
소개
XLA는 선형 대수학을 위한 하드웨어 및 프레임워크 도메인별 컴파일러로, 동급 최고의 성능을 제공합니다. JAX, TF, Pytorch 등은 사용자 입력을 StableHLO('고급 작업': 더하기, 빼기, matmul 등 정적으로 모양이 지정된 약 100개의 명령어 집합) 작업 집합으로 변환하여 XLA를 사용하며, 여기에서 XLA는 다양한 백엔드에 최적화된 코드를 생성합니다.
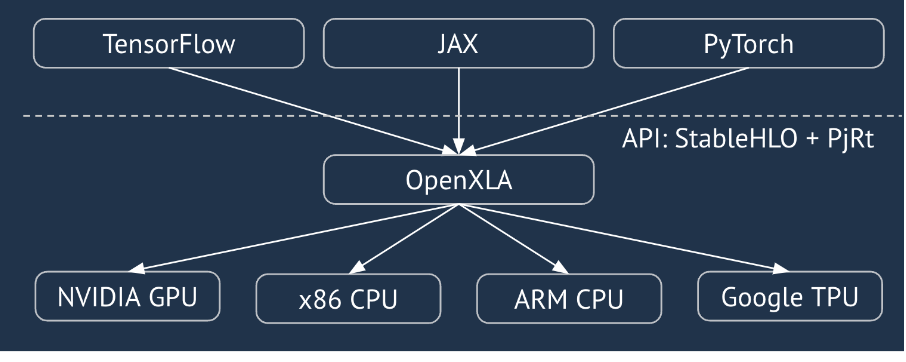
실행 중에 프레임워크는 PJRT 런타임 API를 호출합니다. 이 API를 통해 프레임워크는 '특정 기기에서 지정된 StableHLO 프로그램을 사용하여 지정된 버퍼를 채우기' 작업을 실행할 수 있습니다.
XLA:GPU 파이프라인
XLA:GPU는 '네이티브'(LLVM을 통한 PTX) 이미터와 TritonIR 이미터를 조합하여 고성능 GPU 커널을 생성합니다 (파란색은 서드 파티 구성요소를 나타냄).
