
Todos pueden contribuir a OpenXLA, y valoramos las contribuciones de todos. Existen varias formas de contribuir, incluidas las siguientes:
Responder preguntas en los foros de debate de OpenXLA (openxla-discuss)
Mejorar o ampliar la documentación de OpenXLA
Cómo contribuir a la base de código de OpenXLA
Contribuir de cualquiera de las formas anteriores al ecosistema más amplio de bibliotecas compiladas en OpenXLA
El proyecto de OpenXLA sigue los Lineamientos de la comunidad de código abierto de Google.
Antes de comenzar
Firma el Contrato de Licencia para Colaboradores
Las contribuciones a este proyecto deben estar acompañadas de un Contributor License Agreement (CLA). Tú (o tu empleador) conservan los derechos de autor de tu contribución. Esto simplemente nos otorga permiso para usar y redistribuir tus contribuciones como parte del proyecto.
Si tú o tu empleador actual ya firmaron el CLA de Google (incluso si fue para un proyecto diferente), probablemente no sea necesario que lo vuelvan a hacer.
Visita <https://cla.developers.google.com/> para ver tus acuerdos actuales o firmar uno nuevo.
Revisa el Código de Conducta
Este proyecto sigue el Código de conducta de TensorFlow.
Proceso de contribución
Guía para desarrolladores
Si deseas obtener una guía para configurar un entorno de desarrollo para OpenXLA, que incluye cómo obtener el código, compilarlo, ejecutar pruebas y enviar cambios, consulta la Guía para desarrolladores.
Guía de contribuciones
La arquitectura del compilador consta de los siguientes componentes.
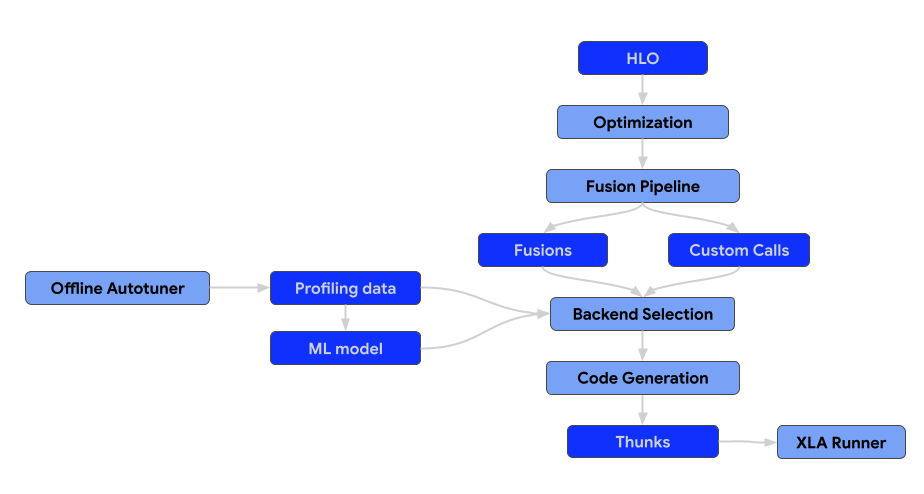
Pases de optimización
Los pases de optimización ejecutan transformaciones en el HLO para mejorar la eficiencia computacional. Estas transformaciones abarcan desde mejoras de alto nivel independientes de la arquitectura hasta ajustes específicos del hardware (p.ej., para GPUs de NVIDIA).
Qué aceptamos generalmente:
- Pases que se generalizan en múltiples cargas de trabajo y demuestran un impacto positivo claro y significativo en las comparativas de rendimiento.
Por lo general, rechazamos lo siguiente:
- Son pases que realizan optimizaciones únicas dirigidas a modelos específicos.
Pases de fusión
La fusión es una optimización crítica que combina varias operaciones de HLO en un solo kernel para reducir la sobrecarga de E/S de memoria y de inicio del kernel.
Todos los pases de fusión se deben agregar solo a la canalización de fusión, no antes ni después. Esto también significa que el módulo de HLO preoptimizado no debe contener instrucciones de fusión. Si la fusión se forma al principio de la canalización, se convierte en una barrera para los pases de optimización. Si la fusión se forma tarde, perdemos la capacidad de seleccionar y ajustar el backend para la fusión generada.
