
این سند یک گردش کار کلی برای اشکالزدایی مشکلات MXLA را شرح میدهد.
پیشنیاز
- از JAX 0.6 یا بالاتر استفاده کنید و سرویس توزیعشدهی JAX را فعال کنید. این نسخه از JAX شامل گزارشگیریهای اضافی است که میتواند به شناسایی اینکه کدام کارگران با مشکل مواجه هستند کمک کند.
- (اختیاری) هنگام مقداردهی اولیه بار کاری خود، با استفاده از فلگ --xla_dump_to یک HLO dump ایجاد کنید. این موضوع در مستندات XLA مورد بحث قرار گرفته است.
- (اختیاری) برای فعال کردن ثبت وقایع وضعیت اجرای برنامه TPU، مقدار --vmodule=real_program_continuator=1 را تنظیم کنید.
نمودار جریان
فلوچارت زیر فرآیند اشکالزدایی را نشان میدهد. برای دسترسی به دستورالعملهای دقیق هر مرحله، روی مورد مربوطه در نمودار کلیک کنید.
آویزان است
خطای شناسایی هنگ مگااسکیل را پیدا کنید
اگر پیام خطای زیر را در گزارشهای TPU worker خود مشاهده کردید، به این معنی است که MXLA پس از تشخیص عدم پیشرفت، مهلتش تمام شده است:
Megascale hang detected: Timed out waiting for 4 graphs to complete at launch_id 13650. Already completed: 100. StepGloballyInProgress: true. Timeout: 1m
- کارگران خطاها را برای رسیدگی به هماهنگکننده گزارش خواهند داد.
- برای کارهای Pathways : خلاصه را میتوان در گزارشهای مربوط به کار
resource_managerیافت. - برای کارهای McJAX : گزارشها را میتوان در MXLA Coordinator یافت. این معمولاً وظیفه شماره ۰ از برش شماره ۰ است.
- برای کارهای Pathways : خلاصه را میتوان در گزارشهای مربوط به کار
- لاگها را در زمان تشخیص خطا بررسی کنید و ببینید آیا
Megascale detects a hang. - برای تشخیص مشکل بر اساس علت شناسایی شده، مراحل زیر را دنبال کنید.
تشخیص
تفسیر وضعیت TPU
قبل از تشخیص مشکل هنگ کردن MXLA، درک فرمت گزارش وضعیت TPU مهم است. در زیر یک نمونه گزارش آمده است:
Full error digest:
Potential cause: <determined_cause>
Potential culprit workers: <task_name>
First error timestamp: <timestamp>
First error type: <error_type>
TPU states:
Launch ID: <launch_id>
Module: jit.step_fn Fingerprint: <fingerprint>
Sample worker: <task_name>@<host_name>:<tpu_chip>:<tpu_core>
Tag:PC breakdown:
<num_cores>@<location>(HLO): [<task_name>:<host_name>@<tpu_chip>:<tpu_core>, ...]
...
تراشه TPU خراب (هسته تنسور یا هسته پراکنده)
Megascale detects a hang that is likely caused by bad TPU chips on the following hosts. Please remove the hosts from the fleet and restart the workload. If problem persists please contact Megascale XLA team.
The host that have bad TPUs are: <host_name>
Full error digest:
Potential cause: Bad TPU chips
Potential culprit workers: <job_name>/<task_id>:<host_name>
این خطا به این معنی است که مشکل به طور بالقوه توسط یک تراشه TPU معیوب ایجاد شده است. پیام خطا باید شامل اطلاعات کار و نام میزبان تراشه معیوب باشد. در مثال بالا، تراشه معیوب روی میزبان <host_name> قرار دارد و بر وظیفه <task_id> کار <job_name> تأثیر میگذارد. میتوانید کار خود را طوری پیکربندی کنید که از آن میزبان اجتناب کند.
مشکل شبکه
Megascale detects a hang that is likely caused by a networking issue. Please examine the underlying networking stack for the following hosts.
