
Giriş
XLA, doğrusal cebir için donanım ve çerçeve alanına özgü bir derleyicidir ve sınıfının en iyisi performansı sunar. JAX, TF, Pytorch ve diğerleri, kullanıcı girişini StableHLO'ya ("üst düzey işlem": toplama, çıkarma, matris çarpımı vb. gibi yaklaşık 100 statik şekilli talimattan oluşan bir işlem kümesi) dönüştürerek XLA'yı kullanır. XLA, bu işlem kümesinden çeşitli arka uçlar için optimize edilmiş kod üretir:
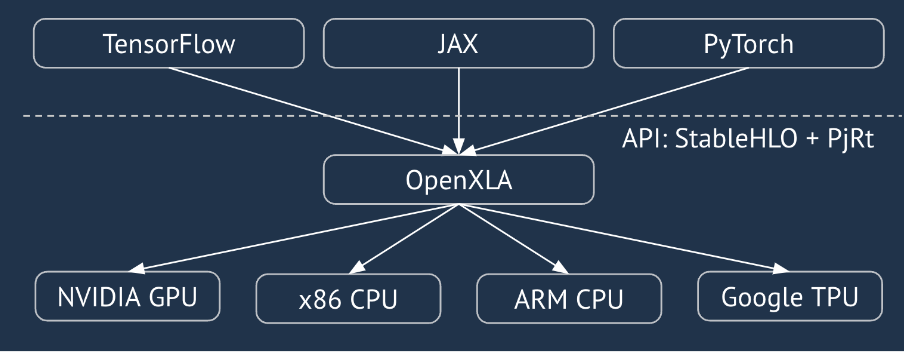
Çalışma sırasında çerçeveler, PJRT çalışma zamanı API'sini çağırır. Bu API, çerçevelerin "belirli bir cihazda belirli bir StableHLO programı kullanarak belirtilen arabellekleri doldurma" işlemini gerçekleştirmesine olanak tanır.
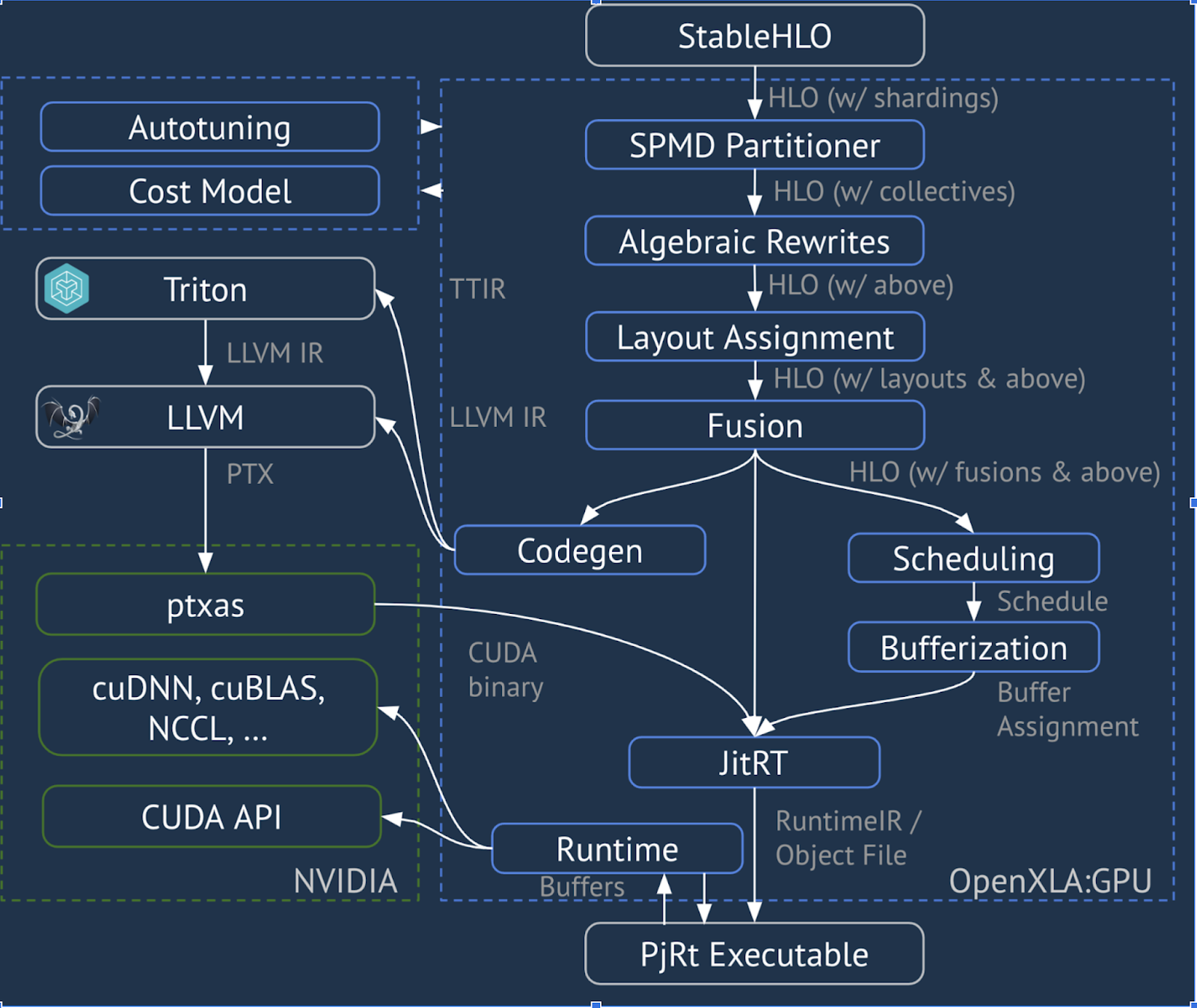
XLA:GPU Pipeline
XLA:GPU, yüksek performanslı GPU çekirdekleri oluşturmak için "yerel" (LLVM aracılığıyla PTX) yayıcılar ve TritonIR yayıcıların bir kombinasyonunu kullanır (mavi renk, 3. taraf bileşenlerini gösterir):
Çalıştırma örneği: JAX
İşlem hattını göstermek için JAX'te çalışan bir örnekle başlayalım. Bu örnek, sabit bir sayıyla çarpma ve olumsuzlama ile birlikte matmul hesaplar:
