
บทนำ
XLA เป็นคอมไพเลอร์เฉพาะโดเมนของฮาร์ดแวร์และเฟรมเวิร์กสำหรับพีชคณิตเชิงเส้น ซึ่งให้ประสิทธิภาพที่ดีที่สุดในระดับเดียวกัน JAX, TF, Pytorch และอื่นๆ ใช้ XLA โดย แปลงอินพุตของผู้ใช้เป็นชุดการดำเนินการ StableHLO ("การดำเนินการระดับสูง": ชุดคำสั่งที่มีรูปร่างคงที่ประมาณ 100 รายการ เช่น การบวก การลบ การคูณเมทริกซ์ ฯลฯ) จากนั้น XLA จะสร้างโค้ดที่เพิ่มประสิทธิภาพ สำหรับแบ็กเอนด์ต่างๆ
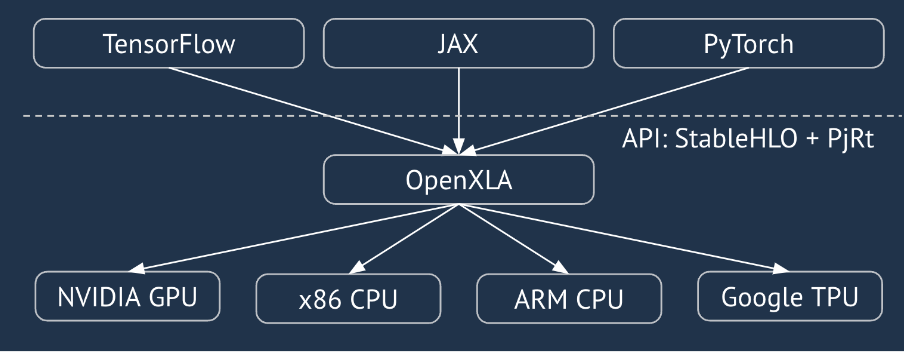
ในระหว่างการดำเนินการ เฟรมเวิร์กจะเรียกใช้ API ของรันไทม์ PJRT ซึ่งช่วยให้เฟรมเวิร์กดำเนินการ "ป้อนข้อมูลบัฟเฟอร์ที่ระบุโดยใช้โปรแกรม StableHLO ที่กำหนดในอุปกรณ์ที่เฉพาะเจาะจง" ได้
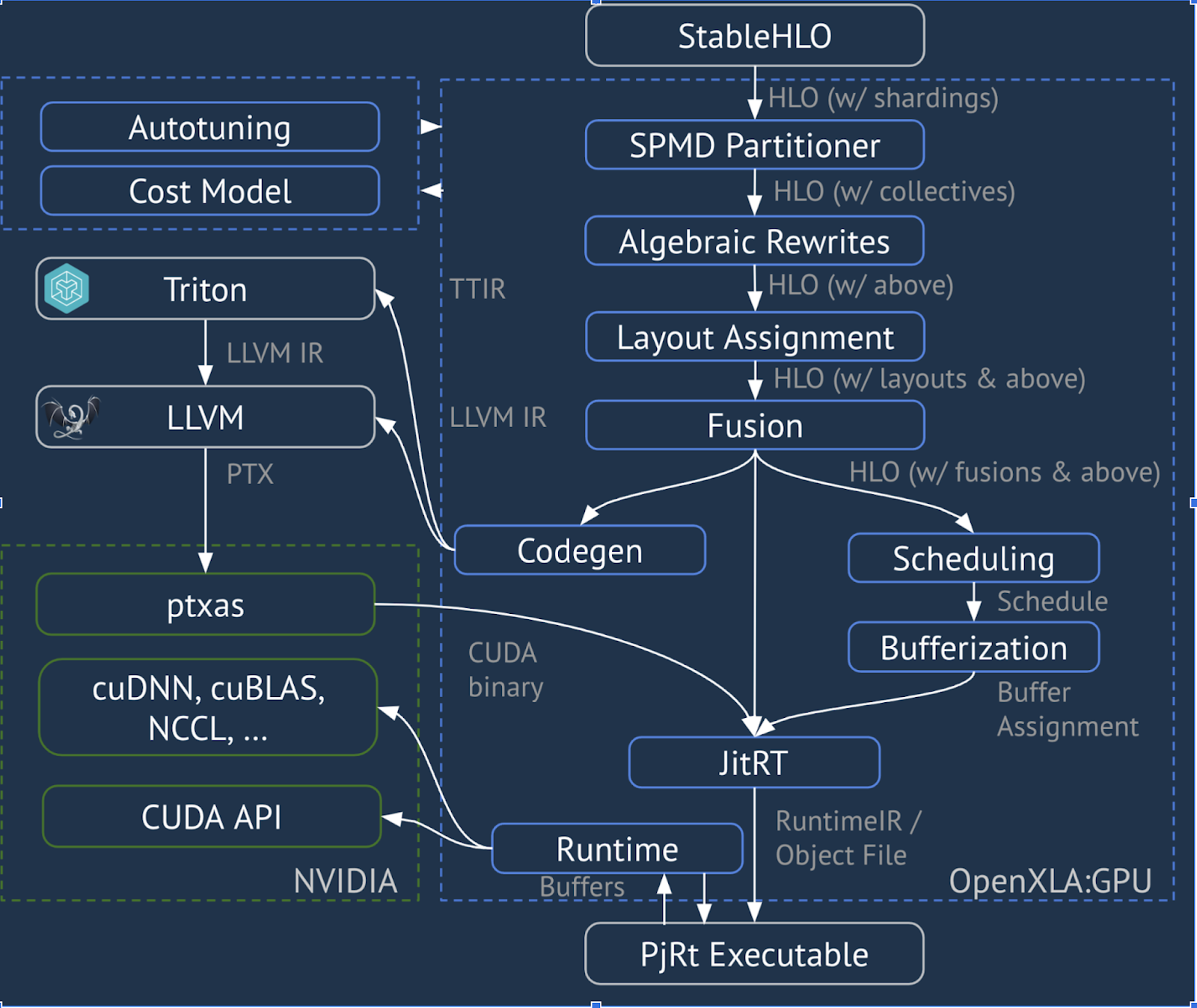
XLA:GPU Pipeline
XLA:GPU ใช้การผสมผสานระหว่างโปรแกรมปล่อยสัญญาณ "ดั้งเดิม" (PTX ผ่าน LLVM) และโปรแกรมปล่อยสัญญาณ TritonIR เพื่อสร้างเคอร์เนล GPU ประสิทธิภาพสูง (สีน้ำเงินระบุคอมโพเนนต์ 3P )