The hosts are: <host_name>
Full error digest:
Potential cause: Networking issue
Potential culprit workers: <host_name_1>, <host_name_2>
این خطا نشان میدهد که کار شما با یک لینک شبکه ناموفق مواجه شده است. پیام خطا باید شامل یک یا دو نام کار، شناسه وظیفه، نام میزبان لینک شبکه معیوب باشد. در مثال بالا، لینک شبکه معیوب بین میزبان host_name_1 و host_name_2 قرار دارد. گاهی اوقات RapidEye میتواند میزبان معیوب را در صورت وجود یک میزبان واحد در چندین لینک شبکه معیوب، بیشتر بومیسازی کند.
ماژولهای مختلف
Megascale detects a hang that is likely caused by running different modules on different devices. Please confirm that all workers is running the exact same program. It can also be caused by a hang in a subset of devices and the unaffected devices have moved on to the next program. Please inspect the digest below to further root cause the hang.
Example hosts that have different HLO modules: <host_name>
Full error digest:
Potential cause: Different module
Potential culprit workers: <host_name>
TPU stats:
<host_name>: <pc>
TPU states:
Module: jit_loss_and_grad
Fingerprint: <fingerprint>
Launch ID: 193
<tag>:<pc>(<hlo>): <host_name>
Module: jit_optimizer_apply
Fingerprint: <fingerprint>
Launch ID: 0
<tag>:<pc>(<hlo>): <host_name>
این خطا ممکن است نشان دهد که در زیرمجموعهای از workerها، هنگی رخ داده است و باعث میشود آن workerها در ماژول فعلی گیر کنند، در حالی که workerهای دیگر به ماژول بعدی میروند. برای شناسایی علت اصلی، خلاصهای که توسط RapidEye در لاگها چاپ شده است را بررسی کنید.
بخش TPU states در لاگها نشان میدهد که کدام ماژولها روی کدام workerها اجرا میشوند. در مثال بالا، workerها ماژولهای مختلفی را اجرا میکنند: jit_loss_and_grad و jit_optimizer_apply .
عدم تطابق اثر انگشت برای ماژول HLO
Megascale detects a hang that is likely caused by inconsistent HLO module compilation across workers. This is likely a bug in JAX tracing or XLA compiler. Please inspect the HLO dumps to confirm the root cause.
Example hosts that have different HLO fingerprints: <host_name>
Full error digest:
Potential cause: Fingerprint mismatch
Potential culprit workers: <host_name>
TPU stats:
Module: reduce.31
Fingerprint: <fingerprint_1>
Launch ID: 37
<tag>:<pc>(<hlo>): <host_name>
Module: reduce.31
Fingerprint: <fingerprint_2>
Launch ID: 40
<tag>:<pc>(<hlo>): <host_name>
این پیام لاگ نشان میدهد که احتمالاً مشکل به دلیل کامپایل ناهماهنگ ماژول HLO در بین workerها، و احتمالاً به دلیل مشکلی در ردیابی JAX یا کامپایلر XLA، ایجاد شده است. اگر این لاگ را مشاهده کردید، برای جمعآوری dumpهای HLO از workerهای مقصر برای اشکالزدایی بیشتر، این مراحل را دنبال کنید.
غرفه ورودی داده
Megascale detects a hang that is likely caused by data input stall on the
following hosts. Please check the workers to make sure the data input pipeline
is working properly.
The host that have data input stalls are: <host_name>
این خطا به این معنی است که همه دستگاهها برنامه یکسانی را اجرا کردهاند، اما دادههای ورودی قبل از اتمام زمان سیستم به برنامه ارائه نشدهاند. برای رفع این مشکل، موارد زیر را تأیید کنید:
- میزبانهای شناساییشده میتوانند به منبع داده ورودی دسترسی داشته باشند.
- میزبانهای شناساییشده به درستی در حال بارگذاری/تجزیه منبع داده ورودی هستند.
- تأیید کنید که میزبانهای شناساییشده هنگام خواندن منبع داده ورودی، دچار اختلال نشوند.
خطای غیرقابل بازیابی
Some workers have halted with an unrecoverable error:
<worker> : {some error}
Please inspect the error log of these workers:
<worker>
این خطا به این معنی است که مشکلی وجود داشته که مانع از اجرای صحیح برنامه شده و به طور خودکار قابل بازیابی نیست. این خطا را نمیتوان به طور خاص طبقهبندی کرد. اطلاعات بیشتر را میتوان از بررسی گزارشهای مربوط به کارگر(ان) ذکر شده در گزارش خطا به دست آورد.
