
Tout le monde peut contribuer à OpenXLA, et nous apprécions toutes les contributions. Vous pouvez contribuer de plusieurs façons, par exemple :
Répondre aux questions sur les forums de discussion OpenXLA (openxla-discuss)
Améliorer ou étendre la documentation d'OpenXLA
Contribuer à la codebase d'OpenXLA
Contribuer de l'une des manières ci-dessus à l'écosystème plus large de bibliothèques basées sur OpenXLA
Le projet OpenXLA suit les Consignes de la communauté Open Source de Google.
Avant de commencer
Signer le contrat de licence du contributeur
Les contributions à ce projet doivent être accompagnées d'un Contrat de licence de contributeur (CLA). Vous (ou votre employeur) conservez les droits d'auteur sur votre contribution. Cela nous autorise simplement à utiliser et à redistribuer vos contributions dans le cadre du projet.
Si vous ou votre employeur actuel avez déjà signé le CLA Google (même si c'était pour un autre projet), vous n'avez probablement pas besoin de le faire à nouveau.
Accédez à <https://cla.developers.google.com/> pour consulter vos contrats actuels ou en signer un nouveau.
Consulter le code de conduite
Ce projet respecte le code de conduite de TensorFlow.
Processus de contribution
Guide du développeur
Pour savoir comment configurer un environnement de développement pour OpenXLA, y compris comment obtenir le code, le compiler, exécuter des tests et envoyer des modifications, veuillez consulter le Guide du développeur.
Guide de contribution
L'architecture du compilateur se compose des composants suivants.
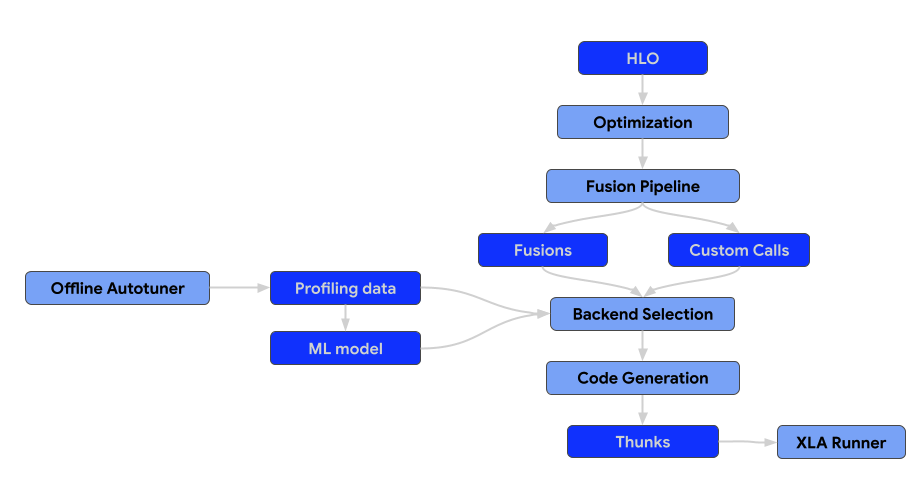
Passes d'optimisation
Les passes d'optimisation exécutent des transformations sur le HLO pour améliorer l'efficacité du calcul. Ces transformations vont des améliorations de haut niveau indépendantes de l'architecture aux ajustements spécifiques au matériel (par exemple, pour les GPU NVIDIA).
Ce que nous acceptons généralement :
- Passes qui se généralisent sur plusieurs charges de travail et qui démontrent un impact positif clair et significatif sur les benchmarks de performances.
Voici ce que nous refusons généralement :
- Passes qui effectuent des optimisations uniques ciblant des modèles spécifiques.
Cartes Fusion
La fusion est une optimisation essentielle qui combine plusieurs opérations HLO dans un seul kernel pour réduire les frais généraux liés aux E/S de mémoire et au lancement de kernels.
Tous les passes de fusion doivent être ajoutés au pipeline de fusion uniquement, et non avant ni après. Cela signifie également que le module HLO préoptimisé ne doit pas contenir d'instructions de fusion. Si la fusion est formée tôt dans le pipeline, elle devient une barrière pour les passes d'optimisation. Si la fusion est formée tardivement, nous perdons la possibilité de sélectionner et d'ajuster le backend pour la fusion générée.
