
В этом документе описывается общий алгоритм отладки проблем MXLA.
Предварительное условие
- Используйте JAX версии 0.6 или выше и включите распределенную службу JAX. Эта версия JAX содержит дополнительные функции логирования, которые могут помочь определить, у каких рабочих процессов возникают проблемы.
- (Необязательно) Создайте дамп HLO, используя флаг --xla_dump_to при инициализации рабочей нагрузки. Это описано в документации XLA .
- (Необязательно) Установите параметр --vmodule=real_program_continuator=1, чтобы включить подробное логирование состояния выполнения программы TPU.
Блок-схема
Приведенная ниже блок-схема иллюстрирует процесс отладки. Чтобы получить доступ к подробным руководствам по каждому шагу, щелкните соответствующий элемент на схеме.
Висит
Найдите ошибку "Megascale Hang Detected".
Если в журналах вашего TPU-воркера отображается следующее сообщение об ошибке, это означает, что MXLA завершился по истечении времени ожидания, не обнаружив прогресса:
Megascale hang detected: Timed out waiting for 4 graphs to complete at launch_id 13650. Already completed: 100. StepGloballyInProgress: true. Timeout: 1m
- Сотрудники будут сообщать об ошибках координатору для их обработки.
- Для заданий Pathways : дайджест можно найти в логах задания
resource_manager. - Для заданий McJAX : журналы можно найти в MXLA Coordinator. Обычно это задача 0 в срезе 0.
- Для заданий Pathways : дайджест можно найти в логах задания
- Проверьте журналы событий в период обнаружения ошибки и найдите запись
Megascale detects a hang. - Выполните следующие шаги для диагностики проблемы на основе выявленной причины.
Диагноз
Интерпретация состояний ТПУ
Перед диагностикой зависаний MXLA важно понимать формат отчета о состоянии TPU. Ниже приведен пример отчета:
Full error digest:
Potential cause: <determined_cause>
Potential culprit workers: <task_name>
First error timestamp: <timestamp>
First error type: <error_type>
TPU states:
Launch ID: <launch_id>
Module: jit.step_fn Fingerprint: <fingerprint>
Sample worker: <task_name>@<host_name>:<tpu_chip>:<tpu_core>
Tag:PC breakdown:
<num_cores>@<location>(HLO): [<task_name>:<host_name>@<tpu_chip>:<tpu_core>, ...]
...
Неисправный чип TPU (тензорное ядро или разреженное ядро)
Megascale detects a hang that is likely caused by bad TPU chips on the following hosts. Please remove the hosts from the fleet and restart the workload. If problem persists please contact Megascale XLA team.
The host that have bad TPUs are: <host_name>
Full error digest:
Potential cause: Bad TPU chips
Potential culprit workers: <job_name>/<task_id>:<host_name>
Эта ошибка означает, что проблема, возможно, вызвана неисправным чипом TPU. Сообщение об ошибке должно содержать информацию о задании и имя хоста неисправного чипа. В приведенном выше примере неисправный чип находится на хосте <host_name> , влияя на задачу <task_id> задания <job_name> . Вы можете настроить задание таким образом, чтобы оно не затрагивало этот хост.
Проблема сети
Megascale detects a hang that is likely caused by a networking issue. Please examine the underlying networking stack for the following hosts.
The hosts are: <host_name>
Full error digest:
Potential cause: Networking issue
Potential culprit workers: <host_name_1>, <host_name_2>
Эта ошибка указывает на то, что ваше задание столкнулось с неисправным сетевым соединением. Сообщение об ошибке должно содержать одно или несколько имен задания, идентификатора задачи и имени хоста неисправного сетевого соединения. В приведенном выше примере неисправное сетевое соединение находится между хостами host_name_1 и host_name_2 . Иногда RapidEye может дополнительно локализовать неисправный хост, если один и тот же хост фигурирует в нескольких неработающих сетевых соединениях.
Различные модули
Megascale detects a hang that is likely caused by running different modules on different devices. Please confirm that all workers is running the exact same program. It can also be caused by a hang in a subset of devices and the unaffected devices have moved on to the next program. Please inspect the digest below to further root cause the hang.
