
Questa guida mostra come utilizzare gli strumenti disponibili con XProf per monitorare le prestazioni dei modelli TensorFlow sull'host (CPU), sul dispositivo (GPU) o su una combinazione di host e dispositivo/i.
La profilazione consente di comprendere il consumo di risorse hardware (tempo e memoria) delle varie operazioni TensorFlow (ops) nel modello e risolvere i colli di bottiglia delle prestazioni e, in definitiva, rendere l'esecuzione del modello più veloce.
Questa guida ti mostrerà come utilizzare i vari strumenti disponibili e le diverse modalità di raccolta dei dati sul rendimento di Profiler.
Se vuoi profilare le prestazioni del modello sulle Cloud TPU, consulta la guida di Cloud TPU.
Raccogliere i dati sul rendimento
XProf raccoglie le attività host e le tracce GPU del tuo modello TensorFlow. Puoi configurare XProf per raccogliere i dati sul rendimento tramite la modalità programmatica o la modalità di campionamento.
Profiling APIs
Puoi utilizzare le seguenti API per eseguire la profilazione.
Modalità programmatica utilizzando il callback TensorBoard Keras (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Modalità programmatica utilizzando l'API Function
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Modalità programmatica utilizzando il gestore del contesto
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Modalità di campionamento: esegui la profilazione on demand utilizzando
tf.profiler.experimental.server.startper avviare un server gRPC con l'esecuzione del modello TensorFlow. Dopo aver avviato il server gRPC ed eseguito il modello, puoi acquisire un profilo tramite il pulsante Acquisisci profilo in XProf. Utilizza lo script nella sezione Installa Profiler riportata sopra per avviare un'istanza di TensorBoard se non è già in esecuzione.Ad esempio,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Un esempio per la profilazione di più worker:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
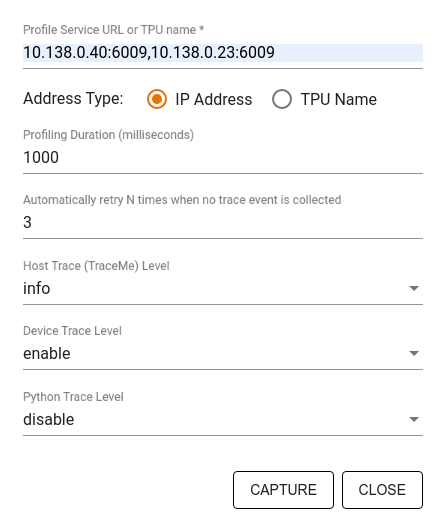
Utilizza la finestra di dialogo Acquisisci profilo per specificare:
- Un elenco delimitato da virgole di URL dei servizi del profilo o nomi TPU.
- Durata della profilazione.
- Il livello di tracciamento delle chiamate di funzioni di dispositivo, host e Python.
- Quante volte vuoi che Profiler tenti di acquisire i profili se non riesce al primo tentativo.
Profilazione dei loop di addestramento personalizzati
Per profilare i cicli di addestramento personalizzati nel codice TensorFlow, strumenta il ciclo di addestramento con l'API tf.profiler.experimental.Trace per contrassegnare i limiti dei passaggi per XProf.
L'argomento name viene utilizzato come prefisso per i nomi dei passaggi, l'argomento parola chiave step_num
viene aggiunto ai nomi dei passaggi e l'argomento parola chiave _r
fa sì che questo evento di traccia venga elaborato come evento di passaggio da XProf.
Ad esempio,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
In questo modo, verrà attivata l'analisi delle prestazioni basata sui passaggi di XProf e gli eventi di passaggio verranno visualizzati nel visualizzatore di tracce.
Assicurati di includere l'iteratore del set di dati nel contesto di tf.profiler.experimental.Trace per un'analisi accurata della pipeline di input.
Lo snippet di codice riportato di seguito è un anti-pattern:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Casi d'uso di profilazione
Il profiler copre una serie di casi d'uso lungo quattro assi diversi. Alcune combinazioni sono attualmente supportate, mentre altre verranno aggiunte in futuro. Ecco alcuni casi d'uso:
- Profilazione locale e remota: questi sono due modi comuni per configurare l'ambiente di profilazione. Nel profiling locale, l'API Profiling viene chiamata sulla stessa macchina in cui viene eseguito il modello, ad esempio una workstation locale con GPU. Nella profilazione remota, l'API Profiling viene chiamata su una macchina diversa da quella in cui viene eseguito il modello, ad esempio su una Cloud TPU.
- Profilazione di più worker: puoi profilare più macchine quando utilizzi le funzionalità di addestramento distribuito di TensorFlow.
- Piattaforma hardware: profila CPU, GPU e TPU.
La tabella seguente fornisce una rapida panoramica dei casi d'uso supportati da TensorFlow menzionati in precedenza:
| API Profiling | Locale | Telecomando | Più worker | Piattaforme hardware |
|---|---|---|---|---|
| TensorBoard Keras Callback | Supportato | Non supportato | Non supportato | CPU, GPU |
tf.profiler.experimental
start/stop API |
Supportato | Non supportato | Non supportato | CPU, GPU |
tf.profiler.experimental
client.trace API |
Supportato | Supportato | Supportato | CPU, GPU, TPU |
| API Context Manager | Supportato | Non supportato | Non supportato | CPU, GPU |
Risorse aggiuntive
- Il tutorial TensorFlow Profiler: Profile model performance con Keras e TensorBoard, in cui puoi applicare i suggerimenti di questa guida.
- La presentazione Performance profiling in TensorFlow 2 del TensorFlow Dev Summit 2020.
- La demo di TensorFlow Profiler del TensorFlow Dev Summit 2020.