
Todos podem contribuir com o OpenXLA, e valorizamos as contribuições de todos. Há várias maneiras de contribuir, incluindo:
Responder a perguntas nos fóruns de discussão do OpenXLA (openxla-discuss)
Melhorar ou expandir a documentação do OpenXLA
Como contribuir com a base de código do OpenXLA
Contribuir de qualquer uma das maneiras acima para o ecossistema mais amplo de bibliotecas criadas no OpenXLA
O projeto OpenXLA segue as diretrizes da comunidade de código aberto do Google.
Antes de começar
Assinar o Contrato de Licença de Colaborador
As contribuições para este projeto precisam ser acompanhadas de um Contrato de Licença de Colaborador (CLA, na sigla em inglês). Você (ou seu empregador) mantém os direitos autorais da sua contribuição. Isso apenas nos dá permissão para usar e redistribuir suas contribuições como parte do projeto.
Se você ou seu empregador atual já assinaram o CLA do Google (mesmo que para um projeto diferente), provavelmente não será necessário fazer isso de novo.
Acesse <https://cla.developers.google.com/> para conferir seus contratos atuais ou assinar um novo.
Leia o Código de conduta
Este projeto segue o Código de Conduta do TensorFlow.
Processo de contribuição
Guia do desenvolvedor
Para um guia sobre como configurar um ambiente de desenvolvimento para o OpenXLA, incluindo receber código, criar, executar testes e enviar mudanças, consulte o Guia do desenvolvedor.
Guia de contribuição
A arquitetura do compilador consiste nos seguintes componentes.
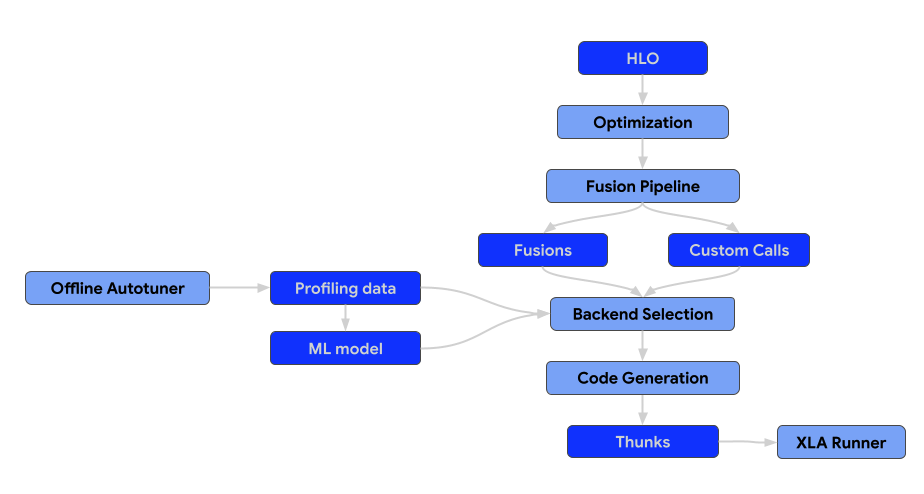
Passagens de otimização
As transmissões de otimização executam transformações no HLO para aumentar a eficiência computacional. Essas transformações abrangem desde melhorias de alto nível e independentes de arquitetura até ajustes específicos de hardware (por exemplo, para GPUs NVIDIA).
O que geralmente aceitamos:
- Aprovam em várias cargas de trabalho e demonstram um impacto positivo claro e significativo nos comparativos de performance.
O que geralmente rejeitamos:
- Passagens que realizam otimizações exclusivas segmentando modelos específicos.
Cartões de fusão
A fusão é uma otimização essencial que combina várias operações HLO em um único kernel para reduzir a E/S de memória e o overhead de inicialização do kernel.
Todas as transmissões de fusão precisam ser adicionadas apenas ao pipeline de fusão, não antes nem depois. Isso também significa que o módulo HLO pré-otimizado não pode conter instruções de fusão. Se a fusão for formada no início do pipeline, ela se tornará uma barreira para as transmissões de otimização. Se a fusão for formada tarde, vamos perder a capacidade de selecionar e ajustar o back-end para a fusão gerada.
