
In dieser Anleitung wird gezeigt, wie Sie mit den in XProf verfügbaren Tools die Leistung Ihrer TensorFlow-Modelle auf dem Host (CPU), dem Gerät (GPU) oder auf einer Kombination aus Host und Gerät(en) verfolgen können.
Durch das Profiling können Sie den Hardware-Ressourcenverbrauch (Zeit und Speicher) der verschiedenen TensorFlow-Operationen (Ops) in Ihrem Modell nachvollziehen, Leistungsengpässe beheben und letztendlich die Ausführung des Modells beschleunigen.
In diesem Leitfaden erfahren Sie, wie Sie die verschiedenen verfügbaren Tools verwenden und wie der Profiler Leistungsdaten erfasst.
Wenn Sie die Leistung Ihres Modells auf Cloud TPUs analysieren möchten, lesen Sie den Cloud TPU-Leitfaden.
Leistungsdaten erheben
XProf erfasst Hostaktivitäten und GPU-Traces Ihres TensorFlow-Modells. Sie können XProf so konfigurieren, dass Leistungsdaten entweder im programmatischen Modus oder im Sampling-Modus erfasst werden.
Profiling-APIs
Sie können die folgenden APIs für das Profiling verwenden.
Programmatischer Modus mit dem TensorBoard Keras-Callback (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Programmatischer Modus mit der
tf.profilerFunction APItf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Programmatischer Modus mit dem Kontextmanager
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Sampling-Modus: Führen Sie die Profilerstellung bei Bedarf durch, indem Sie
tf.profiler.experimental.server.startverwenden, um einen gRPC-Server mit Ihrem TensorFlow-Modelllauf zu starten. Nachdem Sie den gRPC-Server gestartet und Ihr Modell ausgeführt haben, können Sie ein Profil über die Schaltfläche Capture Profile (Profil erfassen) in XProf erfassen. Verwenden Sie das Skript im Abschnitt „Profiler installieren“ oben, um eine TensorBoard-Instanz zu starten, falls sie noch nicht ausgeführt wird.Beispiel:
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Ein Beispiel für das Profiling mehrerer Worker:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
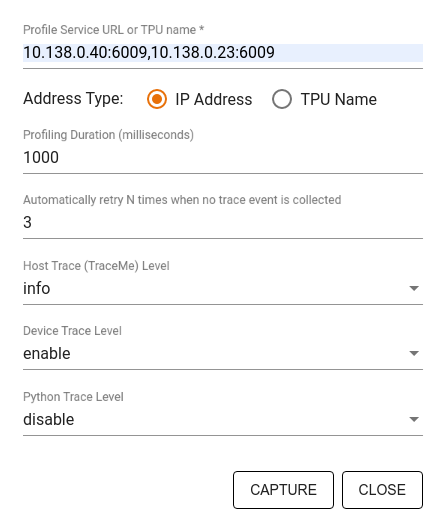
Im Dialogfeld Profil erfassen können Sie Folgendes angeben:
- Eine durch Kommas getrennte Liste mit Profildienst-URLs oder TPU-Namen.
- Eine Profilerstellungsdauer.
- Die Ebene der Ablaufverfolgung von Geräte-, Host- und Python-Funktionsaufrufen.
- Gibt an, wie oft der Profiler versuchen soll, Profile zu erfassen, wenn dies beim ersten Mal nicht gelingt.
Benutzerdefinierte Trainingsschleifen profilieren
Wenn Sie benutzerdefinierte Trainingsschleifen in Ihrem TensorFlow-Code profilieren möchten, instrumentieren Sie die Trainingsschleife mit der tf.profiler.experimental.Trace API, um die Schrittgrenzen für XProf zu markieren.
Das Argument name wird als Präfix für die Schrittnamen verwendet, das Schlüsselwortargument step_num wird an die Schrittnamen angehängt und das Schlüsselwortargument _r bewirkt, dass dieses Ablaufverfolgungsereignis von XProf als Schrittereignis verarbeitet wird.
Beispiel:
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Dadurch wird die schrittbasierte Leistungsanalyse von XProf aktiviert und die Schrittereignisse werden im Trace Viewer angezeigt.
Achten Sie darauf, dass Sie den Dataset-Iterator in den tf.profiler.experimental.Trace-Kontext einfügen, um die Eingabepipeline genau zu analysieren.
Das folgende Code-Snippet ist ein Anti-Pattern:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Anwendungsfälle für Profilerstellung
Der Profiler deckt eine Reihe von Anwendungsfällen entlang von vier verschiedenen Achsen ab. Einige der Kombinationen werden derzeit unterstützt, andere werden in Zukunft hinzugefügt. Hier einige Anwendungsfälle:
- Lokales und Remote-Profiling: Dies sind zwei gängige Methoden zum Einrichten Ihrer Profiling-Umgebung. Beim lokalen Profiling wird die Profiling API auf demselben Computer aufgerufen, auf dem Ihr Modell ausgeführt wird, z. B. auf einer lokalen Workstation mit GPUs. Beim Remote-Profiling wird die Profiling-API auf einem anderen Computer aufgerufen als dem, auf dem Ihr Modell ausgeführt wird, z. B. auf einer Cloud TPU.
- Mehrere Worker profilieren: Wenn Sie die Funktionen für verteiltes Training von TensorFlow verwenden, können Sie mehrere Maschinen profilieren.
- Hardwareplattform: CPUs, GPUs und TPUs profilieren.
Die folgende Tabelle bietet einen kurzen Überblick über die oben genannten von TensorFlow unterstützten Anwendungsfälle:
| Profiler API | Lokal | Remote | Mehrere Worker | Hardwareplattformen |
|---|---|---|---|---|
| TensorBoard Keras-Callback | Unterstützt | Nicht unterstützt | Nicht unterstützt | CPU, GPU |
tf.profiler.experimental
Starten/Beenden der API |
Unterstützt | Nicht unterstützt | Nicht unterstützt | CPU, GPU |
tf.profiler.experimental
client.trace API |
Unterstützt | Unterstützt | Unterstützt | CPU, GPU, TPU |
| Context Manager API | Unterstützt | Nicht unterstützt | Nicht unterstützt | CPU, GPU |
Zusätzliche Ressourcen
- Das TensorFlow Profiler-Tutorial: Modellleistung profilieren mit Keras und TensorBoard, in dem Sie die Ratschläge in diesem Leitfaden anwenden können.
- Der Vortrag Performance profiling in TensorFlow 2 vom TensorFlow Dev Summit 2020.
- Die TensorFlow Profiler-Demo vom TensorFlow Dev Summit 2020.