
Introdução
O XLA é um compilador específico de domínio de hardware e framework para álgebra linear, oferecendo o melhor desempenho da categoria. O JAX, o TF, o Pytorch e outros usam o XLA convertendo a entrada do usuário em um conjunto de operações StableHLO ("operação de alto nível": um conjunto de aproximadamente 100 instruções com formato estático, como adição, subtração, multiplicação de matrizes etc.), com base no qual o XLA produz código otimizado para vários backends:
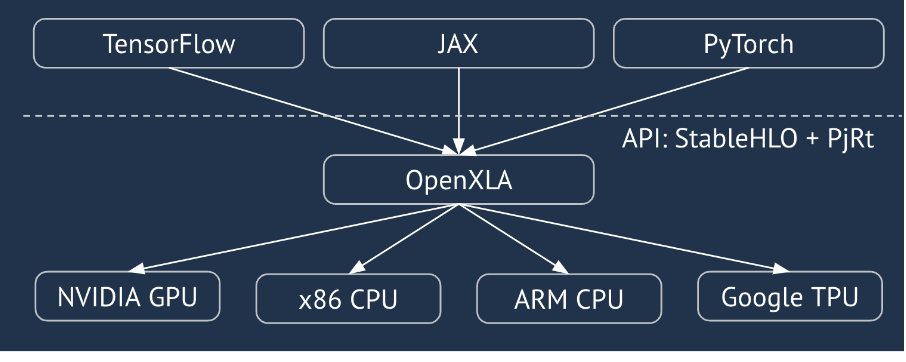
Durante a execução, os frameworks invocam a API PJRT runtime, que permite que eles realizem a operação "preencher os buffers especificados usando um determinado programa StableHLO em um dispositivo específico".
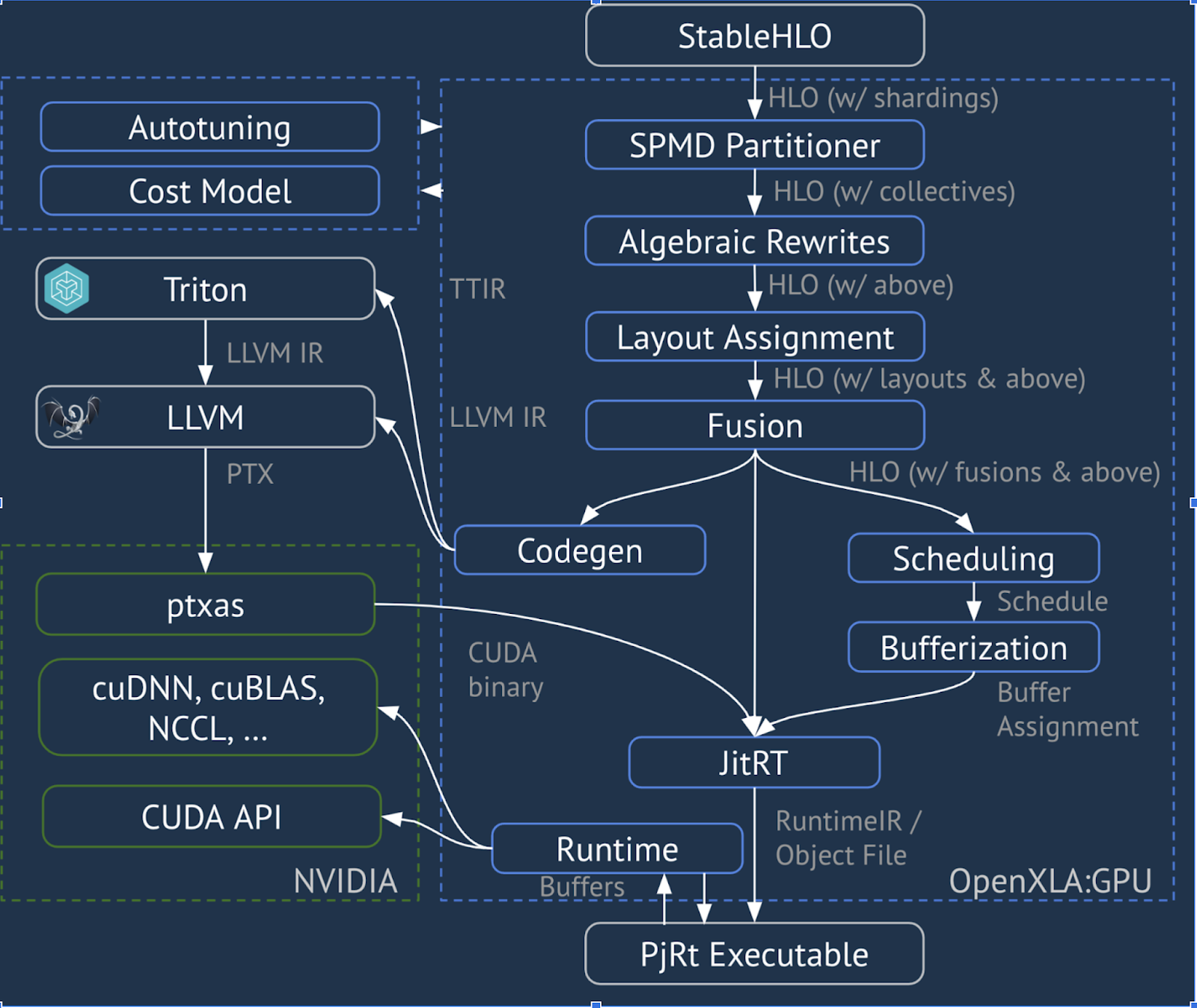
Pipeline XLA:GPU