def f(a, b):
return -((a @ b) * 0.125)
İşlev tarafından oluşturulan HLO'yu inceleyebiliriz:
M = 1024
K = 512
N = 2048
key = jax.random.PRNGKey(1701)
a = jax.random.randint(key, (M, K), dtype=jax.numpy.int8, minval=0, maxval=255)
b = jax.random.normal(key, (K, N), dtype=jax.dtypes.bfloat16)
print(jax.xla_computation(f)(a, b).as_hlo_text())
Bu işlem sonucunda:
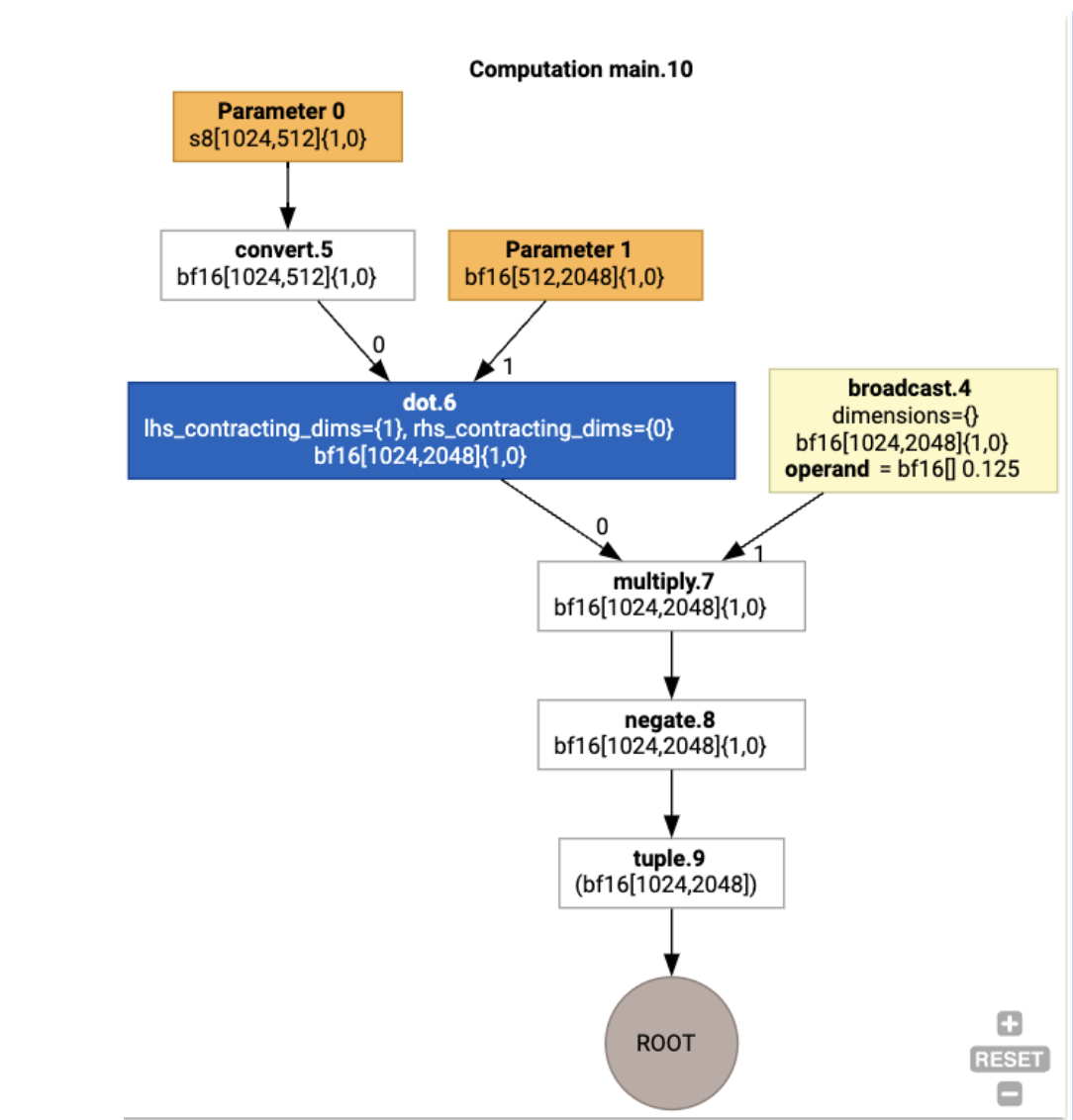
HloModule xla_computation_f, entry_computation_layout={(s8[1024,512]{1,0}, bf16[512,2048]{1,0})->(bf16[1024,2048]{1,0})}
ENTRY main.10 {
Arg_0.1 = s8[1024,512]{1,0} parameter(0)
convert.5 = bf16[1024,512]{1,0} convert(Arg_0.1)
Arg_1.2 = bf16[512,2048]{1,0} parameter(1)
dot.6 = bf16[1024,2048]{1,0} dot(convert.5, Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}
constant.3 = bf16[] constant(0.125)
broadcast.4 = bf16[1024,2048]{1,0} broadcast(constant.3), dimensions={}
multiply.7 = bf16[1024,2048]{1,0} multiply(dot.6, broadcast.4)
ROOT negate.8 = bf16[1024,2048]{1,0} negate(multiply.7)
}
Giriş HLO hesaplamasını da jax.xla_computation(f)(a, b).as_hlo_dot_graph() kullanarak görselleştirebiliriz:
HLO'da Optimizasyon: Temel Bileşenler
HLO'da HLO->HLO yeniden yazma işlemleri olarak bir dizi önemli optimizasyon geçişi gerçekleşir.
SPMD Partitioner
GSPMD: General and Scalable Parallelization for MLComputation Graphs başlıklı makalede açıklandığı gibi, XLA SPMD bölümleyici, parçalama ek açıklamaları içeren HLO'yu (ör. jax.pjit tarafından üretilen) kullanır ve ardından bir dizi ana makinede ve cihazda çalıştırılabilen parçalanmış bir HLO üretir.
SPMD, bölümleme dışında HLO'yu en iyi yürütme planı, çakışan hesaplama ve düğümler arasındaki iletişim için optimize etmeye çalışır.
Örnek
İki cihaz arasında parçalanmış basit bir JAX programıyla başlamayı deneyin:
# Defines a mesh with two axes called ‘x’ and ‘y’,
# sharded across two devices: first and second CPU.
with jax.sharding.Mesh(
[['cpu:0', 'cpu:1']], ('x', 'y')):
@pjit
def f(a, b):
out = -((a @ b) * 0.125)
# Shard output matrix access across ‘x’
# and ‘y’ respectively. Generates ‘Sharding’
# custom call.
out = with_sharding_constraint(
out, jax.lax.PartitionSpec('x', 'y'))
