
এই ডকুমেন্টে MXLA-এর সমস্যা ডিবাগ করার একটি সাধারণ কার্যপ্রবাহ বর্ণনা করা হয়েছে।
পূর্বশর্ত
- JAX 0.6 বা তার উচ্চতর সংস্করণ ব্যবহার করুন এবং JAX ডিস্ট্রিবিউটেড সার্ভিস সক্রিয় করুন। JAX-এর এই সংস্করণে অতিরিক্ত লগিং রয়েছে যা কোন ওয়ার্কারগুলিতে সমস্যা হচ্ছে তা শনাক্ত করতে সাহায্য করতে পারে।
- (ঐচ্ছিক) আপনার ওয়ার্কলোড ইনিশিয়ালাইজ করার সময় --xla_dump_to ফ্ল্যাগ ব্যবহার করে একটি HLO ডাম্প তৈরি করুন। এই বিষয়ে XLA ডকুমেন্টেশনে আলোচনা করা হয়েছে।
- (ঐচ্ছিক) টিপিইউ প্রোগ্রাম নির্বাহের স্থিতির বিশদ লগিং সক্রিয় করতে --vmodule=real_program_continuator=1 সেট করুন।
ফ্লো চার্ট
নিচের ফ্লোচার্টটি ডিবাগিং প্রক্রিয়াটি তুলে ধরেছে। প্রতিটি ধাপের বিস্তারিত প্লেবুক পেতে, চার্টে সংশ্লিষ্ট আইটেমটিতে ক্লিক করুন।
ঝুলছে
মেগাস্কেল হ্যাং ডিটেক্টেড ত্রুটিটি সনাক্ত করুন
আপনার TPU ওয়ার্কার লগ-এ যদি নিম্নলিখিত ত্রুটি বার্তাটি দেখতে পান, তাহলে এর অর্থ হলো কোনো অগ্রগতি শনাক্ত করতে না পারায় MXLA-এর টাইম আউট হয়ে গেছে:
Megascale hang detected: Timed out waiting for 4 graphs to complete at launch_id 13650. Already completed: 100. StepGloballyInProgress: true. Timeout: 1m
- কর্মীরা প্রক্রিয়াকরণের জন্য একজন সমন্বয়কারীর কাছে ত্রুটিগুলো জানাবেন।
- Pathways জবগুলির ক্ষেত্রে: ডাইজেস্টটি
resource_managerজবের লগ-এ পাওয়া যাবে। - McJAX জবগুলোর ক্ষেত্রে: লগগুলো MXLA Coordinator-এ পাওয়া যাবে। এটি সাধারণত স্লাইস ০-এর টাস্ক ০ হয়ে থাকে।
- Pathways জবগুলির ক্ষেত্রে: ডাইজেস্টটি
- ত্রুটি শনাক্ত হওয়ার সময়ের আশেপাশের লগগুলো পরীক্ষা করুন এবং
Megascale detects a hangলেখাটি খুঁজুন। - শনাক্তকৃত কারণের ভিত্তিতে সমস্যাটি নির্ণয় করতে নিচের ধাপগুলো অনুসরণ করুন।
রোগ নির্ণয়
টিপিইউ অবস্থা ব্যাখ্যা করা
MXLA হ্যাং নির্ণয় করার আগে, TPU স্টেটস রিপোর্ট ফরম্যাটটি বোঝা জরুরি। নিচে একটি নমুনা রিপোর্ট দেওয়া হলো:
Full error digest:
Potential cause: <determined_cause>
Potential culprit workers: <task_name>
First error timestamp: <timestamp>
First error type: <error_type>
TPU states:
Launch ID: <launch_id>
Module: jit.step_fn Fingerprint: <fingerprint>
Sample worker: <task_name>@<host_name>:<tpu_chip>:<tpu_core>
Tag:PC breakdown:
<num_cores>@<location>(HLO): [<task_name>:<host_name>@<tpu_chip>:<tpu_core>, ...]
...
ত্রুটিপূর্ণ টিপিইউ চিপ (টেনসর কোর বা স্পার্স কোর)
Megascale detects a hang that is likely caused by bad TPU chips on the following hosts. Please remove the hosts from the fleet and restart the workload. If problem persists please contact Megascale XLA team.
