
Wprowadzenie
XLA to kompilator specyficzny dla sprzętu i platformy, który służy do algebry liniowej i zapewnia najlepszą w swojej klasie wydajność. JAX, TF, PyTorch i inne platformy korzystają z XLA, przekształcając dane wejściowe użytkownika w zestaw operacji StableHLO („operacja wysokiego poziomu”: zestaw około 100 instrukcji o statycznym kształcie, takich jak dodawanie, odejmowanie, mnożenie macierzy itp.), z którego XLA generuje zoptymalizowany kod dla różnych backendów:
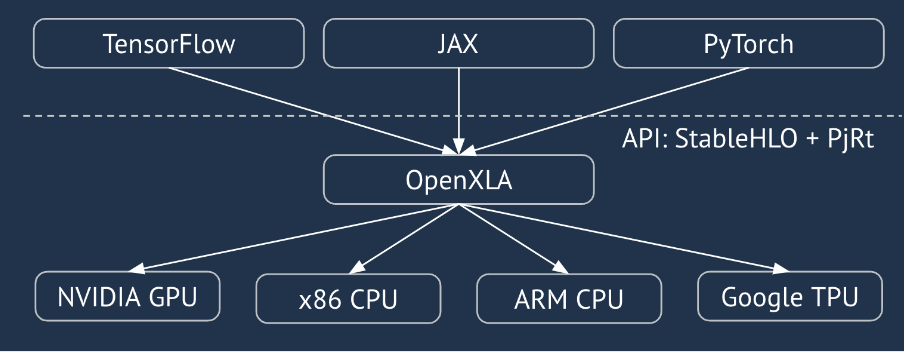
Podczas wykonywania platformy wywołują interfejs API środowiska wykonawczego PJRT, który umożliwia im wykonanie operacji „wypełnij określone bufory za pomocą danego programu StableHLO na konkretnym urządzeniu”.
XLA:potok GPU
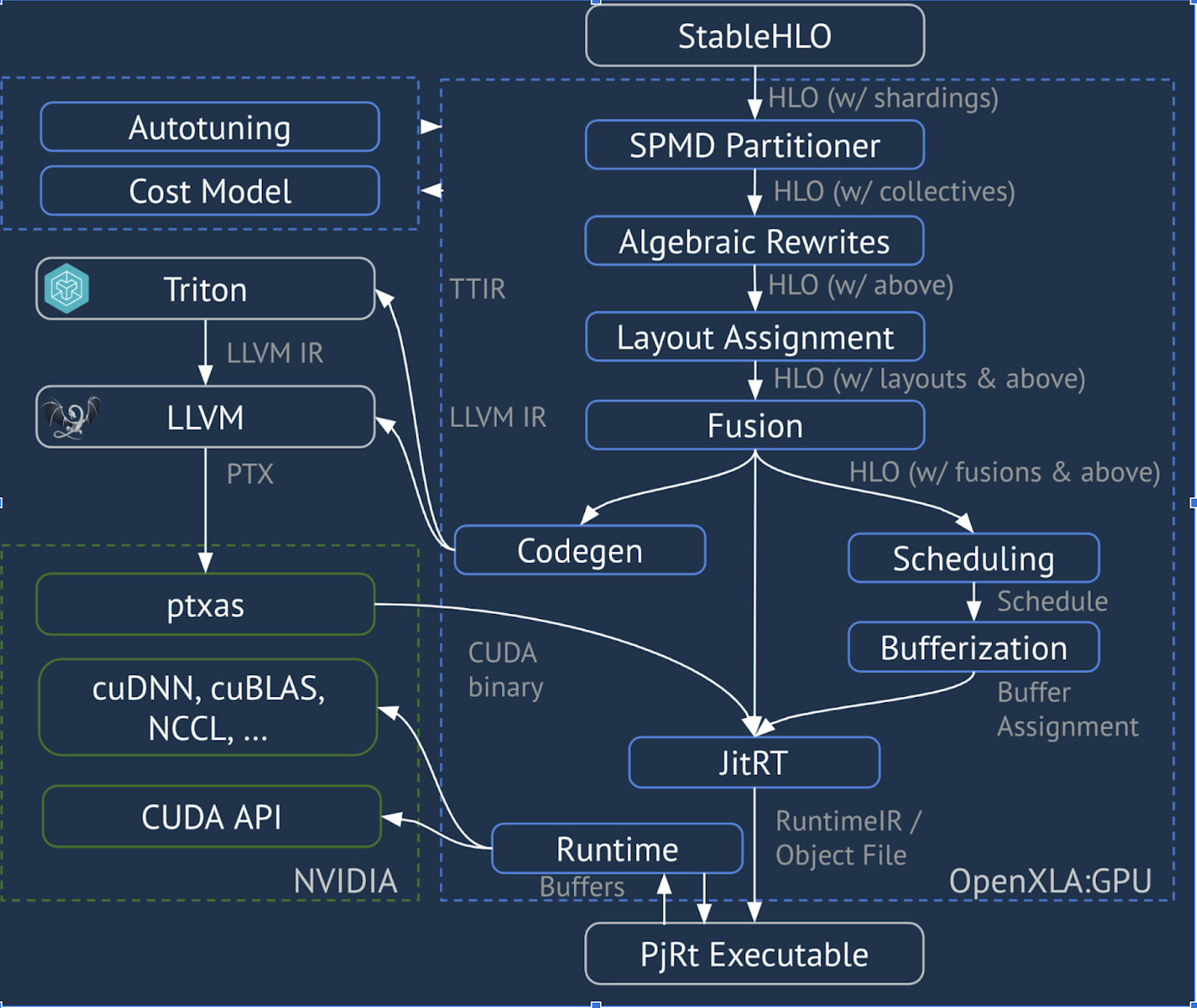
