
Każdy może współtworzyć OpenXLA, a my cenimy wkład wszystkich osób. Możesz to zrobić na kilka sposobów, m.in.:
odpowiadanie na pytania na forach dyskusyjnych OpenXLA (openxla-discuss);
Ulepszanie lub rozszerzanie dokumentacji OpenXLA
Współtworzenie bazy kodu OpenXLA
wspieranie w dowolny z powyższych sposobów szerszego ekosystemu bibliotek opartych na OpenXLA;
Projekt OpenXLA jest zgodny z Wytycznymi Google dla społeczności open source.
Zanim zaczniesz
Podpisz umowę licencyjną dla współtwórców
Współtworzenie tego projektu musi być poprzedzone Umową licencyjną na treści. Ty (lub Twój pracodawca) zachowujesz prawa autorskie do swojego wkładu. Po prostu udzielasz nam zezwolenia na wykorzystywanie i redystrybucję Twoich materiałów w ramach projektu.
Jeśli Ty lub Twój obecny pracodawca podpisaliście już Umowę licencyjną na treści Google (nawet jeśli dotyczyła ona innego projektu), prawdopodobnie nie musisz tego robić ponownie.
Aby wyświetlić obecne umowy lub podpisać nową, wejdź na <https://cla.developers.google.com/>.
Zapoznaj się z Kodeksem postępowania
Ten projekt jest zgodny z kodeksem postępowania TensorFlow.
Proces przekazywania darowizny
Przewodnik dla programistów
Przewodnik po konfigurowaniu środowiska programistycznego dla OpenXLA, w tym pobieraniu kodu, jego kompilowaniu, uruchamianiu testów i przesyłaniu zmian, znajdziesz w Przewodniku dla deweloperów.
Przewodnik dla współtwórców
Architektura kompilatora składa się z tych komponentów:
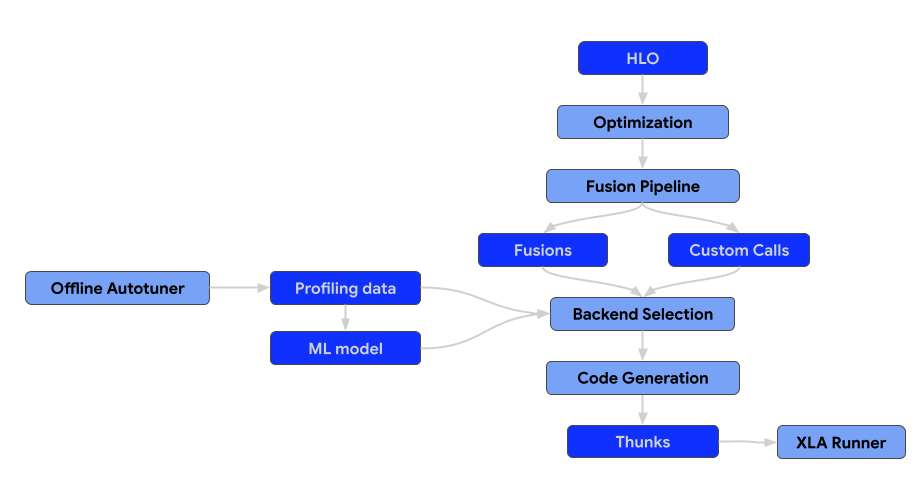
Etapy optymalizacji
Fazy optymalizacji przeprowadzają transformacje na HLO, aby zwiększyć wydajność obliczeniową. Obejmują one zarówno niezależne od architektury ulepszenia wysokiego poziomu, jak i dostosowania do konkretnego sprzętu (np. procesorów graficznych NVIDIA).
Co zwykle akceptujemy:
- Testy, które można uogólnić na wiele rodzajów zadań i które wykazują wyraźny i znaczący pozytywny wpływ na wyniki testów porównawczych.
Czego zazwyczaj nie akceptujemy:
- Przekazuje informacje o unikalnych optymalizacjach kierowanych na konkretne modele.
Karty Fusion
Fuzja to kluczowa optymalizacja, która łączy wiele operacji HLO w jeden kernel, aby zmniejszyć obciążenie wejścia/wyjścia pamięci i narzut związany z uruchamianiem kernela.
Wszystkie przepustki fuzji należy dodawać tylko do potoku fuzji, a nie przed nim ani po nim. Oznacza to również, że wstępnie zoptymalizowany moduł HLO nie powinien zawierać instrukcji scalania. Jeśli fuzja zostanie utworzona na wczesnym etapie potoku, stanie się barierą dla przebiegów optymalizacji. Jeśli fuzja zostanie utworzona późno, nie będziemy mogli wybrać i dostosować backendu do wygenerowanej fuzji.
Łączenie w wywołania niestandardowe, czyli dopasowywanie wywołań niestandardowych do wzorców z producentami/konsumentami i przekształcanie ich w nowe wywołania niestandardowe, jest niedozwolone. W takim przypadku należy go zastąpić odpowiednim karnetem łączonym.