The host that have bad TPUs are: <host_name>
Full error digest:
Potential cause: Bad TPU chips
Potential culprit workers: <job_name>/<task_id>:<host_name>
এই ত্রুটির অর্থ হলো, সমস্যাটি সম্ভবত একটি ত্রুটিপূর্ণ TPU চিপের কারণে হচ্ছে। ত্রুটির বার্তায় ত্রুটিপূর্ণ চিপটির জব ইনফরমেশন এবং হোস্ট নেম অন্তর্ভুক্ত থাকা উচিত। উপরের উদাহরণে, ত্রুটিপূর্ণ চিপটি <host_name> হোস্টে রয়েছে, যা <job_name> জবের <task_id> টাস্ককে প্রভাবিত করছে। আপনি আপনার জবটি কনফিগার করে ওই হোস্টটিকে এড়িয়ে যেতে পারেন।
নেটওয়ার্কিং সমস্যা
Megascale detects a hang that is likely caused by a networking issue. Please examine the underlying networking stack for the following hosts.
The hosts are: <host_name>
Full error digest:
Potential cause: Networking issue
Potential culprit workers: <host_name_1>, <host_name_2>
এই ত্রুটিটি নির্দেশ করে যে আপনার কাজটি একটি ব্যর্থ নেটওয়ার্ক লিঙ্কের সম্মুখীন হয়েছে। ত্রুটির বার্তায় কাজের নাম, টাস্ক আইডি এবং ত্রুটিপূর্ণ নেটওয়ার্ক লিঙ্কের হোস্টের নাম এক বা একাধিক বার অন্তর্ভুক্ত থাকা উচিত। উপরের উদাহরণে, ত্রুটিপূর্ণ নেটওয়ার্ক লিঙ্কটি host_name_1 এবং host_name_2 হোস্টের মধ্যে অবস্থিত। কখনও কখনও, যদি একটিমাত্র হোস্ট একাধিক ভাঙা নেটওয়ার্ক লিঙ্কে উপস্থিত থাকে, তাহলে RapidEye ত্রুটিপূর্ণ হোস্টটিকে আরও সুনির্দিষ্টভাবে চিহ্নিত করতে পারে।
বিভিন্ন মডিউল
Megascale detects a hang that is likely caused by running different modules on different devices. Please confirm that all workers is running the exact same program. It can also be caused by a hang in a subset of devices and the unaffected devices have moved on to the next program. Please inspect the digest below to further root cause the hang.
Example hosts that have different HLO modules: <host_name>
Full error digest:
Potential cause: Different module
Potential culprit workers: <host_name>
TPU stats:
<host_name>: <pc>
TPU states:
Module: jit_loss_and_grad
Fingerprint: <fingerprint>
Launch ID: 193
<tag>:<pc>(<hlo>): <host_name>
Module: jit_optimizer_apply
Fingerprint: <fingerprint>
Launch ID: 0
<tag>:<pc>(<hlo>): <host_name>
এই ত্রুটিটি নির্দেশ করতে পারে যে কিছু সংখ্যক ওয়ার্কার হ্যাং হয়ে গেছে, যার ফলে তারা বর্তমান মডিউলে আটকে আছে, অথচ অক্ষত ওয়ার্কাররা পরবর্তী মডিউলে চলে যাচ্ছে। মূল কারণ শনাক্ত করতে, লগ-এ RapidEye দ্বারা প্রিন্ট করা ডাইজেস্টটি পরীক্ষা করুন।
লগ-এর TPU states সেকশনটি দেখায় কোন ওয়ার্কারে কোন মডিউলগুলো চলছে। উপরের উদাহরণটিতে, ওয়ার্কারগুলো ভিন্ন ভিন্ন মডিউল চালাচ্ছে: jit_loss_and_grad এবং jit_optimizer_apply ।
HLO মডিউলের জন্য ফিঙ্গারপ্রিন্ট অমিল
Megascale detects a hang that is likely caused by inconsistent HLO module compilation across workers. This is likely a bug in JAX tracing or XLA compiler. Please inspect the HLO dumps to confirm the root cause.
Example hosts that have different HLO fingerprints: <host_name>
Full error digest:
Potential cause: Fingerprint mismatch
Potential culprit workers: <host_name>
TPU stats:
Module: reduce.31
Fingerprint: <fingerprint_1>
Launch ID: 37
<tag>:<pc>(<hlo>): <host_name>
Module: reduce.31
Fingerprint: <fingerprint_2>
Launch ID: 40
<tag>:<pc>(<hlo>): <host_name>
এই লগ বার্তাটি নির্দেশ করে যে, বিভিন্ন ওয়ার্কারের মধ্যে HLO মডিউল কম্পাইলেশনের অসামঞ্জস্যতার কারণে সম্ভবত হ্যাংটি ঘটেছে, যা সম্ভবত JAX ট্রেসিং বা XLA কম্পাইলারের কোনো সমস্যার কারণে হতে পারে। আপনি যদি এই লগটি দেখতে পান, তাহলে আরও ডিবাগিংয়ের জন্য দায়ী ওয়ার্কারগুলো থেকে HLO ডাম্প সংগ্রহ করতে এই ধাপগুলো অনুসরণ করুন।
ডেটা ইনপুট আটকে গেছে
Megascale detects a hang that is likely caused by data input stall on the
following hosts. Please check the workers to make sure the data input pipeline
is working properly.
