
יש שלוש דרכים ליצור קוד ל-HLO ב-XLA:GPU.
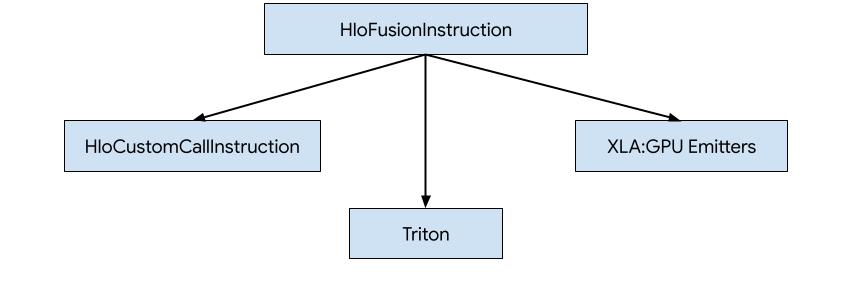
- החלפת HLO בקריאות מותאמות אישית לספריות חיצוניות, למשל NVidia cuBLAS, cuDNN.
- החלוקה של HLO לאריחים ברמת הבלוק ואז שימוש ב-OpenAI Triton.
- שימוש ב-XLA Emitters כדי להוריד את HLO ל-LLVM IR באופן הדרגתי.
המאמר הזה מתמקד ב-XLA:GPU Emitters.
Hero-based codegen
יש 7 סוגים של פולטים ב-XLA:GPU. כל סוג של פולט תואם ל'גיבור' של המיזוג, כלומר הפעולה הכי חשובה בחישוב הממוזג שמעצב את יצירת הקוד למיזוג כולו.
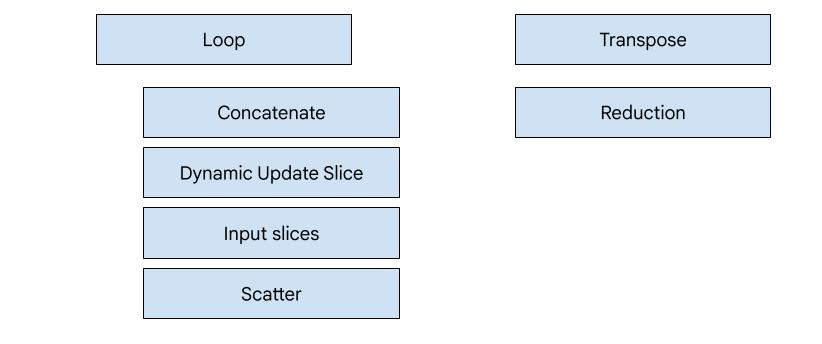
לדוגמה, פולט הטרנספוזיציה ייבחר אם יש HloTransposeInstruction בתוך המיזוג שדורש שימוש בזיכרון משותף כדי לשפר את דפוסי הקריאה והכתיבה של הזיכרון. הפונקציה להפחתת פליטות יוצרת הפחתות באמצעות ערבובים וזיכרון משותף. הפלטה של הלולאה היא פלטת ברירת המחדל. אם למיזוג אין גיבור שיש לנו פולט מיוחד בשבילו,
המערכת תשתמש בפולט הלולאה.
