
רקע
מטרת הייצוג של חלוקה למקטעים היא לציין איך מתבצעת חלוקת המטריצה למקטעים ביחס לקבוצה של מכשירים זמינים.
הייצוג של חלוקת המטא-נתונים יכול להיות:
- המשתמש מציין אותם באופן ידני כאילוצים של חלוקה לפלחים על קלט, פלט או נתונים ביניים.
- הטרנספורמציה מתבצעת לכל פעולה בתהליך ההפצה של חלוקת המחיצות.
סקירה כללית
המבנה הבסיסי
רשת לוגית היא תצוגה רב-ממדית של מכשירים, שמוגדרת לפי רשימה של שמות גדלים של צירים.
הייצוג המוצע של חלוקת המשנה קשור לרשת לוגית ספציפית לפי השם שלה, והוא יכול להפנות רק לשמות של צירים מהרשת הזו. חלוקת הטנסור לחלקים קובעת לאורך אילו צירים (של רשת לוגית ספציפית) כל מאפיין של הטנסור מחולק, בסדר מגדול לקטן. הטנזור משכפל לאורך כל הצירים האחרים של הרשת.
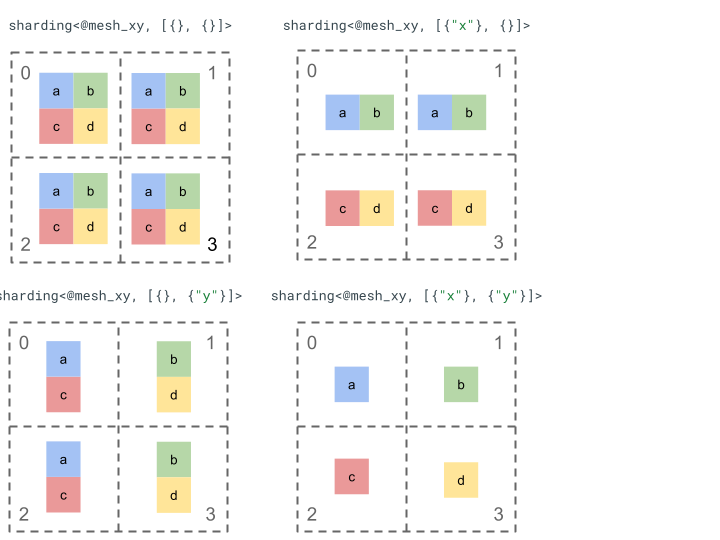
נבחן את הייצוג של חלוקה לקטעים באמצעות טינסור פשוט של דרגה 2 ו-4 מכשירים.
קודם משנים את הצורה של 4 המכשירים [0, 1, 2, 3] למערך דו-מימדי [[0, 1], [2,
3]] כדי ליצור רשת עם 2 צירים:
@mesh_xy = <["x"=2, "y"=2]>
לאחר מכן אפשר לפצל את הטנסור [[a, b], [c, d]] של דרגה 2 באופן הבא:
רכיבים מרכזיים אחרים
- מאפיינים פתוחים/סגורים – המאפיינים יכולים להיות פתוחים – אפשר לפצל אותם לעוד קטעים בצירים זמינים, או סגורים – הם קבועים ואי אפשר לשנות אותם.
- צירים שמתבצעת בהם רפליקה באופן מפורש – כל הצירים שלא משמשים לחלוקה של מאפיין עוברים רפליקה באופן משתמע, אבל אפשר לציין בצירוף לחלוקה צירים שמתבצעת בהם רפליקה באופן מפורש, ולכן לא ניתן להשתמש בהם לחלוקה של מאפיין בשלב מאוחר יותר.
- פיצול צירים וצירים משניים – אפשר לפצל ציר רשת (מלא) למספר צירים משניים, שאפשר להשתמש בהם בנפרד כדי לפצל מאפיין או ליצור רפליקה באופן מפורש.
- רשתות רשתות לוגיות מרובות – אפשר לשייך חלוקות שונות לרשתות רשתות לוגיות שונות, שיכולות להיות להן צירים שונים או אפילו סדר שונה של מזהי מכשירים לוגיים.
- עדיפויות – כדי לפצל תוכנית באופן מצטבר, אפשר לצרף עדיפויות לחלוקות של מאפיינים. העדיפויות קובעות את הסדר שבו אילוצים של חלוקה לפי מאפיין יועברו לאורך המודול.
- חלוקה של מאפיינים לקטעים (shards) לפי חלוקה – אפשר לפצל מאפיין לפי צירים שמכפלת הגדלים שלהם לא מחלקת את גודל המאפיין.
