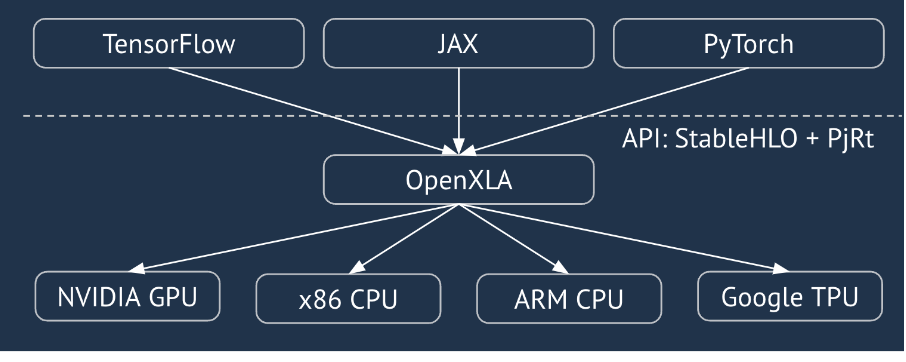
במהלך ההרצה, ה-frameworks מפעילים את ה-API של PJRT runtime, שמאפשר ל-frameworks לבצע את הפעולה 'אכלוס המאגרים שצוינו באמצעות תוכנית StableHLO נתונה במכשיר ספציפי'.
XLA:GPU Pipeline
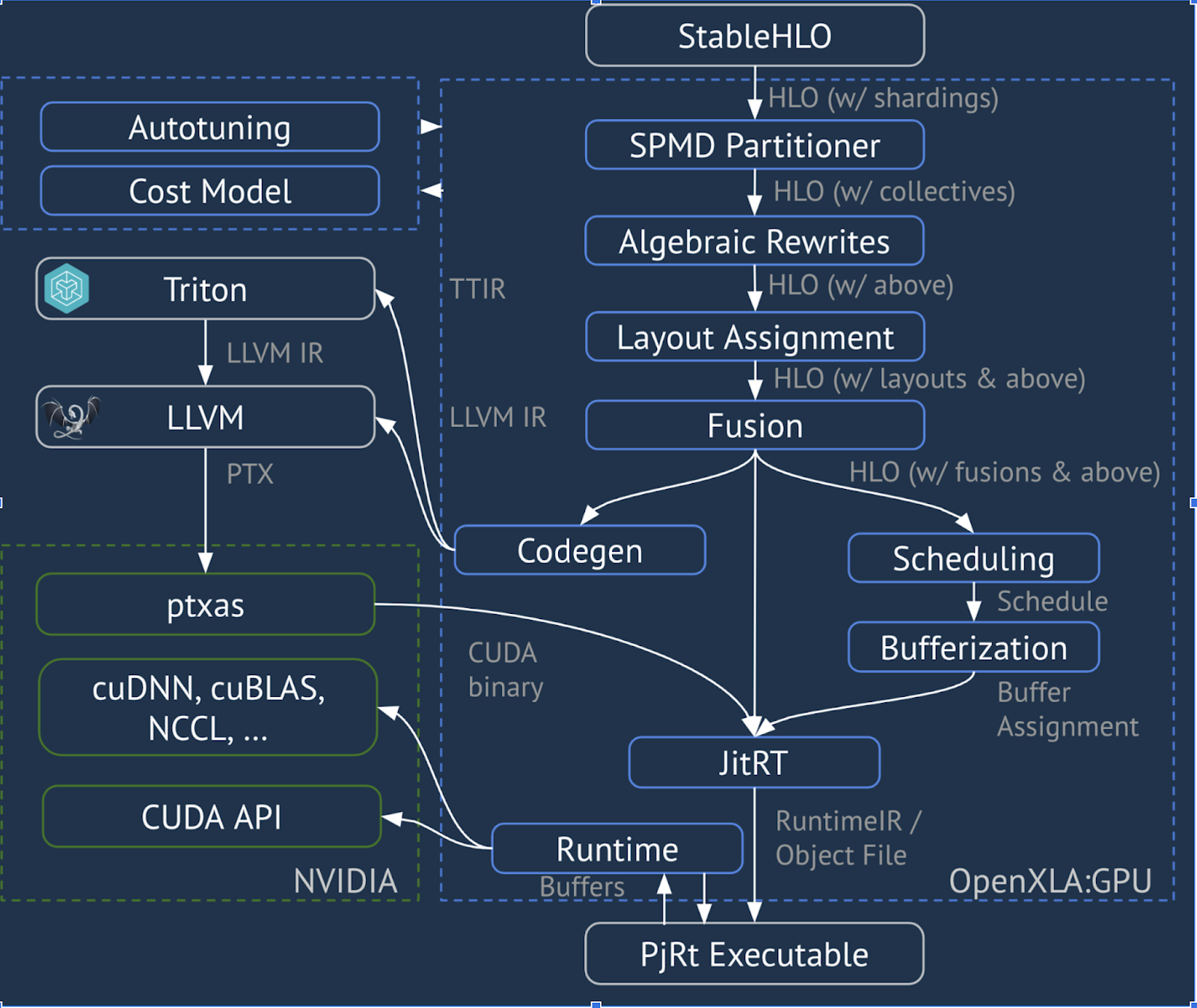
XLA:GPU משתמש בשילוב של פולטי 'נייטיב' (PTX, דרך LLVM) ופולטי TritonIR כדי ליצור ליבות GPU עם ביצועים גבוהים (הצבע הכחול מציין רכיבי צד שלישי):
דוגמה: JAX
