
簡介
XLA 是適用於硬體和架構領域的線性代數專用編譯器,可提供頂尖效能。JAX、TF、PyTorch 等會將使用者輸入內容轉換為 StableHLO (「高階運算」:一組約 100 個靜態形狀指令,例如加法、減法、matmul 等) 運算集,XLA 會從中為各種後端產生最佳化程式碼:
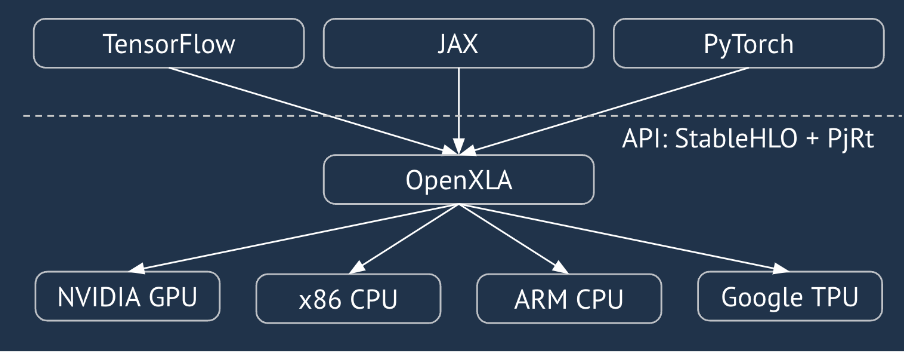
執行期間,架構會叫用 PJRT 執行階段 API,讓架構執行「在特定裝置上使用指定 StableHLO 程式填入指定緩衝區」作業。
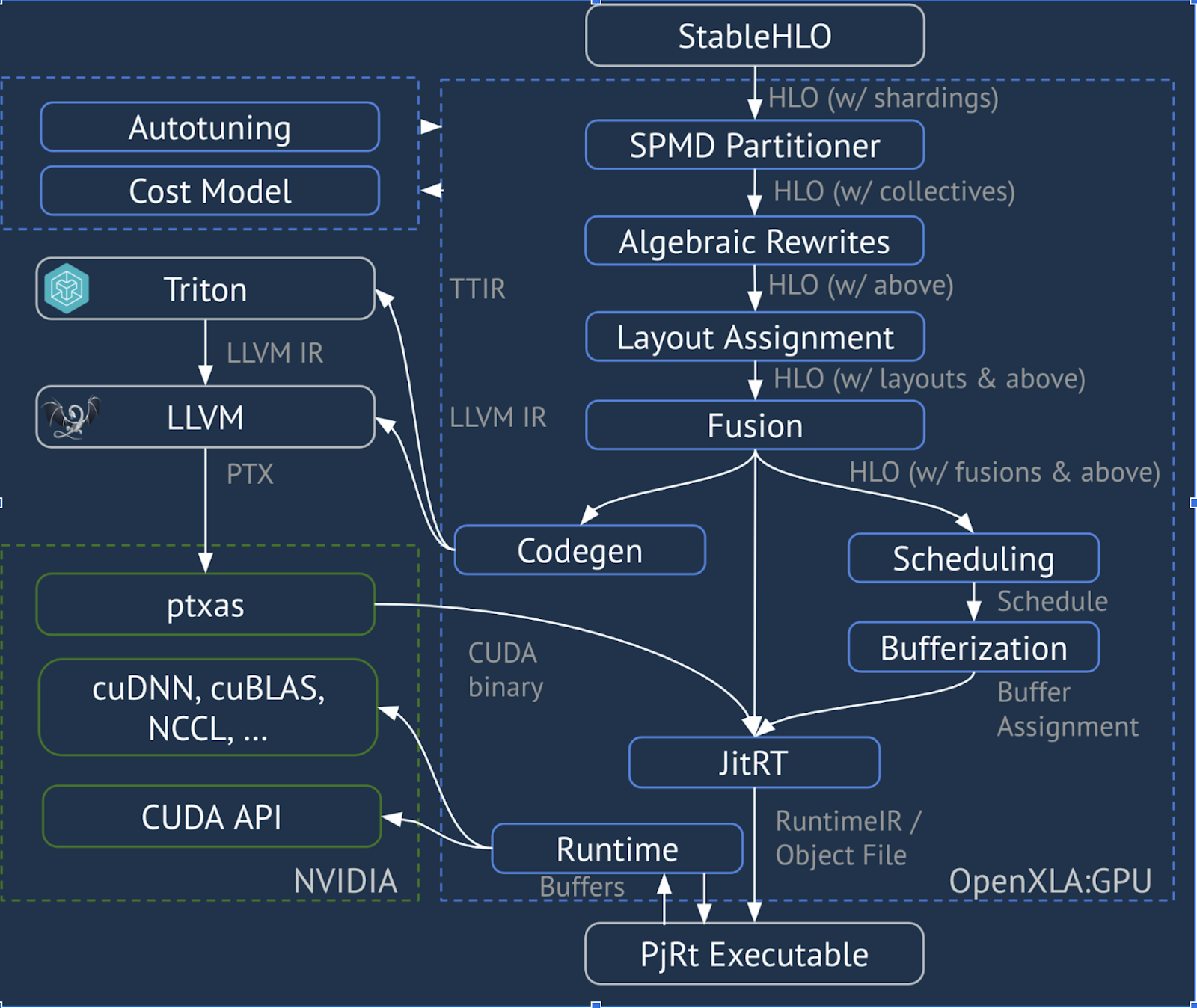
XLA:GPU 管道
XLA:GPU 會結合使用「原生」(透過 LLVM 的 PTX) 發射器和 TritonIR 發射器,產生高效能 GPU 核心 (藍色表示第三方元件):
執行範例:JAX
為說明管線,我們先從 JAX 中的執行範例開始,該範例會計算 matmul,並結合常數乘法和否定:
