
Introduzione
XLA è un compilatore specifico per il dominio di hardware e framework per l'algebra lineare, che offre prestazioni di prima classe. JAX, TF, Pytorch e altri utilizzano XLA convertendo l'input dell'utente in un set di operazioni StableHLO ("operazione di alto livello": un insieme di circa 100 istruzioni con forma statica come addizione, sottrazione, matmul e così via), da cui XLA produce codice ottimizzato per una serie di backend:
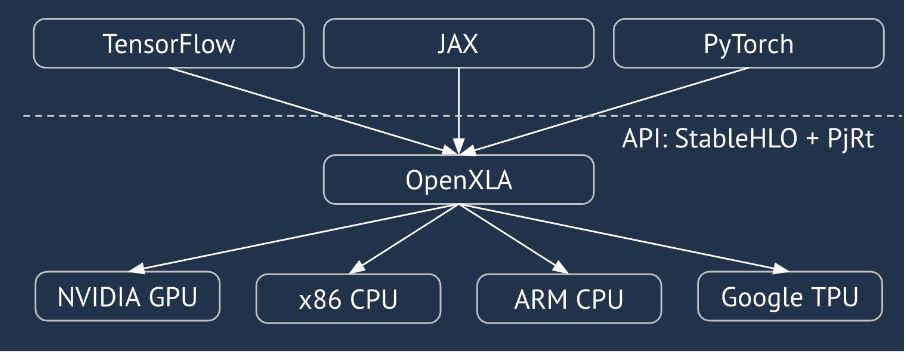
Durante l'esecuzione, i framework richiamano l'API PJRT runtime, che consente ai framework di eseguire l'operazione "popola i buffer specificati utilizzando un determinato programma StableHLO su un dispositivo specifico".
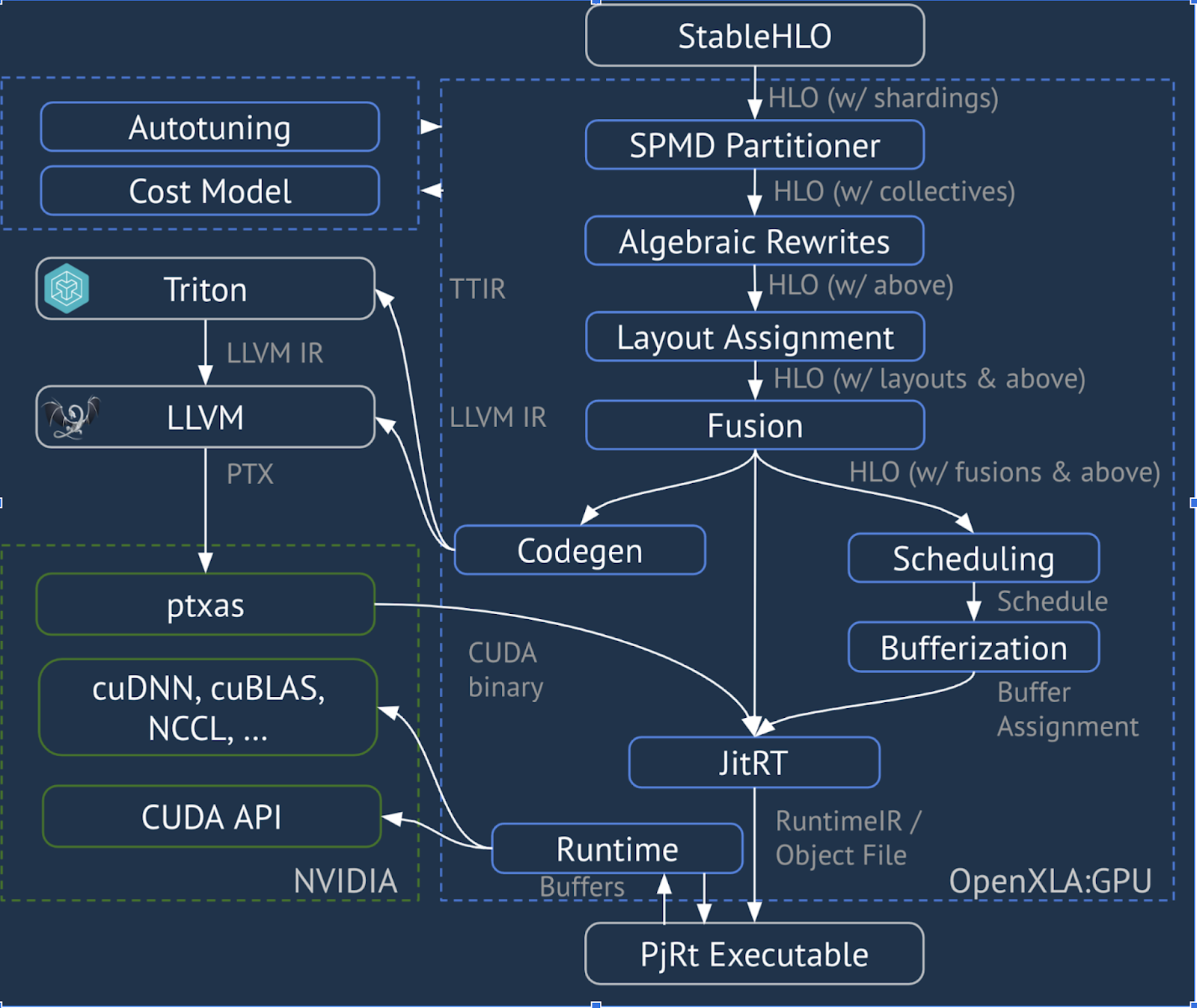
XLA:GPU Pipeline
