
Pengantar
XLA adalah compiler khusus domain hardware dan framework untuk aljabar linier, yang menawarkan performa terbaik di kelasnya. JAX, TF, Pytorch, dan lainnya menggunakan XLA dengan mengonversi input pengguna ke StableHLO (“operasi tingkat tinggi”: serangkaian ~100 instruksi berbentuk statis seperti penambahan, pengurangan, matmul, dll.), yang kemudian XLA menghasilkan kode yang dioptimalkan untuk berbagai backend:
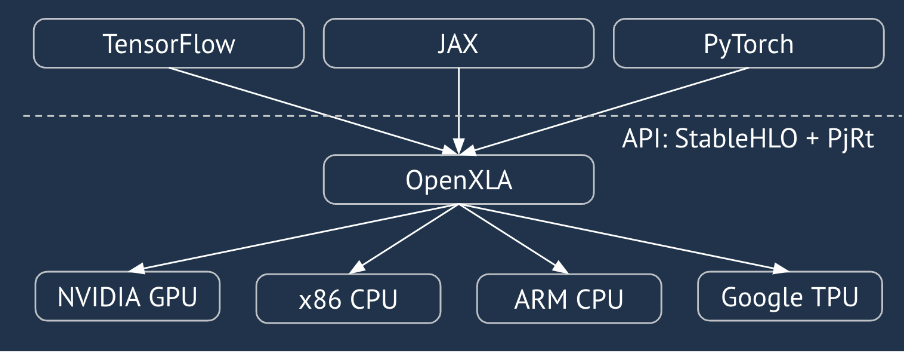
Selama eksekusi, framework memanggil API runtime PJRT, yang memungkinkan framework melakukan operasi “mengisi buffer yang ditentukan menggunakan program StableHLO tertentu di perangkat tertentu”.
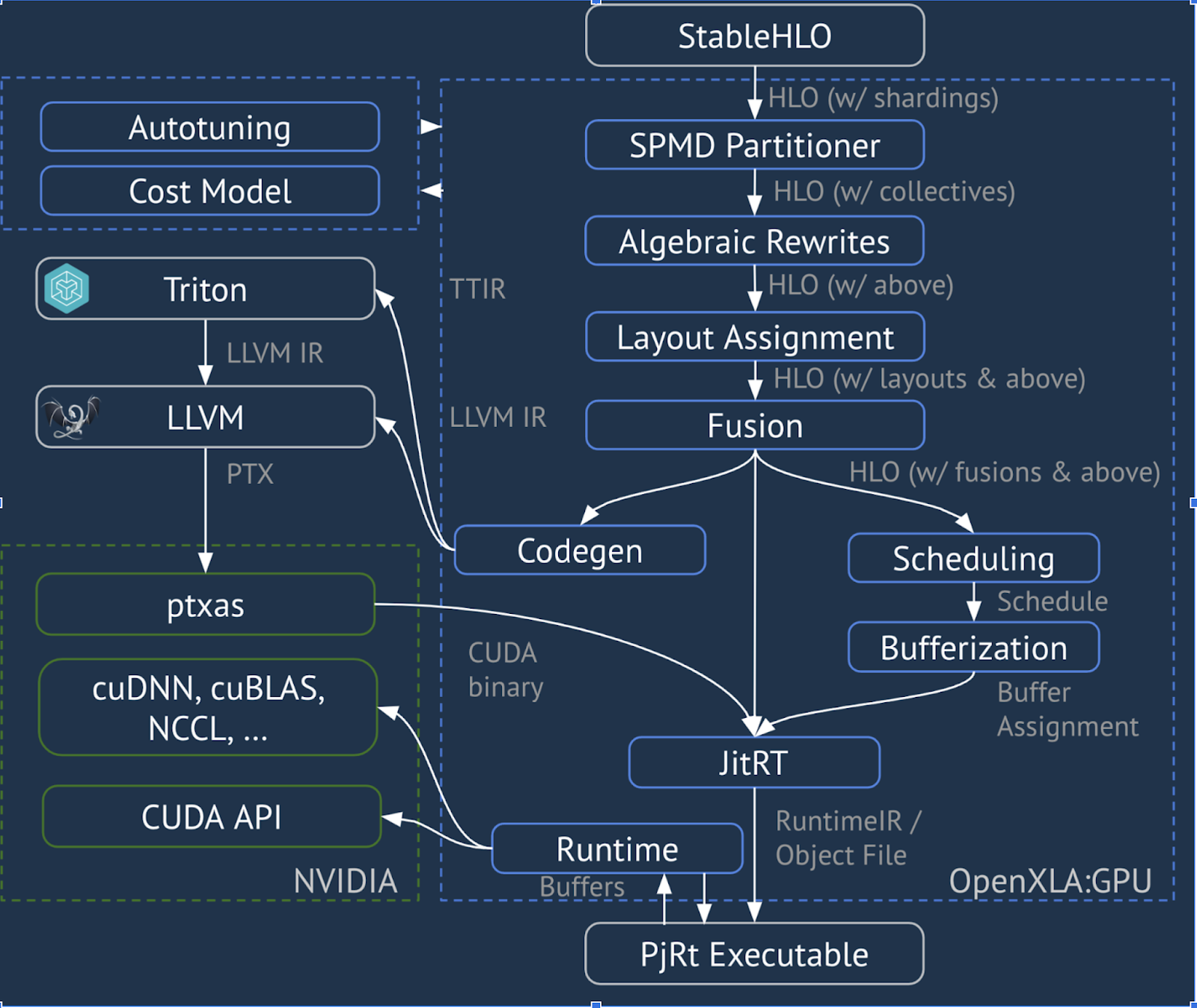
Pipeline XLA:GPU
XLA:GPU menggunakan kombinasi pemancar “asli” (PTX, melalui LLVM) dan pemancar TritonIR untuk menghasilkan kernel GPU berperforma tinggi (warna biru menunjukkan komponen 3P):