def f(a, b):
return -((a @ b) * 0.125)
我們可以檢查函式產生的 HLO:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
這會產生:
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
我們也可以使用 jax.xla_computation(f)(a, b).as_hlo_dot_graph(),將輸入 HLO 的運算結果視覺化:
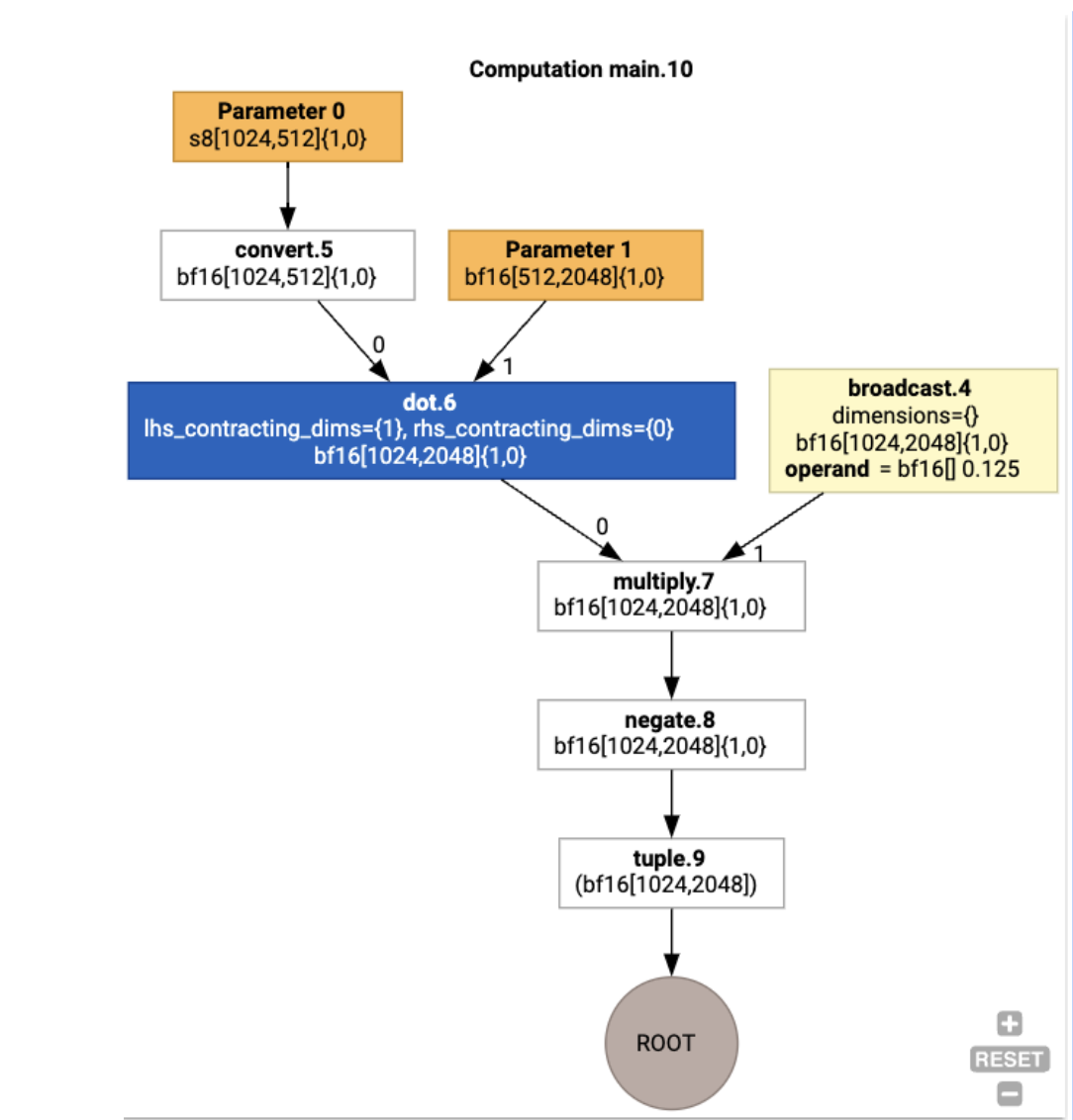
HLO 最佳化:重要元件
HLO 上會進行多項重要的最佳化傳遞作業,例如 HLO->HLO 重寫。
SPMD Partitioner
