
Visão geral
A propagação de fragmentação usa as fragmentações especificadas pelo usuário para inferir as fragmentações não especificadas de tensores (ou dimensão específica de tensores). Ele percorre o fluxo de dados (cadeias de uso-def) do gráfico de computação em ambas as direções até que um ponto fixo seja alcançado. Ou seja, o particionamento não pode mais mudar sem desfazer as decisões anteriores.
A propagação pode ser dividida em etapas. Cada etapa envolve analisar uma operação específica e propagar entre os tensores (operandos e resultados), com base nas características dessa operação. Usando uma matmul como exemplo, propagaríamos entre a dimensão não contraída de lhs ou rhs para a dimensão correspondente do resultado ou entre a dimensão contraída de lhs e rhs.
As características de uma operação determinam a conexão entre as dimensões correspondentes nas entradas e saídas e podem ser abstratas como uma regra de fragmentação por operação.
Sem a resolução de conflitos, uma etapa de propagação simplesmente propagaria o máximo possível, ignorando os eixos em conflito. Chamamos isso de eixos de divisão principais (mais longos) compatíveis.
Design detalhado
Hierarquia de resolução de conflitos
Criamos várias estratégias de resolução de conflitos em uma hierarquia:
- Prioridades definidas pelo usuário. Em
Representação de divisão, descrevemos como
as prioridades podem ser anexadas a divisões de dimensão para permitir a partição
incremental do programa, por exemplo, fazendo paralelismo de lote -> megatron ->
divisão ZERO. Isso é feito aplicando a propagação em iterações. Na iteração
i, propagamos todos os shardings de dimensão que têm prioridade<=ie ignoramos todos os outros. Também garantimos que a propagação não vai substituir fragmentações definidas pelo usuário com prioridade mais baixa (>i), mesmo que sejam ignoradas durante iterações anteriores. - Prioridades baseadas em operações. Nós propagamos os shardings com base no tipo de operação. As operações de "transmissão" (por exemplo, operações por elemento e remodelagem) têm a maior prioridade, enquanto as operações com transformação de forma (por exemplo, ponto e redução) têm prioridade menor.
- Propagação agressiva. Propague os shardings com uma estratégia agressiva. A estratégia básica só propaga partições sem conflitos, enquanto a estratégia agressiva resolve conflitos. Uma maior agressividade pode reduzir o consumo de memória em detrimento da comunicação potencial.
- Propagação básica. É a estratégia de propagação mais baixa na hierarquia, que não faz nenhuma resolução de conflito e, em vez disso, propaga eixos compatíveis entre todos os operandos e resultados.

Essa hierarquia pode ser interpretada como loops aninhados. Por exemplo, para cada prioridade do usuário, uma propagação completa de prioridade de operação é aplicada.
Regra de fragmentação de operações
A regra de fragmentação introduz uma abstração de cada operação que fornece ao algoritmo de propagação real as informações necessárias para propagar fragmentações de operandos para resultados ou entre operandos sem precisar raciocinar sobre tipos de operação específicos e os atributos deles. Isso é basicamente separar a lógica específica da operação e fornecer uma representação compartilhada (estrutura de dados) para todas as operações apenas para fins de propagação. Na forma mais simples, ele fornece apenas esta função:
GetOpShardingRule(Operation *) -> OpShardingRuleAttr
A regra permite que o algoritmo de propagação seja escrito apenas uma vez de maneira genérica,
com base nesta estrutura de dados (OpShardingRule), em vez de replicar
partes semelhantes do código em muitas operações, reduzindo muito a possibilidade de bugs
ou comportamento inconsistente em várias operações.
Vamos voltar ao exemplo de matmul.
Uma codificação que encapsula as informações necessárias durante a propagação, ou seja, as relações entre as dimensões, pode ser gravada na forma de notação einsum:
(i, k), (k, j) -> (i, j)
Nessa codificação, cada dimensão é mapeada para um único fator.
Como a propagação usa esse mapeamento:se uma dimensão de um operando/resultado for fragmentada em um eixo, a propagação vai procurar o fator dessa dimensão nesse mapeamento e fragmentar outros operandos/resultados na respectiva dimensão com o mesmo fator. Além disso, (sujeito à discussão anterior sobre a replicação) também pode replicar outros operandos/resultados que não têm esse fator ao longo desse eixo.
