
Введение
XLA — это компилятор для линейной алгебры, зависящий от оборудования и фреймворка, предлагающий лучшую в своем классе производительность. JAX, TF, Pytorch и другие используют XLA, преобразуя пользовательский ввод в набор операций StableHLO («операция высокого уровня»: набор из ~100 статически сформированных инструкций, таких как сложение, вычитание, matmul и т. д.), из которого XLA создает оптимизированный код для различных бэкэндов:
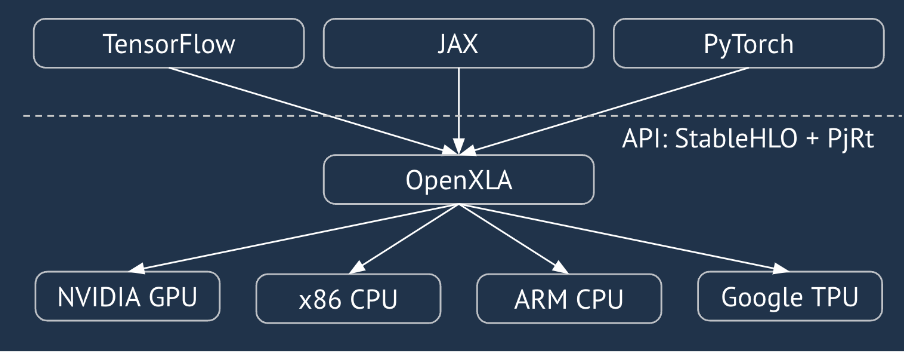
Во время выполнения фреймворки вызывают API среды выполнения PJRT , который позволяет фреймворкам выполнять операцию «заполнять указанные буферы, используя заданную программу StableHLO на определенном устройстве».
XLA: конвейер графического процессора
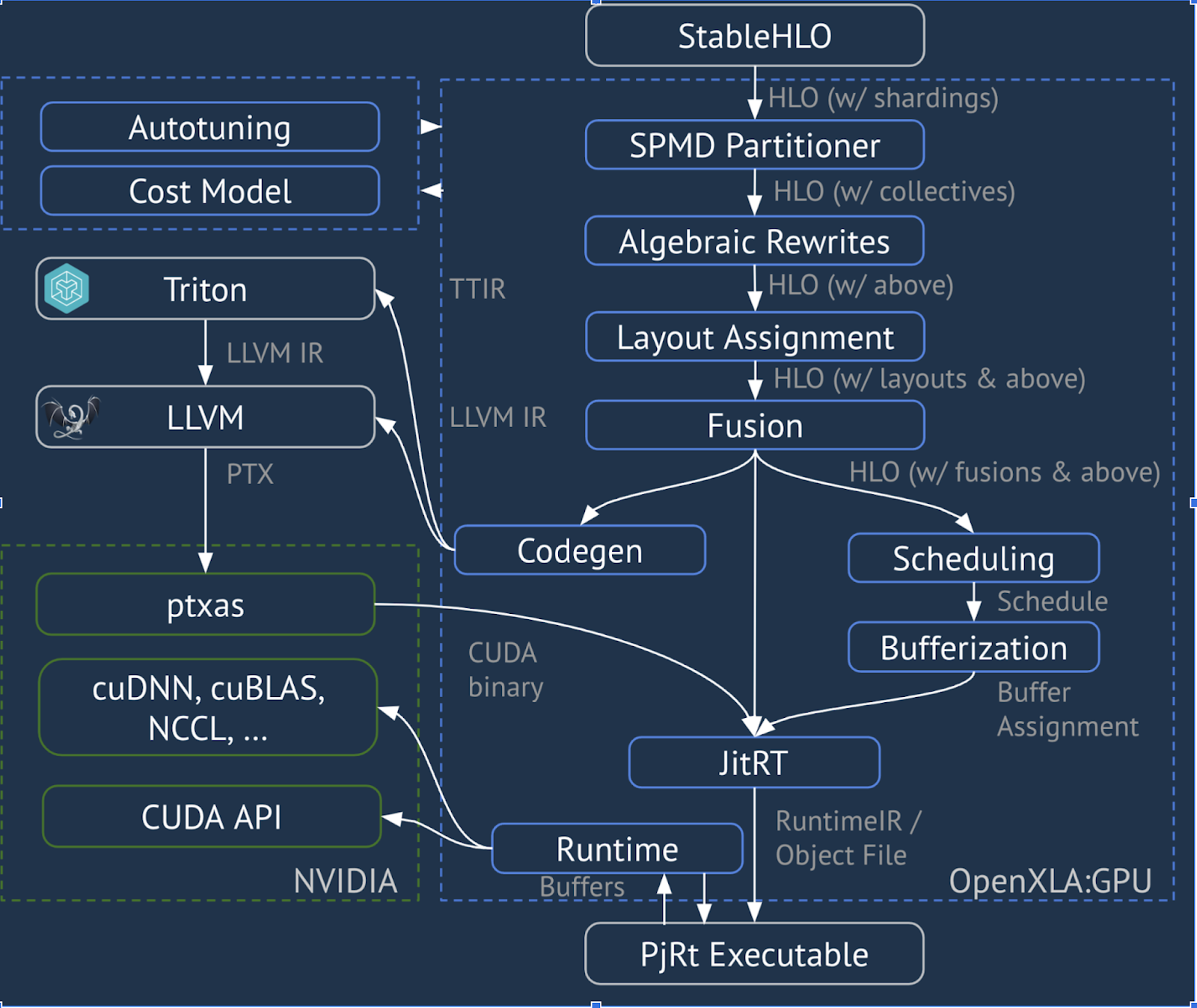