اگر به نظر میرسد خطا مختص دستگاه مورد نظر است (مثلاً عدم کپی کردن دادهها از TPU به میزبان)، میتوانید job خود را طوری پیکربندی کنید که از آن میزبانها اجتناب کند.
خطای ناشناخته
Megascale detects a hang but cannot determine the root cause. Please inspect the
full digest below.
این خطا به این معنی است که مشکلی وجود داشته که مانع از اجرای صحیح برنامه شده و به طور خودکار قابل بازیابی نیست. این خطا را نمیتوان به طور خاص طبقهبندی کرد و اطلاعات خطای بیشتری در دسترس نیست.
عملکرد
یک جلسه XProf دریافت کنید
برای ایجاد یک مسیر XProf برای اجرای مشکلساز خود، دستورالعملهای موجود در مستندات XProf را دنبال کنید.
کمبود بافرهای DMA نگاشت شده را بررسی کنید
زمان اجرای Megascale XLA قبل از اینکه بتواند برای DMAها به و از TPU استفاده شود، باید حافظه میزبان را ثبت کند. این اتفاق کمی پس از شروع فرآیند رخ میدهد. اگر این ثبتها (فراخوانیهای MapDmaBuffer ) را در حالت پایدار مشاهده کردید، نشان میدهد که مشکلی وجود دارد. به دنبال وجود این فراخوانیها در XProf Trace Viewer باشید. برای مرجع، به تصویر زیر مراجعه کنید.
نکته: نام دقیق worker را جستجو کنید، زیرا ممکن است workerهای دیگری با نامهای مشابه یا نزدیک به آن وجود داشته باشند. همچنین میتوانید عبارت «MapDmaBuffer» را در صفحه جستجو کنید.
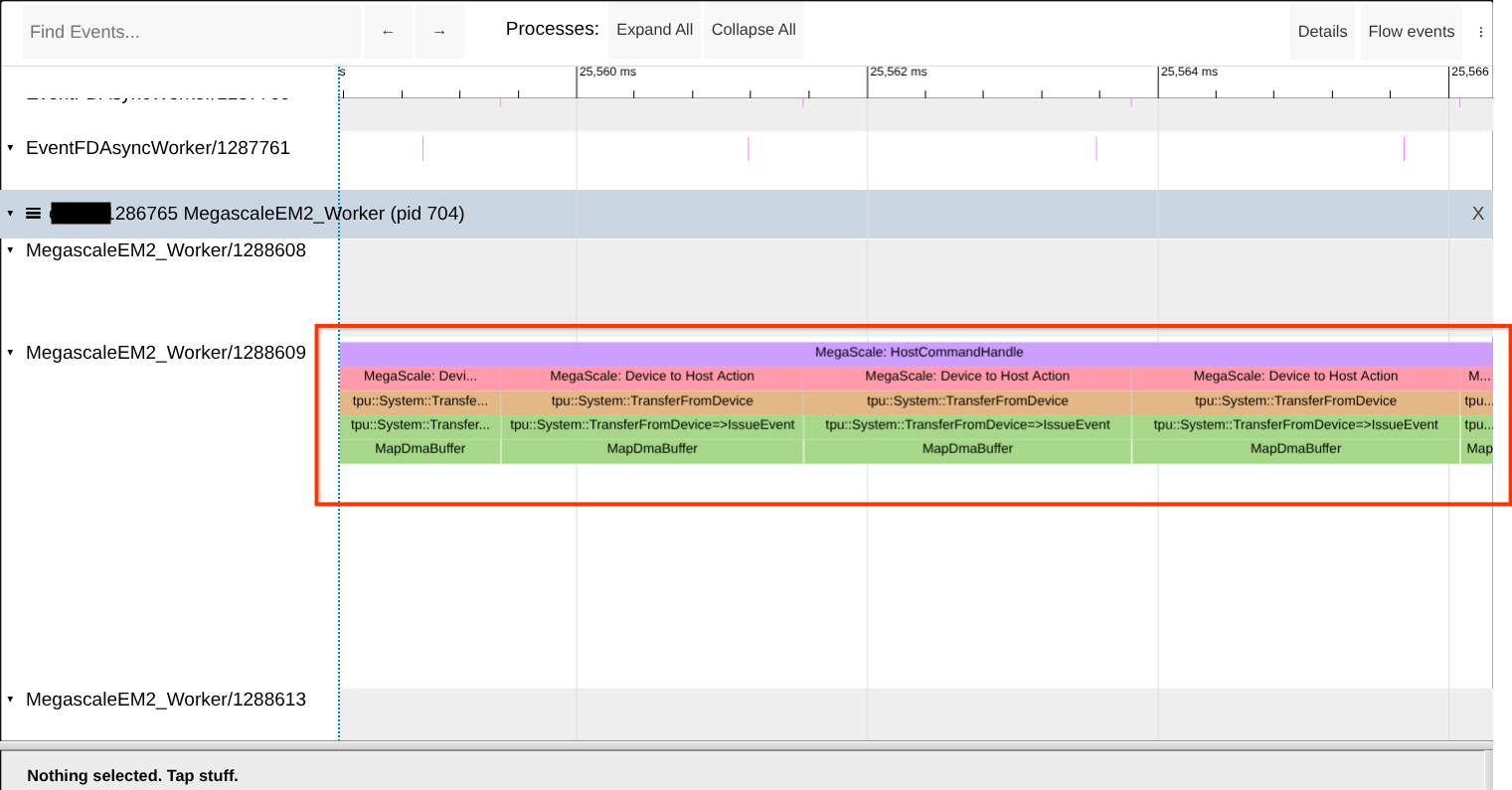