סקירה כללית
הקוד מורכב מאבני הבניין הגדולות הבאות:
- Computation partitioner - splitting an HLO fusion computation into functions
- פונקציות פלט – המרה של מיזוג HLO מחולק למחיצות ל-MLIR (ניבי שפה
xla_gpu,tensor,arith,math,scf) - צינור קומפילציה – מבצע אופטימיזציה ומוריד את IR ל-LLVM
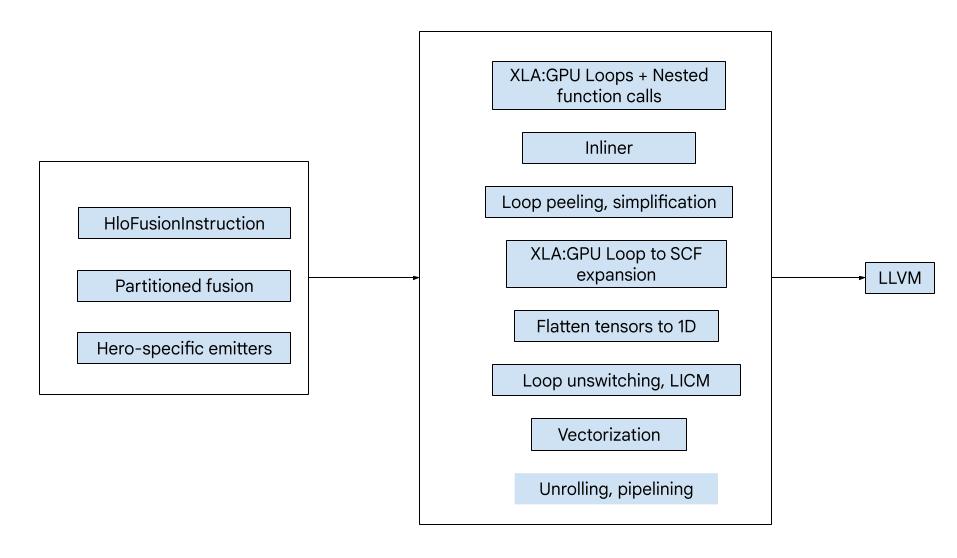
חלוקה למחיצות
מידע נוסף זמין בקובץ computation_partitioner.h.
לא תמיד אפשר לפלוט יחד הוראות HLO שאינן elementwise. כדאי לעיין בתרשים הבא של HLO:
param
|
log
| \
| transpose
| /
add
אם נשתמש בפונקציה אחת, תהיה גישה ל-log בשני אינדקסים שונים לכל רכיב של add. הפלטות הישנות פותרות את הבעיה הזו על ידי יצירת log פעמיים. במקרה של התרשים הזה, זו לא בעיה, אבל כשיש כמה פיצולים, גודל הקוד גדל באופן אקספוננציאלי.
כאן אנחנו פותרים את הבעיה הזו על ידי חלוקת הגרף לחלקים שאפשר להוציא בבטחה כפונקציה אחת. הנה הקריטריונים:
- הוראות שיש להן רק משתמש אחד בטוחות לפליטה יחד עם המשתמש שלהן.
- הוראות שמשתמשות בכמה משתמשים בטוחות לשימוש יחד עם המשתמשים שלהן אם כל המשתמשים ניגשים אליהן דרך אותם אינדקסים.
בדוגמה שלמעלה, add ו-tranpose ניגשים לאינדקסים שונים של log, ולכן לא בטוח להשתמש בהם יחד.
לכן הגרף מחולק לשלוש פונקציות (כל אחת מכילה רק הוראה אחת).
אותו עיקרון חל על הדוגמה הבאה עם slice ו-pad של add.
פליטה של רכיב
הפליטה של Elemental יוצרת לולאות ופעולות מתמטיות/אריתמטיות עבור HloInstructions. ברוב המקרים זה פשוט, אבל יש כאן כמה דברים מעניינים.
טרנספורמציות של הוספה לאינדקס
חלק מההוראות (transpose, broadcast, reshape, slice, reverse ועוד כמה) הן טרנספורמציות טהורות של אינדקסים: כדי ליצור רכיב של התוצאה, צריך ליצור רכיב אחר של הקלט. לשם כך, אפשר להשתמש מחדש ב-indexing_analysis של XLA, שיש לו פונקציות ליצירת מיפוי של פלט לקלט עבור הוראה.
לדוגמה, עבור transpose מ-[20,40] ל-[40,20], ייווצר מיפוי האינדקס הבא (ביטוי אפיני אחד לכל מימד קלט; d0 ו-d1 הם מימדי הפלט):
(d0, d1) -> d1
(d0, d1) -> d0
לכן, כדי לבצע את ההוראות האלה לשינוי אינדקס טהור, אפשר פשוט לקבל את המיפוי, להחיל אותו על אינדקסי הפלט וליצור את הקלט באינדקס שמתקבל.