return out
# Random inputs to call our function.
a = jax.random.randint(key, (1024, 512), jnp.int8)
b = jax.random.normal(key, (512, 2048), jnp.float32)
print(f.lower(a, b).compiler_ir())
Görselleştirildiğinde parçalama ek açıklamaları özel çağrılar olarak gösterilir:
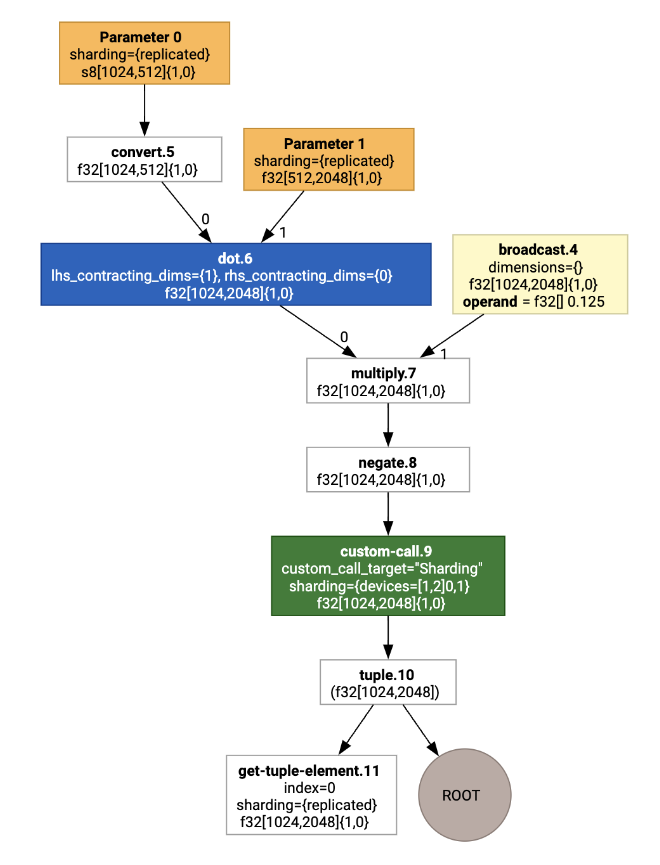
SPMD bölümleyicinin özel çağrıyı nasıl genişlettiğini kontrol etmek için optimizasyonlardan sonraki HLO'ya bakabiliriz:
print(f.lower(np.ones((8, 8)).compile().as_text())
Kolektif ile HLO oluşturan:
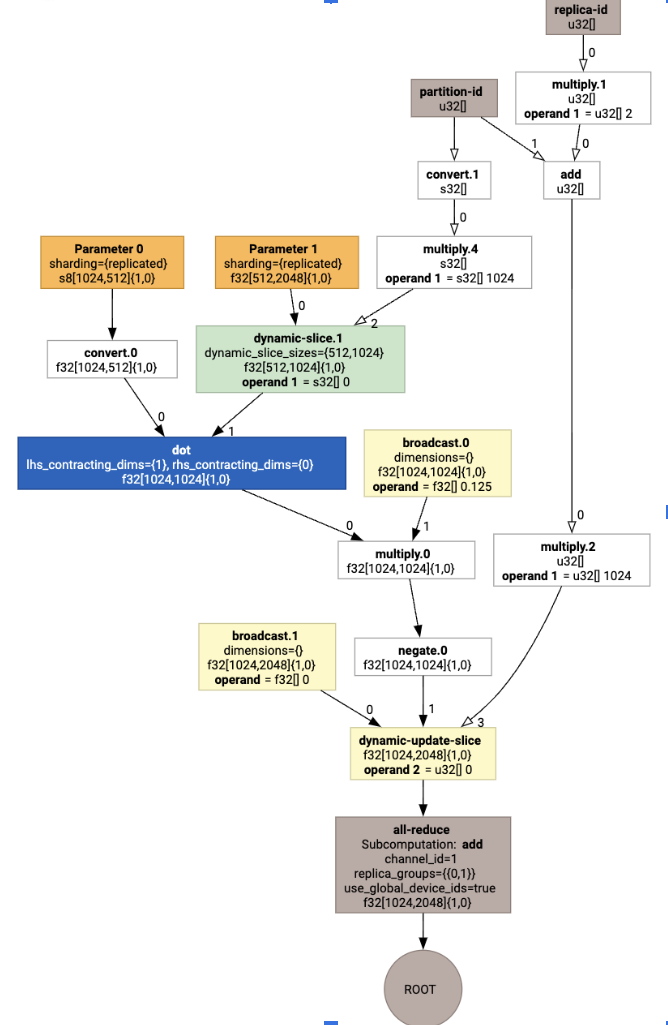
Düzen Ataması
HLO, mantıksal şekli ve fiziksel düzeni (tensörlerin bellekte nasıl düzenlendiği) birbirinden ayırır. Örneğin, bir matris f32[32, 64] satır öncelikli veya sütun öncelikli sırada gösterilebilir. Bu durumda sırasıyla {1,0} veya {0,1} olarak gösterilir.