O XLA:GPU usa uma combinação de emissores "nativos" (PTX, via LLVM) e emissores TritonIR para gerar kernels de GPU de alta performance (a cor azul indica componentes 3P):
Exemplo de execução: JAX
Para ilustrar o pipeline, vamos começar com um exemplo em execução no JAX, que calcula uma multiplicação de matrizes combinada com a multiplicação por uma constante e negação:
def f(a, b):
return -((a @ b) * 0.125)
Podemos inspecionar o HLO gerado pela função:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
que gera:
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
Também podemos visualizar a computação HLO de entrada usando jax.xla_computation(f)(a, b).as_hlo_dot_graph():
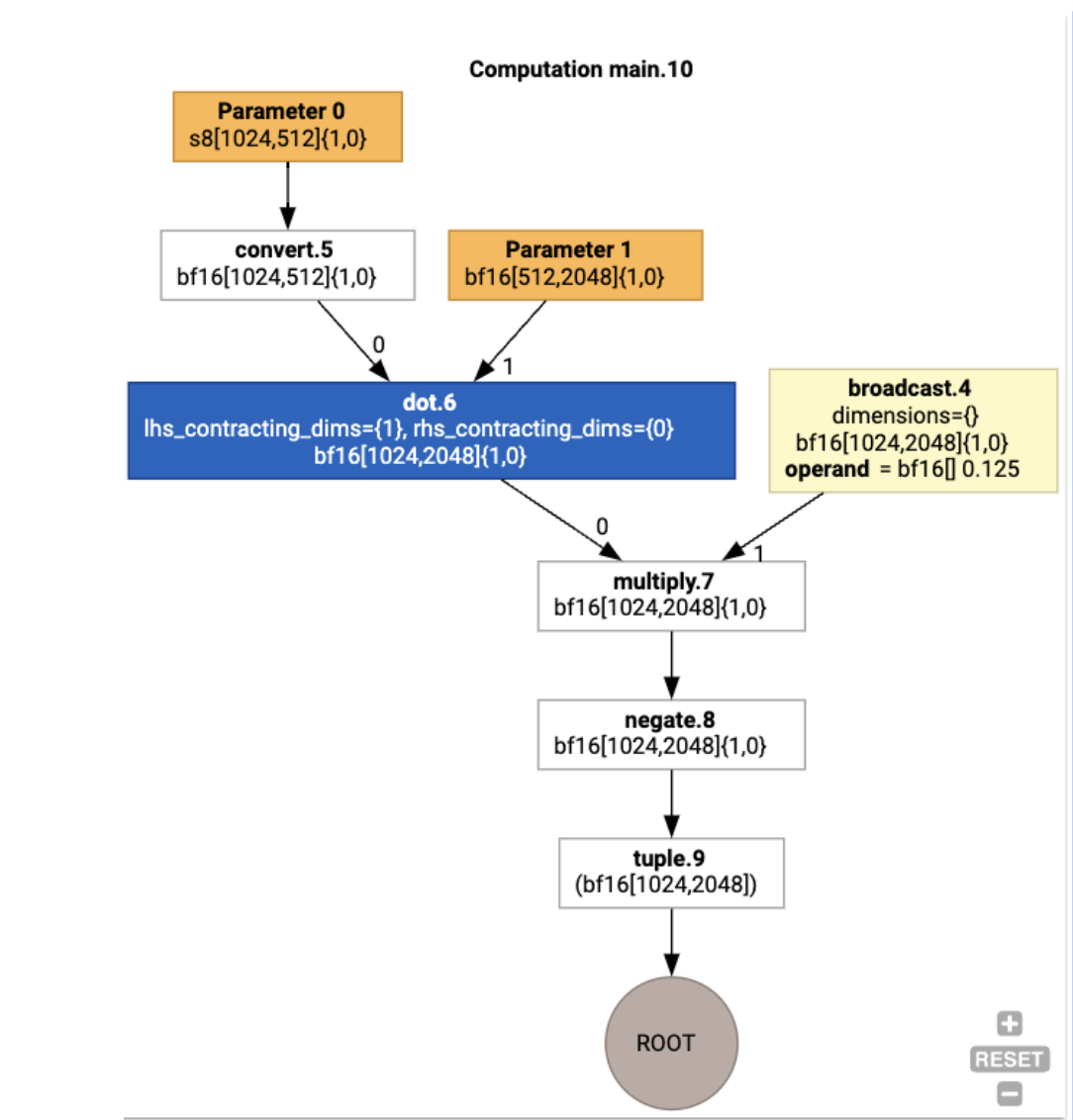
Otimizações no HLO: componentes principais
Várias transmissões de otimização notáveis acontecem no HLO, como as reescritas HLO->HLO.
Particionador SPMD