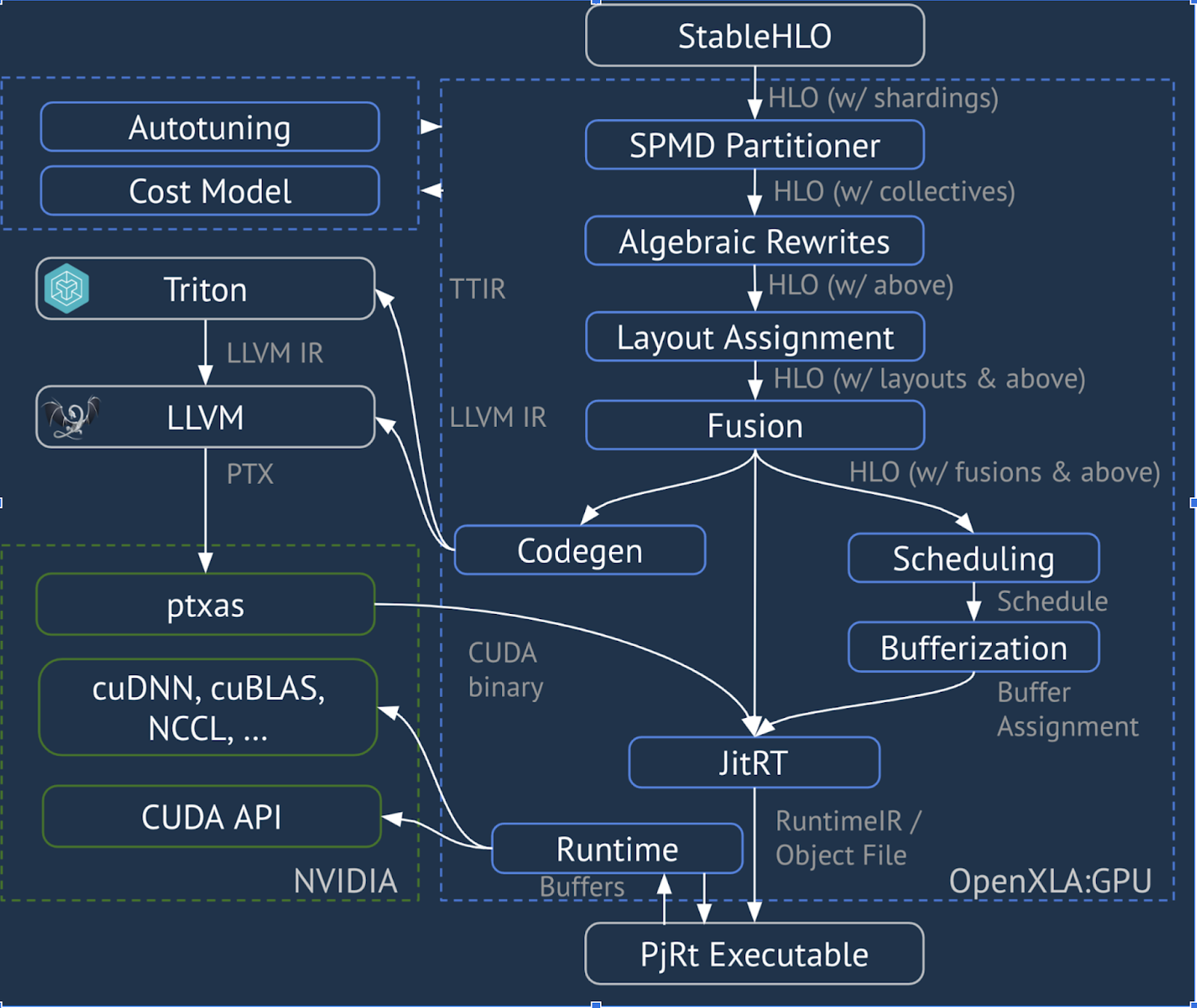
실행 예: JAX
파이프라인을 설명하기 위해 JAX에서 실행되는 예시부터 시작해 보겠습니다. 이 예시에서는 상수 곱셈 및 부정과 결합된 행렬 곱셈을 계산합니다.
def f(a, b):
return -((a @ b) * 0.125)
함수에서 생성된 HLO를 검사할 수 있습니다.
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
그러면 다음과 같은 결과가 생성됩니다.
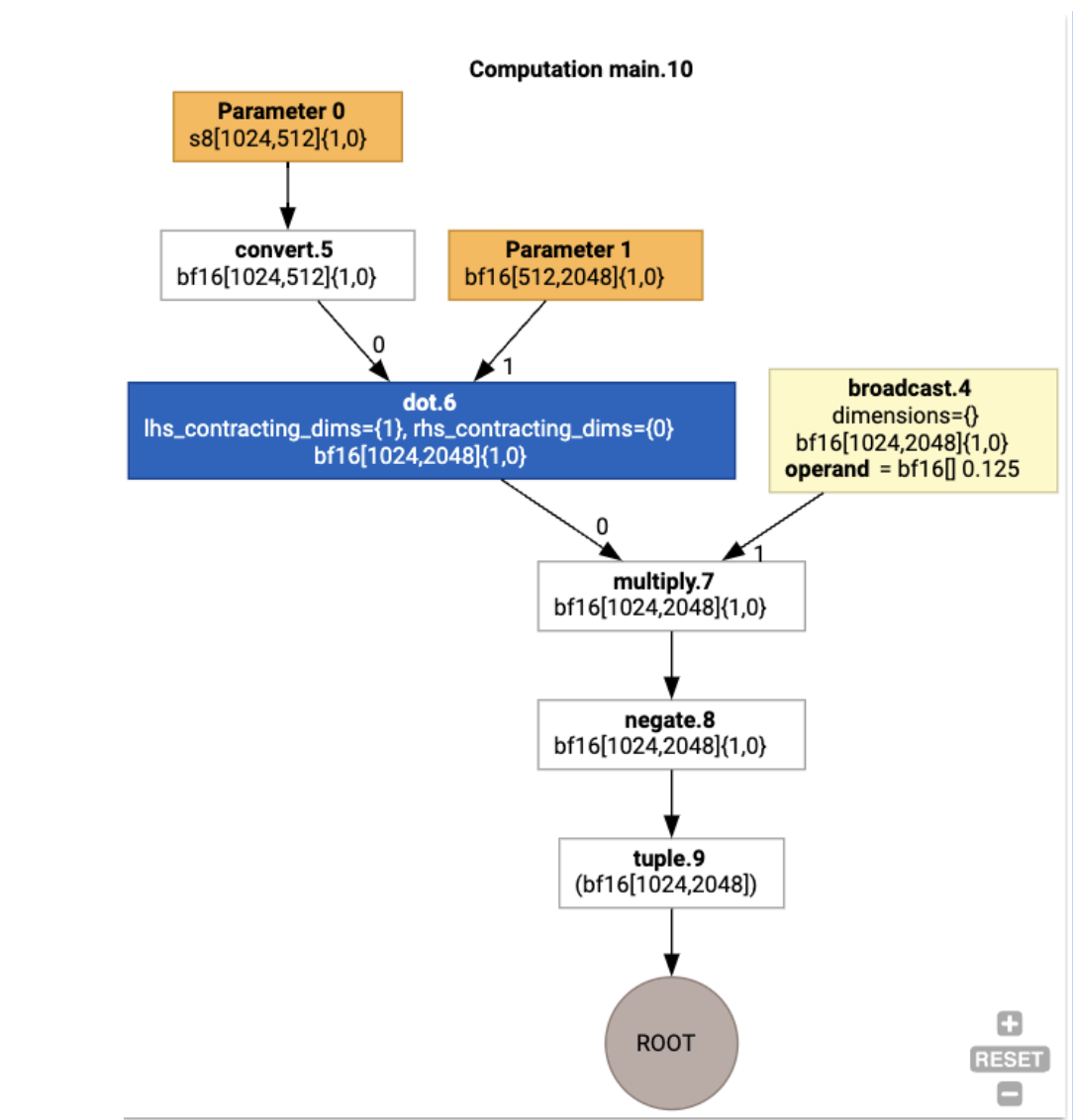
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
jax.xla_computation(f)(a, b).as_hlo_dot_graph()를 사용하여 입력 HLO 계산도 시각화할 수 있습니다.
HLO 최적화: 주요 구성요소
HLO에서 HLO->HLO 재작성으로 여러 가지 주목할 만한 최적화 패스가 발생합니다.
