
परिचय
XLA, लीनियर अलजेब्रा के लिए हार्डवेयर और फ़्रेमवर्क के हिसाब से काम करने वाला कंपाइलर है. यह सबसे अच्छी परफ़ॉर्मेंस देता है. JAX, TF, Pytorch, और अन्य XLA का इस्तेमाल करते हैं. इसके लिए, वे उपयोगकर्ता के इनपुट को StableHLO (“हाई-लेवल ऑपरेशन”: जोड़, घटाव, matmul वगैरह जैसे ~100 स्टैटिक निर्देशों का सेट) ऑपरेशन सेट में बदलते हैं. XLA, इस सेट से अलग-अलग बैकएंड के लिए ऑप्टिमाइज़ किया गया कोड जनरेट करता है:
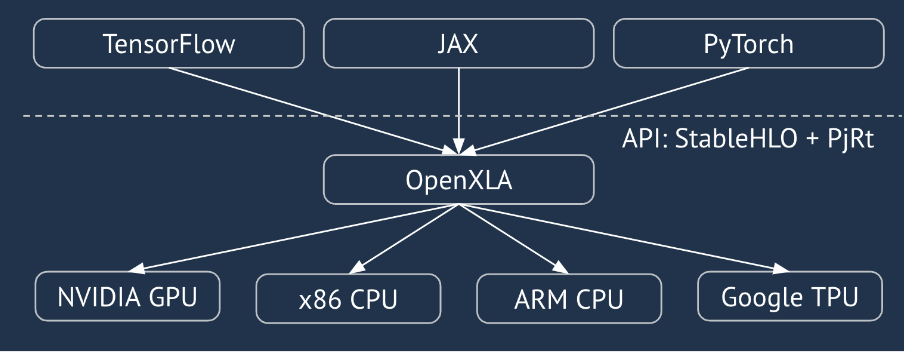
एक्ज़ीक्यूशन के दौरान, फ़्रेमवर्क PJRT रनटाइम एपीआई को कॉल करते हैं. इससे फ़्रेमवर्क, “किसी डिवाइस पर दिए गए StableHLO प्रोग्राम का इस्तेमाल करके, तय किए गए बफ़र में डेटा डाल सकते हैं”.
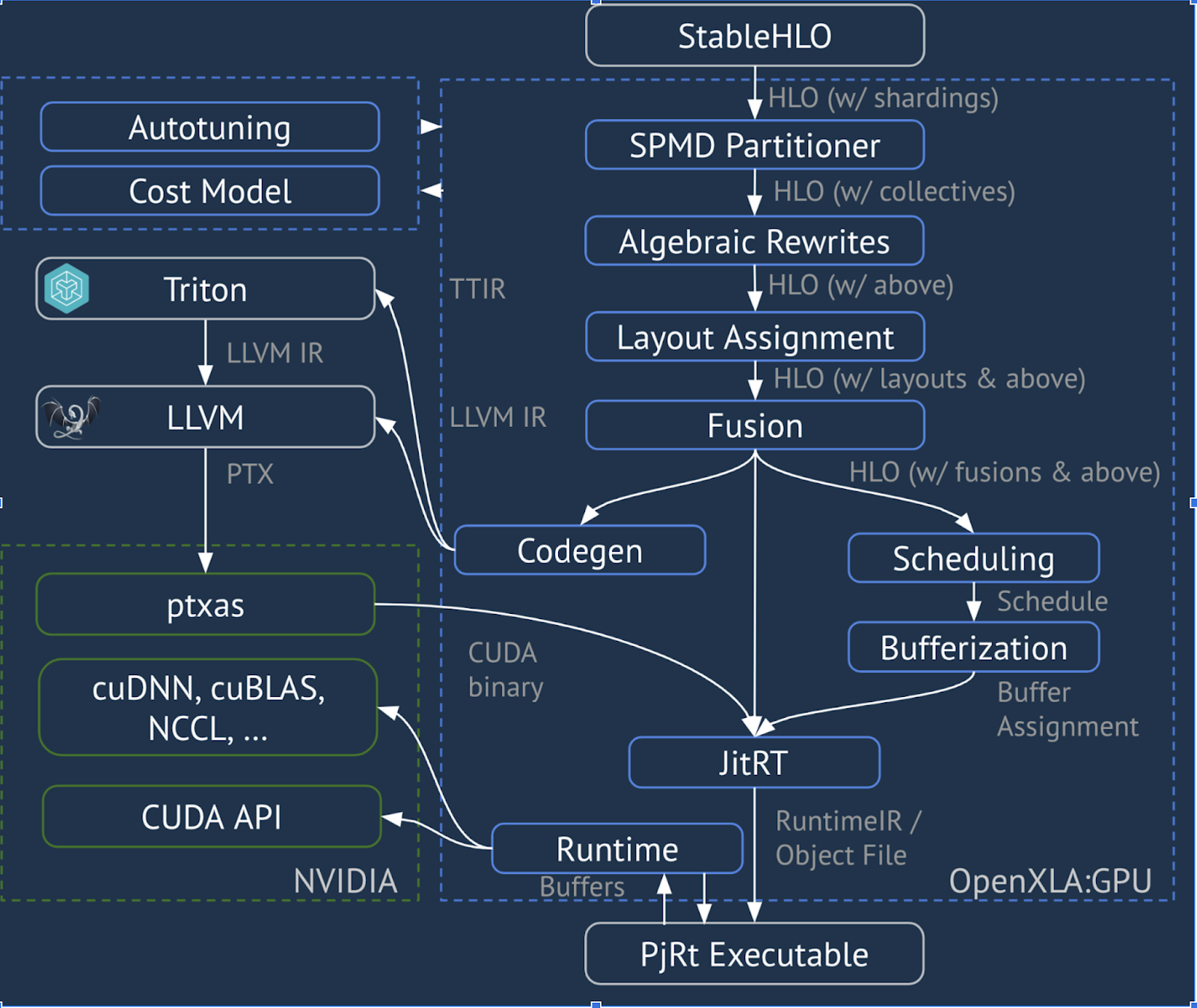
XLA:GPU Pipeline
