
以下では、XlaBuilder インターフェースで定義されているオペレーションのセマンティクスについて説明します。通常、これらのオペレーションは xla_data.proto の RPC インターフェースで定義されているオペレーションに 1 対 1 でマッピングされます。
命名法に関する注: XLA が扱う汎用データ型は、均一な型(32 ビット浮動小数点など)の要素を保持する N 次元配列です。ドキュメント全体で、配列は任意の次元の配列を表すために使用されます。便宜上、特殊なケースにはより具体的でわかりやすい名前が付けられています。たとえば、ベクトルは 1 次元配列、行列は 2 次元配列です。
Op の構造について詳しくは、シェイプとレイアウトとタイル レイアウトをご覧ください。
腹筋
XlaBuilder::Abs もご覧ください。
要素単位の絶対値 x -> |x|。
Abs(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
StableHLO の詳細については、StableHLO - abs をご覧ください。
追加
XlaBuilder::Add もご覧ください。
lhs と rhs の要素ごとの加算を行います。
Add(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Add には、異なる次元のブロードキャストをサポートする代替バリアントがあります。
Add(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の情報については、StableHLO - add をご覧ください。
AddDependency
HloInstruction::AddDependency もご覧ください。
AddDependency は HLO ダンプに表示されることがありますが、エンドユーザーが手動で構築することを意図したものではありません。
AfterAll
XlaBuilder::AfterAll もご覧ください。
AfterAll は可変数のトークンを受け取り、単一のトークンを生成します。トークンは、副作用のあるオペレーション間でスレッド化して順序を強制できるプリミティブ型です。AfterAll は、一連のオペレーションの後にオペレーションを順序付けるためのトークンの結合として使用できます。
AfterAll(tokens)
| 引数 | タイプ | セマンティクス |
|---|---|---|
tokens |
XlaOp のベクトル |
可変数のトークン |
StableHLO の情報については、StableHLO - after_all をご覧ください。
AllGather
XlaBuilder::AllGather もご覧ください。
レプリカ間で連結を実行します。
AllGather(operand, all_gather_dimension, shard_count, replica_groups,
channel_id, layout, use_global_device_ids)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand
|
XlaOp
|
レプリカ間で連結する配列 |
all_gather_dimension |
int64 |
連結ディメンション |
shard_count
|
int64
|
各レプリカ グループのサイズ |
replica_groups
|
int64 のベクトルのベクトル |
連結が実行されるグループ |
channel_id
|
省略可
ChannelHandle |
クロスモジュール通信用のオプションのチャンネル ID |
layout
|
省略可 Layout
|
引数で一致したレイアウトをキャプチャするレイアウト パターンを作成します。 |
use_global_device_ids
|
省略可 bool
|
ReplicaGroup 構成の ID がグローバル ID を表す場合は true を返します。 |
replica_groupsは、連結が実行されるレプリカ グループのリストです(現在のレプリカのレプリカ ID はReplicaIdを使用して取得できます)。各グループ内のレプリカの順序によって、結果内の入力の順序が決まります。replica_groupsは空(この場合、すべてのレプリカは 1 つのグループに属し、0からN - 1の順に並べられます)であるか、レプリカの数と同じ数の要素を含んでいる必要があります。たとえば、replica_groups = {0, 2}, {1, 3}はレプリカ0と2、1と3の間で連結を実行します。shard_countは各レプリカ グループのサイズです。これは、replica_groupsが空の場合に必要です。channel_idはモジュール間の通信に使用されます。同じchannel_idを持つall-gatherオペレーションのみが相互に通信できます。use_global_device_idsReplicaGroup 構成の ID がレプリカ ID ではなく(replica_id * partition_count + partition_id)のグローバル ID を表す場合は true を返します。これにより、このオールリデュースがパーティション間とレプリカ間の両方である場合に、デバイスのより柔軟なグループ化が可能になります。
出力形状は、all_gather_dimension が shard_count 倍になった入力形状です。たとえば、2 つのレプリカがあり、オペランドが 2 つのレプリカでそれぞれ [1.0, 2.5] と [3.0, 5.25] の値を持つ場合、all_gather_dim が 0 のこの演算からの出力値は、両方のレプリカで [1.0, 2.5, 3.0,5.25] になります。
AllGather の API は、内部的に 2 つの HLO 命令(AllGatherStart と AllGatherDone)に分解されます。
HloInstruction::CreateAllGatherStart もご覧ください。
AllGatherStart、AllGatherDone は HLO のプリミティブとして機能します。これらのオペレーションは HLO ダンプに表示されることがありますが、エンドユーザーが手動で構築することを想定していません。
StableHLO の詳細については、StableHLO - all_gather をご覧ください。
AllReduce
XlaBuilder::AllReduce もご覧ください。
レプリカ間でカスタム計算を実行します。
AllReduce(operand, computation, replica_groups, channel_id,
shape_with_layout, use_global_device_ids)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand
|
XlaOp
|
レプリカ間で削減する配列または配列の空でないタプル |
computation |
XlaComputation |
削減の計算 |
replica_groups
|
ReplicaGroup ベクトル |
削減が実行されるグループ |
channel_id
|
省略可
ChannelHandle |
クロスモジュール通信用のオプションのチャンネル ID |
shape_with_layout
|
省略可 Shape
|
転送されるデータのレイアウトを定義します。 |
use_global_device_ids
|
省略可 bool
|
ReplicaGroup 構成の ID がグローバル ID を表す場合は true を返します。 |
operandが配列のタプルの場合、タプルの各要素に対して all-reduce が実行されます。replica_groupsは、削減が実行されるレプリカ グループのリストです(現在のレプリカのレプリカ ID はReplicaIdを使用して取得できます)。replica_groupsは空(すべてのレプリカが単一のグループに属している場合)であるか、レプリカの数と同じ数の要素を含んでいる必要があります。たとえば、replica_groups = {0, 2}, {1, 3}はレプリカ0と2、1と3の間で削減を実行します。channel_idはモジュール間の通信に使用されます。同じchannel_idを持つall-reduceオペレーションのみが相互に通信できます。shape_with_layout: AllReduce のレイアウトを指定されたレイアウトに強制します。これは、個別にコンパイルされた AllReduce オペレーションのグループに同じレイアウトを保証するために使用されます。use_global_device_idsReplicaGroup 構成の ID がレプリカ ID ではなく(replica_id * partition_count + partition_id)のグローバル ID を表す場合は true を返します。これにより、このオールリデュースがパーティション間とレプリカ間の両方である場合に、デバイスのより柔軟なグループ化が可能になります。
出力シェイプは入力シェイプと同じです。たとえば、2 つのレプリカがあり、オペランドの値が 2 つのレプリカでそれぞれ [1.0, 2.5] と [3.0, 5.25] の場合、この op と合計計算の出力値は両方のレプリカで [4.0, 7.75] になります。入力がタプルの場合、出力もタプルになります。
AllReduce の結果を計算するには、各レプリカからの入力が 1 つ必要です。そのため、あるレプリカが別のレプリカよりも AllReduce ノードを多く実行すると、前者のレプリカは永久に待機します。レプリカはすべて同じプログラムを実行しているため、このような状況が発生する可能性はそれほど高くありませんが、while ループの条件が infeed のデータに依存し、その infeed のデータによって、あるレプリカで while ループが別のレプリカよりも多く繰り返される場合に発生する可能性があります。
