
L'analyse d'indexation HLO est une analyse du flux de données qui décrit la relation entre les éléments d'un Tensor et ceux d'un autre à l'aide de "cartes d'indexation". Par exemple, comment les indices d'une sortie d'instruction HLO sont mappés aux indices des opérandes d'instruction HLO.
Exemple
Pour une diffusion de tensor<20xf32> à tensor<10x20x30xf32>
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
La carte d'indexation de la sortie à l'entrée est (i, j, k) -> (j) pour i in
[0, 10], j in [0, 20] et k in [0, 30].
Motivation
XLA utilise plusieurs solutions sur mesure pour raisonner sur la fusion, l'utilisation des opérandes et les schémas de tiling (plus de détails ci-dessous). L'objectif de l'analyse de l'indexation est de fournir un composant réutilisable pour de tels cas d'utilisation. L'analyse de l'indexation s'appuie sur l'infrastructure Affine Map de MLIR et ajoute la sémantique HLO.
Coalescence
Le raisonnement sur la fusion de la mémoire devient possible pour les cas non triviaux, lorsque nous savons quels éléments/tranches des entrées sont lus pour calculer un élément de la sortie.
Utilisation des opérandes
Dans XLA, l'utilisation des opérandes indique la mesure dans laquelle chaque entrée de l'instruction est utilisée en supposant que sa sortie est entièrement utilisée. Actuellement, l'utilisation n'est pas non plus calculée pour un cas générique. L'analyse de l'indexation nous permet de calculer précisément l'utilisation.
Mosaïque
Une tuile/tranche est un sous-ensemble hyperrectangulaire d'un Tensor paramétré par des décalages, des tailles et des foulées. La propagation des blocs est un moyen de calculer les paramètres de bloc du producteur/consommateur de l'opération à l'aide des paramètres de bloc de l'opération elle-même. Il existe déjà une bibliothèque qui le fait pour softmax et dot. La propagation des tuiles peut être rendue plus générique et robuste si elle est exprimée via des cartes d'indexation.
Mappage de l'indexation
Une carte d'indexation est une combinaison de
- une fonction exprimée symboliquement qui mappe chaque élément d'un Tensor
Aà des plages d'éléments dans le TensorB; - contraintes sur les arguments de fonction valides, y compris le domaine de la fonction.
Les arguments de fonction sont répartis en trois catégories pour mieux communiquer leur nature :
Variables de dimension du Tensor
Aou d'une grille GPU à partir de laquelle nous effectuons le mappage. Les valeurs sont connues de manière statique. Les éléments d'index sont également appelés variables de dimension.Variables range. Elles définissent un mappage un-à-plusieurs et spécifient un ensemble d'éléments dans
Butilisés pour calculer une seule valeur deA. Les valeurs sont connues de manière statique. La dimension de contraction d'une multiplication matricielle est un exemple de variable de plage.des variables d'exécution qui ne sont connues que lors de l'exécution. Par exemple, l'argument d'index de l'opération gather.
Le résultat de la fonction est un index du Tensor B cible.
En bref, une fonction d'indexation du tenseur A au tenseur B pour l'opération x est
map_ab(index in A, range variables, runtime variables) -> index in B.
Pour mieux séparer les types d'arguments de mappage, nous les écrivons comme suit :
map_ab(index in A)[range variables]{runtime variables} -> (index in B)
Par exemple, examinons les mappages d'indexation pour l'opération de réduction f32[4, 8] out = reduce(f32[2, 4, 8, 16] in, 0), dimensions={0,3} :
Pour mapper les éléments de
inàout, notre fonction peut être exprimée sous la forme(d0, d1, d2, d3) -> (d1, d2). Les contraintes des variablesd0 in [0, 1], d1 in [0, 3], d2 in [0, 7], d3 in [0, 15]sont définies par la forme dein.Pour mapper les éléments de
outàin:outne comporte que deux dimensions, et la réduction introduit deux variables de plage qui couvrent les dimensions de réduction. La fonction de mappage est donc(d0, d1)[s0, s1] -> (s0, d0, d1, s1), où(d0, d1)est l'index deout.s0ets1sont des plages définies par la sémantique de l'opération et couvrent les dimensions 0 et 3 du Tensorin. Les contraintes sontd0 in [0, 3], d1 in [0, 7], s0 in [0,1], s1 in [0, 15].