XLA:GPU używa kombinacji emiterów „natywnych” (PTX, za pomocą LLVM) i emiterów TritonIR do generowania wydajnych jąder GPU (kolor niebieski oznacza komponenty innych firm):
Przykład działania: JAX
Aby zilustrować potok, zacznijmy od przykładu w JAX, który oblicza mnożenie macierzy połączone z mnożeniem przez stałą i negacją:
def f(a, b):
return -((a @ b) * 0.125)
Możemy sprawdzić HLO wygenerowany przez funkcję:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
który generuje:
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
Obliczenia HLO można też wizualizować za pomocą polecenia jax.xla_computation(f)(a, b).as_hlo_dot_graph():
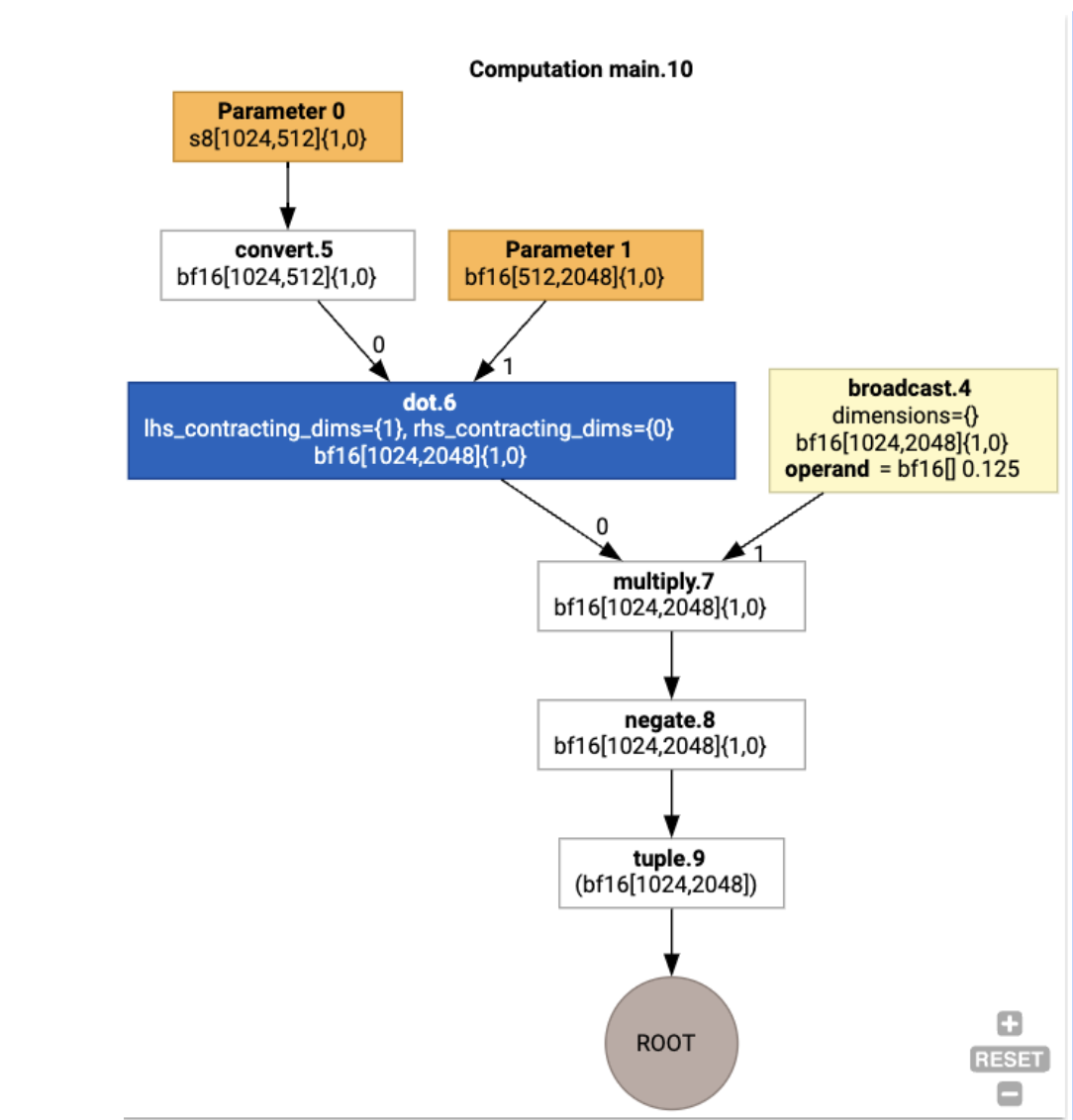
Optymalizacje w HLO: kluczowe komponenty
Na poziomie HLO zachodzi wiele istotnych optymalizacji w postaci przekształceń HLO –> HLO.
SPMD Partitioner