Contoh Menjalankan: JAX
Untuk menggambarkan pipeline, mari kita mulai dengan contoh yang berjalan di JAX, yang menghitung matmul yang dikombinasikan dengan perkalian dengan konstanta dan negasi:
def f(a, b):
return -((a @ b) * 0.125)
Kita dapat memeriksa HLO yang dihasilkan oleh fungsi:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
yang menghasilkan:
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
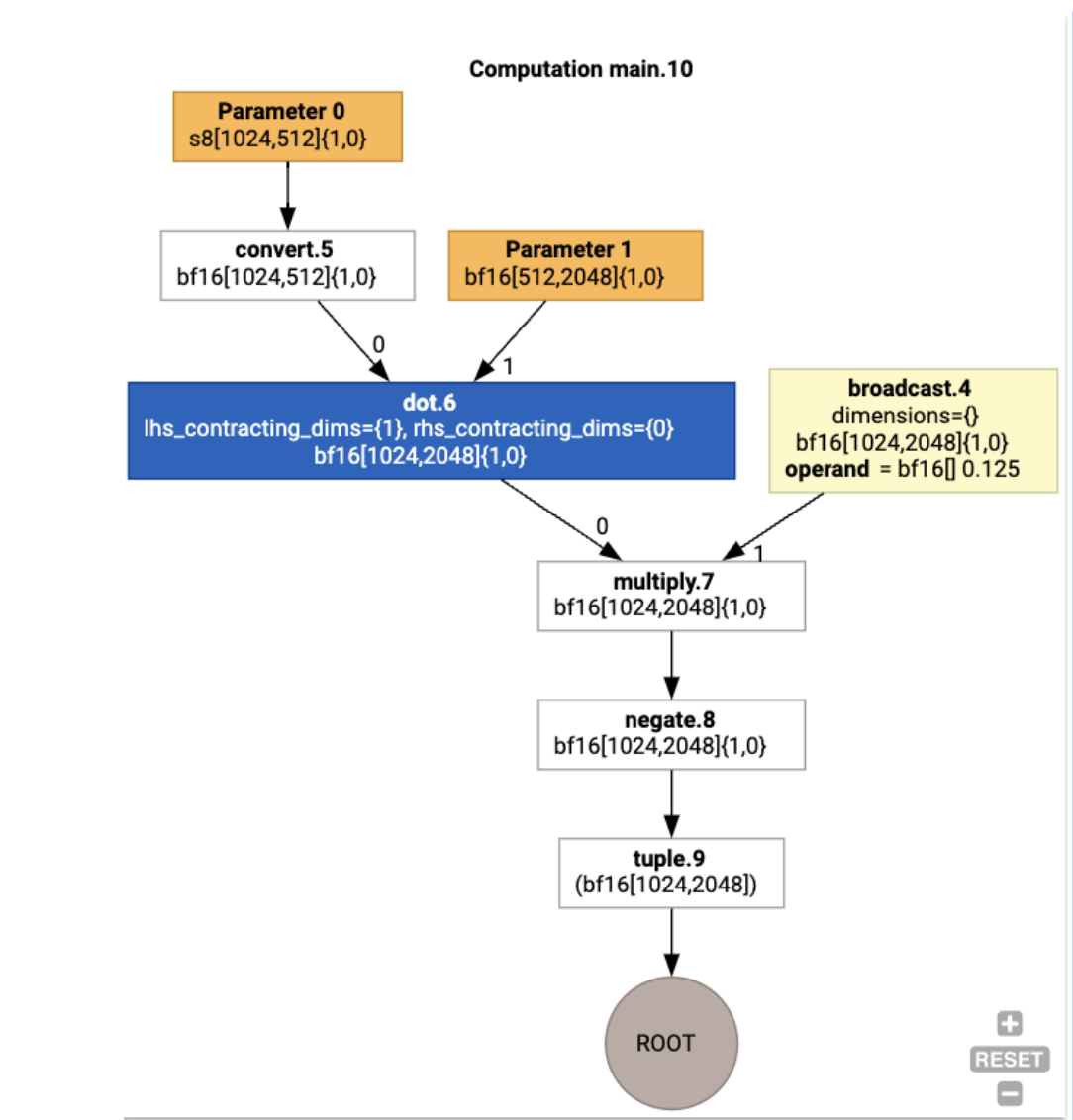
Kita juga dapat memvisualisasikan komputasi HLO input, menggunakan
jax.xla_computation(f)(a, b).as_hlo_dot_graph():
Pengoptimalan di HLO: Komponen Utama
Sejumlah pengoptimalan penting terjadi di HLO, sebagai penulisan ulang HLO->HLO.
Partisi SPMD
Partisi SPMD XLA, seperti yang dijelaskan dalam