Skalowanie w poziomie
Wkład w skalowanie w poziomie obejmuje optymalizacje HLO, ulepszenia modelu kosztów, aktualizacje bibliotek i różne modyfikacje infrastruktury. Ze względu na trudność w odtworzeniu wzrostu wydajności i ograniczone wewnętrzne zapotrzebowanie na konfiguracje z wieloma hostami stosujemy ścisłe kryteria akceptacji:
Priorytetowo traktujemy zmiany o minimalnym wpływie i niskim ryzyku.
Co zwykle akceptujemy:
Aktualizacje bibliotek obsługujących komunikację między procesorami graficznymi lub hostami.
Aktualizacje tabeli wyników na potrzeby nowych platform.
Czego zazwyczaj nie akceptujemy:
Przepisywanie HLO lub zmiany w czasie działania dostosowane do konkretnego modelu.
zmiany infrastruktury, które wprowadzają nowe flagi, dług techniczny lub regresje;
Backendy i automatyczne dostrajanie
Backendy dla operacji bez zagnieżdżenia, np. wywołań niestandardowych i fuzji, powinny implementować interfejs CodegenBackend.
Ten interfejs jest niezbędny do optymalnego wyboru backendu, ponieważ udostępnia metody włączania parametrów dla danych instrukcji HLO do przestrzeni wyszukiwania automatycznego tunera.
// Returns all supported configs for the given HLO instruction.
virtual absl::StatusOr<std::vector<std::unique_ptr<BackendConfig>>>
GetSupportedConfigs(const HloInstruction& instr);
// Returns a default config for the given HLO instruction.
virtual absl::StatusOr<std::unique_ptr<BackendConfig>> GetDefaultConfig(
const HloInstruction& instr);
Środowisko wykonawcze
Końcowym wynikiem potoku kompilacji XLA jest sekwencja thunków, którą można serializować.
Wszystkie nowe typy thunków powinny być serializowalne, tzn. GpuCompiler lub CpuCompiler powinny umożliwiać skompilowanie programu i jego serializację, aby później moduł wykonawczy XLA mógł go wczytać i wykonać. Oznacza to, że nie powinno być wskaźników do HloInstruction ani do innych części kompilatora lub StreamExecutor.
Standardy kodu
Styl kodowania: stosujemy wytyczne Google dotyczące stylu kodu. Zapoznaj się z przewodnikami dotyczącymi C/C++ i Pythona. Wszystkie przesłane kody muszą być zgodne z tymi przewodnikami po stylu.
Kompaktowe zmiany: postępujemy zgodnie z praktykami inżynieryjnymi Google. Zapoznaj się zwłaszcza z przewodnikiem po pisaniu zwięzłych zmian. Dzięki temu znacznie zwiększysz szybkość scalania kodu, ponieważ poprawisz możliwość jego sprawdzenia i zmniejszysz prawdopodobieństwo niezamierzonych skutków ubocznych zmian. Nawet jeśli chcesz wprowadzić dużą zmianę, możesz ją podzielić na mniejsze, stopniowe zmiany.
Pokrycie testami: wszystkie zmiany powinny obejmować odpowiednie testy jednostkowe. Testy jednostkowe nie powinny zależeć od konkretnych czasów sprzętowych (procesora, procesora graficznego itp.) i powinny w dużym stopniu wykorzystywać atrapy i podróbki, aby tworzyć deterministyczne i skoncentrowane testy. Zmiany mające na celu rozszerzenie istniejącego kodu, który jest obecnie trudny do przetestowania, powinny odpowiednio zwiększyć jego testowalność.
Wszystkie zmiany powinny zawierać odpowiednie wyniki testów porównawczych w tytule zmiany, aby korzyści były wyraźnie widoczne.
Jeśli masz wątpliwości co do konwencji w kodzie, zawsze warto sprawdzić istniejący kod i spróbować zastosować wzorce już używane w OpenXLA.
Proces weryfikacji
Wszystkie zgłoszenia, w tym zgłoszenia członków projektu, wymagają sprawdzenia. W tym celu używamy żądań pull na GitHubie. Więcej informacji o korzystaniu z żądania pull znajdziesz w Pomocy GitHuba.
Przed sprawdzeniem kod musi spełniać wszystkie wymienione powyżej standardy. Nie są one opcjonalne i bardzo ważne jest, aby osoba przesyłająca kod upewniła się, że jest on zgodny z wymaganiami, zanim poprosi o sprawdzenie, aby zapewnić terminową akceptację zmian.
Wszystkie testy muszą zakończyć się wynikiem pozytywnym. Jeśli okaże się, że test jest uszkodzony, a problem nie jest związany ze środowiskiem kompilacji ani z Twoimi zmianami, skontaktuj się z osobami odpowiedzialnymi za utrzymanie projektu.