اگر مشکل مشاهده شد، سعی کنید اندازه ناحیه حافظه از پیش نگاشت شده را با افزایش مقدار --megascale_grpc_premap_memory_bytes افزایش دهید، کار را مجدداً راهاندازی کنید و سپس دوباره بررسی کنید.
بررسی کپیهای حافظه در حین انتقال شبکه
انتقالهای شبکهی XLA مگااسکیل از اساس بدون کپی طراحی شدهاند. با این حال، مواردی وجود دارد که کپیهای حافظه رخ میدهند و باعث افت عملکرد میشوند. همانطور که در تصویر زیر نشان داده شده است، در مسیرهای "انتقال ارتباطات" مگااسکیل، کپیهای حافظه را جستجو کنید.
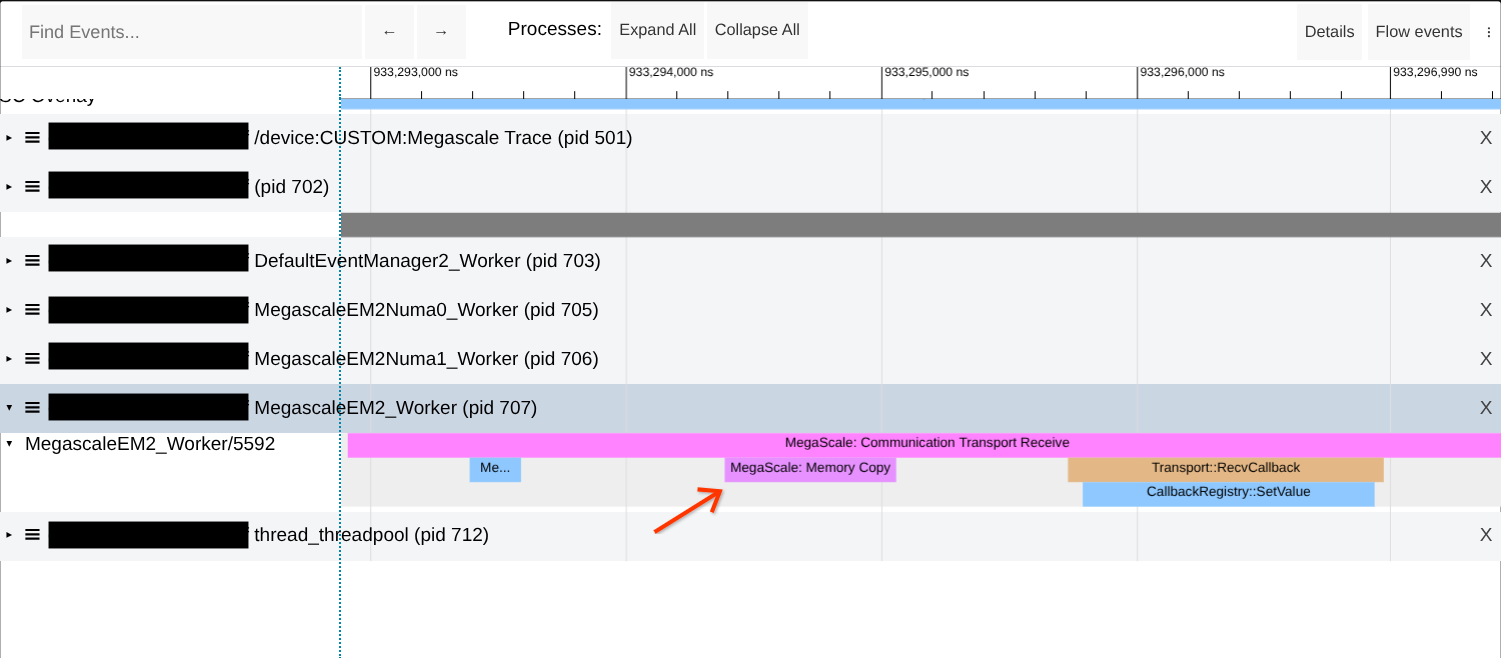
اگر مشکل مشاهده شد، سعی کنید اندازه ناحیه حافظه از پیش نگاشت شده را با افزایش مقدار --megascale_grpc_premap_memory_bytes افزایش دهید، کار را مجدداً راهاندازی کنید و سپس دوباره بررسی کنید.
تحلیل شبکه
مگااسکیل همچنین یک دفترچه یادداشت کولاب (Colab) ارائه میدهد تا به تجزیه و تحلیل عملکرد شبکه با استفاده از ردیابی XProf کمک کند.
از این ابزار میتوان برای انجام موارد زیر استفاده کرد:
- تأخیرهای انتقال را بررسی کنید تا کندیهای احتمالی شبکه یا کندی میزبان را شناسایی کنید.
- اندازههای انتقال را بررسی کنید تا مشخص شود که آیا حجم کاری شما برای استفاده از تعداد کمتری از انتقالهای بزرگتر در مقایسه با تعداد زیادی از انتقالهای کوچک بهینه شده است یا خیر.
- مشخص کنید که آیا حجم کاری شما بهینه نشده است و collecti های پشت سر هم تولید میکند یا همیشه تعداد زیادی collecti های در انتظار دارد.