XLA:GPU utilizza una combinazione di emettitori "nativi" (PTX, tramite LLVM) ed emettitori TritonIR per generare kernel GPU ad alte prestazioni (il colore blu indica i componenti di terze parti):
Esempio di corsa: JAX
Per illustrare la pipeline, iniziamo con un esempio in esecuzione in JAX, che calcola una moltiplicazione di matrici combinata con la moltiplicazione per una costante e la negazione:
def f(a, b):
return -((a @ b) * 0.125)
Possiamo esaminare l'HLO generato dalla funzione:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
che genera:
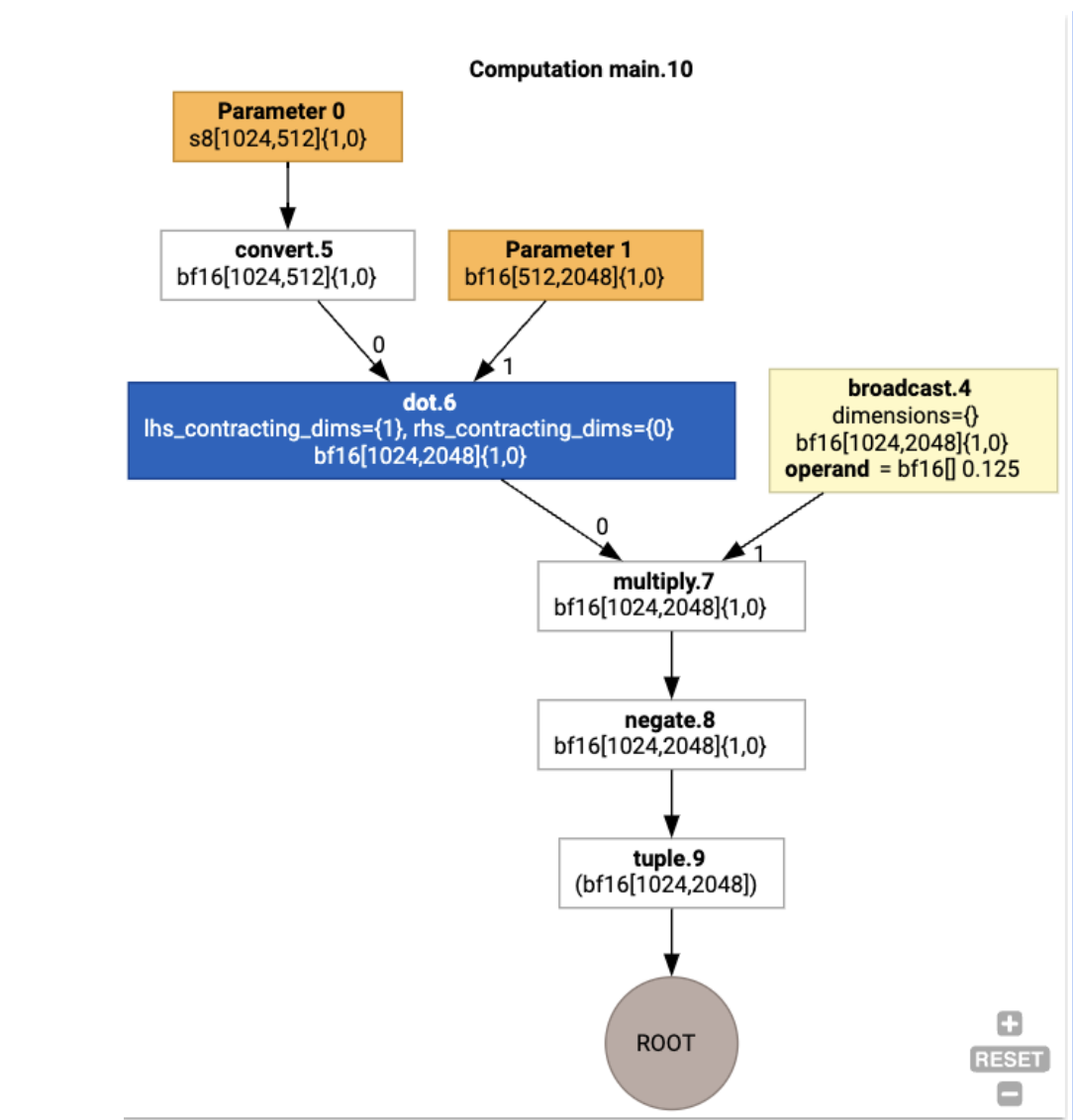
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
Possiamo visualizzare anche il calcolo HLO di input utilizzando
jax.xla_computation(f)(a, b).as_hlo_dot_graph():
Ottimizzazioni su HLO: componenti chiave
Su HLO vengono eseguite diverse ottimizzazioni importanti, come le riscritture HLO->HLO.
SPMD Partitioner
Il partizionatore XLA SPMD, come descritto in