באופן דומה, האופרטור pad משתמש במיפויים ובאילוצים של אינדקסים ברוב ההטמעה. pad היא גם טרנספורמציה של אינדקס עם כמה בדיקות נוספות כדי לראות אם אנחנו מחזירים רכיב של הקלט או את ערך הריפוד.
טופלים
אנחנו לא תומכים בtuple פנימיים. בנוסף, אנחנו לא תומכים בפלט של טאפל מוטבע. אפשר להמיר את כל הגרפים של XLA שמשתמשים בתכונות האלה לגרפים שלא משתמשים בהן.
איסוף
אנחנו תומכים רק בנתונים קנוניים שנאספים על ידי gather_simplifier.
פונקציות של תרשים משני
עבור תת-גרף של חישוב עם פרמטרים %p0 עד %p_n, ושורשי תת-גרף עם r מאפיינים וסוגי רכיבים (e0 עד e_m), אנחנו משתמשים בחתימת הפונקציה הבאה של MLIR:
(%p0: tensor<...>, %p1: tensor<...>, ..., %pn: tensor<...>,
%i0: index, %i1: index, ..., %i_r-1: index) -> (e0, ..., e_m)
כלומר, יש לנו טנסור קלט אחד לכל פרמטר חישוב, קלט אינדקס אחד לכל ממד של הפלט ותוצאה אחת לכל פלט.
כדי להפעיל פונקציה, פשוט משתמשים בפונקציית הפעלה הבסיסית שלמעלה, ומפעילים באופן רקורסיבי את האופרנדים שלה עד שמגיעים לקצה של תת-הגרף. לאחר מכן, אנחנו:פולטים tensor.extract לפרמטרים או פולטים func.call לגרפים משניים אחרים
פונקציית כניסה
כל סוג של פולט שונה באופן שבו הוא יוצר את פונקציית הכניסה, כלומר את הפונקציה של הגיבור. פונקציית הכניסה שונה מהפונקציות שלמעלה, כי אין לה אינדקסים כקלט (רק מזהי השרשור והבלוק) והיא צריכה לכתוב את הפלט איפשהו. במקרה של פולט הלולאה, זה די פשוט, אבל לפולטים של טרנספוזיציה וצמצום יש לוגיקה לא טריוויאלית של כתיבה.
החתימה של חישוב הרשומה היא:
(%p0: tensor<...>, ..., %pn: tensor<...>,
%r0: tensor<...>, ..., %rn: tensor<...>) -> (tensor<...>, ..., tensor<...>)
כמו קודם, הם הפרמטרים של החישוב, ו- הם התוצאות של החישוב.%pn%rn החישוב של הרשומה מקבל את התוצאות כטנסורים, מעדכן אותם באמצעות tensor.inserts ומחזיר אותם.
אסור להשתמש בטנסורים של הפלט בשום דרך אחרת.
צינור עיבוד נתונים של אוסף
אובייקט פולט בלולאה
מידע נוסף זמין ב-loop.h.
נבחן את השלבים החשובים ביותר בצינור ההידור של MLIR באמצעות HLO עבור פונקציית GELU.
