
مقدمة
XLA هو برنامج تجميع خاص بمجال الأجهزة والإطارات للجبر الخطي، ويوفّر أداءً هو الأفضل في فئته. تستخدم JAX وTensorFlow وPyTorch وغيرها XLA من خلال تحويل إدخال المستخدم إلى مجموعة عمليات StableHLO (عملية "عالية المستوى": مجموعة من حوالي 100 تعليمات ثابتة الشكل، مثل الجمع والطرح وضرب المصفوفات وما إلى ذلك)، والتي تنتج منها XLA رمزًا محسّنًا لمجموعة متنوعة من الخلفيات:
أثناء التنفيذ، تستدعي الأُطر واجهة برمجة التطبيقات وقت تشغيل PJRT، ما يتيح للأُطر تنفيذ العملية "تعبئة المخازن المؤقتة المحدّدة باستخدام برنامج StableHLO معيّن على جهاز محدّد".
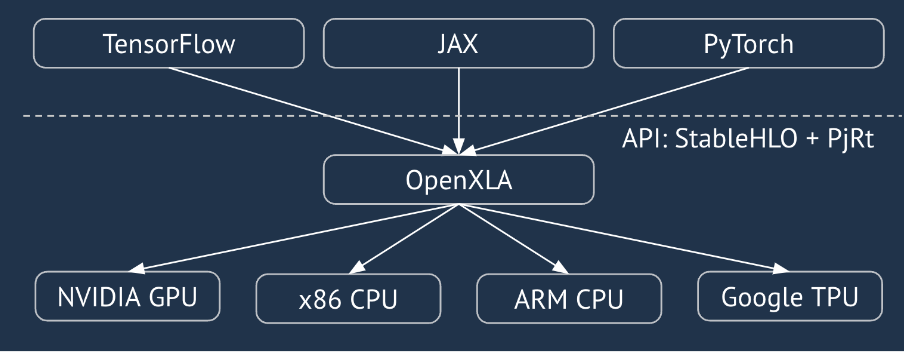
XLA:GPU Pipeline
