
Tutti possono contribuire a OpenXLA e apprezziamo il contributo di tutti. Esistono diversi modi per contribuire, tra cui:
Rispondere alle domande nei forum di discussione di OpenXLA (openxla-discuss)
Migliorare o ampliare la documentazione di OpenXLA
Contribuire al codebase di OpenXLA
Contribuire in uno dei modi sopra descritti all'ecosistema più ampio di librerie basate su OpenXLA
Il progetto OpenXLA segue le linee guida per la community open source di Google.
Prima di iniziare
Firma il Contributor License Agreement
I contributi a questo progetto devono essere accompagnati da un Contratto di licenza per i collaboratori (CLA). Tu (o il tuo datore di lavoro) mantieni il copyright del tuo contributo; questo ci dà semplicemente il permesso di utilizzare e ridistribuire i tuoi contributi nell'ambito del progetto.
Se tu o il tuo attuale datore di lavoro avete già firmato il contratto CLA di Google (anche se per un altro progetto), probabilmente non dovrai farlo di nuovo.
Visita la pagina <https://cla.developers.google.com/> per visualizzare i tuoi contratti attuali o per firmarne uno nuovo.
Rivedi il Codice di condotta
Questo progetto segue il codice di condotta di TensorFlow.
Procedura di contributo
Guida per gli sviluppatori
Per una guida su come configurare un ambiente di sviluppo per OpenXLA, inclusi l'ottenimento del codice, la sua compilazione, l'esecuzione di test e l'invio di modifiche, consulta la guida per gli sviluppatori.
Guida ai contributi
L'architettura del compilatore è costituita dai seguenti componenti.
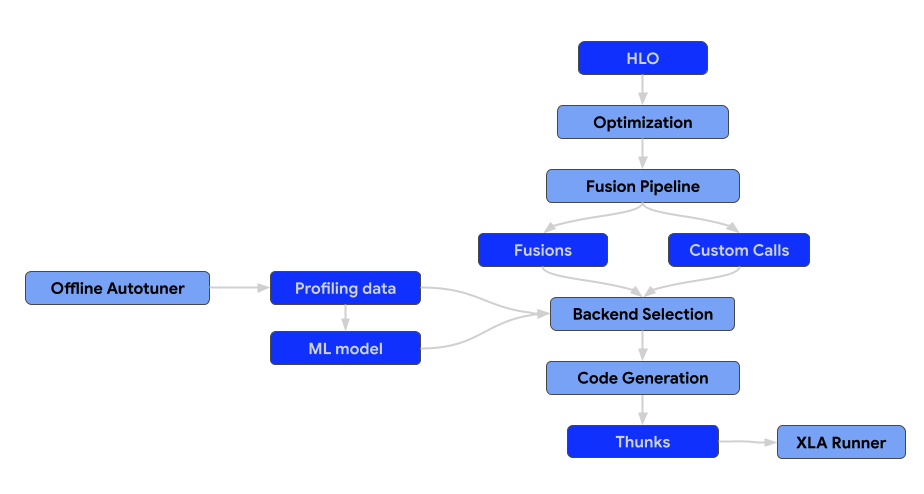
Passaggi di ottimizzazione
Le pass di ottimizzazione eseguono trasformazioni sull'HLO per migliorare l'efficienza computazionale. Queste trasformazioni vanno da miglioramenti di alto livello indipendenti dall'architettura ad aggiustamenti specifici dell'hardware (ad es. per le GPU NVIDIA).
Cosa accettiamo in genere:
- Test che vengono generalizzati in più carichi di lavoro e dimostrano un impatto positivo chiaro e significativo sui benchmark delle prestazioni.
Cosa rifiutiamo in genere:
- Passaggi che eseguono ottimizzazioni uniche per modelli specifici.
Tessere fusion
La fusione è un'ottimizzazione fondamentale che combina più operazioni HLO in un unico kernel per ridurre l'I/O della memoria e l'overhead di avvio del kernel.
Tutti i pass di fusione devono essere aggiunti solo alla pipeline di fusione, non prima o dopo. Ciò significa anche che il modulo HLO pre-ottimizzato non deve contenere istruzioni di fusione. Se la fusione viene eseguita all'inizio della pipeline, diventa un ostacolo per le passate di ottimizzazione. Se la fusione viene formata in ritardo, perdiamo la possibilità di selezionare e ottimizzare il backend per la fusione generata.