AllReduce の API は、内部的に 2 つの HLO 命令(AllReduceStart と AllReduceDone)に分解されます。
HloInstruction::CreateAllReduceStart もご覧ください。
AllReduceStart と AllReduceDone は HLO のプリミティブとして機能します。これらのオペレーションは HLO ダンプに表示されることがありますが、エンドユーザーが手動で構築することを想定していません。
CrossReplicaSum
XlaBuilder::CrossReplicaSum もご覧ください。
合計計算で AllReduce を実行します。
CrossReplicaSum(operand, replica_groups)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand
|
XlaOp | レプリカ間で削減する配列または配列の空でないタプル |
replica_groups
|
int64 のベクトルのベクトル |
削減が実行されるグループ |
レプリカの各サブグループ内のオペランド値の合計を返します。すべてのレプリカが合計に 1 つの入力を提供し、すべてのレプリカが各サブグループの結果の合計を受け取ります。
AllToAll
XlaBuilder::AllToAll もご覧ください。
AllToAll は、すべてのコアからすべてのコアにデータを送信する集団オペレーションです。次の 2 つのフェーズがあります。
- 散布フェーズ。各コアで、オペランドは
split_dimensionsに沿ってsplit_count個のブロックに分割され、ブロックはすべてのコアに分散されます。たとえば、i 番目のブロックは i 番目のコアに送信されます。 - 収集フェーズ。各コアは、受信したブロックを
concat_dimensionに沿って連結します。
参加するコアは、次の方法で構成できます。
replica_groups: 各 ReplicaGroup には、計算に参加しているレプリカ ID のリストが含まれています(現在のレプリカのレプリカ ID はReplicaIdを使用して取得できます)。AllToAll は、指定された順序でサブグループ内で適用されます。たとえば、replica_groups = { {1,2,3}, {4,5,0} }は、レプリカ{1, 2, 3}内で AllToAll が適用され、収集フェーズで、受信したブロックが 1、2、3 の同じ順序で連結されることを意味します。次に、レプリカ 4、5、0 内で別の AllToAll が適用され、連結順序も 4、5、0 になります。replica_groupsが空の場合、すべてのレプリカは 1 つのグループに属し、連結順序は出現順になります。
前提条件:
split_dimensionのオペランドのディメンション サイズはsplit_countで割り切れます。- オペランドの形状がタプルではありません。
AllToAll(operand, split_dimension, concat_dimension, split_count,
replica_groups, layout, channel_id)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
n 次元入力配列 |
split_dimension
|
int64
|
オペランドが分割されるディメンションの名前を指定する [0,n) の値 |
concat_dimension
|
int64
|
分割ブロックが連結されるディメンションの名前を指定する、間隔 [0,n) の値 |
split_count
|
int64
|
このオペレーションに参加するコアの数。replica_groups が空の場合は、レプリカの数にする必要があります。それ以外の場合は、各グループのレプリカの数と同じにする必要があります。 |
replica_groups
|
ReplicaGroupvector
|
各グループには、レプリカ ID のリストが含まれています。 |
layout |
省略可 Layout |
ユーザー指定のメモリ レイアウト |
channel_id
|
省略可 ChannelHandle
|
各送受信ペアの一意の識別子 |
シェイプとレイアウトについて詳しくは、xla::shapes をご覧ください。
StableHLO の詳細については、StableHLO - all_to_all をご覧ください。
AllToAll - 例 1。
XlaBuilder b("alltoall");
auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {4, 16}), "x");
AllToAll(
x,
/*split_dimension=*/ 1,
/*concat_dimension=*/ 0,
/*split_count=*/ 4);
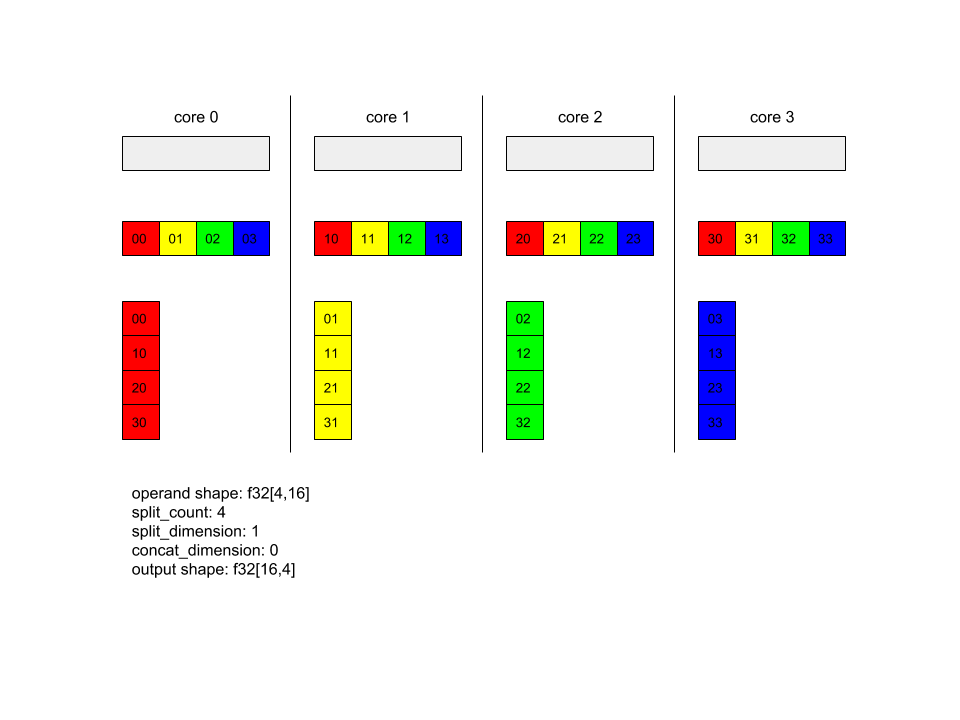
上記の例では、Alltoall に参加しているコアが 4 つあります。各コアで、オペランドはディメンション 1 に沿って 4 つの部分に分割されるため、各部分の形状は f32[4,4] になります。4 つの部分はすべてのコアに分散されます。次に、各コアは受信した部分をディメンション 0 に沿ってコア 0 ~ 4 の順に連結します。したがって、各コアの出力の形状は f32[16,4] になります。
AllToAll - 例 2 - StableHLO

上記の例では、AllToAll に 2 つのレプリカが参加しています。各レプリカでは、オペランドの形状は f32[2,4] です。オペランドはディメンション 1 に沿って 2 つの部分に分割されるため、各部分の形状は f32[2,2] になります。次に、レプリカ グループ内の位置に従って、2 つの部分がレプリカ間で交換されます。各レプリカは、両方のオペランドから対応する部分を収集し、ディメンション 0 に沿って連結します。その結果、各レプリカの出力の形状は f32[4,2] になります。
RaggedAllToAll
XlaBuilder::RaggedAllToAll もご覧ください。
RaggedAllToAll は、入力と出力がラグド テンソルである集合的な全対全オペレーションを実行します。
RaggedAllToAll(input, input_offsets, send_sizes, output, output_offsets,
recv_sizes, replica_groups, channel_id)
| 引数 | タイプ | セマンティクス |
|---|---|---|
input |
XlaOp |
型 T の N 配列 |
input_offsets |
XlaOp |
型 T の N 配列 |
send_sizes |
XlaOp |
型 T の N 配列 |
output |
XlaOp |
型 T の N 配列 |
output_offsets |
XlaOp |
型 T の N 配列 |
recv_sizes |
XlaOp |
型 T の N 配列 |
replica_groups
|
ReplicaGroup ベクトル |
各グループには、レプリカ ID のリストが含まれています。 |
channel_id
|
省略可 ChannelHandle
|
各送受信ペアの一意の識別子 |
ラグド テンソルは、次の 3 つのテンソルのセットで定義されます。
data:dataテンソルは最も外側のディメンションに沿って「不揃い」であり、各インデックス付き要素のサイズは可変です。offsets:offsetsテンソルはdataテンソルの最も外側のディメンションをインデックスし、dataテンソルの各ラグド要素の開始オフセットを表します。sizes:sizesテンソルは、dataテンソルの各ラグド要素のサイズを表します。サイズはサブ要素の単位で指定されます。サブ要素は、最も外側の「ラグド」ディメンションを削除して取得した「データ」テンソル形状の接尾辞として定義されます。offsetsテンソルとsizesテンソルは同じサイズにする必要があります。
ラグド テンソルの例:
data: [8,3] =
{ {a,b,c},{d,e,f},{g,h,i},{j,k,l},{m,n,o},{p,q,r},{s,t,u},{v,w,x} }
offsets: [3] = {0, 1, 4}
sizes: [3] = {1, 3, 4}
// Index 'data' at 'offsets'[0], 'sizes'[0]' // {a,b,c}
// Index 'data' at 'offsets'[1], 'sizes'[1]' // {d,e,f},{g,h,i},{j,k,l}
// Index 'data' at 'offsets'[2], 'sizes'[2]' // {m,n,o},{p,q,r},{s,t,u},{v,w,x}
output_offsets は、各レプリカがターゲット レプリカ出力パースペクティブでオフセットを持つようにシャーディングする必要があります。
i 番目の出力オフセットの場合、現在のレプリカは input[input_offsets[i]:input_offsets[i]+send_sizes[i]] 更新を i 番目のレプリカに送信します。これは、i 番目のレプリカの output の output_i[output_offsets[i]:output_offsets[i]+send_sizes[i]] に書き込まれます。
たとえば、レプリカが 2 つある場合:
replica 0:
input: [1, 2, 2]
output:[0, 0, 0, 0]
input_offsets: [0, 1]
send_sizes: [1, 2]