SPMD 파티셔너
GSPMD: 일반적이고 확장 가능한 ML 계산 그래프 병렬화에 설명된 XLA SPMD 파티셔너는 샤딩 주석이 있는 HLO (예: jax.pjit로 생성됨)를 사용하고 여러 호스트와 기기에서 실행할 수 있는 샤딩된 HLO를 생성합니다.
파티셔닝 외에도 SPMD는 최적의 실행 일정에 맞게 HLO를 최적화하여 노드 간 계산과 통신을 오버랩하려고 시도합니다.
예
두 기기에 샤딩된 간단한 JAX 프로그램부터 시작해 보세요.
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
시각화하면 샤딩 주석이 맞춤 호출로 표시됩니다.
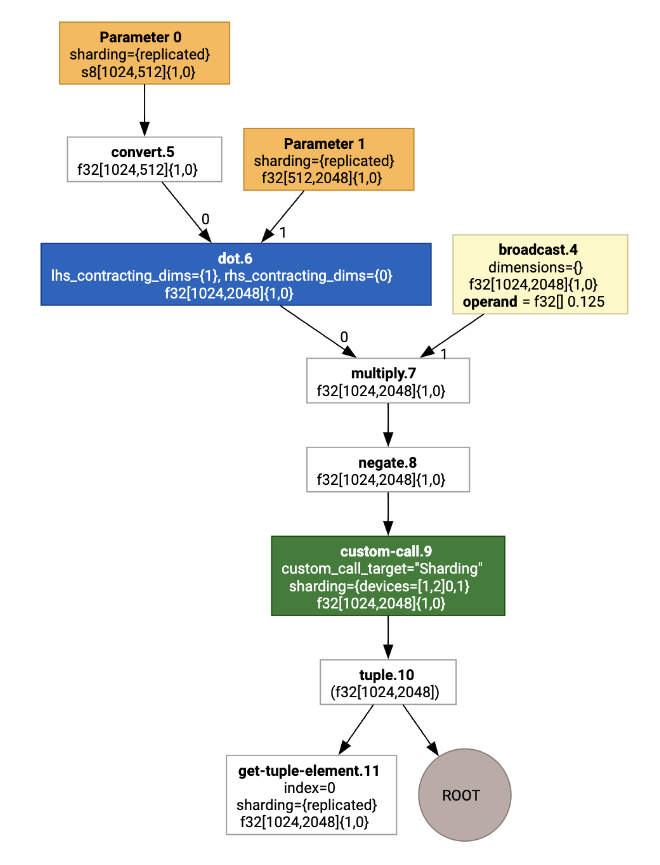
SPMD 파티셔너가 맞춤 호출을 확장하는 방법을 확인하려면 최적화 후 HLO를 살펴보면 됩니다.
print(f.lower(np.ones((8, 8)).compile().as_text())
그러면 집합이 있는 HLO가 생성됩니다.
