
Giới thiệu
XLA là một trình biên dịch dành riêng cho miền phần cứng và khung cho đại số tuyến tính, mang lại hiệu suất tốt nhất. JAX, TF, Pytorch và các thư viện khác sử dụng XLA bằng cách chuyển đổi dữ liệu đầu vào của người dùng thành tập hợp thao tác StableHLO ("thao tác cấp cao": một tập hợp gồm khoảng 100 chỉ dẫn có hình dạng tĩnh như phép cộng, phép trừ, phép nhân ma trận, v.v.), từ đó XLA tạo ra mã được tối ưu hoá cho nhiều chương trình phụ trợ:
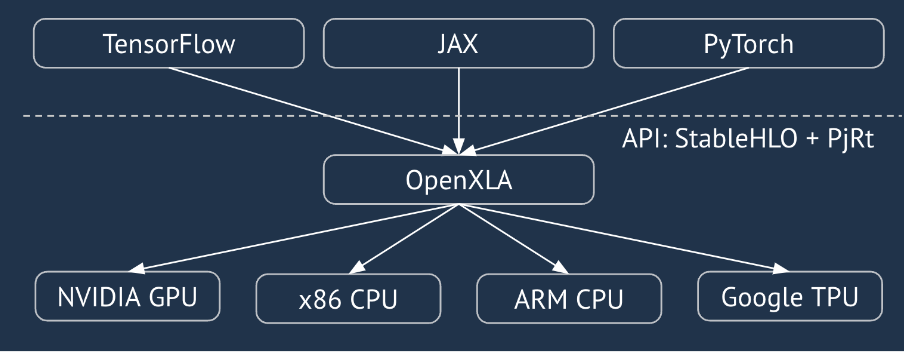
Trong quá trình thực thi, các khung sẽ gọi API thời gian chạy PJRT, cho phép các khung thực hiện thao tác "điền vào các vùng đệm đã chỉ định bằng một chương trình StableHLO nhất định trên một thiết bị cụ thể".