Il est important de noter que, dans la plupart des cas, nous souhaitons mapper les éléments de la sortie. Pour les calculs
C = op1(A, B)
E = op2(C, D)
Nous pouvons parler d'"indexation de B", ce qui signifie "mappage des éléments de E dans les éléments de B". Cela peut sembler contre-intuitif par rapport à d'autres types d'analyse du flux de données qui fonctionnent de l'entrée vers les sorties.
Les contraintes sur les variables permettent d'identifier des opportunités d'optimisation et facilitent la génération de code. Dans la documentation et les contraintes d'implémentation, on parle également de domaine, car elles définissent toutes les combinaisons ou valeurs d'arguments valides de la fonction de mappage. Pour de nombreuses opérations, les contraintes décrivent simplement les dimensions des Tensors, mais pour certaines opérations, elles peuvent être plus complexes. Voir les exemples ci-dessous.
En exprimant les fonctions et les contraintes d'arguments de manière symbolique et en étant capable de combiner des fonctions et des contraintes, nous pouvons calculer un mappage d'indexation compact pour un calcul arbitrairement grand (fusion).
L'expressivité des fonctions et des contraintes symboliques est un équilibre entre la complexité de l'implémentation et les gains d'optimisation que nous obtenons en ayant une représentation plus précise. Pour certaines opérations HLO, nous ne capturons les modèles d'accès qu'approximativement.
Implémentation
Comme nous voulons minimiser le recalcul, nous avons besoin d'une bibliothèque pour les calculs symboliques. XLA dépendant déjà de MLIR, nous utilisons mlir::AffineMap au lieu d'écrire une autre bibliothèque d'arithmétique symbolique.
Un AffineMap type se présente comme suit :
(d0)[s0, s1] -> (s0 + 5, d0 * 2, s1 * 3 + 50)
AffineMap comporte deux types de paramètres : les dimensions et les symboles.
Les dimensions correspondent aux variables de dimension d, tandis que les symboles correspondent aux variables de plage r et aux variables d'exécution rt. AffineMap ne contient aucune métadonnée sur les contraintes des paramètres. Nous devons donc les fournir séparément.
struct Interval {
int64_t lower;
int64_t upper;
};
class IndexingMap {
// Variable represents dimension, range or runtime variable.
struct Variable {
Interval bounds;
// Name of the variable is used for nicer printing.
std::string name = "";
};
mlir::AffineMap affine_map_;
// DimVars represent dimensions of a tensor or of a GPU grid.
std::vector<Variable> dim_vars_;
// RangeVars represent ranges of values, e.g. to compute a single element of
// the reduction's result we need a range of values from the input tensor.
std::vector<Variable> range_vars_;
// RTVars represent runtime values, e.g. a dynamic offset in
// HLO dynamic-update-slice op.
std::vector<Variable> rt_vars_;
llvm::DenseMap<mlir::AffineExpr, Interval> constraints_;
};
dim_vars_ encode les contraintes de boîte inclusives pour les variables de dimension d de la carte d'indexation, qui coïncident généralement avec la forme du Tensor de sortie pour les opérations telles que transpose, reduce, elementwise, dot, mais il existe quelques exceptions comme HloConcatenateInstruction.
range_vars_ toutes les valeurs que prennent les variables de plage s. Les variables de plage sont nécessaires lorsque plusieurs valeurs sont nécessaires pour calculer un seul élément du Tensor à partir duquel nous effectuons le mappage, par exemple pour le mappage d'index de sortie vers entrée des réductions ou le mappage d'entrée vers sortie pour les diffusions.
rt_vars_ encode les valeurs possibles au moment de l'exécution. Par exemple, le décalage est dynamique pour un HloDynamicSliceInstruction 1D. La RTVar correspondante aura des valeurs possibles comprises entre 0 et tensor_size - slice_size - 1.
constraints_ capture les relations entre les valeurs au format <expression> in <range>, par exemple d0 + s0 in [0, 20]. Avec Variable.bounds, ils définissent le "domaine" de la fonction d'indexation.