The host that have data input stalls are: <host_name>
এই ত্রুটির অর্থ হলো, সমস্ত ডিভাইস একই প্রোগ্রাম চালু করেছিল, কিন্তু সিস্টেমের সময়সীমা শেষ হওয়ার আগে প্রোগ্রামটিতে ইনপুট ডেটা সরবরাহ করা হয়নি। এই সমস্যাটি সমাধান করতে, নিশ্চিত করুন যে:
- শনাক্তকৃত হোস্টগুলো ইনপুট ডেটাসোর্স অ্যাক্সেস করতে পারে।
- শনাক্তকৃত হোস্টগুলো ইনপুট ডেটাসোর্সটি সঠিকভাবে লোড ও পার্স করছে।
- নিশ্চিত করুন যে শনাক্তকৃত হোস্টগুলো ইনপুট ডেটাসোর্স থেকে ডেটা পড়ার ক্ষেত্রে থ্রটলড হচ্ছে না।
অপূরণীয় ত্রুটি
Some workers have halted with an unrecoverable error:
<worker> : {some error}
Please inspect the error log of these workers:
<worker>
এই ত্রুটির অর্থ হলো, এমন কোনো সমস্যা হয়েছিল যার কারণে প্রোগ্রামটি সঠিকভাবে চলতে পারেনি এবং তা স্বয়ংক্রিয়ভাবে সমাধান করা সম্ভব হয়নি। এই ত্রুটিটিকে সুনির্দিষ্টভাবে কোনো শ্রেণিতে ফেলা যায়নি। ত্রুটি প্রতিবেদনে উল্লিখিত ওয়ার্কার(গুলি)-এর লগ পরীক্ষা করে আরও তথ্য পাওয়া যেতে পারে।
যদি ত্রুটিটি কোনো নির্দিষ্ট মেশিনের ক্ষেত্রেই ঘটছে বলে মনে হয় (যেমন, টিপিইউ থেকে হোস্টে ডেটা কপি করতে ব্যর্থ হওয়া), তাহলে আপনি আপনার জবটি কনফিগার করে সেই হোস্টগুলোকে এড়িয়ে যেতে পারেন।
অজানা ত্রুটি
Megascale detects a hang but cannot determine the root cause. Please inspect the