כדי להמחיש את הצינור, נתחיל עם דוגמה פעילה ב-JAX, שמחשבת matmul בשילוב עם כפל בקבוע ושלילה:
def f(a, b):
return -((a @ b) * 0.125)
אפשר לבדוק את ה-HLO שנוצר על ידי הפונקציה:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
שיוצרת:
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
אפשר גם להציג באופן ויזואלי את חישוב ה-HLO של הקלט באמצעות הפקודה jax.xla_computation(f)(a, b).as_hlo_dot_graph():
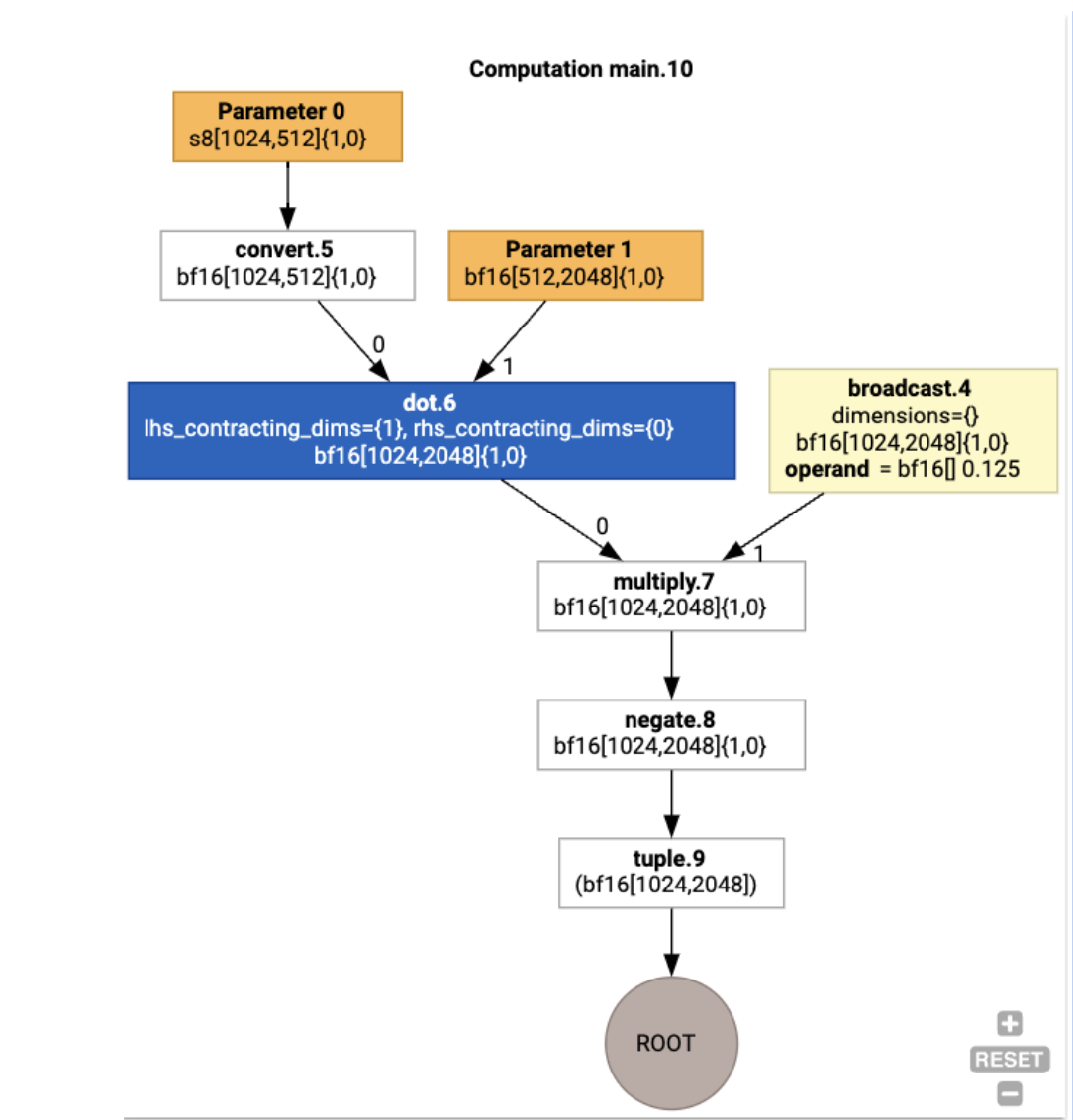
אופטימיזציות ב-HLO: רכיבים מרכזיים
מספר מעברים חשובים של אופטימיזציה מתרחשים ב-HLO, כתיבות מחדש של HLO->HLO.
SPMD Partitioner
הכלי לחלוקת מחיצות של XLA SPMD, כפי שמתואר במאמר GSPMD: General and Scalable Parallelization for MLComputation Graphs, צורך HLO עם הערות שרדינג (שנוצרות למשל על ידי jax.pjit), ומפיק HLO עם שרדינג שאפשר להריץ אותו במספר מארחים ומכשירים.
בנוסף לחלוקה למחיצות, SPMD מנסה לבצע אופטימיזציה של HLO כדי ליצור תזמון אופטימלי של הביצוע, חפיפה בין החישובים והתקשורת בין הצמתים.
