
Hướng dẫn này minh hoạ cách sử dụng các công cụ có trong XProf để theo dõi hiệu suất của các mô hình TensorFlow trên máy chủ (CPU), thiết bị (GPU) hoặc trên cả máy chủ và(các) thiết bị.
Hồ sơ giúp bạn hiểu được mức tiêu thụ tài nguyên phần cứng (thời gian và bộ nhớ) của nhiều thao tác TensorFlow (ops) trong mô hình, đồng thời giải quyết các nút thắt về hiệu suất và cuối cùng là giúp mô hình thực thi nhanh hơn.
Hướng dẫn này sẽ hướng dẫn bạn cách sử dụng các công cụ hiện có và các chế độ khác nhau về cách Trình phân tích tài nguyên thu thập dữ liệu hiệu suất.
Nếu bạn muốn lập hồ sơ hiệu suất mô hình trên Cloud TPU, hãy tham khảo hướng dẫn về Cloud TPU.
Thu thập dữ liệu hiệu suất
XProf thu thập các hoạt động của máy chủ lưu trữ và dấu vết GPU của mô hình TensorFlow. Bạn có thể định cấu hình XProf để thu thập dữ liệu hiệu suất thông qua chế độ theo chương trình hoặc chế độ lấy mẫu.
API lập hồ sơ
Bạn có thể sử dụng các API sau để thực hiện việc lập hồ sơ.
Chế độ có lập trình bằng cách sử dụng TensorBoard Keras Callback (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Chế độ có lập trình bằng cách sử dụng API hàm
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Chế độ có lập trình bằng trình quản lý bối cảnh
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Chế độ lấy mẫu: Thực hiện việc phân tích hiệu suất theo yêu cầu bằng cách sử dụng
tf.profiler.experimental.server.startđể khởi động một máy chủ gRPC bằng lượt chạy mô hình TensorFlow. Sau khi khởi động máy chủ gRPC và chạy mô hình, bạn có thể ghi lại một hồ sơ thông qua nút Capture Profile (Ghi lại hồ sơ) trong XProf. Sử dụng tập lệnh trong phần Cài đặt trình phân tích tài nguyên ở trên để khởi chạy một phiên bản TensorBoard nếu phiên bản này chưa chạy.Ví dụ:
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Ví dụ về việc lập hồ sơ nhiều worker:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
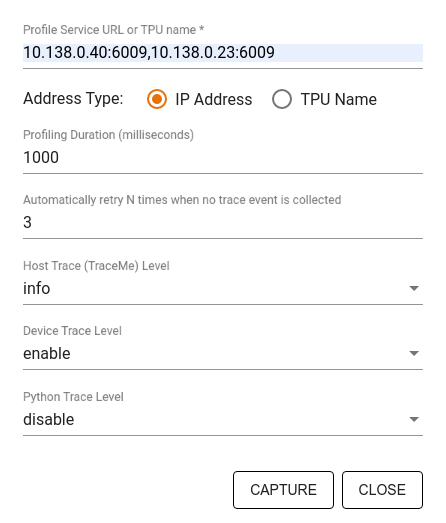
Sử dụng hộp thoại Capture Profile (Hồ sơ chụp) để chỉ định:
- Danh sách các URL dịch vụ hồ sơ hoặc tên TPU được phân tách bằng dấu phẩy.
- Thời lượng lập hồ sơ.
- Mức độ theo dõi lệnh gọi hàm thiết bị, máy chủ lưu trữ và Python.
- Số lần bạn muốn Trình phân tích tài nguyên thử lại chụp các hồ sơ nếu không thành công ngay từ đầu.
Lập hồ sơ các vòng lặp huấn luyện tuỳ chỉnh
Để lập hồ sơ các vòng lặp huấn luyện tuỳ chỉnh trong mã TensorFlow, hãy đo lường vòng lặp huấn luyện bằng API tf.profiler.experimental.Trace để đánh dấu ranh giới bước cho XProf.
Đối số name được dùng làm tiền tố cho tên bước, đối số từ khoá step_num được thêm vào tên bước và đối số từ khoá _r khiến sự kiện theo dõi này được XProf xử lý dưới dạng sự kiện bước.
Ví dụ:
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Thao tác này sẽ cho phép phân tích hiệu suất theo từng bước của XProf và khiến các sự kiện bước xuất hiện trong trình xem dấu vết.
Đảm bảo rằng bạn đưa trình lặp tập dữ liệu vào trong ngữ cảnh tf.profiler.experimental.Trace để phân tích chính xác quy trình đầu vào.
Đoạn mã dưới đây là một mẫu chống lại:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Các trường hợp sử dụng lập hồ sơ
Trình phân tích tài nguyên bao gồm một số trường hợp sử dụng theo 4 trục khác nhau. Hiện tại, chúng tôi hỗ trợ một số tổ hợp và sẽ bổ sung các tổ hợp khác trong tương lai. Sau đây là một số trường hợp sử dụng:
- Hồ sơ cục bộ so với hồ sơ từ xa: Đây là hai cách phổ biến để thiết lập môi trường lập hồ sơ. Trong lập hồ sơ cục bộ, API lập hồ sơ được gọi trên cùng một máy mà mô hình của bạn đang thực thi, ví dụ: một máy trạm cục bộ có GPU. Trong hoạt động lập hồ sơ từ xa, API lập hồ sơ được gọi trên một máy khác với nơi mô hình của bạn đang thực thi, ví dụ: trên Cloud TPU.
- Hồ sơ nhiều worker: Bạn có thể lập hồ sơ nhiều máy khi sử dụng các chức năng huấn luyện phân tán của TensorFlow.
- Nền tảng phần cứng: Lập hồ sơ CPU, GPU và TPU.
Bảng dưới đây cung cấp thông tin tổng quan nhanh về các trường hợp sử dụng được TensorFlow hỗ trợ như đã đề cập ở trên:
| Profiling API | Địa phương | Điều khiển từ xa | Nhiều worker | Nền tảng phần cứng |
|---|---|---|---|---|
| TensorBoard Keras Callback | Có thể làm | Không được hỗ trợ | Không được hỗ trợ | CPU, GPU |
tf.profiler.experimental
API bắt đầu/dừng |
Có thể làm | Không được hỗ trợ | Không được hỗ trợ | CPU, GPU |
tf.profiler.experimental
client.trace API |
Có thể làm | Có thể làm | Có thể làm | CPU, GPU, TPU |
| Context manager API | Có thể làm | Không được hỗ trợ | Không được hỗ trợ | CPU, GPU |
Tài nguyên khác
- Hướng dẫn TensorFlow Profiler: Phân tích hiệu suất mô hình bằng Keras và TensorBoard, trong đó bạn có thể áp dụng lời khuyên trong hướng dẫn này.
- Bài nói chuyện Hồ sơ hiệu suất trong TensorFlow 2 tại Hội nghị Nhà phát triển TensorFlow 2020.
- Bản minh hoạ TensorFlow Profiler trong Hội nghị dành cho nhà phát triển TensorFlow năm 2020.