
简介
XLA 是一种针对特定领域(硬件和框架)的线性代数编译器,可提供出色的性能。JAX、TF、Pytorch 等通过将用户输入转换为 StableHLO(“高级别操作”:一组大约 100 个静态形状的指令,例如加法、减法、matmul 等)操作集来使用 XLA,XLA 从中为各种后端生成优化后的代码:
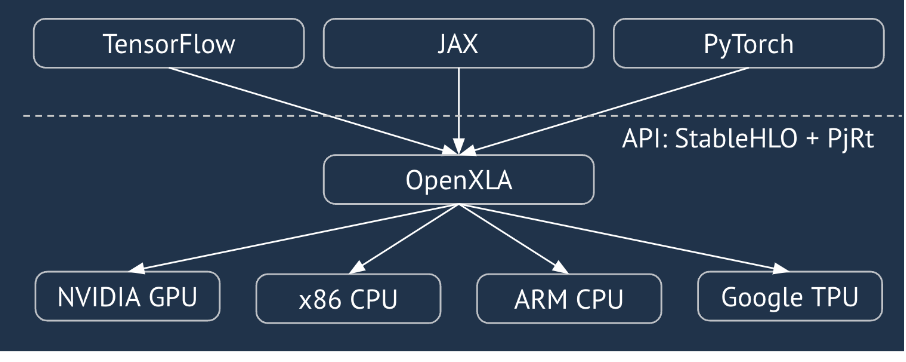
在执行期间,框架会调用 PJRT 运行时 API,从而让框架执行“在特定设备上使用给定的 StableHLO 程序填充指定缓冲区”的操作。
XLA:GPU 流水线
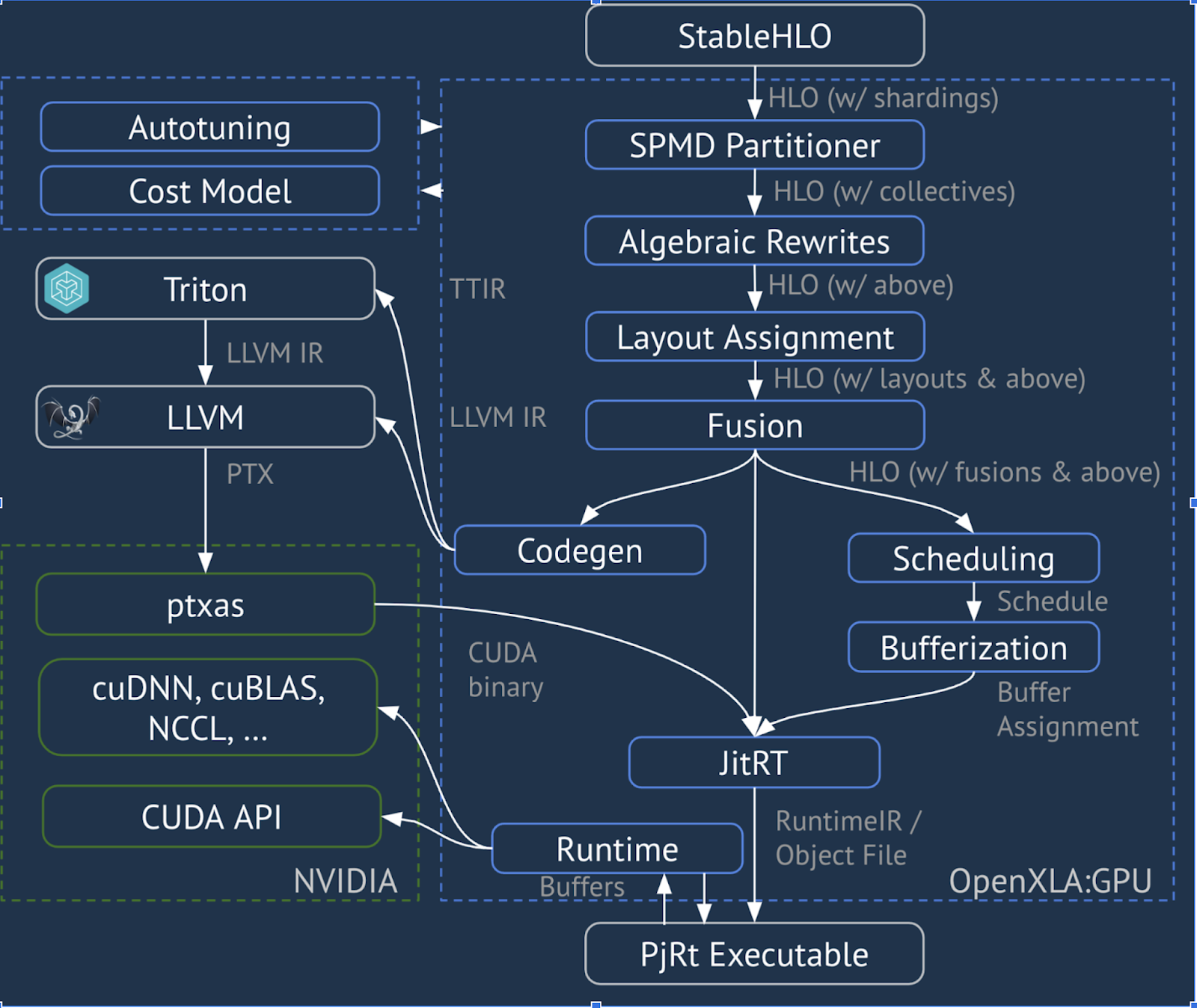
XLA:GPU 结合使用“原生”(通过 LLVM 的 PTX)发射器和 TritonIR 发射器来生成高性能 GPU 内核(蓝色表示第三方组件):
运行示例:JAX