Étudions un exemple pour comprendre ce que tout cela signifie concrètement.
Indexation des cartes pour les opérations non fusionnées
Élément par élément
Pour les opérations élément par élément, le mappage d'indexation est une identité.
p0 = f32[10, 20] parameter(0)
p1 = f32[10, 20] parameter(1)
output = f32[10, 20] add(p0, p1)
Mappage de la sortie vers l'entrée output -> p0 :
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Mappage des entrées vers les sorties p0 -> output :
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 9],
d1 in [0, 19]
Mégaphone
La diffusion signifie que certaines dimensions seront supprimées lorsque nous mapperons la sortie à l'entrée et ajoutées lorsque nous mapperons l'entrée à la sortie.
p0 = f32[20] parameter(0)
bc0 = f32[10, 20, 30] broadcast(p0), dimensions={1}
Mappage de la sortie vers l'entrée :
(d0, d1, d2) -> (d1),
domain:
d0 in [0, 9],
d1 in [0, 19],
d2 in [0, 29]
Mappage des entrées et des sorties :
(d0)[s0, s1] -> (s0, d0, s1),
domain:
d0 in [0, 19],
s0 in [0, 9],
s1 in [0, 29]
Notez que nous avons maintenant des variables de plage s sur la droite pour le mappage d'entrée à sortie. Il s'agit des symboles qui représentent des plages de valeurs.
Par exemple, dans ce cas particulier, chaque élément d'entrée avec l'index d0 est mappé à une tranche de sortie de 10 x 1 x 30.
Iota
Iota ne comporte aucun opérande Tensor d'entrée. Il n'y a donc pas d'arguments d'index d'entrée.
iota = f32[2,4] iota(), dimensions={1}
Sortie vers le mappage d'entrée :
(d0, d1) -> ()
domain:
d0 in [0, 1]
d1 in [0, 3]
Mappage des entrées aux sorties :
()[s0, s1] -> (s0, s1)
domain:
s0 in [0, 1]
s1 in [0, 3]
DynamicSlice
DynamicSlice comporte des décalages qui ne sont connus qu'au moment de l'exécution.
src = s32[2, 2, 258] parameter(0)
of1 = s32[] parameter(1)
of2 = s32[] parameter(2)
of3 = s32[] parameter(3)
ds = s32[1, 2, 32] dynamic-slice(src, of1, of2, of3), dynamic_slice_sizes={1, 2, 32}
Mappage des sorties vers les entrées de ds à src :
(d0, d1, d2){rt0, rt1, rt2} -> (d0 + rt0, d1 + rt1, d2 + rt2),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31],
rt0 in [0, 1],
rt1 in [0, 0],
rt2 in [0, 226]
Notez que nous avons maintenant rt sur le côté droit pour le mappage d'entrée à sortie.
Il s'agit des symboles qui représentent les valeurs d'exécution. Par exemple, dans ce cas particulier, pour chaque élément de la sortie avec des indices d0, d1, d2, nous accédons aux décalages de tranche of1, of2 et of3 pour calculer l'index de l'entrée.
Les intervalles pour les variables d'exécution sont dérivés en supposant que l'intégralité de la tranche reste dans les limites.
Mappage des sorties vers les entrées pour of1, of2 et of3 :
(d0, d1, d2) -> (),
domain:
d0 in [0, 0],
d1 in [0, 1],
d2 in [0, 31]
DynamicUpdateSlice
src = s32[20,30] parameter(0)
upd = s32[5,10] parameter(1)
of1 = s32[] parameter(2)
of2 = s32[] parameter(3)
dus = s32[20,30] dynamic-update-slice(
s32[20,30] src, s32[5,10] upd, s32[] of1, s32[] of2)
Le mappage des sorties aux entrées pour src est trivial. Elle peut être rendue plus précise en limitant le domaine aux index non mis à jour, mais pour le moment, les mappages d'indexation ne prennent pas en charge les contraintes d'inégalité.
