
はじめに
XLA は、線形代数のためのハードウェアとフレームワークのドメイン固有のコンパイラであり、クラス最高のパフォーマンスを提供します。JAX、TF、Pytorch などは、ユーザー入力を StableHLO(「高レベル オペレーション」: 加算、減算、matmul などの約 100 個の静的に整形された命令のセット)オペレーション セットに変換して XLA を使用します。XLA は、このオペレーション セットからさまざまなバックエンド向けに最適化されたコードを生成します。
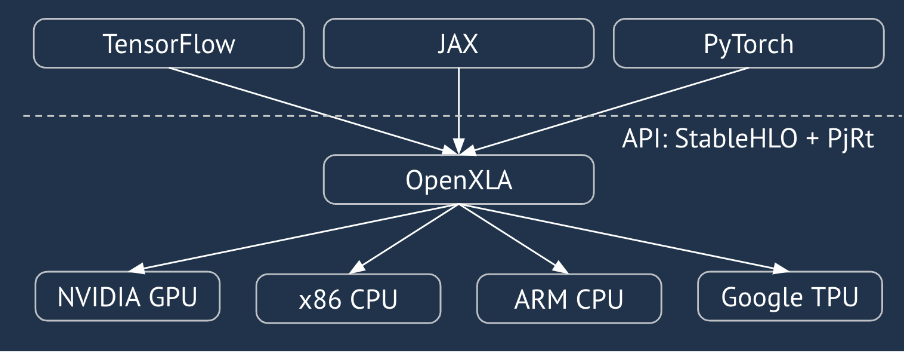
実行中、フレームワークは PJRT ランタイム API を呼び出します。これにより、フレームワークは「特定のデバイス上の特定の StableHLO プログラムを使用して指定されたバッファを移入する」オペレーションを実行できます。
XLA:GPU パイプライン
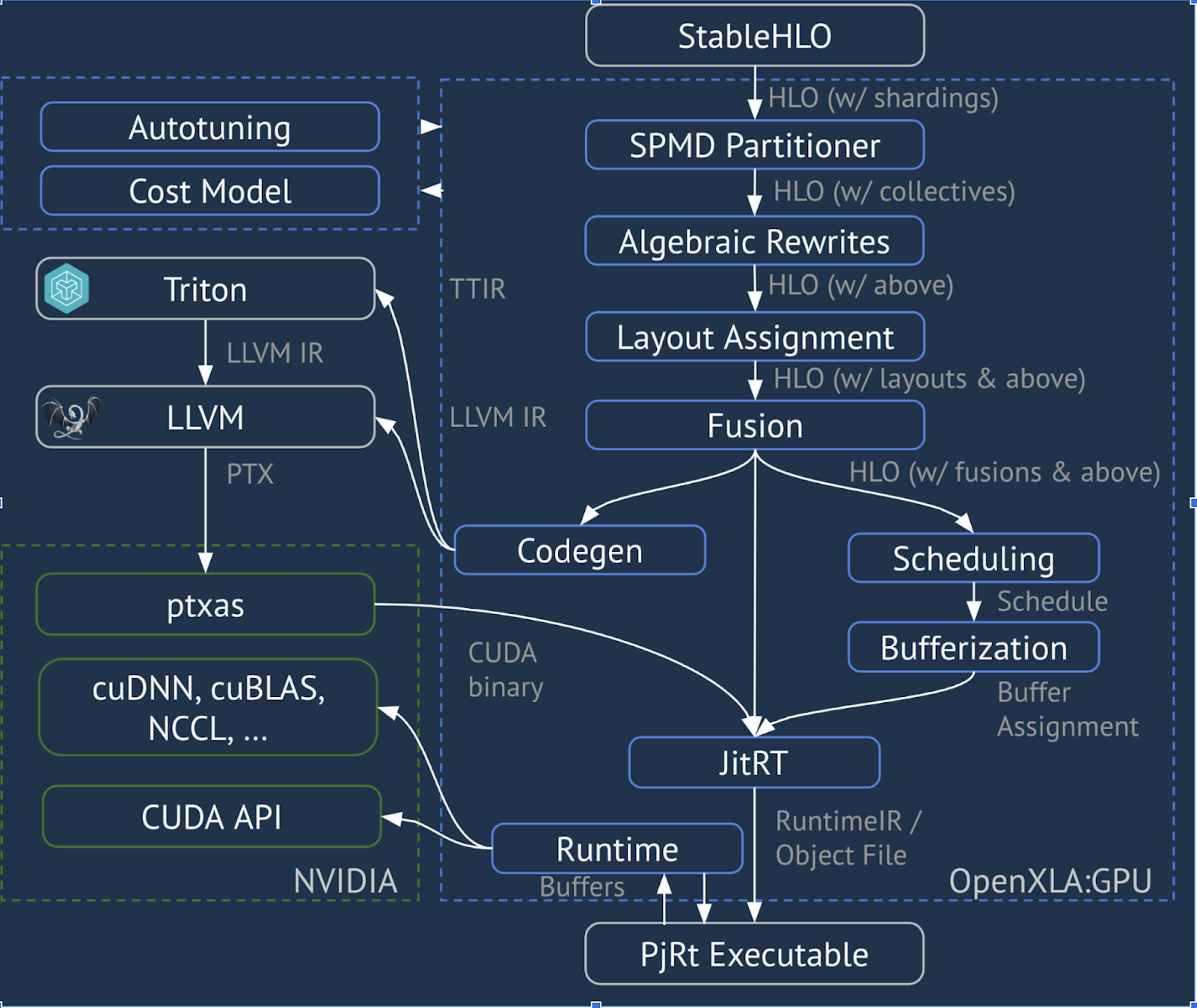
XLA:GPU は、「ネイティブ」(LLVM 経由の PTX)エミッタと TritonIR エミッタを組み合わせて使用し、高性能 GPU カーネルを生成します(青色はサードパーティ コンポーネントを示します)。