ตัวอย่างการเรียกใช้: JAX
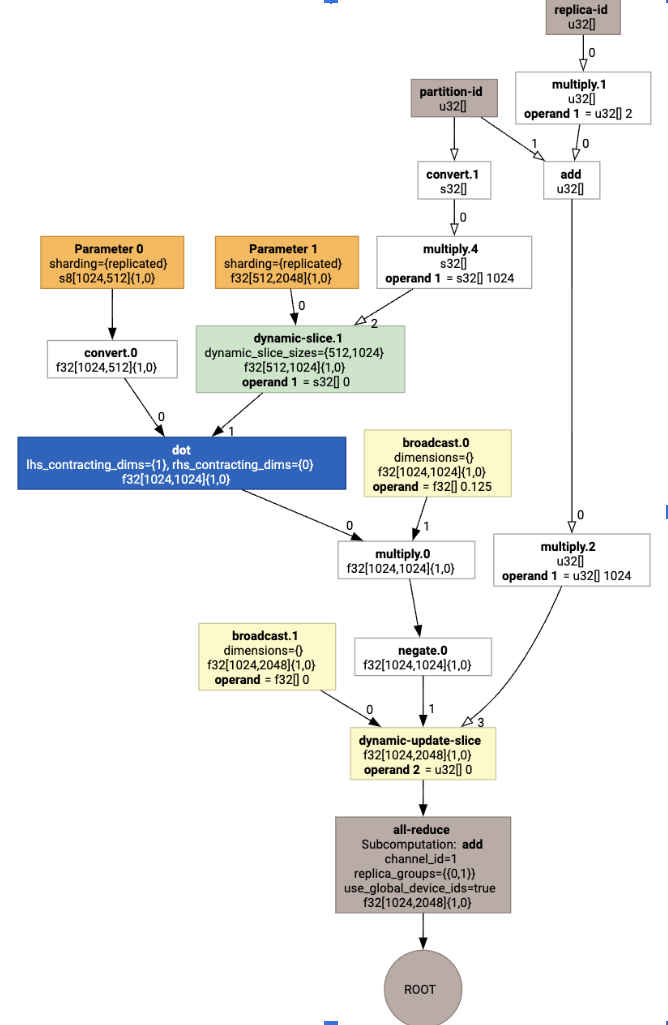
เพื่อแสดงให้เห็นถึงไปป์ไลน์ เรามาเริ่มด้วยตัวอย่างที่ทำงานใน JAX ซึ่ง คำนวณการคูณเมทริกซ์ร่วมกับการคูณด้วยค่าคงที่และการนิเสธ
def f(a, b):
return -((a @ b) * 0.125)
เราสามารถตรวจสอบ HLO ที่ฟังก์ชันสร้างขึ้นได้โดยทำดังนี้
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
ซึ่งจะสร้าง
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
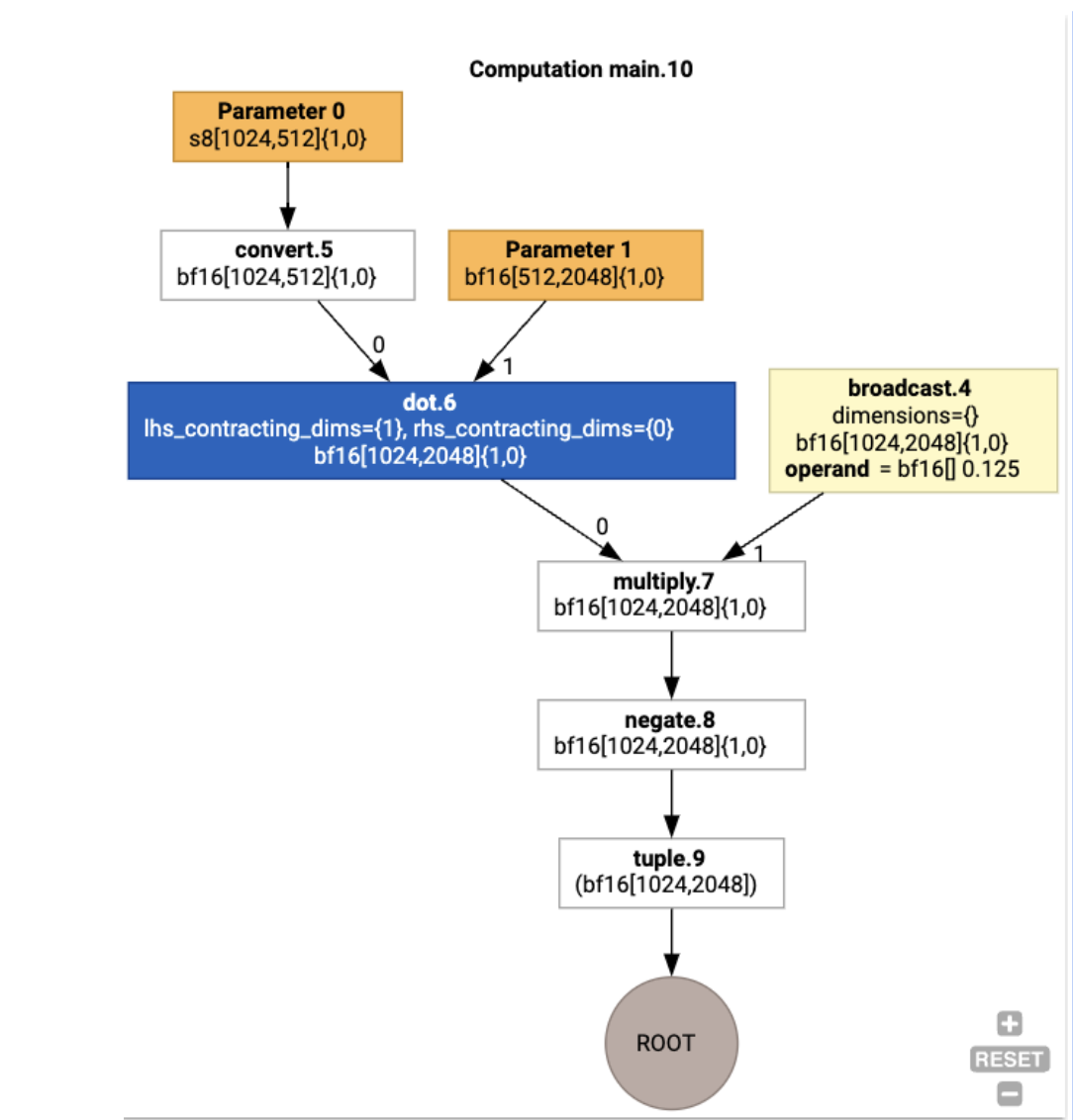
เรายังแสดงภาพการคำนวณ HLO ของอินพุตได้ด้วยโดยใช้
jax.xla_computation(f)(a, b).as_hlo_dot_graph() ดังนี้
การเพิ่มประสิทธิภาพใน HLO: องค์ประกอบสำคัญ
การเพิ่มประสิทธิภาพที่สำคัญหลายอย่างเกิดขึ้นใน HLO ในรูปแบบการเขียนซ้ำจาก HLO เป็น HLO
SPMD Partitioner