XLA:GPU использует комбинацию «собственных» (PTX, через LLVM) излучателей и излучателей TritonIR для генерации высокопроизводительных ядер графического процессора (синий цвет обозначает компоненты 3P):
Пример выполнения: JAX
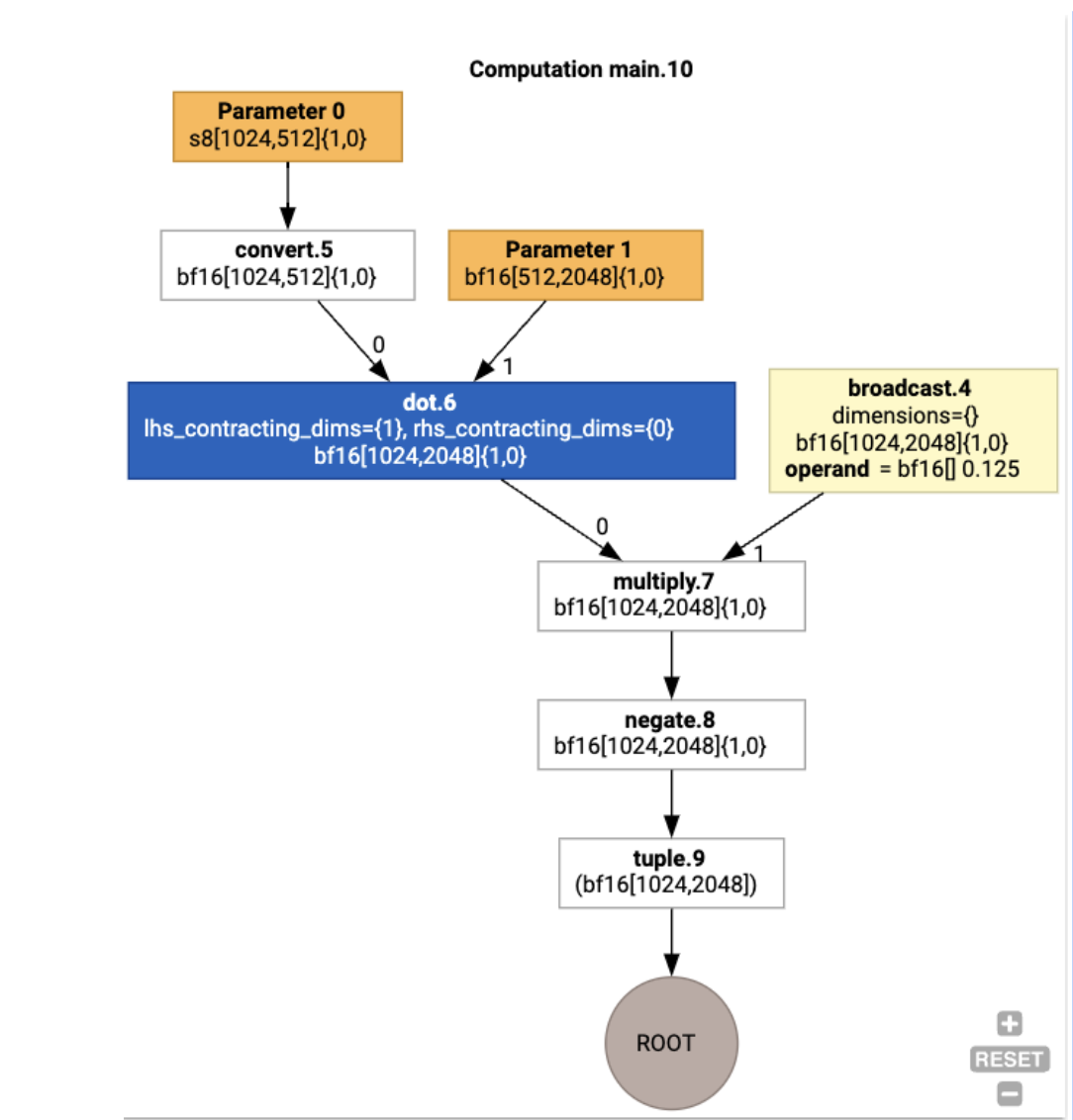
Чтобы проиллюстрировать конвейер, начнем с работающего примера в JAX, который вычисляет matmul в сочетании с умножением на константу и отрицанием:
def f(a, b):
return -((a @ b) * 0.125)
Мы можем проверить HLO, сгенерированный функцией:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
который генерирует:
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
Мы также можем визуализировать входное вычисление HLO, используя jax.xla_computation(f)(a, b).as_hlo_dot_graph() :
Оптимизации HLO: ключевые компоненты
В HLO происходит ряд важных оптимизационных проходов, когда происходит перезапись HLO->HLO.