A fusão em chamadas personalizadas, ou seja, a correspondência de padrões de chamadas personalizadas com os produtores/consumidores e a reescrita delas em novas chamadas personalizadas, não é permitida. Nesse caso, ele precisa ser substituído por uma transmissão de fusão adequada.
Escalonamento horizontal
As contribuições para o escalonamento horizontal incluem otimizações de HLO, melhorias no modelo de custo, atualizações de biblioteca e várias modificações na infraestrutura. Devido à dificuldade de reproduzir os ganhos de performance e à necessidade limitada de configurações de vários hosts internamente, aderimos a critérios de aceitação rigorosos:
Priorizamos mudanças minimamente invasivas que apresentam baixo risco.
O que geralmente aceitamos:
Atualizações nas bibliotecas que processam a comunicação entre GPUs ou hosts.
Atualizações da tabela de performance para novas plataformas.
O que geralmente rejeitamos:
Reescritas de HLO ou mudanças de tempo de execução adaptadas a um modelo específico.
Mudanças na infraestrutura que introduzem novas flags, dívidas técnicas ou regressões.
Back-ends e ajuste automático
Os back-ends para as operações não aninhadas, como fusões e chamadas personalizadas, precisam implementar a interface CodegenBackend.
Essa interface é necessária para permitir a seleção ideal de back-end, porque ela fornece os métodos para incluir os parâmetros das instruções HLO no espaço de pesquisa do autotuner.
// Returns all supported configs for the given HLO instruction.
virtual absl::StatusOr<std::vector<std::unique_ptr<BackendConfig>>>
GetSupportedConfigs(const HloInstruction& instr);
// Returns a default config for the given HLO instruction.
virtual absl::StatusOr<std::unique_ptr<BackendConfig>> GetDefaultConfig(
const HloInstruction& instr);
Ambiente de execução
O resultado final do pipeline de compilação do XLA é uma sequência de thunk que pode ser serializada.
Todos os novos tipos de thunk precisam ser serializáveis, ou seja, GpuCompiler ou CpuCompiler precisam ser capazes de compilar e serializar o programa para que, mais tarde, o executor de XLA possa carregar e executar o programa. Isso significa que não pode haver ponteiros para HloInstruction ou para outras partes do compilador ou do StreamExecutor.
Padrões de código
Estilo de programação: seguimos o guia de estilo de código do Google. Consulte especificamente os guias C/C++ e Python. Todo o código enviado precisa estar em conformidade com esses guias de estilo.
Mudanças compactas: seguimos as práticas de engenharia do Google. Em especial, consulte o guia sobre como escrever mudanças compactas. Isso aumenta muito a velocidade com que seu código pode ser mesclado devido à melhoria da capacidade de revisão e à redução da probabilidade de efeitos colaterais não intencionais da mudança. Mesmo que você tenha uma mudança grande, há muitas estratégias para dividi-la em mudanças mais incrementais.
Cobertura de teste: todas as mudanças precisam incluir testes de unidade adequados. Os testes de unidade não podem depender de tempos específicos de hardware (CPU, GPU etc.) e precisam usar mocks e fakes para criar testes determinísticos e focados. As mudanças que buscam estender o código atual que é difícil de testar precisam fazer melhorias adequadas na capacidade de teste.
Todas as mudanças precisam incluir resultados de comparativo de mercado relevantes no título para garantir que os benefícios sejam claramente compreendidos.
Em caso de dúvida sobre as convenções no código, é sempre bom examinar o código pré-existente e tentar seguir os padrões já estabelecidos no OpenXLA.
Processo de revisão
Todos os envios, incluindo os feitos por membros do projeto, precisam ser revisados. Usamos solicitações de envio do GitHub para isso. Consulte a Ajuda do GitHub para mais informações sobre como usar solicitações de envio.
O código precisa seguir todos os padrões listados acima antes da revisão. Essas etapas não são opcionais, e é fundamental que o usuário que enviou o código garanta a conformidade antes de solicitar a revisão para garantir a aceitação das mudanças no prazo.