ตัวแบ่งพาร์ติชัน XLA SPMD ตามที่อธิบายไว้ใน
GSPMD: General and Scalable Parallelization for MLComputation Graphs
ใช้ HLO ที่มีคำอธิบายประกอบการแบ่ง (สร้างขึ้นโดย jax.pjit เป็นต้น) และ
สร้าง HLO ที่แบ่งพาร์ติชันซึ่งสามารถเรียกใช้ในโฮสต์และอุปกรณ์จำนวนมากได้
นอกจากการแบ่งพาร์ติชันแล้ว SPMD ยังพยายามเพิ่มประสิทธิภาพ HLO เพื่อให้ได้กำหนดการดำเนินการที่เหมาะสมที่สุด
การทับซ้อนกันของการคำนวณ
และการสื่อสารระหว่างโหนด
ตัวอย่าง
ลองเริ่มจากโปรแกรม JAX อย่างง่ายที่แบ่งออกเป็น 2 อุปกรณ์
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
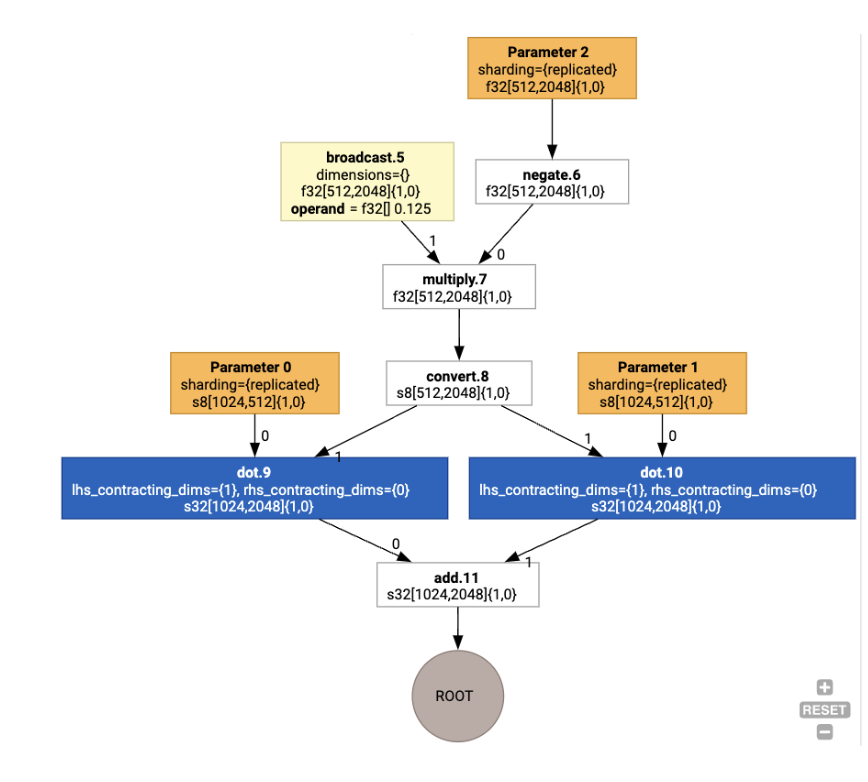
เมื่อแสดงภาพ คำอธิบายประกอบการแบ่งข้อมูลจะแสดงเป็นการเรียกที่กำหนดเองดังนี้
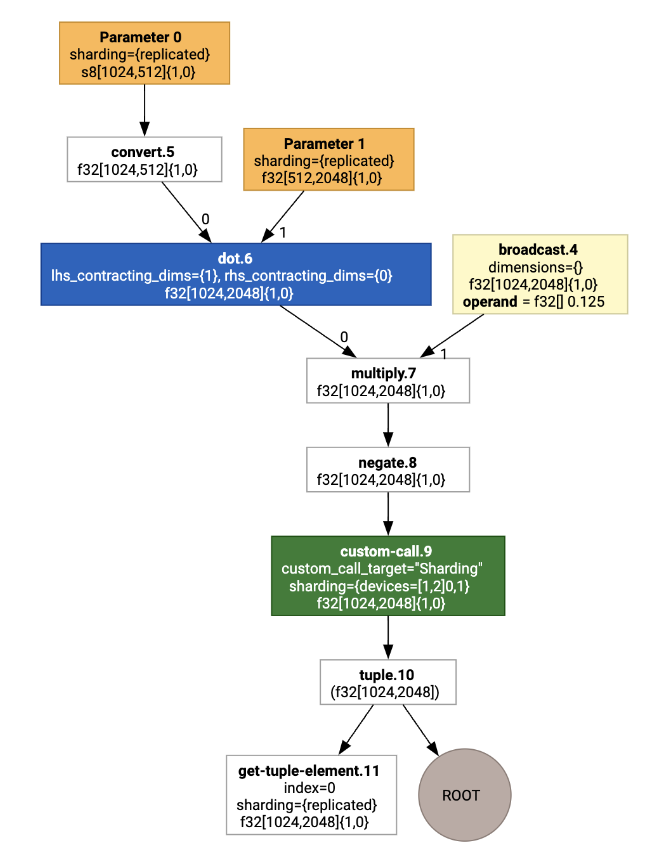
หากต้องการตรวจสอบว่าตัวแบ่งพาร์ติชัน SPMD ขยายการเรียกที่กำหนดเองอย่างไร เราสามารถดู HLO หลังการเพิ่มประสิทธิภาพได้