דוגמה
כדאי להתחיל עם תוכנית JAX פשוטה שמתבצעת בשני מכשירים:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
ההערות על חלוקת הנתונים מוצגות כקריאות מותאמות אישית:
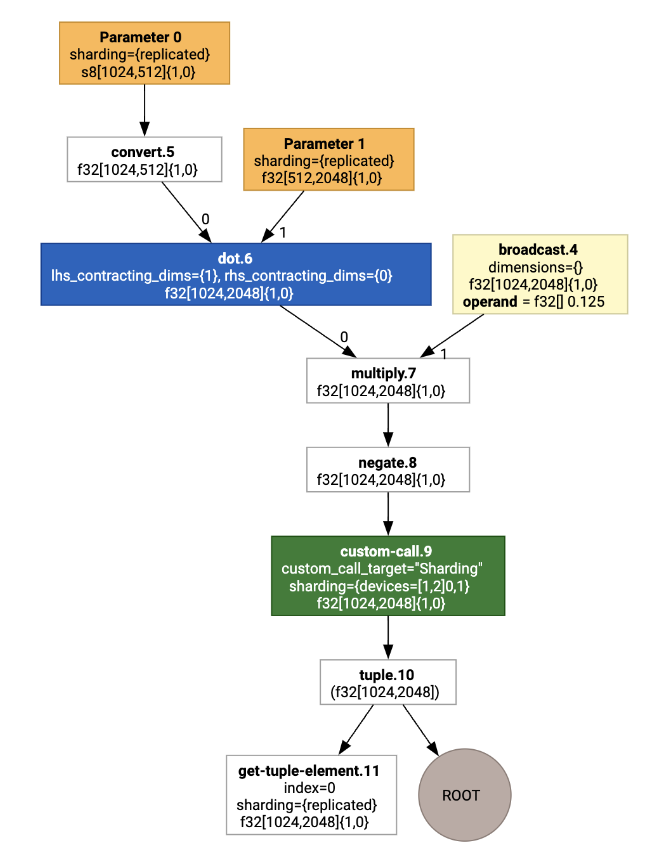
כדי לבדוק איך מחלק ה-SPMD מרחיב את הקריאה המותאמת אישית, אפשר להסתכל על HLO אחרי האופטימיזציות:
print(f.lower(np.ones((8, 8)).compile().as_text())
שיוצרת HLO עם קולקטיב:
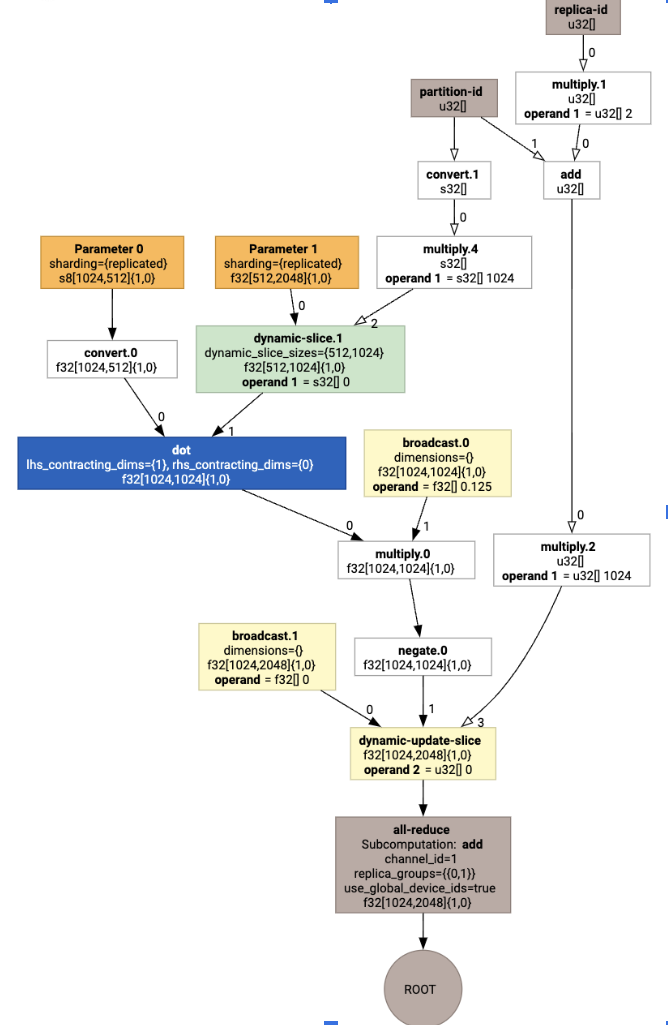
הקצאת פריסה
HLO מפריד בין הצורה הלוגית לבין הפריסה הפיזית (איך טנסורים מונחים בזיכרון). לדוגמה, מטריצה f32[32, 64] יכולה להיות מיוצגת בסדר שורות או בסדר עמודות, כפי שמוצג ב-{1,0} או ב-{0,1} בהתאמה.