La fusion dans les appels personnalisés, c'est-à-dire la mise en correspondance des appels personnalisés avec les producteurs/consommateurs et leur réécriture dans les nouveaux appels personnalisés, n'est pas autorisée. Dans ce cas, il doit être remplacé par un pass de fusion approprié.
Scaling horizontal
Les contributions à l'évolutivité horizontale englobent les optimisations HLO, les améliorations du modèle de coût, les mises à jour de la bibliothèque et diverses modifications de l'infrastructure. En raison de la difficulté à reproduire les gains de performances et du besoin limité de configurations multi-hôtes en interne, nous respectons des critères d'acceptation stricts :
Nous privilégions les modifications peu invasives et peu risquées.
Ce que nous acceptons généralement :
Mises à jour des bibliothèques gérant la communication entre les GPU ou les hôtes.
Mises à jour du tableau des performances pour les nouvelles plates-formes.
Voici ce que nous refusons généralement :
Réécritures HLO ou modifications du runtime adaptées à un modèle spécifique.
Modifications de l'infrastructure qui introduisent de nouveaux indicateurs, une dette technique ou des régressions.
Backends et réglage automatique
Les backends pour les opérations non imbriquées, par exemple les appels et les fusions personnalisés, doivent implémenter l'interface CodegenBackend.
Cette interface est nécessaire pour permettre une sélection optimale du backend, car elle fournit les méthodes permettant d'inclure les paramètres des instructions HLO données dans l'espace de recherche de l'autotuner.
// Returns all supported configs for the given HLO instruction.
virtual absl::StatusOr<std::vector<std::unique_ptr<BackendConfig>>>
GetSupportedConfigs(const HloInstruction& instr);
// Returns a default config for the given HLO instruction.
virtual absl::StatusOr<std::unique_ptr<BackendConfig>> GetDefaultConfig(
const HloInstruction& instr);
Environnement d'exécution
Le résultat final du pipeline de compilation XLA est une séquence de thunks pouvant être sérialisée.
Tous les nouveaux types de thunk doivent être sérialisables, c'est-à-dire que GpuCompiler ou CpuCompiler doivent pouvoir compiler le programme et le sérialiser afin que l'exécuteur XLA puisse le charger et l'exécuter ultérieurement. Cela signifie qu'il ne doit pas y avoir de pointeurs vers HloInstruction ni vers d'autres parties du compilateur ou de StreamExecutor.
Normes de code
Style de codage : nous suivons le guide de style de codage de Google. Consultez plus précisément les guides C/C++ et Python. Tout code envoyé doit respecter scrupuleusement ces guides de style.
Modifications compactes : nous suivons les pratiques d'ingénierie de Google. En particulier, veuillez consulter le guide sur la rédaction de modifications compactes. Cela augmentera considérablement la vitesse à laquelle votre code peut être fusionné en raison de l'amélioration de la revue, et réduira la probabilité d'effets secondaires involontaires des modifications. Même si vous devez apporter un changement important, il existe de nombreuses stratégies pour le diviser en modifications plus progressives.
Couverture des tests : toutes les modifications doivent inclure des tests unitaires appropriés. Les tests unitaires ne doivent pas dépendre de timings matériels spécifiques (CPU, GPU, etc.). Ils doivent utiliser largement des mocks et des fakes afin de créer des tests déterministes et ciblés. Les modifications visant à étendre le code existant qui est actuellement difficile à tester doivent apporter les améliorations appropriées à la testabilité.
Tous les changements doivent inclure des résultats de référence appropriés dans le titre du changement pour que les avantages soient clairement compris.
En cas de doute sur les conventions dans le code, il est toujours judicieux d'examiner le code préexistant et d'essayer de suivre les modèles déjà en place dans OpenXLA.
Procédure d'examen
Tous les envois, y compris ceux des membres du projet, doivent être examinés. Pour ce faire, nous utilisons les demandes d'extraction GitHub. Pour en savoir plus sur l'utilisation des demandes d'extraction, consultez l'aide GitHub.
Avant d'être examiné, le code doit respecter toutes les normes listées ci-dessus. Ces éléments ne sont pas facultatifs. Il est essentiel que l'auteur de la demande s'assure que son code est conforme avant de demander un examen afin de garantir l'acceptation rapide des modifications.
Tous les tests doivent réussir. Si vous constatez qu'un test est défaillant et que le problème n'est pas lié à votre environnement de compilation ni à vos modifications, veuillez contacter les responsables.