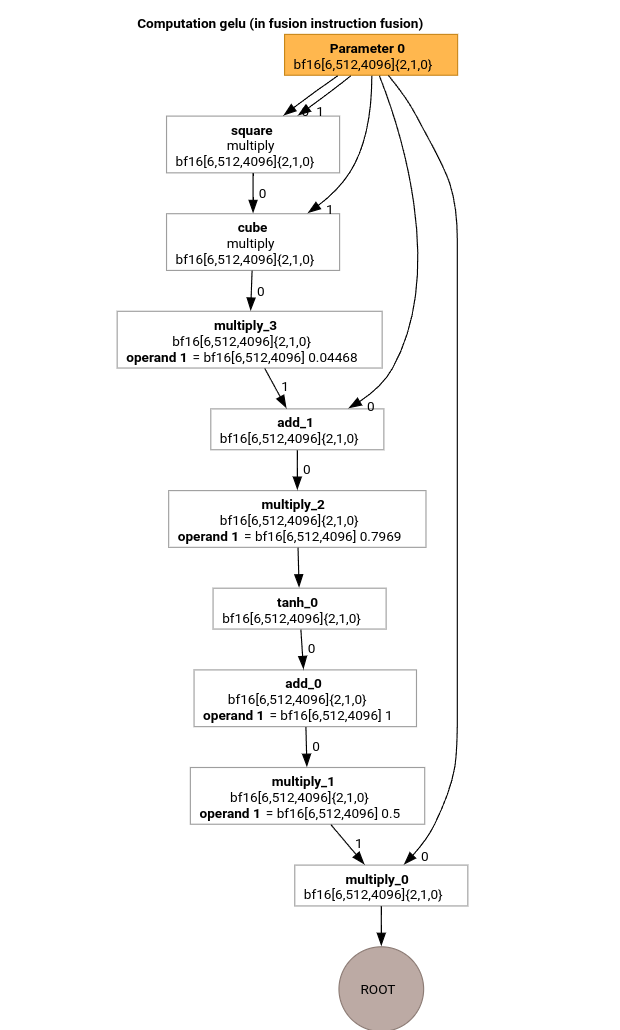
החישוב של HLO הזה כולל רק פעולות אלמנטריות, קבועים ושידורים. הוא ישודר באמצעות פולט הלולאה.
המרת MLIR
אחרי ההמרה ל-MLIR, מקבלים xla_gpu.loop שתלוי ב-%thread_id_x וב-%block_id_x ומגדיר את הלולאה שמעבירה את כל הרכיבים של הפלט באופן ליניארי כדי להבטיח כתיבה מאוחדת.
בכל איטרציה של הלולאה הזו אנחנו קוראים
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
כדי לחשב את הרכיבים של פעולת הבסיס. שימו לב, יש לנו רק פונקציה אחת עם קו מתאר ל-@gelu, כי הכלי לחלוקת נתונים לא זיהה טנסור עם 2 או יותר דפוסי גישה שונים.
#map = #xla_gpu.indexing_map<"(th_x, bl_x)[vector_index] -> ("
"bl_x floordiv 4096, (bl_x floordiv 8) mod 512, (bl_x mod 8) * 512 + th_x * 4 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<6x512x4096xbf16> , %output: tensor<6x512x4096xbf16>)
-> tensor<6x512x4096xbf16> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%pure_call = xla_gpu.pure_call @gelu(%input, %dim0, %dim1, %dim2)
: (tensor<6x512x4096xbf16>, index, index, index) -> bf16
%inserted = tensor.insert %pure_call into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
func.func private @gelu(%arg0: tensor<6x512x4096xbf16>, %i: index, %j: index, %k: index) -> bf16 {
%cst = arith.constant 5.000000e-01 : bf16
%cst_0 = arith.constant 1.000000e+00 : bf16
%cst_1 = arith.constant 7.968750e-01 : bf16
%cst_2 = arith.constant 4.467770e-02 : bf16
%extracted = tensor.extract %arg0[%i, %j, %k] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst_2 : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_1 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_0 : bf16
%7 = arith.mulf %6, %cst : bf16
%8 = arith.mulf %extracted, %7 : bf16
return %8 : bf16
}
Inliner
אחרי שהפונקציה @gelu מוטמעת, מקבלים פונקציה אחת @main. יכול להיות שאותה פונקציה נקראת פעמיים או יותר. במקרה כזה, אנחנו לא משתמשים בשיטת inline. פרטים נוספים על כללי ההטמעה מוצגים בקובץ xla_gpu_dialect.cc.
func.func @main(%arg0: tensor<6x512x4096xbf16>, %arg1: tensor<6x512x4096xbf16>) -> tensor<6x512x4096xbf16> {
...