Разделитель SPMD
Разделитель XLA SPMD, как описано в GSPMD: General and Scalable Parallelization for MLComputation Graphs , потребляет HLO с аннотациями шардинга (созданными, например, jax.pjit ) и создает шардированный HLO, который затем может работать на нескольких хостах и устройствах. Помимо разделения, SPMD пытается оптимизировать HLO для оптимального графика выполнения, перекрывая вычисления и связь между узлами.
Пример
Рассмотрим пример простой программы JAX, распределенной по двум устройствам:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
Визуализируя это, аннотации шардинга представлены в виде пользовательских вызовов:
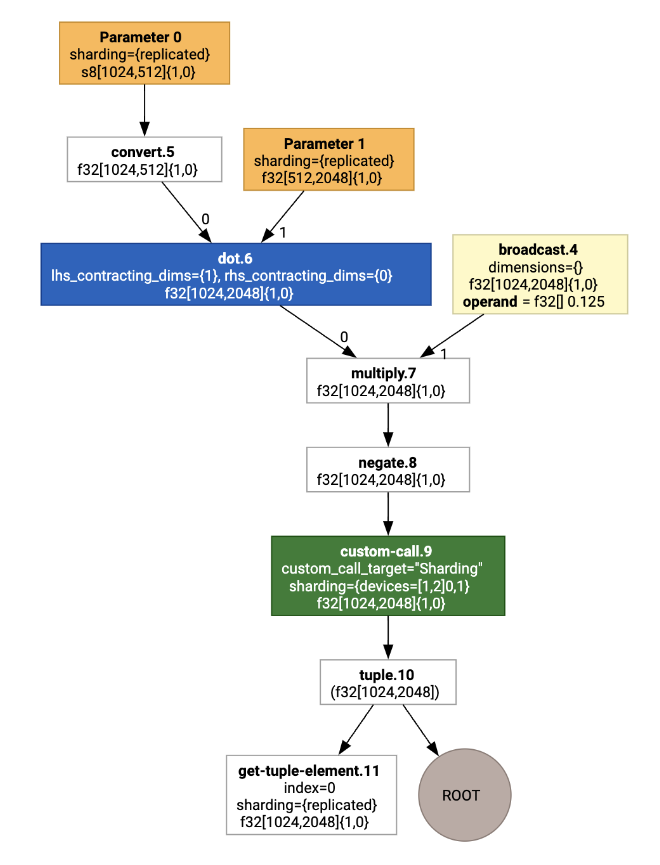
Чтобы проверить, как разделитель SPMD расширяет пользовательский вызов, мы можем посмотреть на HLO после оптимизаций:
print(f.lower(np.ones((8, 8)).compile().as_text())