تستخدم XLA:GPU مجموعة من أدوات إنشاء الرموز البرمجية "الأصلية" (PTX، من خلال LLVM) وأدوات إنشاء الرموز البرمجية TritonIR لإنشاء نوى وحدة معالجة الرسومات عالية الأداء (يشير اللون الأزرق إلى مكوّنات تابعة لجهات خارجية):
مثال على التنفيذ: JAX
لتوضيح عملية التنفيذ المتسلسل، لنبدأ بمثال عملي في JAX، وهو يحسب عملية ضرب المصفوفات مع الضرب في ثابت والنفي:
def f(a, b):
return -((a @ b) * 0.125)
يمكننا فحص HLO الذي تم إنشاؤه بواسطة الدالة:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
التي تنشئ ما يلي:
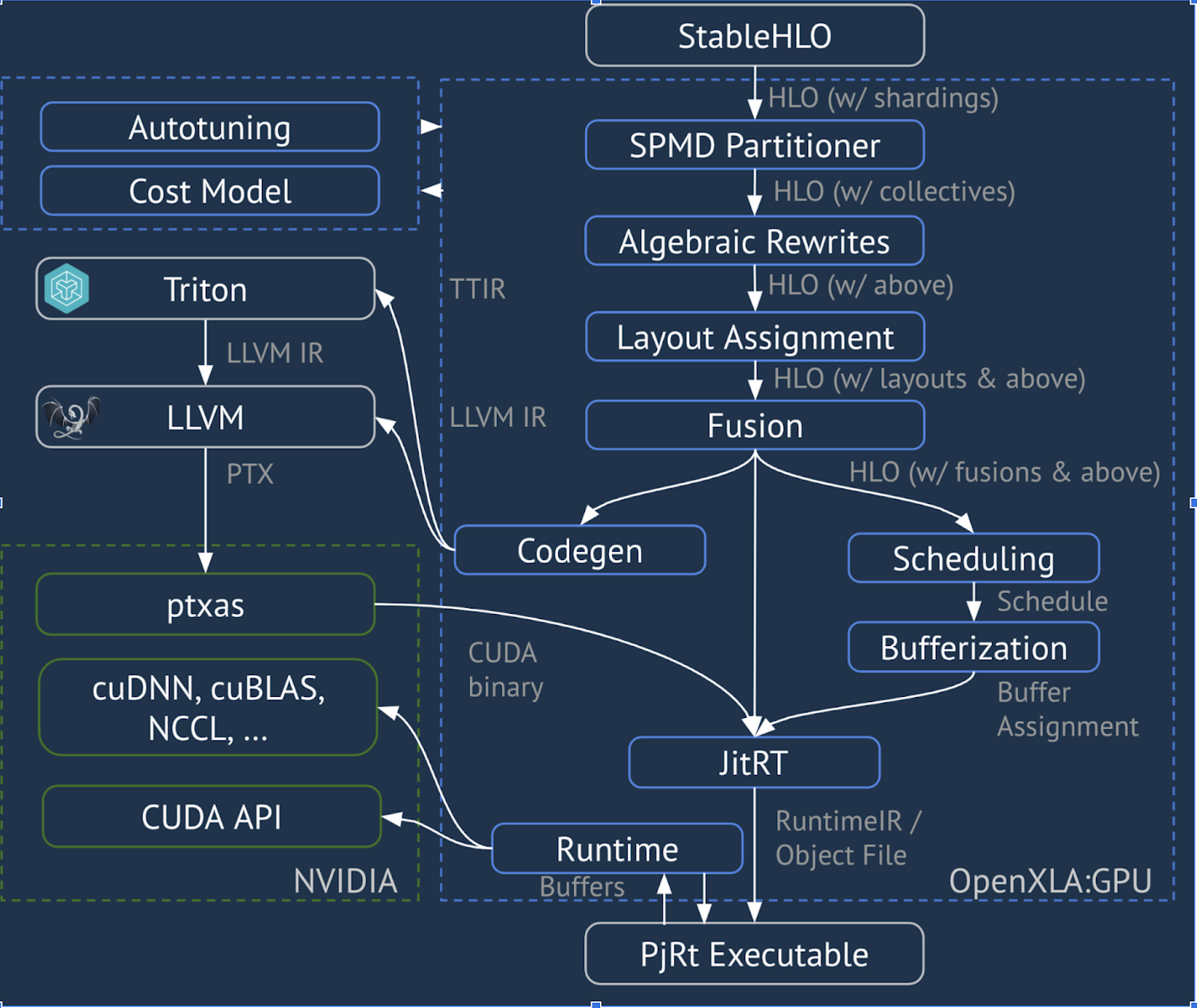
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
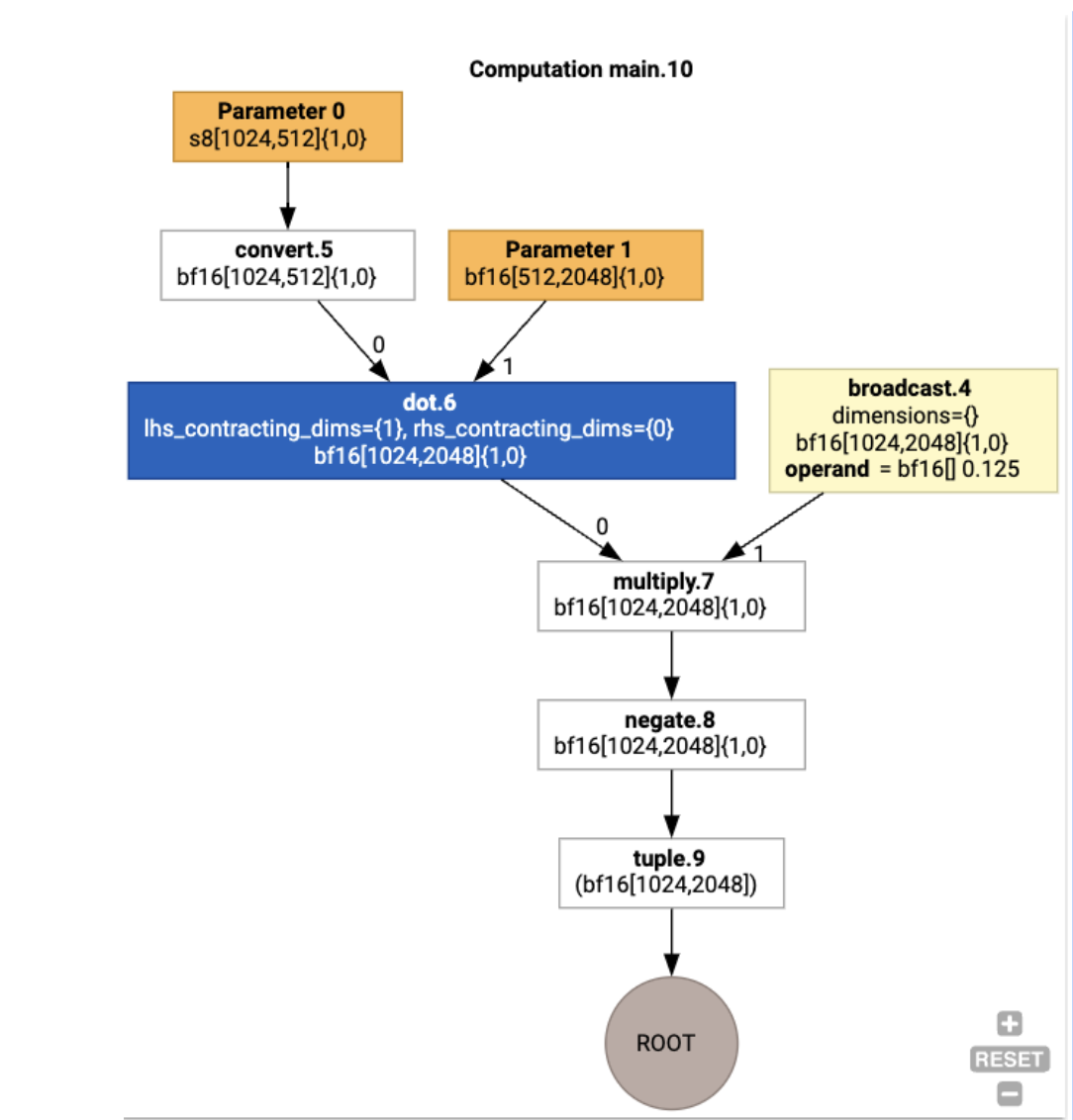
يمكننا أيضًا عرض عملية احتساب HLO للإدخال باستخدام
jax.xla_computation(f)(a, b).as_hlo_dot_graph():
التحسينات على HLO: المكوّنات الرئيسية
يتم إجراء عدد من عمليات التحسين البارزة على HLO، مثل عمليات إعادة الكتابة من HLO إلى HLO.
SPMD Partitioner
يستهلك مقسّم XLA SPMD، كما هو موضّح في GSPMD: General and Scalable Parallelization for MLComputation Graphs، لغة HLO مع تعليقات توضيحية للتجزئة (يتم إنتاجها مثلاً بواسطة jax.pjit)، وينتج لغة HLO مجزّأة يمكن تشغيلها بعد ذلك على عدد من المضيفين والأجهزة.
بالإضافة إلى التقسيم، تحاول SPMD تحسين HLO للحصول على جدول تنفيذي مثالي،
وتداخل العمليات الحسابية
والتواصل بين العُقد.