print(f.lower(np.ones((8, 8)).compile().as_text())
ซึ่งสร้าง HLO ด้วยการรวบรวมข้อมูลต่อไปนี้
การกำหนดเลย์เอาต์
HLO จะแยกรูปร่างเชิงตรรกะและเลย์เอาต์จริง (วิธีจัดวางเทนเซอร์ใน
หน่วยความจำ) เช่น เมทริกซ์ f32[32, 64] สามารถแสดงได้ทั้งในลำดับแถวหลักหรือคอลัมน์หลัก ซึ่งแสดงเป็น {1,0} หรือ {0,1} ตามลำดับ
โดยทั่วไป เลย์เอาต์จะแสดงเป็นส่วนหนึ่งของรูปร่าง ซึ่งแสดงการเรียงสับเปลี่ยนตามจำนวนมิติที่ระบุเลย์เอาต์จริงในหน่วยความจำ
สำหรับการดำเนินการแต่ละอย่างที่มีอยู่ใน HLO พาสการกำหนดเลย์เอาต์จะเลือกเลย์เอาต์ที่เหมาะสมที่สุด (เช่น NHWC สำหรับการ Convolution ใน Ampere) ตัวอย่างเช่น การดำเนินการ int8xint8->int32 matmul ต้องการเลย์เอาต์ {0,1} สำหรับ RHS ของการคำนวณ
ในทำนองเดียวกัน ระบบจะไม่สนใจ "การเปลี่ยนคีย์" ที่ผู้ใช้แทรก และจะ
เข้ารหัสเป็นการเปลี่ยนแปลงเลย์เอาต์
