
배경
샤딩 표현의 목적은 사용 가능한 기기 집합을 기준으로 텐서가 샤딩되는 방식을 지정하는 것입니다.
샤딩 표현은 다음 중 하나일 수 있습니다.
- 사용자가 입력, 출력 또는 중간 값에 대한 샤딩 제약 조건으로 수동으로 지정합니다.
- 샤딩 전파 과정에서 작업별로 변환됩니다.
개요
기본 구조
논리 메시는 축 이름 및 크기 목록으로 정의되는 기기의 다차원 뷰입니다.
제안된 샤딩 표현은 이름으로 특정 논리적 메시에 바인딩되며 해당 메시의 축 이름만 참조할 수 있습니다. 텐서의 샤딩은 특정 논리 메시의 어떤 축을 따라 텐서의 각 차원이 샤딩되는지 지정하며, 주요 축에서 부차적인 축으로 순서가 지정됩니다. 텐서는 메시의 다른 모든 축을 따라 복제됩니다.
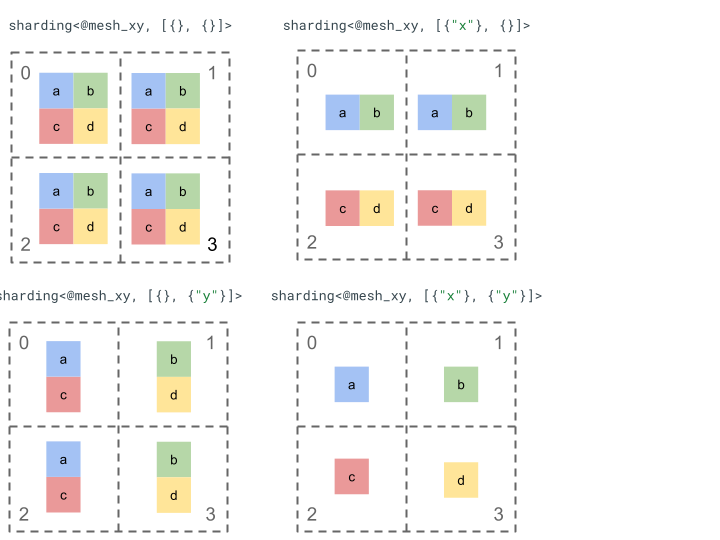
간단한 2차원 텐서와 4개의 기기로 샤딩 표현을 살펴보겠습니다.
먼저 4개의 기기 [0, 1, 2, 3]를 2차원 배열 [[0, 1], [2,
3]]로 변형하여 2축 메시를 만듭니다.
@mesh_xy = <["x"=2, "y"=2]>
그런 다음 다음과 같이 2차원 텐서 [[a, b], [c, d]]를 샤딩할 수 있습니다.
기타 주요 구성요소
- 개방형/폐쇄형 측정기준 - 측정기준은 개방형(사용 가능한 축에서 추가로 샤딩 가능)이거나 폐쇄형(고정되어 변경 불가)일 수 있습니다.
- 명시적으로 복제된 축 - 측정기준을 샤딩하는 데 사용되지 않는 모든 축은 암시적으로 복제되지만 샤딩은 명시적으로 복제된 축을 지정할 수 있으므로 나중에 측정기준을 샤딩하는 데 사용할 수 없습니다.
- 축 분할 및 하위 축 - (전체) 메시 축은 측정기준을 샤딩하거나 명시적으로 복제하는 데 개별적으로 사용할 수 있는 여러 하위 축으로 분할할 수 있습니다.
- 여러 개의 논리 메시 - 여러 개의 샤딩을 여러 개의 논리 메시에 바인드할 수 있으며, 이러한 논리 메시는 축이 다르거나 논리 기기 ID의 순서가 다를 수 있습니다.
- 우선순위 - 프로그램을 점진적으로 분할하려면 측정기준 샤딩에 우선순위를 연결할 수 있습니다. 그러면 측정기준별 샤딩 제약조건이 모듈 전체에 전파되는 순서가 결정됩니다.
- 측정기준 샤딩 분할 가능성 - 크기의 곱셈 결과가 측정기준 크기를 나누지 않는 축에서 측정기준을 샤딩할 수 있습니다.
세부 설계
이 섹션에서는 기본 구조와 각 주요 구성요소를 확장합니다.