GSPMD: General and Scalable Parallelization for MLComputation Graphs,
menggunakan HLO dengan anotasi sharding (dihasilkan misalnya oleh jax.pjit), dan
menghasilkan HLO yang di-shard yang kemudian dapat berjalan di sejumlah host dan perangkat.
Selain partisi, SPMD mencoba mengoptimalkan HLO untuk jadwal eksekusi yang optimal, komputasi dan komunikasi yang tumpang-tindih antar-node.
Contoh
Pertimbangkan untuk memulai dari program JAX sederhana yang di-shard di dua perangkat:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
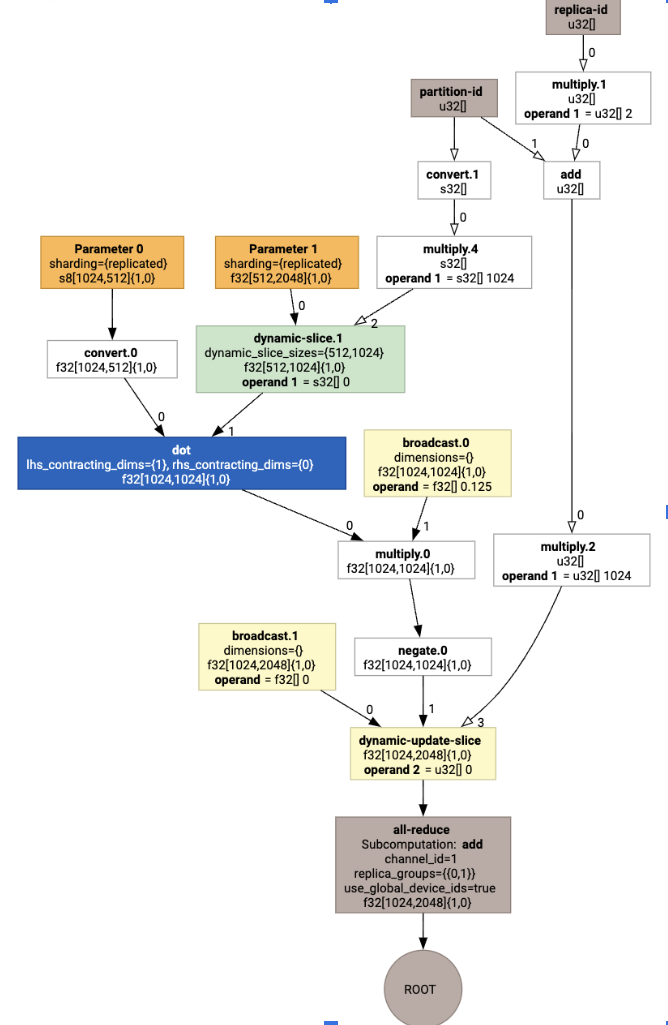
Secara visual, anotasi sharding ditampilkan sebagai panggilan kustom:
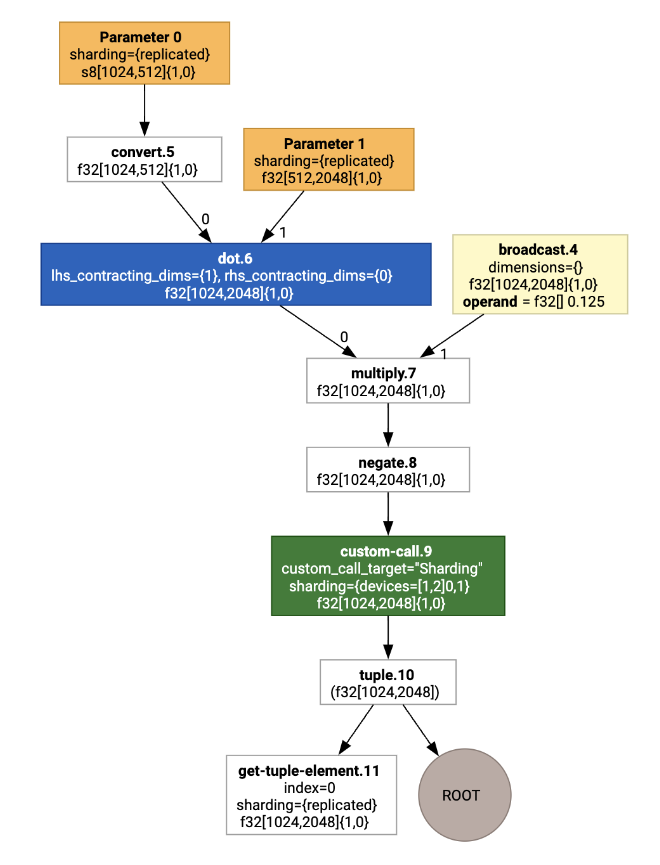
Untuk memeriksa cara pemartisi SPMD memperluas panggilan kustom, kita dapat melihat HLO setelah pengoptimalan:
print(f.lower(np.ones((8, 8)).compile().as_text())
Yang menghasilkan HLO dengan kolektif:
Penetapan Tata Letak
HLO memisahkan bentuk logis dan tata letak fisik (cara tensor ditata di
memori). Misalnya, matriks f32[32, 64] dapat direpresentasikan dalam urutan baris-utama atau kolom-utama, yang masing-masing direpresentasikan sebagai {1,0} atau {0,1}.
Secara umum, tata letak direpresentasikan sebagai bagian dari bentuk, yang menunjukkan permutasi atas jumlah dimensi yang menunjukkan tata letak fisik dalam memori.
Untuk setiap operasi yang ada di HLO, langkah Layout Assignment memilih tata letak
optimal (misalnya NHWC untuk konvolusi di Ampere). Misalnya, operasi
int8xint8->int32 matmul lebih memilih tata letak {0,1} untuk sisi kanan
penghitungan. Demikian pula, “transposisi” yang dimasukkan oleh pengguna diabaikan, dan
dikodekan sebagai perubahan tata letak.