مثال
لنبدأ ببرنامج JAX بسيط مقسّم على جهازَين:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
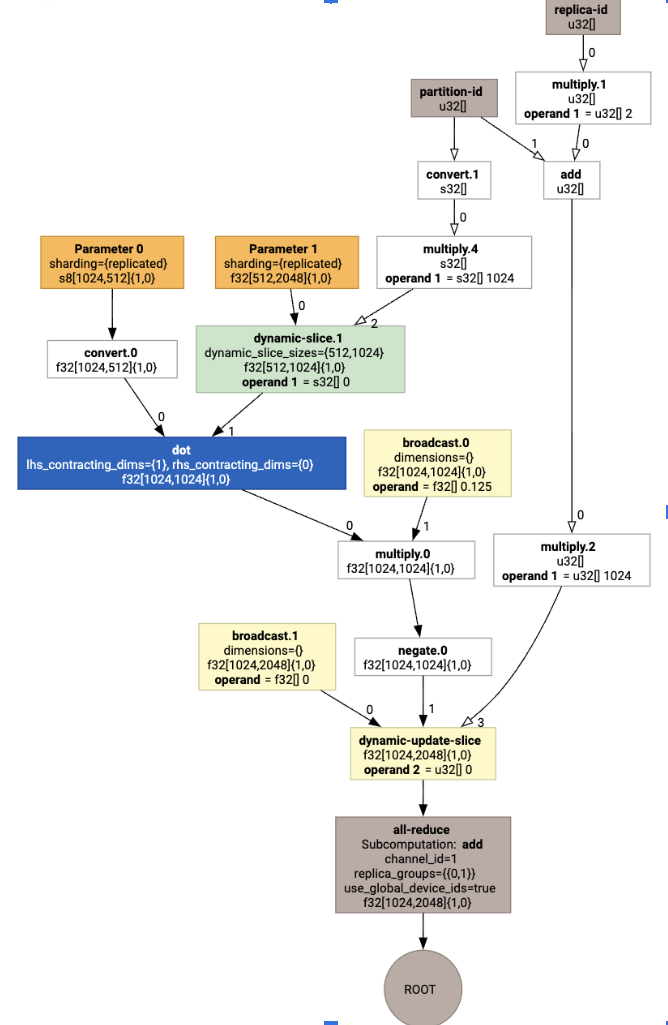
عند عرضها، يتم تقديم التعليقات التوضيحية الخاصة بالتقسيم على شكل طلبات مخصّصة:
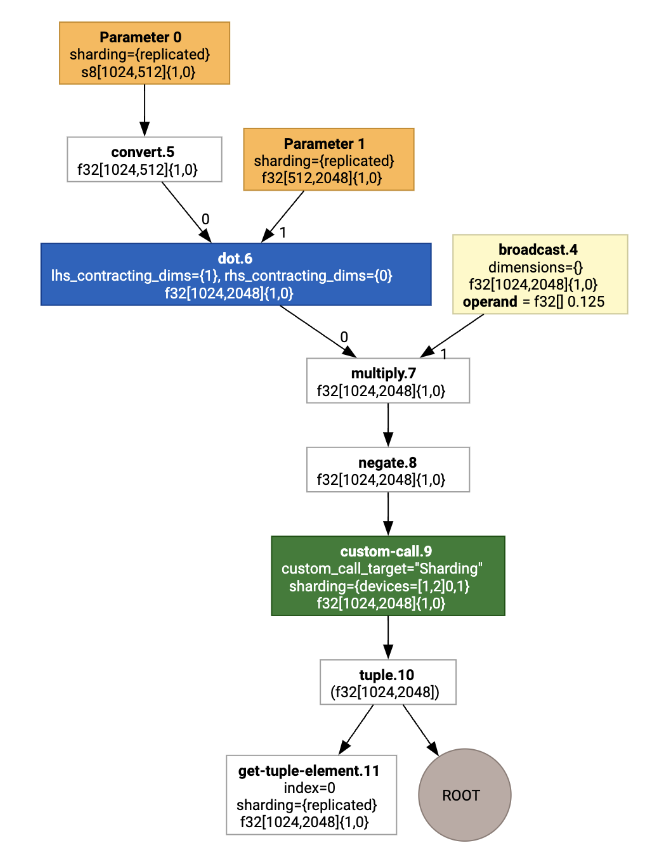
للتحقّق من كيفية توسيع أداة التقسيم SPMD للمكالمة المخصّصة، يمكننا الاطّلاع على HLO بعد إجراء التحسينات:
print(f.lower(np.ones((8, 8)).compile().as_text())
الذي ينشئ HLO مع مجموعة:
تحديد التنسيق
يفصل HLO الشكل المنطقي عن التنسيق المادي (طريقة ترتيب الموترات في الذاكرة). على سبيل المثال، يمكن تمثيل المصفوفة f32[32, 64] بترتيب الصفوف أو الأعمدة، كما هو موضح في {1,0} أو {0,1} على التوالي.
