
當加速器 (GPU 或 TPU) 的高頻寬記憶體 (HBM) 容量用盡時,就會發生記憶體不足 (OOM) 錯誤。如要瞭解 OOM 問題的常見原因和偵錯技術,請參閱「E1000 - Compile Time HBM OOM documentation」和「JAX documentation on GPU memory allocation」。
本頁面說明如何使用 XProf 的記憶體檢視器工具,以視覺化方式呈現 JAX 程式的記憶體用量、找出尖峰用量執行個體,以及偵錯 OOM 錯誤。其中包含下列步驟:
- 使用
jax.profiler.trace執行程式,擷取設定檔。 - 在背景啟動 XProf,並使用記憶體檢視器工具查看記憶體用量詳細資料。
範例程式
下列 JAX 程式會導致 OOM 錯誤:
import jax
from jax import random
import jax.numpy as jnp
@jax.profiler.trace("/tmp/xprof")
@jax.jit
def oom():
a = random.normal(random.PRNGKey(1), (327680, 327680), dtype=jnp.bfloat16)
return a @ a
if __name__ == "__main__":
oom()
在 TPU 機器上,這個程式會失敗並顯示以下訊息:
XlaRuntimeError: RESOURCE_EXHAUSTED: Allocation (size=107374182400) would exceed memory (size=17179869184) :: #allocation7 [shape = 'u8[327680,327680]{1,0:T(8,128)(4,1)}', space=hbm, size = 0xffffffffffffffff, tag = 'output of xor_convert_fusion@{}'] :: <no-hlo-instruction>
(在 GPU 機器上,錯誤看起來會像這樣:XlaRuntimeError: RESOURCE_EXHAUSTED:
Out of memory while trying to allocate 214748364800 bytes.)
執行 XProf
安裝 xprof (pip install xprof),然後啟動 XProf 執行個體,並指定設定檔的儲存目錄:
xprof --logdir=/tmp/xprof/ --port=6006
前往執行個體 (在本機上,位於 http://localhost:6006)。在「工具」下拉式選單中,選取「記憶體檢視器」,然後在「記憶體檢視器」工具視窗中,選取「記憶體類型」下拉式選單中的「HBM」 (通常預設會選取這個選項)。
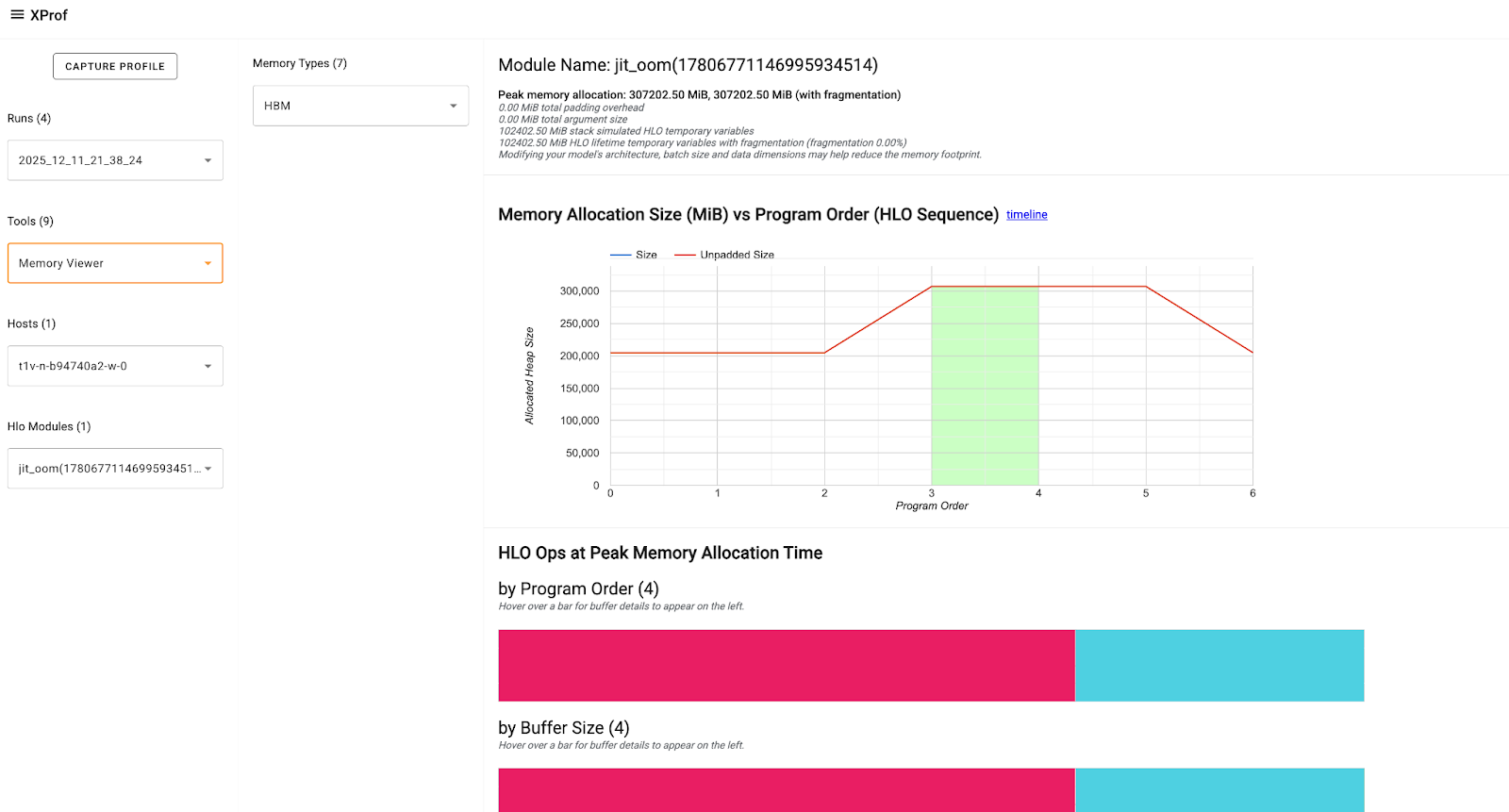
XProf:記憶體檢視器工具說明文件說明瞭工具的元件和顯示的資訊。
請著重查看「HLO Ops at Peak Memory Allocation」(尖峰記憶體分配時的 HLO 作業) 專區,該專區會顯示尖峰記憶體用量點的三張緩衝區圖表。緩衝區包含:* 程式輸入和輸出:訓練批次、最佳化工具狀態等。* TensorCore 和 SparseCore 暫時性:中間計算所需的動態記憶體 (例如啟用、梯度等)
將滑鼠游標懸停在緩衝區圖表上,即可查看 Op 的詳細資料,例如大小、形狀、分配類型等。這有助於找出並評估可能具有高或長期暫時性的作業、任何具有無效率填補的大型輸入/中介/輸出張量等,這些都會導致記憶體用量達到高峰,因此需要調整或最佳化。
請參閱「E1000:偵錯」一文,瞭解具體的偵錯技術。