Example hosts that have different HLO modules: <host_name>
Full error digest:
Potential cause: Different module
Potential culprit workers: <host_name>
TPU stats:
<host_name>: <pc>
TPU states:
Module: jit_loss_and_grad
Fingerprint: <fingerprint>
Launch ID: 193
<tag>:<pc>(<hlo>): <host_name>
Module: jit_optimizer_apply
Fingerprint: <fingerprint>
Launch ID: 0
<tag>:<pc>(<hlo>): <host_name>
Эта ошибка может указывать на зависание в подгруппе рабочих процессов, в результате чего эти процессы застряли на текущем модуле, в то время как неповрежденные процессы переходят к следующему модулю. Для определения первопричины изучите дайджест, выведенный RapidEye в журналах.
В разделе TPU states логов отображается информация о том, какие модули запущены на каких рабочих процессах. В приведенном выше примере рабочие процессы запускают разные модули: jit_loss_and_grad и jit_optimizer_apply .
Несоответствие отпечатков пальцев для модуля HLO
Megascale detects a hang that is likely caused by inconsistent HLO module compilation across workers. This is likely a bug in JAX tracing or XLA compiler. Please inspect the HLO dumps to confirm the root cause.
Example hosts that have different HLO fingerprints: <host_name>
Full error digest:
Potential cause: Fingerprint mismatch
Potential culprit workers: <host_name>
TPU stats:
Module: reduce.31
Fingerprint: <fingerprint_1>
Launch ID: 37
<tag>:<pc>(<hlo>): <host_name>
Module: reduce.31
Fingerprint: <fingerprint_2>
Launch ID: 40
<tag>:<pc>(<hlo>): <host_name>
Это сообщение в журнале указывает на то, что зависание, вероятно, было вызвано непоследовательной компиляцией модуля HLO на разных рабочих процессах, возможно, из-за проблемы с трассировкой JAX или компилятором XLA. Если вы видите это сообщение в журнале, выполните следующие действия , чтобы собрать дампы HLO с проблемных рабочих процессов для дальнейшей отладки.
Задержка ввода данных
Megascale detects a hang that is likely caused by data input stall on the
following hosts. Please check the workers to make sure the data input pipeline
is working properly.
The host that have data input stalls are: <host_name>
Эта ошибка означает, что на всех устройствах была запущена одна и та же программа, но входные данные не были переданы программе до истечения времени ожидания системы. Для устранения этой проблемы убедитесь в следующем:
- Указанные хосты могут получить доступ к источнику входных данных.
- Выявленные хосты корректно загружают/анализируют входной источник данных.
- Убедитесь, что идентифицированные хосты не ограничены по скорости чтения из источника входных данных.
Неустранимая ошибка
Some workers have halted with an unrecoverable error:
<worker> : {some error}
Please inspect the error log of these workers:
<worker>
Эта ошибка означает, что возникла проблема, которая помешала корректному выполнению программы и не могла быть автоматически устранена. Данная ошибка не может быть классифицирована. Дополнительную информацию можно получить, проверив журналы рабочих процессов, упомянутых в отчете об ошибке.
Если ошибка, по-видимому, специфична для конкретной машины (например, сбой копирования данных с TPU на хост), то вы можете настроить задание таким образом, чтобы оно избегало этих хостов.
Неизвестная ошибка
Megascale detects a hang but cannot determine the root cause. Please inspect the
full digest below.
Эта ошибка означает, что возникла проблема, которая помешала корректному выполнению программы и не могла быть автоматически устранена. Данная ошибка не может быть классифицирована, и дополнительная информация об ошибке отсутствует.
Производительность
Получите сессию XProf
Следуйте инструкциям в документации XProf , чтобы сгенерировать трассировку XProf для проблемного запуска.
Проверьте наличие нехватки отображенных буферов DMA.
Для использования памяти TPU в процессе выполнения Megascale XLA необходимо зарегистрировать память хоста. Это происходит вскоре после запуска процесса. Если вы видите эти регистрации (вызовы MapDmaBuffer ) в установившемся режиме, это указывает на проблему. Проверьте наличие этих вызовов в XProf Trace Viewer. См. скриншот ниже для справки.
Совет: Ищите точное имя рабочего процесса, так как могут быть и другие рабочие процессы с похожими или близкими именами. Также можно выполнить поиск по термину «MapDmaBuffer» на странице.