XLA:GPU, “नेटिव” (एलएलवीएम के ज़रिए पीटीएक्स) एमिटर और TritonIR एमिटर का इस्तेमाल करके, ज़्यादा परफ़ॉर्मेंस वाले जीपीयू कर्नल जनरेट करता है. नीले रंग से 3P कॉम्पोनेंट का पता चलता है:
उदाहरण: JAX
पाइपलाइन को समझने के लिए, आइए JAX में चल रहे एक उदाहरण से शुरुआत करते हैं. यह उदाहरण, एक कॉन्स्टेंट से गुणा करने और नेगेटिव करने के साथ-साथ matmul की गणना करता है:
def f(a, b):
return -((a @ b) * 0.125)
हम फ़ंक्शन से जनरेट किए गए HLO की जांच कर सकते हैं:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
जिससे ये जनरेट होते हैं:
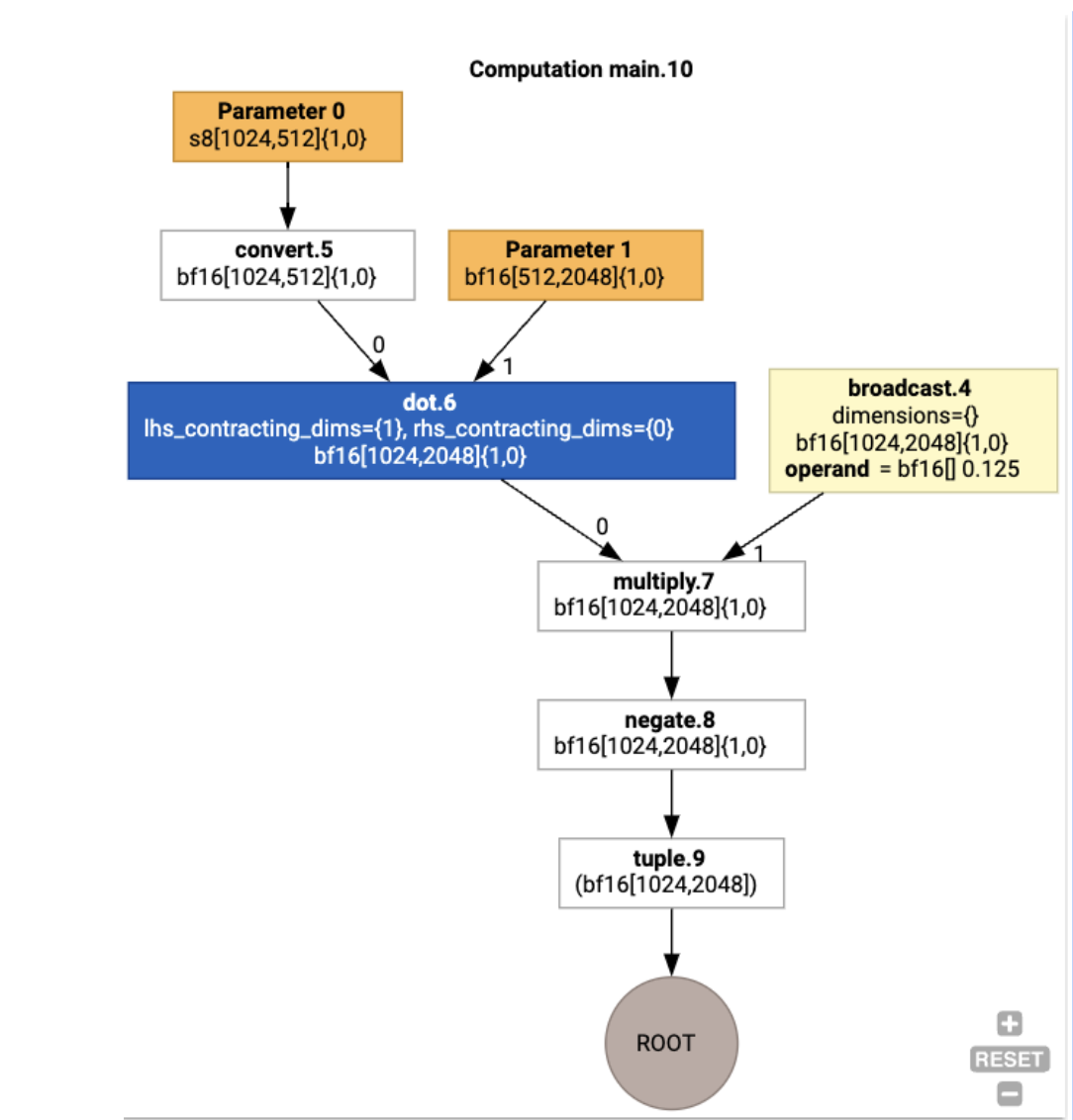
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
हम jax.xla_computation(f)(a, b).as_hlo_dot_graph() का इस्तेमाल करके, इनपुट किए गए एचएलओ कंप्यूटेशन को भी विज़ुअलाइज़ कर सकते हैं:
एचएलओ पर ऑप्टिमाइज़ेशन: मुख्य कॉम्पोनेंट
HLO पर कई अहम ऑप्टिमाइज़ेशन पास होते हैं. जैसे, HLO->HLO फिर से लिखना.
SPMD Partitioner
XLA SPMD पार्टीशनर, GSPMD: MLComputation Graph के लिए सामान्य और स्केलेबल पैरेललाइज़ेशन में बताए गए तरीके से काम करता है. यह शार्डिंग एनोटेशन वाले HLO का इस्तेमाल करता है. ये एनोटेशन, jax.pjit जैसे ऑपरेटर से जनरेट होते हैं. इसके बाद, यह शार्ड किया गया HLO जनरेट करता है. इसे कई होस्ट और डिवाइसों पर चलाया जा सकता है.
एसपीएमडी, पार्टीशनिंग के अलावा, एचएलओ को ऑप्टिमाइज़ करने की कोशिश करता है. ऐसा सबसे बेहतर तरीके से एक्ज़ीक्यूट करने के लिए शेड्यूल बनाने, ओवरलैपिंग कंप्यूटेशन, और नोड के बीच कम्यूनिकेशन के लिए किया जाता है.