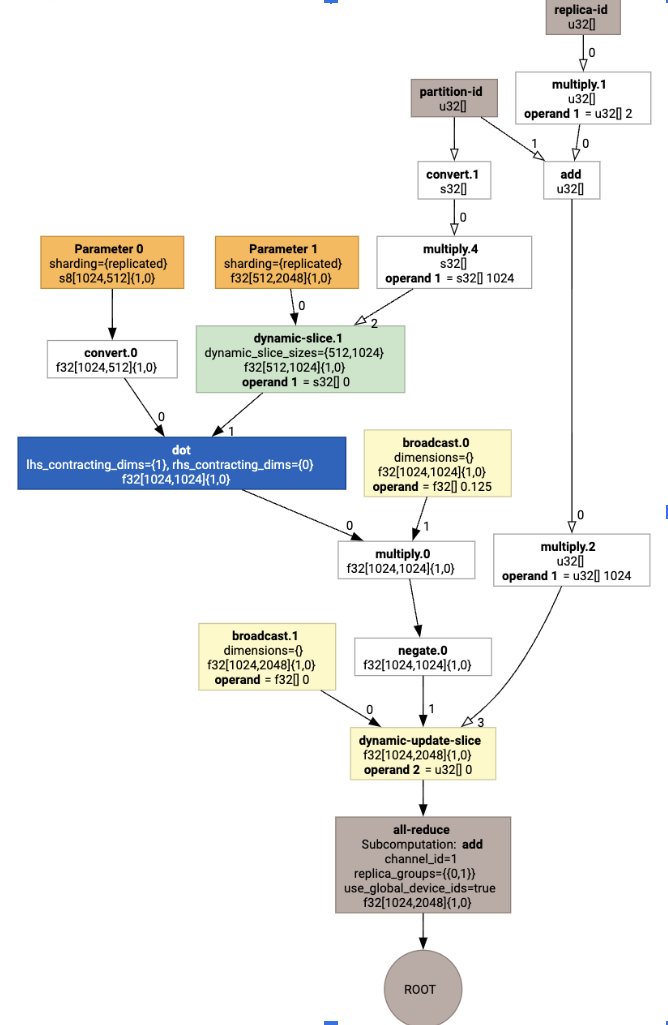
레이아웃 할당
HLO는 논리적 모양과 물리적 레이아웃 (텐서가 메모리에 배치되는 방식)을 분리합니다. 예를 들어 행렬 f32[32, 64]는 행 우선 순서 또는 열 우선 순서로 나타낼 수 있으며, 각각 {1,0} 또는 {0,1}로 나타냅니다.
일반적으로 레이아웃은 메모리의 실제 레이아웃을 나타내는 차원 수에 대한 순열을 보여주는 모양의 일부로 표현됩니다.
HLO에 있는 각 작업에 대해 레이아웃 할당 패스는 최적의 레이아웃을 선택합니다 (예: Ampere의 컨볼루션의 경우 NHWC). 예를 들어 int8xint8->int32 matmul 작업은 계산의 RHS에 {0,1} 레이아웃을 선호합니다. 마찬가지로 사용자가 삽입한 '트랜스포즈'는 무시되고 레이아웃 변경으로 인코딩됩니다.