如這篇論文所述,XLA SPMD 分區器會使用附有分片註解的 HLO (例如由 jax.pjit 產生),並產生分片 HLO,然後在多個主機和裝置上執行。除了分割之外,SPMD 還會嘗試將 HLO 最佳化,以取得最佳執行時間表、重疊運算,以及節點之間的通訊。
範例
不妨先從簡單的 JAX 程式開始,在兩部裝置之間分片:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
以視覺化方式呈現時,分片註解會顯示為自訂呼叫:
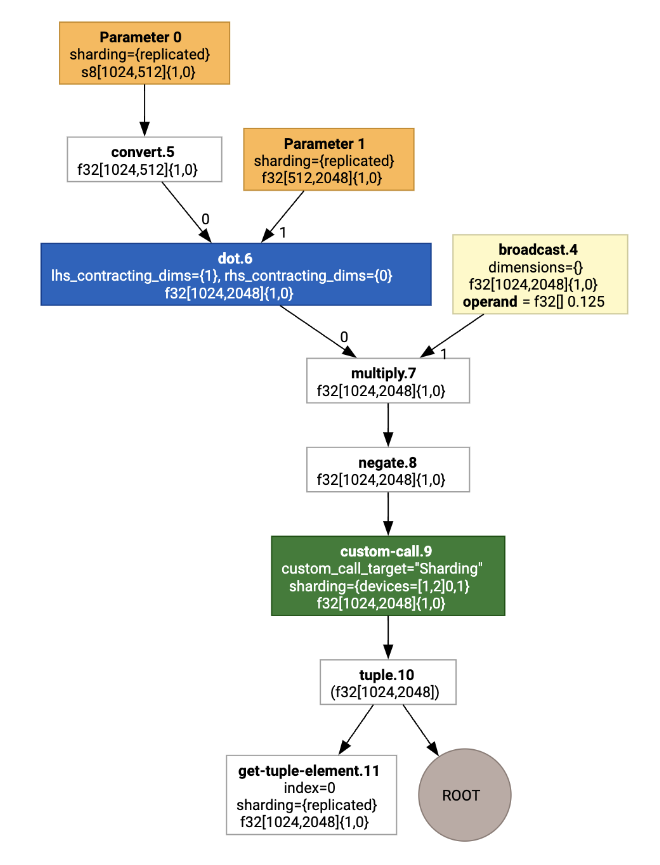
如要查看 SPMD 分割器如何擴充自訂呼叫,我們可以查看最佳化後的 HLO:
print(f.lower(np.ones((8, 8)).compile().as_text())
這會產生具有集合的 HLO:
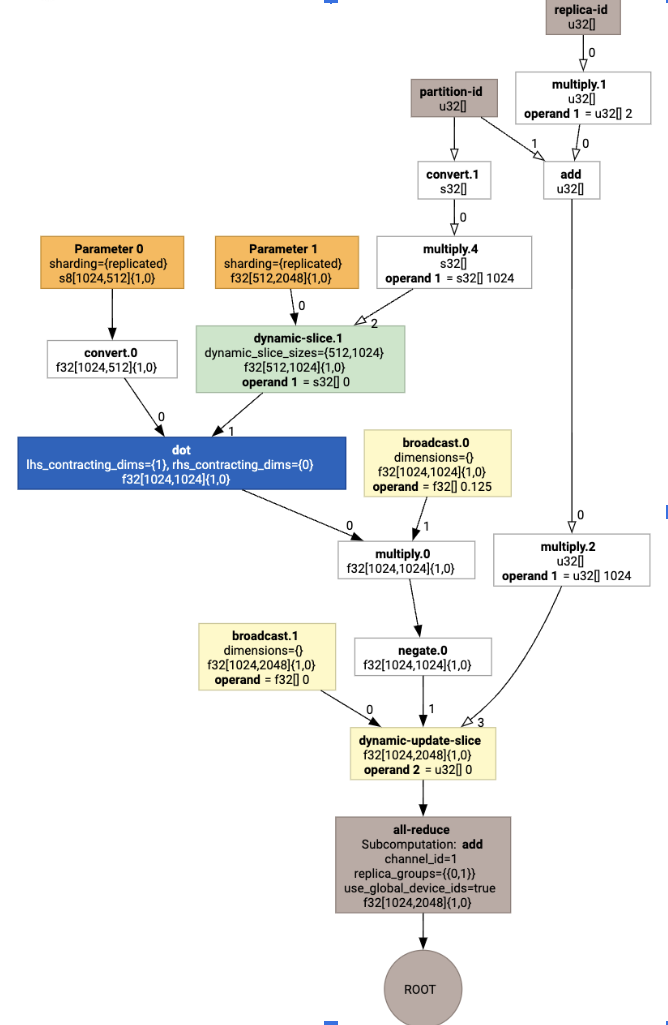
版面配置指派