output_offsets: [0, 0]
recv_sizes: [1, 1]
replica 1:
input: [3, 4, 0]
output: [0, 0, 0, 0]
input_offsets: [0, 1]
send_sizes: [1, 1]
output_offsets: [1, 2]
recv_sizes: [2, 1]
// replica 0's result will be: [1, 3, 0, 0]
// replica 1's result will be: [2, 2, 4, 0]
ラグド all-to-all HLO には次の引数があります。
input: ラグ入力データ テンソル。output: ラグド出力データ テンソル。input_offsets: 不規則な入力オフセット テンソル。send_sizes: ラグド送信サイズ テンソル。output_offsets: ターゲット レプリカ出力の不揃いなオフセットの配列。recv_sizes: ラグド recv サイズ テンソル。
*_offsets テンソルと *_sizes テンソルはすべて同じ形状である必要があります。
*_offsets テンソルと *_sizes テンソルでは、次の 2 つのシェイプがサポートされています。
[num_devices]。ragged-all-to-all は、レプリカ グループ内の各リモート デバイスに最大 1 つの更新を送信できます。次に例を示します。
for (remote_device_id : replica_group) {
SEND input[input_offsets[remote_device_id]],
output[output_offsets[remote_device_id]],
send_sizes[remote_device_id] }
[num_devices, num_updates]では、ラグド オールツーオールが、レプリカ グループ内の各リモート デバイスに対して、同じリモート デバイスに最大num_updates個の更新を送信する場合があります(それぞれ異なるオフセット)。
次に例を示します。
for (remote_device_id : replica_group) {
for (update_idx : num_updates) {
SEND input[input_offsets[remote_device_id][update_idx]],
output[output_offsets[remote_device_id][update_idx]]],
send_sizes[remote_device_id][update_idx] } }
および
XlaBuilder::And もご覧ください。
2 つのテンソル lhs と rhs の要素ごとの AND を実行します。
And(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
And には、異なる次元のブロードキャストをサポートする別のバリアントがあります。
And(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の詳細については、StableHLO - and をご覧ください。
非同期
HloInstruction::CreateAsyncStart、HloInstruction::CreateAsyncUpdate、HloInstruction::CreateAsyncDone もご覧ください。
AsyncDone、AsyncStart、AsyncUpdate は、非同期オペレーションに使用される内部 HLO 命令であり、HLO のプリミティブとして機能します。これらのオペレーションは HLO ダンプに表示されることがありますが、エンドユーザーが手動で構築することを想定していません。
Atan2
XlaBuilder::Atan2 もご覧ください。
lhs と rhs で要素ごとの atan2 演算を実行します。
Atan2(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Atan2 には、異なる次元のブロードキャストをサポートする別のバリアントがあります。
Atan2(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の詳細については、StableHLO - atan2 をご覧ください。
BatchNormGrad
アルゴリズムの詳細については、XlaBuilder::BatchNormGrad とバッチ正規化の元の論文もご覧ください。
バッチ正規化の勾配を計算します。
BatchNormGrad(operand, scale, batch_mean, batch_var, grad_output, epsilon,
feature_index)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp | 正規化する n 次元配列(x) |
scale |
XlaOp | 1 次元配列(\(\gamma\)) |
batch_mean |
XlaOp | 1 次元配列(\(\mu\)) |
batch_var |
XlaOp | 1 次元配列(\(\sigma^2\)) |
grad_output |
XlaOp | BatchNormTraining(\(\nabla y\))に渡されたグラデーション |
epsilon |
float |
イプシロン値(\(\epsilon\)) |
feature_index |
int64 |
operand の特徴量の次元のインデックス |
特徴ディメンションの各特徴(feature_index は operand の特徴ディメンションのインデックス)について、このオペレーションは他のすべてのディメンションで operand、offset、scale に関するグラデーションを計算します。feature_index は、operand の特徴ディメンションの有効なインデックスである必要があります。
3 つのグラデーションは、次の式で定義されます(4 次元配列を operand とし、特徴ディメンション インデックスを l、バッチサイズを m、空間サイズを w と h とします)。
\[ \begin{split} c_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sigma^2_l+\epsilon} \right) \\\\ d_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \\\\ \nabla x_{ijkl} &= \frac{\gamma_{l} }{\sqrt{\sigma^2_{l}+\epsilon} } \left( \nabla y_{ijkl} - d_l - c_l (x_{ijkl} - \mu_{l}) \right) \\\\ \nabla \gamma_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sqrt{\sigma^2_{l}+\epsilon} } \right) \\\\\ \nabla \beta_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \end{split} \]
入力 batch_mean と batch_var は、バッチ ディメンションと空間ディメンションのモーメント値を表します。
出力タイプは、次の 3 つのハンドルのタプルです。
| 出力 | タイプ | セマンティクス |
|---|---|---|
grad_operand
|
XlaOp | 入力 operand(\(\nabla x\))に関するグラデーション |
grad_scale
|
XlaOp | 入力 **scale **
(\(\nabla\gamma\))に関するグラデーション |
grad_offset
|
XlaOp | 入力 offset(\(\nabla\beta\)) に関するグラデーション |
StableHLO の情報については、StableHLO - batch_norm_grad をご覧ください。
BatchNormInference
アルゴリズムの詳細については、XlaBuilder::BatchNormInference とバッチ正規化の元の論文もご覧ください。
バッチ ディメンションと空間ディメンションにわたって配列を正規化します。
BatchNormInference(operand, scale, offset, mean, variance, epsilon,
feature_index)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp | 正規化する n 次元配列 |
scale |
XlaOp | 1 次元配列 |
offset |
XlaOp | 1 次元配列 |
mean |
XlaOp | 1 次元配列 |
variance |
XlaOp | 1 次元配列 |
epsilon |
float |
イプシロン値 |
feature_index |
int64 |
operand の特徴量の次元のインデックス |
特徴量ディメンションの各特徴量(feature_index は operand の特徴量ディメンションのインデックス)について、このオペレーションは他のすべてのディメンションの平均と分散を計算し、その平均と分散を使用して operand の各要素を正規化します。feature_index は、operand の特徴ディメンションの有効なインデックスである必要があります。
BatchNormInference は、各バッチの mean と variance を計算せずに BatchNormTraining を呼び出すことに相当します。代わりに、入力 mean と variance を推定値として使用します。この op の目的は、推論のレイテンシを短縮することです。そのため、BatchNormInference という名前が付けられています。