GSPMD: General and Scalable Parallelization for MLComputation Graphs,
utilizza HLO con annotazioni di sharding (prodotte ad esempio da jax.pjit) e
produce un HLO sottoposto a sharding che può essere eseguito su un numero di host e dispositivi.
Oltre al partizionamento, SPMD tenta di ottimizzare HLO per una pianificazione di esecuzione ottimale, un calcolo sovrapposto e la comunicazione tra i nodi.
Esempio
Valuta di iniziare con un semplice programma JAX suddiviso in due dispositivi:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
Se visualizzate, le annotazioni di sharding vengono presentate come chiamate personalizzate:
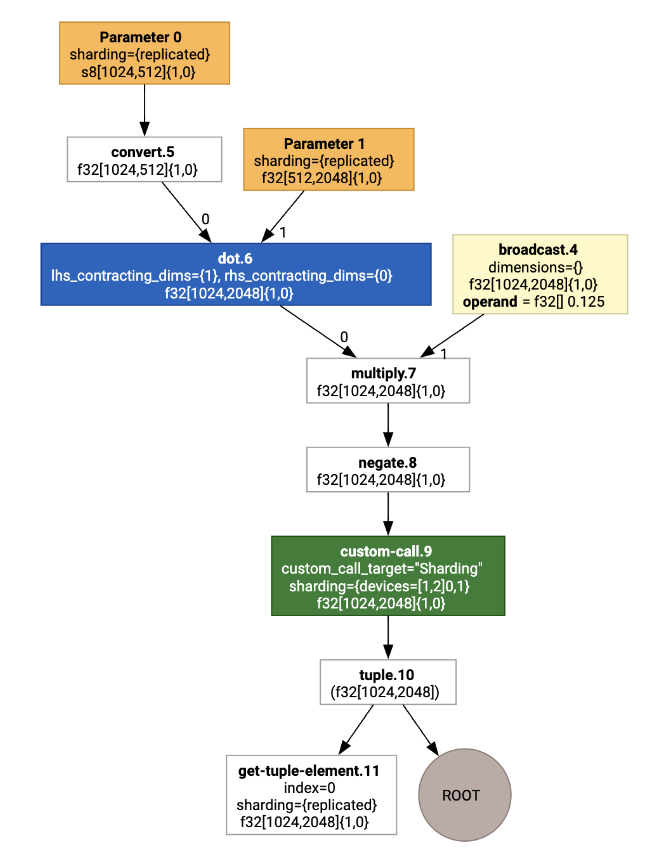
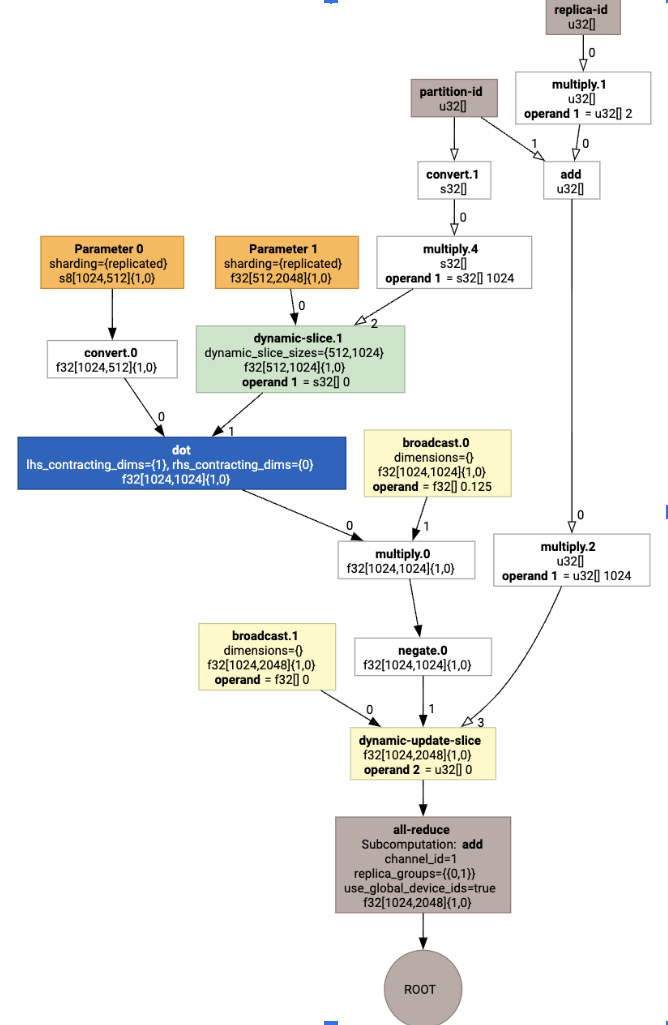
Per verificare in che modo il partizionatore SPMD espande la chiamata personalizzata, possiamo esaminare HLO dopo le ottimizzazioni:
print(f.lower(np.ones((8, 8)).compile().as_text())
che genera HLO con una collettiva:
Assegnazione layout
HLO separa la forma logica e il layout fisico (come sono disposti i tensori in
memoria). Ad esempio, una matrice f32[32, 64] può essere rappresentata in ordine
per righe o per colonne, come {1,0} o {0,1} rispettivamente.
In generale, il layout è rappresentato come parte della forma, mostrando una permutazione sul numero di dimensioni che indicano il layout fisico in memoria.
Per ogni operazione presente nell'HLO, il passaggio di assegnazione del layout sceglie un
layout ottimale (ad es. NHWC per una convoluzione su Ampere). Ad esempio, un'operazione
int8xint8->int32 matmul preferisce il layout {0,1} per il lato destro del
calcolo. Allo stesso modo, le "trasposizioni" inserite dall'utente vengono ignorate e
codificate come una modifica del layout.