full digest below.
এই ত্রুটির অর্থ হলো, এমন কোনো সমস্যা হয়েছিল যা প্রোগ্রামটিকে সঠিকভাবে চলতে বাধা দিয়েছে এবং যা স্বয়ংক্রিয়ভাবে সমাধান করা সম্ভব হয়নি। এই ত্রুটিটিকে সুনির্দিষ্টভাবে শ্রেণিবদ্ধ করা যায়নি এবং এ বিষয়ে আর কোনো তথ্য উপলব্ধ নেই।
কর্মক্ষমতা
একটি এক্সপ্রফ সেশন নিন
আপনার সমস্যাযুক্ত রানটির জন্য একটি XProf ট্রেস তৈরি করতে XProf ডকুমেন্টেশনে দেওয়া নির্দেশাবলী অনুসরণ করুন।
ম্যাপ করা ডিএমএ বাফারের ঘাটতি আছে কিনা তা পরীক্ষা করুন।
TPU-এর সাথে DMA আদান-প্রদানের জন্য ব্যবহার করার আগে Megascale XLA রানটাইমকে হোস্ট মেমরি রেজিস্টার করতে হয়। প্রসেসটি শুরু হওয়ার পরপরই এটি ঘটে। যদি আপনি স্টেডি-স্টেটে এই রেজিস্ট্রেশনগুলো ( MapDmaBuffer কল) দেখতে পান, তাহলে বুঝতে হবে কোনো সমস্যা হয়েছে। XProf Trace Viewer-এ এই কলগুলোর উপস্থিতি খুঁজে দেখুন। রেফারেন্সের জন্য নিচের স্ক্রিনশটটি দেখুন।
পরামর্শ: ওয়ার্কারের সঠিক নামটি দিয়ে অনুসন্ধান করুন, কারণ একই রকম বা কাছাকাছি নামের অন্যান্য ওয়ার্কারও থাকতে পারে। এছাড়াও, পেজটিতে “MapDmaBuffer” শব্দটি দিয়ে অনুসন্ধান করুন।
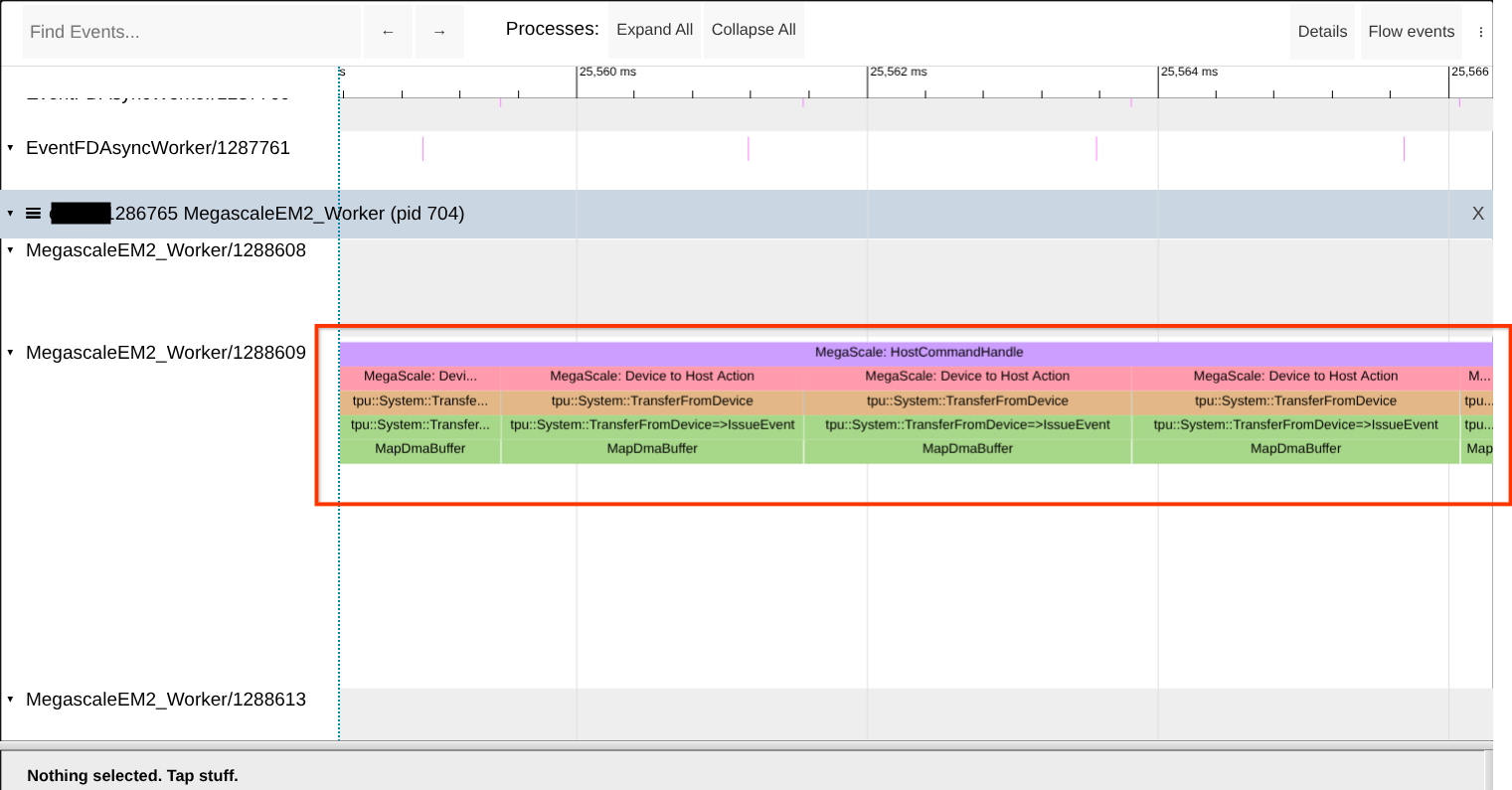