XLA:GPU Pipeline
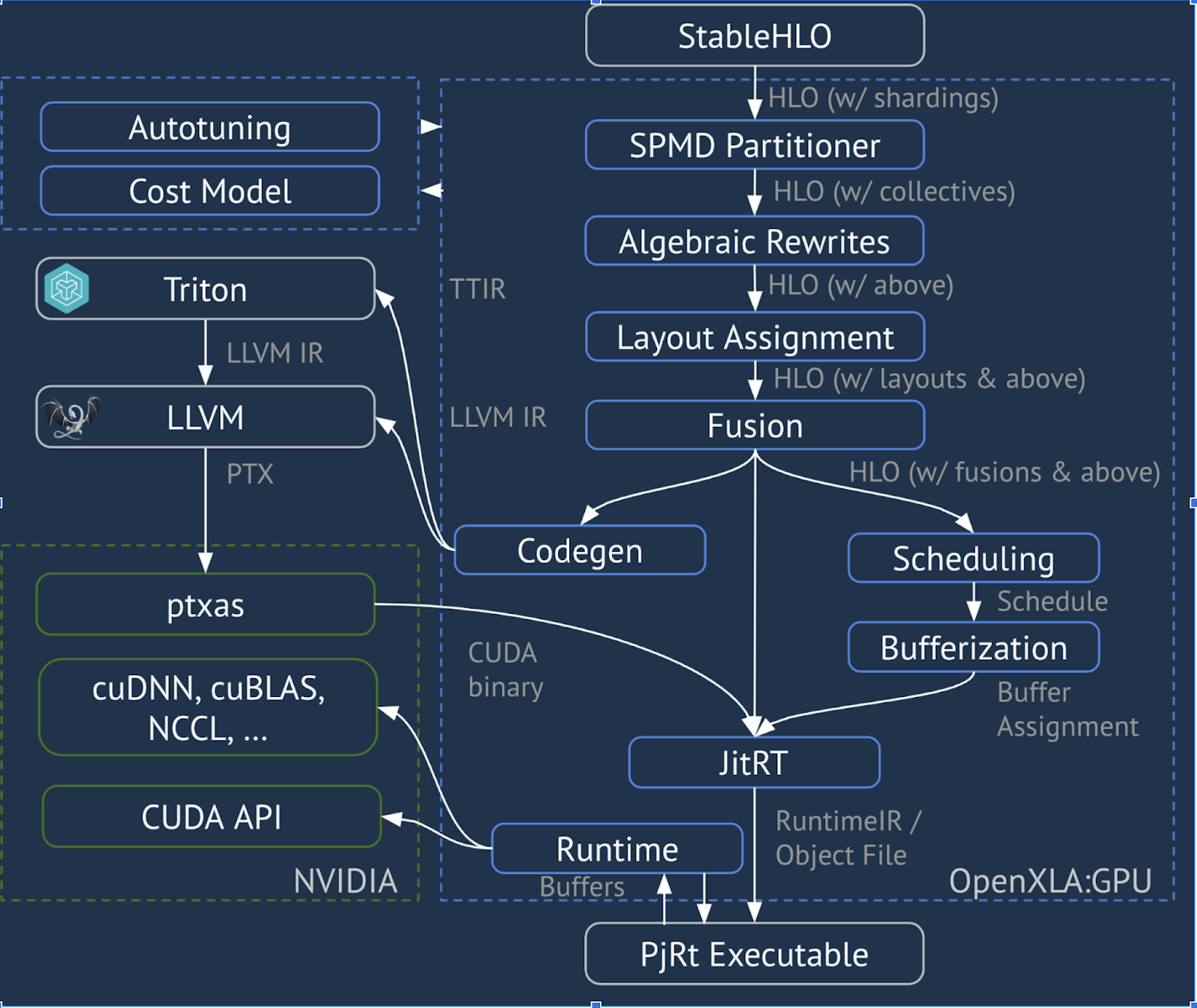
XLA:GPU sử dụng kết hợp các trình phát "gốc" (PTX, thông qua LLVM) và trình phát TritonIR để tạo các nhân GPU hiệu suất cao (màu xanh dương cho biết các thành phần 3P):
Ví dụ đang chạy: JAX
Để minh hoạ quy trình, hãy bắt đầu bằng một ví dụ đang chạy trong JAX, trong đó tính toán một matmul kết hợp với phép nhân theo hằng số và phép phủ định:
def f(a, b):
return -((a @ b) * 0.125)
Chúng ta có thể kiểm tra HLO do hàm này tạo ra:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
tạo ra:
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