Что генерирует HLO с коллективом:
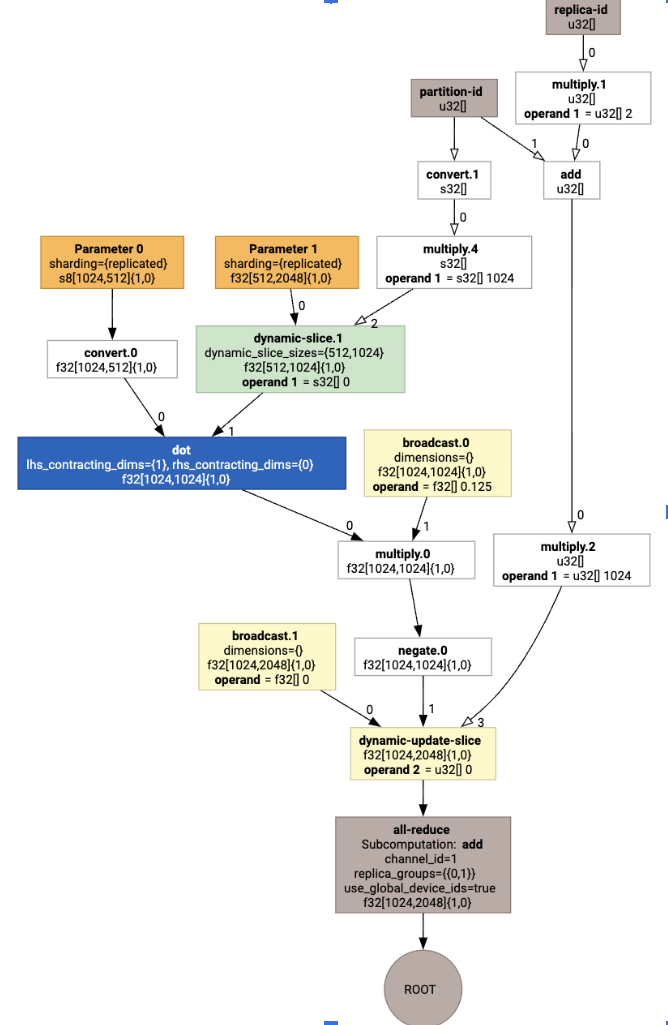
Задание по макету
HLO разделяет логическую форму и физическую компоновку (как тензоры располагаются в памяти). Например, матрица f32[32, 64] может быть представлена либо в строковом, либо в столбцовом порядке, представляемом как {1,0} или {0,1} соответственно. В общем случае компоновка представляется как часть формы, показывая перестановку по числу измерений, указывающих физическую компоновку в памяти.
Для каждой операции, присутствующей в HLO, проход назначения макета выбирает оптимальный макет (например, NHWC для свертки по Амперу). Например, операция matmul int8xint8->int32 предпочитает макет {0,1} для RHS вычисления. Аналогично, «транспонирование», вставленное пользователем, игнорируется и кодируется как изменение макета.
