
Jeder kann zu OpenXLA beitragen und wir schätzen die Beiträge aller. Es gibt verschiedene Möglichkeiten, Beiträge zu leisten:
Fragen in den OpenXLA-Diskussionsforen (openxla-discuss) beantworten
Dokumentation zu OpenXLA verbessern oder erweitern
Beiträge zur OpenXLA-Codebasis leisten
Beiträge in einer der oben genannten Formen zum breiteren Ökosystem von Bibliotheken, die auf OpenXLA basieren
Das OpenXLA-Projekt folgt den Open-Source-Community-Richtlinien von Google.
Hinweis
Unterzeichnen Sie die Contributor License Agreement.
Beiträge zu diesem Projekt müssen mit einer Lizenzvereinbarung für Beitragende (Contributor License Agreement, CLA) einhergehen. Sie (oder Ihr Arbeitgeber) behalten das Urheberrecht an Ihrem Beitrag. Wir erhalten lediglich die Erlaubnis, Ihre Beiträge im Rahmen des Projekts zu verwenden und weiterzugeben.
Wenn Sie oder Ihr aktueller Arbeitgeber die Google CLA bereits unterzeichnet haben (auch wenn es für ein anderes Projekt war), müssen Sie dies wahrscheinlich nicht noch einmal tun.
Unter <https://cla.developers.google.com/> können Sie Ihre aktuellen Vereinbarungen einsehen oder eine neue unterzeichnen.
Verhaltenskodex lesen
Dieses Projekt folgt dem Verhaltenskodex von TensorFlow.
Beitragsprozess
Entwicklerleitfaden
Eine Anleitung zum Einrichten einer Entwicklungsumgebung für OpenXLA, einschließlich des Abrufens von Code, des Erstellens, des Ausführens von Tests und des Einreichens von Änderungen, finden Sie im Entwicklerleitfaden.
Leitfaden für Beiträge
Die Architektur des Compilers besteht aus den folgenden Komponenten.
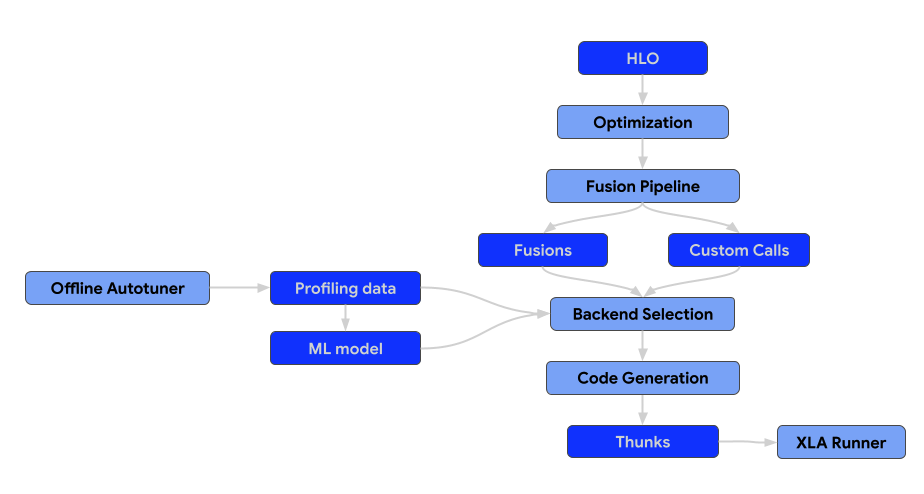
Optimierungsdurchläufe
Bei Optimierungsdurchläufen werden Transformationen auf den HLO angewendet, um die Recheneffizienz zu steigern. Diese Transformationen reichen von architekturunabhängigen Verbesserungen auf hoher Ebene bis hin zu hardwarespezifischen Anpassungen (z.B. für NVIDIA-GPUs).
Was wir in der Regel akzeptieren:
- Optimierungen, die für mehrere Arbeitslasten gelten und einen deutlichen und signifikanten positiven Einfluss auf Leistungsbenchmarks haben.
Was wir in der Regel ablehnen:
- Passes, die einzigartige Optimierungen für bestimmte Modelle durchführen.
Fusion-Karten/Tickets
Die Fusion ist eine wichtige Optimierung, bei der mehrere HLO-Vorgänge in einem einzelnen Kernel kombiniert werden, um den Speicher-E/A- und Kernel-Startaufwand zu reduzieren.
Alle Fusion-Durchläufe sollten nur der Fusion-Pipeline hinzugefügt werden, nicht davor oder danach. Das bedeutet auch, dass das voroptimierte HLO-Modul keine Fusionsanweisungen enthalten sollte. Wenn die Zusammenführung früh in der Pipeline erfolgt, wird sie zu einer Barriere für die Optimierungsdurchläufe. Wenn die Fusion erst spät erfolgt, können wir das Backend für die generierte Fusion nicht mehr auswählen und optimieren.