באופן כללי, הפריסה מיוצגת כחלק מהצורה, ומציגה פרמוטציה של מספר הממדים שמציינת את הפריסה הפיזית בזיכרון.
לכל פעולה שמופיעה ב-HLO, שלב הקצאת הפריסה בוחר פריסה אופטימלית (למשל NHWC עבור קונבולוציה ב-Ampere). לדוגמה, פעולת int8xint8->int32 matmul מעדיפה פריסה של {0,1} בצד ימין של החישוב. באופן דומה, המערכת מתעלמת מ'העתקות' שהמשתמש מוסיף, ומקודדת אותן כשינוי פריסה.
לאחר מכן הפריסות מועברות דרך הגרף, וקונפליקטים בין פריסות או בנקודות הקצה של הגרף ממומשים כפעולות copy, שמבצעות את ההמרה הפיזית. לדוגמה, מתחילים מהתרשים
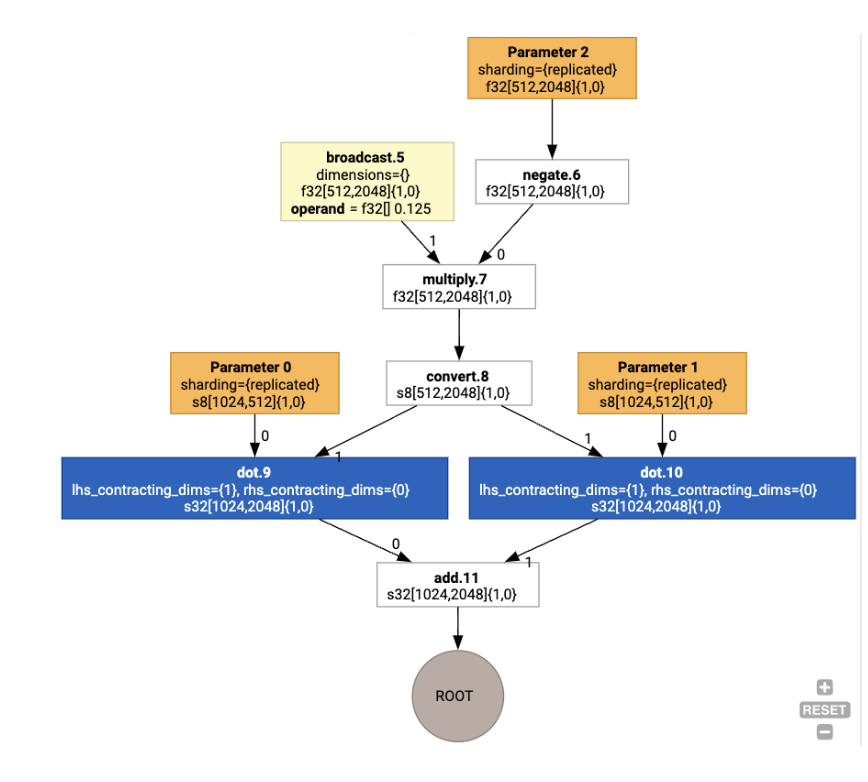
כשמריצים את הקצאת הפריסה, רואים את הפריסות הבאות ואת הפעולה copy שנוספה:
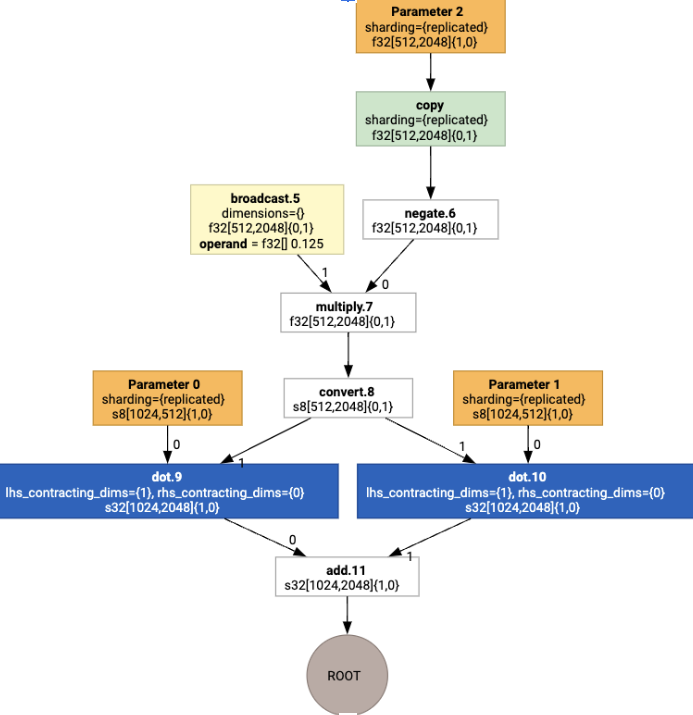
פיוז'ן