Tata letak kemudian disebarkan melalui grafik, dan konflik antara tata letak
atau di endpoint grafik diwujudkan sebagai operasi copy, yang melakukan
transposisi fisik. Misalnya, mulai dari grafik
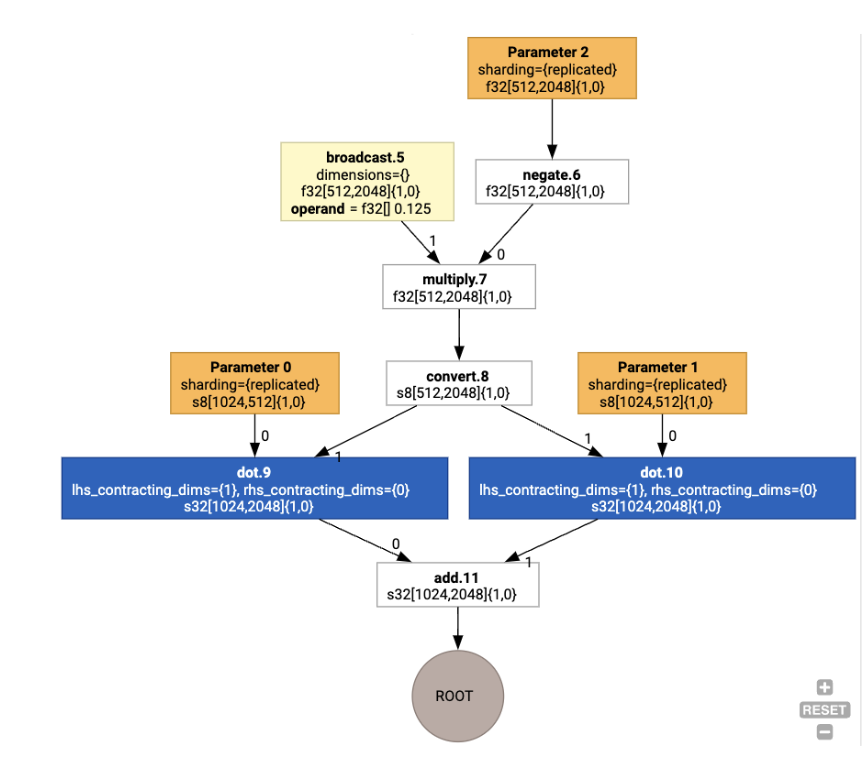
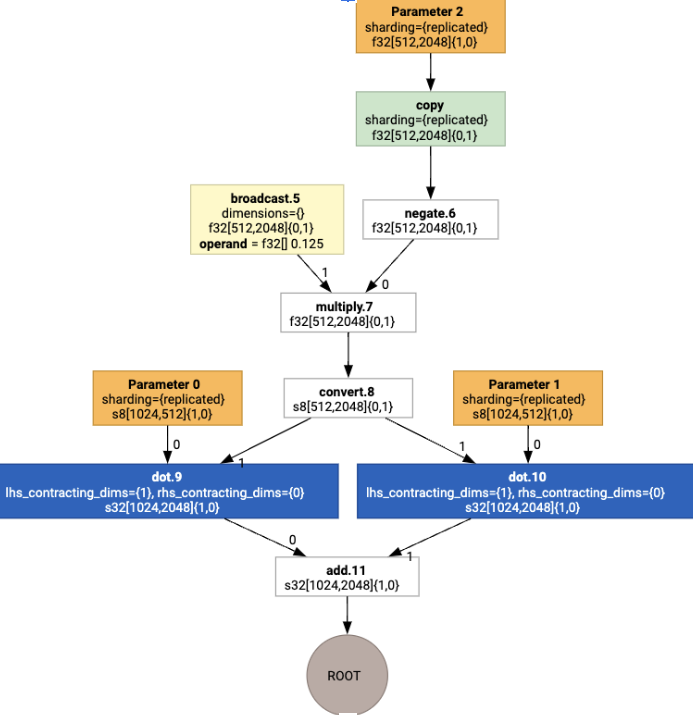
Dengan menjalankan penetapan tata letak, kita akan melihat tata letak dan operasi copy berikut yang dimasukkan:
Fusion
Fusi adalah pengoptimalan terpenting XLA, yang mengelompokkan beberapa operasi (misalnya, penambahan ke eksponensiasi ke matmul) ke dalam satu kernel. Karena banyak workload GPU cenderung terikat memori, fusi secara dramatis mempercepat eksekusi dengan menghindari penulisan tensor perantara ke HBM dan kemudian membacanya kembali, dan sebagai gantinya, meneruskannya di register atau memori bersama.
Petunjuk HLO gabungan diblokir bersama dalam satu komputasi gabungan, yang menetapkan invarian berikut:
Tidak ada penyimpanan perantara di dalam fusi yang diwujudkan dalam HBM (semuanya harus diteruskan melalui register atau memori bersama).
Fusi selalu dikompilasi ke tepat satu kernel GPU
Pengoptimalan HLO pada Contoh yang Sedang Berjalan
Kita dapat memeriksa HLO pasca-pengoptimalan menggunakan jax.jit(f).lower(a,
b).compile().as_text(), dan memverifikasi bahwa satu fusi telah dibuat:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
Perhatikan bahwa penggabungan backend_config memberi tahu kita bahwa Triton akan digunakan sebagai strategi pembuatan kode, dan menentukan pengelompokan yang dipilih.
