
本指南說明如何使用 XProf 提供的工具,追蹤主機 (CPU)、裝置 (GPU) 或主機和裝置組合上 TensorFlow 模型的效能。
剖析有助於瞭解模型中各種 TensorFlow 作業 (作業) 的硬體資源耗用量 (時間和記憶體),並解決效能瓶頸,最終加快模型執行速度。
本指南將逐步說明如何使用各種可用工具,以及 Profiler 收集效能資料的不同模式。
如要在 Cloud TPU 上剖析模型效能,請參閱 Cloud TPU 指南。
收集成效資料
XProf 會收集 TensorFlow 模型的主機活動和 GPU 追蹤記錄。您可以設定 XProf,透過程式輔助模式或取樣模式收集效能資料。
剖析 API
您可以使用下列 API 執行剖析作業。
使用 TensorBoard Keras 回呼 (
tf.keras.callbacks.TensorBoard) 的程式輔助模式# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])使用
tf.profilerFunction API 的程式輔助模式tf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()使用內容管理工具的程式輔助模式
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
取樣模式:使用
tf.profiler.experimental.server.start啟動 gRPC 伺服器,並執行 TensorFlow 模型,即可執行隨選剖析。啟動 gRPC 伺服器並執行模型後,即可透過 XProf 中的「Capture Profile」按鈕擷取設定檔。如果 TensorBoard 執行個體尚未啟動,請使用上方「安裝剖析器」一節中的指令碼啟動。舉例來說,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)以下是為多個工作人員建立設定檔的範例:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
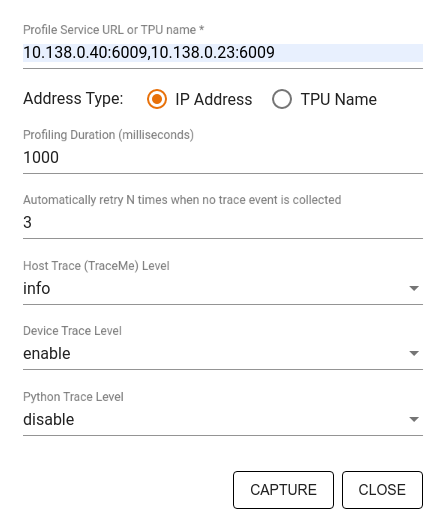
使用「擷取設定檔」對話方塊指定:
- 以半形逗號分隔的剖析服務網址或 TPU 名稱清單。
- 剖析時間長度。
- 裝置、主機和 Python 函式呼叫追蹤的層級。
- 如果第一次擷取剖析資料失敗,Profiler 應重試擷取剖析資料的次數。
分析自訂訓練迴圈
如要剖析 TensorFlow 程式碼中的自訂訓練迴圈,請使用 tf.profiler.experimental.Trace API 檢測訓練迴圈,標記 XProf 的步驟界線。
name 引數會做為步驟名稱的前置字元,step_num 關鍵字引數會附加在步驟名稱中,而 _r 關鍵字引數會讓 XProf 將這個追蹤事件處理為步驟事件。
舉例來說,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
這會啟用 XProf 的步驟式效能分析,並導致步驟事件顯示在追蹤記錄檢視器中。
請務必在 tf.profiler.experimental.Trace 環境中加入資料集疊代器,以便準確分析輸入管道。
以下程式碼片段是反模式:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
剖析用途
剖析器涵蓋四個不同軸向的各種用途。目前支援部分組合,日後會新增其他組合。部分用途包括:
- 本機與遠端剖析:這是設定剖析環境的兩種常見方式。在本機剖析中,剖析 API 會在模型執行的同一部機器上呼叫,例如搭載 GPU 的本機工作站。在遠端剖析中,剖析 API 會在模型執行的機器以外的機器上呼叫,例如在 Cloud TPU 上。
- 分析多個工作站:使用 TensorFlow 的分散式訓練功能時,您可以分析多部機器。
- 硬體平台:剖析 CPU、GPU 和 TPU。
下表簡要列出上述 TensorFlow 支援的用途:
| Profiling API | 本機 | 遙控器 | 多個工作人員 | 硬體平台 |
|---|---|---|---|---|
| TensorBoard Keras 回呼 | 支援 | 不支援 | 不支援 | CPU、GPU |
tf.profiler.experimental
啟動/停止 API |
支援 | 不支援 | 不支援 | CPU、GPU |
tf.profiler.experimental
client.trace API |
支援 | 支援 | 支援 | CPU、GPU、 TPU |
| Context manager API | 支援 | 不支援 | 不支援 | CPU、GPU |
其他資源
- 請參閱 TensorFlow Profiler:剖析模型效能教學課程,瞭解如何使用 Keras 和 TensorBoard 應用本指南中的建議。
- TensorFlow 開發人員高峰會 2020 的「TensorFlow 2 中的效能剖析」演講。
- 2020 年 TensorFlow 開發人員高峰會的 TensorFlow Profiler 示範。