Genel olarak düzen, şeklin bir parçası olarak gösterilir ve bellekteki fiziksel düzeni belirten boyut sayısının üzerinde bir permütasyon gösterir.
Düzen atama geçişi, HLO'da bulunan her işlem için optimum bir düzen seçer (ör. Ampere'de bir evrişim için NHWC). Örneğin, bir int8xint8->int32 matmul işlemi, hesaplamanın sağ tarafı için {0,1} düzenini tercih eder. Benzer şekilde, kullanıcı tarafından eklenen "transpoze"ler de yoksayılır ve yerleşim değişikliği olarak kodlanır.
Daha sonra düzenler grafik boyunca yayılır ve düzenler arasındaki veya grafik uç noktalarındaki çakışmalar, fiziksel transpozisyonu gerçekleştiren copy işlemleri olarak somutlaştırılır. Örneğin, grafikten başlayarak
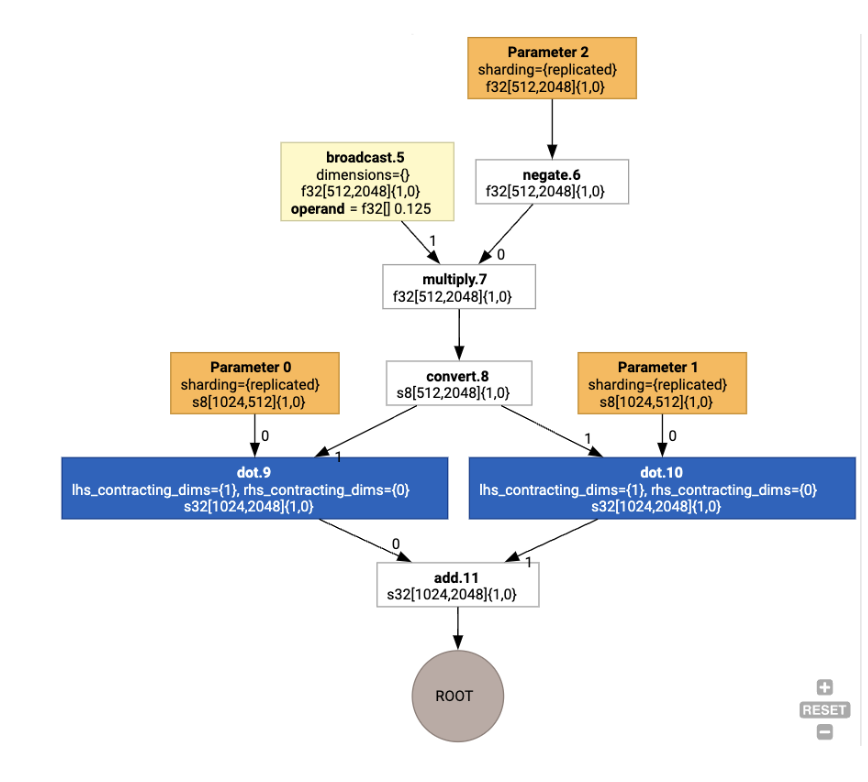
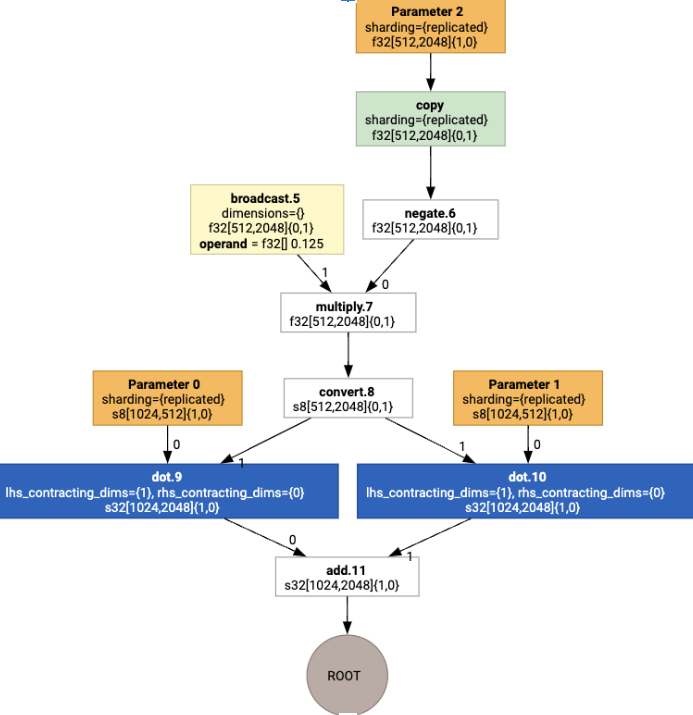
Düzen ataması çalıştırıldığında aşağıdaki düzenler ve copy işlemi eklenir:
Karma
Birleştirme, XLA'nın en önemli optimizasyonudur.Birden fazla işlemi (ör. toplama, üs alma, matris çarpımı) tek bir çekirdekte gruplandırır. Birçok GPU iş yükü belleğe bağlı olduğundan birleştirme, ara tensörlerin HBM'ye yazılmasını ve ardından geri okunmasını önleyerek yürütmeyi önemli ölçüde hızlandırır. Bunun yerine, tensörleri kayıtlar veya paylaşılan bellek içinde geçirir.