उदाहरण
दो डिवाइसों पर शार्ड किए गए एक सामान्य JAX प्रोग्राम से शुरुआत करें:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
इसे विज़ुअलाइज़ करने पर, शार्डिंग एनोटेशन को कस्टम कॉल के तौर पर दिखाया जाता है:
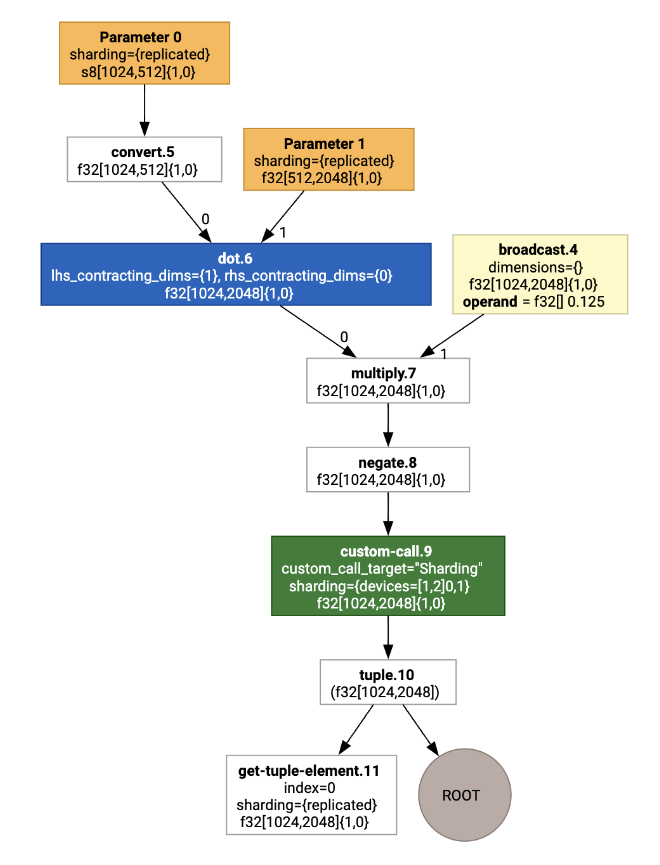
एसपीएमडी पार्टीशनर, कस्टम कॉल को कैसे बड़ा करता है, यह देखने के लिए हम ऑप्टिमाइज़ेशन के बाद HLO को देख सकते हैं:
print(f.lower(np.ones((8, 8)).compile().as_text())
इससे एक सामूहिक एचएलओ जनरेट होता है:
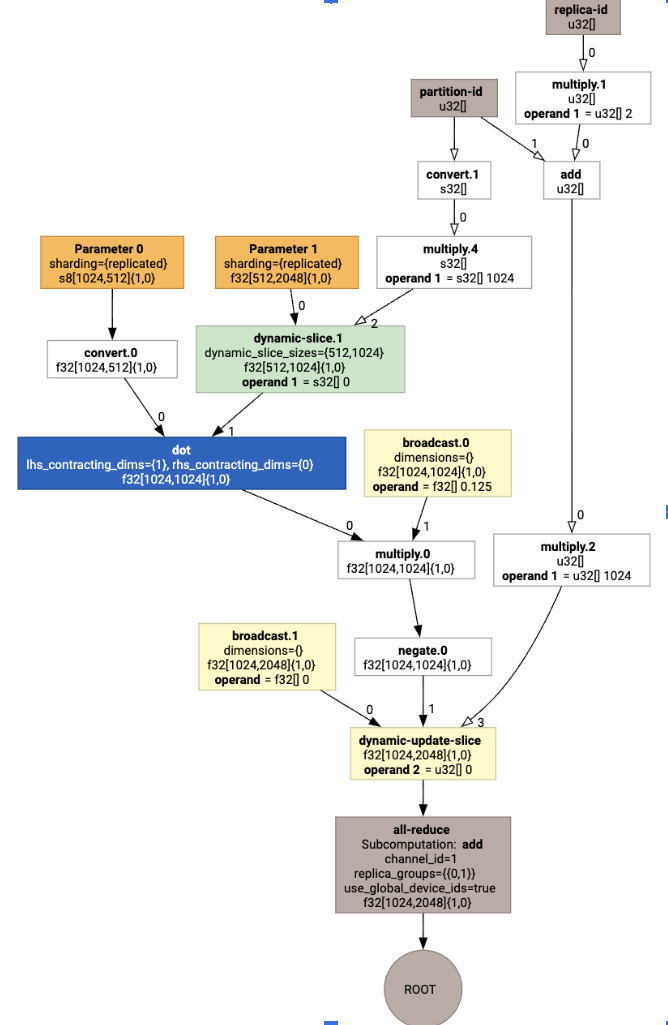
लेआउट असाइनमेंट
एचएलओ, लॉजिकल शेप और फ़िज़िकल लेआउट (टेंसर को मेमोरी में कैसे लेआउट किया जाता है) को अलग करता है. उदाहरण के लिए, मैट्रिक्स f32[32, 64] को पंक्ति-मुख्य या कॉलम-मुख्य क्रम में दिखाया जा सकता है. इसे क्रमशः {1,0} या {0,1} के तौर पर दिखाया जाता है.
