
이 가이드에서는 XProf에서 제공하는 도구를 사용하여 호스트(CPU), 기기(GPU) 또는 호스트와 기기의 조합에서 TensorFlow 모델의 성능을 추적하는 방법을 보여줍니다.
프로파일링은 모델의 다양한 TensorFlow 작업 (op)의 하드웨어 리소스 소비 (시간 및 메모리)를 이해하고 성능 병목 현상을 해결하여 궁극적으로 모델을 더 빠르게 실행하는 데 도움이 됩니다.
이 가이드에서는 사용할 수 있는 다양한 도구와 프로파일러가 성능 데이터를 수집하는 다양한 모드를 설명합니다.
Cloud TPU에서 모델 성능을 프로파일링하려면 Cloud TPU 가이드를 참고하세요.
성능 데이터 수집
XProf는 TensorFlow 모델의 호스트 활동과 GPU 트레이스를 수집합니다. 프로그래매틱 모드 또는 샘플링 모드를 통해 성능 데이터를 수집하도록 XProf를 구성할 수 있습니다.
프로파일링 API
다음 API를 사용하여 프로파일링을 실행할 수 있습니다.
TensorBoard Keras 콜백 (
tf.keras.callbacks.TensorBoard)을 사용하는 프로그래매틱 모드# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])tf.profiler함수 API를 사용하는 프로그래매틱 모드tf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()컨텍스트 관리자를 사용하는 프로그래매틱 모드
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
샘플링 모드:
tf.profiler.experimental.server.start를 사용하여 TensorFlow 모델 실행으로 gRPC 서버를 시작하여 주문형 프로파일링을 실행합니다. gRPC 서버를 시작하고 모델을 실행한 후 XProf의 프로필 캡처 버튼을 통해 프로필을 캡처할 수 있습니다. TensorBoard 인스턴스가 아직 실행되고 있지 않다면 위의 프로파일러 설치 섹션의 스크립트를 사용하여 실행합니다.예를 들어
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)여러 작업자 프로파일링의 예:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
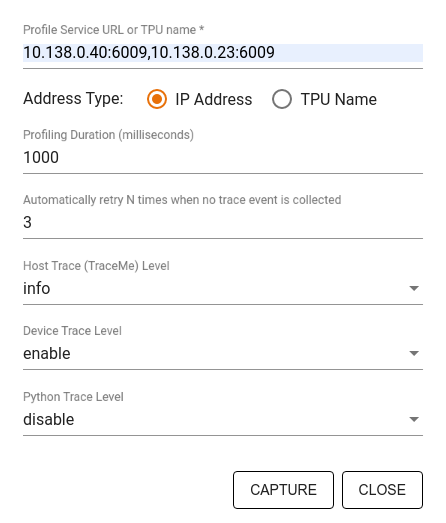
프로필 캡처 대화상자를 사용하여 다음을 지정합니다.
- 쉼표로 구분된 프로필 서비스 URL 또는 TPU 이름 목록입니다.
- 프로파일링 기간입니다.
- 기기, 호스트, Python 함수 호출 추적 수준입니다.
- 프로파일러가 처음 캡처에 실패한 경우 프로필 캡처를 재시도할 횟수입니다.
맞춤 학습 루프 프로파일링
TensorFlow 코드에서 맞춤 학습 루프를 프로파일링하려면 tf.profiler.experimental.Trace API로 학습 루프를 계측하여 XProf의 단계 경계를 표시하세요.
name 인수는 단계 이름의 접두사로 사용되고 step_num 키워드 인수는 단계 이름에 추가되며 _r 키워드 인수로 인해 이 추적 이벤트가 XProf에서 단계 이벤트로 처리됩니다.
예를 들어
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
이렇게 하면 XProf의 단계 기반 성능 분석이 사용 설정되고 단계 이벤트가 트레이스 뷰어에 표시됩니다.
입력 파이프라인을 정확하게 분석하려면 tf.profiler.experimental.Trace 컨텍스트 내에 데이터 세트 반복자를 포함해야 합니다.
아래 코드 스니펫은 안티 패턴입니다.
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
프로파일링 사용 사례
프로파일러는 네 가지 축을 따라 여러 사용 사례를 다룹니다. 일부 조합은 현재 지원되며 다른 조합은 향후 추가될 예정입니다. 사용 사례는 다음과 같습니다.
- 로컬 프로파일링과 원격 프로파일링: 프로파일링 환경을 설정하는 두 가지 일반적인 방법입니다. 로컬 프로파일링에서는 모델이 실행되는 동일한 머신(예: GPU가 있는 로컬 워크스테이션)에서 프로파일링 API가 호출됩니다. 원격 프로파일링에서는 모델이 실행되는 머신(예: Cloud TPU)이 아닌 다른 머신에서 프로파일링 API가 호출됩니다.
- 여러 작업자 프로파일링: TensorFlow의 분산 학습 기능을 사용할 때 여러 머신을 프로파일링할 수 있습니다.
- 하드웨어 플랫폼: CPU, GPU, TPU를 프로파일링합니다.
아래 표에서는 위에서 언급한 TensorFlow 지원 사용 사례를 간략하게 보여줍니다.
| 프로파일링 API | 지역 | 원격 | 여러 작업자 | 하드웨어 플랫폼 |
|---|---|---|---|---|
| TensorBoard Keras 콜백 | 지원됨 | 지원되지 않음 | 지원되지 않음 | CPU, GPU |
tf.profiler.experimental
API 시작/중지 |
지원됨 | 지원되지 않음 | 지원되지 않음 | CPU, GPU |
tf.profiler.experimental
client.trace API |
지원됨 | 지원됨 | 지원됨 | CPU, GPU, TPU |
| Context Manager API | 지원됨 | 지원되지 않음 | 지원되지 않음 | CPU, GPU |
추가 리소스
- 이 가이드의 조언을 적용할 수 있는 Keras 및 텐서보드를 사용한 TensorFlow 프로파일러: 모델 성능 프로파일링 튜토리얼
- TensorFlow Dev Summit 2020의 TensorFlow 2의 성능 프로파일링 강연
- TensorFlow Dev Summit 2020의 TensorFlow 프로파일러 데모