L'unione nelle chiamate personalizzate, ovvero le chiamate personalizzate con corrispondenza di pattern con i produttori/consumatori e la loro riscrittura nelle nuove chiamate personalizzate non è consentita. In questo caso, deve essere sostituito con un pass di fusione appropriato.
Scalabilità orizzontale
I contributi allo scaling orizzontale comprendono ottimizzazioni HLO, miglioramenti del modello di costi, aggiornamenti delle librerie e varie modifiche all'infrastruttura. A causa della difficoltà di riprodurre i miglioramenti delle prestazioni e della necessità limitata di configurazioni multi-host internamente, rispettiamo criteri di accettazione rigorosi:
Diamo la priorità alle modifiche minimamente invasive e a basso rischio.
Cosa accettiamo in genere:
Aggiornamenti alle librerie che gestiscono la comunicazione tra GPU o tra host.
Aggiornamenti della tabella del rendimento per le nuove piattaforme.
Cosa rifiutiamo in genere:
Riscritture HLO o modifiche di runtime personalizzate per un modello specifico.
Modifiche all'infrastruttura che introducono nuovi flag, debito tecnico o regressioni.
Backend e ottimizzazione automatica
I backend per le operazioni non nidificate, ad esempio chiamate e fusioni personalizzate, devono implementare l'interfaccia CodegenBackend.
Questa interfaccia è necessaria per consentire la selezione ottimale del backend, perché fornisce i metodi per includere i parametri per le istruzioni HLO specificate nello spazio di ricerca dell'ottimizzatore automatico.
// Returns all supported configs for the given HLO instruction.
virtual absl::StatusOr<std::vector<std::unique_ptr<BackendConfig>>>
GetSupportedConfigs(const HloInstruction& instr);
// Returns a default config for the given HLO instruction.
virtual absl::StatusOr<std::unique_ptr<BackendConfig>> GetDefaultConfig(
const HloInstruction& instr);
Runtime
Il risultato finale della pipeline di compilazione XLA è una sequenza di thunk che può essere serializzata.
Tutti i nuovi tipi di thunk devono essere serializzabili, ovvero GpuCompiler o
CpuCompiler devono essere in grado di compilare il programma, serializzarlo, in modo che in un secondo momento
il runner XLA possa caricare ed eseguire il programma. Ciò significa che non devono
essere presenti puntatori a HloInstruction o ad altre parti del compilatore o di
StreamExecutor.
Standard di codifica
Stile di programmazione: seguiamo la guida allo stile del codice di Google. Consulta in particolare le guide C/C++ e Python. Tutto il codice inviato deve essere strettamente conforme a queste guide di stile.
Modifiche compatte: seguiamo le pratiche di ingegneria di Google. In particolare, segui la guida alla scrittura di modifiche compatte. In questo modo, la velocità di unione del codice aumenterà notevolmente grazie al miglioramento della revisione e alla riduzione della probabilità di effetti collaterali involontari della modifica. Anche se hai una modifica di grandi dimensioni, esistono molte strategie per suddividerla in modifiche più incrementali.
Copertura dei test: tutte le modifiche devono includere test delle unità appropriati. I test delle unità non devono dipendere da tempistiche hardware specifiche (CPU, GPU e così via) e devono fare un uso generoso di simulazioni e dati fittizi per eseguire test deterministici e mirati. Le modifiche che mirano a estendere il codice esistente che attualmente è difficile da testare devono apportare i miglioramenti appropriati alla testabilità.
Tutte le modifiche devono includere anche risultati di benchmark appropriati nel titolo della modifica per garantire che i vantaggi siano chiaramente compresi.
In caso di dubbi sulle convenzioni all'interno del codice, è sempre una buona idea esaminare il codice preesistente e cercare di seguire i pattern già in uso in OpenXLA.
Procedura di revisione
Tutti i contenuti inviati, inclusi quelli dei membri del progetto, richiedono una revisione. A questo scopo, utilizziamo le richieste di pull di GitHub. Consulta la Guida di GitHub per maggiori informazioni sull'utilizzo delle richieste di pull.
Prima della revisione, il codice deve rispettare tutti gli standard elencati sopra. Questi campi non sono facoltativi ed è fondamentale che l'autore dell'invio si assicuri che il codice sia conforme prima di richiedere la revisione, per garantire l'accettazione tempestiva delle modifiche.