بشكل عام، يتم تمثيل التنسيق كجزء من الشكل، ما يعرض تبديلاً لعدد السمات التي تشير إلى التنسيق الفعلي في الذاكرة.
بالنسبة إلى كل عملية مضمّنة في HLO، يختار تمرير "تعيين التنسيق" تنسيقًا مثاليًا (مثل NHWC لعملية التفاف على Ampere). على سبيل المثال، تفضّل عملية ضرب المصفوفات int8xint8->int32 تنسيق {0,1} للجانب الأيمن من العملية الحسابية. وبالمثل، يتم تجاهل "عمليات النقل" التي يُدخلها المستخدم، ويتم ترميزها كتغيير في التنسيق.
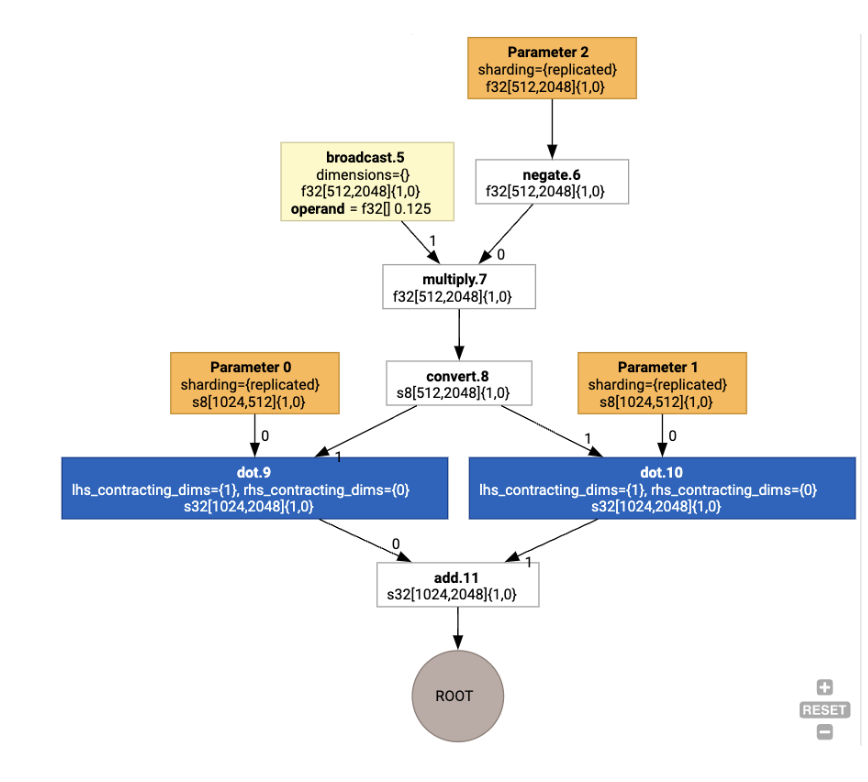
بعد ذلك، يتم نشر التنسيقات من خلال الرسم البياني، ويتم تحويل التعارضات بين التنسيقات أو في نقاط نهاية الرسم البياني إلى عمليات copy، والتي تنفّذ عملية التبديل المادي. على سبيل المثال، بدءًا من الرسم البياني
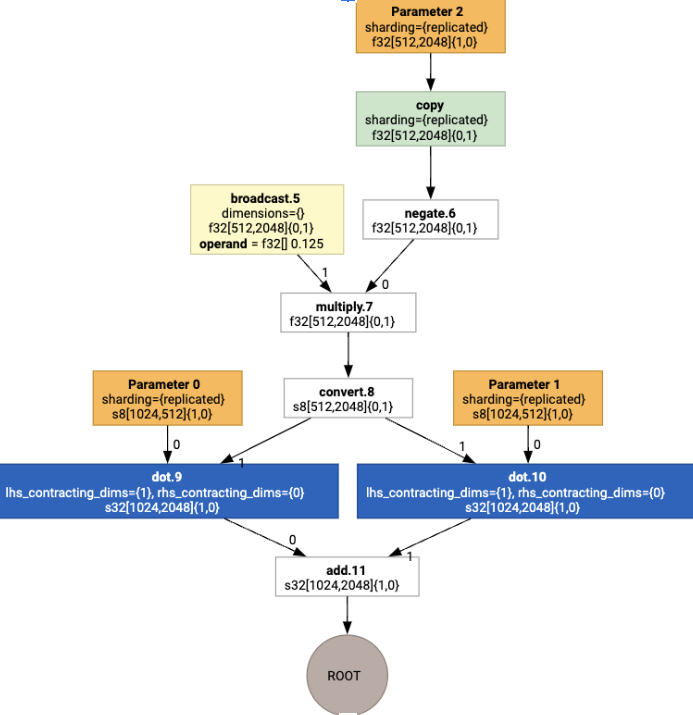
عند تنفيذ عملية تعيين التنسيق، نرى التنسيقات التالية وعملية copy التي تم إدراجها:
فيوجن