Podczas procesu sprawdzania staraj się unikać rozszerzania zakresu. Odpowiedzialność za to ponoszą zarówno osoba przesyłająca, jak i osoba sprawdzająca. Jeśli zmiana zaczyna być zbyt duża, rozważ podzielenie jej na kilka mniejszych zmian.
Zanim zmiana zostanie scalona, przejdzie wewnętrzne testy z użyciem kodu wewnętrznego Google i innych dostawców sprzętu. Może to spowodować dodatkowe kroki w procesie sprawdzania, jeśli testy wewnętrzne wykażą błędy, których nie wykryje nasz publiczny system ciągłej integracji. Osoba z Google sprawdzająca Twoją zmianę poinformuje Cię o wszelkich wewnętrznych błędach testów i opisze, co należy poprawić.
Najczęstsze pytania
„Ta zmiana infrastruktury nie jest związana z moim zgłoszeniem. Dlaczego warto to zrobić?”
Zespół XLA nie ma własnego zespołu ds. infrastruktury, więc to od nas wszystkich zależy, czy będziemy tworzyć biblioteki pomocnicze i unikać długu technicznego. Uważamy, że jest to standardowy element wprowadzania zmian w XLA i oczekujemy, że wszyscy będą w nim uczestniczyć. Zwykle tworzymy infrastrukturę w miarę potrzeb podczas pisania kodu.
Osoby sprawdzające XLA mogą poprosić Cię o zbudowanie infrastruktury (lub wprowadzenie dużej zmiany w prośbie o scalenie) wraz z napisaną przez Ciebie prośbą o scalenie. Ta prośba może wydawać się niepotrzebna lub niezwiązana ze zmianą, którą próbujesz wprowadzić. Prawdopodobnie wynika to z rozbieżności między Twoimi oczekiwaniami co do ilości infrastruktury, którą musisz zbudować, a oczekiwaniami osoby sprawdzającej.
Rozbieżność oczekiwań jest w porządku. Jest to normalne, gdy dopiero zaczynasz pracę nad projektem (czasami zdarza się to nawet doświadczonym osobom). Prawdopodobnie projekty, nad którymi pracowałeś(-aś) w przeszłości, wiązały się z innymi oczekiwaniami. To też jest w porządku i jest oczekiwane. Nie oznacza to, że któryś z tych projektów ma niewłaściwe podejście. Są po prostu różne. Zapraszamy do zapoznania się z prośbami dotyczącymi infrastruktury oraz innymi komentarzami do weryfikacji. Dzięki temu dowiesz się, czego oczekujemy w tym projekcie.
„Czy mogę odnieść się do Twojego komentarza w przyszłym zgłoszeniu zmiany?”
Często zadawane pytanie dotyczące próśb o zmiany w infrastrukturze (lub innych dużych próśb) w PR dotyczy tego, czy zmiana musi zostać wprowadzona w oryginalnym PR, czy też można ją wprowadzić w ramach dalszych działań w przyszłym PR.
Zasadniczo XLA nie zezwala autorom żądań pull na odpowiadanie na komentarze w ramach sprawdzania za pomocą kolejnych żądań pull. Jeśli weryfikator uzna, że w danym żądaniu wprowadzenia zmian należy coś poprawić, oczekujemy, że autorzy wprowadzą te zmiany w tym żądaniu, nawet jeśli wymagają one dużych modyfikacji. Ten standard jest stosowany zarówno zewnętrznie, jak i wewnętrznie w Google.
Istnieje kilka powodów, dla których XLA stosuje takie podejście.
Zaufanie: kluczowym elementem jest zdobycie zaufania recenzenta. W projekcie open source współtwórcy mogą się pojawiać i znikać w dowolnym momencie. Po zatwierdzeniu prośby o zmiany osoby sprawdzające nie mają możliwości upewnienia się, że obiecane działania następcze zostaną faktycznie wykonane.
Wpływ na innych deweloperów: jeśli wyślesz prośbę o scalenie dotyczącą konkretnej części XLA, istnieje duże prawdopodobieństwo, że inne osoby również przyglądają się tej części. Jeśli zaakceptujemy dług techniczny w Twoim żądaniu scalenia, będzie on wpływać na wszystkich, którzy przeglądają ten plik, dopóki nie zostanie przesłana kolejna wersja.
Obciążenie osób sprawdzających: odłożenie zmiany do późniejszego terminu wiąże się z wieloma kosztami dla naszych już przeciążonych osób sprawdzających. Osoby sprawdzające prawdopodobnie zapomną, czego dotyczyło pierwsze zgłoszenie, czekając na kolejne, co utrudni następną weryfikację. Weryfikatorzy będą też musieli śledzić oczekiwane działania następcze i pilnować, aby rzeczywiście zostały podjęte. Jeśli zmianę można wprowadzić w taki sposób, aby była ona całkowicie niezależna od pierwotnego żądania zmiany, dzięki czemu inny recenzent mógłby ją sprawdzić, przepustowość nie byłaby problemem. Z naszego doświadczenia wynika, że rzadko się to zdarza.