Chúng ta cũng có thể trực quan hoá quá trình tính toán HLO đầu vào bằng cách sử dụng jax.xla_computation(f)(a, b).as_hlo_dot_graph():
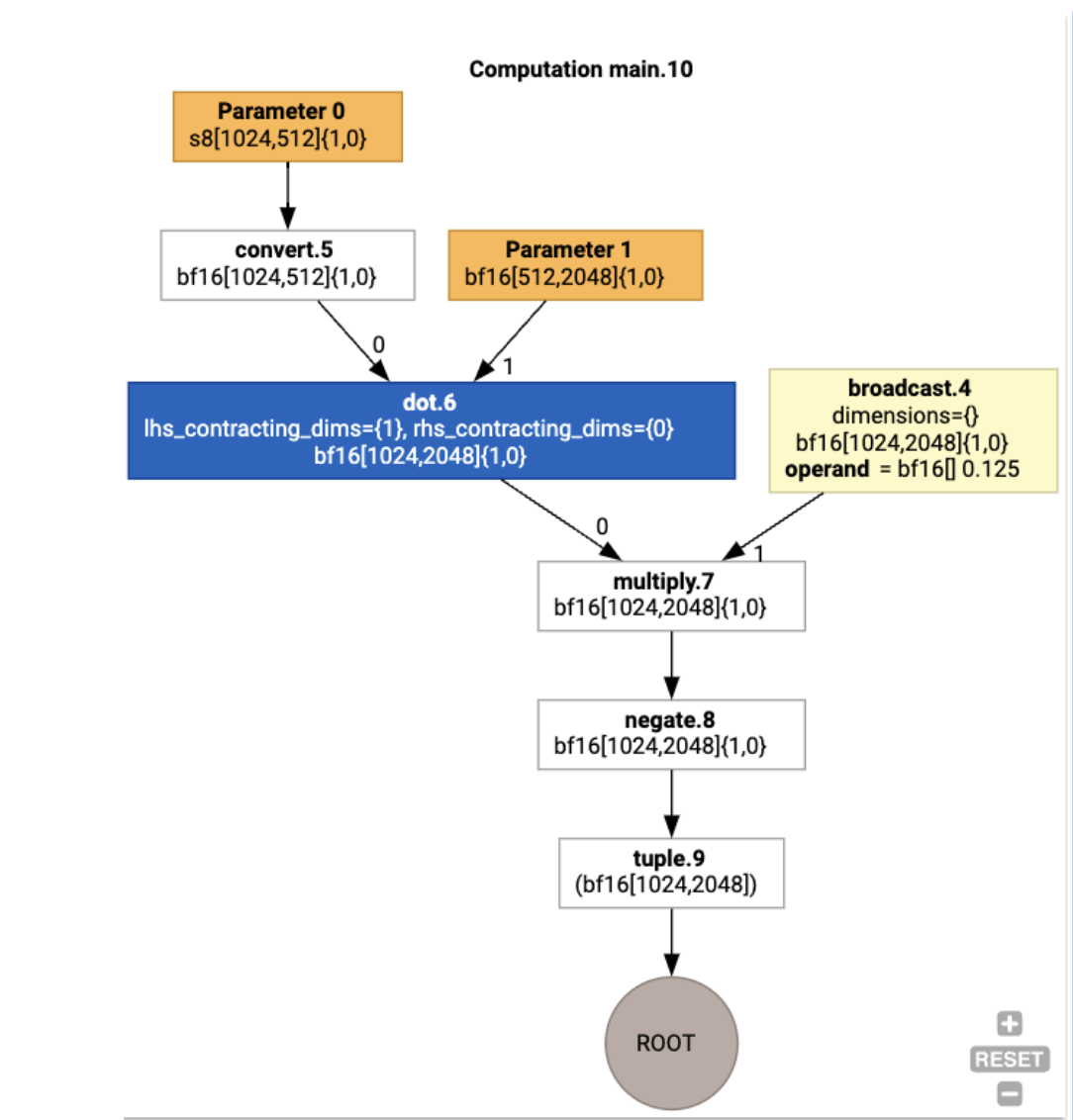
Tối ưu hoá trên HLO: Các thành phần chính
Một số lượt tối ưu hoá đáng chú ý xảy ra trên HLO, dưới dạng ghi lại HLO->HLO.
Trình phân vùng SPMD
Trình phân vùng XLA SPMD, như mô tả trong GSPMD: General and Scalable Parallelization for MLComputation Graphs, tiêu thụ HLO bằng chú thích phân mảnh (do jax.pjit tạo ra, chẳng hạn) và tạo ra một HLO được phân mảnh, sau đó có thể chạy trên một số máy chủ và thiết bị.
Ngoài việc phân vùng, SPMD còn cố gắng tối ưu hoá HLO để có lịch trình thực thi tối ưu, tính toán chồng chéo và giao tiếp giữa các nút.