Затем макеты распространяются по графу, а конфликты между макетами или в конечных точках графа материализуются как операции copy , которые выполняют физическую транспозицию. Например, начиная с графа
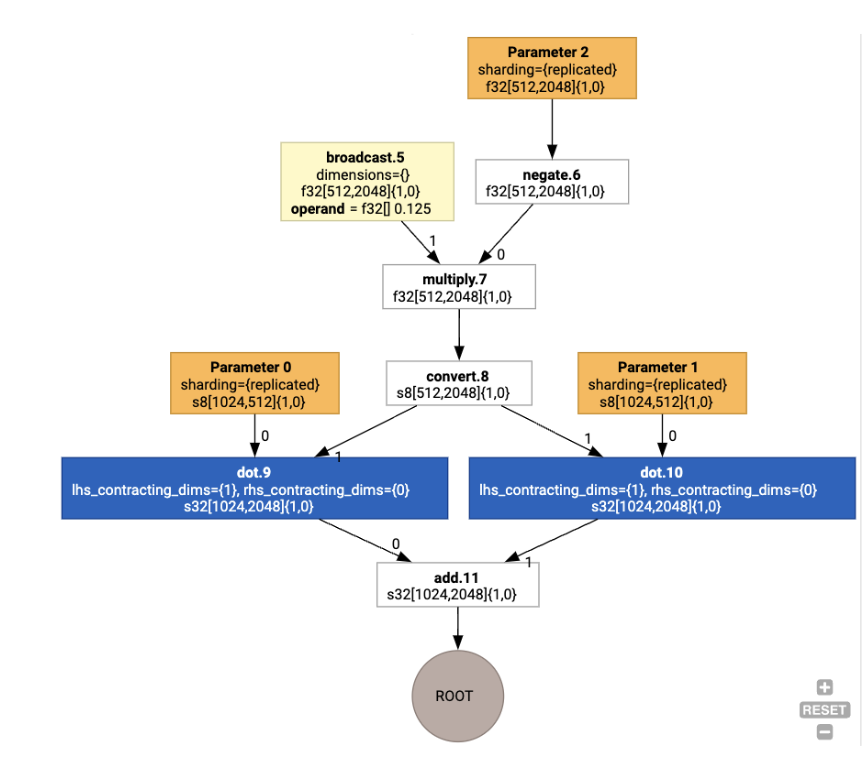
Выполнив задание макета, мы видим следующие макеты и вставленную операцию copy :
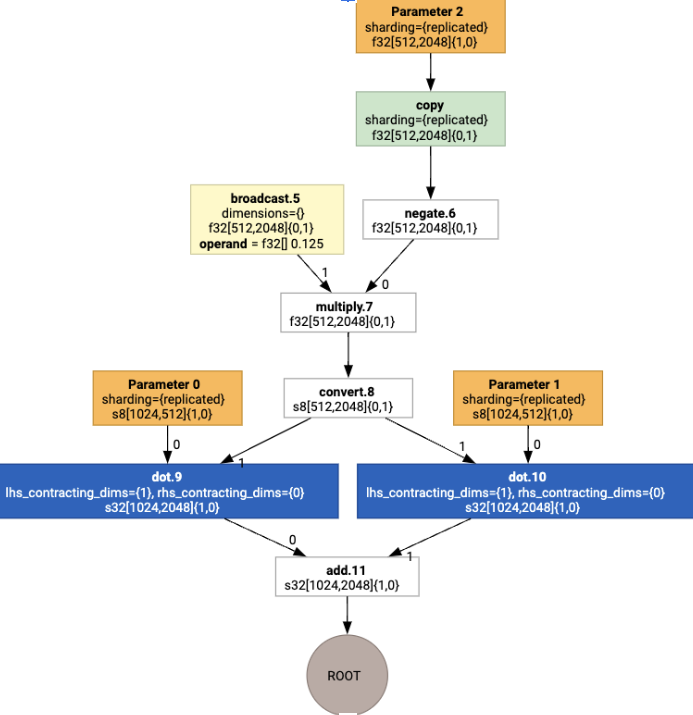
Слияние
Fusion — это единственная важнейшая оптимизация XLA, которая группирует несколько операций (например, сложение в возведение в степень в matmul) в одно ядро. Поскольку многие рабочие нагрузки GPU, как правило, привязаны к памяти, Fusion значительно ускоряет выполнение, избегая записи промежуточных тензоров в HBM и последующего их обратного чтения, и вместо этого передает их либо в регистры, либо в общую память.
Объединенные инструкции HLO объединяются в единое вычисление слияния, которое устанавливает следующие инварианты:
В HBM не реализовано промежуточное хранилище внутри слияния (всё должно передаваться либо через регистры, либо через общую память).
Слияние всегда компилируется только в одно ядро графического процессора.
Оптимизации HLO на примере выполнения
Мы можем проверить HLO после оптимизации с помощью jax.jit(f).lower(a, b).compile().as_text() и убедиться, что было сгенерировано одно слияние:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
Обратите внимание, что fusion backend_config сообщает нам, что Triton будет использоваться в качестве стратегии генерации кода, и указывает выбранную разбивку на блоки.