기본 구조
차원 샤딩은 텐서의 각 차원에 대해 주요 축에서 보조 축으로 샤딩되는 축 (또는 하위 축)을 알려줍니다. 측정기준을 샤딩하지 않는 다른 모든 축은 암시적으로 복제됩니다 (또는 명시적으로 복제됨).
간단한 예시로 시작하여 추가 기능을 설명하면서 확장해 보겠습니다.
@mesh_xy = <["x"=2, "y"=4, "z"=2]>
// The 1st tensor dimension is sharded along axis "x" and the 2nd tensor dimension is
// sharded along axis "z" then further along axis "y". The local shape of this tensor (i.e. the shape on a single device), would be tensor<2x1xf32>.
sharding<@mesh_xy, [{"x"}, {"z", "y"}]> : tensor<4x8xf32>
불변항
- 차원 샤딩 수는 텐서 등급과 일치해야 합니다.
- 모든 축 이름은 참조된 메시에 있어야 합니다.
- 축 또는 하위 축은 샤딩 표현에서 한 번만 나타날 수 있습니다 (각 축은 측정기준을 샤딩하거나 명시적으로 복제됨).
개방형/폐쇄형 측정기준
텐서의 각 측정기준은 개방형 또는 폐쇄형일 수 있습니다.
열기
열린 측정기준은 추가 축을 따라 추가로 샤딩할 수 있도록 전파할 수 있습니다. 즉, 지정된 측정기준 샤딩이 해당 측정기준의 최종 샤딩일 필요는 없습니다. 이는 GSPMD의 unspecified_dims와 유사하지만 정확히 일치하지는 않습니다.
측정기준이 열려 있으면 측정기준이 이미 샤딩된 축 뒤에 ?를 추가합니다 (아래 예 참고).
종료됨
종료된 측정기준은 더 이상 샤딩을 추가할 수 없도록 전파할 수 없는 측정기준입니다. 즉, 지정된 측정기준 샤딩이 해당 측정기준의 최종 샤딩이며 변경할 수 없습니다. 일반적인 사용 사례는 GSPMD가 일반적으로 모듈의 입력/출력 인수를 수정하지 않는 방식이나 jax.jit의 경우 사용자가 지정한 in_shardings가 정적이며 변경할 수 없는 방식입니다.
위의 예를 확장하여 개방형 측정기준과 폐쇄형 측정기준을 만들 수 있습니다.
@mesh_xy = <["x"=2, "y"=4, "z"=2]>
// The 1st dimension is closed, therefore it can't be further sharded and {"x"}
// will remain its sharding. The 2nd dimension is open, and can therefore be
// further sharded during propagation, e.g. by "y".
sharding<@mesh_xy, [{"x"}, {"z", ?}]> : tensor<4x8xf32>
명시적으로 복제된 축
텐서가 복제되는 명시적인 축 집합입니다. 축에서 샤딩되지 않은 텐서가 축에 암시적으로 복제된다고 판단할 수 있지만(현재 jax.sharding.PartitionSpec와 같이) 명시적으로 지정하면 전파가 이러한 축을 사용하여 이러한 축으로 열린 측정기준을 더 샤딩할 수 없습니다. 암시적 복제를 사용하면 텐서를 더 세분화할 수 있습니다. 하지만 명시적 복제를 사용하면 아무것도 해당 축을 따라 텐서를 분할할 수 없습니다.
복제된 축의 순서는 텐서 데이터가 저장되는 방식에 영향을 미치지 않습니다. 그러나 일관성을 위해 축은 최상위 메시에 지정된 순서대로 저장됩니다. 예를 들어 메시가 다음과 같은 경우
@mesh_xy = <["c"=2, "a"=2, "b"=2]>
축 "a" 및 "c"를 명시적으로 복제하려면 순서가 다음과 같아야 합니다.
replicated={"c", "a"}
위의 예를 확장하여 명시적으로 복제된 축을 가질 수 있습니다.