出力は、入力 operand と同じ形状の n 次元正規化配列です。
StableHLO の詳細については、StableHLO - batch_norm_inference をご覧ください。
BatchNormTraining
アルゴリズムの詳細については、XlaBuilder::BatchNormTraining と the original batch normalization paper もご覧ください。
バッチ ディメンションと空間ディメンションにわたって配列を正規化します。
BatchNormTraining(operand, scale, offset, epsilon, feature_index)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
正規化する n 次元配列(x) |
scale |
XlaOp |
1 次元配列(\(\gamma\)) |
offset |
XlaOp |
1 次元配列(\(\beta\)) |
epsilon |
float |
イプシロン値(\(\epsilon\)) |
feature_index |
int64 |
operand の特徴量の次元のインデックス |
特徴量ディメンションの各特徴量(feature_index は operand の特徴量ディメンションのインデックス)について、このオペレーションは他のすべてのディメンションの平均と分散を計算し、その平均と分散を使用して operand の各要素を正規化します。feature_index は、operand の特徴ディメンションの有効なインデックスである必要があります。
アルゴリズムは、空間次元のサイズとして w と h を含む m 要素を含む operand \(x\) の各バッチに対して次のように実行されます(operand は 4 次元配列と仮定)。
特徴ディメンションの各特徴
lのバッチ平均 \(\mu_l\) を計算します。 \(\mu_l=\frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h x_{ijkl}\)バッチ分散を計算します。 \(\sigma^2_l\): $\sigma^2l=\frac{1}{mwh}\sum{i=1}^m\sum{j=1}^w\sum{k=1}^h (x_{ijkl} - \mu_l)^2$
正規化、スケーリング、シフト:\(y_{ijkl}=\frac{\gamma_l(x_{ijkl}-\mu_l)}{\sqrt[2]{\sigma^2_l+\epsilon} }+\beta_l\)
通常は小さい数値であるイプシロン値が追加され、ゼロ除算エラーが回避されます。
出力の型は、3 つの XlaOp のタプルです。
| 出力 | タイプ | セマンティクス |
|---|---|---|
output
|
XlaOp
|
入力 operand(y)と同じ形状の n 次元配列 |
batch_mean |
XlaOp |
1 次元配列(\(\mu\)) |
batch_var |
XlaOp |
1 次元配列(\(\sigma^2\)) |
batch_mean と batch_var は、上記の式を使用してバッチ ディメンションと空間ディメンション全体で計算されたモーメントです。
StableHLO の詳細については、StableHLO - batch_norm_training をご覧ください。
Bitcast
HloInstruction::CreateBitcast もご覧ください。
Bitcast は HLO ダンプに表示されることがありますが、エンドユーザーが手動で構築することを意図したものではありません。
BitcastConvertType
XlaBuilder::BitcastConvertType もご覧ください。
TensorFlow の tf.bitcast と同様に、データシェイプからターゲット シェイプへの要素ごとのビットキャスト オペレーションを実行します。入力サイズと出力サイズは一致している必要があります。たとえば、s32 要素はビットキャスト ルーティンを介して f32 要素になり、1 つの s32 要素は 4 つの s8 要素になります。ビットキャストは低レベルのキャストとして実装されるため、浮動小数点表現が異なるマシンでは異なる結果が得られます。
BitcastConvertType(operand, new_element_type)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
次元 D の型 T の配列 |
new_element_type |
PrimitiveType |
タイプ U |
オペランドとターゲット シェイプのディメンションは、変換前後のプリミティブ サイズの比率で変更される最後のディメンションを除き、一致している必要があります。
ソース要素と宛先要素の型はタプルにできません。
StableHLO の詳細については、StableHLO - bitcast_convert をご覧ください。
異なる幅のプリミティブ型へのビットキャスト変換
BitcastConvert HLO 命令は、出力要素型 T' のサイズが入力要素 T のサイズと等しくない場合をサポートします。オペレーション全体は概念的にはビットキャストであり、基盤となるバイトを変更しないため、出力要素の形状を変更する必要があります。B = sizeof(T), B' =
sizeof(T') には、次の 2 つのケースがあります。
まず、B > B' の場合、出力形状にはサイズ B/B' の新しい最小次元が追加されます。次に例を示します。
f16[10,2]{1,0} %output = f16[10,2]{1,0} bitcast-convert(f32[10]{0} %input)
有効なスカラーのルールは同じです。
f16[2]{0} %output = f16[2]{0} bitcast-convert(f32[] %input)
また、B' > B の場合、入力シェイプの最後の論理ディメンションが B'/B と等しくなるように指示する必要があります。このディメンションは変換時に削除されます。
f32[10]{0} %output = f32[10]{0} bitcast-convert(f16[10,2]{1,0} %input)
異なるビット幅間の変換は要素ごとに行われません。
ブロードキャスト
XlaBuilder::Broadcast もご覧ください。
配列内のデータを複製して、配列にディメンションを追加します。
Broadcast(operand, broadcast_sizes)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
複製する配列 |
broadcast_sizes |
ArraySlice<int64> |
新しいディメンションのサイズ |
新しいディメンションは左側に挿入されます。つまり、broadcast_sizes の値が {a0, ..., aN} で、オペランドの形状のディメンションが {b0, ..., bM} の場合、出力の形状のディメンションは {a0, ..., aN, b0, ..., bM} になります。
新しいディメンションは、オペランドのコピーにインデックスを付けます。
output[i0, ..., iN, j0, ..., jM] = operand[j0, ..., jM]
たとえば、operand が値 2.0f のスカラー f32 で、broadcast_sizes が {2, 3} の場合、結果は形状 f32[2, 3] の配列になり、結果のすべての値は 2.0f になります。
StableHLO の詳細については、StableHLO - ブロードキャストをご覧ください。
BroadcastInDim
XlaBuilder::BroadcastInDim もご覧ください。
配列内のデータを複製して、配列のサイズとディメンションの数を拡大します。
BroadcastInDim(operand, out_dim_size, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
複製する配列 |
out_dim_size
|
ArraySlice<int64>
|
ターゲット シェイプのディメンションのサイズ |
broadcast_dimensions
|
ArraySlice<int64>
|
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
ブロードキャストに似ていますが、任意の場所にディメンションを追加したり、サイズ 1 の既存のディメンションを拡張したりできます。
operand は、out_dim_size で記述された形状にブロードキャストされます。broadcast_dimensions は、operand のディメンションをターゲット形状のディメンションにマッピングします。つまり、オペランドの i 番目のディメンションは、出力形状の broadcast_dimension[i] 番目のディメンションにマッピングされます。operand のディメンションのサイズは 1 であるか、マッピング先の出力シェイプのディメンションと同じサイズである必要があります。残りのディメンションはサイズ 1 のディメンションで埋められます。縮退次元ブロードキャストは、これらの縮退次元に沿ってブロードキャストし、出力形状に到達します。セマンティクスについては、ブロードキャストのページで詳しく説明しています。
電話
XlaBuilder::Call もご覧ください。
指定された引数を使用して計算を呼び出します。
Call(computation, operands...)