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 24575 : index]}
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%vector_index] -> (%dim0, %dim1, %dim2)
in #map iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
%0 = arith.mulf %extracted, %extracted : bf16
%1 = arith.mulf %0, %extracted : bf16
%2 = arith.mulf %1, %cst : bf16
%3 = arith.addf %extracted, %2 : bf16
%4 = arith.mulf %3, %cst_0 : bf16
%5 = math.tanh %4 : bf16
%6 = arith.addf %5, %cst_1 : bf16
%7 = arith.mulf %6, %cst_2 : bf16
%8 = arith.mulf %extracted, %7 : bf16
%inserted = tensor.insert %8 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
xla_gpu.yield %inserted : tensor<6x512x4096xbf16>
}
return %xla_loop : tensor<6x512x4096xbf16>
}
המרת xla_gpu ל-scf
מידע נוסף זמין בכתובת lower_xla_gpu_to_scf.cc.
xla_gpu.loop מייצג לולאה מקוננת עם בדיקת גבולות בתוכה. אם משתני האינדוקציה של הלולאה
חורגים מהגבולות של תחום מיפוי האינדקס, המערכת מדלגת על האיטרציה הזו. המשמעות היא שהלולאה מומרת לפעולות scf.for מקוננות אחת או יותר עם scf.if בתוכן.
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<6x512x4096xbf16>) {
%2 = arith.cmpi sge, %thread_id_x, %c0 : index
%3 = arith.cmpi sle, %thread_id_x, %c127 : index
%4 = arith.andi %2, %3 : i1
%5 = arith.cmpi sge, %block_id_x, %c0 : index
%6 = arith.cmpi sle, %block_id_x, %c24575 : index
%7 = arith.andi %5, %6 : i1
%inbounds = arith.andi %4, %7 : i1
%9 = scf.if %inbounds -> (tensor<6x512x4096xbf16>) {
%dim0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x)[%vector_index]
%dim1 = xla_gpu.apply_indexing #map1(%thread_id_x, %block_id_x)[%vector_index]
%dim2 = xla_gpu.apply_indexing #map2(%thread_id_x, %block_id_x)[%vector_index]
%extracted = tensor.extract %input[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
// ... more arithmetic operations
%29 = arith.mulf %extracted, %28 : bf16
%inserted = tensor.insert %29 into %iter[%dim0, %dim1, %dim2] : tensor<6x512x4096xbf16>
scf.yield %inserted : tensor<6x512x4096xbf16>
} else {
scf.yield %iter : tensor<6x512x4096xbf16>
}
scf.yield %9 : tensor<6x512x4096xbf16>
}
השטחת טנסורים
ראו flatten_tensors.cc.
טנסורים של N ממדים מוקרנים על ממד אחד. הפעולה הזו תפשט את הווקטוריזציה ואת ההמרה ל-LLVM, כי כל גישה לטנסור תתאים עכשיו לאופן שבו הנתונים מיושרים בזיכרון.
#map = #xla_gpu.indexing_map<"(th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index),"
"domain: th_x in [0, 127], bl_x in [0, 24575], vector_index in [0, 3]">
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%xla_loop = scf.for %vector_index = %c0 to %c4 step %c1 iter_args(%iter = %output) -> (tensor<12582912xbf16>) {
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %vector_index)
%extracted = tensor.extract %input[%dim] : tensor<12582912xbf16>
%2 = arith.mulf %extracted, %extracted : bf16
%3 = arith.mulf %2, %extracted : bf16
%4 = arith.mulf %3, %cst_2 : bf16
%5 = arith.addf %extracted, %4 : bf16
%6 = arith.mulf %5, %cst_1 : bf16
%7 = math.tanh %6 : bf16
%8 = arith.addf %7, %cst_0 : bf16
%9 = arith.mulf %8, %cst : bf16
%10 = arith.mulf %extracted, %9 : bf16
%inserted = tensor.insert %10 into %iter[%dim] : tensor<12582912xbf16>
scf.yield %inserted : tensor<12582912xbf16>
}
return %xla_loop : tensor<12582912xbf16>
}
וקטוריזציה
למידע נוסף: vectorize_loads_stores.cc
ההעברה מנתחת את האינדקסים בפעולות tensor.extract ו-tensor.insert, ואם הם נוצרים על ידי xla_gpu.apply_indexing שמגשת לאלמנטים באופן רציף ביחס ל-%vector_index והגישה מיושרת, אז tensor.extract מומר ל-vector.transfer_read ומועבר אל מחוץ ללולאה.