आम तौर पर, लेआउट को शेप के हिस्से के तौर पर दिखाया जाता है. इससे डाइमेंशन की संख्या के हिसाब से क्रमपरिवर्तन दिखता है. यह क्रमपरिवर्तन, मेमोरी में फ़िज़िकल लेआउट को दिखाता है.
एचएलओ में मौजूद हर ऑपरेशन के लिए, लेआउट असाइनमेंट पास एक सबसे सही लेआउट चुनता है. उदाहरण के लिए, Ampere पर कनवोल्यूशन के लिए NHWC. उदाहरण के लिए, int8xint8->int32 matmul ऑपरेशन, कंप्यूटेशन के आरएचएस के लिए {0,1} लेआउट को प्राथमिकता देता है. इसी तरह, उपयोगकर्ता की ओर से डाले गए “ट्रांसपोज़” को अनदेखा कर दिया जाता है. साथ ही, उन्हें लेआउट में बदलाव के तौर पर कोड में बदला जाता है.
इसके बाद, लेआउट को ग्राफ़ में फैलाया जाता है. साथ ही, लेआउट या ग्राफ़ के एंडपॉइंट के बीच होने वाले टकरावों को copy ऑपरेशनों के तौर पर दिखाया जाता है. ये ऑपरेशन, फ़िजिकल ट्रांसपोज़िशन करते हैं. उदाहरण के लिए, ग्राफ़ से शुरू करना
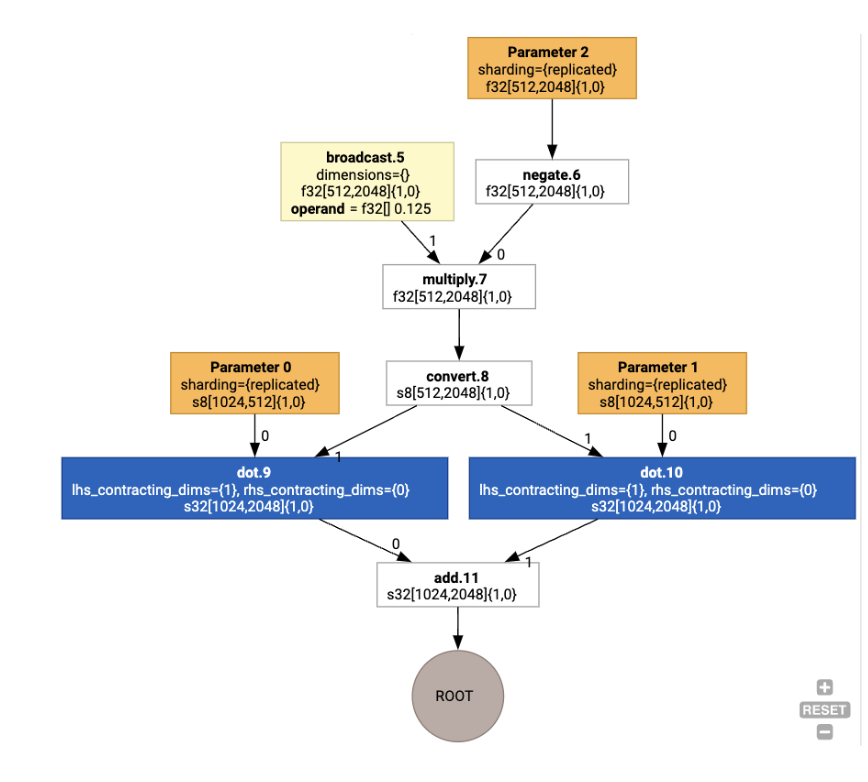
लेआउट असाइनमेंट चलाने पर, हमें ये लेआउट और copy ऑपरेशन दिखता है:
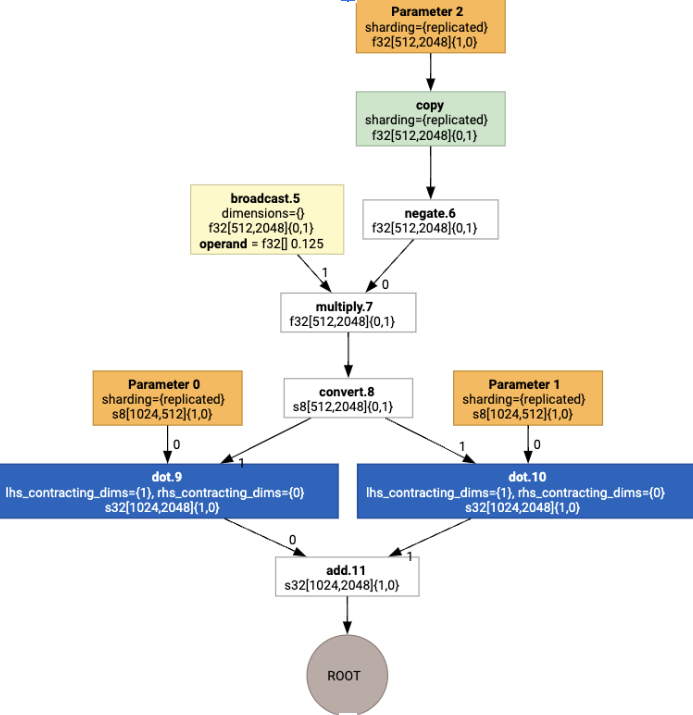
फ़्यूज़न