그런 다음 레이아웃이 그래프를 통해 전파되고 레이아웃 간의 충돌이나 그래프 엔드포인트의 충돌은 물리적 전치를 실행하는 copy 작업으로 구체화됩니다. 예를 들어 그래프에서 시작하여
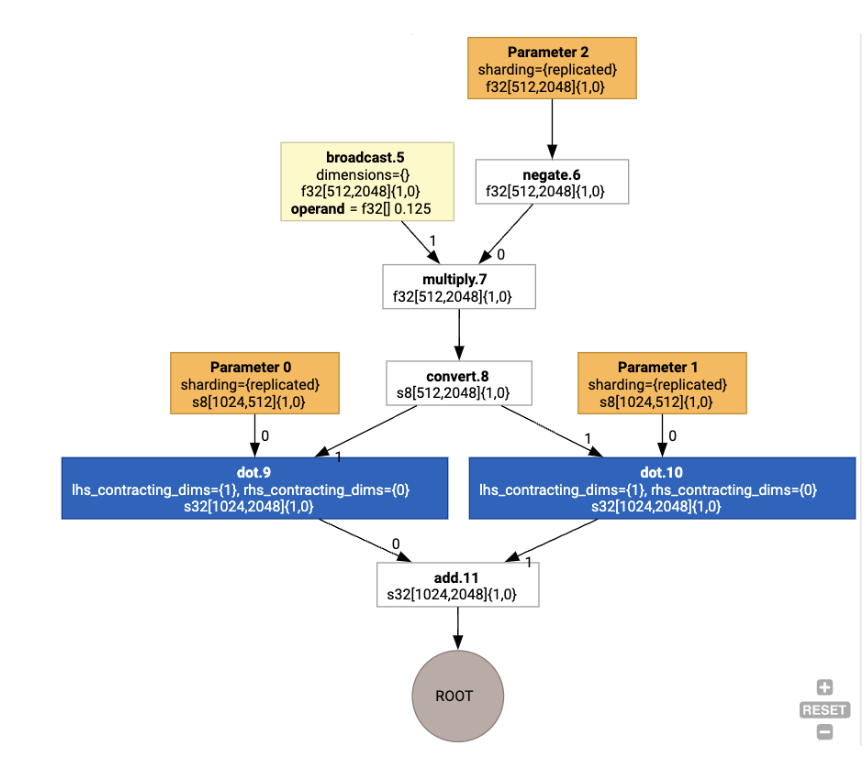
레이아웃 할당을 실행하면 다음 레이아웃과 copy 작업이 삽입됩니다.
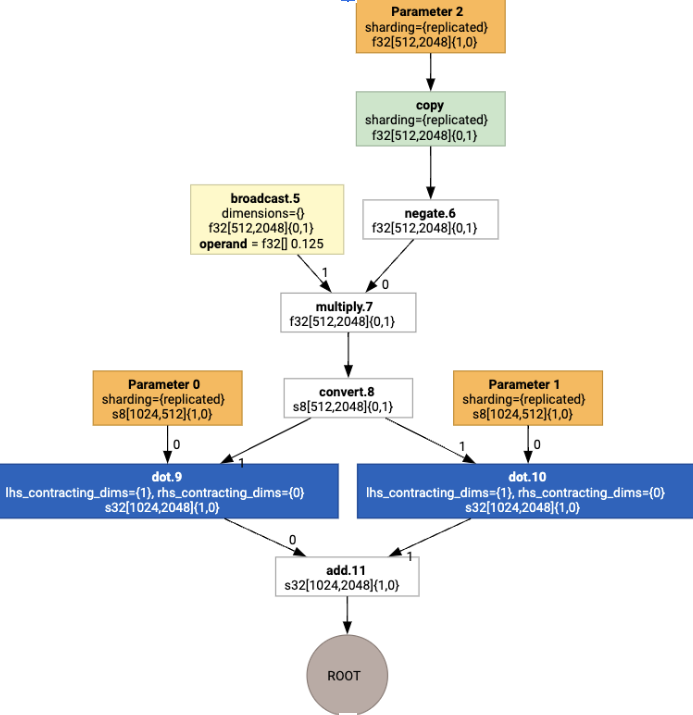
Fusion
융합은 XLA의 가장 중요한 단일 최적화로, 여러 작업 (예: 덧셈에서 지수화, 행렬 곱셈)을 단일 커널로 그룹화합니다. 많은 GPU 워크로드는 메모리 바운드인 경향이 있으므로 융합은 중간 텐서를 HBM에 쓴 다음 다시 읽는 것을 방지하고 대신 레지스터나 공유 메모리에서 전달하여 실행 속도를 크게 높입니다.
융합된 HLO 명령어는 단일 융합 계산에서 함께 차단되어 다음 불변성을 설정합니다.
융합 내부의 중간 스토리지는 HBM에서 구체화되지 않습니다 (레지스터나 공유 메모리를 통해 모두 전달되어야 함).
퓨전은 항상 정확히 하나의 GPU 커널로 컴파일됩니다.
실행 예시의 HLO 최적화
jax.jit(f).lower(a,
b).compile().as_text()를 사용하여 최적화 후 HLO를 검사하고 단일 융합이 생성되었는지 확인할 수 있습니다.