Partycjoner XLA SPMD, opisany w artykule GSPMD: General and Scalable Parallelization for MLComputation Graphs, przetwarza HLO z adnotacjami dotyczącymi dzielenia (generowanymi np. przez jax.pjit) i tworzy podzielony HLO, który można następnie uruchomić na wielu hostach i urządzeniach.
Oprócz podziału SPMD próbuje zoptymalizować HLO pod kątem optymalnego harmonogramu wykonania, nakładających się obliczeń oraz komunikacji między węzłami.
Przykład
Zacznij od prostego programu JAX podzielonego na 2 urządzenia:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
Wizualizacja adnotacji dotyczących dzielenia na fragmenty jest przedstawiona jako wywołania niestandardowe:
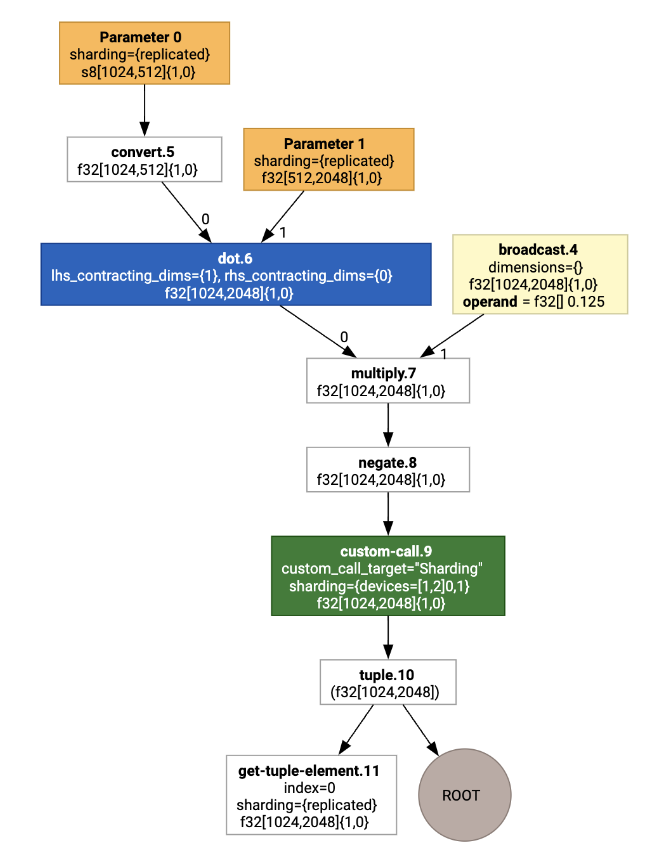
Aby sprawdzić, jak partycjoner SPMD rozwija wywołanie niestandardowe, możemy przyjrzeć się HLO po optymalizacjach:
print(f.lower(np.ones((8, 8)).compile().as_text())