Birleştirilmiş HLO talimatları, aşağıdaki değişmezleri oluşturan tek bir birleştirme hesaplamasında birlikte engellenir:
Birleştirme içinde HBM'de gerçekleştirilen ara depolama yoktur (tüm veriler, kayıtlar veya paylaşılan bellek üzerinden aktarılmalıdır).
Bir füzyon her zaman tam olarak bir GPU çekirdeğine derlenir.
Çalışan örnek üzerinde HLO optimizasyonları
jax.jit(f).lower(a,
b).compile().as_text() kullanarak optimizasyon sonrası HLO'yu inceleyebilir ve tek bir birleştirme oluşturulduğunu doğrulayabiliriz:
HloModule jit_f, is_scheduled=true, entry_computation_layout={(s8[3,2]{1,0}, bf16[2,3]{1,0})->bf16[3,3]{1,0} }, allow_spmd_sharding_propagation_to_output={true}
%triton_gemm_dot.6_computation (parameter_0: s8[3,2], parameter_1: bf16[2,3]) -> bf16[3,3] {
%parameter_0 = s8[3,2]{1,0} parameter(0)
%convert.0 = bf16[3,2]{1,0} convert(s8[3,2]{1,0} %parameter_0)
%parameter_1 = bf16[2,3]{1,0} parameter(1)
%dot.0 = bf16[3,3]{1,0} dot(bf16[3,2]{1,0} %convert.0, bf16[2,3]{1,0} %parameter_1), lhs_contracting_dims={1}, rhs_contracting_dims={0}
%convert.1 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %dot.0)
%constant_0 = bf16[] constant(0.125)
%broadcast.0 = bf16[3,3]{1,0} broadcast(bf16[] %constant_0), dimensions={}
%convert.2 = f32[3,3]{1,0} convert(bf16[3,3]{1,0} %broadcast.0)
%multiply.0 = f32[3,3]{1,0} multiply(f32[3,3]{1,0} %convert.1, f32[3,3]{1,0} %convert.2)
%negate.0 = f32[3,3]{1,0} negate(f32[3,3]{1,0} %multiply.0)
ROOT %convert.6 = bf16[3,3]{1,0} convert(f32[3,3]{1,0} %negate.0)
}
ENTRY %main.9 (Arg_0.1: s8[3,2], Arg_1.2: bf16[2,3]) -> bf16[3,3] {
%Arg_1.2 = bf16[2,3]{1,0} parameter(1), sharding={replicated}
%Arg_0.1 = s8[3,2]{1,0} parameter(0), sharding={replicated}
ROOT %triton_gemm_dot.6 = bf16[3,3]{1,0} fusion(s8[3,2]{1,0} %Arg_0.1, bf16[2,3]{1,0} %Arg_1.2), kind=kCustom, calls=%triton_gemm_dot.6_computation, backend_config={"kind":"__triton_gemm","triton_gemm_config":{"block_m":"64","block_n":"64","block_k":"64","split_k":"1","num_stages":"2","num_warps":"4"} }
}
Birleştirme backend_config işaretinin, Triton'un kod oluşturma stratejisi olarak kullanılacağını ve seçilen döşemeyi belirttiğini unutmayın.