| 引数 | タイプ | セマンティクス |
|---|---|---|
computation
|
XlaComputation
|
任意の型の N 個のパラメータを持つ T_0, T_1, ...,
T_{N-1} -> S 型の計算 |
operands |
N 個の XlaOp のシーケンス |
任意の型の N 個の引数 |
operands の項数と型は、computation のパラメータと一致する必要があります。operands がなくても構いません。
CompositeCall
XlaBuilder::CompositeCall もご覧ください。
他の StableHLO オペレーションで構成されるオペレーションをカプセル化し、入力と composite_attributes を受け取って結果を生成します。op のセマンティクスは分解属性によって実装されます。複合演算は、プログラムのセマンティクスを変更することなく、その分解に置き換えることができます。分解をインライン化しても同じオペレーション セマンティクスが提供されない場合は、custom_call の使用を優先します。
バージョン フィールド(デフォルトは 0)は、複合のセマンティクスが変更されたタイミングを示すために使用されます。
このオペレーションは、属性 is_composite=true を持つ kCall として実装されます。decomposition フィールドは computation 属性で指定します。フロントエンド属性には、composite. という接頭辞が付いた残りの属性が格納されます。
CompositeCall オペレーションの例:
f32[] call(f32[] %cst), to_apply=%computation, is_composite=true,
frontend_attributes = {
composite.name="foo.bar",
composite.attributes={n = 1 : i32, tensor = dense<1> : tensor<i32>},
composite.version="1"
}
CompositeCall(computation, operands..., name, attributes, version)
| 引数 | タイプ | セマンティクス |
|---|---|---|
computation
|
XlaComputation
|
任意の型の N 個のパラメータを持つ T_0, T_1, ...,
T_{N-1} -> S 型の計算 |
operands |
N 個の XlaOp のシーケンス |
可変個数の値 |
name |
string |
複合の名前 |
attributes
|
省略可 string
|
属性の文字列化された辞書(省略可) |
version
|
省略可 int64
|
複合オペレーションのセマンティクスにバージョン更新の数を指定します。 |
op の decomposition は呼び出されるフィールドではなく、下位レベルの実装(to_apply=%funcname)を含む関数を指す to_apply 属性として表示されます。
合成と分解の詳細については、StableHLO 仕様をご覧ください。
Cbrt
XlaBuilder::Cbrt もご覧ください。
要素ごとの立方根演算 x -> cbrt(x)。
Cbrt(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Cbrt は、オプションの result_accuracy 引数もサポートしています。
Cbrt(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
StableHLO の詳細については、StableHLO - cbrt をご覧ください。
切り上げ
XlaBuilder::Ceil もご覧ください。
要素ごとの天井関数 x -> ⌈x⌉。
Ceil(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
StableHLO の情報については、StableHLO - ceil をご覧ください。
Cholesky
XlaBuilder::Cholesky もご覧ください。
対称(エルミート)正定値行列のバッチの Cholesky 分解を計算します。
Cholesky(a, lower)
| 引数 | タイプ | セマンティクス |
|---|---|---|
a
|
XlaOp
|
2 次元を超える複素数型または浮動小数点型の配列。 |
lower |
bool |
a の上向きの三角形と下向きの三角形のどちらを使用するか。 |
lower が true の場合、$a = l$ となる下三角行列 l を計算します。l^T$。lower が false の場合、\(a = u^T . u\)となる上三角行列 u を計算します。
入力データは、lower の値に応じて a の下三角または上三角からのみ読み取られます。もう一方の三角形の値は無視されます。出力データは同じ三角形で返されます。もう一方の三角形の値は実装定義であり、任意の値にすることができます。
a の次元が 2 より大きい場合、a は行列のバッチとして扱われます。ここで、下位 2 次元を除くすべての次元がバッチ ディメンションになります。
a が対称(エルミート)正定値でない場合、結果は実装定義になります。
StableHLO の詳細については、StableHLO - cholesky をご覧ください。
範囲制限
XlaBuilder::Clamp もご覧ください。
オペランドを最小値と最大値の範囲内にクランプします。
Clamp(min, operand, max)
| 引数 | タイプ | セマンティクス |
|---|---|---|
min |
XlaOp |
型 T の配列 |
operand |
XlaOp |
型 T の配列 |
max |
XlaOp |
型 T の配列 |
オペランドと最小値、最大値が指定された場合、オペランドが最小値と最大値の範囲内であればオペランドを返し、オペランドがこの範囲を下回る場合は最小値を返し、オペランドがこの範囲を上回る場合は最大値を返します。つまり、clamp(a, x, b) = min(max(a, x), b) のようになります。
3 つの配列はすべて同じ形状にする必要があります。または、ブロードキャストの制限付き形式として、min や max を T 型のスカラーにすることもできます。
スカラー min と max を使用した例:
let operand: s32[3] = {-1, 5, 9};
let min: s32 = 0;
let max: s32 = 6;
==>
Clamp(min, operand, max) = s32[3]{0, 5, 6};
StableHLO の詳細については、StableHLO - clamp をご覧ください。
閉じる
XlaBuilder::Collapseもご覧ください。tf.reshape オペレーション。
配列のディメンションを 1 つのディメンションに折りたたみます。
Collapse(operand, dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
型 T の配列 |
dimensions |
int64 ベクトル |
T のディメンションの順序どおりの連続したサブセット。 |
Collapse は、オペランドのディメンションの指定されたサブセットを単一のディメンションに置き換えます。入力引数は、型 T の任意の配列と、ディメンション インデックスのコンパイル時定数ベクトルです。ディメンション インデックスは、T のディメンションの順序どおりの(ディメンション番号の小さい順)連続したサブセットである必要があります。したがって、{0, 1, 2}、{0, 1}、{1, 2} はすべて有効なディメンション セットですが、{1, 0} や {0, 2} は有効ではありません。これらは、置き換えられるディメンションと同じディメンション シーケンス内の位置にある単一の新しいディメンションに置き換えられます。新しいディメンションのサイズは、元のディメンションのサイズの積に等しくなります。dimensions の最小のディメンション番号は、これらのディメンションを折りたたむループネストの最も変化の遅い(最も大きい)ディメンションであり、最大のディメンション番号は最も変化の速い(最も小さい)ディメンションです。より一般的な折りたたみ順序が必要な場合は、tf.reshape 演算子をご覧ください。
たとえば、v を 24 個の要素の配列とします。
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
// Collapse to a single dimension, leaving one dimension.
let v012 = Collapse(v, {0,1,2});
then v012 == f32[24] {10, 11, 12, 15, 16, 17,
20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37,
40, 41, 42, 45, 46, 47};
// Collapse the two lower dimensions, leaving two dimensions.
let v01 = Collapse(v, {0,1});
then v01 == f32[4x6] { {10, 11, 12, 15, 16, 17},
{20, 21, 22, 25, 26, 27},
{30, 31, 32, 35, 36, 37},
{40, 41, 42, 45, 46, 47} };
// Collapse the two higher dimensions, leaving two dimensions.