No se permite la fusión en las llamadas personalizadas, es decir, la correlación de patrones de llamadas personalizadas con los productores o consumidores y la reescritura en las nuevas llamadas personalizadas. En ese caso, se debe reemplazar por un pase de fusión adecuado.
Escalamiento horizontal
Las contribuciones al escalamiento horizontal abarcan optimizaciones de HLO, mejoras en el modelo de costos, actualizaciones de bibliotecas y varias modificaciones en la infraestructura. Debido a la dificultad para reproducir las mejoras en el rendimiento y la necesidad limitada de las configuraciones de varios hosts de forma interna, nos adherimos a criterios de aceptación estrictos:
Priorizamos los cambios mínimamente invasivos que conllevan un riesgo bajo.
Qué aceptamos generalmente:
Se actualizaron las bibliotecas que controlan la comunicación entre GPU o entre hosts.
Se actualizaron las tablas de rendimiento para las plataformas nuevas.
Por lo general, rechazamos lo siguiente:
Son reescrituras de HLO o cambios en el tiempo de ejecución adaptados a un modelo específico.
Cambios en la infraestructura que introducen marcas nuevas, deuda técnica o regresiones
Backends y ajuste automático
Los backends para las operaciones no anidadas, como las llamadas y las fusiones personalizadas, deben implementar la interfaz CodegenBackend.
Esta interfaz es necesaria para habilitar la selección óptima del backend, ya que proporciona los métodos para incluir los parámetros de las instrucciones de HLO determinadas en el espacio de búsqueda del autotuner.
// Returns all supported configs for the given HLO instruction.
virtual absl::StatusOr<std::vector<std::unique_ptr<BackendConfig>>>
GetSupportedConfigs(const HloInstruction& instr);
// Returns a default config for the given HLO instruction.
virtual absl::StatusOr<std::unique_ptr<BackendConfig>> GetDefaultConfig(
const HloInstruction& instr);
Entorno de ejecución
El resultado final de la canalización de compilación de XLA es una secuencia de thunks que se puede serializar.
Todos los tipos de thunk nuevos deben ser serializables, es decir, GpuCompiler o CpuCompiler deben poder compilar el programa y serializarlo para que, más adelante, el ejecutor de XLA pueda cargarlo y ejecutarlo. Esto significa que no debe haber punteros a HloInstruction ni a otras partes del compilador o de StreamExecutor.
Estándares de código
Estilo de programación: Seguimos la guía de estilo de código de Google. Consulta específicamente las guías de C/C++ y Python. Todo el código enviado debe cumplir estrictamente con estas guías de estilo.
Cambios compactos: Seguimos las prácticas de ingeniería de Google. En particular, consulta la guía para escribir cambios compactos. Si lo haces, aumentarás considerablemente la velocidad con la que se puede combinar tu código debido a la mejora de la capacidad de revisión y a la reducción de la probabilidad de efectos secundarios no intencionales del cambio. Incluso si tienes un cambio grande, existen muchas estrategias para dividirlo en cambios más incrementales.
Cobertura de pruebas: Todos los cambios deben incluir pruebas de unidades adecuadas. Las pruebas de unidades no deben depender de los tiempos de hardware específicos (CPU, GPU, etcétera) y deben usar de forma liberal simulaciones y falsificaciones para realizar pruebas determinísticas y enfocadas. Los cambios que buscan extender el código existente que actualmente es difícil de probar deben realizar las mejoras adecuadas en la capacidad de prueba.
Todos los cambios deben incluir los resultados de las comparativas adecuadas en el título del cambio para garantizar que se comprendan claramente los beneficios.
Cuando tengas dudas sobre las convenciones dentro del código, siempre es una buena idea examinar el código preexistente y tratar de seguir los patrones ya establecidos en OpenXLA.
Proceso de revisión
Todos los envíos, incluidos los de los miembros del proyecto, requieren revisión. Para ello, usamos solicitudes de extracción de GitHub. Consulta la Ayuda de GitHub para obtener más información sobre el uso de las solicitudes de extracción.