תכנון מפורט
בקטע הזה נסביר על המבנה הבסיסי ועל כל אחד מהרכיבים המרכזיים.
המבנה הבסיסי
חלוקות המאפיינים מאפשרות לנו לדעת לאורך אילו צירים (או צירי משנה) מתבצעת חלוקה של כל מאפיין בטרנספורמר, מהציר הראשי לציר המשני. כל שאר הצירים שלא מחלקים מאפיין לקטעים עוברים שכפול מרומז (או שכפול מפורש).
נתחיל בדוגמה פשוטה ונרחיב אותה ככל שנמשיך לתאר תכונות נוספות.
@mesh_xy = <["x"=2, "y"=4, "z"=2]>
// The 1st tensor dimension is sharded along axis "x" and the 2nd tensor dimension is
// sharded along axis "z" then further along axis "y". The local shape of this tensor (i.e. the shape on a single device), would be tensor<2x1xf32>.
sharding<@mesh_xy, [{"x"}, {"z", "y"}]> : tensor<4x8xf32>
Invariants
- מספר החלוקות של המאפיינים חייב להתאים לדרג (rank) של הטנזור.
- כל שמות הצירים חייבים להופיע ברשת שמופיעה בהפניה.
- צירים או צירי משנה יכולים להופיע פעם אחת בלבד בייצוג של חלוקת המשנה (כל אחד מהם מחלק מאפיין או מבוצע לו רפליקה באופן מפורש).
מאפיינים פתוחים/סגורים
כל מאפיין של טינסור יכול להיות פתוח או סגור.
פתיחה
מאפיין פתוח זמין להפצה כדי לפצל אותו ליותר צירים, כלומר פיצול המאפיין שצוין לא חייב להיות הפיצול הסופי של המאפיין הזה. הערך הזה דומה (אבל לא זהה) לערך של unspecified_dims ב-GSPMD.
אם מאפיין פתוח, מוסיפים ? אחרי הצירים שבהם המאפיין כבר מפוצל (ראו דוגמה בהמשך).
סגור
מאפיין סגור הוא מאפיין שלא זמין להפצה כדי להוסיף לו חלוקה לפלחים נוספת. כלומר, חלוקת המאפיין שצוינה היא חלוקת המאפיין הסופית, ולא ניתן לשנות אותה. תרחיש שימוש נפוץ לכך הוא האופן שבו GSPMD (בדרך כלל) לא משנה את ארגומנטים הקלט/הפלט של מודול, או האופן שבו ב-jax.jit, הערכים של in_shardings שצוינו על ידי המשתמש הם סטטיים – אי אפשר לשנות אותם.
אפשר להרחיב את הדוגמה שלמעלה כך שתכלול מאפיין פתוח ומאפיין סגור.
@mesh_xy = <["x"=2, "y"=4, "z"=2]>
// The 1st dimension is closed, therefore it can't be further sharded and {"x"}
// will remain its sharding. The 2nd dimension is open, and can therefore be
// further sharded during propagation, e.g. by "y".
sharding<@mesh_xy, [{"x"}, {"z", ?}]> : tensor<4x8xf32>
צירים שמתבצעת להם רפליקה באופן מפורש
קבוצה מפורשת של צירים שבהם מתבצע שכפול של טינסור. אפשר לקבוע שמתבצעת רפליקה משתמעת של טינסור שלא פוצל לפי ציר (כמו jax.sharding.PartitionSpec היום), אבל אם מציינים זאת במפורש, אפשר לוודא שההעברה לא תשתמש בצירים האלה כדי לפצל עוד יותר מאפיין פתוח עם הצירים האלה. באמצעות שכפול משתמע, אפשר לפצל טרנספורמציה לטנסור. אבל עם שכפול מפורש, אי אפשר לחלק את הטנזור לאורך הציר הזה.
הסדר של צירים ששכפלתם לא משפיע על אופן האחסון של הנתונים של הטנזור. עם זאת, מטעמי עקביות בלבד, הצירים יישמרו בסדר שבו הם צוינו ברשת ברמה העליונה. לדוגמה, אם הרשת היא:
@mesh_xy = <["c"=2, "a"=2, "b"=2]>
ואנחנו רוצים שהצירים "a" ו-"c" ישוחזרו באופן מפורש, הסדר צריך להיות:
replicated={"c", "a"}
אפשר להרחיב את הדוגמה שלמעלה כך שתכלול ציר שמתבצעת לו רפליקה באופן מפורש.