let v12 = Collapse(v, {1,2});
then v12 == f32[8x3] { {10, 11, 12},
{15, 16, 17},
{20, 21, 22},
{25, 26, 27},
{30, 31, 32},
{35, 36, 37},
{40, 41, 42},
{45, 46, 47} };
Clz
XlaBuilder::Clz もご覧ください。
要素ごとに先頭のゼロの数をカウントします。
Clz(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
CollectiveBroadcast
XlaBuilder::CollectiveBroadcast もご覧ください。
レプリカ間でデータをブロードキャストします。各グループの最初のレプリカ ID から、同じグループ内の他の ID にデータが送信されます。レプリカ ID がレプリカ グループに属していない場合、そのレプリカの出力は shape の 0 で構成されるテンソルになります。
CollectiveBroadcast(operand, replica_groups, channel_id)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
replica_groups
|
ReplicaGroupvector
|
各グループには、レプリカ ID のリストが含まれています。 |
channel_id
|
省略可 ChannelHandle
|
各送受信ペアの一意の識別子 |
StableHLO の詳細については、StableHLO - collective_broadcast をご覧ください。
CollectivePermute
XlaBuilder::CollectivePermute もご覧ください。
CollectivePermute は、レプリカ間でデータを送受信する集団オペレーションです。
CollectivePermute(operand, source_target_pairs, channel_id)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
n 次元入力配列 |
source_target_pairs
|
<int64, int64> ベクトル
|
(source_replica_id, target_replica_id) ペアのリスト。各ペアについて、オペランドはソースレプリカからターゲット レプリカに送信されます。 |
channel_id
|
省略可 ChannelHandle
|
クロスモジュール通信用のオプションのチャンネル ID |
source_target_pairs には次の制限があります。
- 2 つのペアに同じターゲット レプリカ ID を使用することはできません。また、同じソース レプリカ ID を使用することもできません。
- レプリカ ID がペアのターゲットでない場合、そのレプリカの出力は、入力と同じ形状の 0 で構成されるテンソルになります。
CollectivePermute オペレーションの API は、内部的に 2 つの HLO 命令(CollectivePermuteStart と CollectivePermuteDone)に分解されます。
HloInstruction::CreateCollectivePermuteStart もご覧ください。
CollectivePermuteStart と CollectivePermuteDone は HLO のプリミティブとして機能します。これらのオペレーションは HLO ダンプに表示されることがありますが、エンドユーザーが手動で構築することを想定していません。
StableHLO の情報については、StableHLO - collective_permute をご覧ください。
比較
XlaBuilder::Compare もご覧ください。
次の lhs と rhs の要素ごとの比較を行います。
Eq
XlaBuilder::Eq もご覧ください。
lhs と rhs の要素ごとの等しい比較を行います。
\(lhs = rhs\)
Eq(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Eq には、異なる次元のブロードキャストをサポートする別のバリアントがあります。
Eq(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
浮動小数点数に対する全順序を Eq でサポートするには、次の条件を適用します。
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
EqTotalOrder(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
StableHLO の詳細については、StableHLO - 比較をご覧ください。
Ne
XlaBuilder::Ne もご覧ください。
lhs と rhs の要素ごとの等しくない比較を行います。
\(lhs != rhs\)
Ne(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Ne には、異なる次元のブロードキャストをサポートする代替バリアントがあります。
Ne(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
Ne では、次の制約により、浮動小数点数を超える合計注文をサポートしています。
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
NeTotalOrder(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
StableHLO の詳細については、StableHLO - 比較をご覧ください。
Ge
XlaBuilder::Ge もご覧ください。
lhs と rhs の要素ごとのgreater-or-equal-than比較を行います。
\(lhs >= rhs\)
Ge(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Ge には、異なる次元のブロードキャストをサポートする代替バリアントがあります。
Ge(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
Gt の浮動小数点数に対する全順序をサポートします。次の条件を適用します。
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
GtTotalOrder(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
StableHLO の詳細については、StableHLO - 比較をご覧ください。
Gt
XlaBuilder::Gt もご覧ください。
lhs と rhs の要素ごとの大なり比較を行います。
\(lhs > rhs\)
Gt(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Gt には、異なる次元のブロードキャストをサポートする代替バリアントが存在します。
Gt(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の詳細については、StableHLO - 比較をご覧ください。
Le
XlaBuilder::Le もご覧ください。
lhs と rhs の要素ごとのless-or-equal-than比較を行います。
\(lhs <= rhs\)
Le(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Le には、異なる次元のブロードキャストをサポートする代替バリアントがあります。
Le(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
Le の合計注文が浮動小数点数を超える場合をサポートします。次の条件を適用します。
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
LeTotalOrder(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
StableHLO の詳細については、StableHLO - 比較をご覧ください。
Lt
XlaBuilder::Lt もご覧ください。
lhs と rhs の要素ごとの小なり比較を行います。
\(lhs < rhs\)
Lt(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Lt には、異なる次元のブロードキャストをサポートする代替バリアントがあります。
Lt(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
Lt の浮動小数点数を超える合計注文をサポートします。次の条件を適用します。
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
LtTotalOrder(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
StableHLO の詳細については、StableHLO - 比較をご覧ください。
複雑
XlaBuilder::Complex もご覧ください。
実数値と虚数値のペア lhs と rhs から複素数値への要素ごとの変換を行います。
Complex(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Complex には、異なる次元のブロードキャストをサポートする代替バリアントがあります。
Complex(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の詳細については、StableHLO - 複雑をご覧ください。
ConcatInDim(連結)
XlaBuilder::ConcatInDim もご覧ください。
Concatenate は、複数の配列オペランドから配列を作成します。配列の次元数は、入力配列オペランドの次元数と同じです(入力配列オペランドの次元数は互いに同じである必要があります)。また、配列には、指定された順序で引数が含まれます。
Concatenate(operands..., dimension)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operands
|
N 個の XlaOp のシーケンス |
