
Thông tin khái quát
Mục đích của việc biểu thị phân đoạn là chỉ định cách phân đoạn một tensor liên quan đến một tập hợp thiết bị có sẵn.
Cách trình bày phân đoạn có thể là:
- Do người dùng chỉ định theo cách thủ công dưới dạng các quy tắc ràng buộc phân đoạn đối với dữ liệu đầu vào, đầu ra hoặc trung gian.
- Biến đổi theo từng thao tác trong quá trình truyền phân đoạn.
Tổng quan
Cấu trúc cơ bản
Lưới logic là một chế độ xem đa chiều của các thiết bị, được xác định bằng danh sách tên và kích thước trục.
Biểu diễn phân đoạn đề xuất được liên kết với một lưới logic cụ thể theo tên và chỉ có thể tham chiếu tên trục từ lưới đó. Việc phân đoạn một tensor chỉ định theo trục nào (của một lưới logic cụ thể) mỗi phương diện của tensor được phân đoạn, sắp xếp từ chính đến phụ. Tensor được sao chép dọc theo tất cả các trục khác của lưới.
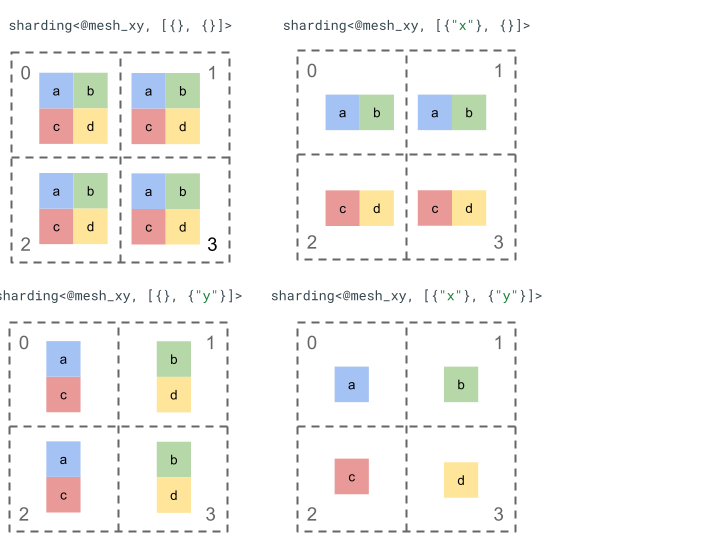
Hãy khám phá cách biểu thị phân đoạn bằng một tensor thứ hạng 2 đơn giản và 4 thiết bị.
Trước tiên, chúng ta định hình lại 4 thiết bị [0, 1, 2, 3] thành một mảng 2 chiều [[0, 1], [2,
3]] để tạo một lưới có 2 trục:
@mesh_xy = <["x"=2, "y"=2]>
Sau đó, chúng ta có thể phân đoạn tensor thứ hạng 2 [[a, b], [c, d]] như sau:
Các thành phần chính khác
- Phương diện Mở/Đóng – phương diện có thể là phương diện mở – có thể được phân đoạn thêm trên các trục có sẵn; hoặc phương diện đóng – là phương diện cố định và không thể thay đổi.
- Trục được sao chép rõ ràng – tất cả các trục không được dùng để phân đoạn một phương diện đều được sao chép ngầm ẩn, nhưng tính năng phân đoạn có thể chỉ định các trục được sao chép rõ ràng và do đó không thể dùng để phân đoạn một phương diện sau này.
- Phân chia trục và trục phụ – một trục lưới (đầy đủ) có thể được chia thành nhiều trục phụ có thể được sử dụng riêng lẻ để phân đoạn một phương diện hoặc được sao chép rõ ràng.
- Nhiều lưới logic – nhiều phân đoạn có thể được liên kết với nhiều lưới logic, có thể có các trục khác nhau hoặc thậm chí là thứ tự mã thiết bị logic khác nhau.
- Mức độ ưu tiên – để phân vùng một chương trình tăng dần, bạn có thể đính kèm mức độ ưu tiên vào các phân đoạn phương diện. Mức độ ưu tiên này sẽ xác định thứ tự mà các quy tắc ràng buộc phân đoạn theo phương diện sẽ được truyền trong toàn bộ mô-đun.
- Khả năng phân đoạn theo phương diện – một phương diện có thể được phân đoạn trên các trục có tích kích thước không chia hết cho kích thước phương diện.
Thiết kế chi tiết
Chúng ta sẽ mở rộng cấu trúc cơ bản và từng thành phần chính trong phần này.
