
This tool is currently only available in nightly builds.
יעד
מטרת הכלי הזה היא לספק תצוגה כללית של הביצועים של מערכת TPU, ולאפשר לנתח ביצועים לזהות חלקים במערכת שבהם יכולות להיות בעיות בביצועים.
הדמיה של ניצול ברמת הצ'יפ
כדי להשתמש בכלי, מחפשים את הכלי 'Utilization Viewer' (צפייה בשימוש) ב'מגירה' בצד ימין. בכלי מוצגים 4 תרשימי עמודות שמציגים את השימוש ביחידות הביצוע (2 התרשימים העליונים) ובנתיבי ה-DMA (2 התרשימים התחתונים) עבור 2 צמתי Tensor בשבב TPU.
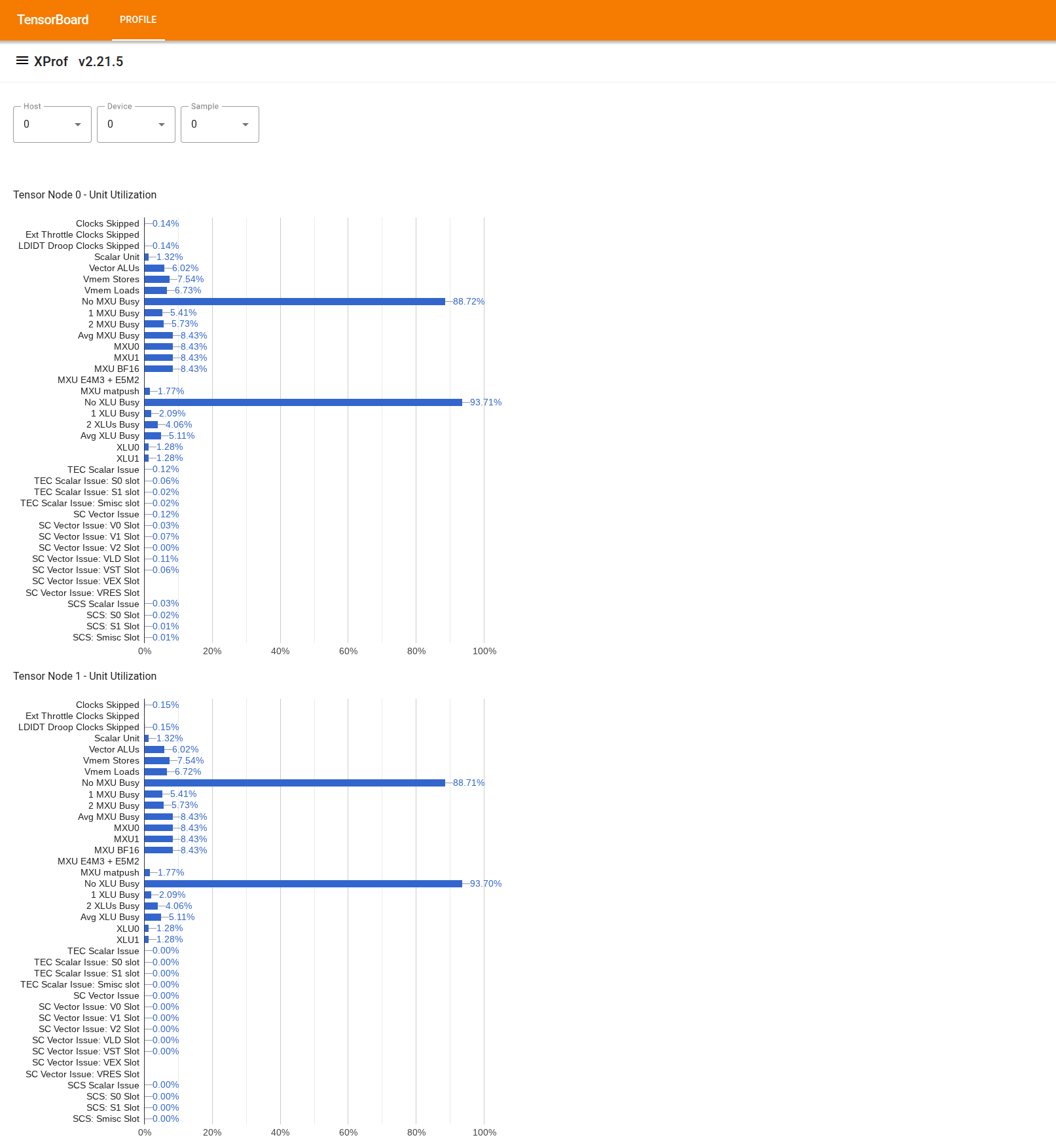
כשמעבירים את העכבר מעל עמודה, מופיע הסבר קצר עם פרטים על הניצול: הכמות 'שהושגה' והכמות ה'מקסימלית' (התיאורטית). אחוז הניצול שמוצג בסרגל מתקבל מחלוקת הסכום 'הושג' בסכום 'השיא'. הכמויות שהושגו והכמויות המקסימליות מוצגות ביחידות של הוראות לניצול יחידת הביצוע, וביחידות של בייטים לניצול רוחב הפס.