Das Zusammenführen in die benutzerdefinierten Aufrufe, d.h. das Musterabgleichen benutzerdefinierter Aufrufe mit den Produzenten/Konsumenten und das Umschreiben in die neuen benutzerdefinierten Aufrufe, ist nicht zulässig. In diesem Fall sollte er durch einen geeigneten Fusionsdurchlauf ersetzt werden.
Horizontale Skalierung
Zu den Beiträgen zur horizontalen Skalierung gehören HLO-Optimierungen, Verbesserungen des Kostenmodells, Bibliotheksupdates und verschiedene Infrastrukturänderungen. Da es schwierig ist, die Leistungssteigerungen zu reproduzieren, und der Bedarf an den Multi-Host-Konfigurationen intern begrenzt ist, halten wir uns an strenge Akzeptanzkriterien:
Wir bevorzugen minimalinvasive Änderungen, die ein geringes Risiko bergen.
Was wir in der Regel akzeptieren:
Bibliotheken für die Kommunikation zwischen GPUs oder Hosts wurden aktualisiert.
Aktualisierungen der Leistungstabelle für neue Plattformen.
Was wir in der Regel ablehnen:
HLO-Umschreibungen oder Laufzeitänderungen, die auf ein bestimmtes Modell zugeschnitten sind.
Infrastrukturänderungen, die neue Flags, technische Schulden oder Regressionen einführen.
Back-Ends und automatische Abstimmung
Back-Ends für die nicht verschachtelten Vorgänge, z.B. benutzerdefinierte Aufrufe und Fusions, sollten die CodegenBackend-Schnittstelle implementieren.
Diese Schnittstelle ist für die optimale Backend-Auswahl erforderlich, da sie die Methoden zum Einbeziehen der Parameter für die angegebenen HLO-Anweisungen in den Suchbereich des Autotuners bereitstellt.
// Returns all supported configs for the given HLO instruction.
virtual absl::StatusOr<std::vector<std::unique_ptr<BackendConfig>>>
GetSupportedConfigs(const HloInstruction& instr);
// Returns a default config for the given HLO instruction.
virtual absl::StatusOr<std::unique_ptr<BackendConfig>> GetDefaultConfig(
const HloInstruction& instr);
Laufzeit
Das Endergebnis der XLA-Kompilierungspipeline ist eine Thunk-Sequenz, die serialisiert werden kann.
Alle neuen Thunk-Typen sollten serialisierbar sein, d.h. GpuCompiler oder CpuCompiler sollten das Programm kompilieren und serialisieren können, damit der XLA-Runner das Programm später laden und ausführen kann. Das bedeutet, dass es keine Verweise auf HloInstruction oder andere Teile des Compilers oder der StreamExecutor geben sollte.
Code standards
Programmierstil: Wir folgen dem Google-Leitfaden für den Programmierstil. Weitere Informationen finden Sie in den Anleitungen für C/C++ und Python. Der gesamte eingereichte Code muss diesen Styleguides entsprechen.
Kompakte Änderungen: Wir halten uns an die Engineering-Praktiken von Google. Beachten Sie insbesondere die Anleitung zum Schreiben kompakter Änderungen. Dadurch wird die Geschwindigkeit, mit der Ihr Code zusammengeführt werden kann, erheblich erhöht, da die Überprüfbarkeit verbessert wird und die Wahrscheinlichkeit unbeabsichtigter Nebenwirkungen von Änderungen sinkt. Auch wenn Sie eine große Änderung vornehmen möchten, gibt es viele Strategien, um sie in kleinere, schrittweise Änderungen aufzuteilen.
Testabdeckung: Alle Änderungen sollten geeignete Unittests enthalten. Unittests sollten nicht von bestimmten Hardware-Timings (CPU, GPU usw.) abhängig sein und sollten großzügig Mocks und Fakes verwenden, um deterministische und fokussierte Tests zu ermöglichen. Bei Änderungen, die darauf abzielen, vorhandenen Code zu erweitern, der derzeit schwer zu testen ist, sollten entsprechende Verbesserungen an der Testbarkeit vorgenommen werden.
Alle Änderungen sollten auch entsprechende Benchmark-Ergebnisse im Änderungstitel enthalten, damit die Vorteile klar ersichtlich sind.
Wenn Sie sich bezüglich der Konventionen im Code nicht sicher sind, sollten Sie immer vorhandenen Code untersuchen und versuchen, die in OpenXLA bereits vorhandenen Muster zu befolgen.
Überprüfungsprozess
Alle Beiträge, auch die von Projektmitgliedern, müssen überprüft werden. Dazu verwenden wir GitHub-Pull-Anfragen. Weitere Informationen zur Verwendung von Pull-Anfragen finden Sie in der GitHub-Hilfe.
Der Code muss vor der Überprüfung allen oben aufgeführten Standards entsprechen. Diese sind nicht optional und es ist wichtig, dass der Einreicher dafür sorgt, dass sein Code den Anforderungen entspricht, bevor er eine Überprüfung anfordert, damit Änderungen rechtzeitig akzeptiert werden.