@mesh_xyz = <["x"=2, "y"=4, "z"=2]>
// Since "y" is explicitly replicated, it can't be used to shard the 2nd
// dimension that is open. However, "z" is implicitly replicated so it can be
// used to shard that dimension. The local shape of this tensor (i.e. the
// shape on a single device), would be tensor<2x8xf32>.
sharding<@mesh_xyz, [{"x"}, {?}], replicated={"y"}> : tensor<4x8xf32>
פיצול צירים וצירים משניים
כדי ליצור רשת לוגית של n צירים, מעצבים מחדש מערך של מכשירי 1-ממד למערך של n-ממדים, שבו כל מאפיין יוצר ציר עם שם שהוגדר על ידי המשתמש.
אפשר לבצע את אותו תהליך במהדר כדי לפצל ציר בגודל k ל-m צירי משנה, על ידי שינוי צורת הרשת מ-[...,k,...] ל-[...,k1,...,km,...].
למה בחרנו לעשות זאת?
כדי להבין את המניע מאחורי פיצול צירים, נבחן את הדוגמה הבאה:
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 : (tensor<8xf32>) -> tensor<2x4xf32>
אנחנו רוצים לפצל את התוצאה של יצירת המבנה מחדש באופן שיימנע צורך בתקשורת (כלומר, לשמור את הנתונים במקום שבו הם נמצאים). מכיוון שהגודל של "x" גדול מהמאפיין הראשון של התוצאה, צריך לפצל את הציר לשני צירי משנה, "x.0" ו-"x.1", בגודל 2 כל אחד, ולחלק את המאפיין הראשון ב-"x.0" ואת המאפיין השני ב-"x.1".
חלוקה לפלחים של קלט/פלט של פונקציות
יכול להיות שבמהלך ההעברה, קלט או פלט של הפונקציה הראשית יתחלקו לפי ציר משנה. זה יכול להיות בעיה במסגרות מסוימות, שבהן אי אפשר להביע חלוקות כאלה כדי להחזיר אותן למשתמש (לדוגמה, ב-JAX אי אפשר להביע צירים משניים באמצעות jax.sharding.NamedSharding).
יש לנו כמה אפשרויות לטיפול במקרים כאלה:
- לאפשר את הפילוח ולהחזיר אותו בפורמט אחר (למשל
jax.sharding.PositionalShardingבמקוםjax.sharding.NamedShardingב-JAX). - אסור להשתמש ב-Disallow ובצירי משנה מסוג all-gather שמחלקים את הקלט/הפלט.
בשלב הזה אנחנו מאפשרים צירים משניים בנתוני הקלט/הפלט בצינור עיבוד הנתונים להפצה. נשמח לדעת אם אתם רוצים לדעת איך להשבית את התכונה הזו.
ייצוג
בדומה לאופן שבו אפשר להפנות לצירים מלאים ספציפיים מהעיגול לפי השם שלהם, אפשר להפנות לצירי משנה ספציפיים לפי הגודל שלהם והמכפלה של כל הגדלים של צירי המשנה (באותו שם ציר) שמשמאל אליהם (שחשובים להם).
כדי לחלץ ציר משנה ספציפי בגודל k מציר מלא "x" בגודל n, אנחנו משנים את הצורה של n (במערך) ל-[m, k, n/(m*k)] ומשתמשים במאפיין השני כציר המשנה. כך אפשר לציין ציר משנה באמצעות שני מספרים, m ו-k, ואנחנו משתמשים בסימון המצומצם הבא כדי לציין צירים משנה: "x":(m)k.
m>=1הוא הגודל המקדים של ציר המשנה הזה (mצריך להיות מחלק שלn). הגודל המקדים הוא המכפלה של כל גדלי צירי המשנה שמשמאל לציר המשנה הזה (אם הוא שווה ל-1, סימן שאין אף אחד. אם הוא גדול מ-1, הוא תואם לציר משנה יחיד או לכמה צירי משנה).הערך של
k>1הוא הגודל בפועל של ציר המשנה הזה (kצריך להיות מחלק שלn).n/(m*k)הוא post-size. הוא המכפלה של כל גדלי צירי המשנה שמימין לציר המשנה הזה (אם הוא שווה ל-1, סימן שאין צירי משנה. אם הוא גדול מ-1, הוא מתאים לציר משנה יחיד או לכמה צירי משנה).
עם זאת, מספר הצירים המשניים האחרים לא משנה כשמשתמשים בציר משני ספציפי "x":(m)k, ואין צורך להפנות לציר משני אחר בחלוקה של הטנזור אם הוא לא מחלק מאפיין או שהוא משכפל באופן מפורש.