במקרה הספציפי הזה, יש מפת אינדקס (th_x, bl_x, vector_index) -> (th_x * 4 + bl_x * 512 + vector_index) שמשמשת לחישוב רכיבים לחילוץ ולהוספה בלולאה scf.for מ-0 עד 4.
לכן, אפשר לבצע וקטוריזציה גם של tensor.extract וגם של tensor.insert.
func.func @main(%input: tensor<12582912xbf16>, %output: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%vector_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%0 = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%0], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%xla_loop:2 = scf.for %vector_index = %c0 to %c4 step %c1
iter_args(%iter = %output, %iter_vector = %vector_0) -> (tensor<12582912xbf16>, vector<4xbf16>) {
%5 = vector.extract %2[%vector_index] : bf16 from vector<4xbf16>
%6 = arith.mulf %5, %5 : bf16
%7 = arith.mulf %6, %5 : bf16
%8 = arith.mulf %7, %cst_4 : bf16
%9 = arith.addf %5, %8 : bf16
%10 = arith.mulf %9, %cst_3 : bf16
%11 = math.tanh %10 : bf16
%12 = arith.addf %11, %cst_2 : bf16
%13 = arith.mulf %12, %cst_1 : bf16
%14 = arith.mulf %5, %13 : bf16
%15 = vector.insert %14, %iter_vector [%vector_index] : bf16 into vector<4xbf16>
scf.yield %iter, %15 : tensor<12582912xbf16>, vector<4xbf16>
}
%4 = vector.transfer_write %xla_loop#1, %output[%0] {in_bounds = [true]}
: vector<4xbf16>, tensor<12582912xbf16>
return %4 : tensor<12582912xbf16>
}
ביטול גלגול של לולאה
למידע נוסף: optimize_loops.cc
הפונקציה loop unrolling מוצאת scf.for לולאות שאפשר לפתוח. במקרה כזה, הלולאה מעל האלמנטים של הווקטור נעלמת.
func.func @main(%input: tensor<12582912xbf16>, %arg1: tensor<12582912xbf16>) -> tensor<12582912xbf16> {
%cst_0 = arith.constant dense<0.000000e+00> : vector<4xbf16>
%dim = xla_gpu.apply_indexing #map(%thread_id_x, %block_id_x, %c0)
%2 = vector.transfer_read %input[%dim], %cst {in_bounds = [true]} : tensor<12582912xbf16>, vector<4xbf16>
%3 = vector.extract %2[%c0] : bf16 from vector<4xbf16>
...
%13 = vector.insert %12, %cst_0 [%c0] : bf16 into vector<4xbf16>
%14 = vector.extract %2[%c1] : bf16 from vector<4xbf16>
...
%24 = vector.insert %23, %13 [%c1] : bf16 into vector<4xbf16>
%25 = vector.extract %2[%c2] : bf16 from vector<4xbf16>
...
%35 = vector.insert %34, %24 [%c2] : bf16 into vector<4xbf16>
%36 = vector.extract %2[%c3] : bf16 from vector<4xbf16>
...
%46 = vector.insert %45, %35 [%c3] : bf16 into vector<4xbf16>
%47 = vector.transfer_write %46, %arg1[%dim] {in_bounds = [true]} : vector<4xbf16>, tensor<12582912xbf16>
return %47 : tensor<12582912xbf16>
}
המרת קוד ל-LLVM
אנחנו משתמשים בעיקר בהורדות של LLVM רגיל, אבל יש כמה מעברים מיוחדים.