O particionador SPMD do XLA, conforme descrito em GSPMD: General and Scalable Parallelization for MLComputation Graphs, consome HLO com anotações de fragmentação (produzidas, por exemplo, por jax.pjit) e produz um HLO fragmentado que pode ser executado em vários hosts e dispositivos.
Além do particionamento, o SPMD tenta otimizar o HLO para uma programação de execução ideal, sobrepondo a computação e a comunicação entre os nós.
Exemplo
Comece com um programa JAX simples fragmentado em dois dispositivos:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
Ao visualizar, as anotações de fragmentação são apresentadas como chamadas personalizadas:
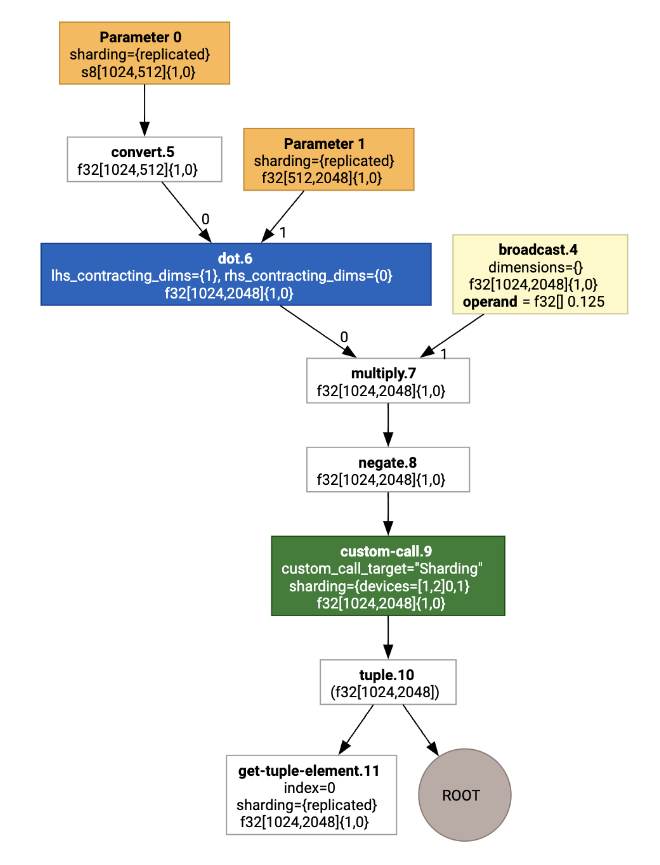
Para verificar como o particionador SPMD expande a chamada personalizada, podemos analisar o HLO após as otimizações:
print(f.lower(np.ones((8, 8)).compile().as_text())
que gera um HLO com um coletivo:
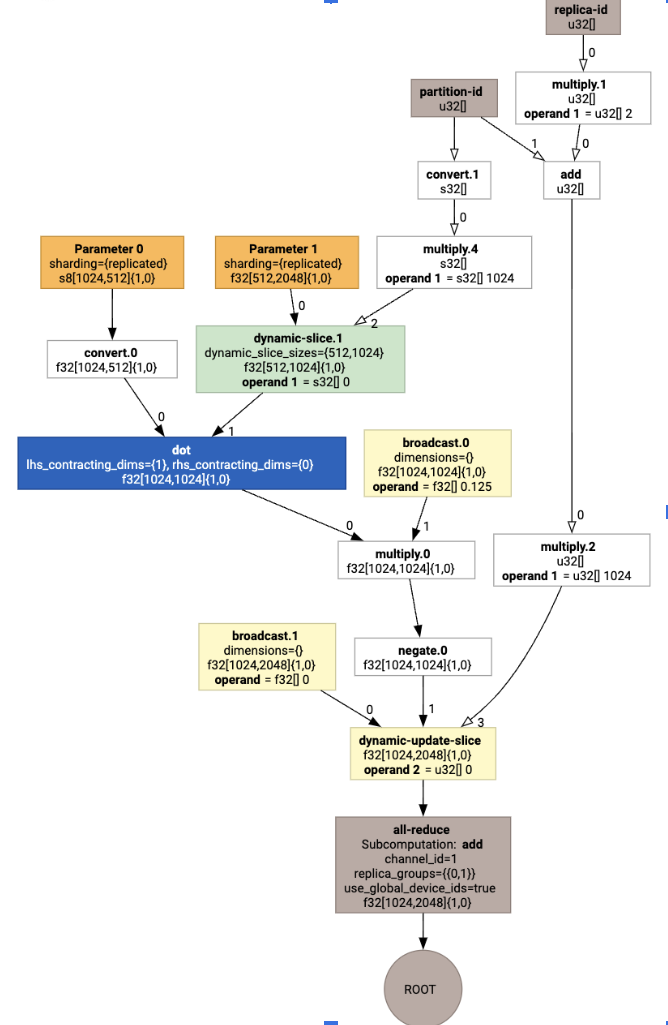
Atribuição de layout
O HLO separa a forma lógica e o layout físico (como os tensores são dispostos na memória). Por exemplo, uma matriz f32[32, 64] pode ser representada na ordem de linha principal ou de coluna principal, representada como {1,0} ou {0,1}, respectivamente.
Em geral, o layout é representado como parte de uma forma, mostrando uma permutação sobre o número de dimensões que indicam o layout físico na memória.
Para cada operação presente no HLO, a transmissão de atribuição de layout escolhe um
layout ideal (por exemplo, NHWC para uma convolução no Ampere). Por exemplo, uma operação de multiplicação de matrizes int8xint8->int32 prefere o layout {0,1} para o lado direito do cálculo. Da mesma forma, as transposições inseridas pelo usuário são ignoradas e codificadas como uma mudança de layout.