- جدول زمانی توان عملیاتی شبکه را تجسم کنید تا ببینید آیا حجم کار به شبکه محدود است یا خیر.
- جفتهای {مبدا، مقصد} را بررسی کنید تا سختافزار معیوب احتمالی روی میزبانهای منفرد را شناسایی کنید.
سستی جمعی خیلی کوچک است
یکی از نشانههایی که نشان میدهد حجم کاری شما برای همپوشانی محاسباتی/ارتباطی بهینه نشده است، مشاهده زمانهای سکون کوچک برای زیرمجموعهای از Collectiveها است. این میتواند به صورت ردیابیهای recv-done طولانیتر از حد انتظار در نمایشگر trace یا به صورت Collectiveهایی با زمان سکون صفر یا نزدیک به صفر ظاهر شود.
در این صورت، به دنبال شناسایی گلوگاههای موجود در حجم کاری خود باشید که ممکن است باعث شوند بخشهایی از برنامه شما با محاسبات و ارتباطات شبکه همپوشانی نداشته باشند.
تقاضای بالای پهنای باند شبکه
اگر در مدل XProf خود، تأخیرهای طولانی recv-done مشاهده میکنید، این میتواند نشانهای از این باشد که مدل در آن بخشهای تابع پلهای «محدود به پهنای باند» است (توسط پهنای باند شبکه موجود در سیستم مسدود شده است).
شما میتوانید یک جدول زمانی از میزان استفاده از شبکه برای مدل خود ایجاد کنید. اگر در طول مرحله، میزان استفاده از شبکه به طور مداوم بالا بود، یا در مناطق خاصی افزایش ناگهانی زیادی مشاهده کردید، ممکن است مدل شما در آن مناطق به پهنای باند محدود شده باشد.