@mesh_xyz = <["x"=2, "y"=4, "z"=2]>
// Since "y" is explicitly replicated, it can't be used to shard the 2nd
// dimension that is open. However, "z" is implicitly replicated so it can be
// used to shard that dimension. The local shape of this tensor (i.e. the
// shape on a single device), would be tensor<2x8xf32>.
sharding<@mesh_xyz, [{"x"}, {?}], replicated={"y"}> : tensor<4x8xf32>
축 분할 및 하위 축
n 축의 논리적 메시는 기기의 1차원 배열을 n차원 배열로 재형성하여 생성됩니다. 여기서 각 차원은 사용자 정의 이름으로 축을 형성합니다.
컴파일러에서도 동일한 프로세스를 실행하여 메시지를 [...,k,...]에서 [...,k1,...,km,...]로 다시 셰이프하여 크기가 k인 축을 m 하위 축으로 더 분할할 수 있습니다.
동기
축을 분할하는 이유를 이해하려면 다음 예를 살펴보겠습니다.
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 : (tensor<8xf32>) -> tensor<2x4xf32>
통신을 피하는 방식으로 (즉, 데이터를 있는 그대로 유지) 리셰이프 결과를 샤딩하려고 합니다. "x"의 크기가 결과의 첫 번째 차원보다 크므로 축을 크기가 각각 2인 두 개의 하위 축 "x.0" 및 "x.1"으로 분할하고 "x.0"에서 첫 번째 차원을 샤딩하고 "x.1"에서 두 번째 차원을 샤딩해야 합니다.
함수 입력/출력 샤딩
전파 중에 기본 함수의 입력 또는 출력이 하위 축을 따라 샤딩될 수 있습니다. 이는 사용자에게 다시 제공하기 위해 이러한 샤딩을 표현할 수 없는 일부 프레임워크에서 문제가 될 수 있습니다 (예: JAX에서는 jax.sharding.NamedSharding로 하위 축을 표현할 수 없음).
이러한 케이스를 처리하는 방법에는 다음과 같은 몇 가지 옵션이 있습니다.
- 샤딩을 허용하고 다른 형식으로 반환합니다 (예: JAX의
jax.sharding.NamedSharding대신jax.sharding.PositionalSharding). - 입력/출력을 샤딩하는 하위 축을 허용하지 않고 all-gather합니다.
현재는 전파 파이프라인의 입력/출력에 하위 축을 허용합니다. 이 기능을 사용 중지하는 방법을 알고 싶다면 Google에 알려주세요.
표현
메시에서 특정 전체 축을 이름으로 참조하는 것과 동일한 방식으로 특정 하위 축을 크기와 왼쪽에 있는 모든 하위 축 (동일한 축 이름) 크기의 곱 (주요)으로 참조할 수 있습니다.
크기가 n인 전체 축 "x"에서 크기가 k인 특정 하위 축을 추출하려면 메시에서 크기 n를 [m, k, n/(m*k)]로 효과적으로 재형성하고 두 번째 크기를 하위 축으로 사용합니다. 따라서 하위 축은 두 숫자 m 및 k로 지정할 수 있으며 다음과 같은 간결한 표기법을 사용하여 하위 축을 나타냅니다. "x":(m)k.
m>=1는 이 하위 축의 사전 크기입니다 (m는n의 제수여야 함). 사전 크기는 이 하위 축의 왼쪽에 있는 모든 하위 축 크기 (이 하위 축에 대해 기본이 되는 하위 축)의 곱입니다 (1과 같으면 하위 축이 없음을 의미하고 1보다 크면 하나 이상의 하위 축에 해당함).k>1는 이 하위 축의 실제 크기입니다 (k는n의 제수여야 함).n/(m*k)는 게시물 크기입니다. 이 하위 축의 오른쪽에 있는 모든 하위 축 크기(이 하위 축보다 작은 크기)의 곱입니다. 1과 같으면 하위 축이 없음을 의미하고 1보다 크면 하나 또는 여러 개의 하위 축에 해당합니다.
그러나 특정 하위 축 "x":(m)k를 사용할 때는 다른 하위 축의 수가 중요하지 않으며, 다른 하위 축이 측정기준을 샤딩하지 않거나 명시적으로 복제되는 경우에는 텐서 샤딩에서 참조할 필요가 없습니다.
동기 부여 섹션의 예시로 돌아가면 다음과 같이 결과를 샤딩할 수 있습니다.
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 {sdy.sharding_per_value=<[<@mesh_x, [{"x":(1)2}, {"x":(2)2}]>]>}
: (tensor<8xf32>) -> tensor<2x4xf32>
다음은 일부 하위 축만 사용되는 분할 축의 또 다른 예입니다.