为了说明流水线,我们先来看一个 JAX 中的运行示例,该示例计算了与乘以常数和取反相结合的矩阵乘法:
def f(a, b):
return -((a @ b) * 0.125)
我们可以检查该函数生成的 HLO:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
这会生成:
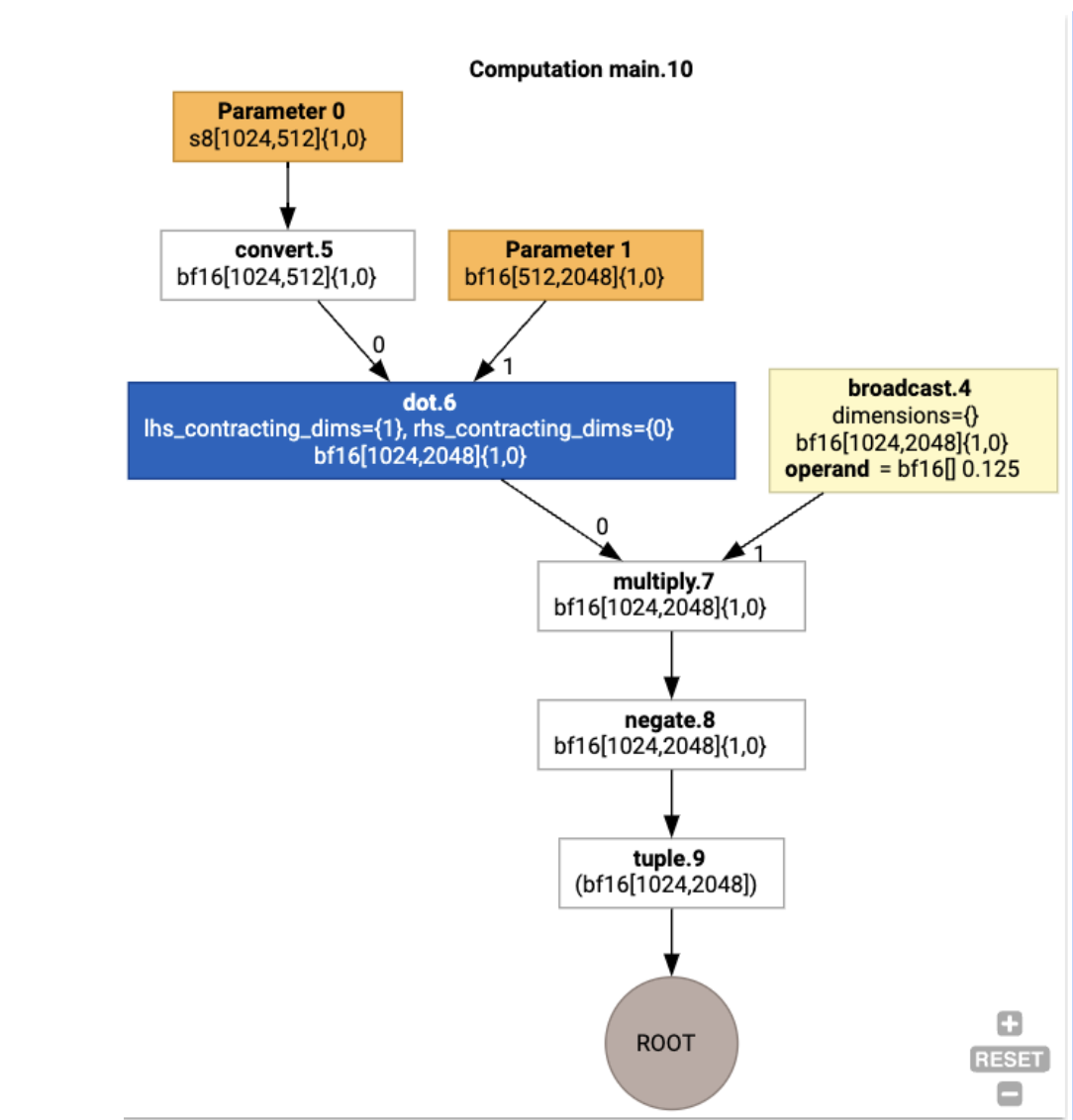
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
我们还可以使用 jax.xla_computation(f)(a, b).as_hlo_dot_graph() 直观呈现输入 HLO 计算:
HLO 优化:关键组件
许多值得注意的优化传递都发生在 HLO 上,作为 HLO->HLO 重写。
SPMD 分区器