الدمج هو أهم عملية تحسين في XLA، وهو يجمع عمليات متعددة (مثل الجمع في الأس في ضرب المصفوفات) في نواة واحدة. بما أنّ العديد من أحمال عمل وحدة معالجة الرسومات تميل إلى أن تكون محدودة الذاكرة، فإنّ الدمج يؤدي إلى تسريع التنفيذ بشكل كبير من خلال تجنُّب كتابة الموترات الوسيطة إلى ذاكرة النطاق الترددي العالي ثم إعادة قراءتها، وبدلاً من ذلك يتم تمريرها في السجلات أو الذاكرة المشتركة.
يتم حظر تعليمات HLO المدمجة معًا في عملية حسابية واحدة للدمج، ما يؤدي إلى إنشاء الثوابت التالية:
لا يتم إنشاء أي مساحة تخزين وسيطة داخل عملية الدمج في ذاكرة النطاق الترددي العالي (HBM) (يجب أن يتم تمريرها كلها من خلال السجلات أو الذاكرة المشتركة).
يتم دائمًا تجميع عملية الدمج في نواة واحدة لوحدة معالجة الرسومات
أمثلة على تحسينات HLO أثناء التشغيل
يمكننا فحص HLO بعد التحسين باستخدام jax.jit(f).lower(a,
b).compile().as_text()، والتحقّق من أنّه تم إنشاء عملية دمج واحدة:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
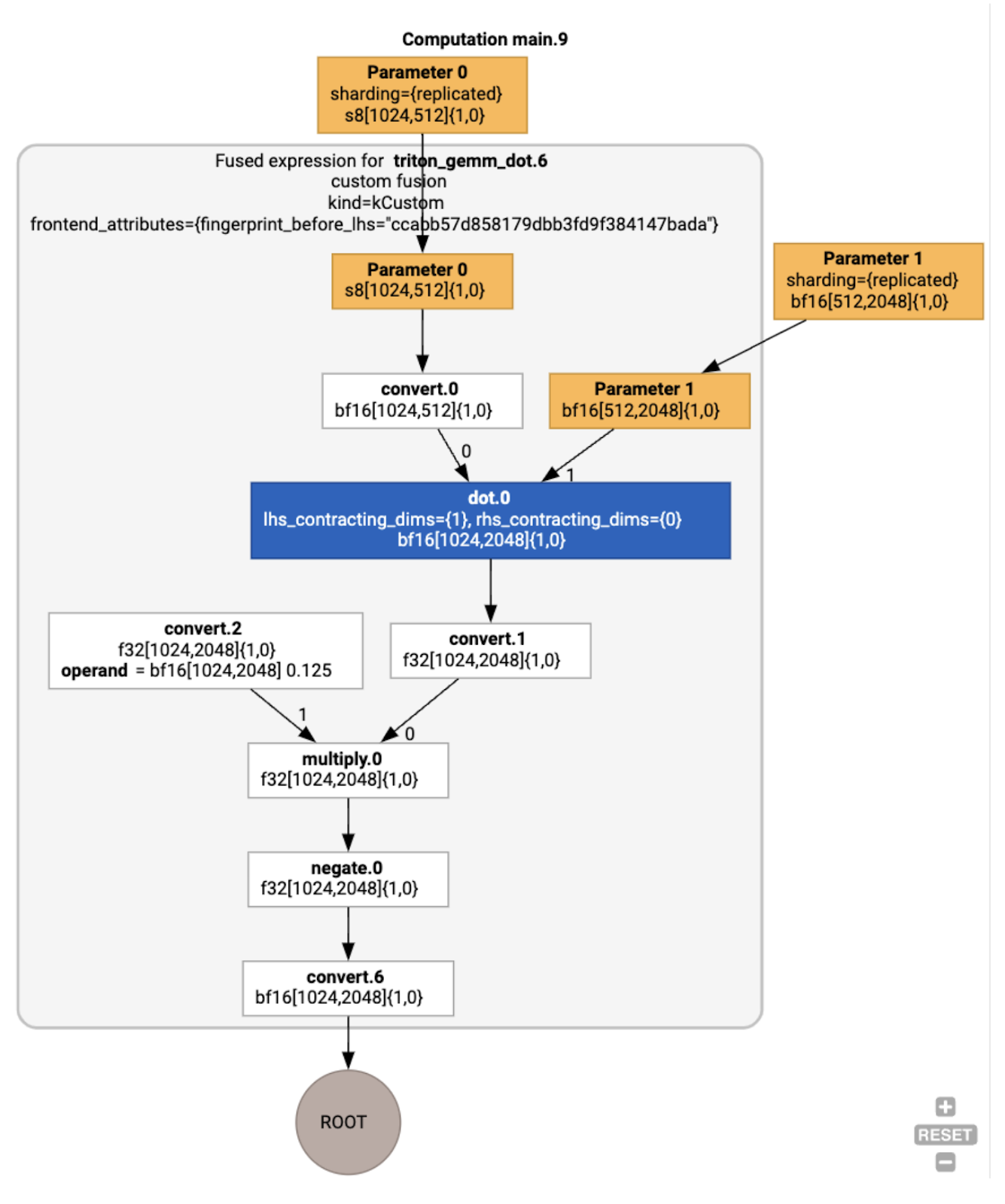
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