Ví dụ:
Hãy cân nhắc bắt đầu từ một chương trình JAX đơn giản được phân mảnh trên 2 thiết bị:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
Khi trực quan hoá, chú thích phân đoạn được trình bày dưới dạng các lệnh gọi tuỳ chỉnh:
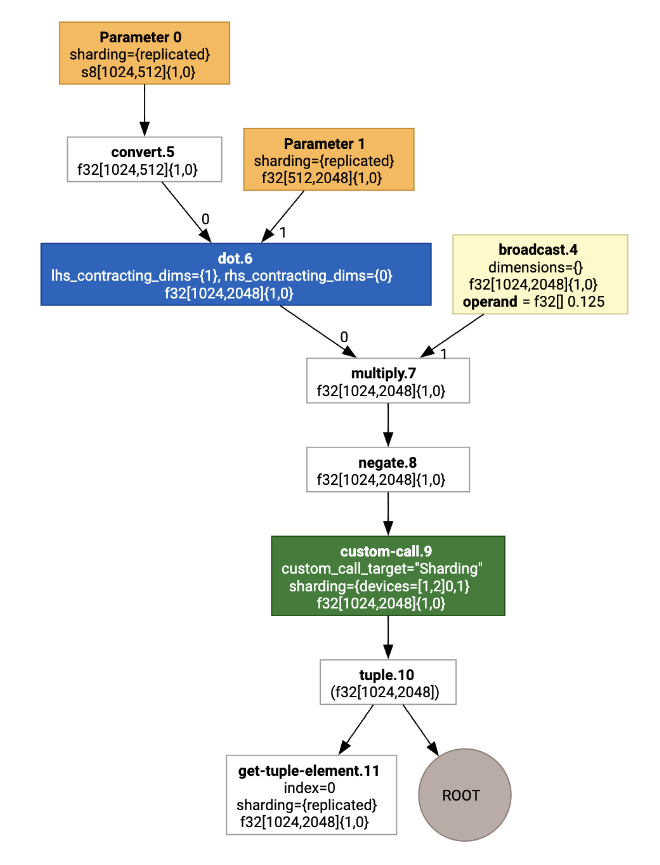
Để kiểm tra cách trình phân vùng SPMD mở rộng lệnh gọi tuỳ chỉnh, chúng ta có thể xem HLO sau khi tối ưu hoá:
print(f.lower(np.ones((8, 8)).compile().as_text())
Thao tác này sẽ tạo ra HLO với một tập hợp:
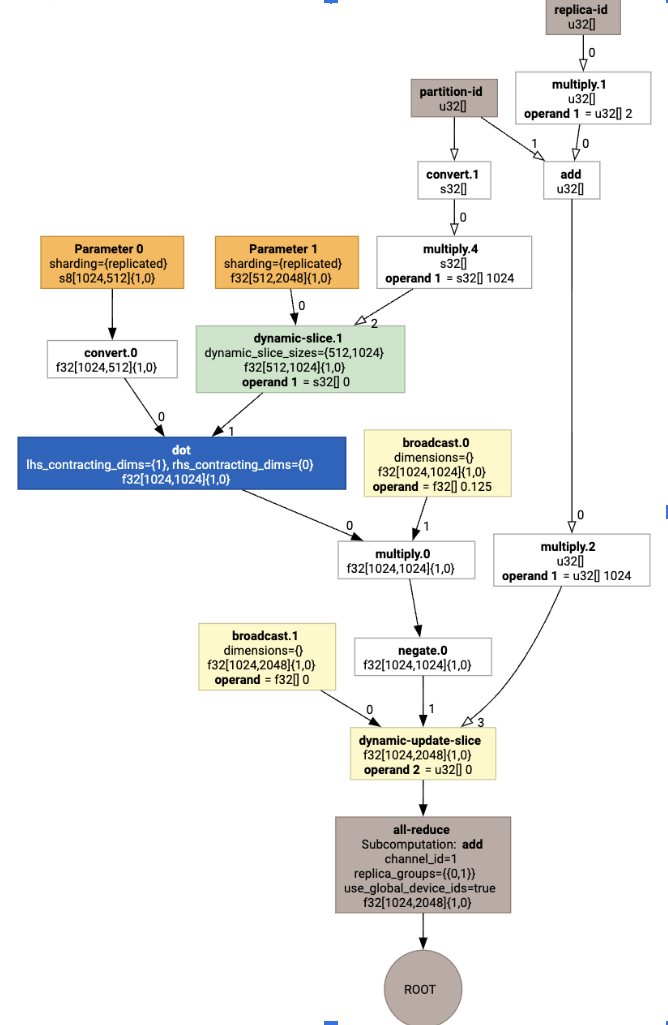
Chỉ định bố cục
HLO tách rời hình dạng logic và bố cục vật lý (cách các tensor được bố trí trong bộ nhớ). Ví dụ: ma trận f32[32, 64] có thể được biểu thị theo thứ tự hàng chính hoặc cột chính, lần lượt được biểu thị là {1,0} hoặc {0,1}.