実行例: JAX
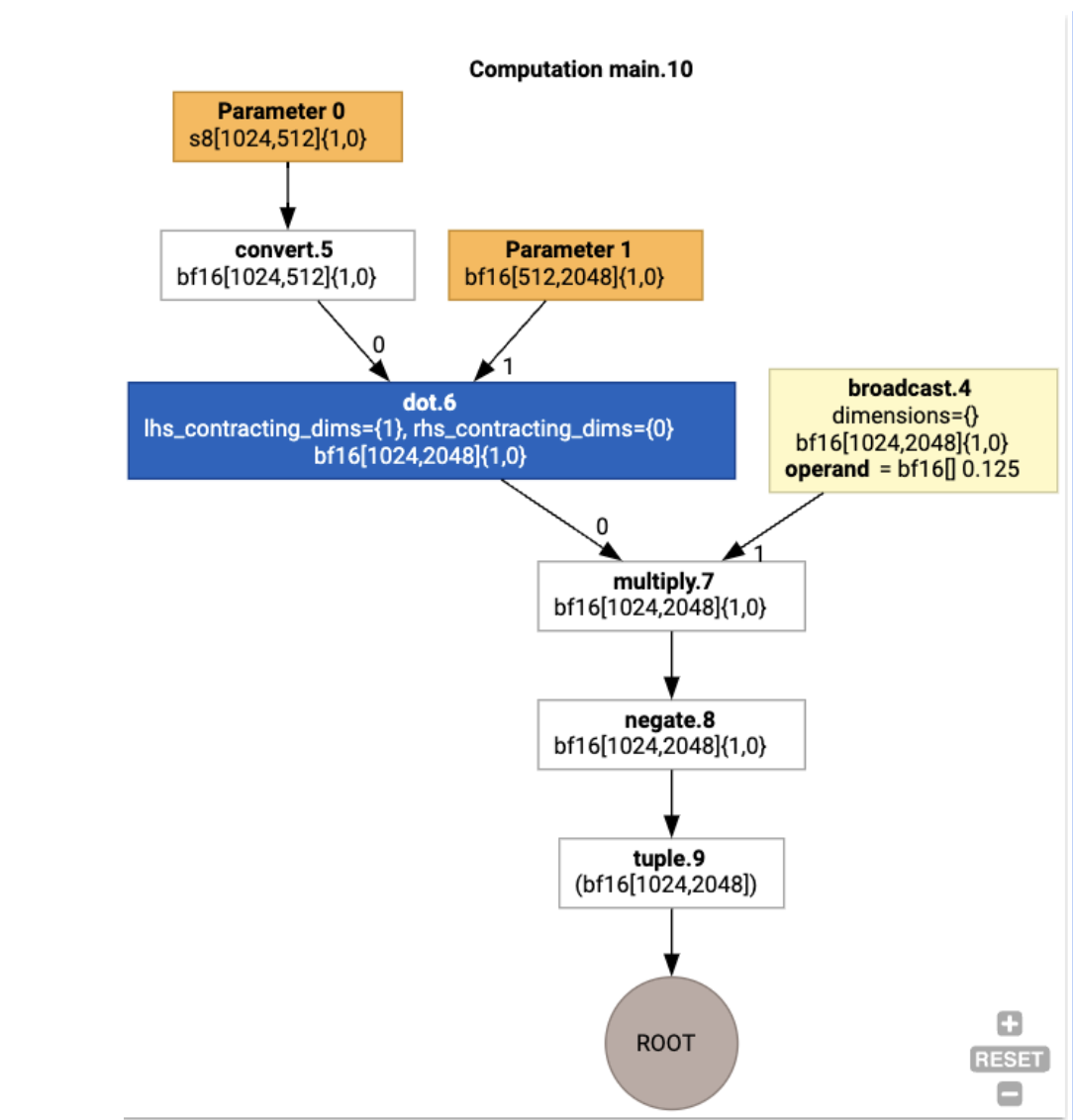
パイプラインを説明するために、JAX の実行例から始めましょう。この例では、定数による乗算と否定を組み合わせた matmul を計算します。
def f(a, b):
return -((a @ b) * 0.125)
関数によって生成された HLO を検査できます。
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
生成されるのは次のとおりです。
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
jax.xla_computation(f)(a, b).as_hlo_dot_graph() を使用して、入力 HLO 計算を可視化することもできます。
HLO の最適化: 主要コンポーネント
HLO では、HLO->HLO の書き換えとして、多くの注目すべき最適化パスが行われます。
SPMD パーティショナー
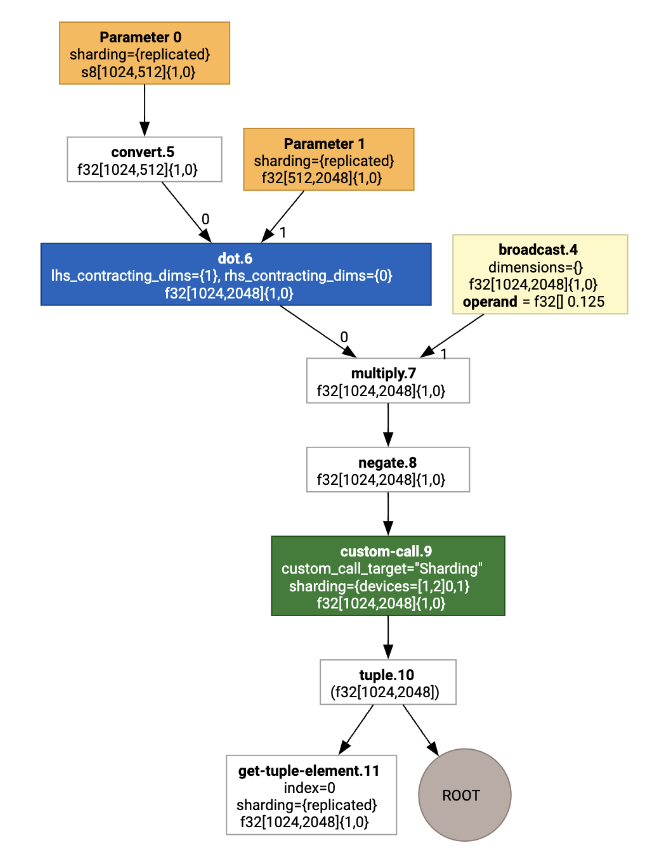
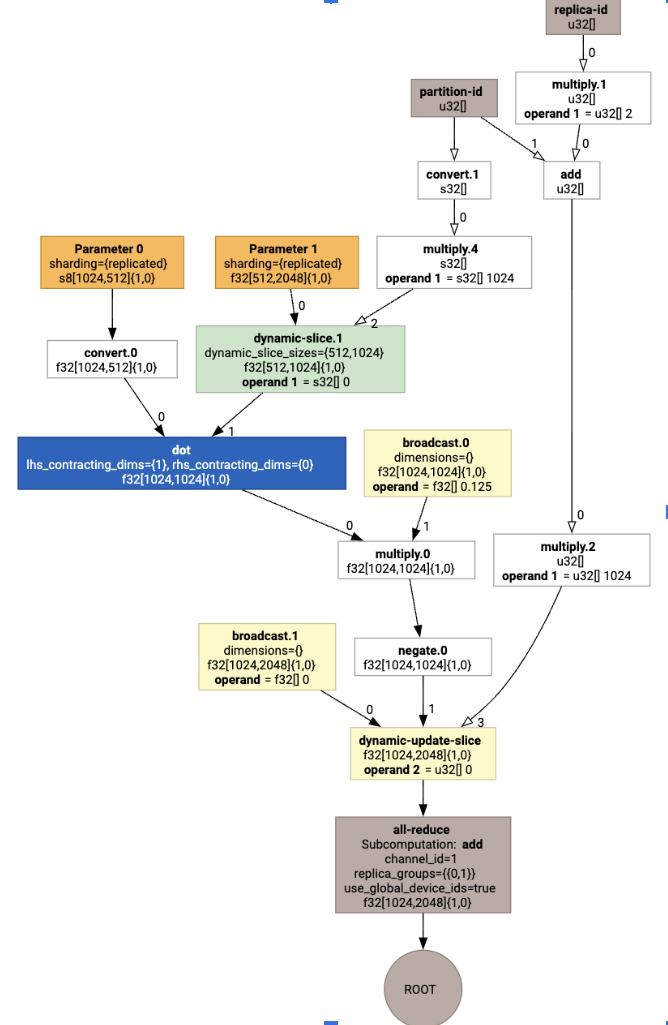