যদি সমস্যাটি দেখা যায়, তাহলে --megascale_grpc_premap_memory_bytes এর মান বাড়িয়ে প্রিম্যাপড মেমরি অঞ্চলের আকার বৃদ্ধি করার চেষ্টা করুন, জবটি পুনরায় চালু করুন এবং তারপর আবার পরীক্ষা করুন।
নেটওয়ার্ক স্থানান্তরের সময় মেমরি কপিগুলি পরীক্ষা করুন
মেগাস্কেল XLA নেটওয়ার্ক ট্রান্সফার ডিজাইনগতভাবেই জিরো-কপি হয়ে থাকে। তবে, এমন কিছু ক্ষেত্র রয়েছে যেখানে মেমরি কপি ঘটে এবং এর ফলে পারফরম্যান্সের অবনতি হয়। নিচের উদাহরণ স্ক্রিনশটে দেখানো অনুযায়ী, মেগাস্কেলের 'কমিউনিকেশন ট্রান্সপোর্ট' ট্রেসে মেমরি কপির সন্ধান করুন।
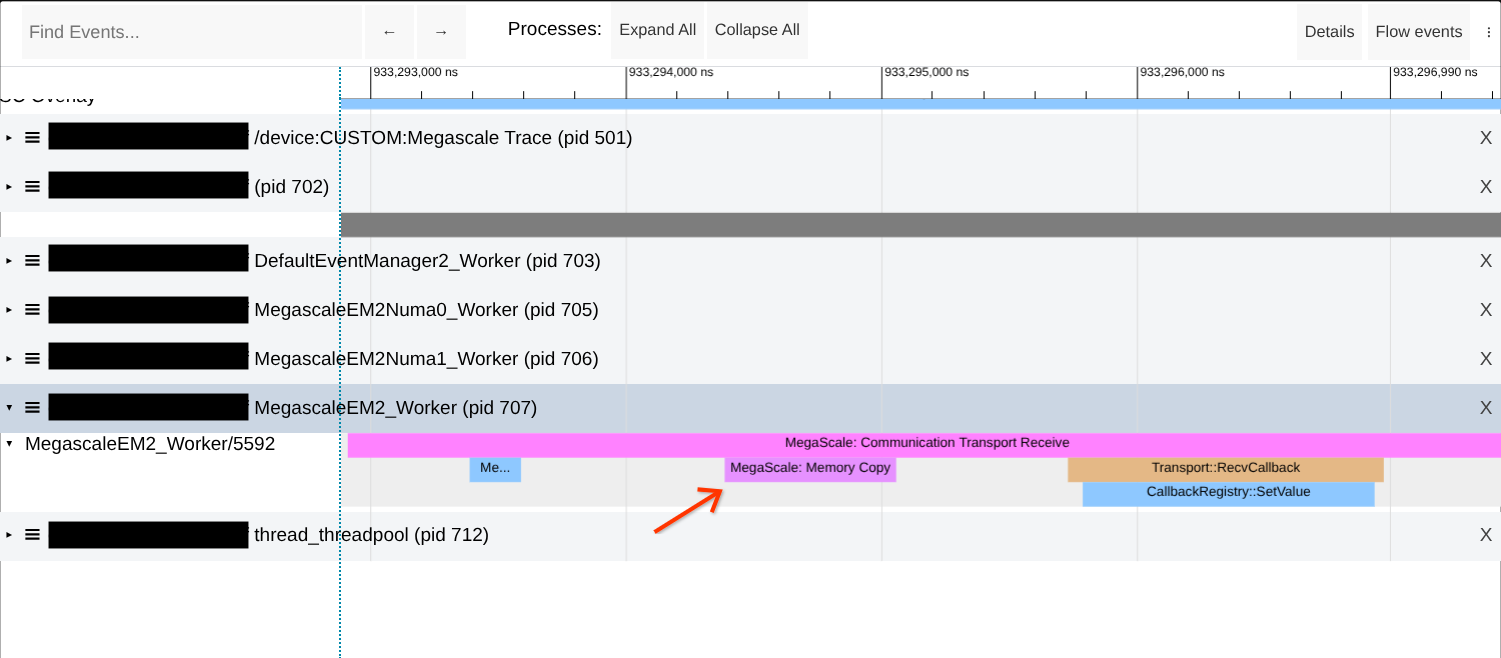
যদি সমস্যাটি দেখা যায়, তাহলে --megascale_grpc_premap_memory_bytes এর মান বাড়িয়ে প্রিম্যাপড মেমরি অঞ্চলের আকার বৃদ্ধি করার চেষ্টা করুন, জবটি পুনরায় চালু করুন এবং তারপর আবার পরীক্ষা করুন।
নেটওয়ার্ক বিশ্লেষণ
MegaScale একটি XProf ট্রেস ব্যবহার করে নেটওয়ার্ক পারফরম্যান্স বিশ্লেষণ করতে সাহায্য করার জন্য একটি Colab নোটবুকও প্রদান করে।
এই টুলটি নিম্নলিখিত কাজগুলো করতে ব্যবহার করা যেতে পারে:
- সম্ভাব্য নেটওয়ার্ক ধীরগতি বা হোস্টের মন্থরতা শনাক্ত করতে ট্রান্সফার ল্যাটেন্সি পরীক্ষা করুন।
- আপনার ওয়ার্কলোডটি প্রচুর সংখ্যক ছোট ট্রান্সফারের পরিবর্তে কম সংখ্যক বড় ট্রান্সফার ব্যবহার করার জন্য অপ্টিমাইজ করা হয়েছে কিনা তা শনাক্ত করতে ট্রান্সফার সাইজগুলো পরীক্ষা করুন।