Nói chung, bố cục được biểu thị dưới dạng một phần của hình dạng, cho thấy một hoán vị trên số lượng phương diện cho biết bố cục thực tế trong bộ nhớ.
Đối với mỗi thao tác có trong HLO, Layout Assignment pass sẽ chọn một bố cục tối ưu (ví dụ: NHWC cho một phép tích chập trên Ampere). Ví dụ: thao tác int8xint8->int32 matmul ưu tiên bố cục {0,1} cho RHS của phép tính. Tương tự, các "chuyển vị" do người dùng chèn sẽ bị bỏ qua và được mã hoá dưới dạng thay đổi bố cục.
Sau đó, các bố cục sẽ được truyền qua biểu đồ và các xung đột giữa các bố cục hoặc tại các điểm cuối của biểu đồ sẽ được hiện thực hoá dưới dạng các thao tác copy, thực hiện việc chuyển vị vật lý. Ví dụ: bắt đầu từ biểu đồ
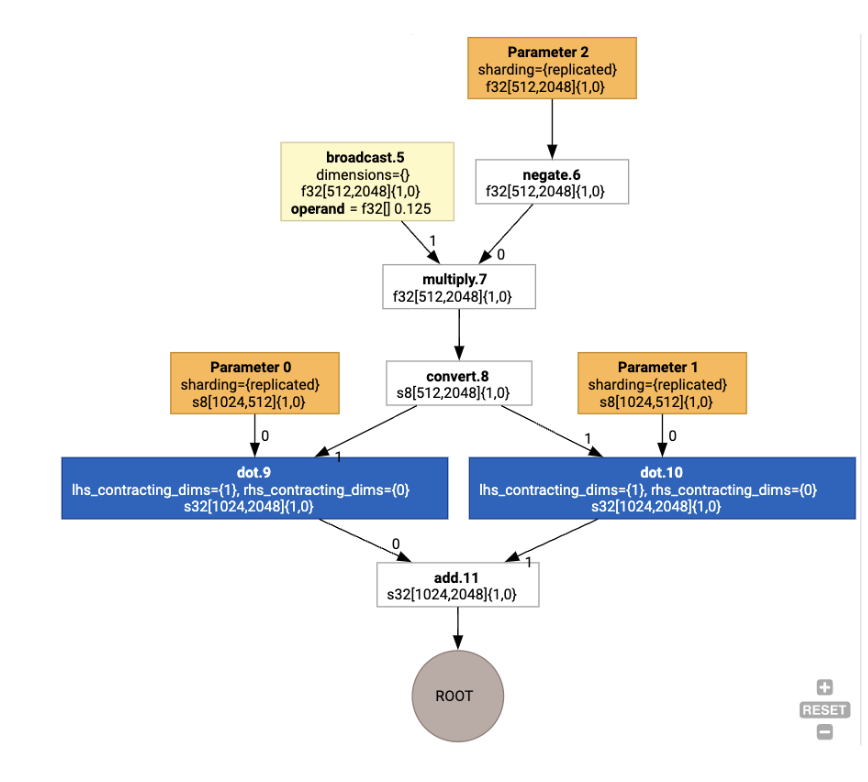
Khi chạy thao tác chỉ định bố cục, chúng ta sẽ thấy các bố cục và thao tác copy sau đây được chèn:
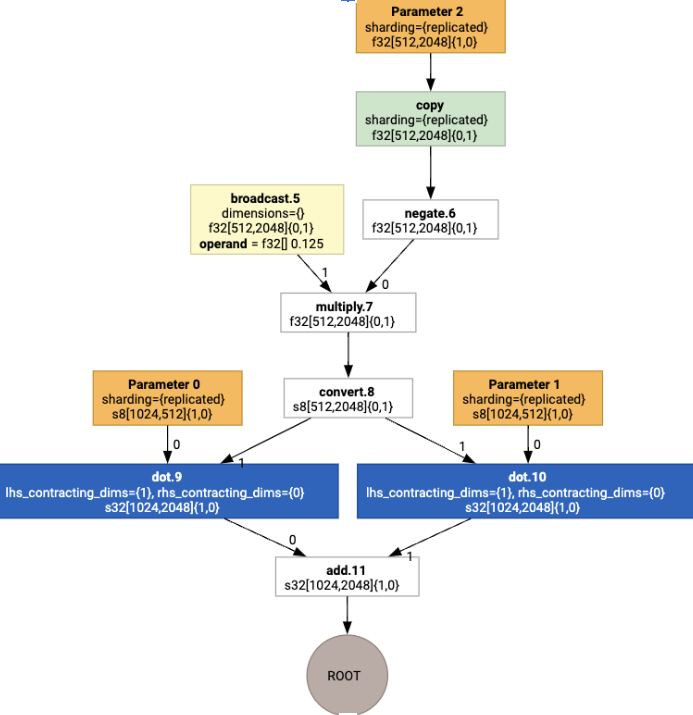
Món ăn hỗn hợp