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Axis "y" is effectively split into 3 sub-axes denoted as
// "y":(1)2, "y":(2)2, "y":(4)2
// in order, but only "y":(2)2 is used, to shard the 2nd dimension. The local
// shape of this tensor (i.e. the shape on a single device), would be
// tensor<2x4xf32>.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}]> : tensor<4x8xf32>
마찬가지로 다음 두 샤딩은 의미상 동일합니다. mesh_xy을 mesh_full의 분할로 생각할 수 있습니다.
@mesh_full = <"devices"=8>
@mesh_xy = <"x"=4, "y"=2>
sharding<@mesh_xy, [{"x"},{ "y"}]> : tensor<4x4xf32>
sharding<@mesh_full, [{"devices":(1)4}, {"devices":(4)2}]> : tensor<4x4xf32>
명시적으로 복제된 하위 축
하위 축은 측정기준을 샤딩하는 데 사용되는 것 외에도 명시적으로 복제된 것으로 표시할 수도 있습니다. 하위 축은 전체 축과 동일하게 동작하므로 표현에서 이를 허용합니다. 즉, 축 "x"의 하위 축을 따라 측정기준을 샤딩하면 "x"의 다른 하위 축이 암시적으로 복제되므로 하위 축이 복제된 상태로 유지되어야 하고 측정기준을 샤딩하는 데 사용할 수 없음을 나타내기 위해 명시적으로 복제할 수 있습니다.
예를 들면 다음과 같습니다.
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Sub-axis "y":(1)2 is explicitly replicated and "y":(4)2 is implicitly replicated.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}], replicated={"y":(1)2}> : tensor<4x8xf32>
동일한 전체 축의 복제된 하위 축은 사전 크기를 기준으로 오름차순으로 정렬해야 합니다. 예를 들면 다음과 같습니다.
replicated={"y":(4)2, "x", "y":(1)2} ~> replicated={"x", "y":(1)2, "y":(4)2}
불변항
텐서 샤딩에서 참조되는 하위 축이 겹쳐서는 안 됩니다(예:
"x":(1)4및"x":(2)4가 겹침).텐서 샤딩에서 참조되는 하위 축은 최대한 커야 합니다. 즉, 측정기준 샤딩에 인접한 하위 축 A와 B가 순서대로 두 개 있거나 하위 축 A와 B가 명시적으로 복제된 경우, 하위 축이 연속되어서는 안 됩니다(예:
"x":(1)2및"x":(2)4). 연속된 하위 축은 단일"x":(1)8로 대체할 수 있기 때문입니다.
여러 논리 메시
하나의 논리 메시는 기기의 다차원 뷰입니다. 특히 임의의 기기 할당의 경우 샤딩을 나타내기 위해 기기의 여러 뷰가 필요할 수 있습니다.
예를 들어 jax.sharding.PositionalSharding에는 하나의 공통 로직 메시지가 없습니다.
GSPMD는 현재 HloSharding으로 이를 지원합니다. 여기서 표현은 기기 및 크기 측정기준 크기의 정렬된 목록일 수 있지만 위의 축 분할로는 표현할 수 없습니다.
프로그램 최상위 수준에서 여러 개의 논리적 메시를 정의하여 이 제한을 극복하고 기존의 특이 사례를 처리합니다. 각 메시지는 이름이 다른 여러 개의 축과 동일한 기기 세트에 대한 자체 임의 할당을 가질 수 있습니다. 즉, 각 메시지는 고유한 논리 ID를 사용하여 동일한 기기 세트를 참조하지만 GSPMD 표현과 마찬가지로 임의의 순서로 참조합니다.
각 샤딩 표현식은 특정 논리적 메시에 연결되므로 해당 메시의 축만 참조합니다.
하나의 논리 메시에 할당된 텐서를 다른 메시에 할당된 연산에서 사용할 수 있습니다. 이를 위해서는 대상 메시에 맞게 텐서를 단순히 다시 샤딩하면 됩니다. GSPMD에서는 일반적으로 충돌하는 메시지를 해결하기 위해 이 작업을 실행합니다.