(d0, d1) -> (d0, d1),
domain:
d0 in [0, 19],
d1 in [0, 29]
Mappage de la sortie vers l'entrée pour upd :
(d0, d1){rt0, rt1} -> (d0 - rt0, d1 - rt1),
domain:
d0 in [0, 19],
d1 in [0, 29],
rt0 in [0, 15],
rt1 in [0, 20]
Notez que nous avons maintenant rt0 et rt1 qui représentent des valeurs d'exécution. Dans ce cas particulier, pour chaque élément de la sortie avec des indices d0, d1, nous accédons aux décalages de tranche of1 et of2 pour calculer l'index de l'entrée. Les intervalles pour les variables d'exécution sont dérivés en supposant que l'intégralité de la tranche reste dans les limites.
Mappage de la sortie vers l'entrée pour of1 et of2 :
(d0, d1) -> (),
domain:
d0 in [0, 19],
d1 in [0, 29]
Gather
Seule la collecte simplifiée est acceptée. Consultez gather_simplifier.h.
operand = f32[33,76,70] parameter(0)
indices = s32[1806,2] parameter(1)
gather = f32[1806,7,8,4] gather(operand, indices),
offset_dims={1,2,3},
collapsed_slice_dims={},
start_index_map={0,1},
index_vector_dim=1,
slice_sizes={7,8,4}
Mappage de la sortie vers l'entrée pour operand :
(d0, d1, d2, d3){rt0, rt1} -> (d1 + rt0, d2 + rt1, d3),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
rt0 in [0, 26],
rt1 in [0, 68]
Notez que nous avons maintenant des symboles rt qui représentent les valeurs d'exécution.
Mappage de la sortie vers l'entrée pour indices :
(d0, d1, d2, d3)[s0] -> (d0, s0),
domain:
d0 in [0, 1805],
d1 in [0, 6],
d2 in [0, 7],
d3 in [0, 3],
s0 in [0, 1]
La variable de plage s0 indique que nous avons besoin de la ligne entière (d0, *) du Tensor indices pour calculer un élément de la sortie.
Transposer
La carte d'indexation pour la transposition est une permutation des dimensions d'entrée/de sortie.
p0 = f32[3, 12288, 6, 128] parameter(0)
transpose = f32[3, 6, 128, 12288] transpose(p0), dimensions={0, 2, 3, 1}
Mappage de la sortie vers l'entrée :
(d0, d1, d2, d3) -> (d0, d3, d1, d2),
domain:
d0 in [0, 2],
d1 in [0, 5],
d2 in [0, 127],
d3 in [0, 12287],
Mappage des entrées et des sorties :
(d0, d1, d2, d3) -> (d0, d2, d3, d1),
domain:
d0 in [0, 2],
d1 in [0, 12287],
d2 in [0, 5],
d3 in [0, 127]
Inverser
La carte d'indexation pour l'inversion des modifications remplace les dimensions rétablies par upper_bound(d_i) -
d_i :
p0 = f32[1, 17, 9, 9] parameter(0)
reverse = f32[1, 17, 9, 9] reverse(p0), dimensions={1, 2}
Mappage de la sortie vers l'entrée :
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
Mappage des entrées et des sorties :
(d0, d1, d2, d3) -> (d0, -d1 + 16, -d2 + 8, d3),
domain:
d0 in [0, 0],
d1 in [0, 16],
d2 in [0, 8],
d3 in [0, 8]
(Variadic)Reduce
La réduction variadique comporte plusieurs entrées et plusieurs valeurs initiales. Le mappage de la sortie à l'entrée ajoute les dimensions réduites.