Hợp nhất là hoạt động tối ưu hoá quan trọng nhất của XLA, nhóm nhiều thao tác (ví dụ: cộng vào hàm mũ vào matmul) thành một hạt nhân duy nhất. Vì nhiều khối lượng công việc của GPU có xu hướng bị giới hạn về bộ nhớ, nên việc hợp nhất sẽ tăng tốc đáng kể quá trình thực thi bằng cách tránh ghi các tensor trung gian vào HBM rồi đọc lại chúng, thay vào đó, hãy truyền chúng trong các thanh ghi hoặc bộ nhớ dùng chung.
Các chỉ dẫn HLO kết hợp được chặn cùng nhau trong một phép tính kết hợp duy nhất, thiết lập các bất biến sau:
Không có bộ nhớ trung gian nào bên trong quá trình hợp nhất được hiện thực hoá trong HBM (tất cả đều phải được truyền qua các thanh ghi hoặc bộ nhớ dùng chung).
Một hợp nhất luôn được biên dịch thành chính xác một hạt nhân GPU
Tối ưu hoá HLO trên ví dụ đang chạy
Chúng ta có thể kiểm tra HLO sau khi tối ưu hoá bằng cách sử dụng jax.jit(f).lower(a,
b).compile().as_text() và xác minh rằng một hoạt động hợp nhất duy nhất đã được tạo:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
Xin lưu ý rằng việc hợp nhất backend_config cho chúng ta biết rằng Triton sẽ được dùng làm chiến lược tạo mã và chỉ định việc phân ô được chọn.