Elde edilen modülü de görselleştirebiliriz:
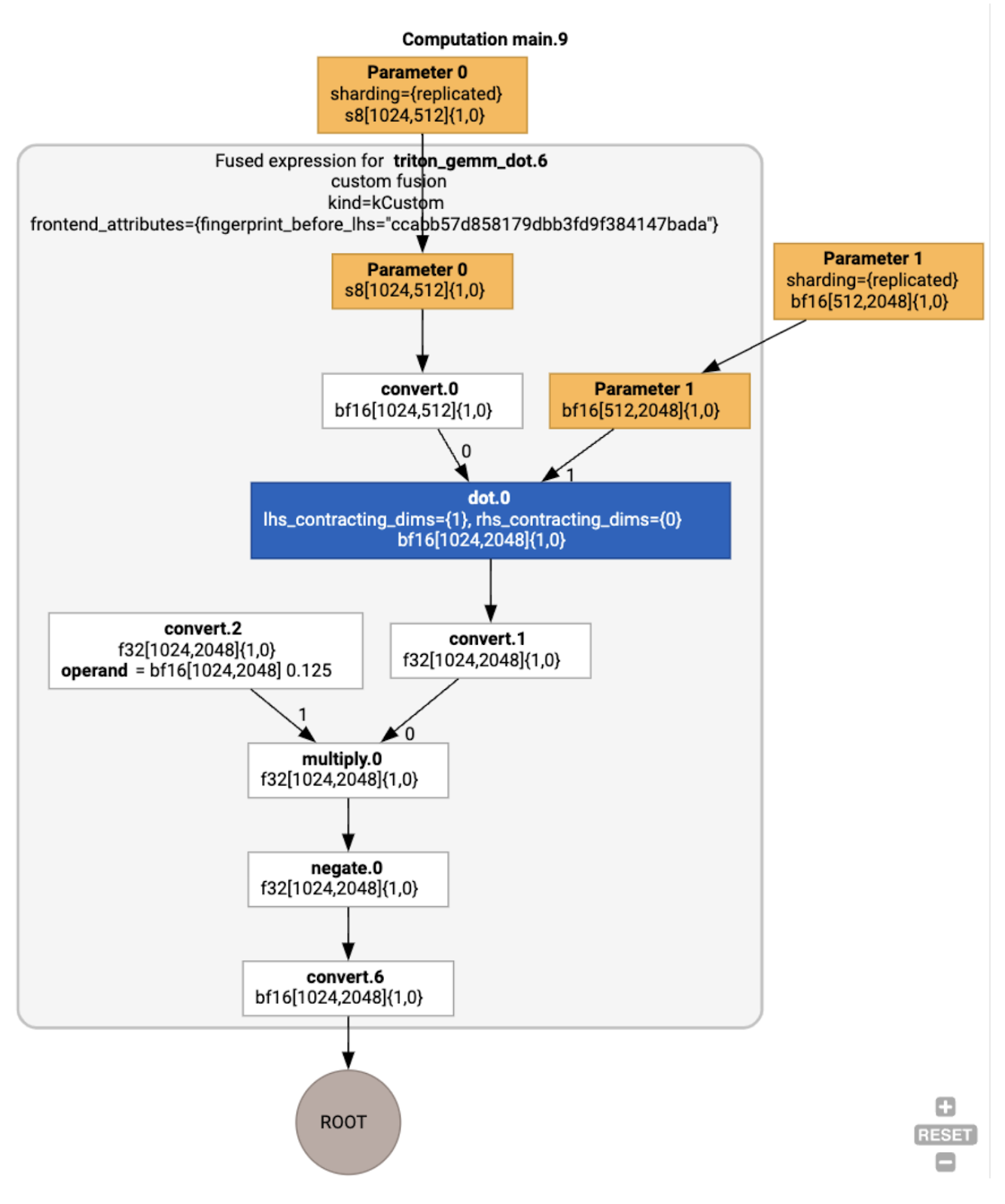
Tampon görev atama ve planlama
Bir arabellek atama geçişi, şekil bilgilerini dikkate alır ve program için en uygun arabellek ayırmayı amaçlayarak tüketilen ara bellek miktarını en aza indirir. Bellek ayırıcının grafiği önceden bilmediği TF veya PyTorch'un anlık mod (derlenmemiş) yürütülmesinin aksine, XLA zamanlayıcı "geleceğe bakabilir" ve optimum bir hesaplama planı oluşturabilir.