Spowoduje to wygenerowanie HLO z kolektywem:
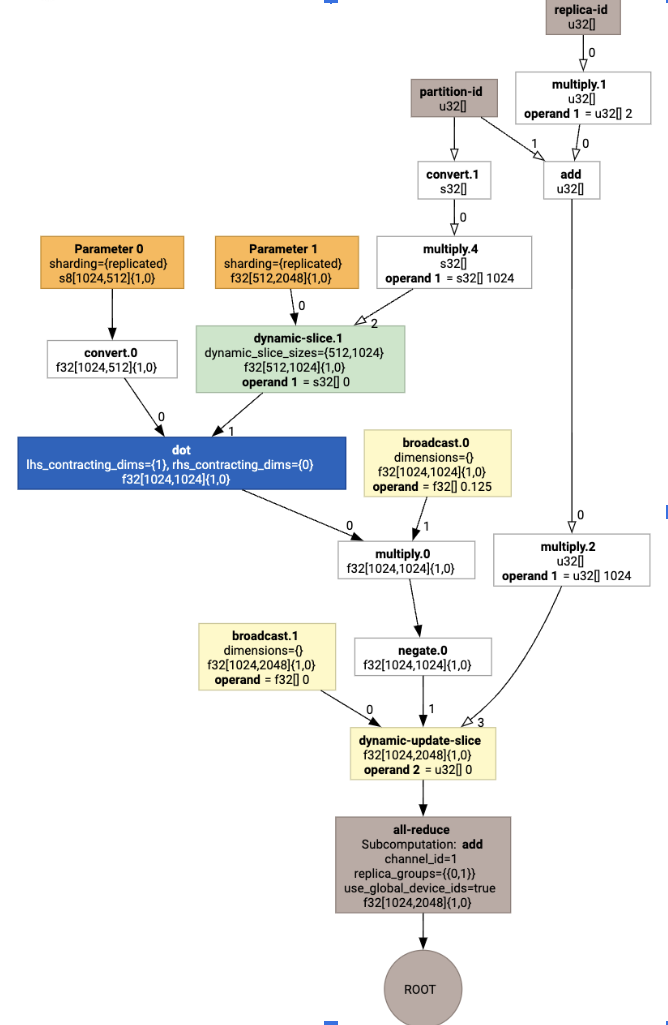
Przypisanie układu
HLO oddziela kształt logiczny od układu fizycznego (sposobu rozmieszczenia tensorów w pamięci). Na przykład macierz f32[32, 64] może być reprezentowana w kolejności wierszowej lub kolumnowej, odpowiednio jako {1,0} lub {0,1}.
Ogólnie rzecz biorąc, układ jest reprezentowany jako część kształtu, która pokazuje permutację liczby wymiarów wskazujących fizyczny układ w pamięci.
W przypadku każdej operacji w HLO etap przypisywania układu wybiera optymalny układ (np. NHWC w przypadku konwolucji na architekturze Ampere). Na przykład operacja int8xint8->int32matmul preferuje układ {0,1} po prawej stronie obliczeń. Podobnie „transpozycje” wstawione przez użytkownika są ignorowane i kodowane jako zmiana układu.