נחזור לדוגמה בקטע הסיבה. אפשר לפצל את התוצאה כך:
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 {sdy.sharding_per_value=<[<@mesh_x, [{"x":(1)2}, {"x":(2)2}]>]>}
: (tensor<8xf32>) -> tensor<2x4xf32>
הנה דוגמה נוספת לציר מפוצל שבו נעשה שימוש רק בחלק מצירי המשנה שלו.
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Axis "y" is effectively split into 3 sub-axes denoted as
// "y":(1)2, "y":(2)2, "y":(4)2
// in order, but only "y":(2)2 is used, to shard the 2nd dimension. The local
// shape of this tensor (i.e. the shape on a single device), would be
// tensor<2x4xf32>.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}]> : tensor<4x8xf32>
באופן דומה, שתי החלקות המשנה הבאות זהות מבחינה סמנטית. אפשר לחשוב על mesh_xy כפיצול של mesh_full.
@mesh_full = <"devices"=8>
@mesh_xy = <"x"=4, "y"=2>
sharding<@mesh_xy, [{"x"},{ "y"}]> : tensor<4x4xf32>
sharding<@mesh_full, [{"devices":(1)4}, {"devices":(4)2}]> : tensor<4x4xf32>
צירים משניים שמתבצעת להם רפליקה באופן מפורש
בנוסף לשימוש בציריות משנה כדי לפצל מאפיינים, אפשר גם לסמן אותן ככאלה שצריך להעתיק אותן באופן מפורש. אנחנו מאפשרים זאת בייצוג כי צירי משנה מתנהגים בדיוק כמו צירים מלאים. כלומר, כשמחלקים מאפיין לפי ציר משנה של ציר "x", צירי המשנה האחרים של "x" עוברים שכפול מרומז, ולכן אפשר לשכפל אותם באופן מפורש כדי לציין שציר משנה חייב להישאר כפול ולא ניתן להשתמש בו כדי לפצל מאפיין.
לדוגמה:
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Sub-axis "y":(1)2 is explicitly replicated and "y":(4)2 is implicitly replicated.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}], replicated={"y":(1)2}> : tensor<4x8xf32>
יש למיין צירים משניים משכפלים של אותו ציר מלא בסדר עולה לפי הגודל שלהם מראש, לדוגמה:
replicated={"y":(4)2, "x", "y":(1)2} ~> replicated={"x", "y":(1)2, "y":(4)2}
Invariants
צירי משנה שמפנים לחלוקה של טינסור לא יכולים לחפוף, למשל
"x":(1)4ו-"x":(2)4חופפים.צירי המשנה שמצוינים בחלוקה של הטנזור חייבים להיות גדולים ככל האפשר. כלומר, אם בחלוקה של המאפיינים יש שני צירי משנה סמוכים A ו-B בסדר, או אם צירי המשנה A ו-B מועתקים באופן מפורש, הם לא יכולים להיות רצופים, למשל
"x":(1)2ו-"x":(2)4, כי אפשר להחליף אותם ב-"x":(1)8יחיד.
כמה רשתות לוגיות
רשת לוגית אחת היא תצוגה רב-ממדית של מכשירים. יכול להיות שנצטרך כמה תצוגות של המכשירים כדי לייצג את החלוקה לפלחים, במיוחד במקרים של הקצאות שרירותיות של מכשירים.
לדוגמה, jax.sharding.PositionalSharding לא כולל רשת לוגית משותפת אחת.
בשלב זה, GSPMD תומך בכך באמצעות HloSharding, שבו הייצוג יכול להיות רשימה מסודרת של מכשירים וגדלים של מאפיינים, אבל אי אפשר לייצג אותו באמצעות חלוקת הצירים שמתוארת למעלה.
כדי להתגבר על המגבלה הזו ולטפל במקרים קיצוניים קיימים, אנחנו מגדירים כמה רשתות לוגיות ברמה העליונה של התוכנית. לכל רשת יכול להיות מספר שונה של צירים עם שמות שונים, וגם הקצאה שרירותית משלה לאותה קבוצה של מכשירים. כלומר, כל רשת מתייחסת לאותה קבוצה של מכשירים (לפי המזהה הלוגי הייחודי שלהם) אבל בסדר שרירותי, בדומה לייצוג של GSMPD.
כל ייצוג של חלוקה לקטעים מקושר לרשת לוגית ספציפית, ולכן הוא יפנה רק לצירים מהרשת הזו.
אפשר להשתמש בטנסור שהוקצה לרשת לוגית אחת בפעולה שהוקצתה לרשת אחרת, על ידי חלוקה מחדש של הטנסור כך שיתאים לרשת היעד. ב-GSPMD, זהו הפתרון הנפוץ לבעיות של רשתות רשתות מתנגשות.