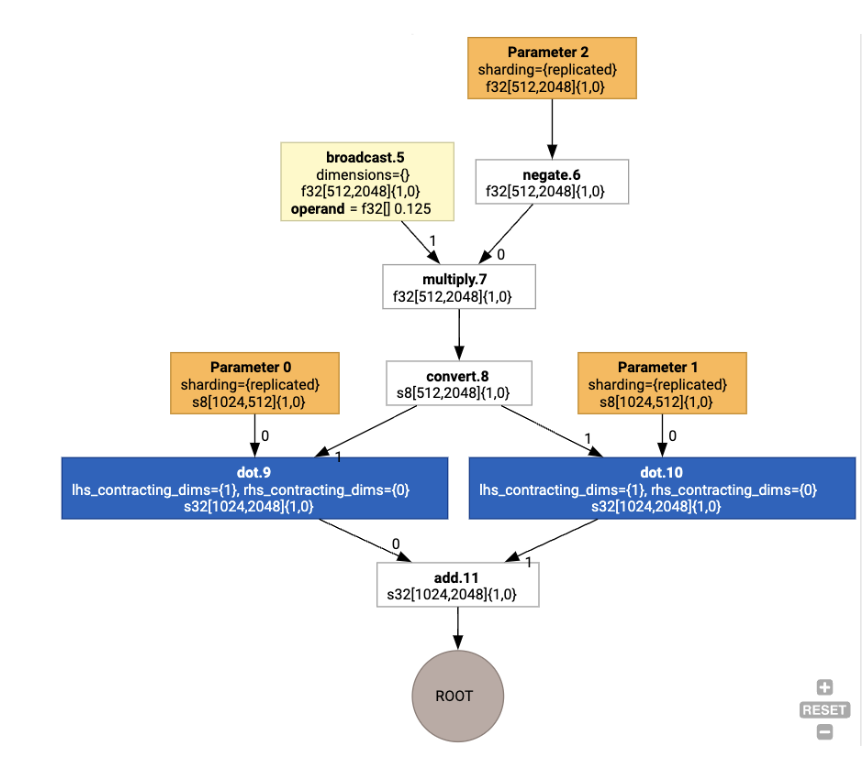
I layout vengono quindi propagati attraverso il grafico e i conflitti tra i layout
o negli endpoint del grafico vengono materializzati come operazioni copy, che eseguono la
trasposizione fisica. Ad esempio, partendo dal grafico
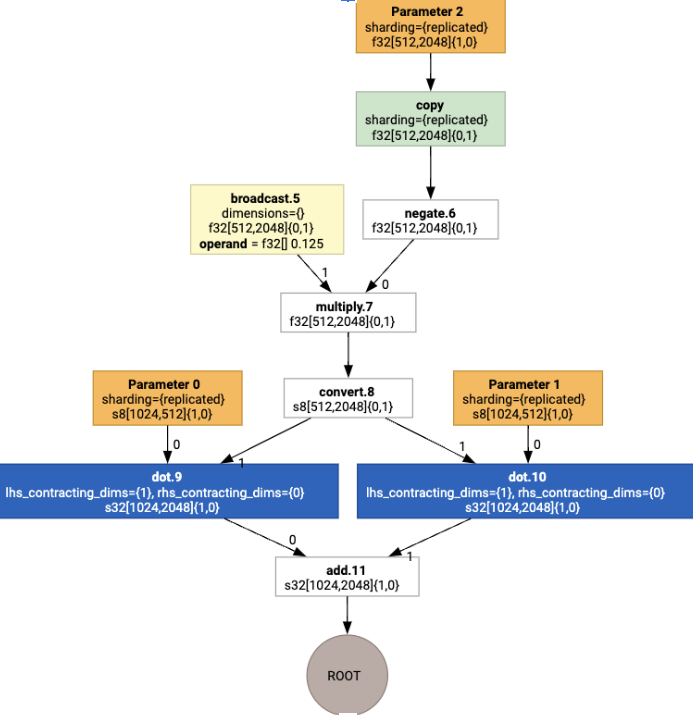
Se esegui l'assegnazione del layout, vengono inseriti i seguenti layout e l'operazione copy:
Fusione
La fusione è l'ottimizzazione più importante di XLA, che raggruppa più operazioni (ad es. addizione in elevamento a potenza in matmul) in un unico kernel. Poiché molti carichi di lavoro della GPU tendono a essere vincolati dalla memoria, la fusione accelera notevolmente l'esecuzione evitando la scrittura di tensori intermedi nella HBM e poi la loro rilettura, e li passa invece in registri o memoria condivisa.
Le istruzioni HLO fuse vengono bloccate insieme in un unico calcolo di fusione, che stabilisce i seguenti invarianti:
Nessuno spazio di archiviazione intermedio all'interno della fusione viene materializzato in HBM (deve essere tutto passato attraverso registri o memoria condivisa).