Fusion היא האופטימיזציה החשובה ביותר של XLA, שמקבצת כמה פעולות (למשל, חיבור, העלאה בחזקה, כפל מטריצות) לגרעין אחד. מכיוון שעומסי עבודה רבים של GPU נוטים להיות מוגבלים על ידי הזיכרון, המיזוג מאיץ באופן משמעותי את הביצוע על ידי הימנעות מכתיבה של טנסורים ביניים ל-HBM ואז קריאה שלהם בחזרה, ובמקום זאת מעביר אותם ברישומים או בזיכרון משותף.
הוראות HLO משולבות נחסמות יחד בחישוב שילוב יחיד, שקובע את התכונות הבלתי משתנות הבאות:
אף אחסון ביניים בתוך המיזוג לא ממומש ב-HBM (הכול צריך לעבור דרך רגיסטרים או זיכרון משותף).
קומפילציה של מיזוג תמיד מתבצעת לליבת GPU אחת בלבד
אופטימיזציות של HLO בדוגמה של הפעלה
אפשר לבדוק את ה-HLO אחרי האופטימיזציה באמצעות jax.jit(f).lower(a,
b).compile().as_text(), ולוודא שנוצר מיזוג יחיד:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
הערה: המיזוג backend_config מציין שהמערכת תשתמש ב-Triton כשיטה ליצירת קוד, ומציין את האריחים שנבחרו.