Em seguida, os layouts são propagados pelo gráfico, e os conflitos entre layouts ou nos endpoints do gráfico são materializados como operações copy, que realizam a transposição física. Por exemplo, começando pelo gráfico
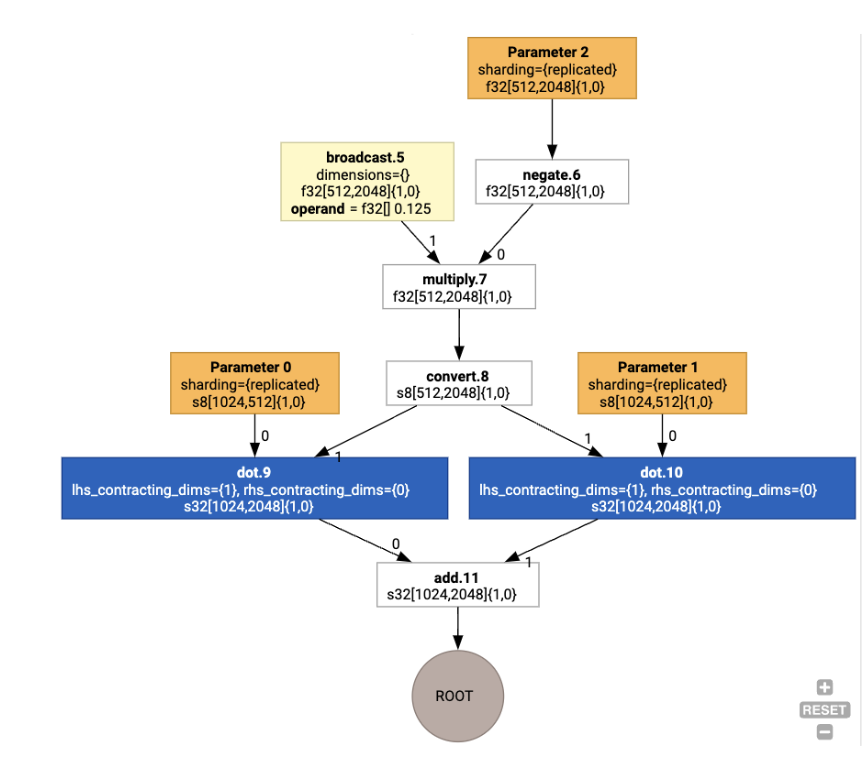
Ao executar a atribuição de layout, vemos os seguintes layouts e a operação copy inserida:
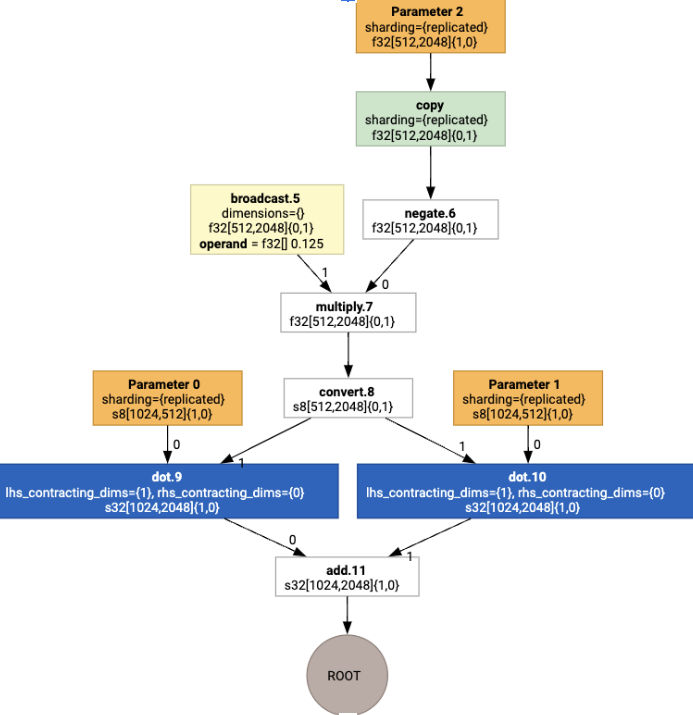
Fusão
A fusão é a otimização mais importante do XLA, que agrupa várias operações (por exemplo, adição em exponenciação em matmul) em um único kernel. Como muitas cargas de trabalho de GPU tendem a ser limitadas pela memória, a fusão acelera muito a execução, evitando a gravação de tensores intermediários na HBM e a leitura deles novamente. Em vez disso, ela os transmite em registros ou memória compartilhada.
As instruções HLO fundidas são bloqueadas juntas em um único cálculo de fusão, o que estabelece os seguintes invariantes:
Nenhum armazenamento intermediário dentro da fusão é materializado em HBM. Tudo precisa ser transmitido por registros ou memória compartilhada.
Uma fusão é sempre compilada para exatamente um kernel de GPU.
Otimizações de HLO no exemplo em execução
Podemos inspecionar o HLO pós-otimização usando jax.jit(f).lower(a,
b).compile().as_text() e verificar se uma única fusão foi gerada:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
A fusão backend_config informa que o Triton será usado como uma estratégia de geração de código e especifica o agrupamento escolhido.