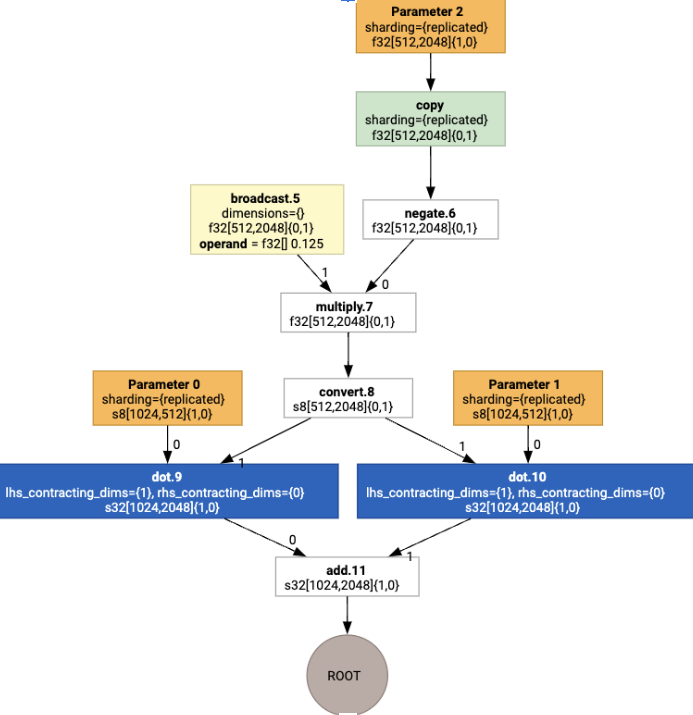
จากนั้นเลย์เอาต์จะแพร่กระจายผ่านกราฟ และความขัดแย้งระหว่างเลย์เอาต์
หรือที่ปลายทางของกราฟจะแสดงเป็นโอเปอเรชัน copy ซึ่งจะดำเนินการ
การสับเปลี่ยนทางกายภาพ เช่น เริ่มจากกราฟ
เมื่อเรียกใช้การกำหนดเลย์เอาต์ เราจะเห็นเลย์เอาต์ต่อไปนี้และcopyการดำเนินการ
ที่แทรกไว้
ฟิวชั่น
ฟิวชันเป็นการเพิ่มประสิทธิภาพที่สำคัญที่สุดของ XLA ซึ่งจัดกลุ่มการดำเนินการหลายอย่าง (เช่น การบวกเป็นการยกกำลังเป็นการคูณเมทริกซ์) ไว้ในเคอร์เนลเดียว เนื่องจากภาระงานของ GPU จำนวนมากมักจะขึ้นอยู่กับหน่วยความจำ การผสานจึงช่วยเพิ่มความเร็วในการดำเนินการได้อย่างมาก โดยหลีกเลี่ยงการเขียนเทนเซอร์กลางไปยัง HBM แล้ว อ่านกลับ และแทนที่ด้วยการส่งเทนเซอร์เหล่านั้นในรีจิสเตอร์หรือหน่วยความจำที่ใช้ร่วมกัน
คำสั่ง HLO ที่ผสานรวมจะถูกบล็อกไว้ด้วยกันในการคำนวณการผสานรวมเดียว ซึ่งสร้างตัวแปรที่ไม่เปลี่ยนแปลงต่อไปนี้