GSPMD: ML 計算グラフの一般および拡張可能な並列化で説明されているように、XLA SPMD パーティショナーは、シャーディング アノテーション(jax.pjit などによって生成)を含む HLO を使用し、シャーディングされた HLO を生成します。この HLO は、複数のホストとデバイスで実行できます。パーティショニング以外にも、SPMD は最適な実行スケジュール、ノード間の計算と通信のオーバーラップのために HLO を最適化しようとします。
例
2 つのデバイスにシャーディングされた簡単な JAX プログラムから始めることを検討してください。
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
視覚化すると、シャーディング アノテーションはカスタム呼び出しとして表示されます。
SPMD パーティショナーがカスタム呼び出しをどのように展開するかを確認するには、最適化後の HLO を確認します。
print(f.lower(np.ones((8, 8)).compile().as_text())
これにより、次のコレクティブを含む HLO が生成されます。
レイアウトの割り当て
HLO は、論理形状と物理レイアウト(テンソルがメモリにどのようにレイアウトされるか)を分離します。たとえば、行列 f32[32, 64] は行優先または列優先の順序で表すことができ、それぞれ {1,0} または {0,1} として表されます。一般に、レイアウトは形状の一部として表され、メモリ内の物理レイアウトを示す次元の数に対する順列を示します。
HLO に存在する各オペレーションに対して、レイアウト割り当てパスは最適なレイアウト(Ampere の畳み込みの場合は NHWC など)を選択します。たとえば、int8xint8->int32 matmul オペレーションは、計算の RHS に {0,1} レイアウトを優先します。同様に、ユーザーが挿入した「転置」は無視され、レイアウトの変更としてエンコードされます。
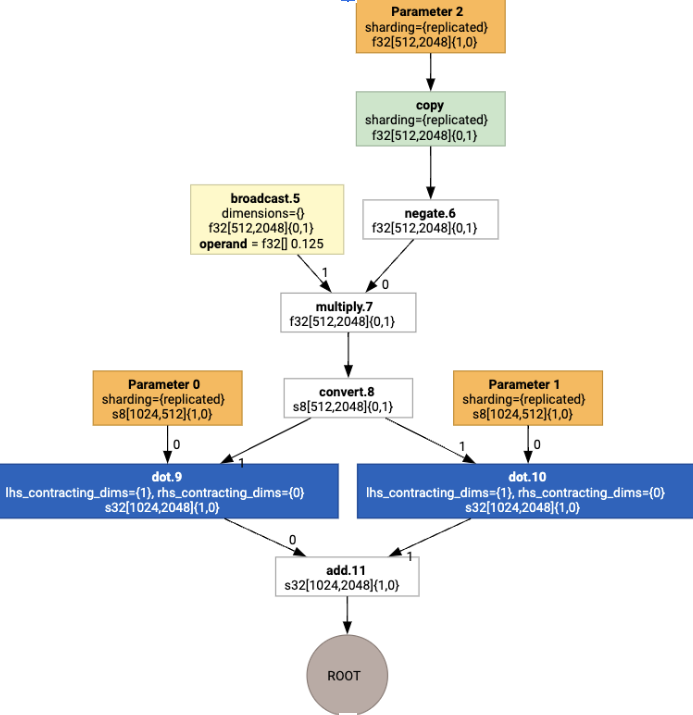
レイアウトはグラフ全体に伝播され、レイアウト間またはグラフ エンドポイントの競合は、物理的な転置を実行する copy オペレーションとして具体化されます。たとえば、グラフから
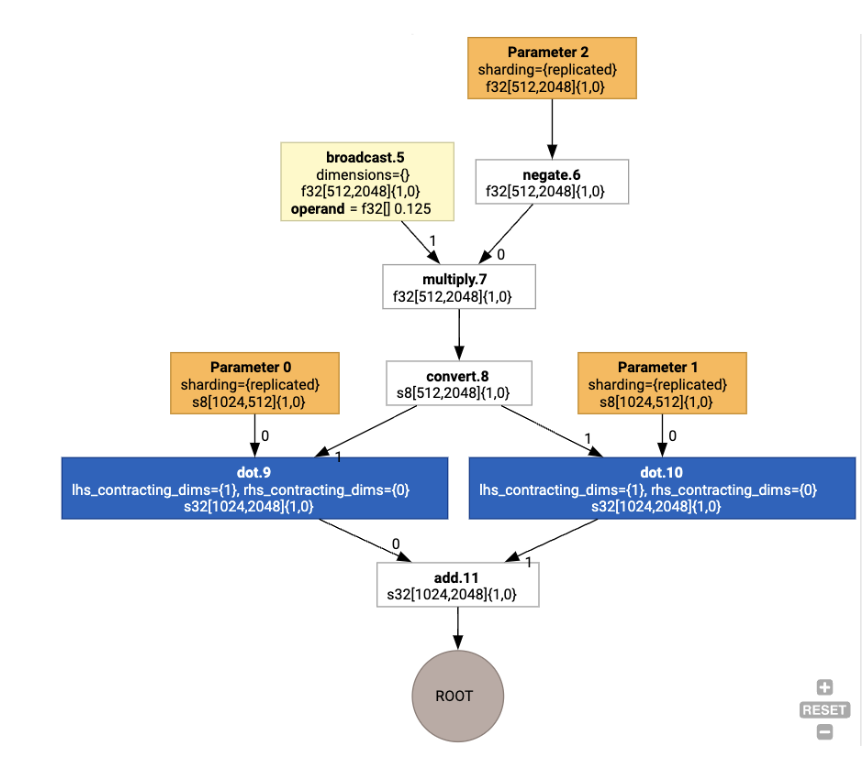
レイアウトの割り当てを実行すると、次のレイアウトと copy オペレーションが挿入されます。
Fusion