Também podemos visualizar o módulo resultante:
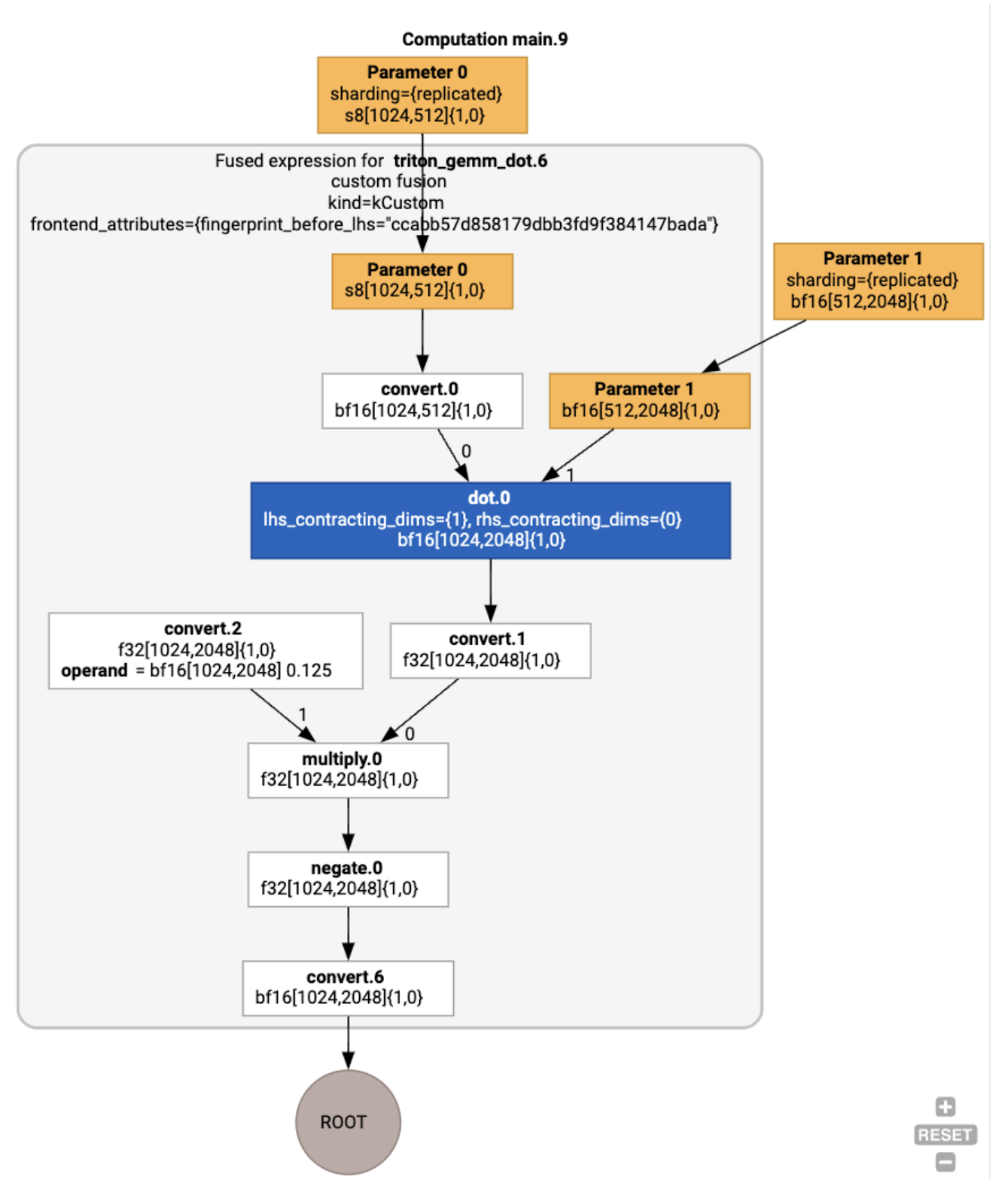
Atribuição e programação de buffer
Uma transmissão de atribuição de buffer considera as informações de forma e visa produzir uma alocação de buffer ideal para o programa, minimizando a quantidade de memória intermediária consumida. Ao contrário da execução no modo imediato (não compilado) do TF ou do PyTorch, em que o alocador de memória não conhece o grafo com antecedência, o programador do XLA pode "prever o futuro" e produzir uma programação de computação ideal.