Chúng ta cũng có thể hình dung mô-đun kết quả:
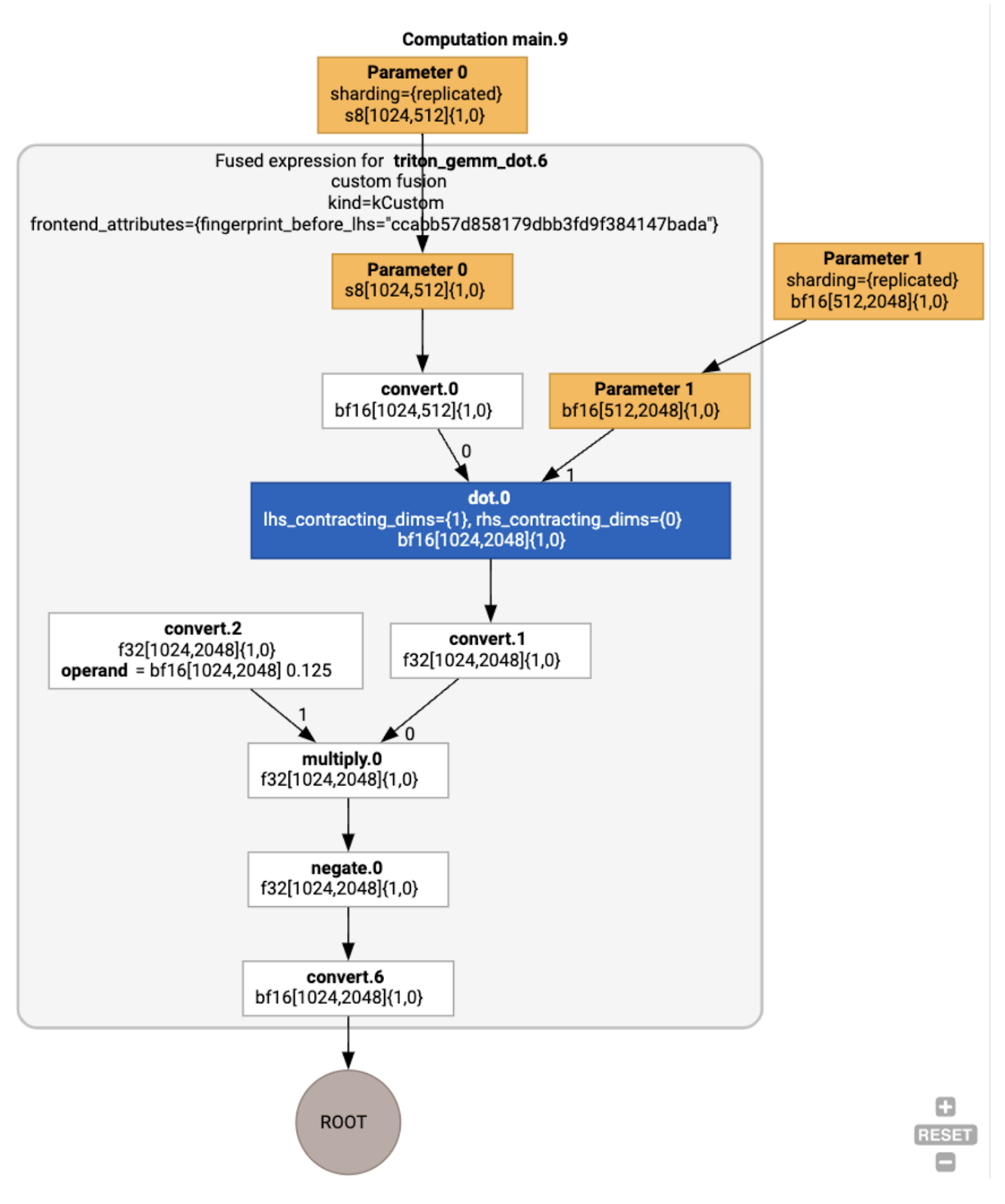
Phân công và lập lịch vùng đệm
Một lượt gán vùng đệm sẽ xem xét thông tin về hình dạng và nhằm mục đích tạo ra một hoạt động phân bổ vùng đệm tối ưu cho chương trình, giảm thiểu lượng bộ nhớ trung gian được sử dụng. Không giống như quá trình thực thi ở chế độ tức thì (chưa được biên dịch) của TF hoặc PyTorch, trong đó trình phân bổ bộ nhớ không biết trước đồ thị, trình lập lịch XLA có thể "nhìn vào tương lai" và tạo ra một lịch tính toán tối ưu.
Phần phụ trợ của trình biên dịch: Codegen và lựa chọn thư viện
Đối với mọi chỉ dẫn HLO trong quá trình tính toán, XLA sẽ chọn xem có chạy chỉ dẫn đó bằng thư viện được liên kết với thời gian chạy hay không, hoặc có tạo mã cho chỉ dẫn đó thành PTX hay không.