ไม่มีการจัดเก็บข้อมูลชั่วคราวภายในฟิวชันใน HBM (ต้องส่งผ่านทั้งหมดผ่านรีจิสเตอร์หรือหน่วยความจำที่ใช้ร่วมกัน)
การผสานจะคอมไพล์เป็นเคอร์เนล GPU 1 รายการเสมอ
การเพิ่มประสิทธิภาพ HLO ในตัวอย่างการวิ่ง
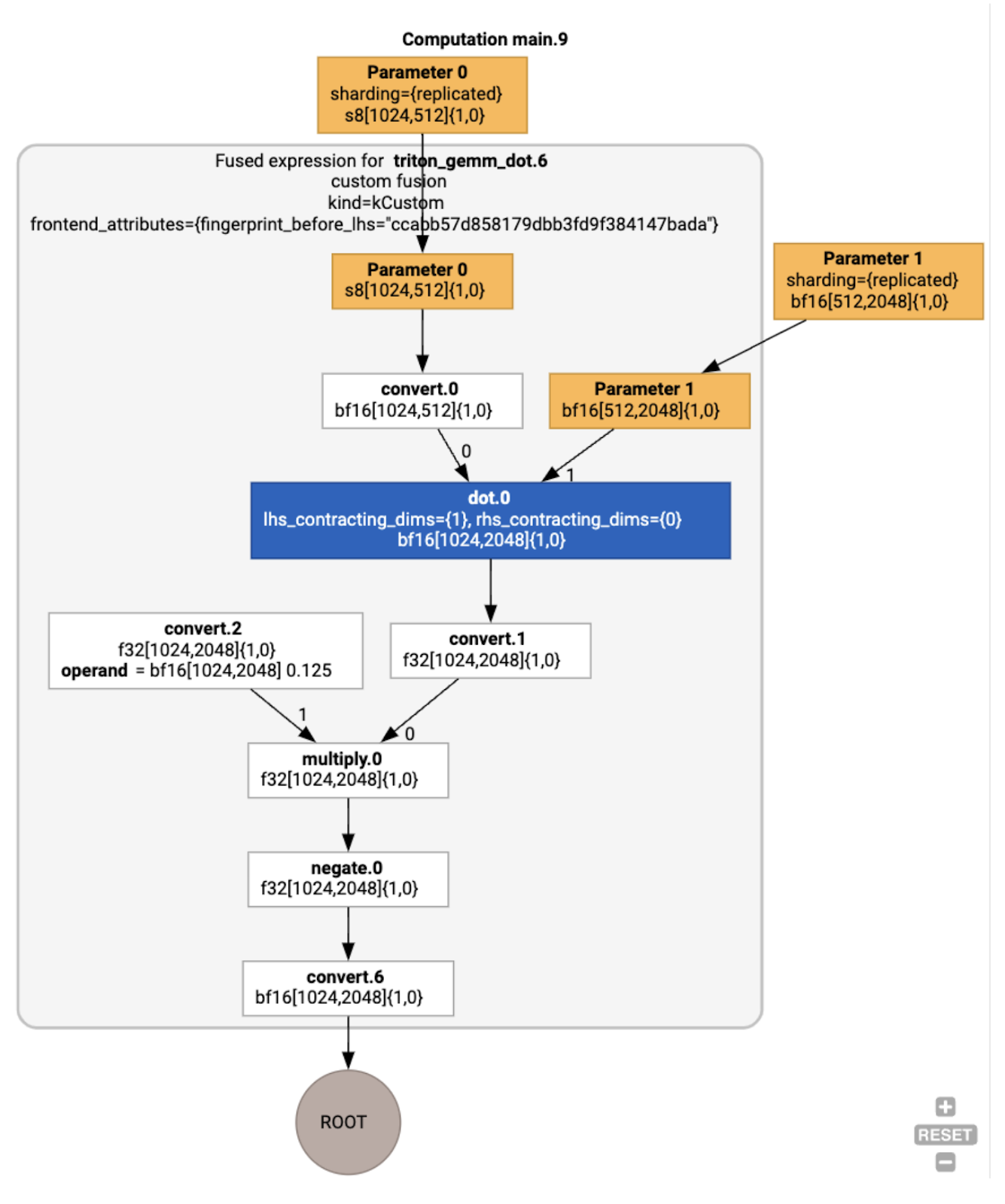
เราสามารถตรวจสอบ HLO หลังการเพิ่มประสิทธิภาพโดยใช้ jax.jit(f).lower(a,
b).compile().as_text() และยืนยันว่ามีการสร้างฟิวชันเดียว
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
โปรดทราบว่าฟิวชัน backend_config จะบอกให้เราทราบว่า Triton จะใช้เป็น
กลยุทธ์การสร้างโค้ด และระบุการแบ่งไทล์ที่เลือก
นอกจากนี้ เรายังแสดงภาพโมดูลผลลัพธ์ได้ด้วย
การกำหนดและการจัดตารางเวลาบัฟเฟอร์