אפשר גם לראות את המודול שנוצר:
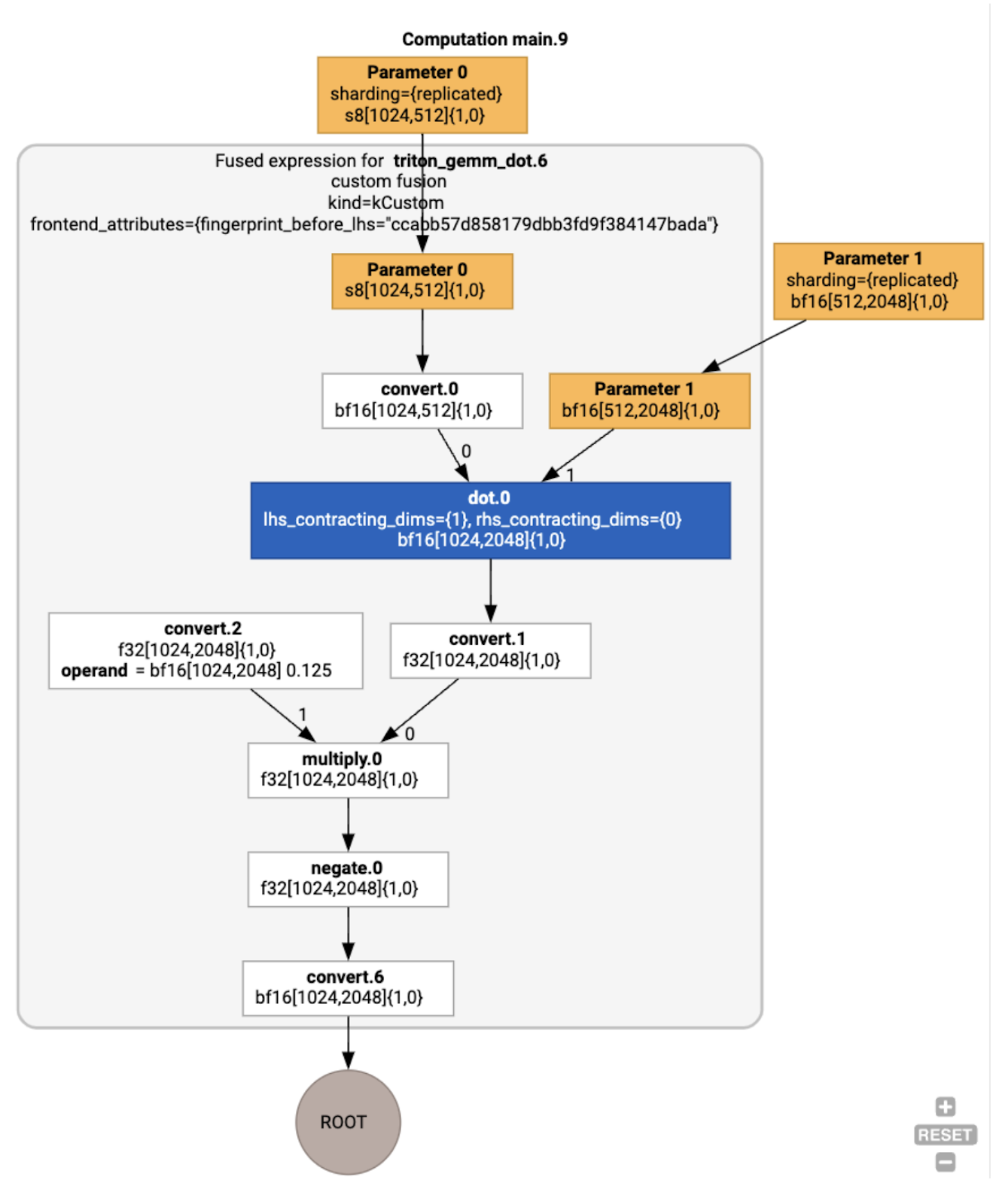
הקצאה ותזמון של מאגר
בשלב הקצאת מאגרים נלקחים בחשבון נתוני הצורה, והמטרה היא להקצות מאגרים בצורה אופטימלית לתוכנית, כך שכמות הזיכרון הזמני שיידרש תהיה מינימלית. בניגוד להרצה במצב מיידי (לא הידור) ב-TF או ב-PyTorch, שבה מקצה הזיכרון לא יודע את הגרף מראש, מתזמן ה-XLA יכול 'להסתכל לעתיד' וליצור תזמון אופטימלי של החישוב.
קצה עורכי המהדורה: יצירת קוד ובחירת ספרייה
עבור כל הוראת HLO בחישוב, XLA בוחר אם להריץ אותה באמצעות ספרייה שמקושרת לזמן ריצה, או ליצור ממנה קוד ל-PTX.
בחירת ספרייה
בפעולות נפוצות רבות, XLA:GPU משתמש בספריות עם ביצועים מהירים מבית NVIDIA, כמו cuBLAS, cuDNN ו-NCCL. היתרון של הספריות הוא ביצועים מהירים ומאומתים, אבל לרוב הן לא מאפשרות הזדמנויות מורכבות לאיחוד.