- আপনার ওয়ার্কলোড অপটিমাইজ করা নেই কিনা এবং এটি আকস্মিকভাবে বিপুল সংখ্যক কালেক্টিভ তৈরি করে কিনা বা এতে সবসময় প্রচুর সংখ্যক পেন্ডিং কালেক্টিভ থাকে কিনা তা নির্ধারণ করুন।
- ওয়ার্কলোডটি নেটওয়ার্ক-বাউন্ড কিনা তা দেখতে নেটওয়ার্ক থ্রুপুট টাইমলাইনটি ভিজ্যুয়ালাইজ করুন।
- প্রতিটি হোস্টে সম্ভাব্য ত্রুটিপূর্ণ হার্ডওয়্যার শনাক্ত করতে {সোর্স, ডেস্টিনেশন} জোড়াগুলো পরীক্ষা করুন।
সম্মিলিত স্ল্যাক খুব ছোট
আপনার ওয়ার্কলোড যে কম্পিউট/কমিউনিকেশন ওভারল্যাপের জন্য অপ্টিমাইজ করা নেই, তার একটি লক্ষণ হলো কিছু নির্দিষ্ট কালেক্টিভের ক্ষেত্রে কম স্ল্যাক টাইম দেখা যাওয়া। এর ফলে ট্রেস ভিউয়ারে প্রত্যাশার চেয়ে দীর্ঘ recv-done ট্রেস দেখা যেতে পারে, অথবা কালেক্টিভগুলোর স্ল্যাক টাইম শূন্য বা প্রায়-শূন্য হতে পারে।
যদি এমনটা হয়, তবে আপনার ওয়ার্কলোডের মধ্যে থাকা সেইসব প্রতিবন্ধকতা চিহ্নিত করার চেষ্টা করুন, যার কারণে আপনার প্রোগ্রামের বিভিন্ন অংশ কম্পিউট এবং নেটওয়ার্ক কমিউনিকেশনের ক্ষেত্রে ওভারল্যাপ করতে পারছে না।
উচ্চ নেটওয়ার্ক ব্যান্ডউইথের চাহিদা
আপনার মডেল XProf-এ যদি recv-done op ল্যাটেন্সি দীর্ঘ হতে দেখেন, তবে এটি একটি ইঙ্গিত হতে পারে যে মডেলটি স্টেপ ফাংশনের ঐ অংশগুলিতে 'ব্যান্ডউইথ বাউন্ড' (অর্থাৎ সিস্টেমের উপলব্ধ নেটওয়ার্ক ব্যান্ডউইথ দ্বারা অবরুদ্ধ)।