Мы также можем визуализировать полученный модуль:
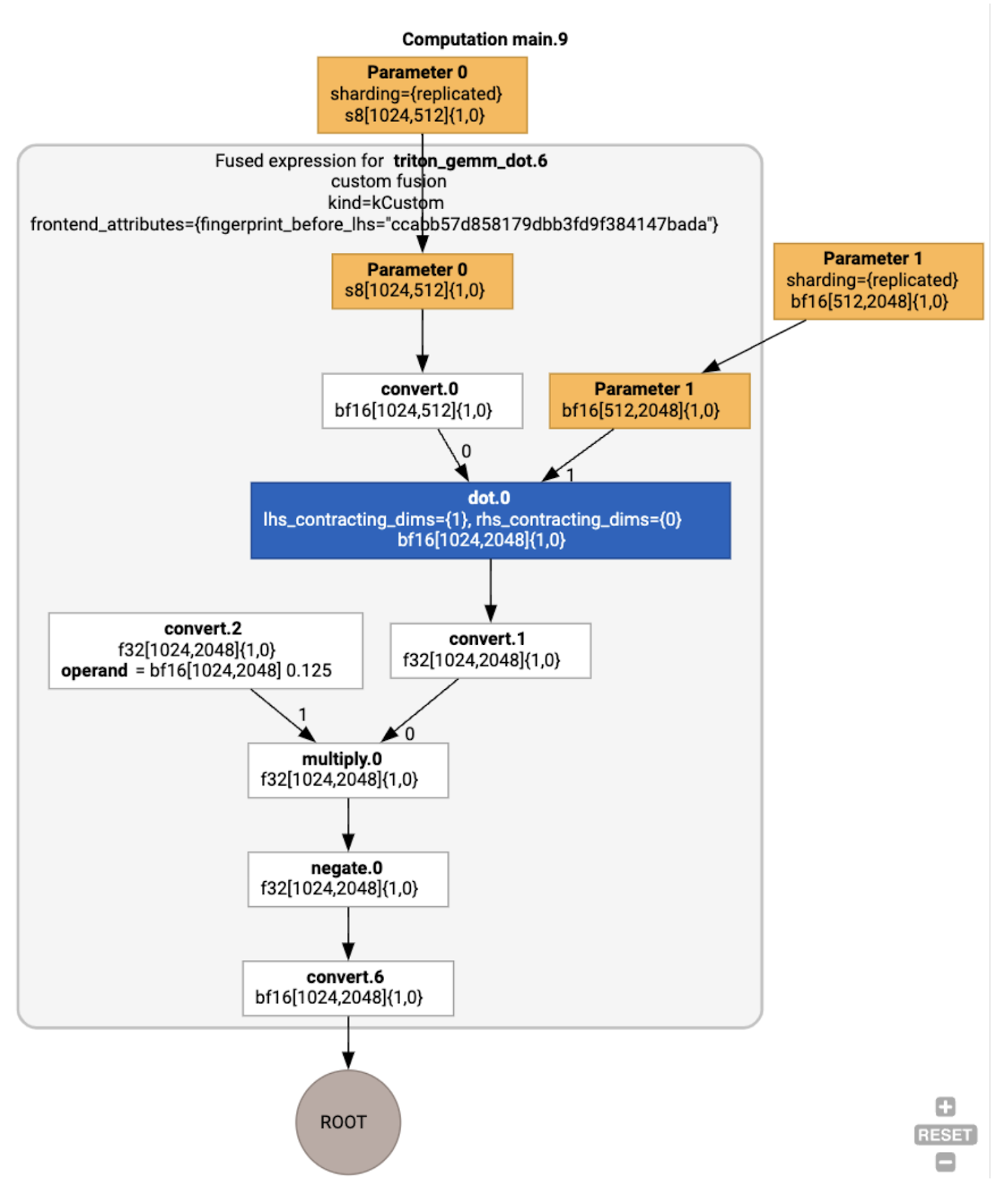
Назначение буфера и планирование
Проход назначения буфера учитывает информацию о форме и нацелен на создание оптимального распределения буфера для программы, минимизируя объем потребляемой промежуточной памяти. В отличие от TF или немедленного (некомпилированного) выполнения PyTorch, где распределитель памяти не знает граф заранее, планировщик XLA может «заглянуть в будущее» и создать оптимальный график вычислений.