HLO 會將邏輯形狀和實體版面配置 (張量在記憶體中的版面配置方式) 分開。舉例來說,矩陣 f32[32, 64] 可以列優先或欄優先順序表示,分別為 {1,0} 或 {0,1}。一般來說,版面配置會以形狀的一部分表示,顯示記憶體中實體版面配置的維度數量排列。
對於 HLO 中存在的每個作業,版面配置指派傳遞會選擇最佳版面配置 (例如 Ampere 上卷積的 NHWC)。舉例來說,int8xint8->int32 matmul 運算偏好使用 {0,1} 版面配置,做為計算的 RHS。同樣地,系統會忽略使用者插入的「轉置」,並編碼為版面配置變更。
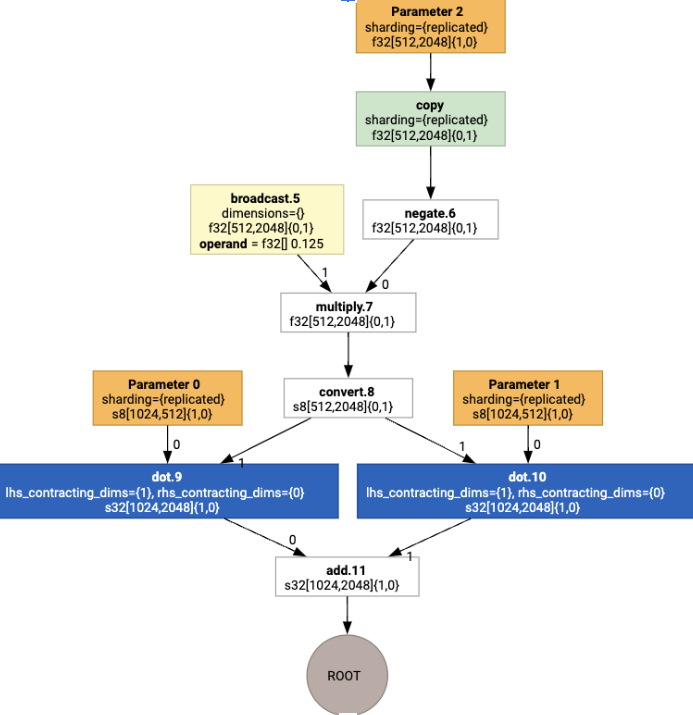
然後,版面配置會透過圖表傳播,版面配置之間或圖表端點的衝突會具體化為 copy 作業,執行實體轉置。舉例來說,從圖表開始
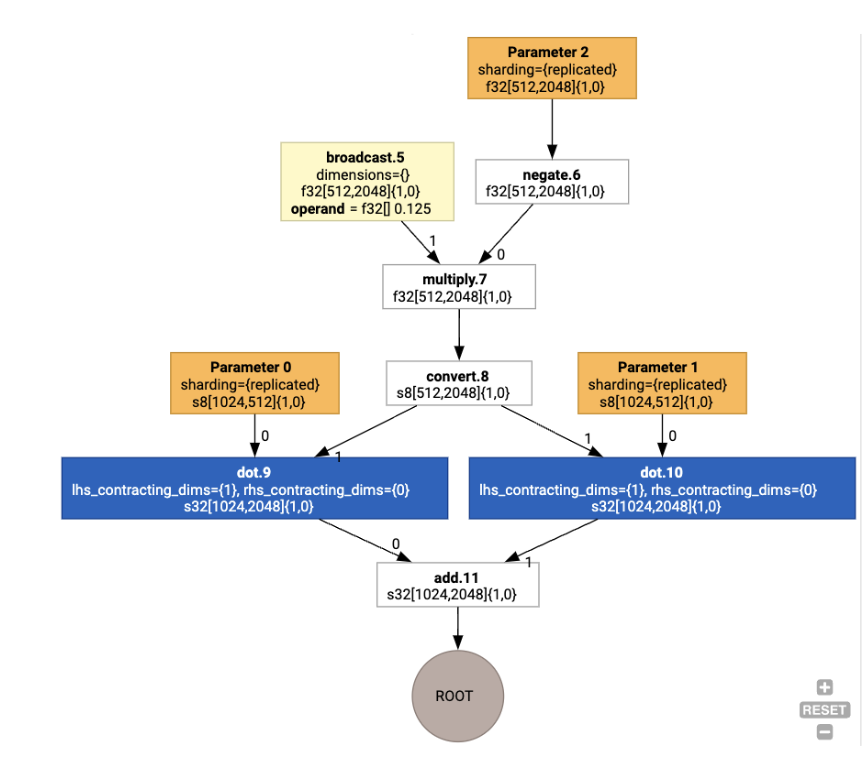
執行版面配置指派作業後,我們會看到下列版面配置和插入的 copy 作業:
Fusion
融合是 XLA 最重要的最佳化方式,可將多項運算 (例如加法、指數運算和矩陣乘法) 分組為單一核心。由於許多 GPU 工作負載往往會受到記憶體限制,因此融合可避免將中間張量寫入 HBM,然後再讀取回來,而是將張量傳遞至暫存器或共用記憶體,大幅加快執行速度。
融合的 HLO 指令會一起封鎖在單一融合運算中,這會建立下列不變量:
融合內部不會在 HBM 中具體化任何中繼儲存空間 (必須全部透過暫存器或共用記憶體傳遞)。
融合一律會編譯為一個 GPU 核心
執行範例的 HLO 最佳化
我們可以使用 jax.jit(f).lower(a,
b).compile().as_text() 檢查最佳化後的 HLO,並確認已產生單一融合:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
請注意,融合 backend_config 會告知我們 Triton 將做為程式碼生成策略,並指定所選的切片。
我們也可以將產生的模組視覺化:
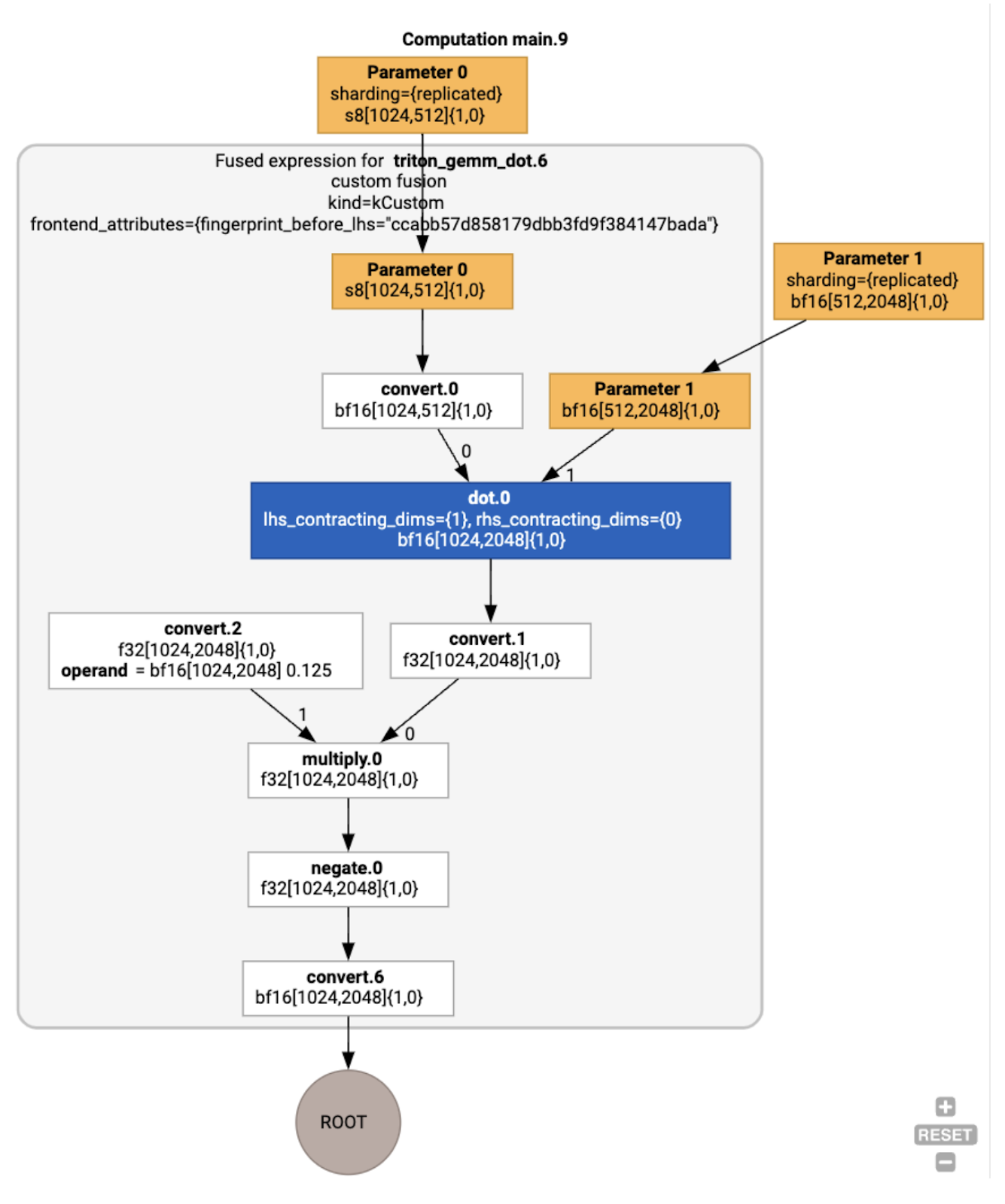
緩衝區指派與排程
緩衝區指派階段會考量形狀資訊,並盡可能為程式產生最佳緩衝區分配,盡量減少所耗用的中繼記憶體量。與 TF 或 PyTorch 即時模式 (未編譯) 執行作業不同,記憶體分配器不會預先知道圖表,但 XLA 排程器可以「預見未來」,並產生最佳的計算排程。
編譯器後端:程式碼產生和程式庫選取
對於運算中的每項 HLO 指令,XLA 會選擇使用連結至執行階段的程式庫執行,或是將其程式碼產生至 PTX。
選擇圖書館
對於許多常見作業,XLA:GPU 會使用 NVIDIA 的高效能程式庫,例如 cuBLAS、cuDNN 和 NCCL。這些程式庫的優點是經過驗證,效能快速,但往往會排除複雜的融合機會。
直接生成程式碼
XLA:GPU 後端會直接為多項作業 (縮減、轉置等) 生成高效能 LLVM IR。