Derleyici Arka Ucu: Kod Oluşturma ve Kitaplık Seçimi
XLA, hesaplamadaki her HLO talimatı için bunu bir çalışma zamanına bağlı bir kitaplık kullanarak çalıştırmayı veya PTX'e kod oluşturmayı seçer.
Kitaplık Seçimi
XLA:GPU, birçok yaygın işlem için NVIDIA'nın yüksek performanslı kitaplıklarını (ör. cuBLAS, cuDNN ve NCCL) kullanır. Kitaplıklar, doğrulanmış hızlı performans avantajına sahiptir ancak genellikle karmaşık birleştirme fırsatlarını engeller.
Doğrudan kod oluşturma
XLA:GPU arka ucu, çeşitli işlemler (azaltmalar, transpozeler vb.) için doğrudan yüksek performanslı LLVM IR oluşturur.
Triton kod oluşturma
Matris çarpımı veya softmax içeren daha gelişmiş birleştirme işlemleri için XLA:GPU, kod oluşturma katmanı olarak Triton'u kullanır. HLO birleştirme işlemleri TritonIR'ye (Triton'a giriş olarak hizmet veren bir MLIR lehçesi) dönüştürülür, döşeme parametreleri seçilir ve PTX oluşturma için Triton çağrılır:
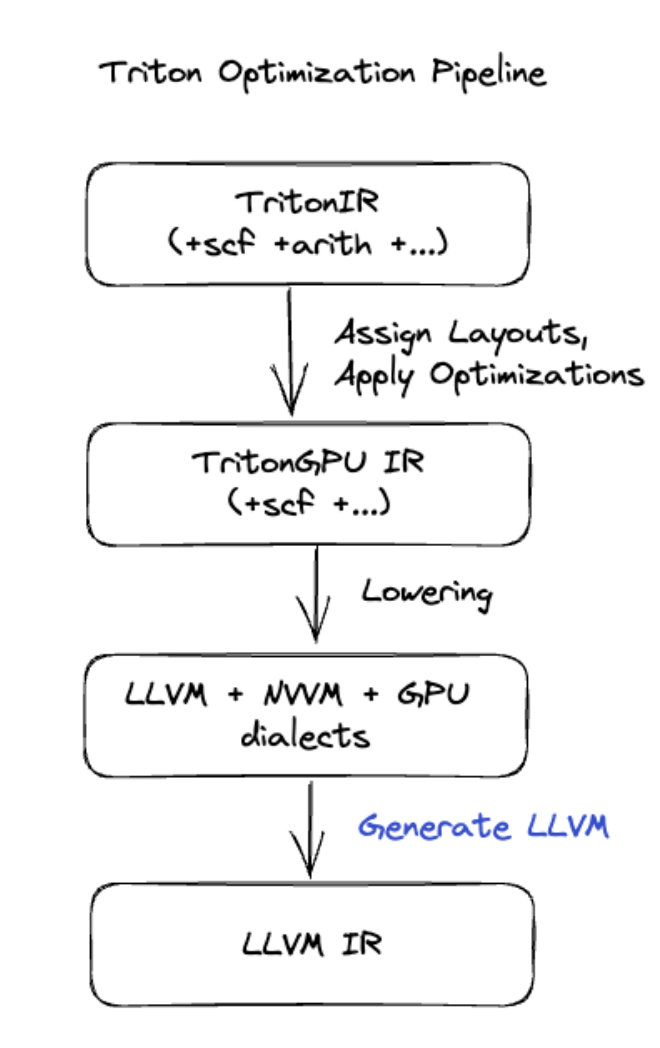
Elde edilen kodun, uygun şekilde ayarlanmış döşeme boyutlarıyla Ampere'de neredeyse en üst düzeyde performans gösterdiğini gözlemledik.
Çalışma zamanı
XLA çalışma zamanı, ortaya çıkan CUDA çekirdek çağrıları ve kitaplık çağırmaları dizisini, CUDA grafiği çıkarma işleminin gerçekleştirildiği bir RuntimeIR'ye (XLA'daki bir MLIR lehçesi) dönüştürür. CUDA grafiği üzerinde çalışmalar devam etmektedir. Şu anda yalnızca bazı düğümler desteklenmektedir. CUDA grafiği sınırları çıkarıldıktan sonra RuntimeIR, LLVM aracılığıyla CPU'da yürütülebilir bir dosya olarak derlenir. Bu dosya daha sonra saklanabilir veya Ahead-Of-Time derlemesi için aktarılabilir.