사용자는 이름이 다른 축 (예: jax.sharding.NamedSharding를 통해)을 사용하여 기기 순서가 동일한 여러 메시를 지정할 수 있습니다. 다음 예를 고려해 보세요. <@mesh_0, "b">는 <@mesh_1, "z">와 동일합니다.
@mesh_0 = {<["a"=4, "b"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
@mesh_1 = {<["x"=2, "y"=2, "z"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
우선순위
우선순위는 특정 파티셔닝 및 전파 결정을 다른 결정보다 우선시하는 방법이며 프로그램의 증분 파티셔닝을 허용합니다.
우선순위는 샤딩 표현의 일부 또는 모든 측정기준에 연결된 값입니다 (복제된 축에는 우선순위가 없음).
예를 들면 다음과 같습니다.
@mesh_xy = <["w"=6, "x"=2, "y"=4, "z"=2]>
// |-> y is implicitly p0
%arg4 : sharding<@mesh_xy, [{"x"}p1, {"y"}, {"z",?}p2], replicated={} }>
우선순위를 사용하면 사용자가 전파를 더 세부적으로 제어할 수 있습니다(예: 먼저 일괄 병렬 처리, 그다음 megatron, 마지막으로 ZeRO 샤딩). 이를 통해 파티션된 항목에 대해 강력한 보장을 제공하고 더 세분화된 샤딩 전략을 사용하여 디버그 가능성을 개선할 수 있습니다 (megatron만 격리된 후 프로그램이 어떻게 표시되는지 확인할 수 있음).
각 측정기준 샤딩에 우선순위를 연결할 수 있습니다 (기본값: 0). 이는 우선순위가 <i인 모든 샤딩이 우선순위가 i인 샤딩보다 먼저 전체 프로그램에 전파됨을 나타냅니다.
샤딩에 우선순위가 낮은 열린 측정기준이 있는 경우에도(예: {"z",?}p2: 전파 중에 우선순위가 더 높은 다른 텐서 샤딩에 의해 재정의되지 않습니다. 그러나 이러한 개방형 측정기준은 모든 우선순위가 더 높은 샤딩이 전파된 후에 추가로 샤딩할 수 있습니다.
즉, 우선순위는 어떤 측정기준 샤딩이 다른 측정기준 샤딩보다 더 중요한지에 관한 것이 NOT. 측정기준 샤딩의 고유한 그룹이 전체 프로그램에 전파되어야 하는 순서와 주석이 없는 중간 텐서의 충돌을 해결하는 방법입니다.
불변항
우선순위는 0 (가장 높은 우선순위)에서 시작하여 증가합니다. 사용자가 우선순위를 쉽게 추가하고 삭제할 수 있도록 우선순위 간에 간격을 허용합니다 (예: p0 및 p2는 사용되지만 p1은 사용되지 않음).
빈 폐쇄된 측정기준 샤딩 (예:
{})는 우선순위가 없어도 됩니다. 영향을 미치지 않기 때문입니다.
측정기준 샤딩 분할 가능 여부
크기가 d인 측정기준이 크기의 곱이 n인 축을 따라 샤딩될 수 있습니다. 즉, d를 n로 나눌 수 없습니다 (실제로는 측정기준을 패딩해야 함).
예를 들면 다음과 같습니다.
@mesh_xy = <["x"=8, "y"=2, "z"=3]>
sharding<@mesh_xy, [{"x"}, {"y"}, {"z"}]> : tensor<7x3x8xf32>
문법
각 논리적 메시는 다음과 같이 정의됩니다.
@mesh_name = <mesh_axis_1,...,mesh_axis_n>
mesh_axis ::= axis_name=axis_size
axis_name ::= str
axis_size ::= int
샤딩 표현은 등급이 r인 텐서의 경우 다음과 같은 구조를 갖습니다.
sharding<@mesh_name, dim_shardings, replicated=replicated_axes}
mesh_name ::= str
dim_shardings ::= [dim_sharding_1,...,dim_sharding_r]
replicated_axes ::= {axis_1,...,axis_m}
dim_sharding ::=
{axis_1,...,axis_k} | // closed dimension
{axis_1,...,axis_k,?} // open dimension
axis ::=
axis_name | // a full axis
sub_axis // a sub axis
axis_name ::= str
sub_axis ::= axis_name:(pre_size)size
pre_size ::= int
size ::= int