Todos os testes precisam ser aprovados. Se você descobrir que um teste está com falha e o problema não está relacionado ao ambiente de build ou às suas mudanças, entre em contato com os mantenedores.
Tente evitar o aumento do escopo durante o processo de revisão. Essa é a responsabilidade do usuário que envia e do revisor. Se uma mudança começar a ficar muito grande, divida-a em várias mudanças.
Antes de uma mudança ser incorporada, ela passa por testes internos que usam código interno do Google e de outros fornecedores de hardware. Isso pode adicionar etapas extras ao processo de revisão se houver falhas em testes internos que nossa CI pública não detecta. O funcionário do Google que estiver analisando sua mudança vai comunicar qualquer falha no teste interno e descrever o que precisa ser corrigido.
Perguntas frequentes
"Essa mudança na infraestrutura não está relacionada ao meu PR. Por que eu deveria fazer isso?"
A equipe de XLA não tem uma equipe de infraestrutura dedicada. Portanto, cabe a todos nós criar bibliotecas auxiliares e evitar dívidas técnicas. Consideramos isso uma parte regular das mudanças no XLA, e todos precisam participar. Geralmente, criamos a infraestrutura conforme necessário ao escrever o código.
Os revisores de XLA podem pedir que você crie alguma infraestrutura (ou faça uma grande mudança em uma solicitação de pull) junto com uma solicitação de pull que você escreveu. Essa solicitação pode parecer desnecessária ou ortogonal à mudança que você está tentando fazer. Isso provavelmente ocorre devido a uma incompatibilidade entre suas expectativas sobre a quantidade de infraestrutura necessária para criar e as expectativas do revisor para o mesmo.
Não tem problema se as expectativas não forem iguais. Isso é esperado quando você é novo em um projeto (e às vezes até acontece com a gente, que já tem experiência). É provável que os projetos em que você trabalhou no passado tenham expectativas diferentes. Isso também é normal e esperado. Isso não significa que um deles esteja errado, apenas que são diferentes. Aproveite os pedidos de infraestrutura e todos os outros comentários de revisão para aprender o que esperamos neste projeto.
"Posso abordar seu comentário em uma futura RP?"
Uma dúvida frequente em relação a solicitações de infraestrutura (ou outras solicitações grandes) em PRs é se a mudança precisa ser feita no PR original ou se pode ser feita como um acompanhamento em um PR futuro.
Em geral, o XLA não permite que os autores de PRs respondam aos comentários de revisão com um PR de acompanhamento. Quando um revisor decide que algo precisa ser abordado em uma determinada solicitação de pull (PR, na sigla em inglês), geralmente esperamos que os autores façam isso na PR, mesmo que o que foi solicitado seja uma grande mudança. Esse padrão se aplica externamente e também internamente no Google.
Há alguns motivos para a XLA usar essa abordagem.
Confiança:ter conquistado a confiança do avaliador é um componente essencial. Em um projeto de código aberto, os colaboradores podem aparecer ou desaparecer quando quiserem. Depois que aprovamos uma solicitação de pull, os revisores não têm como garantir que os acompanhamentos prometidos sejam feitos.
Impacto em outros desenvolvedores:se você enviou uma solicitação de pull (PR, na sigla em inglês) que afeta uma parte específica do XLA, é provável que outras pessoas estejam analisando a mesma parte. Se aceitarmos o débito técnico no seu PR, todos que estiverem analisando esse arquivo serão afetados por ele até que o acompanhamento seja enviado.
Capacidade dos revisores:adiar uma mudança para um acompanhamento impõe vários custos aos nossos revisores, que já estão sobrecarregados. Os revisores provavelmente vão esquecer o assunto do primeiro PR enquanto esperam o acompanhamento, o que dificulta a próxima revisão. Além disso, os revisores precisam acompanhar os acompanhamentos esperados para garantir que eles realmente aconteçam. Se a mudança puder ser feita de forma que seja realmente ortogonal ao PR original, para que outro revisor possa analisá-la, a largura de banda será menos problemática. Na nossa experiência, isso raramente acontece.