Alle Tests müssen bestanden werden. Wenn Sie feststellen, dass ein Test fehlerhaft ist und das Problem nicht mit Ihrer Build-Umgebung oder Ihren Änderungen zusammenhängt, wenden Sie sich bitte an die Verantwortlichen.
Versuchen Sie, während des Überprüfungsprozesses eine Ausweitung des Umfangs zu vermeiden. Das liegt in der Verantwortung des Einreichers und des Prüfers. Wenn eine Änderung zu groß wird, sollten Sie sie in mehrere Änderungen aufteilen.
Bevor eine Änderung zusammengeführt wird, wird sie intern mit Code getestet, der Google und anderen Hardwareanbietern gehört. Dadurch können zusätzliche Schritte im Überprüfungsprozess erforderlich werden, wenn bei internen Tests Fehler auftreten, die von unserem öffentlichen CI nicht erkannt werden. Der Google-Mitarbeiter, der Ihre Änderung prüft, teilt Ihnen alle internen Testfehler mit und beschreibt, was behoben werden muss.
FAQ
„Diese Infrastrukturänderung hat nichts mit meinem PR zu tun. Warum sollte ich das tun?“
Das XLA-Team hat kein eigenes Infrastrukturteam. Daher müssen wir alle Hilfsbibliotheken erstellen und technische Schulden vermeiden. Wir betrachten sie als regulären Bestandteil der Änderungen an XLA und erwarten, dass alle teilnehmen. Wir erstellen Infrastruktur in der Regel nach Bedarf, wenn wir Code schreiben.
XLA-Prüfer können Sie bitten, neben einem von Ihnen geschriebenen PR auch eine Infrastruktur zu erstellen oder eine größere Änderung an einem PR vorzunehmen. Diese Anfrage mag unnötig oder orthogonal zu der Änderung erscheinen, die Sie vornehmen möchten. Das liegt wahrscheinlich daran, dass Ihre Erwartungen hinsichtlich des Umfangs der erforderlichen Infrastruktur nicht mit denen des Prüfers übereinstimmen.
Es ist in Ordnung, wenn die Erwartungen nicht übereinstimmen. Das ist normal, wenn Sie neu in einem Projekt sind (und passiert uns alten Hasen manchmal auch). Bei Projekten, an denen Sie in der Vergangenheit gearbeitet haben, gab es wahrscheinlich andere Erwartungen. Das ist auch in Ordnung und zu erwarten. Das bedeutet nicht, dass eines dieser Projekte den falschen Ansatz verfolgt. Sie sind einfach unterschiedlich. Wir empfehlen Ihnen, Infrastrukturanfragen und alle anderen Überprüfungskommentare als Gelegenheit zu nutzen, um zu erfahren, was wir von diesem Projekt erwarten.
„Kann ich auf deinen Kommentar in einem zukünftigen PR eingehen?“
Eine häufige Frage in Bezug auf Infrastrukturanfragen (oder andere umfangreiche Anfragen) in PRs ist, ob die Änderung im ursprünglichen PR vorgenommen werden muss oder ob sie als Follow-up in einem zukünftigen PR erfolgen kann.
Im Allgemeinen ist es bei XLA nicht zulässig, auf Überprüfungskommentare mit einem Follow-up-PR zu reagieren. Wenn ein Prüfer entscheidet, dass in einem bestimmten PR etwas behoben werden muss, erwarten wir in der Regel, dass die Autoren dies in diesem PR tun, auch wenn die gewünschte Änderung umfangreich ist. Dieser Standard gilt sowohl extern als auch intern bei Google.
Dafür gibt es mehrere Gründe.
Vertrauen:Sie müssen das Vertrauen des Rezensenten gewonnen haben. In einem Open-Source-Projekt können Mitwirkende nach Belieben erscheinen oder verschwinden. Nachdem wir einen PR genehmigt haben, können Prüfer nicht mehr dafür sorgen, dass versprochene Nacharbeiten tatsächlich erledigt werden.
Auswirkungen auf andere Entwickler:Wenn Sie einen PR für einen bestimmten Teil von XLA gesendet haben, sehen sich wahrscheinlich auch andere Personen diesen Teil an. Wenn wir technische Schulden in deinem PR akzeptieren, sind alle, die sich diese Datei ansehen, davon betroffen, bis der Follow-up-PR eingereicht wird.
Bandbreite der Prüfer:Wenn eine Änderung auf einen Follow-up-Vorgang verschoben wird, entstehen für unsere bereits überlasteten Prüfer mehrere Kosten. Prüfer vergessen wahrscheinlich, worum es im ersten PR ging, während sie auf die Fortsetzung warten, was die nächste Überprüfung erschwert. Außerdem müssen sie den Überblick über erwartete Follow-ups behalten und dafür sorgen, dass diese auch tatsächlich erfolgen. Wenn die Änderung so vorgenommen werden kann, dass sie wirklich orthogonal zum ursprünglichen PR ist, sodass ein anderer Prüfer sie überprüfen kann, wäre die Bandbreite weniger ein Problem. Unserer Erfahrung nach ist das selten der Fall.