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
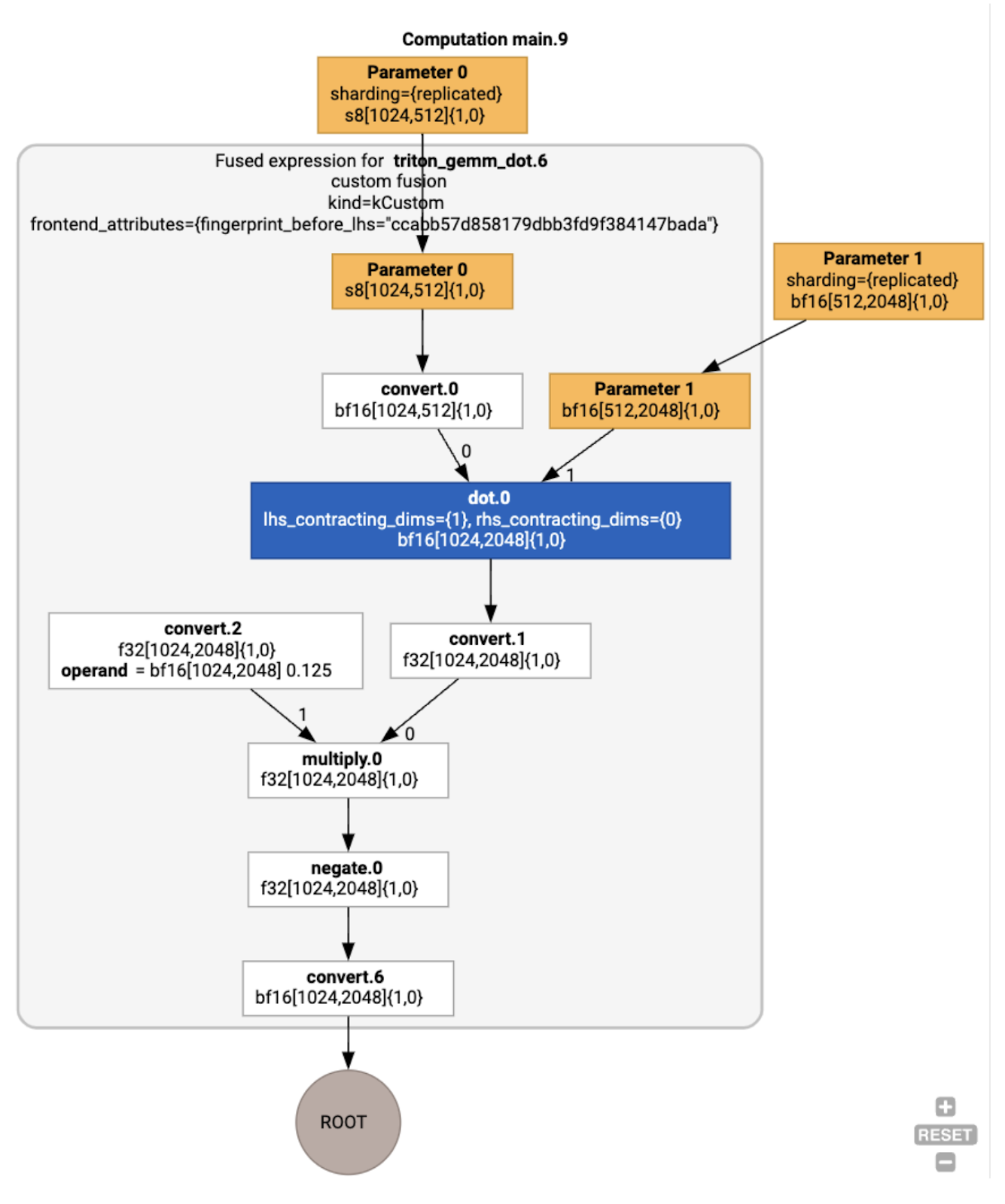
융합 backend_config는 Triton이 코드 생성 전략으로 사용되고 선택한 타일링을 지정한다고 알려줍니다.
결과 모듈을 시각화할 수도 있습니다.
버퍼 할당 및 예약
버퍼 할당 패스는 모양 정보를 고려하고 프로그램에 최적의 버퍼 할당을 생성하여 소비되는 중간 메모리 양을 최소화하는 것을 목표로 합니다. 메모리 할당자가 그래프를 미리 알지 못하는 TF 또는 PyTorch 즉시 모드 (컴파일되지 않음) 실행과 달리 XLA 스케줄러는 '미래를 내다보고' 최적의 연산 일정을 생성할 수 있습니다.