יצירת קוד ישירה
הקצה העורפי XLA:GPU יוצר ישירות LLVM IR עם ביצועים גבוהים למספר פעולות (צמצומים, טרנספוזיציות וכו').
יצירת קוד ב-Triton
למיזוגים מתקדמים יותר שכוללים כפל מטריצות או softmax, XLA:GPU משתמש ב-Triton כשכבת יצירת קוד. מיזוגים של HLO מומרים ל-TritonIR (ניב של MLIR שמשמש כקלט ל-Triton), נבחרים פרמטרים של חלוקה לאריחים ומופעל Triton ליצירת PTX:
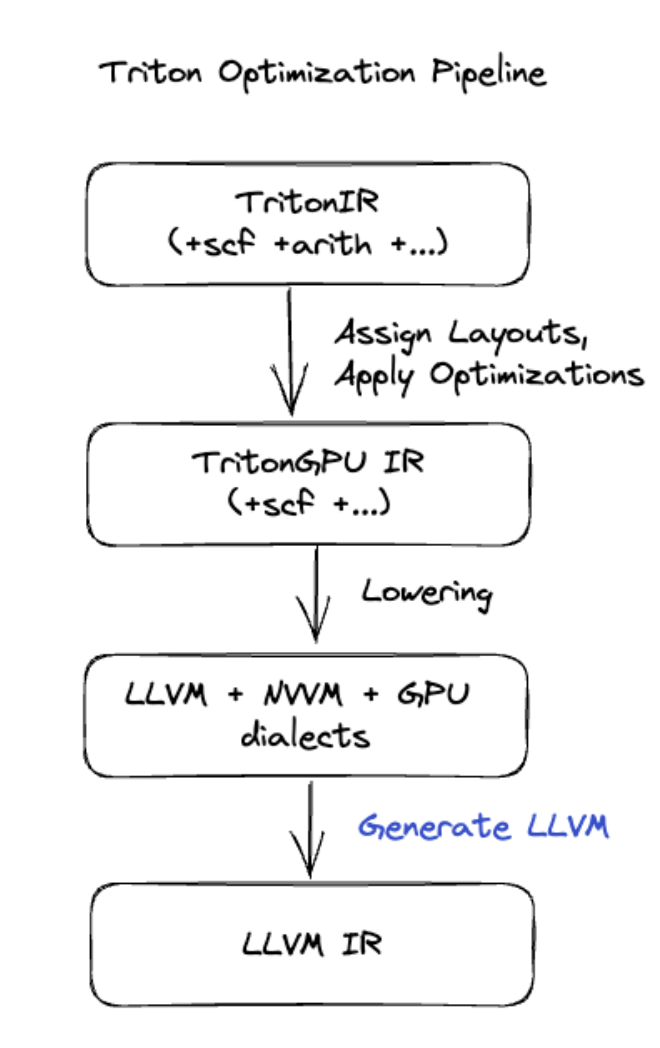
התבוננו בקוד שנוצר וראינו שהוא פועל טוב מאוד ב-Ampere, עם ביצועים כמעט מקסימליים כשגודלי המשבצות מותאמים כראוי.
זמן ריצה
סביבת זמן הריצה של XLA ממירה את הרצף שמתקבל של קריאות לליבת CUDA והפעלות של ספריות ל-RuntimeIR (ניב MLIR ב-XLA), שעליו מתבצעת חילוץ של גרף CUDA. גרף CUDA עדיין נמצא בתהליך פיתוח, וכרגע יש תמיכה רק בחלק מהצמתים. אחרי חילוץ הגבולות של גרף CUDA, RuntimeIR עובר קומפילציה באמצעות LLVM לקובץ הפעלה של CPU, שאפשר לאחסן או להעביר אותו לקומפילציה מראש.