
Z tego przewodnika dowiesz się, jak za pomocą narzędzi dostępnych w XProf śledzić wydajność modeli TensorFlow na hoście (CPU), urządzeniu (GPU) lub na kombinacji hosta i urządzeń.
Profilowanie pomaga zrozumieć zużycie zasobów sprzętowych (czasu i pamięci) przez różne operacje TensorFlow (ops) w modelu, rozwiązywać problemy z wydajnością i ostatecznie przyspieszać wykonywanie modelu.
Z tego przewodnika dowiesz się, jak korzystać z różnych dostępnych narzędzi i jakie są różne tryby zbierania danych o wydajności przez Profiler.
Jeśli chcesz profilować wydajność modelu w Cloud TPU, zapoznaj się z przewodnikiem po Cloud TPU.
Zbieranie danych o skuteczności
XProf zbiera aktywności hosta i ślady GPU Twojego modelu TensorFlow. XProf możesz skonfigurować tak, aby zbierał dane o skuteczności w trybie programowym lub w trybie próbkowania.
Interfejsy API profilowania
Do profilowania możesz używać tych interfejsów API:
Tryb automatyzacji z użyciem wywołania zwrotnego TensorBoard Keras (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Tryb programowy z użyciem interfejsu API funkcji
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Tryb programowy z użyciem menedżera kontekstu
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Tryb próbkowania: wykonaj profilowanie na żądanie, używając
tf.profiler.experimental.server.start, aby uruchomić serwer gRPC z modelem TensorFlow. Po uruchomieniu serwera gRPC i modelu możesz zarejestrować profil, klikając przycisk Capture Profile (Zarejestruj profil) w XProf. Jeśli TensorBoard nie jest jeszcze uruchomiony, użyj skryptu z sekcji Instalowanie profilera powyżej, aby uruchomić instancję TensorBoard.Na przykład
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Przykład profilowania wielu pracowników:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
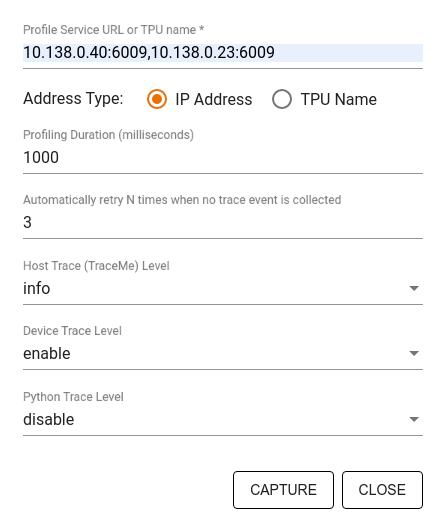
W oknie Zapisz profil określ:
- Rozdzielana przecinkami lista adresów URL usługi tworzenia profilu lub nazw TPU.
- czas profilowania.
- Poziom śledzenia wywołań funkcji urządzenia, hosta i Pythona.
- Liczba ponownych prób przechwytywania profili przez Profiler, jeśli pierwsza próba się nie powiedzie.
Profilowanie niestandardowych pętli trenowania
Aby profilować niestandardowe pętle trenowania w kodzie TensorFlow, użyj interfejsu tf.profiler.experimental.Trace API do oznaczenia granic kroków w pętli trenowania na potrzeby XProf.
Argument name jest używany jako prefiks nazw kroków, argument słowa kluczowego step_num jest dołączany do nazw kroków, a argument słowa kluczowego _r sprawia, że to zdarzenie śledzenia jest przetwarzane przez XProf jako zdarzenie kroku.
Na przykład
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Umożliwi to analizę wydajności XProf na podstawie kroków i spowoduje wyświetlanie zdarzeń kroków w przeglądarce śladów.
Aby uzyskać dokładną analizę potoku wejściowego, umieść iterator zbioru danych w kontekście tf.profiler.experimental.Trace.
Poniższy fragment kodu jest przykładem nieprawidłowego wzorca:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Przypadki użycia profilowania
Profiler obejmuje wiele przypadków użycia w 4 różnych obszarach. Niektóre kombinacje są obecnie obsługiwane, a inne zostaną dodane w przyszłości. Przykłady zastosowań:
- Profilowanie lokalne i zdalne: to 2 popularne sposoby konfigurowania środowiska profilowania. W profilowaniu lokalnym interfejs API profilowania jest wywoływany na tym samym komputerze, na którym jest wykonywany model, np. na lokalnej stacji roboczej z procesorami GPU. W profilowaniu zdalnym interfejs API profilowania jest wywoływany na innym komputerze niż ten, na którym jest wykonywany model, np. na Cloud TPU.
- Profilowanie wielu procesów roboczych: możesz profilować wiele maszyn, korzystając z możliwości trenowania rozproszonego TensorFlow.
- Platforma sprzętowa: profilowanie procesorów, procesorów graficznych i TPU.
W tabeli poniżej znajdziesz krótkie omówienie wymienionych powyżej przypadków użycia obsługiwanych przez TensorFlow:
| Profiling API | Lokalne | Zdalne | Wielu pracowników | Platformy sprzętowe |
|---|---|---|---|---|
| Wywołanie zwrotne TensorBoard Keras | Obsługiwane | Nieobsługiwane | Nieobsługiwane | CPU, GPU |
tf.profiler.experimental
uruchamianie i zatrzymywanie interfejsu API |
Obsługiwane | Nieobsługiwane | Nieobsługiwane | CPU, GPU |
tf.profiler.experimental
client.trace API |
Obsługiwane | Obsługiwane | Obsługiwane | CPU, GPU, TPU |
| Context manager API | Obsługiwane | Nieobsługiwane | Nieobsługiwane | CPU, GPU |
Dodatkowe materiały
- Samouczek TensorFlow Profiler: Profile model performance (Profiler TensorFlow: profilowanie wydajności modelu) z Keras i TensorBoard, w którym możesz zastosować porady z tego przewodnika.
- Prezentacja Performance profiling in TensorFlow 2 z konferencji TensorFlow Dev Summit 2020.
- Demo profilera TensorFlow z konferencji TensorFlow Dev Summit 2020.