p0 = f32[256,10] parameter(0)
p0_init = f32[] constant(-inf)
p1 = s32[256,10] parameter(1)
p1_init = s32[] constant(0)
out = (f32[10], s32[10]) reduce(p0, p1, p0_init, p1_init),
dimensions={0}, to_apply=max
Voici les mappages de sortie vers entrée :
out[0]->p0:
(d0)[s0] -> (s0, d0),
domain:
d0 in [0, 9],
s0 in [0, 255]
out[0]->p0_init:
(d0) -> (),
domain:
d0 in [0, 9]
Voici les mappages d'entrée vers sortie :
p0->out[0]:
(d0, d1) -> (d1),
domain:
d0 in [0, 255],
d1 in [0, 9]
p0_init->out[0]:
()[s0] -> (s0),
domain:
s0 in [0, 9]
Slice
L'indexation de la sortie vers l'entrée pour le slice génère une carte d'indexation à pas qui est valide pour chaque élément de la sortie. Le mappage de l'entrée vers la sortie est limité à une plage d'éléments de l'entrée avec un certain pas.
p0 = f32[10, 20, 50] parameter(0)
slice = f32[5, 3, 25] slice(f32[10, 20, 50] p0),
slice={[5:10:1], [3:20:7], [0:50:2]}
Mappage de la sortie vers l'entrée :
(d0, d1, d2) -> (d0 + 5, d1 * 7 + 3, d2 * 2),
domain:
d0 in [0, 4],
d1 in [0, 2],
d2 in [0, 24]
Mappage des entrées et des sorties :
(d0, d1, d2) -> (d0 - 5, (d1 - 3) floordiv 7, d2 floordiv 2),
domain:
d0 in [5, 9],
d1 in [3, 17],
d2 in [0, 48],
(d1 - 3) mod 7 in [0, 0],
d2 mod 2 in [0, 0]
Remodeler
Il existe différents types de remodelages.
Réduire la forme
Il s'agit d'une remise en forme "linéarisante" de N-D à 1D.
p0 = f32[4,8] parameter(0)
reshape = f32[32] reshape(p0)
Mappage de la sortie vers l'entrée :
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Mappage des entrées et des sorties :
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Développer la forme
Il s'agit d'une opération inverse de "collapse shape" (réduire la forme), qui remodèle une entrée 1D en sortie N-D.
p0 = f32[32] parameter(0)
reshape = f32[4, 8] reshape(p0)
Mappage de la sortie vers l'entrée :
(d0, d1) -> (d0 * 8 + d1),
domain:
d0 in [0, 3],
d1 in [0, 7]
Mappage des entrées et des sorties :
(d0) -> (d0 floordiv 8, d0 mod 8),
domain:
d0 in [0, 31]
Remodeler générique
Il s'agit des opérations de remodelage qui ne peuvent pas être représentées sous la forme d'une seule forme d'expansion ou de réduction. Elles ne peuvent être représentées que sous la forme d'une composition de deux formes d'expansion ou de réduction ou plus.
Exemple 1 : Linéarisation-délinéarisation.
p0 = f32[4,8] parameter(0)
reshape = f32[2, 4, 4] reshape(p0)
Cette remise en forme peut être représentée comme une composition de la forme d'effondrement de tensor<4x8xf32> à tensor<32xf32>, puis une expansion de la forme à tensor<2x4x4xf32>.
Mappage de la sortie vers l'entrée :
(d0, d1, d2) -> (d0 * 2 + d1 floordiv 2, d2 + (d1 mod 2) * 4),
domain:
d0 in [0, 1],
d1 in [0, 3],
d2 in [0, 3]
Mappage des entrées et des sorties :
(d0, d1) -> (d0 floordiv 2, d1 floordiv 4 + (d0 mod 2) * 2, d1 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7]
Exemple 2 : Sous-formes développées et réduites
p0 = f32[4, 8, 12] parameter(0)
reshape = f32[32, 3, 4] reshape(p0)
Cette remise en forme peut être représentée comme une composition de deux remises en forme. Le premier réduit les dimensions extérieures tensor<4x8x12xf32> à tensor<32x12xf32>, et le second développe la dimension intérieure tensor<32x12xf32> en tensor<32x3x4xf32>.