Компилятор Backend: выбор кода и библиотеки
Для каждой инструкции HLO в вычислениях XLA выбирает, запускать ли ее с использованием библиотеки, связанной со средой выполнения, или кодировать ее в PTX.
Выбор библиотеки
Для многих распространенных операций XLA:GPU использует библиотеки быстрой производительности от NVIDIA, такие как cuBLAS, cuDNN и NCCL. Библиотеки имеют преимущество проверенной быстрой производительности, но часто исключают сложные возможности слияния.
Прямая генерация кода
Бэкэнд XLA:GPU напрямую генерирует высокопроизводительный LLVM IR для ряда операций (сокращение, транспонирование и т. д.).
Генерация кода Triton
Для более сложных слияний, включающих умножение матриц или softmax, XLA:GPU использует Triton в качестве слоя генерации кода. Слияния HLO преобразуются в TritonIR (диалект MLIR, который служит входом для Triton), выбирают параметры тайлинга и вызывают Triton для генерации PTX:
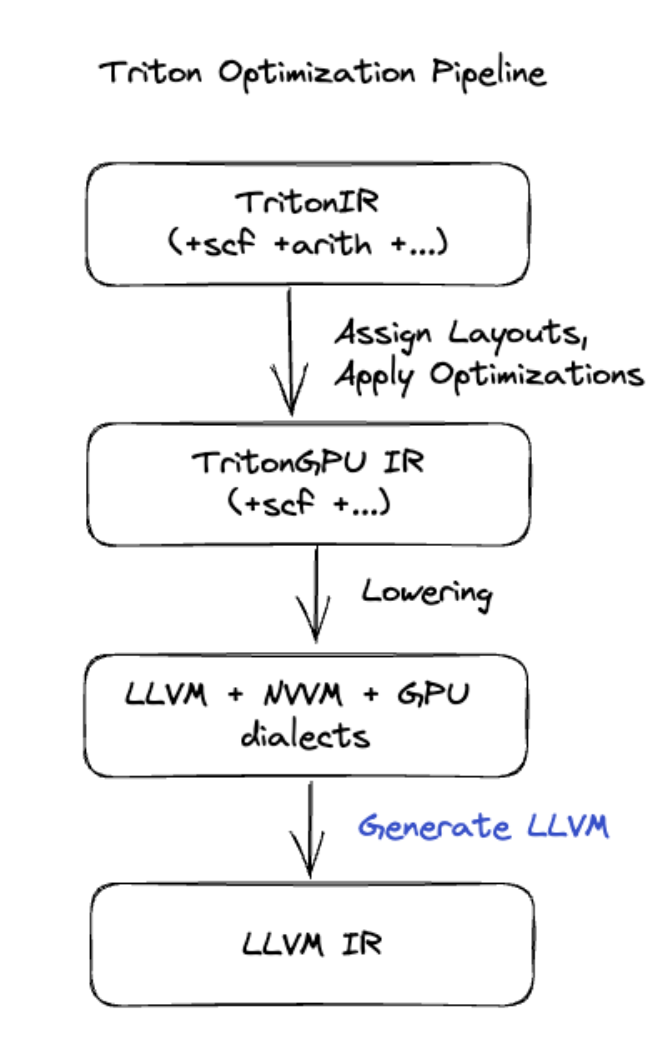
Мы наблюдали, как полученный код очень хорошо работает на Ampere, с производительностью, близкой к линии крыши, при правильно настроенных размерах плитки.
Время выполнения
XLA Runtime преобразует полученную последовательность вызовов ядра CUDA и вызовов библиотеки в RuntimeIR (диалект MLIR в XLA), на котором выполняется извлечение графа CUDA. Граф CUDA все еще находится в стадии разработки, в настоящее время поддерживаются только некоторые узлы. После извлечения границ графа CUDA RuntimeIR компилируется через LLVM в исполняемый файл CPU, который затем может быть сохранен или передан для компиляции Ahead-Of-Time.