फ़्यूज़न, XLA का सबसे अहम ऑप्टिमाइज़ेशन है. यह कई ऑपरेशनों (जैसे, जोड़ना, घातांक, और मैट्रिक्स गुणा) को एक ही कर्नल में ग्रुप करता है. ज़्यादातर जीपीयू वर्कलोड, मेमोरी से जुड़े होते हैं. इसलिए, फ़्यूज़न की मदद से, एग्ज़ीक्यूशन की प्रोसेस को काफ़ी तेज़ किया जा सकता है. ऐसा इसलिए, क्योंकि फ़्यूज़न इंटरमीडिएट टेंसर को एचबीएम में लिखने और फिर उन्हें वापस पढ़ने से बचाता है. इसके बजाय, उन्हें रजिस्टर या शेयर की गई मेमोरी में पास करता है.
फ़्यूज़ किए गए एचएलओ निर्देशों को एक साथ एक फ़्यूज़न कंप्यूटेशन में ब्लॉक किया जाता है. इससे ये इनवेरिएंट सेट अप होते हैं:
फ़्यूज़न के अंदर कोई इंटरमीडिएट स्टोरेज, एचबीएम में नहीं होता. इसे रजिस्टर या शेयर की गई मेमोरी से पास किया जाना चाहिए.
फ़्यूज़न को हमेशा सिर्फ़ एक जीपीयू कर्नल में कंपाइल किया जाता है
दौड़ने के उदाहरण में एचएलओ ऑप्टिमाइज़ेशन
हम jax.jit(f).lower(a,
b).compile().as_text() का इस्तेमाल करके, ऑप्टिमाइज़ेशन के बाद के एचएलओ की जांच कर सकते हैं. साथ ही, यह पुष्टि कर सकते हैं कि एक फ़्यूज़न जनरेट हुआ है:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
ध्यान दें कि फ़्यूज़न backend_config से पता चलता है कि कोड जनरेट करने की रणनीति के तौर पर Triton का इस्तेमाल किया जाएगा. साथ ही, इससे चुनी गई टाइलिंग के बारे में भी पता चलता है.