컴파일러 백엔드: 코드 생성 및 라이브러리 선택
XLA는 계산의 모든 HLO 명령어에 대해 런타임에 연결된 라이브러리를 사용하여 실행할지 아니면 PTX로 코드 생성할지 선택합니다.
라이브러리 선택
많은 일반적인 작업의 경우 XLA:GPU는 cuBLAS, cuDNN, NCCL과 같은 NVIDIA의 고성능 라이브러리를 사용합니다. 라이브러리는 검증된 빠른 성능이라는 장점이 있지만 복잡한 융합 기회를 막는 경우가 많습니다.
직접 코드 생성
XLA:GPU 백엔드는 여러 작업 (축소, 전치 등)에 대해 고성능 LLVM IR을 직접 생성합니다.
Triton 코드 생성
행렬 곱셈 또는 소프트맥스를 포함하는 고급 융합의 경우 XLA:GPU는 Triton을 코드 생성 레이어로 사용합니다. HLO 융합은 TritonIR (Triton의 입력으로 사용되는 MLIR 다이얼렉트)로 변환되고, 타일링 매개변수를 선택하고, PTX 생성을 위해 Triton을 호출합니다.
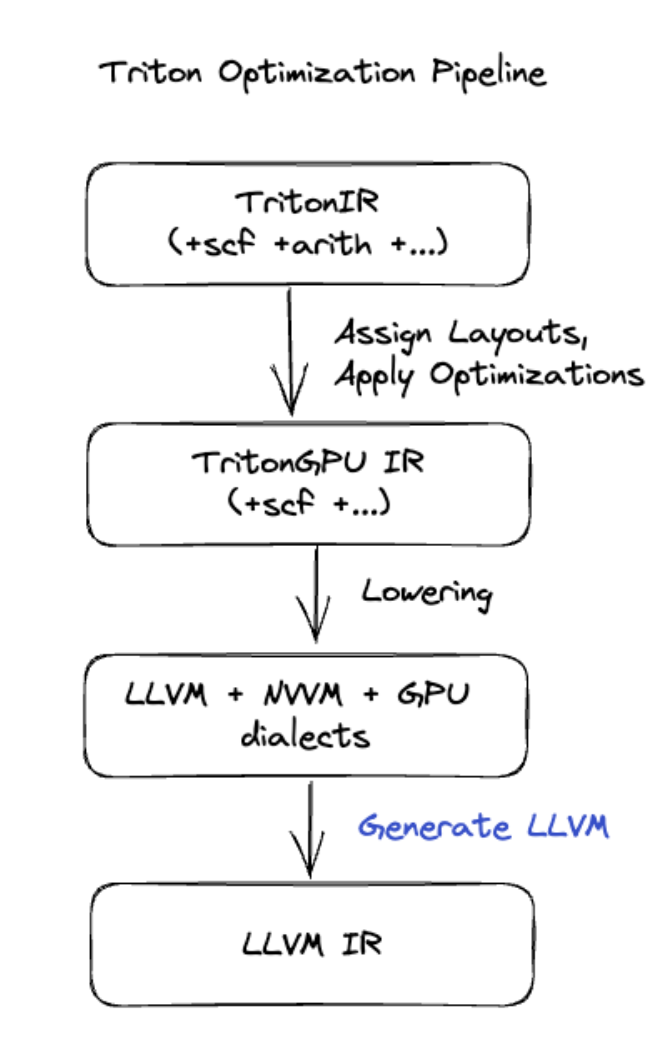
결과 코드는 Ampere에서 매우 우수한 성능을 보였으며, 타일 크기를 적절히 조정하면 최대 성능에 가까운 성능을 보였습니다.
런타임
XLA 런타임은 결과 CUDA 커널 호출 및 라이브러리 호출 시퀀스를 RuntimeIR (XLA의 MLIR 다이얼렉트)로 변환하며, 여기에서 CUDA 그래프 추출이 실행됩니다. CUDA 그래프는 아직 개발 중이며 현재 일부 노드만 지원됩니다. CUDA 그래프 경계가 추출되면 RuntimeIR은 LLVM을 통해 CPU 실행 파일로 컴파일되며, 이는 사전 컴파일을 위해 저장하거나 전송할 수 있습니다.