Essayez d'éviter le dépassement du périmètre lors du processus d'examen. Il s'agit de la responsabilité de l'expéditeur et de l'examinateur. Si une modification devient trop importante, envisagez de la diviser en plusieurs modifications.
Avant qu'une modification ne soit fusionnée, elle fera l'objet de tests internes utilisant du code interne à Google et à d'autres fournisseurs de matériel. Cela peut potentiellement ajouter des étapes supplémentaires au processus d'examen en cas d'échec des tests internes que notre CI publique ne détecte pas. Le Googler qui examine votre modification vous informera de tout échec de test interne et vous indiquera ce qui doit être corrigé.
Questions fréquentes (FAQ)
"Cette modification de l'infrastructure n'est pas liée à ma demande d'extraction. Pourquoi devrais-je le faire ?"
L'équipe XLA ne dispose pas d'une équipe d'infrastructure dédiée. C'est donc à nous tous de créer des bibliothèques d'assistance et d'éviter la dette technique. Nous considérons qu'il s'agit d'une étape normale pour apporter des modifications à XLA, et nous attendons de tous les utilisateurs qu'ils y participent. En général, nous créons l'infrastructure selon nos besoins lorsque nous écrivons du code.
Les examinateurs XLA peuvent vous demander de créer une infrastructure (ou d'apporter une modification importante à une demande d'extraction) en plus de la demande d'extraction que vous avez écrite. Cette demande peut sembler inutile ou orthogonale à la modification que vous essayez d'apporter. Cela est probablement dû à une différence entre vos attentes concernant la quantité d'infrastructure à créer et celles de l'examinateur.
Il n'y a pas de problème si vos attentes ne sont pas satisfaites. C'est normal quand vous découvrez un projet (et cela nous arrive parfois même à nous, les anciens). Il est probable que les projets sur lesquels vous avez travaillé par le passé aient des attentes différentes. C'est également normal et attendu. Cela ne signifie pas que l'une de ces approches est mauvaise, mais simplement qu'elles sont différentes. Nous vous invitons à considérer les demandes d'infrastructure et tous les autres commentaires sur l'examen comme une occasion d'apprendre ce que nous attendons de ce projet.
"Can I address your comment in a future PR?" (Puis-je répondre à votre commentaire dans une prochaine demande d'extraction ?)
Une question fréquente concernant les demandes d'infrastructure (ou d'autres demandes importantes) dans les PR est de savoir si la modification doit être apportée dans la PR d'origine ou si elle peut être effectuée ultérieurement dans une autre PR.
En général, XLA n'autorise pas les auteurs de demandes d'extraction à répondre aux commentaires des réviseurs avec une demande d'extraction de suivi. Lorsqu'un examinateur décide qu'un problème doit être résolu dans une demande de pull donnée, nous attendons généralement des auteurs qu'ils le fassent dans cette demande de pull, même si le changement demandé est important. Cette norme s'applique en externe, mais aussi en interne chez Google.
Plusieurs raisons expliquent cette approche de XLA.
Confiance : il est essentiel d'avoir gagné la confiance de l'examinateur. Dans un projet Open Source, les contributeurs peuvent apparaître ou disparaître à volonté. Une fois que nous avons approuvé une demande d'extraction, les réviseurs n'ont aucun moyen de s'assurer que les suivis promis sont réellement effectués.
Impact sur les autres développeurs : si vous avez envoyé une demande d'extraction concernant une partie spécifique de XLA, il y a de fortes chances que d'autres personnes s'intéressent à la même partie. Si nous acceptons la dette technique dans votre demande de pull, tous ceux qui consultent ce fichier seront concernés par cette dette jusqu'à ce que le suivi soit envoyé.
Capacité des examinateurs : différer une modification à un suivi impose plusieurs coûts à nos examinateurs déjà surchargés. Les réviseurs oublieront probablement l'objet de la première demande d'extraction en attendant la suivante, ce qui rendra la prochaine révision plus difficile. Les réviseurs devront également suivre les suivis attendus et s'assurer qu'ils ont bien lieu. Si la modification peut être apportée de manière véritablement orthogonale à la demande d'extraction d'origine afin qu'un autre réviseur puisse l'examiner, la bande passante ne posera pas de problème. D'après notre expérience, c'est rarement le cas.