हम नतीजे वाले मॉड्यूल को इस तरह भी देख सकते हैं:
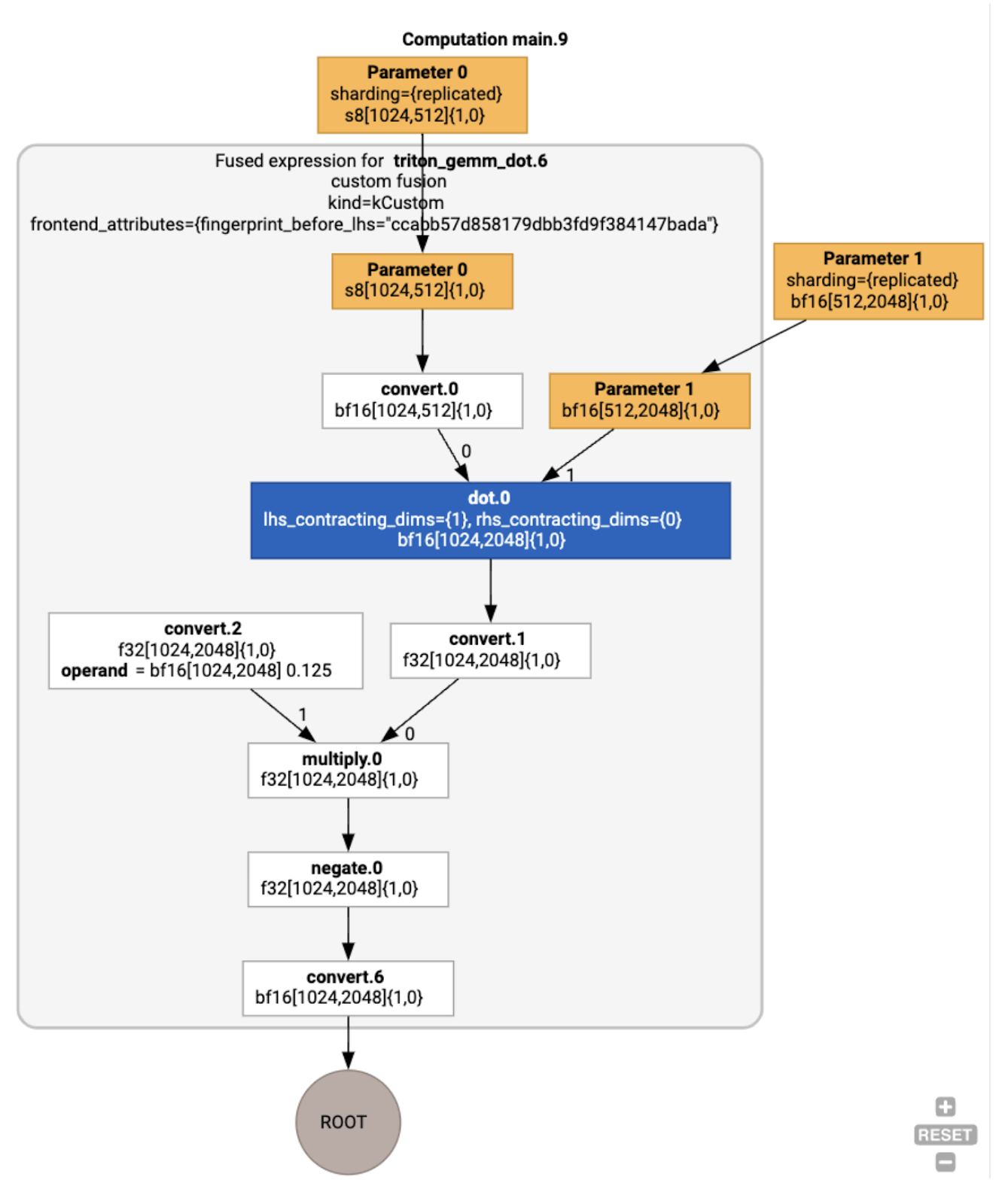
बफ़र असाइनमेंट और शेड्यूलिंग
बफ़र असाइनमेंट पास, शेप की जानकारी को ध्यान में रखता है. इसका मकसद प्रोग्राम के लिए सबसे सही बफ़र असाइनमेंट तैयार करना होता है. इससे इंटरमीडिएट मेमोरी का इस्तेमाल कम से कम होता है. TF या PyTorch के इमीडिएट-मोड (नॉन-कंपाइल) एक्ज़ीक्यूशन में, मेमोरी ऐलोकेटर को ग्राफ़ के बारे में पहले से पता नहीं होता है. इसके उलट, XLA शेड्यूलर “भविष्य में झांक सकता है” और सबसे सही कंप्यूटेशन शेड्यूल बना सकता है.
कंपाइलर बैकएंड: कोड जनरेशन और लाइब्रेरी का चुनाव
कैलकुलेशन में मौजूद हर एचएलओ निर्देश के लिए, XLA यह चुनता है कि उसे रनटाइम से लिंक की गई लाइब्रेरी का इस्तेमाल करके चलाया जाए या उसे PTX में कोडजन किया जाए.
लाइब्रेरी चुनना
कई सामान्य कार्रवाइयों के लिए, XLA:GPU, NVIDIA की तेज़ परफ़ॉर्मेंस वाली लाइब्रेरी का इस्तेमाल करता है. जैसे, cuBLAS, cuDNN, और NCCL. इन लाइब्रेरी का फ़ायदा यह है कि इनकी परफ़ॉर्मेंस की पुष्टि हो चुकी है और ये तेज़ी से काम करती हैं. हालांकि, इनमें अक्सर फ़्यूज़न के जटिल विकल्प नहीं होते.