אנחנו לא יכולים להשתמש בהורדות של memref לטנסורים, כי אנחנו לא מבצעים באפריזציה של ה-IR וה-ABI שלנו לא תואם לממשק ABI של memref. במקום זאת, יש לנו הורדה מותאמת אישית ישירות מטנסורים ל-LLVM.
- הורדת הטנסורים מתבצעת ב-lower_tensors.cc.
tensor.extractיורד ל-llvm.load, ו-tensor.insertל-llvm.store, באופן ברור. - השילוב של propagate_slice_indices ו-merge_pointers_to_same_slice מיישם פרט בהקצאת מאגר נתונים זמני ובממשק ABI של XLA: אם שני טנסורים חולקים את אותו פרוסת מאגר נתונים זמני, הם מועברים רק פעם אחת. במעברים האלה מתבצעת דה-דופליקציה של הארגומנטים של הפונקציה.
llvm.func @__nv_tanhf(f32) -> f32
llvm.func @main(%arg0: !llvm.ptr, %arg1: !llvm.ptr) {
%11 = nvvm.read.ptx.sreg.tid.x : i32
%12 = nvvm.read.ptx.sreg.ctaid.x : i32
%13 = llvm.mul %11, %1 : i32
%14 = llvm.mul %12, %0 : i32
%15 = llvm.add %13, %14 : i32
%16 = llvm.getelementptr inbounds %arg0[%15] : (!llvm.ptr, i32) -> !llvm.ptr, bf16
%17 = llvm.load %16 invariant : !llvm.ptr -> vector<4xbf16>
%18 = llvm.extractelement %17[%2 : i32] : vector<4xbf16>
%19 = llvm.fmul %18, %18 : bf16
%20 = llvm.fmul %19, %18 : bf16
%21 = llvm.fmul %20, %4 : bf16
%22 = llvm.fadd %18, %21 : bf16
%23 = llvm.fmul %22, %5 : bf16
%24 = llvm.fpext %23 : bf16 to f32
%25 = llvm.call @__nv_tanhf(%24) : (f32) -> f32
%26 = llvm.fptrunc %25 : f32 to bf16
%27 = llvm.fadd %26, %6 : bf16
%28 = llvm.fmul %27, %7 : bf16
%29 = llvm.fmul %18, %28 : bf16
%30 = llvm.insertelement %29, %8[%2 : i32] : vector<4xbf16>
...
}
החלפת מיקום של אובייקט פולט
נבחן עכשיו דוגמה קצת יותר מורכבת.
![]()
ההבדל בין פונקציית הפלט של טרנספוזיציה לבין פונקציית הפלט של לולאה הוא רק באופן שבו נוצרת פונקציית הכניסה.
func.func @transpose(%arg0: tensor<20x160x170xf32>, %arg1: tensor<170x160x20xf32>) -> tensor<170x160x20xf32> {
%thread_id_x = gpu.thread_id x {xla.range = [0 : index, 127 : index]}
%block_id_x = gpu.block_id x {xla.range = [0 : index, 959 : index]}
%shmem = xla_gpu.allocate_shared : tensor<32x1x33xf32>
%xla_loop = xla_gpu.loop (%thread_id_x, %block_id_x)[%i, %j]
-> (%input_dim0, %input_dim1, %input_dim2, %shmem_dim0, %shmem_dim1, %shmem_dim2)
in #map iter_args(%iter = %shmem) -> (tensor<32x1x33xf32>) {
%extracted = tensor.extract %arg0[%input_dim0, %input_dim1, %input_dim2] : tensor<20x160x170xf32>
%0 = math.exp %extracted : f32
%inserted = tensor.insert %0 into %iter[%shmem_dim0, %shmem_dim1, %shmem_dim2] : tensor<32x1x33xf32>
xla_gpu.yield %inserted : tensor<32x1x33xf32>
}
%synced_tensor = xla_gpu.sync_threads %xla_loop : tensor<32x1x33xf32>
%xla_loop_0 = xla_gpu.loop (%thread_id_x %block_id_x)[%i, %j] -> (%dim0, %dim1, %dim2)
in #map1 iter_args(%iter = %arg1) -> (tensor<170x160x20xf32>) {
// indexing computations
%extracted = tensor.extract %synced_tensor[%0, %c0, %1] : tensor<32x1x33xf32>
%2 = math.absf %extracted : f32
%inserted = tensor.insert %2 into %iter[%3, %4, %1] : tensor<170x160x20xf32>
xla_gpu.yield %inserted : tensor<170x160x20xf32>
}
return %xla_loop_0 : tensor<170x160x20xf32>
}
במקרה כזה, אנחנו יוצרים שני xla_gpu.loop ops. הראשון מבצע קריאות מאוחדות מהקלט וכותב את התוצאה לזיכרון המשותף.
