
The long term goal is to make Shardy a completely standalone component, able to work with any MLIR dialect. Currently, Shardy directly depends on StableHLO, but we are making progress towards lifting that through various abstractions and interfaces to make Shardy more flexible.
Sharding Rules
A sharding rule encodes how we propagate through an operation. Since Shardy
now depends on StableHLO, it defines sharding rules for each stablehlo op. In
addition, Shardy provides the
ShardingRuleOpInterface
which can be used by dialect owners in their operations to define sharding rules
for their own operations. As long as an operation implements this interface,
Shardy will be able to propagate through it.
def ShardingRuleOpInterface : OpInterface<"ShardingRuleOpInterface"> {
let methods = [
InterfaceMethod<
/*desc=*/[{
Returns the sharding rule of the op.
}],
/*retType=*/"mlir::sdy::OpShardingRuleAttr",
/*methodName=*/"getShardingRule"
>,
];
}
Data flow ops
Some ops, e.g., region-based ops, require a different approach where sharding
rules, which only describe the correspondence between dimensions across all
operands and results, are not enough. In these cases, Shardy defines a
ShardableDataFlowOpInterface
so that dialect owners can describe the propagation of sharding through their
ops. This interface provides methods to get the sources and targets of each data
flow edge through their owner, and also get and set the shardings of edge
owners.
def ShardableDataFlowOpInterface :
OpInterface<"ShardableDataFlowOpInterface"> {
(get|set)BlockArgumentEdgeOwnerShardings;
(get|set)OpResultEdgeOwnerShardings;
getBlockArgumentEdgeOwners;
getOpResultEdgeOwners;
getEdgeSources;
// ...
}
See also Data flow ops for a high-level overview of how we handle data flow ops.
Interfaces not yet implemented
In the future, more interfaces and traits will be added to make Shardy more flexible and dialect-agnostic. We list them below.
Constant splitting
Most tensor programs in MLIR have one instance of a constant that is reused by whatever op that needs that value. This makes sense when the constant needed is the same. However, for optimal sharding of a program, we would like to allow each use of a constant to have its own sharding, and not be affected by how other ops use that constant.
For example in the figure below, if the add is sharded, it should not affect
how the divide and subtract (in different parts of the computation) are
sharded.
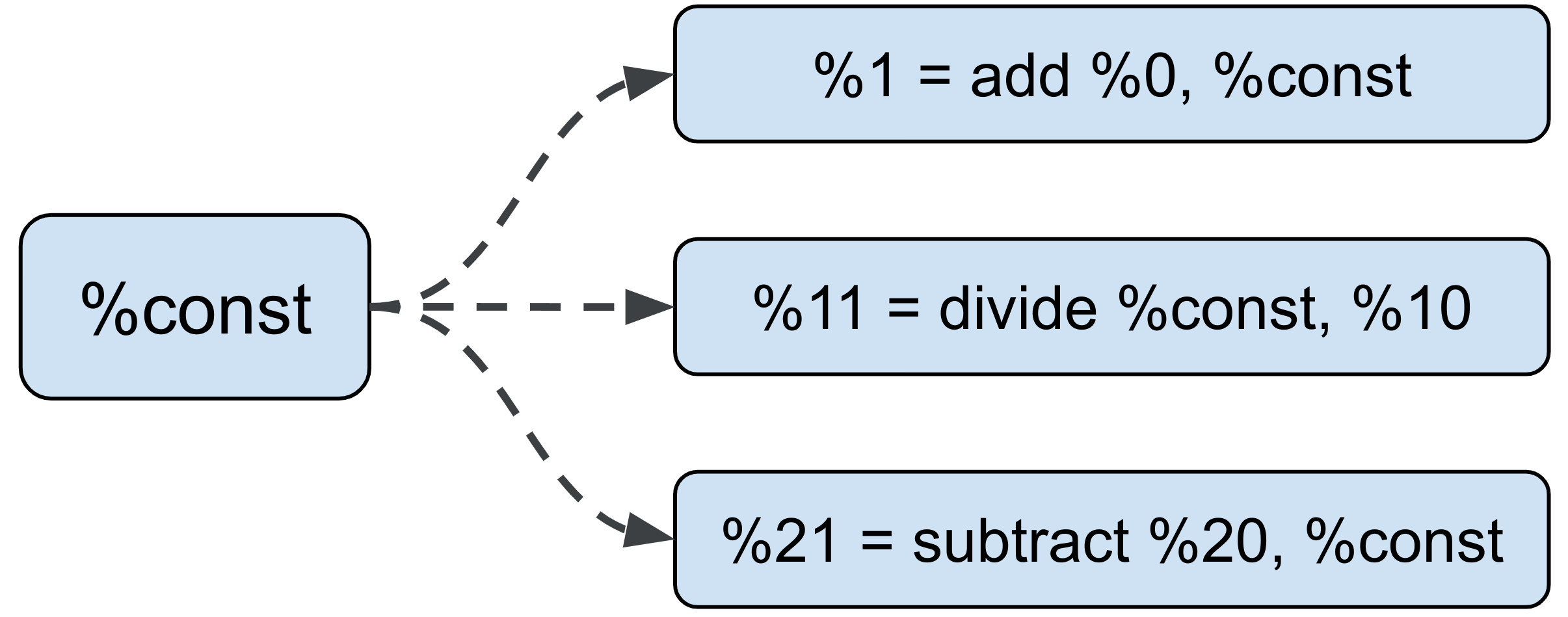
We call this a false dependency: because constants are cheap, there isn't a real dependency between ops that use the same constant. As such, users can decide on the sharding of their constant (and constant-like) ops. Each use of that constant can then have a different sharding that can propagate in isolation to its own copy of the constant sub-computation.