הניצול של יחידת ביצוע הוא החלק של המחזורים שבהם היחידה הייתה עסוקה במהלך תקופת הפרופיל.
מוצג הניצול של יחידות הביצוע הבאות של ליבות טנסור:
- יחידה סקלרית: מחושבת כסכום של
count_s0_instructionו-count_s1_instruction, כלומר מספר ההוראות הסקלריות, חלקי כפליים של מספר המחזורים, כי התפוקה של היחידה הסקלרית היא 2 הוראות לכל מחזור. - Vector ALUs: מחושב כסכום של
count_v0_instructionו-count_v1_instruction, כלומר מספר ההוראות של הווקטור, חלקי כפליים של מספר המחזורים, כי התפוקה של Vector ALUs היא 2 הוראות לכל מחזור. - מאגרי וקטורים: מחושב כ-
count_vector_store, כלומר מספר מאגרי הווקטורים חלקי מספר המחזורים, כי קצב העברת הנתונים של מאגר הווקטורים הוא הוראה אחת לכל מחזור. - טעינות וקטוריות: מחושב כ-
count_vector_load, כלומר מספר הטעינות הווקטוריות חלקי מספר המחזורים, כי קצב העברת הנתונים של הטעינה הווקטורית הוא הוראה אחת לכל מחזור. - יחידת מטריצה (MXU): מחושבת כ-
count_matmulחלקי 1/8 ממספר המחזורים, כי קצב התפוקה של MXU הוא הוראה אחת ל-8 מחזורים. - יחידת טרנספוזיציה (XU): מחושבת כ-
count_transposeחלקי שמינית ממספר המחזורים, כי התפוקה של XU היא הוראה אחת לכל 8 מחזורים. - יחידת צמצום והחלפה (RPU): מחושבת כ-
count_rpu_instructionחלקי שמינית ממספר המחזורים, כי קצב העברת הנתונים של RPU הוא הוראה אחת לכל 8 מחזורים.
באיור הבא מוצג תרשים בלוקים של ליבת הטנסור עם יחידות הביצוע:
flowchart LR classDef redBox fill:#c96665,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef whiteBox fill:#fff,stroke:#000,stroke-width:2px,color:#000,font-weight:bold; classDef invisible fill:none,stroke:none; classDef container fill:#f9f9f9,stroke:#666,stroke-width:3px,stroke-dasharray: 10 5,color:#666,font-size:20px; subgraph TensorCore [TensorCore] direction LR subgraph LeftCol [ ] direction TB CS["Core<br>Sequencer<br>(CS)"]:::redBox VPU["Vector<br>Programmable<br>Unit<br>(VPU)"]:::whiteBox CS --> VPU end subgraph RightCol [ ] direction TB MXU["Matrix Unit<br>(MXU)"]:::whiteBox XU["Transpose Unit<br>(XU)"]:::whiteBox RPU["Reduction and<br>Permutation<br>Unit<br>(RPU)"]:::whiteBox end VPU <==> MXU VPU <==> XU VPU <==> RPU end class TensorCore container class LeftCol,RightCol invisibleלפרטים נוספים על כל אחת מיחידות הביצוע האלה, אפשר לעיין במאמר בנושא ארכיטקטורת TPU.
- יחידה סקלרית: מחושבת כסכום של
הניצול של נתיבי DMA הוא חלק מרוחב הפס (בייט/מחזור) שהיה בשימוש במהלך תקופת הפרופיל. הוא נגזר מNF_CTRL counters.
באיור הבא מוצגים 7 צמתים שמייצגים מקורות או יעדים של אזורי שוק ייעודיים, ו-14 נתיבים של אזורי שוק ייעודיים בצומת Tensor. הנתיבים 'BMem to VMem' ו-'Bmem to ICI' באיור הם למעשה נתיב משותף שנצבר על ידי מונה יחיד, שמוצג כ-'BMem to ICI/VMem' בכלי. DMA שנשלח אל ICI הוא DMA אל HBM או VMEM מרוחקים, בעוד ש-DMA מ-HIB או אל HIB הוא DMA מזיכרון המארח או אל זיכרון המארח.
flowchart TD HIB[HIB] HBM[HBM] IMem[IMem] SMem[SMem] BMem[BMem] VMem[VMem] ICI[ICI] HIB --> HBM HBM --> HIB subgraph Memory_Units [ ] direction LR style Memory_Units fill:none,stroke:none IMem SMem BMem VMem end HBM --> IMem HBM --> SMem HBM --> BMem HBM --> VMem BMem --> VMem BMem --> ICI VMem --> ICI ICI --> VMem ICI --> HBM VMem --> HBM BMem --> HBM SMem --> HBM HBM --> ICI