Una fusione viene sempre compilata in esattamente un kernel GPU
Ottimizzazioni HLO nell'esempio di esecuzione
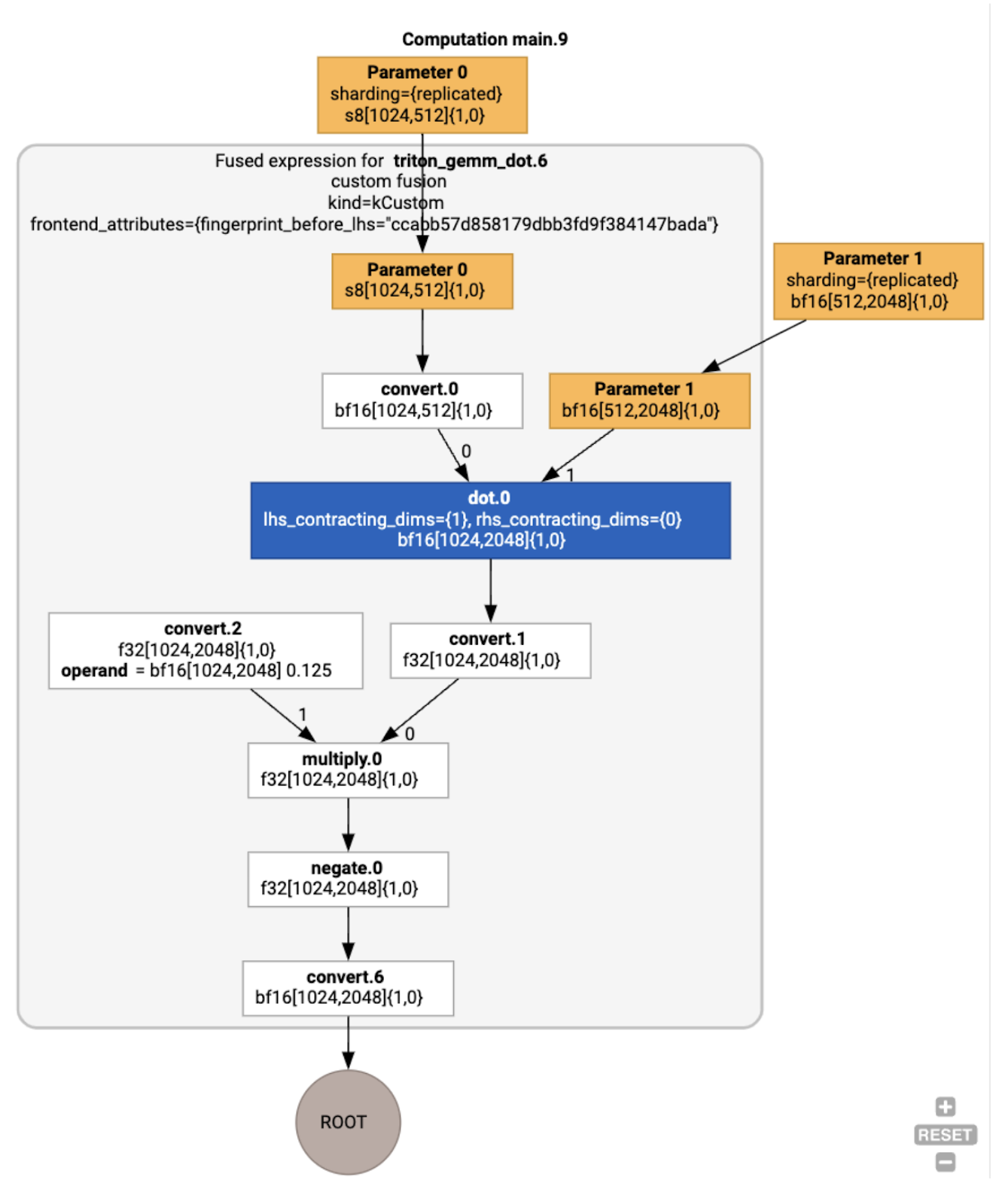
Possiamo esaminare l'HLO post-ottimizzazione utilizzando jax.jit(f).lower(a,
b).compile().as_text() e verificare che sia stata generata una singola fusione:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
Tieni presente che la fusione backend_config indica che Triton verrà utilizzato come
strategia di generazione del codice e specifica il tiling scelto.
Possiamo anche visualizzare il modulo risultante:
Assegnazione e pianificazione del buffer
Un passaggio di assegnazione del buffer tiene conto delle informazioni sulla forma e mira a produrre un'allocazione ottimale del buffer per il programma, riducendo al minimo la quantità di memoria intermedia consumata. A differenza dell'esecuzione in modalità immediata (non compilata) di TF o PyTorch, in cui l'allocatore di memoria non conosce in anticipo il grafico, lo scheduler XLA può "guardare al futuro" e produrre una pianificazione ottimale del calcolo.
