
このガイドでは、XProf で使用可能なツールを使用して、ホスト(CPU)、デバイス(GPU)、またはホストとデバイスの組み合わせで TensorFlow モデルのパフォーマンスを追跡する方法について説明します。
プロファイリングは、モデル内のさまざまな TensorFlow オペレーション(ops)のハードウェア リソース消費量(時間とメモリ)を把握し、パフォーマンスのボトルネックを解消して、最終的にモデルの実行速度を高めるのに役立ちます。
このガイドでは、利用可能なさまざまなツールと、Profiler がパフォーマンス データを収集するさまざまなモードの使用方法について説明します。
Cloud TPU でモデルのパフォーマンスをプロファイリングする場合は、Cloud TPU ガイドをご覧ください。
パフォーマンス データの収集
XProf は、TensorFlow モデルのホスト アクティビティと GPU トレースを収集します。XProf は、プログラム モードまたはサンプリング モードのいずれかでパフォーマンス データを収集するように構成できます。
API のプロファイリング
次の API を使用してプロファイリングを行うことができます。
TensorBoard Keras コールバック(
tf.keras.callbacks.TensorBoard)を使用するプログラム モード# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])tf.profiler関数 API を使用するプログラム モードtf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()コンテキスト マネージャーを使用するプログラム モード
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
サンプリング モード:
tf.profiler.experimental.server.startを使用してオンデマンド プロファイリングを実行し、TensorFlow モデルの実行で gRPC サーバーを起動します。gRPC サーバーを起動してモデルを実行したら、XProf の [プロファイルをキャプチャ] ボタンを使用してプロファイルをキャプチャできます。TensorBoard インスタンスがまだ実行されていない場合は、上記の「プロファイラをインストールする」セクションのスクリプトを使用して起動します。たとえば、
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)複数のワーカーのプロファイリングの例:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
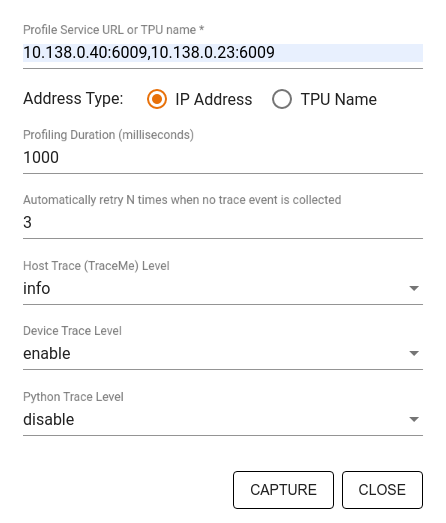
[キャプチャ プロファイル] ダイアログを使用して、次の項目を指定します。
- プロファイル サービス URL または TPU 名のカンマ区切りのリスト。
- プロファイリングの期間。
- デバイス、ホスト、Python 関数呼び出しのトレースのレベル。
- 最初に失敗した場合に、Profiler でプロファイルのキャプチャを再試行する回数。
カスタム トレーニング ループのプロファイリング
TensorFlow コードでカスタム トレーニング ループをプロファイリングするには、tf.profiler.experimental.Trace API を使用してトレーニング ループを計測し、XProf のステップ境界をマークします。
name 引数はステップ名の接頭辞として使用され、step_num キーワード引数はステップ名に追加されます。また、_r キーワード引数により、このトレース イベントは XProf によってステップ イベントとして処理されます。
たとえば、
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
これにより、XProf のステップベースのパフォーマンス分析が有効になり、ステップ イベントがトレース ビューアに表示されます。
入力パイプラインを正確に分析するには、データセット イテレータを tf.profiler.experimental.Trace コンテキストに含めます。
次のコード スニペットはアンチパターンです。
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
プロファイリングのユースケース
プロファイラは、4 つの異なる軸に沿ってさまざまなユースケースをカバーします。現在、一部の組み合わせがサポートされており、今後さらに追加される予定です。ユースケースには、次のようなものがあります。
- ローカル プロファイリングとリモート プロファイリング: プロファイリング環境を設定する一般的な方法が 2 つあります。ローカル プロファイリングでは、モデルが実行されている同じマシン(GPU を搭載したローカル ワークステーションなど)でプロファイリング API が呼び出されます。リモート プロファイリングでは、モデルが実行されているマシン(Cloud TPU など)とは別のマシンでプロファイリング API が呼び出されます。
- 複数のワーカーのプロファイリング: TensorFlow の分散トレーニング機能を使用する場合は、複数のマシンをプロファイリングできます。
- ハードウェア プラットフォーム: CPU、GPU、TPU のプロファイリングを行います。
次の表に、上記の TensorFlow でサポートされているユースケースの概要を示します。
| Profiling API | ローカル | リモート | 複数のワーカー | ハードウェア プラットフォーム |
|---|---|---|---|---|
| TensorBoard Keras コールバック | サポート対象 | サポート対象外 | サポート対象外 | CPU、GPU |
tf.profiler.experimental
API の開始/停止 |
サポート対象 | サポート対象外 | サポート対象外 | CPU、GPU |
tf.profiler.experimental
client.trace API |
サポート対象 | サポート対象 | サポート対象 | CPU、GPU、TPU |
| コンテキスト マネージャー API | サポート対象 | サポート対象外 | サポート対象外 | CPU、GPU |
参考情報
- このガイドのアドバイスを適用できる Keras と TensorBoard を使用した TensorFlow Profiler: モデルのパフォーマンスのプロファイルを作成するチュートリアル。
- TensorFlow Dev Summit 2020 の講演「TensorFlow 2 でのパフォーマンス プロファイリング」
- TensorFlow Dev Summit 2020 の TensorFlow Profiler のデモ。