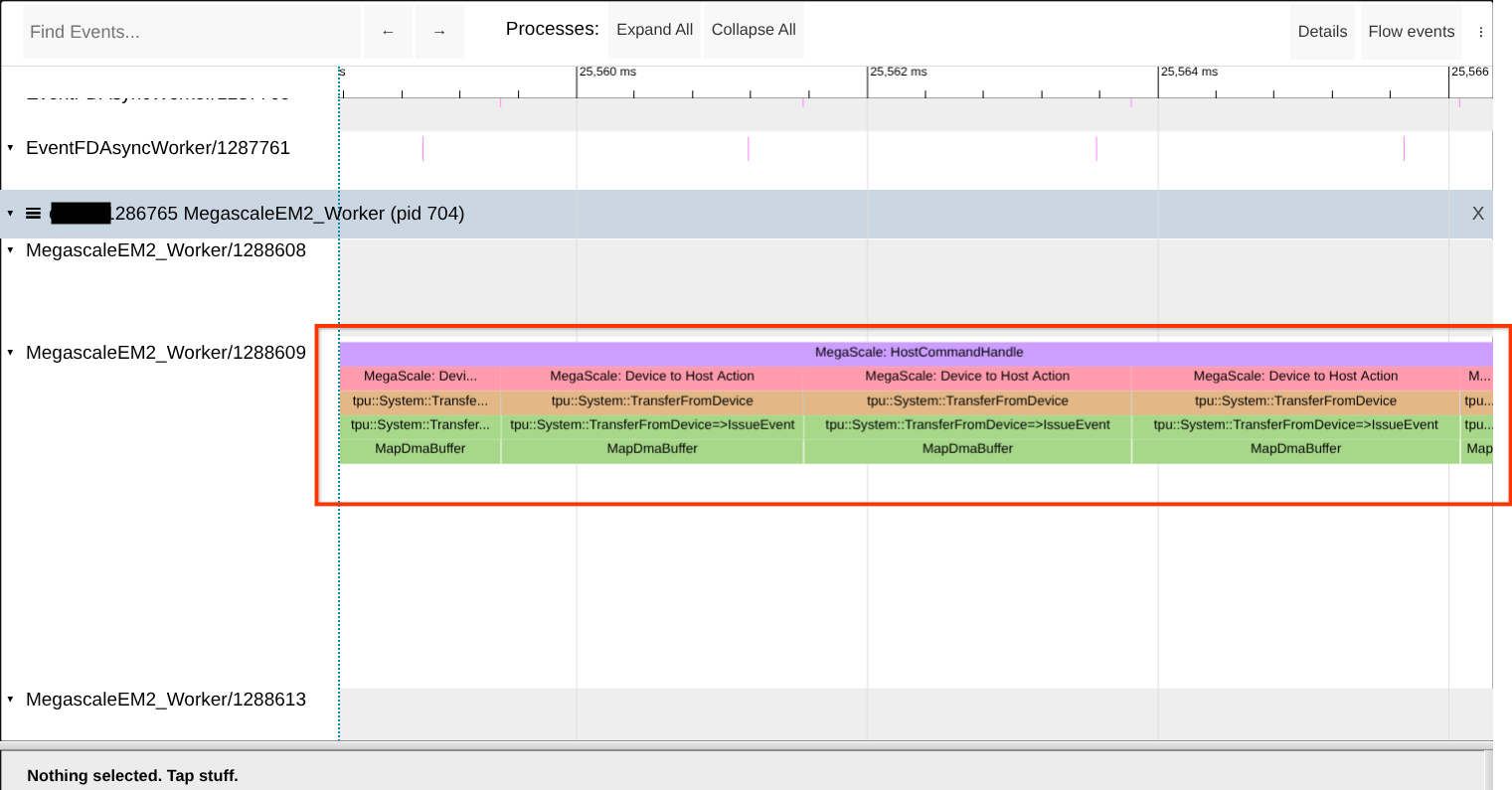
Если проблема сохраняется, попробуйте увеличить размер предварительно отображенной области памяти, увеличив значение параметра --megascale_grpc_premap_memory_bytes , перезапустите задание и проверьте еще раз.
Проверка наличия копий в памяти во время передачи по сети.
В Megascale XLA передача данных по сети осуществляется без копирования. Однако в некоторых случаях копирование данных в память всё же происходит, что приводит к снижению производительности. Ищите случаи копирования данных в памяти в трассировках "Communication Transport" Megascale, как показано на примере скриншота ниже.