การส่งผ่านการกำหนดบัฟเฟอร์จะพิจารณาข้อมูลรูปร่างและมุ่ง จัดสรรบัฟเฟอร์ที่เหมาะสมที่สุดสำหรับโปรแกรม โดยลดปริมาณ หน่วยความจำระดับกลางที่ใช้ ต่างจากการดำเนินการในโหมดทันที (ไม่ได้คอมไพล์) ของ TF หรือ PyTorch ซึ่งตัวจัดสรรหน่วยความจำไม่ทราบกราฟล่วงหน้า ตัวจัดกำหนดการ XLA สามารถ "มองไปในอนาคต" และสร้างกำหนดการคำนวณที่เหมาะสมที่สุดได้
ส่วนหลังของคอมไพเลอร์: การสร้างโค้ดและการเลือกไลบรารี
สำหรับคำสั่ง HLO ทุกรายการในการคำนวณ XLA จะเลือกว่าจะเรียกใช้คำสั่งนั้น โดยใช้ไลบรารีที่ลิงก์กับรันไทม์ หรือจะสร้างโค้ดเป็น PTX
การเลือกห้องสมุด
สำหรับการดำเนินการทั่วไปหลายอย่าง XLA:GPU จะใช้ไลบรารีที่มีประสิทธิภาพสูงจาก NVIDIA เช่น cuBLAS, cuDNN และ NCCL ไลบรารีมีข้อดีคือประสิทธิภาพที่รวดเร็วและได้รับการยืนยัน แต่ก็มักจะปิดกั้นโอกาสในการผสานรวมที่ซับซ้อน
การสร้างโค้ดโดยตรง
แบ็กเอนด์ XLA:GPU จะสร้าง LLVM IR ประสิทธิภาพสูงโดยตรงสำหรับการดำเนินการหลายอย่าง (การลด การเปลี่ยนตำแหน่ง ฯลฯ)