融合は、XLA の唯一かつ重要な最適化手法です。複数のオペレーション(加算、指数関数、matmul など)を単一のカーネルにグループ化します。多くの GPU ワークロードはメモリバウンドであるため、フュージョンは中間テンソルを HBM に書き込んでから読み戻すことを回避し、代わりにレジスタまたは共有メモリで渡すことで、実行を大幅に高速化します。
融合された HLO 命令は、単一の融合計算でまとめてブロックされます。これにより、次の不変条件が確立されます。
フュージョン内の中間ストレージは HBM で具体化されません(レジスタまたは共有メモリのいずれかを介してすべて渡す必要があります)。
フュージョンは常に 1 つの GPU カーネルにコンパイルされます
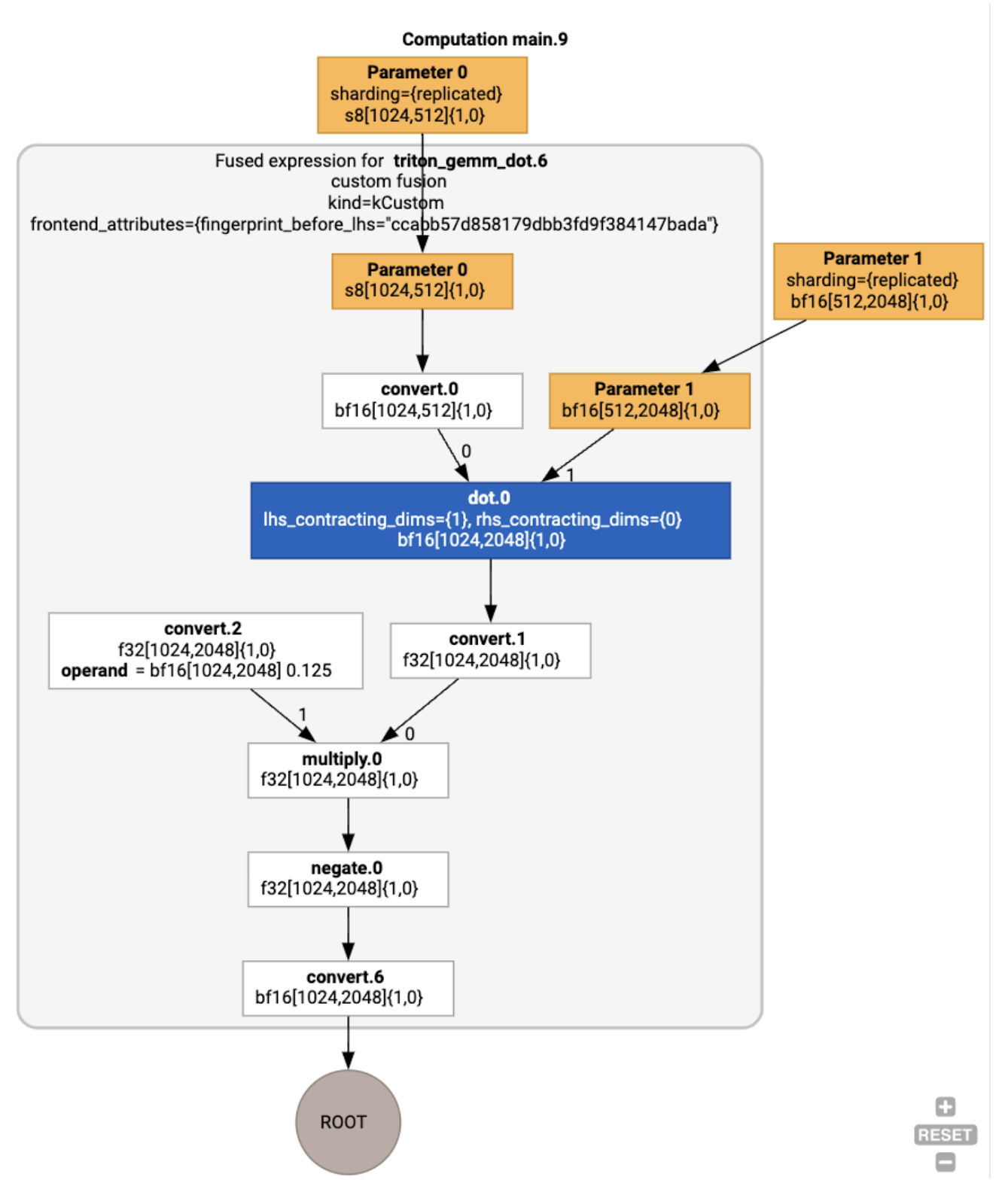
実行例での HLO 最適化
jax.jit(f).lower(a,
b).compile().as_text() を使用して最適化後の HLO を検査し、単一の融合が生成されたことを確認できます。
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