Kita juga dapat memvisualisasikan modul yang dihasilkan:
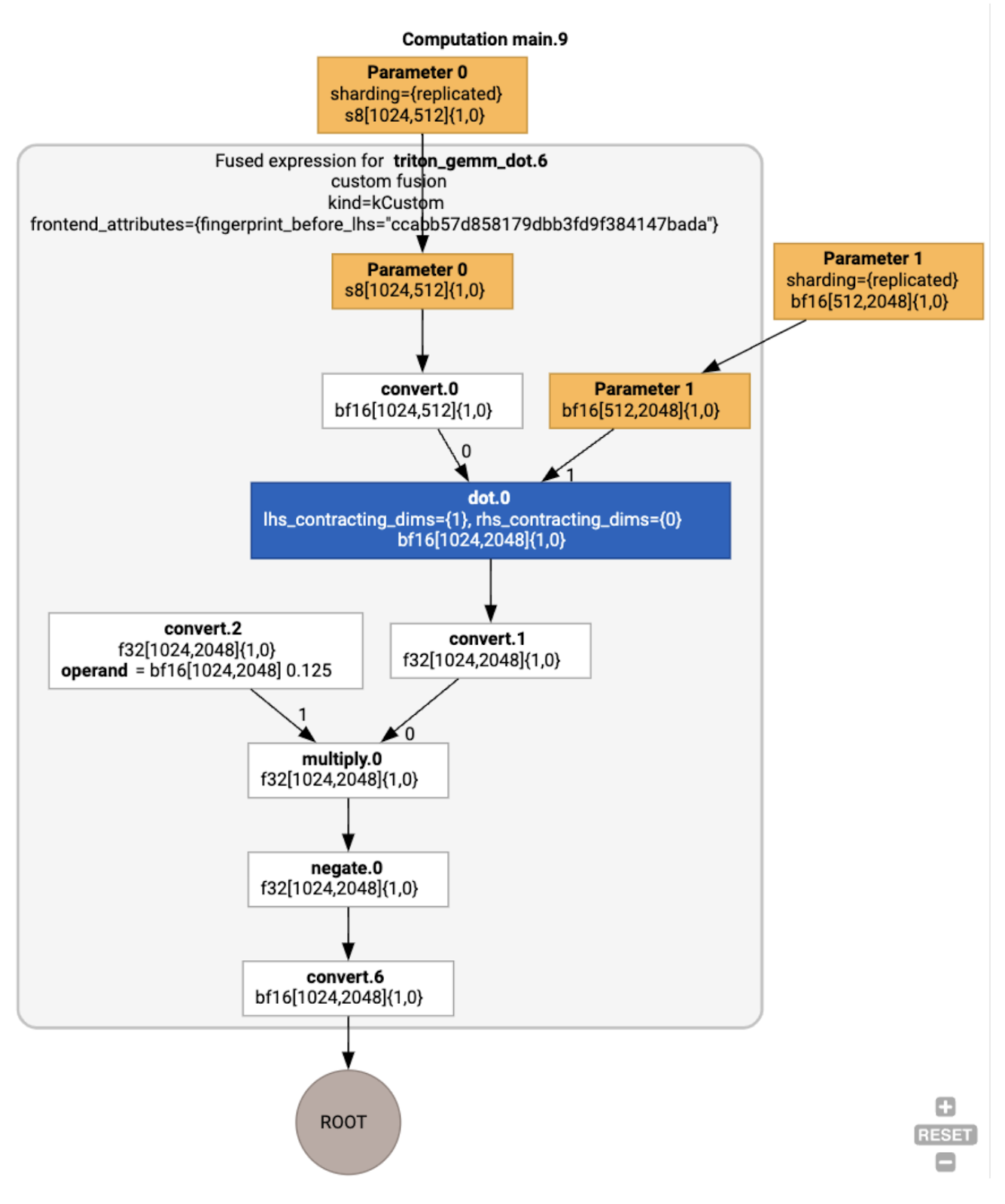
Penugasan dan Penjadwalan Buffer
Penerusan penetapan buffer mempertimbangkan informasi bentuk, dan bertujuan untuk menghasilkan alokasi buffer yang optimal untuk program, sehingga meminimalkan jumlah memori perantara yang digunakan. Tidak seperti eksekusi mode langsung (non-dikompilasi) TF atau PyTorch, di mana pengalokasi memori tidak mengetahui grafiknya terlebih dahulu, penjadwal XLA dapat “melihat ke masa depan” dan menghasilkan jadwal komputasi yang optimal.