Układy są następnie propagowane w grafie, a konflikty między układami lub na końcach grafu są realizowane jako operacje copy, które wykonują fizyczną transpozycję. Na przykład zaczynając od wykresu
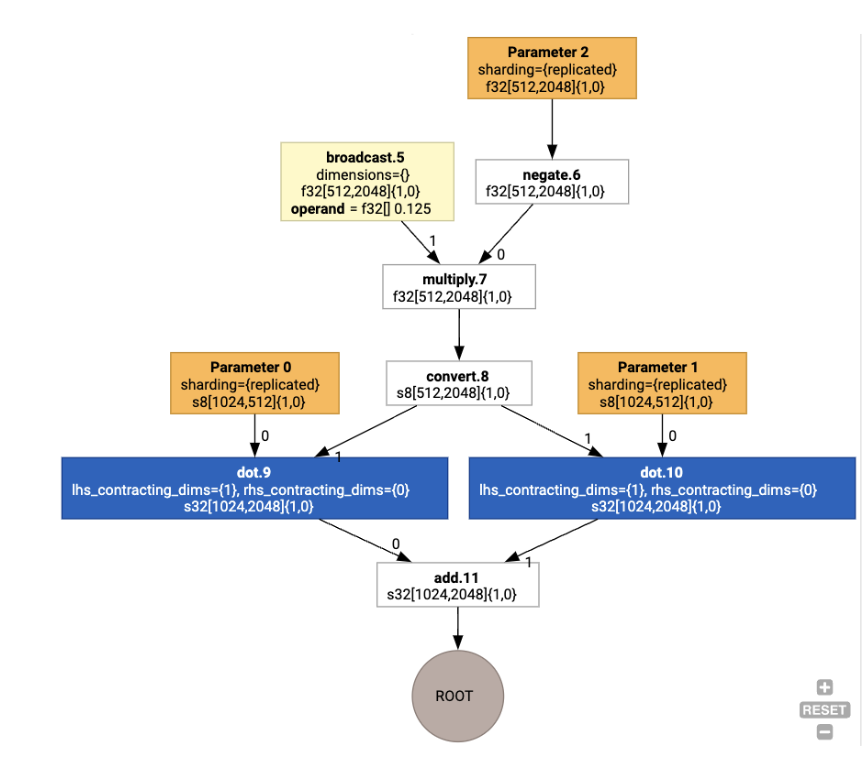
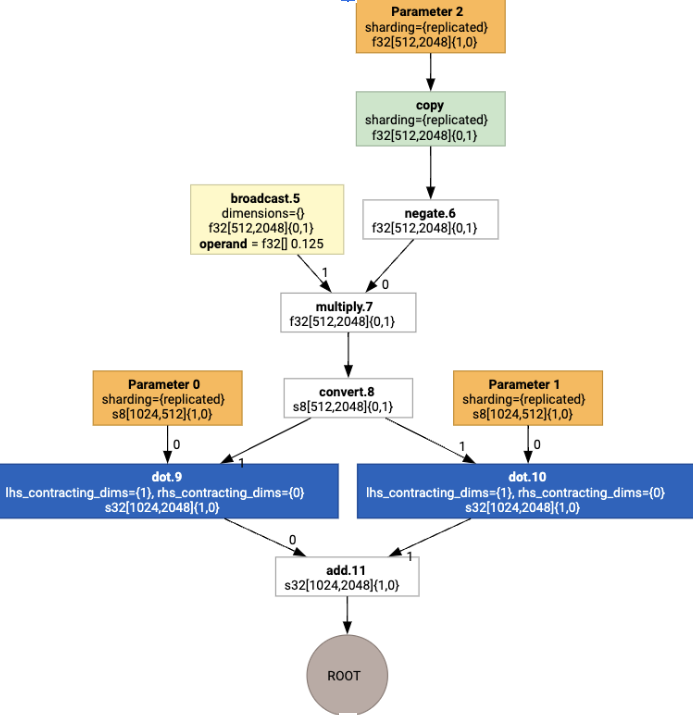
Po uruchomieniu przypisania układu widzimy te układy i operację copy:
Fusion
Fuzja to najważniejsza optymalizacja XLA, która łączy wiele operacji (np. dodawanie, potęgowanie i mnożenie macierzy) w jeden kernel. Wiele zadań GPU jest ograniczonych przez pamięć, więc fuzja znacznie przyspiesza ich wykonywanie, ponieważ nie trzeba zapisywać tensorów pośrednich w pamięci HBM, a potem ich odczytywać. Zamiast tego są one przekazywane w rejestrach lub pamięci współdzielonej.
Scalone instrukcje HLO są blokowane razem w ramach jednego obliczenia scalania, co zapewnia następujące niezmienniki:
W pamięci HBM nie jest przechowywana żadna pamięć pośrednia w ramach fuzji (wszystkie dane muszą być przekazywane przez rejestry lub pamięć współdzieloną).
Fuzja jest zawsze kompilowana do dokładnie jednego jądra GPU.
Optymalizacje HLO na przykładzie działania
Możemy sprawdzić HLO po optymalizacji za pomocą jax.jit(f).lower(a,
b).compile().as_text() i upewnić się, że wygenerowano pojedyncze scalenie:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
Znak backend_config oznacza, że Triton będzie używany jako strategia generowania kodu, i określa wybrane kafelkowanie.