Mappage de la sortie vers l'entrée :
(d0, d1, d2) -> (d0 floordiv 8, d0 mod 8, d1 * 4 + d2),
domain:
d0 in [0, 31],
d1 in [0, 2]
d2 in [0, 3]
Mappage des entrées et des sorties :
(d0, d1, d2) -> (d0 * 8 + d1, d2 floordiv 4, d2 mod 4),
domain:
d0 in [0, 3],
d1 in [0, 7],
d2 in [0, 11]
Bitcast
Une opération bitcast peut être représentée sous la forme d'une séquence de transpositions-remodelages-transpositions. Par conséquent, ses cartes d'indexation ne sont qu'une composition des cartes d'indexation pour cette séquence.
Concaténer
Le mappage de la sortie vers l'entrée pour la concaténation est défini pour toutes les entrées, mais avec des domaines non chevauchants, c'est-à-dire qu'une seule des entrées sera utilisée à la fois.
p0 = f32[2, 5, 7] parameter(0)
p1 = f32[2, 11, 7] parameter(1)
p2 = f32[2, 17, 7] parameter(2)
ROOT output = f32[2, 33, 7] concatenate(f32[2, 5, 7] p0, f32[2, 11, 7] p1, f32[2, 17, 7] p2), dimensions={1}
Mappages des sorties vers les entrées :
output->p0:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
output->p1:
(d0, d1, d2) -> (d0, d1 - 5, d2),
domain:
d0 in [0, 1],
d1 in [5, 15],
d2 in [0, 6]
output->p2:
(d0, d1, d2) -> (d0, d1 - 16, d2),
domain:
d0 in [0, 1],
d1 in [16, 32],
d2 in [0, 6]
Voici les mappages des entrées vers les sorties :
p0->output:
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 4],
d2 in [0, 6]
p1->output:
(d0, d1, d2) -> (d0, d1 + 5, d2),
domain:
d0 in [0, 1],
d1 in [0, 10],
d2 in [0, 6]
p2->output:
(d0, d1, d2) -> (d0, d1 + 16, d2),
domain:
d0 in [0, 1],
d1 in [0, 16],
d2 in [0, 6]
Dot
Les mappages d'index pour dot sont très semblables à ceux de reduce.
p0 = f32[4, 128, 256] parameter(0)
p1 = f32[4, 256, 64] parameter(1)
output = f32[4, 128, 64] dot(p0, p1),
lhs_batch_dims={0}, rhs_batch_dims={0},
lhs_contracting_dims={2}, rhs_contracting_dims={1}
Mappages des sorties vers les entrées :
- output -> p0:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
- output -> p1:
(d0, d1, d2)[s0] -> (d0, s0, d2),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 63],
s0 in [0, 255]
Voici les mappages des entrées vers les sorties :
- p0 -> output:
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 3],
d1 in [0, 127],
d2 in [0, 255],
s0 in [0, 63]
- p1 -> output:
(d0, d1, d2)[s0] -> (d0, s0, d1),
domain:
d0 in [0, 3],
d1 in [0, 255],
d2 in [0, 63],
s0 in [0, 127]
Pad
L'indexation de PadOp est l'inverse de l'indexation de SliceOp.
p0 = f32[4, 4] parameter(0)
p1 = f32[] parameter(1)
pad = f32[12, 16] pad(p0, p1), padding=1_4_1x4_8_0
La configuration du remplissage 1_4_1x4_8_0 indique lowPad_highPad_interiorPad_dim_0 x lowPad_highPad_interiorPad_dim_1.