আপনি আপনার মডেলের জন্য নেটওয়ার্ক ব্যবহারের একটি টাইমলাইন তৈরি করতে পারেন। যদি আপনি পুরো ধাপ জুড়ে ধারাবাহিকভাবে উচ্চ নেটওয়ার্ক ব্যবহার দেখতে পান, অথবা নির্দিষ্ট কিছু অঞ্চলে ব্যবহারের পরিমাণে বড় ধরনের বৃদ্ধি লক্ষ্য করেন, তাহলে আপনার মডেলটি সেই অঞ্চলগুলিতে ব্যান্ডউইথের সীমাবদ্ধতার সম্মুখীন হতে পারে।
নেটওয়ার্ক ব্যবহারের একটি টাইমলাইন তৈরি করতে নেটওয়ার্ক অ্যানালাইসিস ব্যবহার করুন: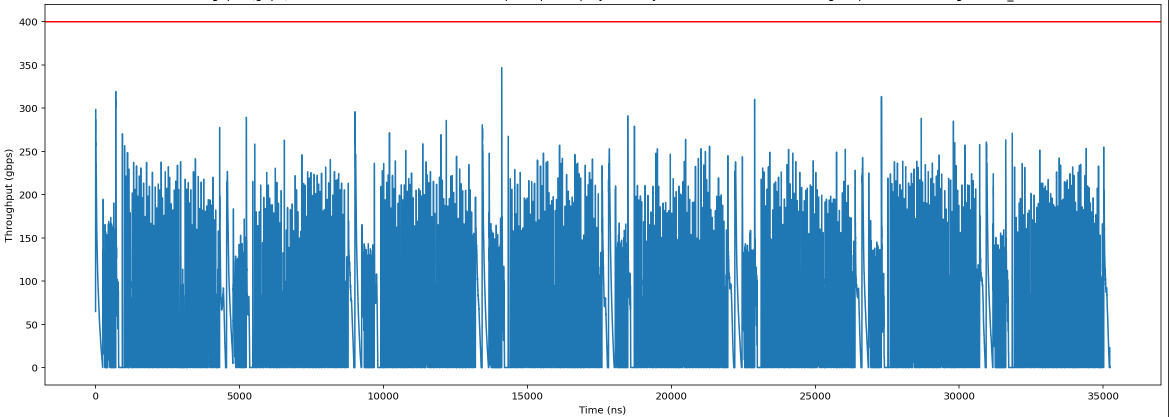
ব্যান্ডউইথ সীমাবদ্ধ মডেলের প্রভাব কমাতে, আপনি নিম্নলিখিত পদক্ষেপগুলো নিতে পারেন:
- আপনার মডেলের কালেক্টিভ স্ল্যাক (Collective Slack) পরীক্ষা করুন। যেসব মডেলে অনেকগুলো কালেক্টিভের স্ল্যাক কম থাকে, সেসব মডেলে ব্যান্ডউইথ-বাউন্ড অঞ্চল (bandwidth bound regions) থাকবে।
- নেটওয়ার্ক সেটিংস অপ্টিমাইজ করা হয়েছে কিনা তা নিশ্চিত করুন।
- আপনার মডেলের কাঠামো এবং ডেটা শার্ডিং পরীক্ষা করে দেখুন যে কম্পিউটেশন ও কমিউনিকেশনের ওভারল্যাপ বাড়ানোর কোনো উপায় আছে কিনা।
- (ডেটা প্যারালাল মডেল) নিশ্চিত করুন যে, কমিউনিকেশনের সাথে ওভারল্যাপ করার জন্য প্রতিটি লোকাল রেপ্লিকাতে আপনার পর্যাপ্ত ব্যাচ সাইজ রয়েছে।
উচ্চ নেটওয়ার্ক লেটেন্সি