Możemy też wizualizować wynikowy moduł:
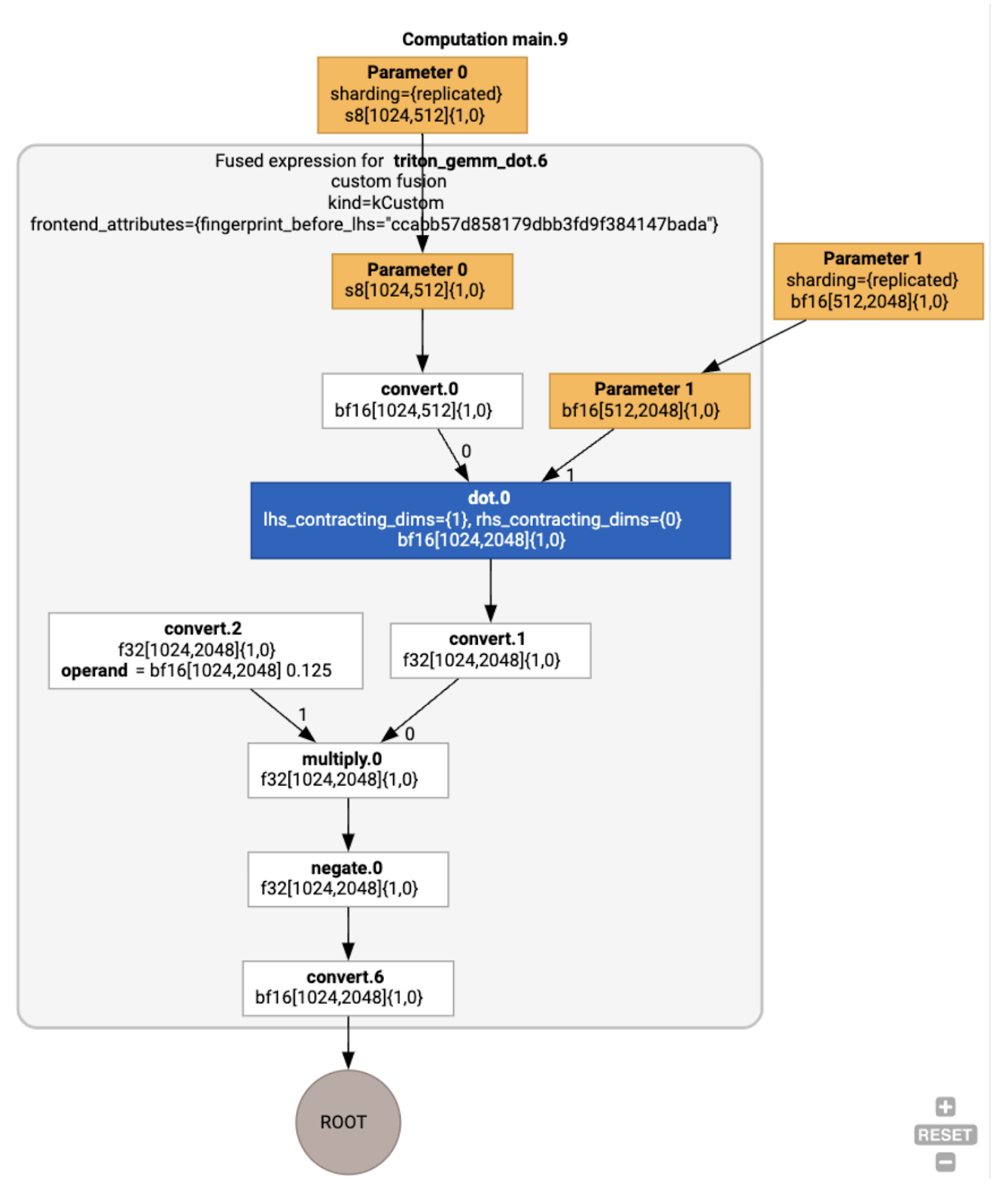
Przydzielanie i planowanie bufora
Etap przypisywania bufora uwzględnia informacje o kształcie i ma na celu optymalne przydzielenie bufora do programu, minimalizując ilość zużywanej pamięci pośredniej. W przeciwieństwie do trybu natychmiastowego (niekompilowanego) wykonywania w TF lub PyTorch, w którym alokator pamięci nie zna z wyprzedzeniem grafu, harmonogram XLA może „spojrzeć w przyszłość” i utworzyć optymalny harmonogram obliczeń.