Cấu trúc cơ bản
Các phân đoạn theo phương diện cho chúng ta biết về mỗi phương diện của tensor, theo đó các trục (hoặc trục phụ) được phân đoạn từ chính đến phụ. Tất cả các trục khác không phân đoạn một phương diện sẽ được sao chép ngầm (hoặc sao chép rõ ràng).
Chúng ta sẽ bắt đầu với một ví dụ đơn giản và mở rộng ví dụ đó khi mô tả các tính năng bổ sung.
@mesh_xy = <["x"=2, "y"=4, "z"=2]>
// The 1st tensor dimension is sharded along axis "x" and the 2nd tensor dimension is
// sharded along axis "z" then further along axis "y". The local shape of this tensor (i.e. the shape on a single device), would be tensor<2x1xf32>.
sharding<@mesh_xy, [{"x"}, {"z", "y"}]> : tensor<4x8xf32>
Biến không đổi
- Số lượng phân đoạn theo phương diện phải khớp với thứ hạng của tensor.
- Tất cả tên trục phải tồn tại trong lưới được tham chiếu.
- Trục hoặc trục phụ chỉ có thể xuất hiện một lần trong bản trình bày phân đoạn (mỗi trục phân đoạn một phương diện hoặc được sao chép rõ ràng).
Phương diện mở/đóng
Mỗi phương diện của một tensor có thể là mở hoặc đóng.
Mở
Phương diện mở có thể được truyền để phân đoạn thêm theo các trục bổ sung, tức là việc phân đoạn phương diện được chỉ định không phải là phân đoạn cuối cùng của phương diện đó. Điều này tương tự (nhưng không giống hệt) với unspecified_dims của GSMPD.
Nếu một phương diện đang mở, chúng ta sẽ thêm một ? theo các trục mà phương diện đó đã được phân đoạn (xem ví dụ bên dưới).
Đã đóng
Phương diện đóng là phương diện không thể dùng để truyền tải nhằm thêm phân đoạn khác, tức là phương diện phân đoạn được chỉ định là phương diện phân đoạn cuối cùng của phương diện đó và không thể thay đổi. Một trường hợp sử dụng phổ biến của việc này là cách GSPMD (thường) không sửa đổi các đối số đầu vào/đầu ra của một mô-đun hoặc cách với jax.jit, in_shardings do người dùng chỉ định là tĩnh – không thể thay đổi.
Chúng ta có thể mở rộng ví dụ ở trên để có một phương diện mở và một phương diện đóng.
@mesh_xy = <["x"=2, "y"=4, "z"=2]>
// The 1st dimension is closed, therefore it can't be further sharded and {"x"}
// will remain its sharding. The 2nd dimension is open, and can therefore be
// further sharded during propagation, e.g. by "y".
sharding<@mesh_xy, [{"x"}, {"z", ?}]> : tensor<4x8xf32>
Trục được sao chép rõ ràng
Một tập hợp các trục rõ ràng mà tensor được sao chép trên đó. Mặc dù có thể xác định rằng một tensor không được phân đoạn trên một trục được sao chép ngầm trên trục đó (chẳng hạn như jax.sharding.PartitionSpec ngày nay), nhưng việc làm rõ điều này sẽ đảm bảo rằng quá trình truyền tải không thể sử dụng các trục này để phân đoạn thêm một phương diện mở bằng các trục đó. Với tính năng sao chép ngầm ẩn, một tensor có thể được phân vùng thêm. Tuy nhiên, với tính năng sao chép rõ ràng, không có gì có thể phân vùng tensor dọc theo trục đó.
Thứ tự của các trục được sao chép không ảnh hưởng đến cách lưu trữ dữ liệu của một tensor. Tuy nhiên, chỉ để đảm bảo tính nhất quán, các trục sẽ được lưu trữ theo thứ tự được chỉ định trong lưới cấp cao nhất. Ví dụ: nếu lưới là:
@mesh_xy = <["c"=2, "a"=2, "b"=2]>
Và chúng ta muốn các trục "a" và "c" được sao chép rõ ràng, thứ tự sẽ là:
replicated={"c", "a"}
Chúng ta có thể mở rộng ví dụ ở trên để có một trục được sao chép rõ ràng.
@mesh_xyz = <["x"=2, "y"=4, "z"=2]>
// Since "y" is explicitly replicated, it can't be used to shard the 2nd
// dimension that is open. However, "z" is implicitly replicated so it can be
// used to shard that dimension. The local shape of this tensor (i.e. the
// shape on a single device), would be tensor<2x8xf32>.
sharding<@mesh_xyz, [{"x"}, {?}], replicated={"y"}> : tensor<4x8xf32>
Phân tách trục và trục phụ
Một lưới logic của các trục n được tạo bằng cách định hình lại một mảng 1 chiều của các thiết bị thành một mảng n chiều, trong đó mỗi chiều tạo thành một trục có tên do người dùng xác định.
