
本指南演示了如何使用 XProf 提供的工具来跟踪 TensorFlow 模型在主机 (CPU)、设备 (GPU) 上或主机和设备组合上的性能。
性能分析有助于了解模型中各种 TensorFlow 操作 (op) 的硬件资源消耗情况(时间和内存),解决性能瓶颈,并最终使模型运行得更快。
本指南将引导您了解如何使用各种可用工具,以及分析器收集性能数据的不同模式。
如果您想在 Cloud TPU 上剖析模型性能,请参阅 Cloud TPU 指南。
收集性能数据
XProf 会收集 TensorFlow 模型的主机活动和 GPU 轨迹。您可以将 XProf 配置为通过程序化模式或抽样模式收集性能数据。
分析 API
您可以使用以下 API 执行分析。
使用 TensorBoard Keras 回调 (
tf.keras.callbacks.TensorBoard) 的程序化模式# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])使用
tf.profiler函数 API 的程序化模式tf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()使用上下文管理器的程序化模式
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
抽样模式:使用
tf.profiler.experimental.server.start启动运行 TensorFlow 模型的 gRPC 服务器,以执行按需分析。启动 gRPC 服务器并运行模型后,您可以通过 XProf 中的 Capture Profile(捕获性能分析文件)按钮捕获性能分析文件。如果 TensorBoard 实例尚未运行,请使用上文“安装分析器”部分中的脚本启动一个实例。例如,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)分析多个工作器的示例:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
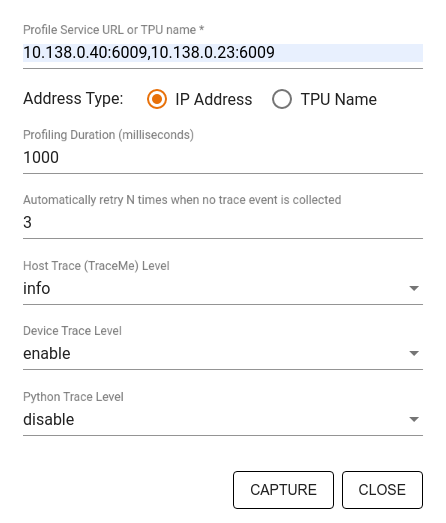
使用捕获配置文件对话框指定:
- 以英文逗号分隔的配置文件服务网址或 TPU 名称列表。
- 分析时长。
- 设备、主机和 Python 函数调用跟踪的级别。
- 如果首次尝试捕获配置文件失败,您希望性能分析器重试捕获配置文件的次数。
分析自定义训练循环
如需对 TensorFlow 代码中的自定义训练循环进行分析,请使用 tf.profiler.experimental.Trace API 对训练循环进行插桩,以标记 XProf 的步边界。
name 实参用作步骤名称的前缀,step_num 关键字实参会附加到步骤名称中,而 _r 关键字实参会使 XProf 将此轨迹事件处理为步骤事件。
例如,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
这将启用 XProf 的基于步数的性能分析,并使步数事件显示在 Trace Viewer 中。
请确保将数据集迭代器包含在 tf.profiler.experimental.Trace 上下文中,以便准确分析输入流水线。
以下代码段是一种反模式:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
分析用例
分析器涵盖了四个不同方面的多种使用情形。目前支持部分组合,未来会添加其他组合。 部分用例包括:
- 本地分析与远程分析:这是设置分析环境的两种常见方式。在本地分析中,分析 API 在模型执行的同一台机器上调用,例如配备 GPU 的本地工作站。在远程性能分析中,性能分析 API 在与模型执行位置不同的机器上(例如在 Cloud TPU 上)调用。
- 对多个 worker 进行性能剖析:使用 TensorFlow 的分布式训练功能时,您可以对多台机器进行性能剖析。
- 硬件平台:分析 CPU、GPU 和 TPU。
下表简要概述了上述 TensorFlow 支持的应用场景:
| Profiling API | 本地 | 远程 | 多个工作器 | 硬件平台 |
|---|---|---|---|---|
| TensorBoard Keras 回调 | 支持 | 不支持 | 不支持 | CPU、GPU |
tf.profiler.experimental
启动/停止 API |
支持 | 不支持 | 不支持 | CPU、GPU |
tf.profiler.experimental
client.trace API |
支持 | 支持 | 支持 | CPU、GPU、TPU |
| 上下文管理器 API | 支持 | 不支持 | 不支持 | CPU、GPU |
其他资源
- TensorFlow Profiler:分析模型性能教程,其中包含 Keras 和 TensorBoard,您可以应用本指南中的建议。
- 2020 年 TensorFlow 开发者峰会上的TensorFlow 2 中的性能分析讲座。
- 2020 年 TensorFlow 开发者峰会上的 TensorFlow Profiler 演示。