Voici les mappages de sortie vers entrée :
- output -> p0:
(d0, d1) -> ((d0 - 1) floordiv 2, d1 - 4),
domain:
d0 in [1, 7],
d1 in [4, 7],
(d0 - 1) mod 2 in [0, 0]
- output -> p1:
(d0, d1) -> (),
domain:
d0 in [0, 11],
d1 in [0, 15]
ReduceWindow
ReduceWindow dans XLA effectue également un remplissage. Par conséquent, les mappages d'indexation peuvent être calculés comme une composition de l'indexation ReduceWindow qui n'effectue aucun remplissage et de l'indexation PadOp.
c_inf = f32[] constant(-inf)
p0 = f32[1024, 514] parameter(0)
outpu = f32[1024, 3] reduce-window(p0, c_inf),
window={size=1x512 pad=0_0x0_0}, to_apply=max
Voici les mappages de sortie vers entrée :
output -> p0:
(d0, d1)[s0] -> (d0, d1 + s0),
domain:
d0 in [0, 1023],
d1 in [0, 2],
s0 in [0, 511]
output -> c_inf:
(d0, d1) -> (),
domain:
d0 in [0, 1023],
d1 in [0, 2]
Indexation des cartes pour Fusion
La carte d'indexation pour l'opération de fusion est une composition des cartes d'indexation pour chaque opération du cluster. Il peut arriver que certaines entrées soient lues plusieurs fois avec différents modèles d'accès.
Une entrée, plusieurs cartes d'indexation
Voici un exemple pour p0 + transpose(p0).
f {
p0 = f32[1000, 1000] parameter(0)
transpose_p0 = f32[1000, 1000]{0, 1} transpose(p0), dimensions={1, 0}
ROOT a0 = f32[1000, 1000] add(p0, transpose_p0)
}
Les mappages d'index de sortie vers entrée pour p0 seront (d0, d1) -> (d0, d1) et (d0, d1) -> (d1, d0). Cela signifie que pour calculer un élément de la sortie, nous pouvons avoir besoin de lire le paramètre d'entrée deux fois.
Une entrée, carte d'indexation dédupliquée
![]()
Il peut arriver que les mappages d'indexation soient en fait identiques, même si cela n'est pas immédiatement évident.
f {
p0 = f32[20, 10, 50] parameter(0)
lhs_transpose_1 = f32[10, 20, 50] transpose(p0), dimensions={1, 0, 2}
lhs_e = f32[10, 20, 50] exponential(lhs_transpose_1)
lhs_transpose_2 = f32[10, 50, 20] transpose(lhs_e), dimensions={0, 2, 1}
rhs_transpose_1 = f32[50, 10, 20] transpose(p0), dimensions={2, 1, 0}
rhs_log = f32[50, 10, 20] exponential(rhs_transpose_1)
rhs_transpose_2 = f32[10, 50, 20] transpose(rhs_log), dimensions={1, 0, 2}
ROOT output = f32[10, 50, 20] add(lhs_transpose_2, rhs_transpose_2)
}
Dans ce cas, la carte d'indexation de la sortie à l'entrée pour p0 est simplement (d0, d1, d2) -> (d2, d0, d1).