Antes de la revisión, el código debe cumplir con todos los estándares mencionados anteriormente. Estos no son opcionales, y es fundamental que el remitente se asegure de que su código cumpla con los requisitos antes de solicitar la revisión para garantizar la aceptación oportuna de los cambios.
Todas las pruebas deben aprobarse. Si detectas que una prueba no funciona y el problema no se relaciona con tu entorno de compilación ni con tus cambios, comunícate con los mantenedores.
Intenta evitar la expansión del alcance durante el proceso de revisión. Esto es responsabilidad tanto del usuario que envía la solicitud como del revisor. Si un cambio comienza a ser demasiado grande, considera dividirlo en varios cambios.
Antes de que se combine un cambio, se someterá a pruebas internas que utilizan código interno de Google y otros proveedores de hardware. Esto puede agregar pasos adicionales al proceso de revisión si hay fallas en las pruebas internas que nuestra CI pública no detecta. El Googler que revise tu cambio te comunicará cualquier falla en las pruebas internas y te describirá lo que debes corregir.
Preguntas frecuentes
"Este cambio en la infraestructura no está relacionado con mi PR. ¿Por qué debería hacerlo?"
El equipo de XLA no tiene un equipo de infraestructura dedicado, por lo que todos debemos crear bibliotecas de ayuda y evitar la deuda técnica. Lo consideramos una parte habitual de los cambios en XLA, y se espera que todos participen. Por lo general, creamos la infraestructura según sea necesario cuando escribimos código.
Es posible que los revisores de XLA te pidan que compiles cierta infraestructura (o que realices algún otro cambio importante en una PR) junto con una PR que hayas escrito. Esta solicitud puede parecer innecesaria o no relacionada con el cambio que intentas realizar. Es probable que se deba a una discrepancia entre tus expectativas sobre la cantidad de infraestructura que necesitas compilar y las expectativas del revisor al respecto.
No hay problema si no coinciden las expectativas. Esto es normal cuando eres nuevo en un proyecto (y, a veces, incluso nos sucede a los veteranos). Es probable que los proyectos en los que trabajaste en el pasado tengan diferentes expectativas. Eso también está bien y es de esperar. Esto no significa que alguno de estos proyectos tenga el enfoque incorrecto, sino que son diferentes. Te invitamos a que consideres las solicitudes de infraestructura junto con todos los demás comentarios de revisión como una oportunidad para aprender lo que esperamos de este proyecto.
"¿Puedo abordar tu comentario en una futura RP?"
Una pregunta frecuente con respecto a las solicitudes de infraestructura (o cualquier otra solicitud grande) en las PR es si el cambio se debe realizar en la PR original o si se puede hacer como seguimiento en una PR futura.
En general, XLA no permite que los autores de la PR aborden los comentarios de la revisión con una PR de seguimiento. Cuando un revisor decide que algo debe abordarse en una PR determinada, generalmente esperamos que los autores lo aborden en esa PR, incluso si lo que se solicita es un cambio grande. Este estándar se aplica de forma externa y también interna dentro de Google.
Existen varios motivos por los que XLA adopta este enfoque.
Confianza: Haberse ganado la confianza del revisor es un componente clave. En un proyecto de código abierto, los colaboradores pueden aparecer o desaparecer a voluntad. Después de que aprobamos una PR, los revisores no tienen forma de asegurarse de que se realicen los seguimientos prometidos.
Impacto en otros desarrolladores: Si enviaste una solicitud de extracción que afecta una parte específica de XLA, es muy probable que otras personas estén mirando la misma parte. Si aceptamos la deuda técnica en tu PR, todos los que vean este archivo se verán afectados por esta deuda hasta que se envíe el seguimiento.
Capacidad de los revisores: Aplazar un cambio para un seguimiento impone varios costos a nuestros revisores, que ya están sobrecargados. Es probable que los revisores olviden de qué se trataba la primera PR mientras esperan la siguiente, lo que dificultará la próxima revisión. Además, los revisores deberán hacer un seguimiento de las acciones posteriores esperadas y asegurarse de que se lleven a cabo. Si el cambio se puede realizar de manera que sea verdaderamente ortogonal a la PR original, de modo que otro revisor pueda revisarlo, el ancho de banda sería un problema menor. Según nuestra experiencia, esto rara vez sucede.