Tutti i test devono essere superati. Se riscontri che un test non funziona e il problema non è correlato all'ambiente di build o alle tue modifiche, contatta i manutentori.
Cerca di evitare l'espansione dell'ambito durante la procedura di revisione. Questa è la responsabilità sia dell'autore dell'invio sia del revisore. Se una modifica inizia a diventare troppo grande, valuta la possibilità di suddividerla in più modifiche.
Prima di essere unita, una modifica verrà sottoposta a test interni che utilizzano codice interno a Google e ad altri fornitori di hardware. Ciò può potenzialmente aggiungere passaggi aggiuntivi alla procedura di revisione se si verificano errori nei test interni che la nostra integrazione continua pubblica non rileva. La persona di Google che esamina la tua modifica ti comunicherà eventuali errori di test interni e descriverà cosa deve essere corretto.
Domande frequenti
"Questa modifica dell'infrastruttura non è correlata alla mia richiesta di pull. Perché dovrei farlo?"
Il team XLA non ha un team di infrastrutture dedicato, quindi tocca a tutti noi creare librerie di supporto ed evitare il debito tecnico. Lo consideriamo una parte normale delle modifiche all'XLA e ci aspettiamo che tutti partecipino. In genere, creiamo l'infrastruttura necessaria durante la scrittura del codice.
I revisori XLA potrebbero chiederti di creare un'infrastruttura (o apportare una modifica importante a una richiesta di pull) insieme a una richiesta di pull che hai scritto. Questa richiesta potrebbe sembrare inutile o ortogonale alla modifica che stai cercando di apportare. Ciò è probabilmente dovuto a una mancata corrispondenza tra le tue aspettative sulla quantità di infrastruttura da creare e quelle del revisore.
È normale che le aspettative non coincidano. È normale quando non si ha esperienza con un progetto (e a volte capita anche a noi esperti). È probabile che i progetti a cui hai lavorato in passato abbiano aspettative diverse. Va bene anche così, è normale. Ciò non significa che uno di questi progetti abbia l'approccio sbagliato, ma solo che sono diversi. Ti invitiamo a considerare le richieste relative all'infrastruttura insieme a tutti gli altri commenti di revisione come un'opportunità per scoprire cosa ci aspettiamo da questo progetto.
"Posso rispondere al tuo commento in una futura PR?"
Una domanda frequente in merito alle richieste di infrastruttura (o ad altre richieste di grandi dimensioni) nelle PR è se la modifica debba essere apportata nella PR originale o se possa essere eseguita come follow-up in una PR futura.
In generale, XLA non consente agli autori delle richieste di pull di rispondere ai commenti di revisione con una richiesta di pull di follow-up. Quando un revisore decide che qualcosa deve essere risolto in una determinata richiesta pull, in genere ci aspettiamo che gli autori lo facciano in quella richiesta pull, anche se ciò che viene richiesto è una modifica importante. Questo standard si applica esternamente e anche internamente a Google.
XLA adotta questo approccio per diversi motivi.
Fiducia:aver guadagnato la fiducia del revisore è un componente fondamentale. In un progetto open source, i collaboratori possono apparire o scomparire a piacimento. Dopo l'approvazione di una richiesta di pull, i revisori non hanno modo di assicurarsi che gli eventuali follow-up promessi vengano effettivamente eseguiti.
Impatto su altri sviluppatori: se hai inviato una richiesta pull che riguarda una parte specifica di XLA, è molto probabile che altre persone stiano esaminando la stessa parte. Se accettiamo il debito tecnico nella tua richiesta di pull, tutti coloro che esaminano questo file saranno interessati da questo debito fino all'invio del follow-up.
Larghezza di banda dei revisori:il rinvio di una modifica a un follow-up impone più costi ai nostri revisori già sovraccarichi. I revisori probabilmente dimenticheranno di cosa trattava la prima richiesta di pull durante l'attesa del follow-up, rendendo la revisione successiva più difficile. Inoltre, i revisori dovranno tenere traccia dei follow-up previsti, assicurandosi che vengano effettivamente eseguiti. Se la modifica può essere apportata in modo che sia veramente ortogonale alla richiesta pull originale, in modo che un altro revisore possa esaminarla, la larghezza di banda non sarebbe un problema. In base alla nostra esperienza, questo accade raramente.