משתמשים יכולים לציין כמה רשתות עם צירים שונים בשמות שונים (למשל באמצעות jax.sharding.NamedSharding), שיש להם את אותו סדר של מכשירים. בדוגמה הבאה, <@mesh_0, "b"> זהה ל-<@mesh_1, "z">:
@mesh_0 = {<["a"=4, "b"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
@mesh_1 = {<["x"=2, "y"=2, "z"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
עדיפויות
העדיפות מאפשרת לתת עדיפות להחלטות מסוימות לגבי חלוקה ושידור על פני החלטות אחרות, ומאפשרת חלוקה מצטברת של תוכנית.
העדיפויות הן ערכים שמצורפים לחלק מהמאפיינים או לכל המאפיינים של ייצוג חלוקה (לאקסים ששכפלו אין עדיפות).
לדוגמה:
@mesh_xy = <["w"=6, "x"=2, "y"=4, "z"=2]>
// |-> y is implicitly p0
%arg4 : sharding<@mesh_xy, [{"x"}p1, {"y"}, {"z",?}p2], replicated={} }>
העדיפויות נותנות למשתמשים שליטה מפורטת יותר על ההעברה, למשל, קודם ביצוע פעולות במקביל באצווה, אחר כך megatron ולבסוף חלוקה לפלחים של ZeRO. כך אפשר להבטיח בצורה טובה יותר מה מחולק למחיצות, ולאפשר ניפוי באגים טוב יותר באמצעות שיטות פירוט מפורט יותר של חלוקה למחיצות (אפשר לראות איך התוכנית נראית אחרי שמבודדים רק את megatron).
אנחנו מאפשרים לצרף עדיפות לכל חלוקה של מאפיין (0 כברירת מחדל). המשמעות היא שכל החלוקות עם העדיפות <i יועברו לכל התוכנית לפני החלוקות עם העדיפות i.
גם אם לחלוקה לפלחים יש מאפיין פתוח עם עדיפות נמוכה יותר, למשל: {"z",?}p2, הוא לא ישתנה על ידי חלוקה אחרת של טינסור עם עדיפות גבוהה יותר במהלך ההעברה. עם זאת, אפשר לפצל עוד מאפיין פתוח כזה אחרי שכל הפיצולים בעדיפות גבוהה יותר מופצים.
במילים אחרות, העדיפויות NOT קובעות איזה חלוקה למקטעים של מאפיינים חשובה יותר מאחרת – הן קובעות את הסדר שבו קבוצות נפרדות של חלוקות למקטעים של מאפיינים צריכות להופיע בתוכנית כולה, ואת האופן שבו צריך לפתור קונפליקטים בטנסורים ביניים ללא הערות.
Invariants
רמות העדיפות מתחילות ב-0 (העדיפות הגבוהה ביותר) וממשיכות לגדול (כדי לאפשר למשתמשים להוסיף ולהסיר עדיפות בקלות, אנחנו מאפשרים פערים בין רמות העדיפות. לדוגמה, נעשה שימוש ב-p0 וב-p2 אבל לא ב-p1).
חלוקה למקטעים של מאפיין סגור ריק (כלומר,
{}), אין להגדיר עדיפות, כי לא תהיה לה השפעה.
חלוקה של מאפיינים לפלחים – חלוקה לחלקים
אפשר לפצל מאפיין בגודל d לפי צירים שמכפלת הגדלים שלהם היא n, כך ש-d לא מתחלק ב-n (במקרה כזה, בפועל יהיה צורך להוסיף למאפיין עוד נתונים).
לדוגמה:
@mesh_xy = <["x"=8, "y"=2, "z"=3]>
sharding<@mesh_xy, [{"x"}, {"y"}, {"z"}]> : tensor<7x3x8xf32>
דקדוק
כל רשת לוגית מוגדרת באופן הבא:
@mesh_name = <mesh_axis_1,...,mesh_axis_n>
mesh_axis ::= axis_name=axis_size
axis_name ::= str
axis_size ::= int
לייצוג של חלוקה לפלחים יהיה המבנה הבא עבור טינסור של דרגה r:
sharding<@mesh_name, dim_shardings, replicated=replicated_axes}
mesh_name ::= str
dim_shardings ::= [dim_sharding_1,...,dim_sharding_r]
replicated_axes ::= {axis_1,...,axis_m}
dim_sharding ::=
{axis_1,...,axis_k} | // closed dimension
{axis_1,...,axis_k,?} // open dimension
axis ::=
axis_name | // a full axis
sub_axis // a sub axis
axis_name ::= str
sub_axis ::= axis_name:(pre_size)size
pre_size ::= int
size ::= int