טנזור הזיכרון המשותף נוצר באמצעות אופרטור xla_gpu.allocate_shared.
אחרי שהשרשורים מסונכרנים באמצעות xla_gpu.sync_threads, השרשור השני xla_gpu.loop קורא את הרכיבים מטנסור הזיכרון המשותף ומבצע כתיבה מאוחדת לפלט.
Reproducer
כדי לראות את ה-IR אחרי כל מעבר של צינור ההידור, אפשר להפעיל את run_hlo_module עם הדגל --xla_dump_emitter_re=mlir-fusion.
run_hlo_module --platform=CUDA --xla_disable_all_hlo_passes --reference_platform="" /tmp/gelu.hlo --xla_dump_emitter_re=mlir-fusion --xla_dump_to=<some_directory>
כאשר /tmp/gelu.hlo מכיל
HloModule m:
gelu {
%param = bf16[6,512,4096] parameter(0)
%constant_0 = bf16[] constant(0.5)
%bcast_0 = bf16[6,512,4096] broadcast(bf16[] %constant_0), dimensions={}
%constant_1 = bf16[] constant(1)
%bcast_1 = bf16[6,512,4096] broadcast(bf16[] %constant_1), dimensions={}
%constant_2 = bf16[] constant(0.79785)
%bcast_2 = bf16[6,512,4096] broadcast(bf16[] %constant_2), dimensions={}
%constant_3 = bf16[] constant(0.044708)
%bcast_3 = bf16[6,512,4096] broadcast(bf16[] %constant_3), dimensions={}
%square = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %param)
%cube = bf16[6,512,4096] multiply(bf16[6,512,4096] %square, bf16[6,512,4096] %param)
%multiply_3 = bf16[6,512,4096] multiply(bf16[6,512,4096] %cube, bf16[6,512,4096] %bcast_3)
%add_1 = bf16[6,512,4096] add(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_3)
%multiply_2 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_1, bf16[6,512,4096] %bcast_2)
%tanh_0 = bf16[6,512,4096] tanh(bf16[6,512,4096] %multiply_2)
%add_0 = bf16[6,512,4096] add(bf16[6,512,4096] %tanh_0, bf16[6,512,4096] %bcast_1)
%multiply_1 = bf16[6,512,4096] multiply(bf16[6,512,4096] %add_0, bf16[6,512,4096] %bcast_0)
ROOT %multiply_0 = bf16[6,512,4096] multiply(bf16[6,512,4096] %param, bf16[6,512,4096] %multiply_1)
}
ENTRY main {
%param = bf16[6,512,4096] parameter(0)
ROOT fusion = bf16[6,512,4096] fusion(%param), kind=kLoop, calls=gelu
}
קישורים לקוד
- צינור עיבוד הנתונים של הקומפילציה: emitter_base.h
- שלבי האופטימיזציה וההמרה: backends/gpu/codegen/emitters/transforms
- לוגיקת החלוקה: computation_partitioner.h
- אובייקטים פולטים שמבוססים על רכיב Hero: backends/gpu/codegen/emitters
- XLA:GPU ops: xla_gpu_ops.td
- בדיקות נכונות ובדיקות קוד: backends/gpu/codegen/emitters/tests