از تحلیل شبکه برای ایجاد یک جدول زمانی از میزان استفاده از شبکه استفاده کنید: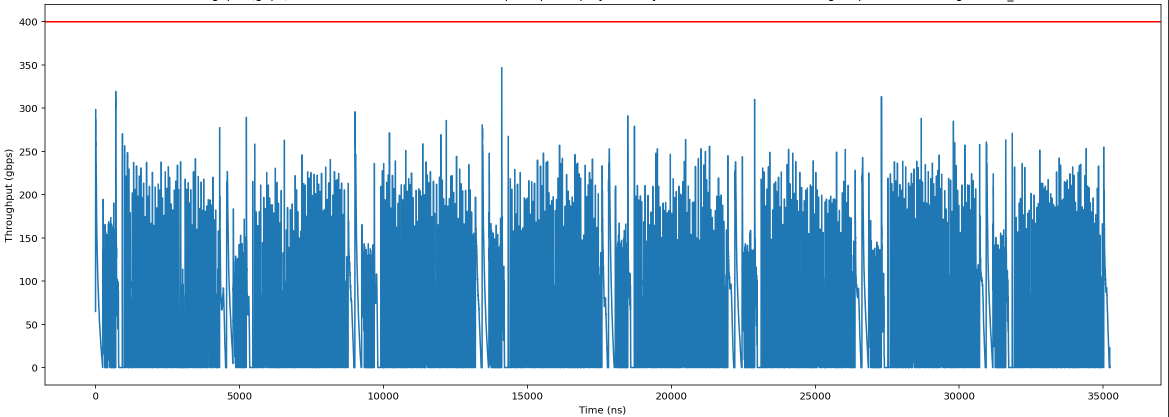
برای کاهش مدلهای محدود به پهنای باند، میتوانید:
- مقدار Collective Slack مدل خود را بررسی کنید. مدلهایی که Collectiveهای زیادی با Slack کم دارند، دارای نواحی محدود به پهنای باند خواهند بود.
- تأیید کنید که تنظیمات شبکه بهینه شدهاند.
- ساختار مدل و تقسیمبندی دادهها را بررسی کنید تا ببینید آیا راههایی برای افزایش همپوشانی محاسبات/ارتباطات وجود دارد یا خیر.
- (مدلهای موازی داده) تأیید کنید که در هر کپی محلی، اندازه دسته کافی برای همپوشانی با ارتباطات دارید.
تأخیر بالای شبکه
اگر پهنای باند اشباع نشده باشد، ممکن است بخواهید جدول زمانی تأخیر RPC را ایجاد کنید. اگر میبینید تأخیرهای RPC بالا به طور مداوم یا گاه به گاه زیاد است، به این معنی است که مشکلاتی در RPCهای MXLA وجود دارد.