Backend kompilatora: generowanie kodu i wybór biblioteki
W przypadku każdej instrukcji HLO w obliczeniach XLA decyduje, czy ma ją wykonać za pomocą biblioteki połączonej z środowiskiem wykonawczym, czy wygenerować dla niej kod PTX.
Wybór biblioteki
W przypadku wielu typowych operacji XLA:GPU korzysta z bibliotek NVIDIA o wysokiej wydajności, takich jak cuBLAS, cuDNN i NCCL. Biblioteki mają tę zaletę, że zapewniają zweryfikowaną, szybką wydajność, ale często wykluczają złożone możliwości fuzji.
Bezpośrednie generowanie kodu
Backend XLA:GPU generuje bezpośrednio kod LLVM IR o wysokiej wydajności dla wielu operacji (redukcje, transpozycje itp.).
Generowanie kodu w Tritonie
W przypadku bardziej zaawansowanych fuzji, które obejmują mnożenie macierzy lub funkcję softmax, XLA:GPU używa Triton jako warstwy generowania kodu. HLO Fusions są przekształcane w TritonIR (dialekt MLIR, który służy jako dane wejściowe dla Tritona), wybiera parametry kafelkowania i wywołuje Tritona w celu wygenerowania PTX:
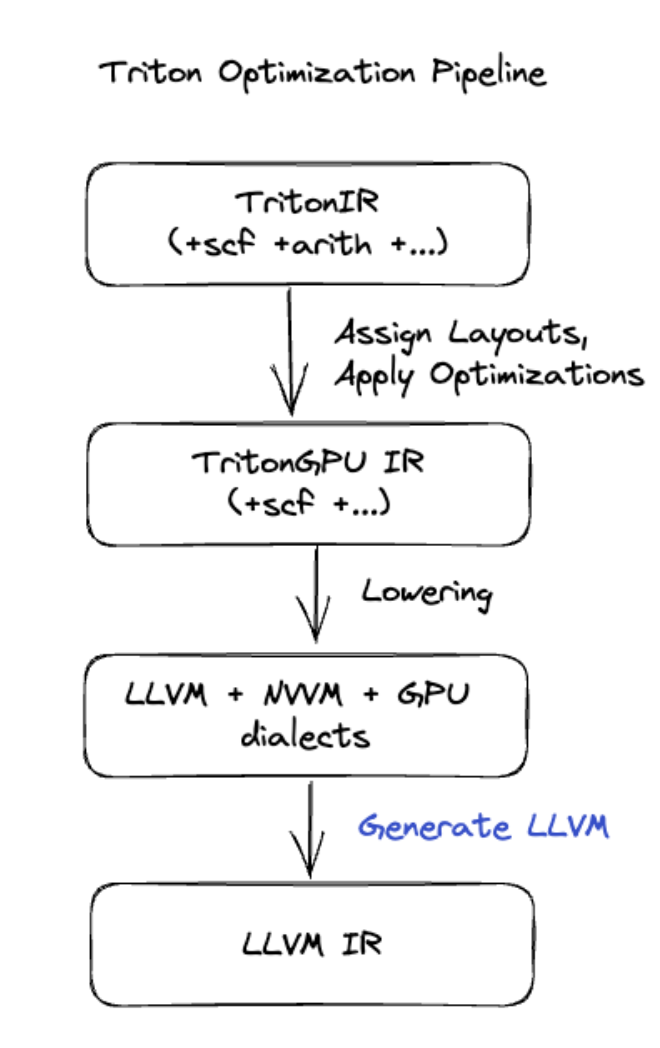
Zaobserwowaliśmy, że uzyskany kod działa bardzo dobrze na architekturze Ampere, osiągając wydajność zbliżoną do maksymalnej przy odpowiednio dostosowanych rozmiarach kafelków.
Środowisko wykonawcze
Środowisko wykonawcze XLA przekształca wynikową sekwencję wywołań jądra CUDA i wywołań biblioteki w RuntimeIR (dialekt MLIR w XLA), na którym przeprowadzane jest wyodrębnianie wykresu CUDA. Wykres CUDA jest w trakcie opracowywania. Obecnie obsługiwane są tylko niektóre węzły. Po wyodrębnieniu granic grafu CUDA środowisko RuntimeIR jest kompilowane za pomocą LLVM do pliku wykonywalnego na procesorze, który można następnie przechowywać lub przesyłać w celu kompilacji z wyprzedzeniem.