Backend del compilatore: generazione di codice e selezione della libreria
Per ogni istruzione HLO nel calcolo, XLA sceglie se eseguirla utilizzando una libreria collegata a un runtime o se generare il codice PTX.
Selezione della raccolta
Per molte operazioni comuni, XLA:GPU utilizza librerie ad alte prestazioni di NVIDIA, come cuBLAS, cuDNN e NCCL. Le librerie hanno il vantaggio di prestazioni veloci verificate, ma spesso precludono opportunità di fusione complesse.
Generazione diretta del codice
Il backend XLA:GPU genera LLVM IR ad alte prestazioni direttamente per una serie di operazioni (riduzioni, trasposizioni e così via).
Generazione del codice Triton
Per fusioni più avanzate che includono la moltiplicazione di matrici o softmax, XLA:GPU utilizza Triton come livello di generazione del codice. Le fusioni HLO vengono convertite in TritonIR (un dialetto MLIR che funge da input per Triton), seleziona i parametri di tiling e richiama Triton per la generazione di PTX:
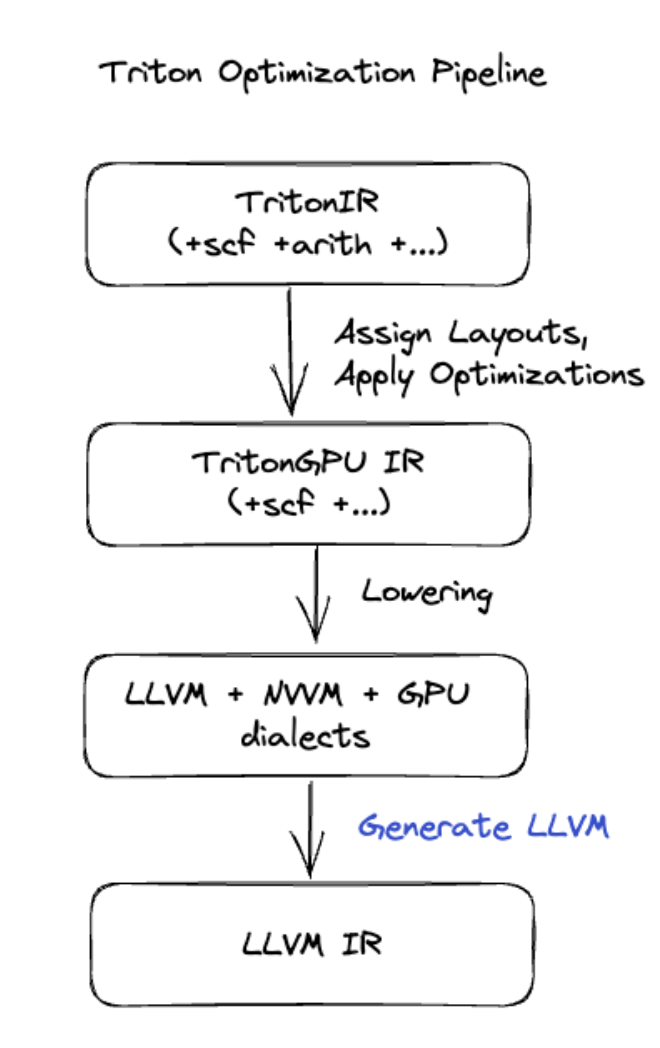
Abbiamo osservato che il codice risultante ha un ottimo rendimento su Ampere, con prestazioni quasi ottimali con dimensioni dei riquadri regolate correttamente.
Runtime
XLA Runtime converte la sequenza risultante di chiamate al kernel CUDA e invocazioni della libreria in un RuntimeIR (un dialetto MLIR in XLA), su cui viene eseguita l'estrazione del grafico CUDA. Il grafico CUDA è ancora in fase di sviluppo e al momento sono supportati solo alcuni nodi. Una volta estratti i limiti del grafico CUDA, RuntimeIR viene compilato tramite LLVM in un eseguibile della CPU, che può essere archiviato o trasferito per la compilazione Ahead-Of-Time.