如 GSPMD:用于机器学习计算图的通用且可伸缩的并行化中所述,XLA SPMD 分区器会使用带有分片注释(例如由 jax.pjit 生成)的 HLO,并生成分片的 HLO,然后该 HLO 可以在多个主机和设备上运行。除了分区之外,SPMD 还尝试优化 HLO,以实现最佳执行时间表,重叠节点之间的计算和通信。
示例
不妨从一个简单的 JAX 程序开始,该程序在两个设备之间进行分片:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
直观地来看,分片注释会显示为自定义调用:
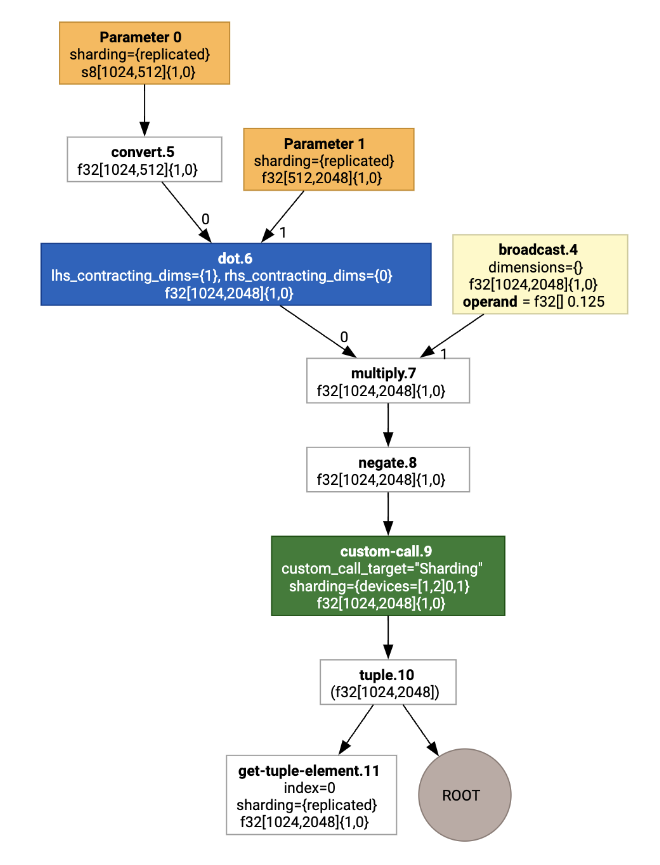
为了检查 SPMD 分区器如何扩展自定义调用,我们可以查看优化后的 HLO:
print(f.lower(np.ones((8, 8)).compile().as_text())
这会生成带有集合的 HLO:
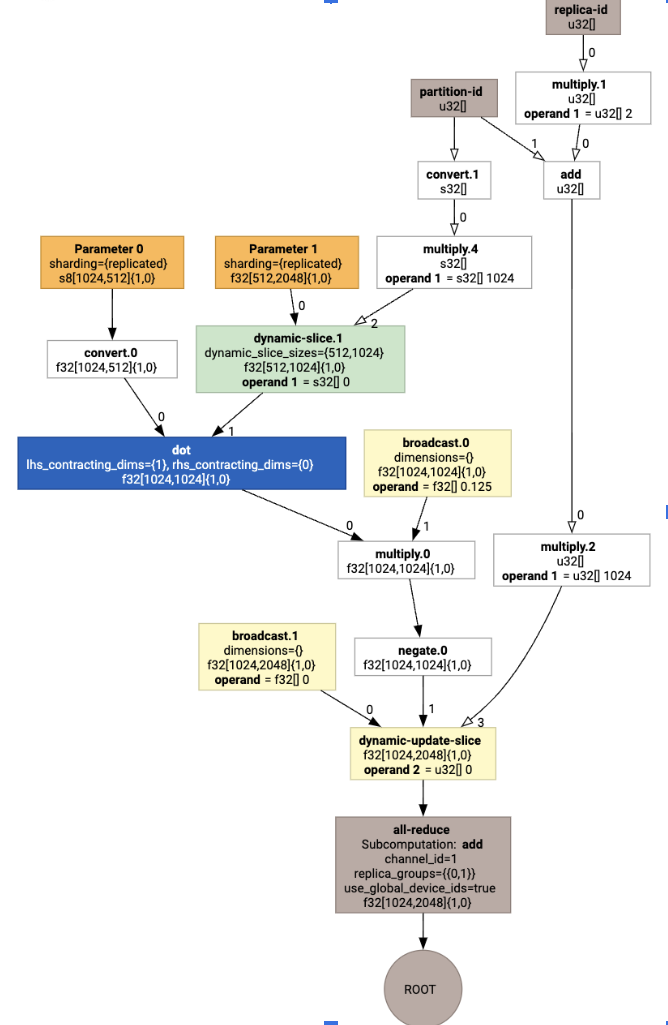
布局分配
