
Ce guide explique comment utiliser les outils disponibles avec XProf pour suivre les performances de vos modèles TensorFlow sur l'hôte (CPU), sur l'appareil (GPU) ou sur une combinaison de l'hôte et de l'appareil(ou des appareils).
Le profilage permet de comprendre la consommation de ressources matérielles (temps et mémoire) des différentes opérations TensorFlow (ops) de votre modèle, de résoudre les goulots d'étranglement des performances et, en fin de compte, d'accélérer l'exécution du modèle.
Ce guide vous explique comment utiliser les différents outils disponibles et les différents modes de collecte des données de performances par le Profileur.
Si vous souhaitez profiler les performances de votre modèle sur les Cloud TPU, consultez le guide Cloud TPU.
Collecter des données sur les performances
XProf collecte les activités de l'hôte et les traces GPU de votre modèle TensorFlow. Vous pouvez configurer XProf pour qu'il collecte des données sur les performances en mode programmatique ou en mode échantillonnage.
Profilage des API
Vous pouvez utiliser les API suivantes pour effectuer le profilage.
Mode programmatique utilisant le rappel Keras TensorBoard (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Mode programmatique utilisant l'API de fonction
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Mode programmatique utilisant le gestionnaire de contexte
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Mode d'échantillonnage : effectuez un profilage à la demande en utilisant
tf.profiler.experimental.server.startpour démarrer un serveur gRPC avec l'exécution de votre modèle TensorFlow. Après avoir démarré le serveur gRPC et exécuté votre modèle, vous pouvez capturer un profil à l'aide du bouton Capture Profile (Capturer le profil) dans XProf. Utilisez le script de la section "Installer le profileur" ci-dessus pour lancer une instance TensorBoard si elle n'est pas déjà en cours d'exécution.Par exemple,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Exemple de profilage de plusieurs nœuds de calcul :
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
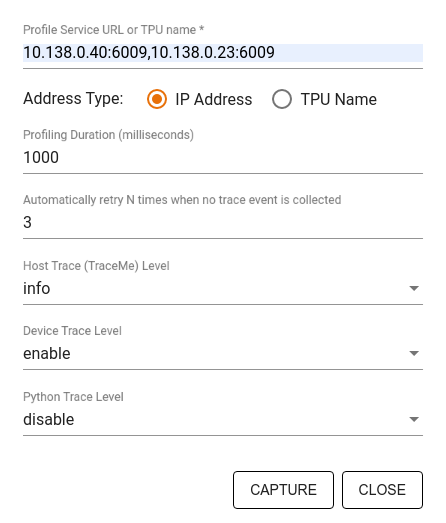
Utilisez la boîte de dialogue Capturer le profil pour spécifier :
- Liste d'URL de service de profil ou de noms de TPU séparés par une virgule.
- Durée du profilage.
- Niveau de traçage des appels de fonction Python, d'hôte et d'appareil.
- Nombre de fois où le Profileur doit réessayer de capturer des profils en cas d'échec initial.
Profiler des boucles d'entraînement personnalisées
Pour profiler des boucles d'entraînement personnalisées dans votre code TensorFlow, instrumentez la boucle d'entraînement avec l'API tf.profiler.experimental.Trace afin de marquer les limites des étapes pour XProf.
L'argument name est utilisé comme préfixe pour les noms d'étapes, l'argument de mot clé step_num est ajouté aux noms d'étapes et l'argument de mot clé _r permet à cet événement de trace d'être traité comme un événement d'étape par XProf.
Par exemple,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Cela permettra à XProf d'analyser les performances par étapes et d'afficher les événements d'étape dans le lecteur de trace.
Assurez-vous d'inclure l'itérateur de l'ensemble de données dans le contexte tf.profiler.experimental.Trace pour une analyse précise du pipeline d'entrée.
L'extrait de code ci-dessous est un anti-pattern :
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Cas d'utilisation du profilage
Le profileur couvre un certain nombre de cas d'utilisation selon quatre axes différents. Certaines combinaisons sont actuellement prises en charge, et d'autres le seront à l'avenir. Voici quelques cas d'utilisation :
- Profilage local et profilage à distance : il s'agit de deux méthodes courantes pour configurer votre environnement de profilage. Dans le profilage local, l'API de profilage est appelée sur la même machine que celle sur laquelle votre modèle s'exécute (par exemple, un poste de travail local avec des GPU). Dans le profilage à distance, l'API de profilage est appelée sur une machine différente de celle sur laquelle votre modèle est exécuté, par exemple sur une Cloud TPU.
- Profilage de plusieurs nœuds de calcul : vous pouvez profiler plusieurs machines lorsque vous utilisez les fonctionnalités d'entraînement distribué de TensorFlow.
- Plate-forme matérielle : profilez les CPU, les GPU et les TPU.
Le tableau ci-dessous offre un aperçu rapide des cas d'utilisation compatibles avec TensorFlow mentionnés ci-dessus :
| API de profilage | Local | Télécommande | Plusieurs nœuds de calcul | Plates-formes matérielles |
|---|---|---|---|---|
| Rappel TensorBoard Keras | Compatible | Non pris en charge | Non pris en charge | Processeur, GPU |
tf.profiler.experimental
API start/stop |
Compatible | Non pris en charge | Non pris en charge | Processeur, GPU |
tf.profiler.experimental
client.trace API |
Compatible | Compatible | Compatible | CPU, GPU, TPU |
| API Context Manager | Compatible | Non pris en charge | Non pris en charge | Processeur, GPU |
Ressources supplémentaires
- Le tutoriel TensorFlow Profiler : profiler les performances des modèles avec Keras et TensorBoard, où vous pouvez appliquer les conseils de ce guide.
- La présentation Performance profiling in TensorFlow 2 (Profilage des performances dans TensorFlow 2) du TensorFlow Dev Summit 2020.
- La démonstration de TensorFlow Profiler présentée lors du TensorFlow Dev Summit 2020.