Fatores compostos: estender a regra para reformulações
Em muitas operações, como matmul, só precisamos mapear cada dimensão para um único fator. No entanto, isso não é suficiente para remodelar.
A reformulação a seguir mescla duas dimensões em uma:
%out = stablehlo.reshape(%in) : (tensor<2x4x32xf32>) -> tensor<8x32xf32>
Aqui, as dimensões 0 e 1 da entrada correspondem à dimensão 0 da saída. Digamos que começamos fornecendo fatores para a entrada:
(i,j,k) : i=2, j=4, k=32
Se quisermos usar os mesmos fatores para a saída, vamos precisar de uma única dimensão para fazer referência a vários fatores:
(i,j,k) -> ((ij), k) : i=2, j=4, k=32
O mesmo pode ser feito se a remodelagem dividir uma dimensão:
%out = stablehlo.reshape(%in) : (tensor<8x32xf32>) -> tensor<2x4x32xf32>
Aqui,
((ij), k) -> (i,j,k) : i=2, j=4, k=32
A dimensão de tamanho 8 aqui é composta essencialmente dos fatores 2 e 4,
por isso chamamos os fatores de (i,j,k).
Esses fatores também podem funcionar em casos em que não há uma dimensão completa que corresponde a um dos fatores:
%out = stablehlo.reshape(%in) : (tensor<8x4xf32>) -> tensor<2x16xf32>
// ((ij), k) -> (i,(jk)) : i=2, j=4, k=4
Esse exemplo também enfatiza por que precisamos armazenar os tamanhos de fator, já que não podemos deduzir facilmente as dimensões correspondentes.
Algoritmo de propagação principal
Propague as partições ao longo de fatores
No Shardy, temos a hierarquia de tensores, dimensões e fatores. Eles
representam dados em níveis diferentes. Um fator é uma subdimensão. É uma
hierarquia interna usada na propagação de fragmentação. Cada dimensão pode corresponder
a um ou mais fatores. O mapeamento entre dimensão e fator é definido por
OpShardingRule.

O Shardy propaga eixos de fragmentação ao longo de fatores em vez de dimensões. Para fazer isso, temos três etapas, conforme mostrado na figura abaixo:
- Projeto
DimShardingparaFactorSharding - Propague eixos de fragmentação no espaço de
FactorSharding - Projete o
FactorShardingatualizado para receber oDimShardingatualizado
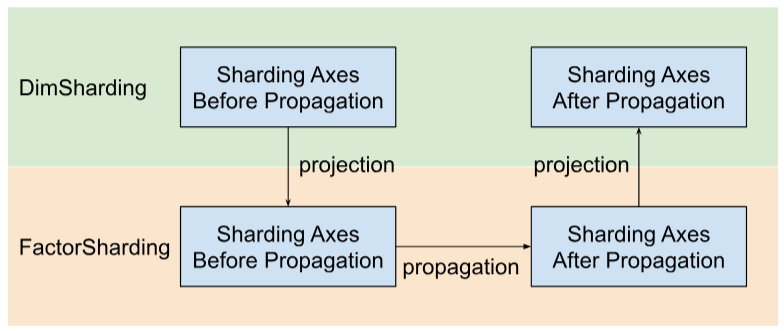
Visualização da propagação de fragmentação ao longo dos fatores
Usaremos a tabela a seguir para visualizar o problema e o algoritmo de propagação de fragmentação.
| F0 | F1 | F2 | Eixos replicados explicitamente | |
|---|---|---|---|---|
| T0 | ||||
| T1 | ||||
| T2 |
- Cada coluna representa um fator. F0 significa o fator com índice 0. Nós propagamos particionamentos ao longo de fatores (colunas).
- Cada linha representa um tensor. T0 se refere ao tensor com índice 0. Os tensores são todos os operandos e resultados envolvidos em uma operação específica. Os eixos em uma linha não podem se sobrepor. Um eixo (ou subeixo) não pode ser usado para particionar um tensor várias vezes. Se um eixo for replicado explicitamente, não será possível usá-lo para particionar o tensor.