सीधे तौर पर कोड जनरेट करना
XLA:GPU बैकएंड, कई तरह के ऑपरेशन (रिडक्शन, ट्रांसपोज़ वगैरह) के लिए सीधे तौर पर हाई-परफ़ॉर्मेंस LLVM IR जनरेट करता है.
Triton की मदद से कोड जनरेट करना
मैट्रिक्स मल्टिप्लिकेशन या सॉफ़्टमैक्स जैसे ज़्यादा बेहतर फ़्यूज़न के लिए, XLA:GPU, कोड जनरेट करने वाली लेयर के तौर पर Triton का इस्तेमाल करता है. HLO फ़्यूज़न को TritonIR (यह MLIR का एक डायलेक्ट है, जो Triton के लिए इनपुट के तौर पर काम करता है) में बदल दिया जाता है. साथ ही, टाइलिंग पैरामीटर चुने जाते हैं और PTX जनरेट करने के लिए Triton को चालू किया जाता है:
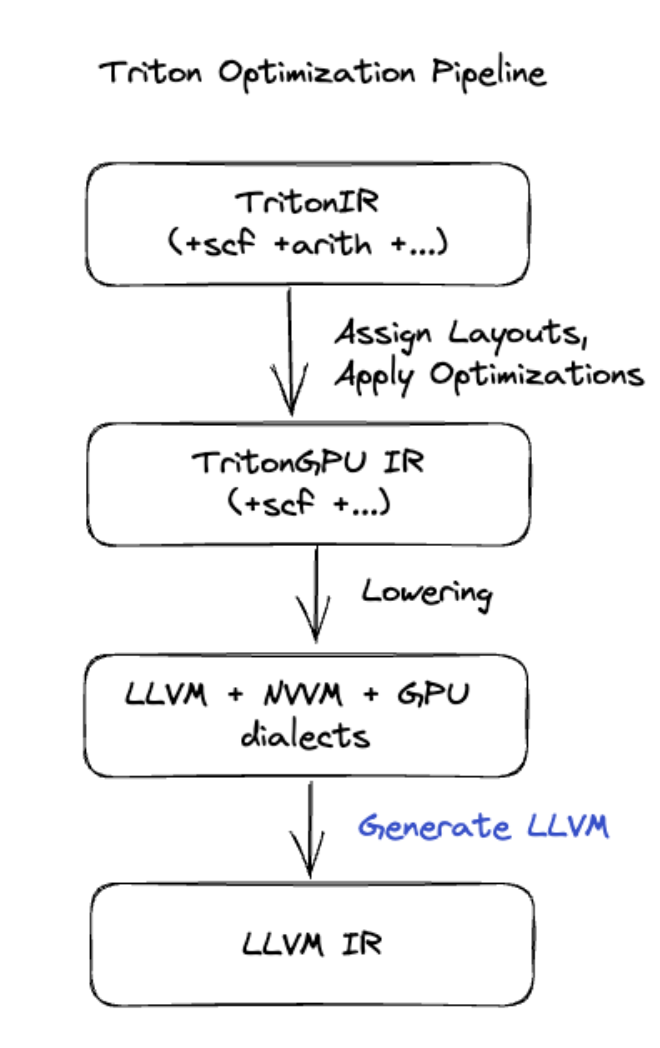
हमने देखा है कि Ampere पर जनरेट किया गया कोड बहुत अच्छा काम करता है. साथ ही, टाइल के साइज़ को सही तरीके से ट्यून करने पर, यह कोड लगभग रूफ़लाइन परफ़ॉर्मेंस देता है.
रनटाइम
XLA रनटाइम, CUDA कर्नल कॉल और लाइब्रेरी इनवोकेशन के नतीजे वाले क्रम को RuntimeIR (XLA में MLIR डाइलैक्ट) में बदलता है. इस पर CUDA ग्राफ़ एक्सट्रैक्शन किया जाता है. CUDA ग्राफ़ पर अब भी काम चल रहा है. फ़िलहाल, सिर्फ़ कुछ नोड इस्तेमाल किए जा सकते हैं. CUDA ग्राफ़ की सीमाओं को निकालने के बाद, RuntimeIR को LLVM के ज़रिए सीपीयू पर चलने वाले प्रोग्राम में कंपाइल किया जाता है. इसके बाद, इसे सेव किया जा सकता है या पहले से कंपाइल करने के लिए ट्रांसफ़र किया जा सकता है.