Backend Compiler: Pemilihan Codegen dan Library
Untuk setiap instruksi HLO dalam komputasi, XLA memilih apakah akan menjalankannya menggunakan library yang ditautkan ke runtime, atau membuat kode PTX.
Pilihan Perpustakaan
Untuk banyak operasi umum, XLA:GPU menggunakan library berperforma tinggi dari NVIDIA, seperti cuBLAS, cuDNN, dan NCCL. Library ini memiliki keunggulan performa cepat yang terverifikasi, tetapi sering kali menghalangi peluang fusi yang kompleks.
Pembuatan kode langsung
Backend XLA:GPU menghasilkan LLVM IR berperforma tinggi secara langsung untuk sejumlah operasi (pengurangan, transposisi, dll.).
Pembuatan kode Triton
Untuk fusi yang lebih canggih yang mencakup perkalian matriks atau softmax, XLA:GPU menggunakan Triton sebagai lapisan pembuatan kode. Fusi HLO dikonversi menjadi TritonIR (dialek MLIR yang berfungsi sebagai input ke Triton), memilih parameter pengelompokan dan memanggil Triton untuk pembuatan PTX:
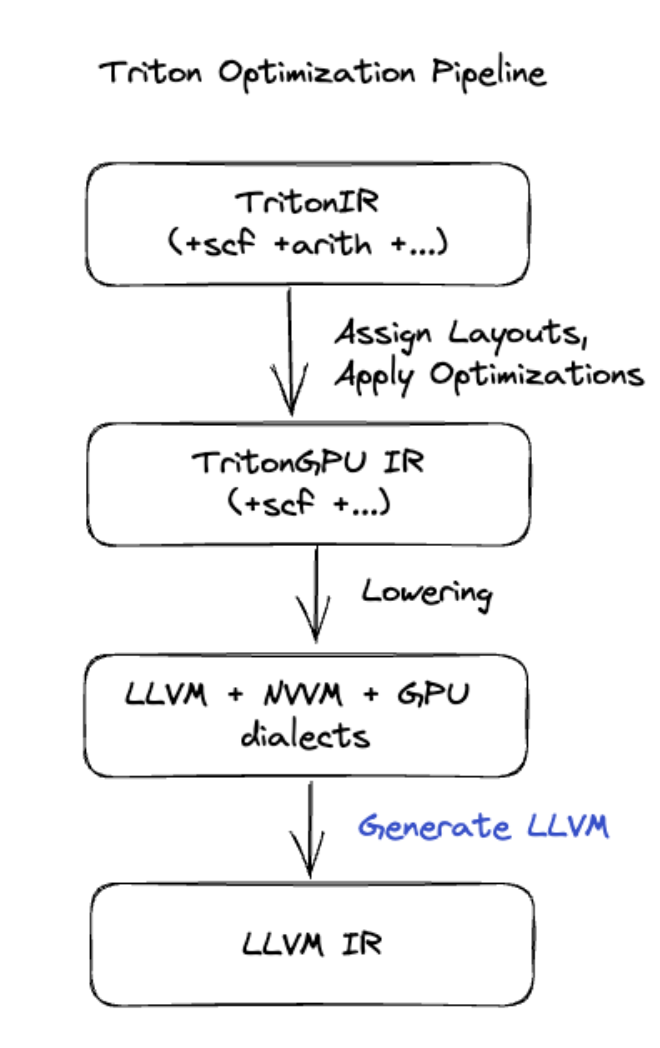
Kami telah mengamati bahwa kode yang dihasilkan berperforma sangat baik di Ampere, dengan performa mendekati batas atas dengan ukuran petak yang disetel dengan benar.
Runtime
XLA Runtime mengonversi urutan panggilan kernel CUDA dan pemanggilan library yang dihasilkan menjadi RuntimeIR (dialek MLIR di XLA), yang kemudian diekstrak grafiknya di CUDA. Grafik CUDA masih dalam proses, hanya beberapa node yang didukung saat ini. Setelah batas grafik CUDA diekstrak, RuntimeIR dikompilasi melalui LLVM ke CPU yang dapat dieksekusi, yang kemudian dapat disimpan atau ditransfer untuk kompilasi Ahead-Of-Time.