ディメンション [L0, L1, ...] を持つ型 T の N 個の配列。N >= 1 が必要です。 |
dimension
|
int64
|
operands の間に連結するディメンションの名前を指定する [0, N) の値。 |
dimension を除くすべてのディメンションは同じである必要があります。これは、XLA が「不揃い」な配列をサポートしていないためです。また、0 次元値は連結できません(連結が発生するディメンションに名前を付けることができないため)。
1 次元の例:
Concat({ {2, 3}, {4, 5}, {6, 7} }, 0)
//Output: {2, 3, 4, 5, 6, 7}
2 次元の例:
let a = { {1, 2},
{3, 4},
{5, 6} };
let b = { {7, 8} };
Concat({a, b}, 0)
//Output: { {1, 2},
// {3, 4},
// {5, 6},
// {7, 8} }
図:
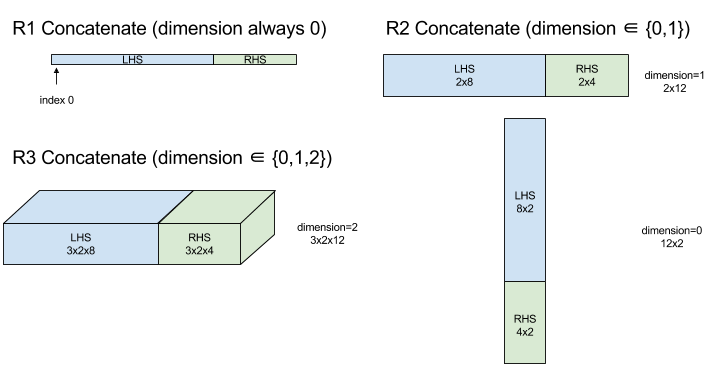
StableHLO の詳細については、StableHLO - 連結をご覧ください。
条件文
XlaBuilder::Conditional もご覧ください。
Conditional(predicate, true_operand, true_computation, false_operand,
false_computation)
| 引数 | タイプ | セマンティクス |
|---|---|---|
predicate |
XlaOp |
PRED 型のスカラー |
true_operand |
XlaOp |
型 \(T_0\)の引数 |
true_computation |
XlaComputation |
型 \(T_0 \to S\)の XlaComputation |
false_operand |
XlaOp |
型 \(T_1\)の引数 |
false_computation |
XlaComputation |
型 \(T_1 \to S\)の XlaComputation |
predicate が true の場合は true_computation を、predicate が false の場合は false_computation を実行し、結果を返します。
true_computation は \(T_0\) 型の単一の引数を取り、同じ型の true_operand で呼び出されます。false_computation は \(T_1\) 型の単一の引数を取り、同じ型の false_operand で呼び出されます。true_computation と false_computation の戻り値の型は同じである必要があります。
predicate の値に応じて、true_computation と false_computation のいずれか 1 つのみが実行されます。
Conditional(branch_index, branch_computations, branch_operands)
| 引数 | タイプ | セマンティクス |
|---|---|---|
branch_index |
XlaOp |
S32 型のスカラー |
branch_computations |
N 個の XlaComputation のシーケンス |
タイプ \(T_0 \to S , T_1 \to S , ..., T_{N-1} \to S\)の XlaComputations |
branch_operands |
N 個の XlaOp のシーケンス |
型 \(T_0 , T_1 , ..., T_{N-1}\)の引数 |
branch_computations[branch_index] を実行し、結果を返します。branch_index が 0 未満または N 以上の S32 の場合、branch_computations[N-1] がデフォルトのブランチとして実行されます。
各 branch_computations[b] は \(T_b\) 型の単一の引数を取り、同じ型である branch_operands[b] で呼び出されます。各 branch_computations[b] の戻り値の型は同じである必要があります。
branch_index の値に応じて、branch_computations のいずれか 1 つのみが実行されます。
StableHLO の詳細については、StableHLO - if をご覧ください。
定数
XlaBuilder::ConstantLiteral もご覧ください。
定数 literal から output を生成します。
Constant(literal)
| 引数 | タイプ | セマンティクス |
|---|---|---|
literal |
LiteralSlice |
既存の Literal の定数ビュー |
StableHLO の情報については、StableHLO - constant をご覧ください。
ConvertElementType
XlaBuilder::ConvertElementType もご覧ください。
C++ の要素ごとの static_cast と同様に、ConvertElementType はデータシェイプからターゲット シェイプへの要素ごとの変換オペレーションを実行します。ディメンションは一致している必要があり、変換は要素ごとに行われます。たとえば、s32 要素は s32 から f32 への変換ルーティンを介して f32 要素になります。
ConvertElementType(operand, new_element_type)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
次元 D の型 T の配列 |
new_element_type |
PrimitiveType |
タイプ U |
オペランドのディメンションとターゲットの形状は一致している必要があります。ソース要素と宛先要素の型はタプルであってはなりません。
T=s32 から U=f32 への変換などの変換では、最近接偶数丸めなどの正規化 int から float への変換ルーチンが実行されます。
let a: s32[3] = {0, 1, 2};
let b: f32[3] = convert(a, f32);
then b == f32[3]{0.0, 1.0, 2.0}
StableHLO の詳細については、StableHLO - 変換をご覧ください。
Conv(畳み込み)
XlaBuilder::Conv もご覧ください。
ニューラル ネットワークで使用される種類の畳み込みを計算します。ここで、畳み込みは、n 次元ベース領域を移動する n 次元ウィンドウと考えることができます。ウィンドウの可能な各位置に対して計算が実行されます。
Conv 畳み込み命令を計算にエンキューします。この計算では、拡張なしのデフォルトの畳み込みディメンション番号が使用されます。
パディングは、SAME または VALID のいずれかとして短縮形で指定されます。SAME パディングは、ストライドを考慮しない場合に出力が入力と同じ形状になるように、入力(lhs)をゼロでパディングします。VALID パディングは、単にパディングがないことを意味します。
Conv(lhs, rhs, window_strides, padding, feature_group_count,
batch_group_count, precision_config, preferred_element_type)
| 引数 | タイプ | セマンティクス |
|---|---|---|
lhs
|
XlaOp
|
入力の (n+2) 次元配列 |
rhs
|
XlaOp
|
カーネル重みの (n+2) 次元配列 |
window_strides |
ArraySlice<int64> |
カーネル ストライドの n 次元配列 |
padding |
Padding |
パディングの列挙型 |
feature_group_count
|
int64 | 特徴グループの数 |
batch_group_count |
int64 | バッチグループの数 |
precision_config
|
省略可
PrecisionConfig |
精度のレベルの列挙型 |
preferred_element_type
|
省略可
PrimitiveType |
スカラー要素型の列挙型 |
Conv では、次のレベルの制御が可能です。
n を空間次元の数とします。lhs 引数は、ベース領域を記述する(n+2)次元配列です。これは入力と呼ばれますが、もちろん rhs も入力です。ニューラル ネットワークでは、これらは入力アクティベーションです。n+2 次元は次の順序です。
batch: このディメンションの各座標は、畳み込みが実行される独立した入力を表します。z/depth/features: ベースエリアの各 (y,x) 位置には、このディメンションに入るベクトルが関連付けられています。spatial_dims: ウィンドウが移動するベース領域を定義するn空間ディメンションを記述します。
rhs 引数は、畳み込みフィルタ/カーネル/ウィンドウを記述する(n+2)次元配列です。次元は次の順序で指定します。
output-z: 出力のzディメンション。input-z: このディメンションのサイズにfeature_group_countを掛けた値は、lhs のzディメンションのサイズと等しくなければなりません。spatial_dims: ベースエリアを移動する n 次元ウィンドウを定義するn空間ディメンションを記述します。
window_strides 引数は、空間次元の畳み込みウィンドウのストライドを指定します。たとえば、最初の空間次元のストライドが 3 の場合、ウィンドウは最初の空間インデックスが 3 で割り切れる座標にのみ配置できます。
padding 引数は、ベース領域に適用するゼロパディングの量を指定します。パディングの量は負の値にできます。負のパディングの絶対値は、畳み込みを行う前に指定されたディメンションから削除する要素の数を示します。padding[0] はディメンション y のパディングを指定し、padding[1] はディメンション x のパディングを指定します。各ペアの最初の要素は下限のパディング、2 番目の要素は上限のパディングです。低いパディングはインデックスが小さい方向に適用され、高いパディングはインデックスが大きい方向に適用されます。たとえば、padding[1] が (2,3) の場合、2 番目の空間次元の左側に 2 つのゼロ、右側に 3 つのゼロがパディングされます。パディングを使用することは、畳み込みを行う前に同じゼロ値を入力(lhs)に挿入することと同じです。