يُرجى العِلم أنّ عملية الدمج backend_config تخبرنا بأنّه سيتم استخدام Triton كاستراتيجية لإنشاء الرموز، وتحدّد عملية التقسيم التي تم اختيارها.
يمكننا أيضًا عرض الوحدة الناتجة على النحو التالي:
تحديد المهام في الفترة الآمنة وجدولتها
تأخذ عملية تخصيص المخزن المؤقت في الاعتبار معلومات الشكل، وتهدف إلى إنتاج تخصيص مثالي للمخزن المؤقت للبرنامج، ما يقلّل من مقدار الذاكرة الوسيطة المستهلكة. على عكس التنفيذ الفوري (غير المجمَّع) في TensorFlow أو PyTorch، حيث لا يعرف برنامج تخصيص الذاكرة الرسم البياني مسبقًا، يمكن لمجدول XLA "النظر إلى المستقبل" وإنشاء جدول زمني مثالي للحساب.
البرنامج الخلفي للمترجم: إنشاء الرموز واختيار المكتبة
بالنسبة إلى كل تعليمات HLO في عملية الحساب، يختار XLA ما إذا كان سيتم تنفيذها باستخدام مكتبة مرتبطة بوقت التشغيل، أو سيتم إنشاء رمز لها إلى PTX.
اختيار المكتبة
بالنسبة إلى العديد من العمليات الشائعة، تستخدم XLA:GPU مكتبات ذات أداء سريع من NVIDIA، مثل cuBLAS وcuDNN وNCCL. تتميّز المكتبات بأداء سريع وموثوق، ولكنها غالبًا ما تمنع فرص الدمج المعقّدة.