Bạn có thể thực hiện quy trình tương tự trong trình biên dịch để chia một trục có kích thước k thành các trục phụ m, bằng cách định hình lại lưới từ [...,k,...] thành [...,k1,...,km,...].
Động lực
Để hiểu rõ lý do chia trục, chúng ta sẽ xem xét ví dụ sau:
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 : (tensor<8xf32>) -> tensor<2x4xf32>
Chúng ta muốn phân đoạn kết quả của việc định hình lại theo cách tránh giao tiếp (tức là giữ nguyên dữ liệu). Vì kích thước của "x" lớn hơn phương diện thứ nhất của kết quả, nên chúng ta cần chia trục thành hai trục phụ "x.0" và "x.1", mỗi trục có kích thước 2, đồng thời phân đoạn phương diện thứ nhất trên "x.0" và phương diện thứ hai trên "x.1".
Phân đoạn đầu vào/đầu ra của hàm
Có thể trong quá trình truyền tải, dữ liệu đầu vào hoặc đầu ra của hàm chính sẽ được phân đoạn dọc theo trục phụ. Đây có thể là vấn đề đối với một số khung, trong đó chúng ta không thể thể hiện các phân đoạn như vậy để trả lại cho người dùng (ví dụ: trong JAX, chúng ta không thể thể hiện các trục phụ bằng jax.sharding.NamedSharding).
Chúng tôi có một số cách để xử lý những trường hợp như vậy:
- Cho phép và trả về phân đoạn ở định dạng khác (ví dụ:
jax.sharding.PositionalShardingthay vìjax.sharding.NamedShardingtrong JAX). - Không cho phép và thu thập tất cả các trục phụ phân đoạn đầu vào/đầu ra.
Hiện tại, chúng tôi cho phép các trục phụ trên đầu vào/đầu ra trong quy trình truyền tải. Hãy cho chúng tôi biết nếu bạn muốn tắt tính năng này.
Bản trình bày
Tương tự như cách chúng ta có thể tham chiếu các trục đầy đủ cụ thể từ lưới theo tên, chúng ta có thể tham chiếu các trục phụ cụ thể theo kích thước và tích của tất cả kích thước trục phụ (của cùng một tên trục) ở bên trái (là trục chính đối với chúng).
Để trích xuất một trục phụ cụ thể có kích thước k từ một trục đầy đủ "x" có kích thước n, chúng ta sẽ định hình lại kích thước n (trong lưới) thành [m, k, n/(m*k)] một cách hiệu quả và sử dụng kích thước thứ 2 làm trục phụ. Do đó, bạn có thể chỉ định một trục phụ bằng hai số, m và k, và chúng tôi sử dụng ký hiệu ngắn gọn sau đây để biểu thị các trục phụ: "x":(m)k.
m>=1là kích thước trước của trục phụ này (mphải là bộ chia củan). Kích thước trước là tích của tất cả kích thước trục phụ ở bên trái (là trục chính của) trục phụ này (nếu bằng 1 thì có nghĩa là không có trục phụ nào, nếu lớn hơn 1 thì tương ứng với một hoặc nhiều trục phụ).k>1là kích thước thực tế của trục phụ này (kphải là bộ chia củan).n/(m*k)là kích thước sau khi đăng. Đây là tích của tất cả kích thước trục phụ ở bên phải (nhỏ hơn) trục phụ này (nếu bằng 1 thì có nghĩa là không có trục phụ nào, nếu lớn hơn 1 thì tương ứng với một hoặc nhiều trục phụ).
Tuy nhiên, số lượng trục phụ khác không tạo ra sự khác biệt khi sử dụng một trục phụ cụ thể "x":(m)k và không cần tham chiếu bất kỳ trục phụ nào khác trong quá trình phân đoạn tensor nếu trục phụ đó không phân đoạn một phương diện hoặc được sao chép rõ ràng.
Quay lại ví dụ trong phần Lý do, chúng ta có thể phân đoạn kết quả như sau:
@mesh_x = <["x"=4]>
%arg0 : tensor<8xf32> {sdy.sharding=<@mesh_x, [{"x"}]>}
%0 = reshape %arg0 {sdy.sharding_per_value=<[<@mesh_x, [{"x":(1)2}, {"x":(2)2}]>]>}
: (tensor<8xf32>) -> tensor<2x4xf32>
Sau đây là một ví dụ khác về trục phân tách, trong đó chỉ một số trục phụ được sử dụng.