To achieve this, Shardy users need to define: - A your_dialect.constant ->
sdy.constant pass; - A sdy::ConstantLike trait, such as
iota; - A mlir::Elementwise trait
for element-wise ops like add and
multiply; - A
sdy::ConstantFoldable for ops like
slice/broadcast.
These ops can technically be calculated at compile time, if all their
operands/results are constants.
Op priorities
In GSPMD, element-wise ops are propagated first, followed by ops like matmul.
In Shardy, we want to allow users to set their own op priorities since we don't
know about their dialects a priori. As such, we will ask them to pass a list
of ops in the order they want Shardy to propagate them in.
The figure below shows how the priorities are used in GSPMD to propagate ops in the right order.
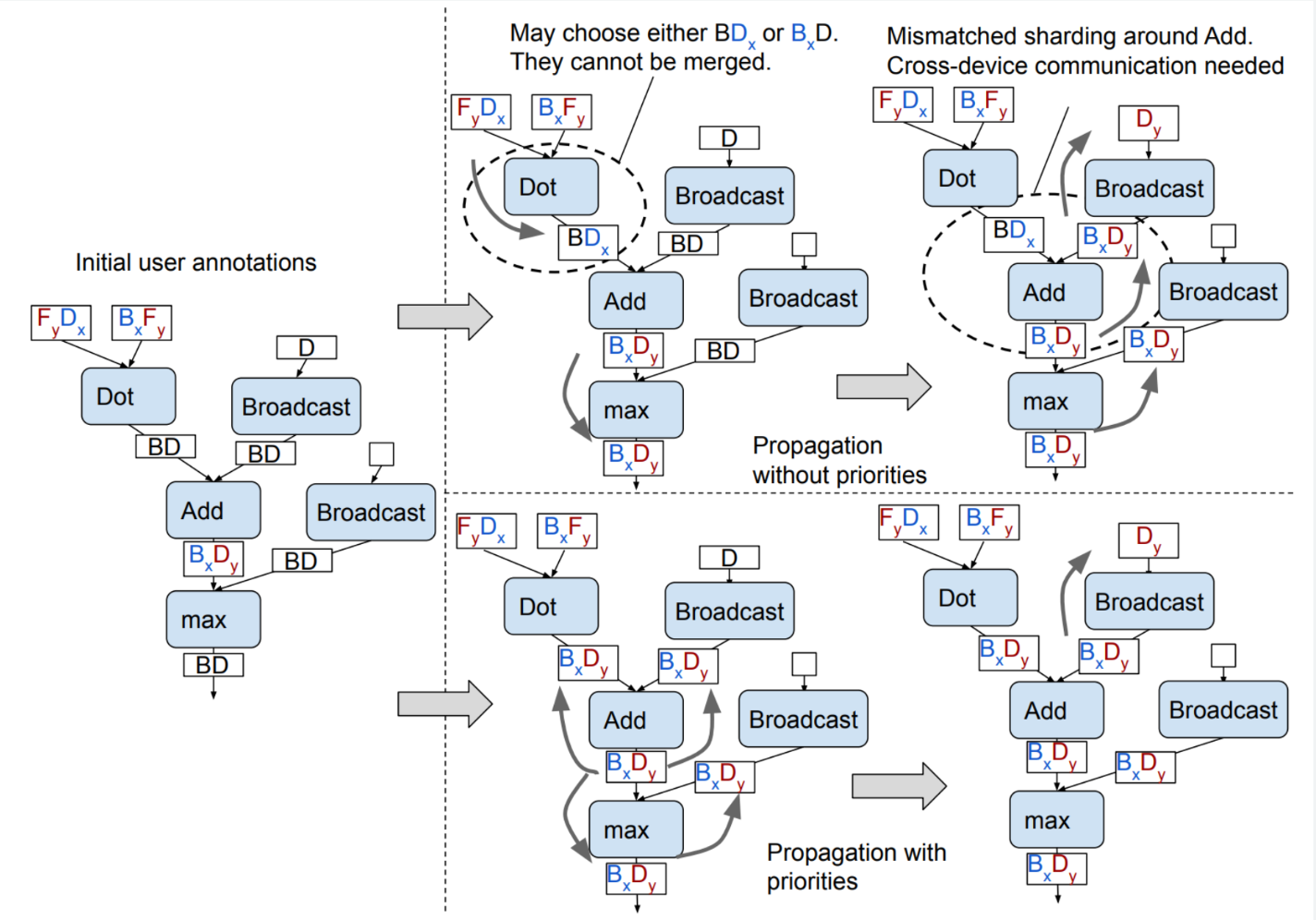
See the GSPMD paper for a discussion on why op priorities are important.
Being dialect-agnostic
As long as you implement the previous interfaces, traits, and pass, Shardy will be able to work for your dialect. We are working on making Shardy more flexible and dialect-agnostic, so stay tuned for more updates.