Lựa chọn trong thư viện
Đối với nhiều thao tác phổ biến, XLA:GPU sử dụng các thư viện hiệu suất cao của NVIDIA, chẳng hạn như cuBLAS, cuDNN và NCCL. Các thư viện này có ưu điểm là hiệu suất nhanh đã được xác minh, nhưng thường loại trừ các cơ hội hợp nhất phức tạp.
Tạo mã trực tiếp
Phần phụ trợ XLA:GPU tạo LLVM IR hiệu suất cao trực tiếp cho một số thao tác (giảm, chuyển vị, v.v.).
Tạo mã Triton
Đối với các hoạt động hợp nhất nâng cao hơn, bao gồm phép nhân ma trận hoặc softmax, XLA:GPU sử dụng Triton làm lớp tạo mã. Hợp nhất HLO được chuyển đổi thành TritonIR (một phương ngữ MLIR đóng vai trò là đầu vào cho Triton), chọn các tham số phân chia và gọi Triton để tạo PTX:
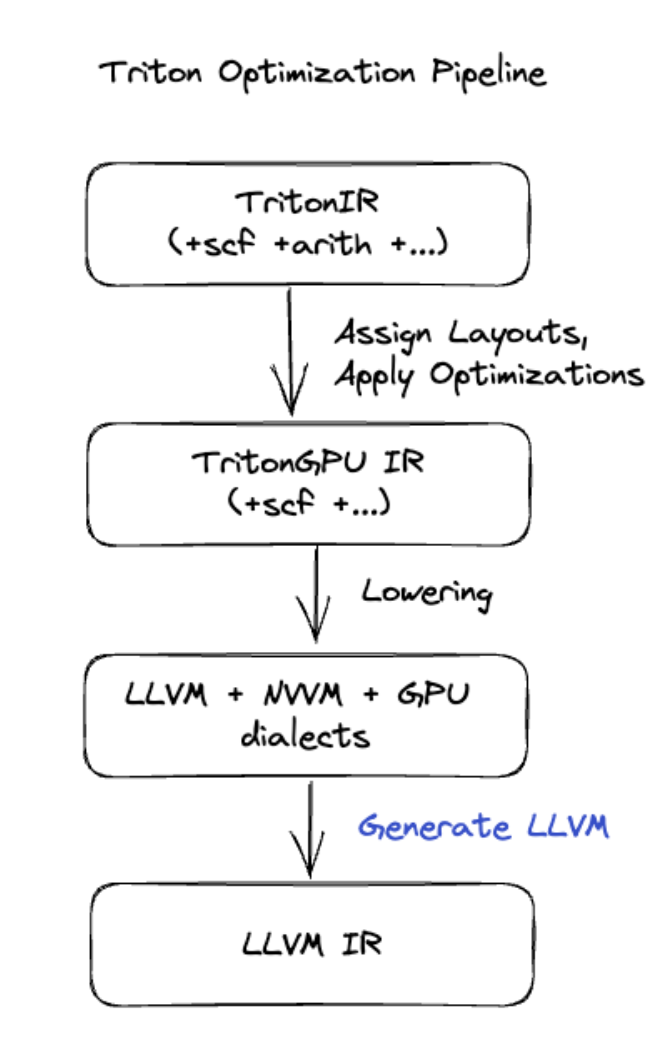
Chúng tôi nhận thấy mã kết quả hoạt động rất tốt trên Ampere, gần đạt hiệu suất tối đa với kích thước ô được điều chỉnh đúng cách.
Thời gian chạy
XLA Runtime chuyển đổi chuỗi lệnh gọi hạt nhân CUDA và lệnh gọi thư viện thu được thành RuntimeIR (một phương ngữ MLIR trong XLA), trên đó quá trình trích xuất biểu đồ CUDA được thực hiện. Biểu đồ CUDA vẫn đang trong quá trình phát triển, hiện chỉ hỗ trợ một số nút. Sau khi trích xuất ranh giới đồ thị CUDA, RuntimeIR sẽ được biên dịch thông qua LLVM thành một tệp thực thi CPU, sau đó có thể được lưu trữ hoặc chuyển để biên dịch Trước thời gian chạy.