যদি ব্যান্ডউইথ পরিপূর্ণ না থাকে, তাহলে আপনি RPC ল্যাটেন্সি টাইমলাইন তৈরি করতে পারেন। যদি দেখেন যে RPC ল্যাটেন্সি ক্রমাগত বা মাঝে মাঝে বেশি থাকছে, এর মানে হলো MXLA RPC-গুলোতে কিছু সমস্যা আছে।
নেটওয়ার্ক অ্যানালাইসিস ব্যবহার করে RPC ল্যাটেন্সি টাইমলাইন তৈরি করুন, নিম্নলিখিত উদাহরণটি দেখায় যে এখানে কিছু বিক্ষিপ্ত ২০০ms দীর্ঘ RPC ল্যাটেন্সি রয়েছে। 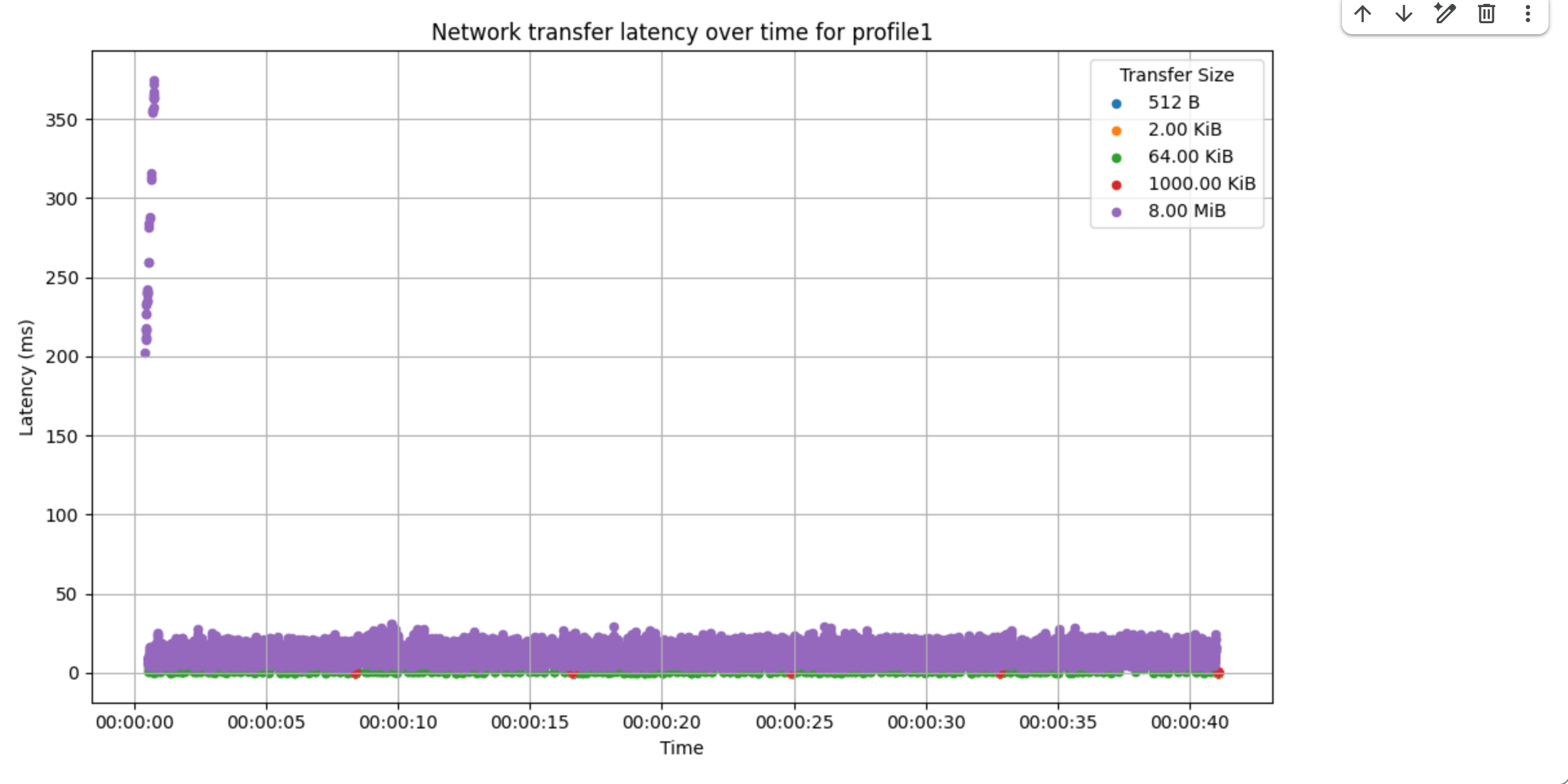
সর্বোত্তম নেটওয়ার্ক সেটিংস নিশ্চিত করুন
ক্লাউড পরিবেশে উচ্চ RPC ল্যাটেন্সির কারণ প্রায়শই ত্রুটিপূর্ণ TCP কনফিগারেশন হয়ে থাকে। অনুগ্রহ করে নিশ্চিত করুন যে কন্টেইনারের মধ্যে সমস্ত TCP প্যারামিটার সঠিকভাবে কনফিগার করা আছে কিনা।
যদি কোনো TCP প্যারামিটার সঠিকভাবে কনফিগার করা না থাকে, তাহলে সেগুলো যথাযথভাবে কনফিগার করার জন্য Google Cloud ML Compute Services (CMCS) টিমের সাথে পরামর্শ করুন।
এইচএলও ডাম্প
TPU ওয়ার্কারের লোকাল ফাইলসিস্টেমে HLO ডাম্প করার জন্য অনুগ্রহ করে এই ধাপগুলো অনুসরণ করুন। XLA বা Megascale টিমের সাথে শেয়ার করার জন্য আপনাকে ডাম্পটি GCS-এ আপলোড করতে হতে পারে।
পথভ্রষ্ট
ভবিষ্যৎ টুলিং সংক্রান্ত বিজ্ঞপ্তি: ক্লাউড টিপিইউ গ্রাহকদের বিচ্ছিন্ন সংযোগ শনাক্ত ও নির্ণয়ের জন্য আরও সুবিন্যস্ত অভিজ্ঞতা প্রদানের লক্ষ্যে গুগল ডায়াগনস্টিক ড্যাশবোর্ডের ওপেন-সোর্স সংস্করণ তৈরিতে সক্রিয়ভাবে কাজ করছে। এগুলি শীঘ্রই উপলব্ধ হবে।