إنشاء الرموز البرمجية مباشرةً
تنشئ الخلفية XLA:GPU رمز LLVM IR عالي الأداء مباشرةً لعدد من العمليات (عمليات التصغير، وعمليات التبديل، وما إلى ذلك).
إنشاء الرموز البرمجية في Triton
بالنسبة إلى عمليات الدمج الأكثر تقدّمًا التي تتضمّن ضرب المصفوفات أو Softmax، تستخدم XLA:GPU Triton كطبقة لإنشاء الرموز. يتم تحويل عمليات دمج HLO إلى TritonIR (وهي صيغة MLIR تعمل كمدخل إلى Triton)، ويتم اختيار مَعلمات التقسيم إلى مربّعات واستدعاء Triton لإنشاء PTX:
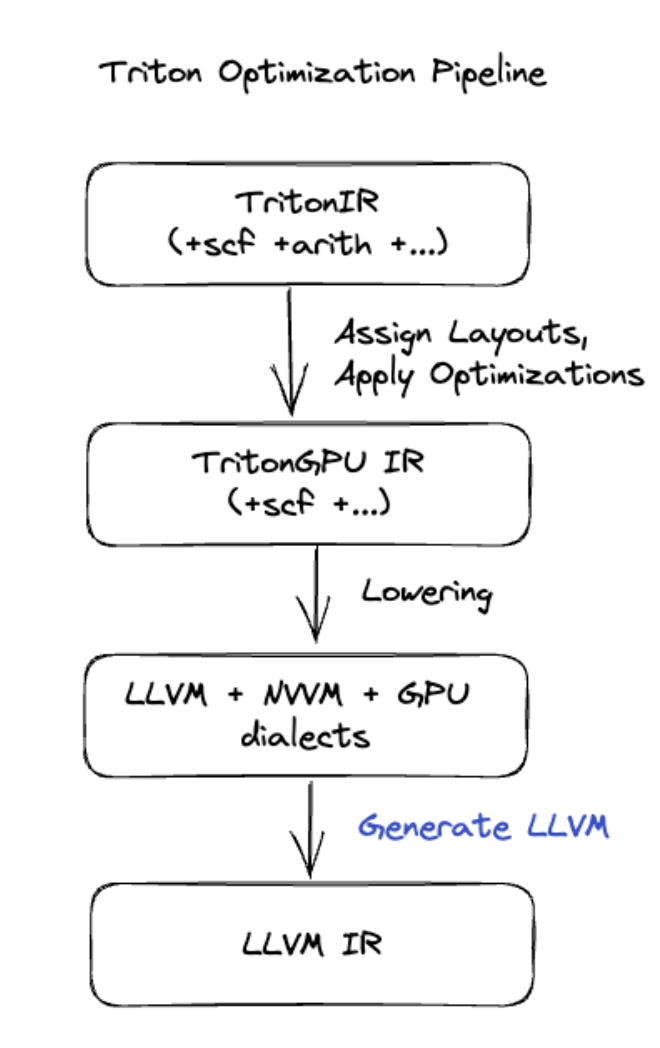
لقد لاحظنا أنّ الرمز الناتج يحقّق أداءً ممتازًا على Ampere، إذ يقدّم أداءً قريبًا من الحدّ الأقصى مع أحجام مربّعات معدَّلة بشكل صحيح.
وقت التشغيل
يحوّل XLA Runtime تسلسل استدعاءات نواة CUDA واستدعاءات المكتبة الناتجة إلى RuntimeIR (وهي صيغة MLIR في XLA)، ويتم استخراج الرسم البياني لـ CUDA عليها. لا يزال العمل جارياً على ميزة "الرسم البياني CUDA"، ولا تتوفّر حاليًا سوى بعض العُقد. بعد استخراج حدود الرسم البياني CUDA، يتم تجميع RuntimeIR من خلال LLVM إلى ملف تنفيذي لوحدة المعالجة المركزية، ويمكن بعد ذلك تخزينه أو نقله للتجميع مسبقًا.