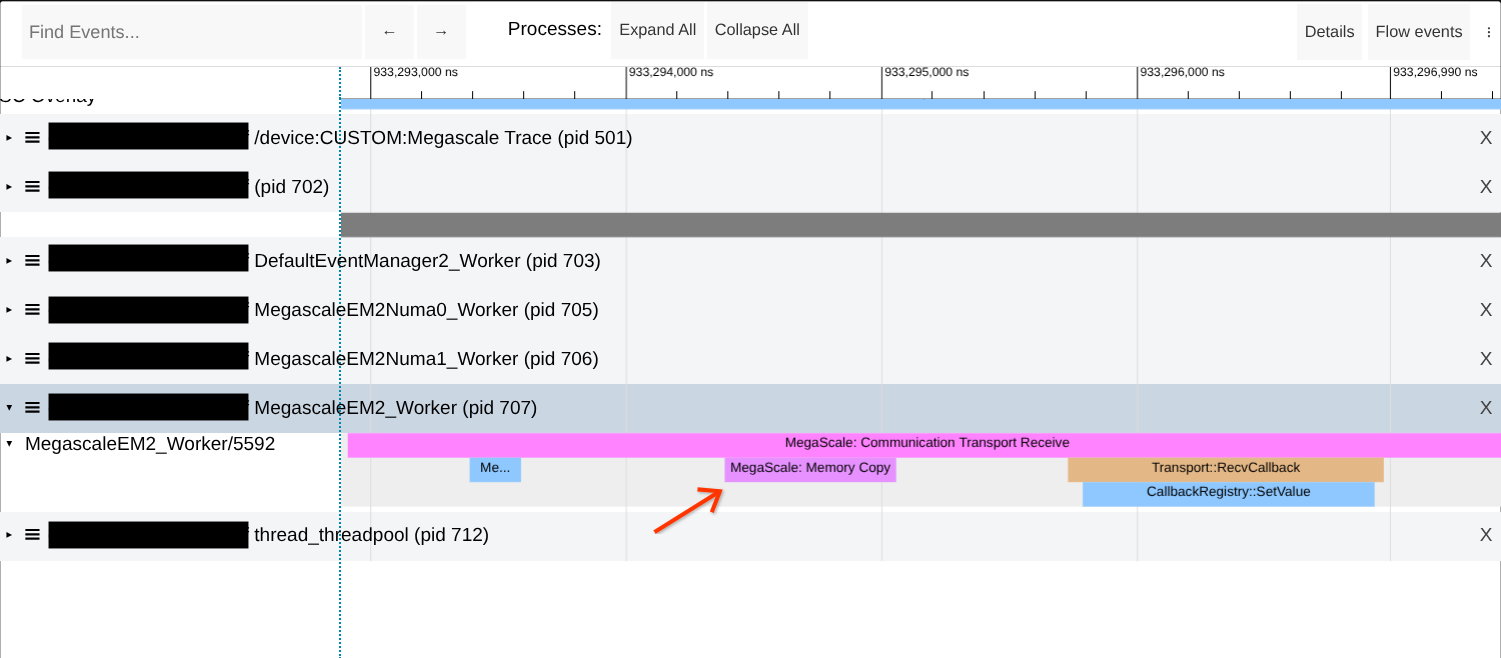
Если проблема сохраняется, попробуйте увеличить размер предварительно отображенной области памяти, увеличив значение параметра --megascale_grpc_premap_memory_bytes , перезапустите задание и проверьте еще раз.
Анализ сети
Компания MegaScale также предоставляет блокнот Colab для анализа производительности сети с помощью трассировки XProf.
Этот инструмент можно использовать для выполнения следующих задач:
- Проанализируйте задержки передачи данных, чтобы выявить потенциальные замедления работы сети или медленной работы хоста.
- Проанализируйте размеры передаваемых данных, чтобы определить, оптимизирована ли ваша рабочая нагрузка для использования меньшего количества крупных передач вместо большого количества мелких передач.
- Определите, является ли ваша рабочая нагрузка неоптимизированной и приводит ли к прерывистым запускам групповых операций/постоянному большому количеству ожидающих выполнения групповых операций.
- Визуализируйте временную шкалу пропускной способности сети, чтобы определить, ограничена ли рабочая нагрузка пропускной способностью сети.
- Проанализируйте пары "источник, пункт назначения", чтобы выявить возможные неисправности оборудования на отдельных хостах.