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Axis "y" is effectively split into 3 sub-axes denoted as
// "y":(1)2, "y":(2)2, "y":(4)2
// in order, but only "y":(2)2 is used, to shard the 2nd dimension. The local
// shape of this tensor (i.e. the shape on a single device), would be
// tensor<2x4xf32>.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}]> : tensor<4x8xf32>
Tương tự, hai phân đoạn sau đây có ý nghĩa tương đương. Chúng ta có thể coi mesh_xy là một phần phân tách của mesh_full.
@mesh_full = <"devices"=8>
@mesh_xy = <"x"=4, "y"=2>
sharding<@mesh_xy, [{"x"},{ "y"}]> : tensor<4x4xf32>
sharding<@mesh_full, [{"devices":(1)4}, {"devices":(4)2}]> : tensor<4x4xf32>
Trục phụ được sao chép rõ ràng
Ngoài việc được dùng để phân đoạn phương diện, các trục phụ cũng có thể được đánh dấu là được sao chép rõ ràng. Chúng tôi cho phép điều này trong bản trình bày vì các trục phụ hoạt động giống như các trục đầy đủ, tức là khi bạn phân đoạn một phương diện dọc theo trục phụ của trục "x", các trục phụ khác của "x" được sao chép ngầm ẩn và do đó có thể được sao chép rõ ràng để cho biết rằng trục phụ phải luôn được sao chép và không thể dùng để phân đoạn một phương diện.
Ví dụ:
@mesh_xyz = <["x"=2, "y"=8, "z"=2]>
// Sub-axis "y":(1)2 is explicitly replicated and "y":(4)2 is implicitly replicated.
sharding<@mesh_xyz, [{"x"}, {"y":(2)2}], replicated={"y":(1)2}> : tensor<4x8xf32>
Trục phụ được sao chép của cùng một trục đầy đủ phải được sắp xếp theo thứ tự tăng dần theo kích thước trước, ví dụ:
replicated={"y":(4)2, "x", "y":(1)2} ~> replicated={"x", "y":(1)2, "y":(4)2}
Biến không đổi
Các trục phụ được tham chiếu trong quá trình phân đoạn tensor không được trùng lặp, ví dụ:
"x":(1)4và"x":(2)4trùng lặp.Các trục phụ được tham chiếu trong một quá trình phân đoạn tensor phải lớn nhất có thể, tức là nếu quá trình phân đoạn phương diện có hai trục phụ A và B liền kề theo thứ tự hoặc các trục phụ A và B được sao chép rõ ràng, thì các trục phụ này không được liên tiếp, ví dụ:
"x":(1)2và"x":(2)4vì các trục này có thể được thay thế bằng một"x":(1)8.
Nhiều lưới logic
Một lưới logic là một chế độ xem đa chiều của các thiết bị. Chúng ta có thể cần nhiều chế độ xem của các thiết bị để thể hiện các phân đoạn, đặc biệt là đối với các lượt chỉ định thiết bị tuỳ ý.
Ví dụ: jax.sharding.PositionalSharding không có một lưới logic chung.
GSPMD hiện hỗ trợ việc đó bằng HloSharding, trong đó nội dung trình bày có thể là một danh sách theo thứ tự các thiết bị và kích thước phương diện, nhưng không thể trình bày bằng tính năng phân tách trục ở trên.
Chúng ta khắc phục hạn chế này và xử lý các trường hợp hiếm gặp hiện có bằng cách xác định nhiều lưới logic ở cấp cao nhất của chương trình. Mỗi lưới có thể có số lượng trục khác nhau với tên khác nhau, cũng như chỉ định tuỳ ý riêng cho cùng một nhóm thiết bị, tức là mỗi lưới tham chiếu đến cùng một nhóm thiết bị (theo mã nhận dạng logic duy nhất của chúng) nhưng theo thứ tự tuỳ ý, tương tự như cách trình bày GSMPD.
Mỗi bản trình bày phân đoạn được liên kết với một lưới logic cụ thể, do đó, bản trình bày này sẽ chỉ tham chiếu các trục từ lưới đó.
Một tensor được chỉ định cho một lưới logic có thể được một toán tử được chỉ định cho một lưới khác sử dụng, bằng cách phân đoạn lại tensor để khớp với lưới đích. Trong GSPMD, đây là việc thường được thực hiện để giải quyết các lưới xung đột.