Softmax
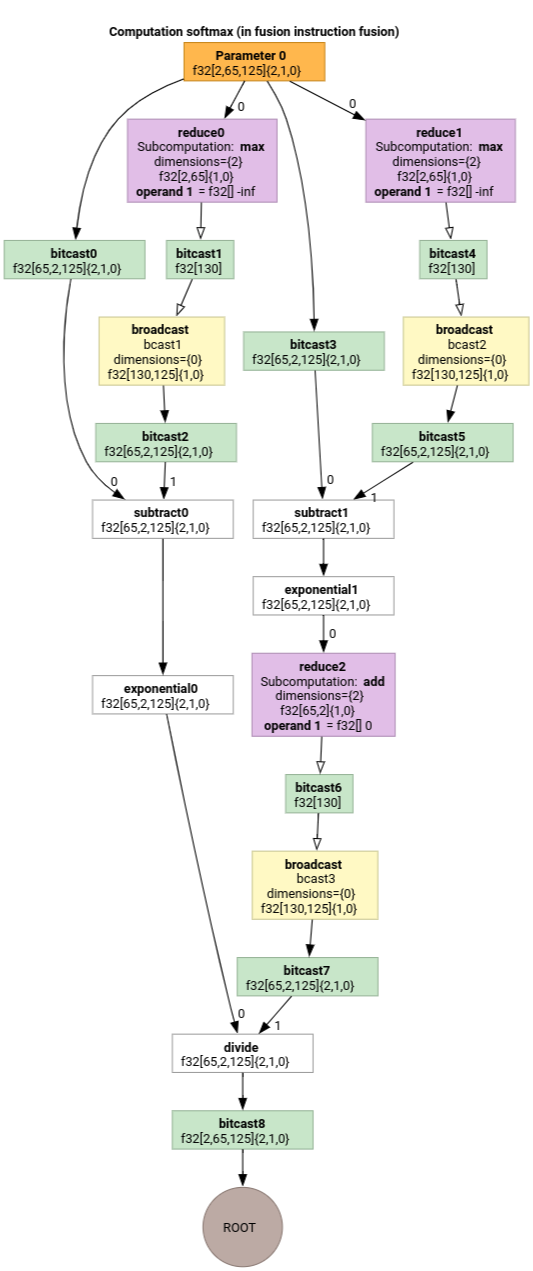
Mappages d'index de sortie vers entrée pour parameter 0 pour softmax :
(d0, d1, d2)[s0] -> (d0, d1, s0),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124],
s0 in [0, 124]
et
(d0, d1, d2) -> (d0, d1, d2),
domain:
d0 in [0, 1],
d1 in [0, 64],
d2 in [0, 124]
où s0 fait référence à la dimension la plus intérieure de l'entrée.
Pour obtenir d'autres exemples, consultez indexing_analysis_test.cc.
Simplificateur de l'indexation des cartes
Le simplificateur par défaut pour mlir::AffineMap en amont ne peut faire aucune hypothèse sur les plages de dimensions/symboles. Par conséquent, il ne peut pas simplifier efficacement les expressions avec mod et div.
Nous pouvons exploiter les connaissances sur les limites inférieure et supérieure des sous-expressions dans les mappages affines pour les simplifier encore plus.
Le simplificateur peut réécrire les expressions suivantes.
(d0, d1) -> (d0 + d1 floordiv 16, d1 mod 16)pour d dans[0, 6] x [0, 14]devient(d0, d1) -> (d0, d1)(d0, d1, d2) -> ((100d0 + 10d1 + d2) floorDiv 100, ((100d0 + 10d1 + d2) mod 100) floordiv 10, d2 mod 10)pourdi in [0, 9]devient(d0, d1, d2) -> (d0, d1, d2).(d0, d1, d2) -> ((16d0 + 4d1 + d2) floordiv 8, (16d0 + 4d1 + d2) mod 8)pourd_i in [0, 9]devient(d0, d1, d2) -> (2d0 + (4d1 + d2) floordiv 8,(4d1 + d2) mod 8).(d0, d1) -> (-(-11d0 - d1 + 109) floordiv 11 + 9)pour d dans[0, 9] x [0, 10]devient(d0, d1) -> (d0).
Le simplificateur de carte d'indexation nous permet de comprendre que certaines des remises en forme chaînées dans HLO s'annulent mutuellement.
p0 = f32[10, 10, 10] parameter(0)
reshape1 = f32[50, 20] reshape(p0)
reshape2 = f32[10, 10, 10] reshape(reshape1)
Après la composition des cartes d'indexation et leur simplification, nous obtenons
(d0, d1, d2) -> (d0, d1, d2).
La simplification de la carte d'indexation simplifie également les contraintes.
- Les contraintes de type
lower_bound <= affine_expr (floordiv, +, -, *) constant <= upper_boundsont réécrites sous la formeupdated_lower_bound <= affine_expr <= updated_upped_bound. - Les contraintes toujours satisfaites, par exemple
d0 + s0 in [0, 20]pourd0 in [0, 5]ets0 in [1, 3], sont éliminées. - Les expressions affines dans les contraintes sont optimisées comme la carte affine d'indexation ci-dessus.
Pour en savoir plus, consultez indexing_map_test.cc.