Back-end do compilador: geração de código e seleção de biblioteca
Para cada instrução HLO no cálculo, o XLA escolhe se vai executá-la usando uma biblioteca vinculada a um ambiente de execução ou se vai gerar código para PTX.
Seleção de biblioteca
Para muitas operações comuns, o XLA:GPU usa bibliotecas de alto desempenho da NVIDIA, como cuBLAS, cuDNN e NCCL. As bibliotecas têm a vantagem de um desempenho rápido e verificado, mas geralmente impedem oportunidades de fusão complexas.
Geração direta de código
O back-end XLA:GPU gera LLVM IR de alta performance diretamente para várias operações (reduções, transposições etc.).
Geração de código do Triton
Para fusões mais avançadas que incluem multiplicação de matrizes ou softmax, o XLA:GPU usa o Triton como uma camada de geração de código. As fusões de HLO são convertidas em TritonIR (um dialeto MLIR que serve como entrada para o Triton), selecionam parâmetros de mosaico e invocam o Triton para geração de PTX:
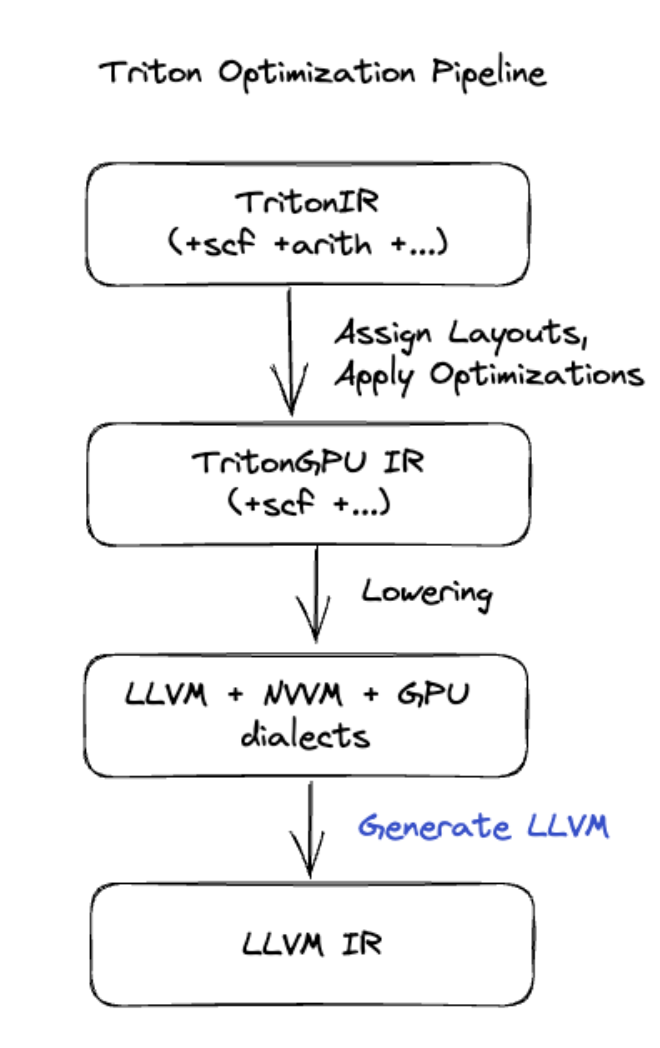
Observamos que o código resultante tem um desempenho muito bom no Ampere, com performance quase no limite do modelo e tamanhos de bloco ajustados corretamente.
Ambiente de execução
O XLA Runtime converte a sequência resultante de chamadas de kernel CUDA e invocações de biblioteca em um RuntimeIR (um dialeto MLIR em XLA), em que a extração de gráficos CUDA é realizada. O gráfico CUDA ainda está em desenvolvimento, e apenas alguns nós são compatíveis no momento. Depois que os limites do gráfico CUDA são extraídos, o RuntimeIR é compilado via LLVM em um executável de CPU, que pode ser armazenado ou transferido para compilação antecipada.