HLO 可将逻辑形状与物理布局(张量在内存中的布局方式)分离。例如,矩阵 f32[32, 64] 可以按行优先顺序或列优先顺序表示,分别表示为 {1,0} 或 {0,1}。一般来说,布局表示为形状的一部分,显示内存中指示物理布局的维度数量的排列。
对于 HLO 中的每个操作,布局分配传递会选择最佳布局(例如,Ampere 上卷积的 NHWC)。例如,int8xint8->int32 matmul 操作偏好于使用 {0,1} 布局进行计算的 RHS。同样,用户插入的“转置”会被忽略,并编码为布局更改。
然后,布局会通过图进行传播,布局之间或图端点处的冲突会具体化为 copy 操作,这些操作会执行物理转置。例如,从图表开始
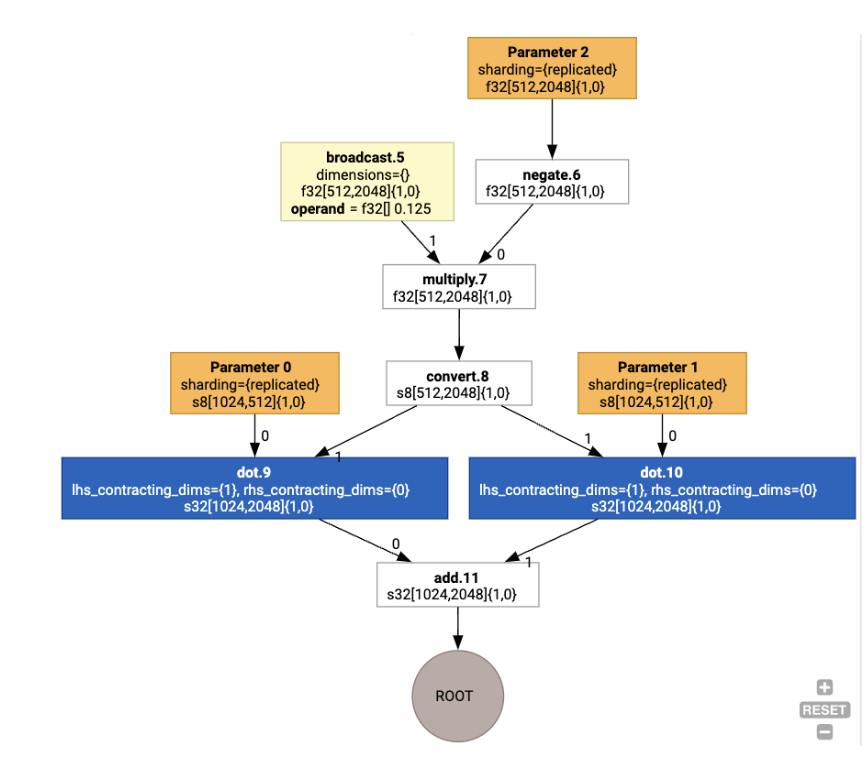
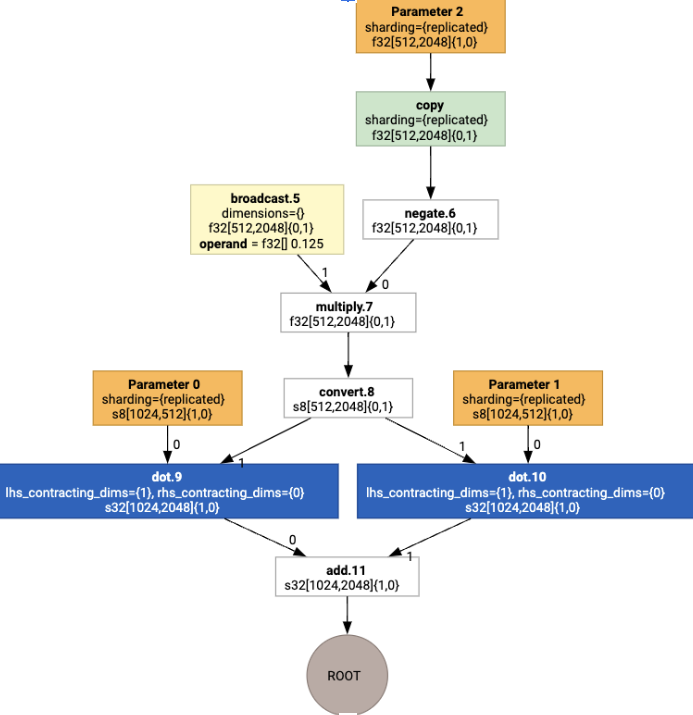
运行布局分配后,我们会看到以下布局和插入的 copy 操作:
Fusion
融合是 XLA 采用的最重要的一项优化措施,它将多个操作(例如加法、指数运算、matmul)分组到一个内核中。由于许多 GPU 工作负载往往受内存限制,融合通过避免将中间张量写入 HBM 然后再读回,而是通过在寄存器或共享内存中传递它们,从而显著加快了执行速度。
融合的 HLO 指令在单个融合计算中一起被屏蔽,从而建立以下不变量:
融合内部没有在 HBM 中具体化的中间存储空间(必须全部通过寄存器或共享内存传递)。
融合始终编译为恰好一个 GPU 内核
运行示例中的 HLO 优化
我们可以使用 jax.jit(f).lower(a,
b).compile().as_text() 检查优化后的 HLO,并验证是否生成了单个融合:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
请注意,融合 backend_config 表明 Triton 将用作代码生成策略,并指定所选的平铺。
我们还可以直观呈现生成的模块:
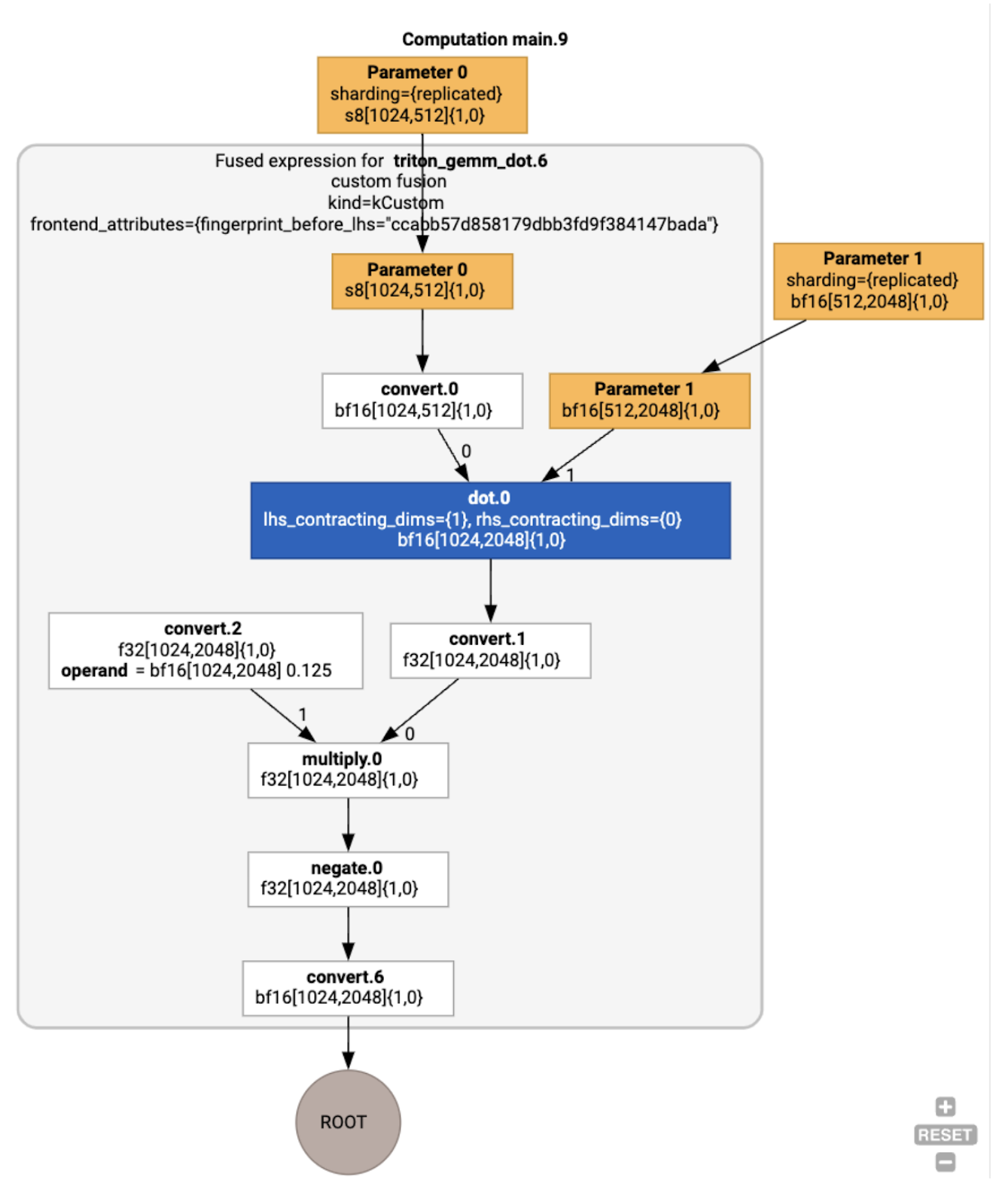
缓冲区分配和调度
缓冲区分配传递会考虑形状信息,并旨在为程序生成最佳缓冲区分配,从而最大限度地减少所消耗的中间内存量。与 TF 或 PyTorch 立即模式(非编译)执行不同,在后一种模式下,内存分配器无法提前了解图,而 XLA 调度器可以“预见未来”,并生成最佳计算调度。
编译器后端:代码生成和库选择
对于计算中的每个 HLO 指令,XLA 会选择是使用关联到运行时的库来运行它,还是将其代码生成为 PTX。
媒体库选择
对于许多常见操作,XLA:GPU 使用 NVIDIA 的高性能库,例如 cuBLAS、cuDNN 和 NCCL。这些库的优势在于经过验证的快速性能,但往往会排除复杂的融合机会。
直接生成代码
XLA:GPU 后端直接为许多操作(归约、转置等)生成高性能 LLVM IR。