生成 Triton 程式碼
如要進行更進階的融合 (包括矩陣乘法或 Softmax),XLA:GPU 會使用 Triton 做為程式碼產生層。HLO Fusion 會轉換為 TritonIR (做為 Triton 輸入內容的 MLIR 方言),選取分塊參數,並叫用 Triton 來產生 PTX:
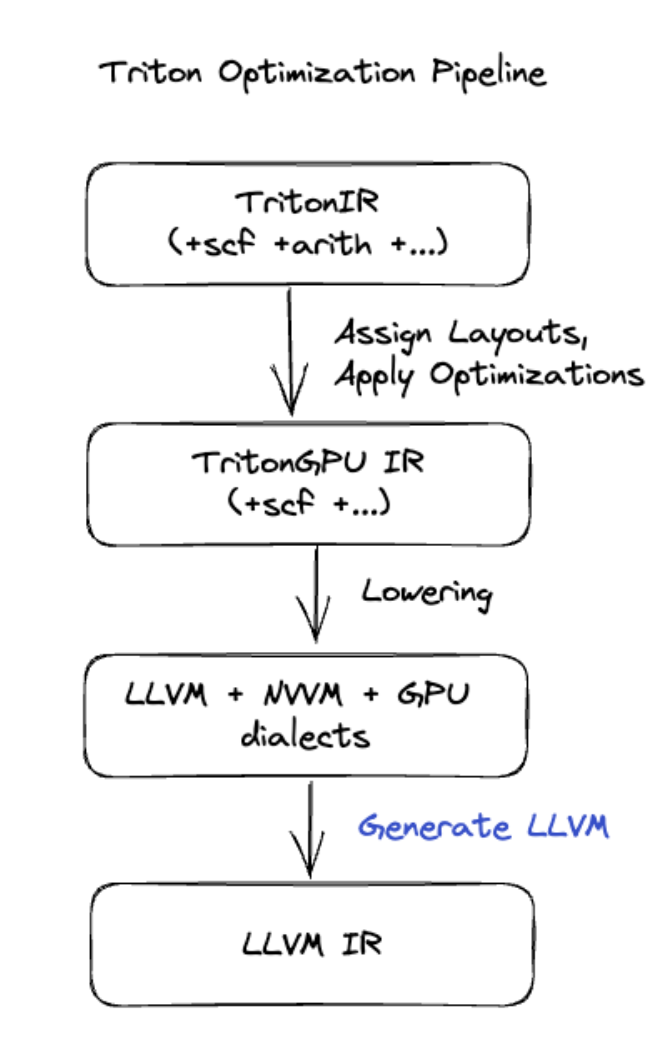
我們觀察到,在適當調整圖塊大小後,產生的程式碼在 Ampere 上的效能非常出色,接近最高效能。
執行階段
XLA 執行階段會將產生的 CUDA 核心呼叫和程式庫調用序列轉換為 RuntimeIR (XLA 中的 MLIR 方言),並對其執行 CUDA 圖形擷取作業。CUDA 圖形仍在開發中,目前僅支援部分節點。擷取 CUDA 圖形邊界後,RuntimeIR 會透過 LLVM 編譯為 CPU 可執行檔,然後儲存或轉移以進行預先編譯。