การสร้างโค้ด Triton
สำหรับการผสานขั้นสูงเพิ่มเติมซึ่งรวมถึงการคูณเมทริกซ์หรือ Softmax XLA:GPU จะใช้ Triton เป็นเลเยอร์การสร้างโค้ด ระบบจะแปลง HLO Fusion เป็น TritonIR (ภาษา MLIR ที่ใช้เป็นอินพุตของ Triton) เลือกพารามิเตอร์การแบ่งไทล์ และเรียกใช้ Triton เพื่อสร้าง PTX
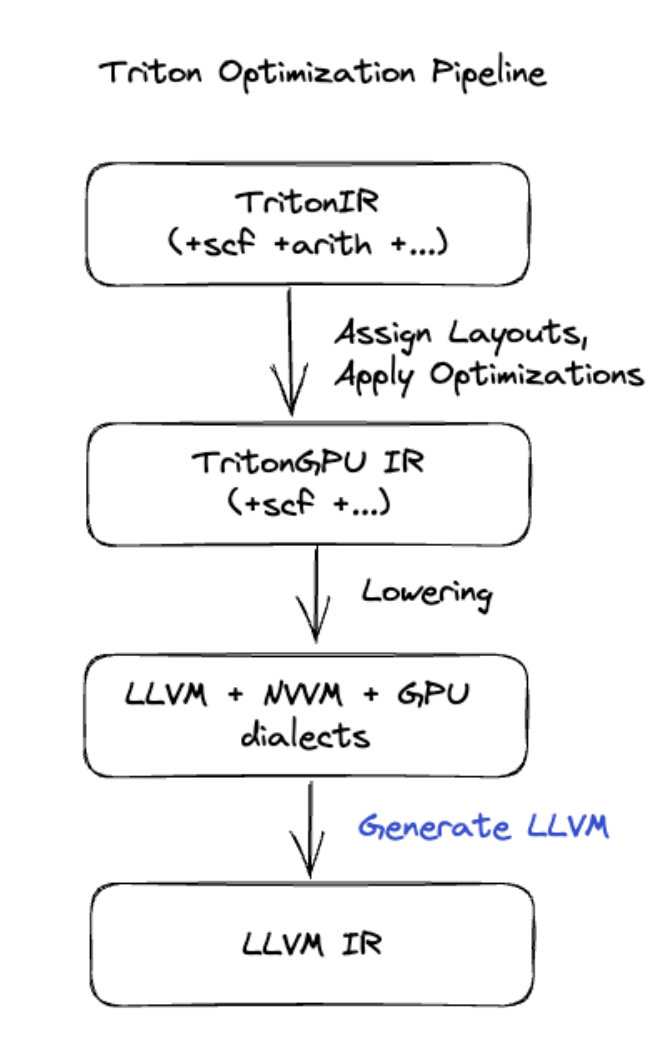
เราสังเกตว่าโค้ดที่ได้ทำงานได้ดีมากบน Ampere โดยมีประสิทธิภาพใกล้เคียงกับประสิทธิภาพสูงสุดเมื่อปรับขนาดไทล์อย่างเหมาะสม
รันไทม์
รันไทม์ XLA จะแปลงลำดับการเรียกใช้เคอร์เนล CUDA และการเรียกใช้ไลบรารี ที่ได้เป็น RuntimeIR (ภาษา MLIR ใน XLA) ซึ่งจะมีการดึงข้อมูลกราฟ CUDA กราฟ CUDA ยังอยู่ระหว่างการพัฒนา และขณะนี้รองรับเฉพาะบางโหนด เมื่อแยกขอบเขตของกราฟ CUDA แล้ว ระบบจะคอมไพล์ RuntimeIR ผ่าน LLVM เป็นไฟล์ที่เรียกใช้ได้ของ CPU ซึ่งจะจัดเก็บหรือโอนสำหรับการคอมไพล์ล่วงหน้าได้