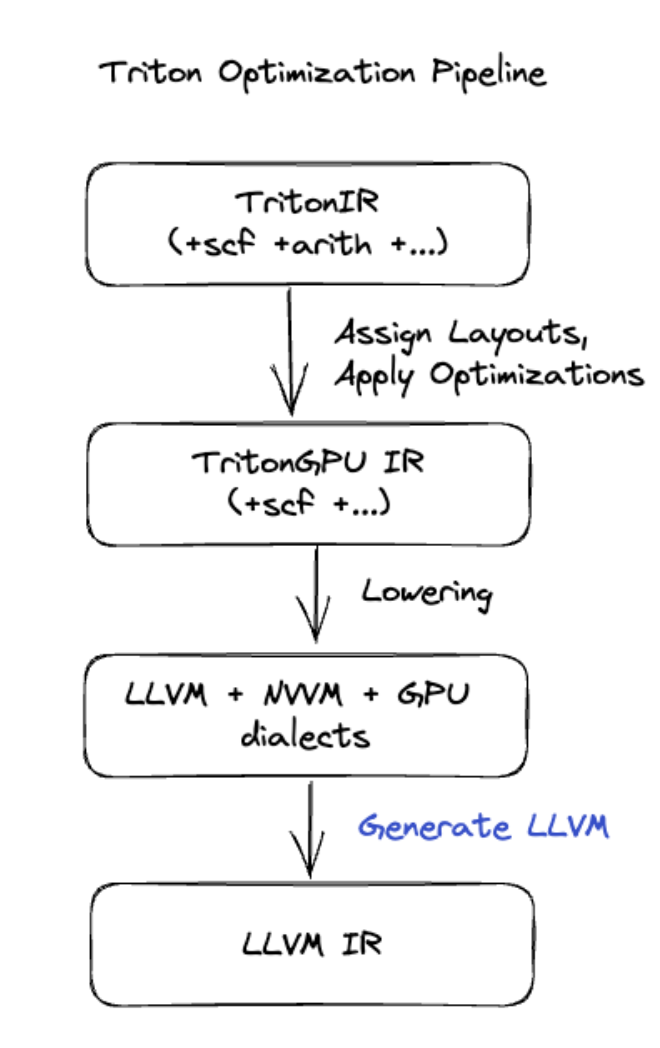
Triton 代码生成
对于包含矩阵乘法或 softmax 的更高级融合,XLA:GPU 使用 Triton 作为代码生成层。HLO Fusion 会转换为 TritonIR(一种用作 Triton 输入的 MLIR 方言),选择平铺参数并调用 Triton 以生成 PTX:
我们观察到,在 Ampere 上,经过适当调整的 tile 大小可使生成的代码达到接近屋顶线的性能。
运行时
XLA 运行时会将生成的 CUDA 内核调用和库调用序列转换为 RuntimeIR(XLA 中的一种 MLIR 方言),然后对该 RuntimeIR 执行 CUDA 图提取。CUDA 图仍在开发中,目前仅支持部分节点。提取 CUDA 图边界后,通过 LLVM 将 RuntimeIR 编译为 CPU 可执行文件,然后可以存储或转移该文件以进行预先编译。