Assim, cada célula representa um fator de fragmentação. Um fator pode estar ausente em tensores
parciais. Confira a tabela de C = dot(A, B) abaixo. As células que contêm um N
implicam que o fator não está no tensor. Por exemplo, F2 está em T1 e T2, mas
não em T0.
C = dot(A, B) |
F0 Diminuição de lote | F1: escurecimento sem contração | Dimensão F2 não contraída | F3: escurecimento da contração | Eixos replicados explicitamente |
|---|---|---|---|---|---|
| T0 = A | N | ||||
| T1 = B | N | ||||
| T2 = C | N |
Coletar e propagar eixos de fragmentação
Usamos um exemplo simples mostrado abaixo para visualizar a propagação.
| F0 | F1 | F2 | Eixos replicados explicitamente | |
|---|---|---|---|---|
| T0 | "a" | "f" | ||
| T1 | "a", "b" | "c", "d" | "g" | |
| T2 | "c", "e" |
Etapa 1: Encontre eixos para propagar em cada fator (também conhecidos como os eixos de fragmentação principais (mais longos) compatíveis). Neste exemplo, propagamos ["a", "b"]
ao longo de F0, propagamos ["c"] ao longo de F1 e não propagamos nada ao longo de F2.
Etapa 2: Expanda os shardings de fator para obter o resultado abaixo.
| F0 | F1 | F2 | Eixos replicados explicitamente | |
|---|---|---|---|---|
| T0 | "a", "b" | "c" | "f" | |
| T1 | "a", "b" | "c", "d" | "g" | |
| T2 | "a", "b" | "c", "e" |
Operações de fluxo de dados
A descrição da etapa de propagação acima se aplica à maioria das operações. No entanto, há casos em que uma regra de fragmentação não é adequada. Nesses casos, o Shardy define operações de fluxo de dados.
Uma borda de fluxo de dados de alguma operação X define uma ponte entre um conjunto de origens e um conjunto de destinos, de modo que todas as origens e destinos sejam particionados da mesma forma. Exemplos de operações desse tipo são stablehlo::OptimizationBarrierOp,
stablehlo::WhileOp, stablehlo::CaseOp e
sdy::ManualComputationOp.
Em última análise, qualquer operação que implemente
ShardableDataFlowOpInterface
é considerada uma operação de fluxo de dados.
Uma operação pode ter várias arestas de fluxo de dados ortogonais entre si. Por exemplo:
y_0, ..., y_n = while (x_0, ..., x_n)
((pred_arg_0,... , pred_arg_n) { ... })
((body_arg_0,..., body_arg_n) {
...
return return_value_0, ..., return_value_n
})
Essa operação "while" tem bordas de fluxo de dados n: as bordas de fluxo de dados i estão entre
as origens x_i, return_value_i e os destinos y_i, pred_arg_i, body_arg_i.
O Shardy vai propagar particionamentos entre todas as origens e destinos de uma borda de fluxo de dados como se fosse uma operação regular com as origens como operandos e os destinos como resultados e uma identidade sdy.op_sharding_rule. Isso significa que a propagação
para frente é de origens para destinos, e a propagação para trás é de destinos
para origens.
Vários métodos precisam ser implementados pelo usuário para descrever como acessar as fontes e os destinos de cada borda do fluxo de dados pelo proprietário e também como extrair e definir os particionamentos dos proprietários de borda. Um proprietário é um destino especificado pelo usuário da borda do fluxo de dados usado pela propagação do Shardy. O usuário pode escolher arbitrariamente, mas ele precisa ser estático.
Por exemplo, considerando o custom_op definido abaixo:
y_1, ..., y_n = custom_op (x_1, ..., x_n)
((body_arg_1,..., body_arg_n) {
...
return return_value_1, ..., return_value_n
})
Esse custom_op tem dois tipos de arestas de fluxo de dados: n entre
return_value_i (origens) e y_i (destinos) e n entre x_i
(origens) e body_arg_i (destinos). Nesse caso, os proprietários de borda são os mesmos
que os destinos.