融合 backend_config は、Triton がコード生成戦略として使用されることを示し、選択したタイリングを指定します。
結果のモジュールを可視化することもできます。
バッファの割り当てとスケジューリング
バッファ割り当てパスでは、形状情報が考慮され、プログラムの最適なバッファ割り当てを生成して、消費される中間メモリの量を最小限に抑えることを目指します。メモリ アロケータがグラフを事前に認識しない TF または PyTorch の即時モード(コンパイルなし)の実行とは異なり、XLA スケジューラは「未来を予測」して最適な計算スケジュールを生成できます。
コンパイラ バックエンド: コード生成とライブラリの選択
XLA は、計算内のすべての HLO 命令について、ランタイムにリンクされたライブラリを使用して実行するか、PTX にコード生成するかを選択します。
ライブラリの選択
多くの一般的なオペレーションでは、XLA:GPU は NVIDIA の高速パフォーマンス ライブラリ(cuBLAS、cuDNN、NCCL など)を使用します。ライブラリには高速なパフォーマンスが検証されているという利点がありますが、複雑なフュージョンを行う機会が失われることがよくあります。
直接コード生成
XLA:GPU バックエンドは、多くのオペレーション(削減、転置など)に対して高性能の LLVM IR を直接生成します。
Triton コード生成
行列乗算や softmax などのより高度なフュージョンでは、XLA:GPU はコード生成レイヤとして Triton を使用します。HLO フュージョンは TritonIR(Triton への入力として機能する MLIR 言語)に変換され、タイリング パラメータが選択され、PTX 生成のために Triton が呼び出されます。
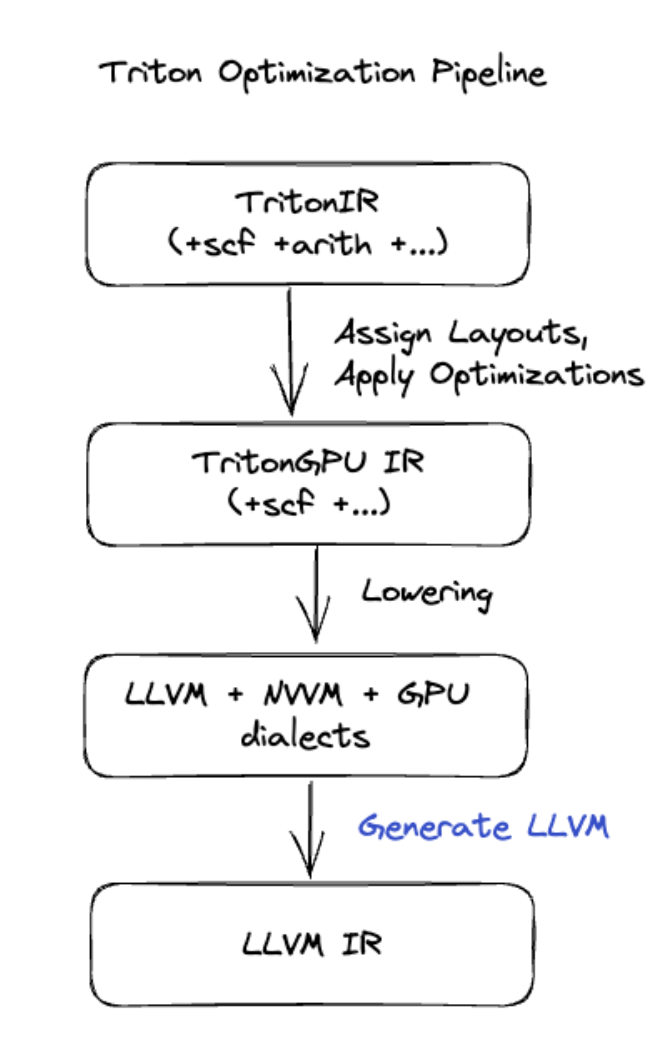
このコードは、Ampere で非常に優れたパフォーマンスを発揮することが確認されています。タイルサイズを適切に調整すると、ほぼルーフラインのパフォーマンスが得られます。
ランタイム
XLA ランタイムは、CUDA カーネル呼び出しとライブラリ呼び出しの結果のシーケンスを RuntimeIR(XLA の MLIR 言語)に変換し、その上で CUDA グラフ抽出が実行されます。CUDA グラフはまだ開発中であり、現在サポートされているのは一部のノードのみです。CUDA グラフの境界が抽出されると、RuntimeIR は LLVM を介して CPU 実行可能ファイルにコンパイルされ、事前コンパイル用に保存または転送できます。