Người dùng có thể chỉ định nhiều lưới có các trục được đặt tên khác nhau (ví dụ: thông qua jax.sharding.NamedSharding), có cùng thứ tự thiết bị. Hãy xem xét ví dụ này, <@mesh_0, "b"> giống hệt với <@mesh_1, "z">:
@mesh_0 = {<["a"=4, "b"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
@mesh_1 = {<["x"=2, "y"=2, "z"=2]>, device_ids=[0, 1, 2, 3, 4, 5, 6, 7]}
Mức độ ưu tiên
Mức độ ưu tiên là một cách để ưu tiên một số quyết định phân vùng và truyền tải nhất định hơn các quyết định khác, đồng thời cho phép phân vùng tăng dần một chương trình.
Mức độ ưu tiên là các giá trị được đính kèm vào một số hoặc tất cả các phương diện của một bản trình bày phân đoạn (các trục được sao chép không có mức độ ưu tiên).
Ví dụ:
@mesh_xy = <["w"=6, "x"=2, "y"=4, "z"=2]>
// |-> y is implicitly p0
%arg4 : sharding<@mesh_xy, [{"x"}p1, {"y"}, {"z",?}p2], replicated={} }>
Mức độ ưu tiên giúp người dùng kiểm soát chi tiết hơn việc truyền tải, ví dụ: trước tiên là tính song song hàng loạt, sau đó là megatron và cuối cùng là phân đoạn ZeRO. Điều này cho phép đảm bảo mạnh mẽ về nội dung được phân vùng và cho phép gỡ lỗi tốt hơn bằng cách có các chiến lược phân đoạn chi tiết hơn (có thể xem giao diện của chương trình sau khi chỉ tách riêng megatron).
Chúng tôi cho phép đính kèm mức độ ưu tiên cho từng phân đoạn phương diện (0 theo mặc định). Điều này cho biết rằng tất cả các phân đoạn có mức độ ưu tiên <i sẽ được truyền đến toàn bộ chương trình trước các phân đoạn có mức độ ưu tiên i.
Ngay cả khi một phân đoạn có một phương diện mở có mức độ ưu tiên thấp hơn, ví dụ: {"z",?}p2,
thông tin này sẽ không bị ghi đè bởi một phân đoạn tensor khác có mức độ ưu tiên cao hơn trong quá trình
truyền. Tuy nhiên, bạn có thể phân đoạn thêm một phương diện mở như vậy sau khi tất cả các phương diện phân đoạn có mức độ ưu tiên cao hơn đã được truyền.
Nói cách khác, mức độ ưu tiên NOT liên quan đến việc phân đoạn kích thước nào quan trọng hơn kích thước khác – đó là thứ tự mà các nhóm phân đoạn kích thước riêng biệt sẽ truyền đến toàn bộ chương trình và cách giải quyết xung đột trên các tensor trung gian, chưa chú thích.
Biến không đổi
Mức độ ưu tiên bắt đầu từ 0 (mức độ ưu tiên cao nhất) và tăng lên (để cho phép người dùng dễ dàng thêm và xoá mức độ ưu tiên, chúng tôi cho phép có khoảng trống giữa các mức độ ưu tiên, ví dụ: p0 và p2 được sử dụng nhưng p1 thì không).
Phân đoạn phương diện đóng trống (tức là
{}), không được có mức độ ưu tiên, vì điều này sẽ không có hiệu lực.
Tính chia được của việc phân đoạn phương diện
Bạn có thể phân đoạn một phương diện có kích thước d dọc theo các trục có tích kích thước là n, sao cho d không chia hết cho n (trong thực tế, bạn sẽ phải thêm khoảng đệm cho phương diện này).
Ví dụ:
@mesh_xy = <["x"=8, "y"=2, "z"=3]>
sharding<@mesh_xy, [{"x"}, {"y"}, {"z"}]> : tensor<7x3x8xf32>
Ngữ pháp
Mỗi lưới logic được xác định như sau:
@mesh_name = <mesh_axis_1,...,mesh_axis_n>
mesh_axis ::= axis_name=axis_size
axis_name ::= str
axis_size ::= int
Biểu diễn phân đoạn sẽ có cấu trúc sau đây cho một tensor có thứ hạng r:
sharding<@mesh_name, dim_shardings, replicated=replicated_axes}
mesh_name ::= str
dim_shardings ::= [dim_sharding_1,...,dim_sharding_r]
replicated_axes ::= {axis_1,...,axis_m}
dim_sharding ::=
{axis_1,...,axis_k} | // closed dimension
{axis_1,...,axis_k,?} // open dimension
axis ::=
axis_name | // a full axis
sub_axis // a sub axis
axis_name ::= str
sub_axis ::= axis_name:(pre_size)size
pre_size ::= int
size ::= int