از تحلیل شبکه برای ایجاد جدول زمانی تأخیر RPC استفاده کنید، مثال زیر نشان میدهد که برخی تأخیرهای RPC با طول ۲۰۰ میلیثانیه به صورت پراکنده وجود دارد. 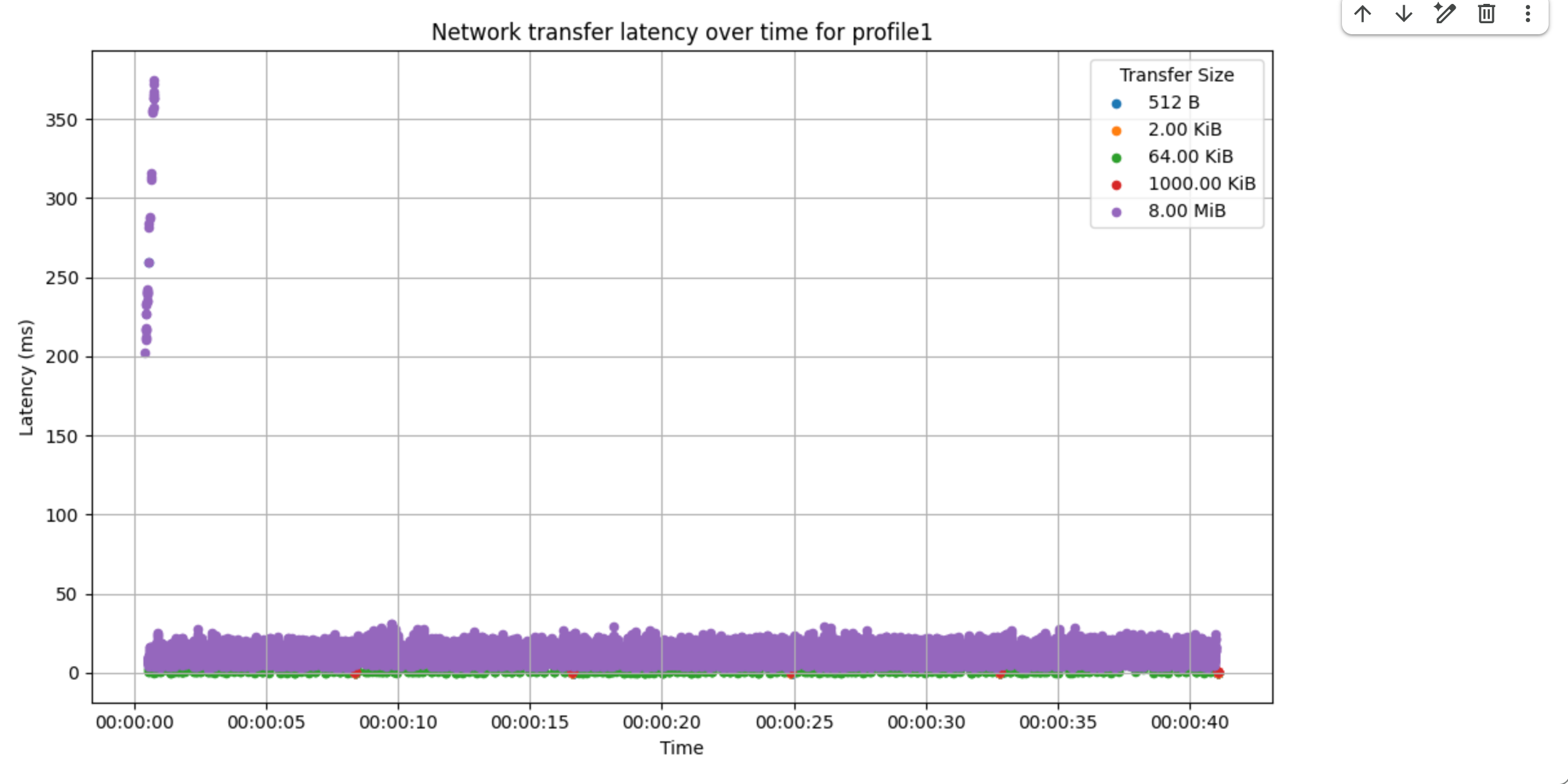
تنظیمات بهینه شبکه را تأیید کنید
تأخیر بالای RPC در محیط ابری اغلب به دلیل پیکربندی TCP غیربهینه ایجاد میشود. لطفاً تأیید کنید که آیا تمام پارامترهای TCP به درستی در کانتینر پیکربندی شدهاند یا خیر.
اگر هر یک از پارامترهای TCP به درستی پیکربندی نشدهاند، برای نحوه پیکربندی صحیح آنها با تیم Google Cloud ML Compute Services (CMCS) مشورت کنید.
تخلیه HLO
لطفاً برای ذخیره HLO در سیستم فایل محلی روی TPU worker، این مراحل را دنبال کنید. ممکن است لازم باشد فایل ذخیره شده را در GCS آپلود کنید تا بتوانید آن را با تیم XLA یا Megascale به اشتراک بگذارید.
استراگلر
نکتهای در مورد ابزارهای آینده: گوگل به طور فعال روی نسخههای متنباز داشبوردهای تشخیصی کار میکند تا تجربهای سادهتر برای مشتریان Cloud TPU فراهم کند تا بتوانند موارد متفرقه را شناسایی و تشخیص دهند. این موارد به زودی در دسترس خواهند بود.