Коллективный Slack слишком мал.
Одним из признаков того, что ваша рабочая нагрузка не оптимизирована для пересечения вычислительных ресурсов и обмена данными, является наличие небольших задержек для подмножества группировок. Это может проявляться в виде более длительных, чем ожидалось, трассировок recv-done в средстве просмотра трассировки или в виде группировок с нулевой или близкой к нулевой задержкой .
В таком случае, следует выявить узкие места в вашей рабочей нагрузке, которые могут препятствовать одновременному использованию вычислительных ресурсов и сетевого взаимодействия в рамках вашей программы.
Высокая потребность в пропускной способности сети
Если вы наблюдаете большие задержки recv-done операции в вашей модели XProf, это может указывать на то, что модель «ограничена пропускной способностью» в этих участках ступенчатой функции (блокируется доступной пропускной способностью сети в системе).
Вы можете построить временную шкалу использования сети для вашей модели. Если вы наблюдаете стабильно высокое использование сети на протяжении всего шага или значительные всплески в определенных регионах, то ваша модель может испытывать проблемы с пропускной способностью в этих регионах.
Используйте инструмент анализа сети , чтобы создать хронологию использования сети: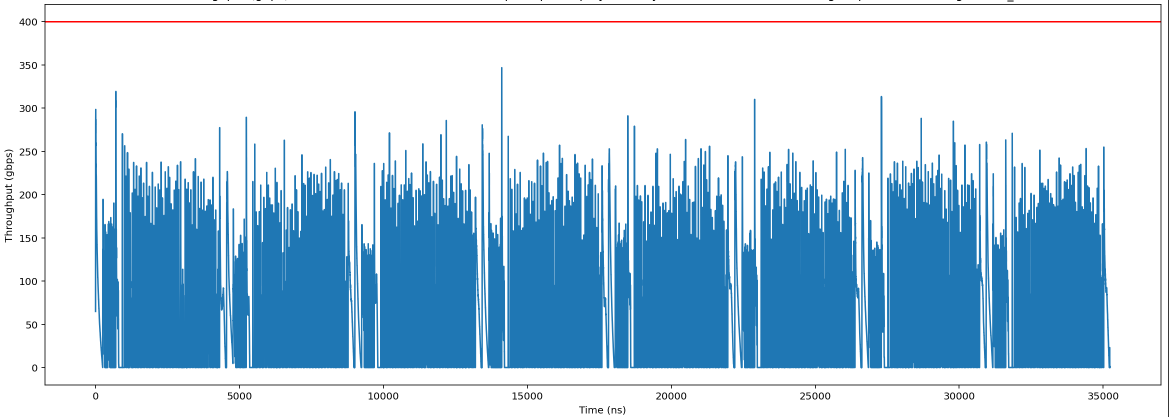
Для смягчения последствий использования моделей, ограниченных пропускной способностью, можно:
- Проверьте значение Collective Slack вашей модели. Модели с большим количеством коллективов с низким значением Slack будут иметь области, ограниченные пропускной способностью.
- Убедитесь, что сетевые настройки оптимизированы.
- Проанализируйте структуру вашей модели и сегментирование данных, чтобы определить, есть ли способы увеличить перекрытие вычислений и обмена данными.
- (Модели параллельной обработки данных) Убедитесь, что размер пакета в каждой локальной реплике достаточен для обеспечения перекрытия с обменом данными.
Высокая задержка в сети
Если пропускная способность не перегружена, возможно, вам стоит построить временную шкалу задержки RPC. Если вы видите, что задержка RPC постоянно или периодически высока, это означает, что есть проблемы с RPC в MXLA.
Используйте инструмент анализа сети для построения временной шкалы задержки RPC. В следующем примере показано наличие спорадических задержек RPC длительностью 200 мс. 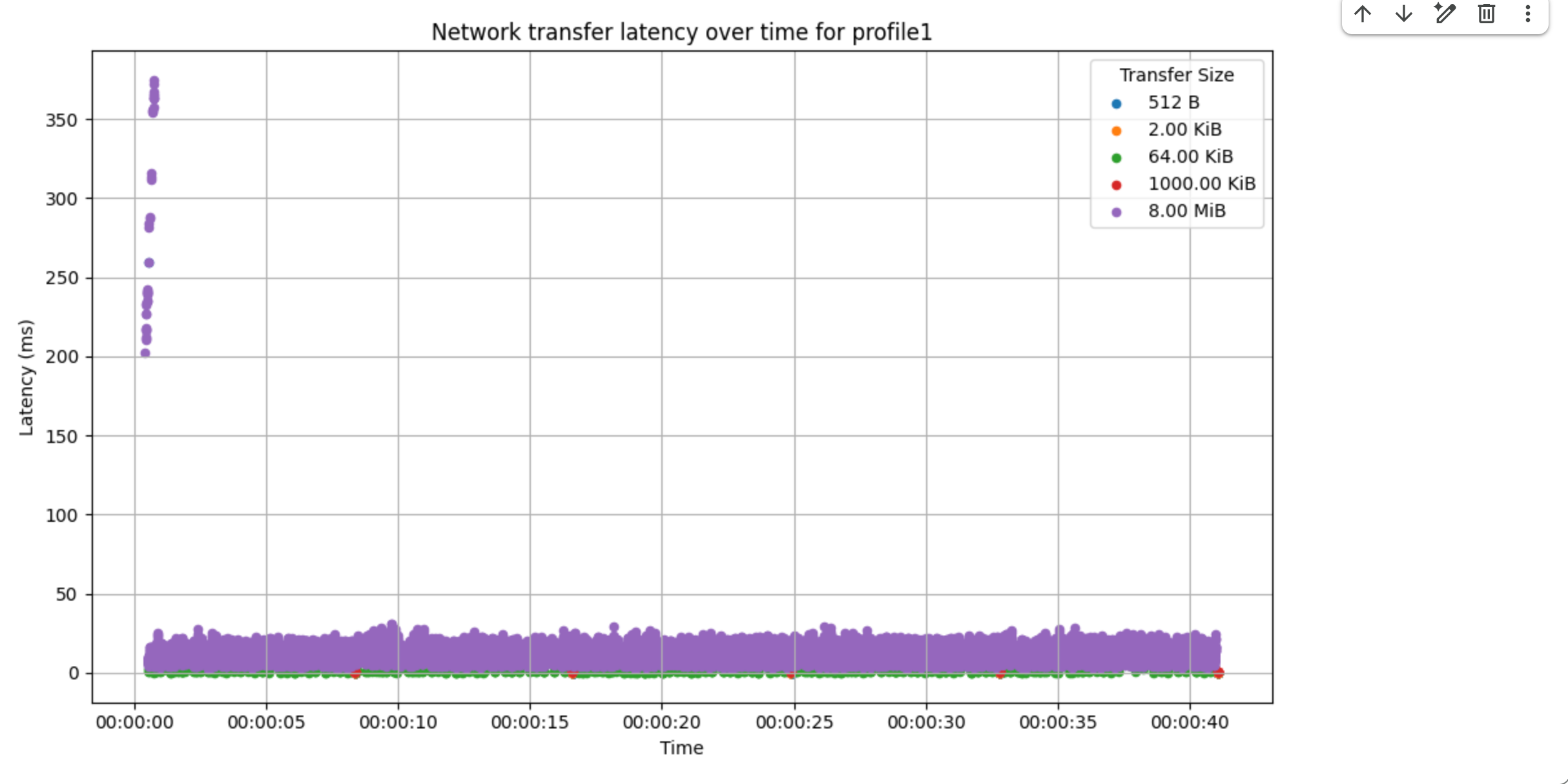
Подтвердите оптимальные настройки сети.
Высокая задержка RPC в облачной среде часто вызвана неоптимальной конфигурацией TCP. Пожалуйста, убедитесь, что все параметры TCP правильно настроены внутри контейнера.
Если какие-либо параметры TCP настроены неправильно, обратитесь к команде Google Cloud ML Compute Services (CMCS) за инструкцией по их правильной настройке.
HLO Дамп
Пожалуйста, выполните следующие шаги , чтобы сохранить дамп HLO в локальную файловую систему на рабочем сервере TPU. Возможно, вам потребуется загрузить дамп в GCS, чтобы поделиться им с командой XLA или Megascale.
Отставший
Примечание о будущих инструментах: Google активно работает над версиями диагностических панелей с открытым исходным кодом, чтобы обеспечить клиентам Cloud TPU более удобную возможность выявлять и диагностировать проблемы, возникающие в процессе работы. Эти версии скоро будут доступны.