lhs_dilation 引数と rhs_dilation 引数は、各空間次元で lhs と rhs にそれぞれ適用される拡張率を指定します。空間次元の拡張率が d の場合、その次元の各エントリ間に d-1 個の穴が暗黙的に配置され、配列のサイズが増加します。穴は no-op 値で埋められます。畳み込みの場合、これはゼロを意味します。
右辺の拡張は、アトラス畳み込みとも呼ばれます。詳しくは、tf.nn.atrous_conv2d をご覧ください。左辺の拡張は、転置畳み込みとも呼ばれます。詳しくは、tf.nn.conv2d_transpose をご覧ください。
feature_group_count 引数(デフォルト値は 1)は、グループ化された畳み込みに使用できます。feature_group_count は、入力特徴と出力特徴の両方の次元の約数である必要があります。feature_group_count が 1 より大きい場合、入力特徴と出力特徴の次元と rhs 出力特徴の次元が、それぞれ feature_group_count 個のグループに均等に分割されます。各グループは、特徴の連続するサブシーケンスで構成されます。rhs の入力特徴の次元は、lhs 入力特徴の次元を feature_group_count で割った値と等しくする必要があります(つまり、入力特徴のグループのサイズになります)。i 番目のグループは、feature_group_count 個の個別の畳み込みを計算するために一緒に使用されます。これらの畳み込みの結果は、出力特徴の次元で連結されます。
デプスワイズ畳み込みの場合、feature_group_count 引数は入力特徴ディメンションに設定され、フィルタは [filter_height, filter_width, in_channels, channel_multiplier] から [filter_height, filter_width, 1, in_channels * channel_multiplier] に再形成されます。詳細については、tf.nn.depthwise_conv2d をご覧ください。
batch_group_count(デフォルト値は 1)引数は、バックプロパゲーション中のグループ化されたフィルタに使用できます。batch_group_count は、lhs(入力)バッチ ディメンションのサイズの約数である必要があります。batch_group_count が 1 より大きい場合、出力バッチ ディメンションのサイズは input batch
/ batch_group_count になります。batch_group_count は、出力特徴サイズの約数である必要があります。
出力形状には、次の順序で次のディメンションがあります。
batch: このディメンションのサイズにbatch_group_countを掛けた値は、lhs のbatchディメンションのサイズと等しくなるはずです。z: カーネルのoutput-zと同じサイズ(rhs)。spatial_dims: 畳み込みウィンドウの有効な配置ごとに 1 つの値。

上の図は、batch_group_count フィールドの仕組みを示しています。実際には、各 lhs バッチを batch_group_count グループに分割し、出力特徴についても同様の処理を行います。次に、これらの各グループに対してペアワイズ畳み込みを行い、出力特徴ディメンションに沿って出力を連結します。他のすべてのディメンション(特徴と空間)のオペレーション セマンティクスは変わりません。
畳み込みウィンドウの有効な配置は、ストライドとパディング後のベース領域のサイズによって決まります。
畳み込みの動作を説明するために、2D 畳み込みを考え、出力で固定の batch、z、y、x 座標を選択します。次に、(y,x) はベース領域内のウィンドウの角の位置です(空間次元の解釈方法に応じて、左上隅など)。これで、ベース領域から取得された 2D ウィンドウができました。各 2D ポイントは 1D ベクトルに関連付けられているため、3D ボックスができます。畳み込みカーネルから、出力座標 z を固定したため、3D ボックスもできます。2 つのボックスのサイズは同じであるため、2 つのボックス間の要素ごとの積の合計を取得できます(内積と同様)。これが出力値です。
output-z が 5 の場合、ウィンドウの各位置で出力の z ディメンションに 5 つの値が生成されます。これらの値は、畳み込みカーネルのどの部分が使用されるかによって異なります。各 output-z 座標に使用される値の 3D ボックスは別個に存在します。つまり、それぞれに異なるフィルタを使用した 5 つの個別の畳み込みと考えることができます。
パディングとストライドを使用した 2D 畳み込みの擬似コードは次のとおりです。
for (b, oz, oy, ox) { // output coordinates
value = 0;
for (iz, ky, kx) { // kernel coordinates and input z
iy = oy*stride_y + ky - pad_low_y;
ix = ox*stride_x + kx - pad_low_x;
if ((iy, ix) inside the base area considered without padding) {
value += input(b, iz, iy, ix) * kernel(oz, iz, ky, kx);
}
}
output(b, oz, oy, ox) = value;
}
precision_config は、精度構成を示すために使用されます。レベルは、必要に応じてより正確な dtype エミュレーションを提供するために、ハードウェアがより多くのマシンコード命令を生成しようとするかどうかを決定します(bf16 matmul のみをサポートする TPU で f32 をエミュレートするなど)。値は DEFAULT、HIGH、HIGHEST になります。詳細については、MXU セクションをご覧ください。
preferred_element_type は、累算に使用される高精度/低精度の出力型のスカラー要素です。preferred_element_type は、特定のオペレーションの累算型を推奨しますが、保証はされません。これにより、一部のハードウェア バックエンドでは、別の型で累算し、優先出力型に変換できます。
StableHLO の詳細については、StableHLO - 畳み込みをご覧ください。
ConvWithGeneralPadding
XlaBuilder::ConvWithGeneralPadding もご覧ください。
ConvWithGeneralPadding(lhs, rhs, window_strides, padding,
feature_group_count, batch_group_count, precision_config,
preferred_element_type)
パディング構成が明示的な Conv と同じです。
| 引数 | タイプ | セマンティクス |
|---|---|---|
lhs
|
XlaOp
|
入力の (n+2) 次元配列 |
rhs
|
XlaOp
|
カーネル重みの (n+2) 次元配列 |
window_strides |
ArraySlice<int64> |
カーネル ストライドの n 次元配列 |
padding
|
ArraySlice<
pair<int64,int64>> |
(低、高)パディングの n 次元配列 |
feature_group_count
|
int64 | 特徴グループの数 |
batch_group_count |
int64 | バッチグループの数 |
precision_config
|
省略可
PrecisionConfig |
精度のレベルの列挙型 |
preferred_element_type
|
省略可
PrimitiveType |
スカラー要素型の列挙型 |
ConvWithGeneralDimensions
XlaBuilder::ConvWithGeneralDimensions もご覧ください。
ConvWithGeneralDimensions(lhs, rhs, window_strides, padding,
dimension_numbers, feature_group_count, batch_group_count, precision_config,
preferred_element_type)
ディメンション番号が明示されている Conv と同じです。
| 引数 | タイプ | セマンティクス |
|---|---|---|
lhs
|
XlaOp
|
入力の (n+2) 次元配列 |
rhs
|
XlaOp
|
カーネル重みの (n+2) 次元配列 |
window_strides
|
ArraySlice<int64>
|
カーネル ストライドの n 次元配列 |
padding |
Padding |
パディングの列挙型 |
dimension_numbers
|
ConvolutionDimensionNumbers
|
ディメンションの数 |
feature_group_count
|
int64 | 特徴グループの数 |
batch_group_count
|
int64 | バッチグループの数 |
precision_config
|
省略可 PrecisionConfig
|
精度のレベルの列挙型 |
preferred_element_type
|
省略可 PrimitiveType
|
スカラー要素型の列挙型 |
ConvGeneral
XlaBuilder::ConvGeneral もご覧ください。
ConvGeneral(lhs, rhs, window_strides, padding, dimension_numbers,
feature_group_count, batch_group_count, precision_config,
preferred_element_type)
ディメンション番号とパディング構成が明示的な Conv と同じ
| 引数 | タイプ | セマンティクス |
|---|---|---|
lhs
|
XlaOp
|
入力の (n+2) 次元配列 |
rhs
|
XlaOp
|
カーネル重みの (n+2) 次元配列 |
window_strides
|
ArraySlice<int64>
|
カーネル ストライドの n 次元配列 |
padding
|
ArraySlice<
pair<int64,int64>>
|
(low, high) パディングの n 次元配列 |
dimension_numbers
|
ConvolutionDimensionNumbers
|
ディメンションの数 |
feature_group_count
|
int64 | 特徴グループの数 |
batch_group_count
|
int64 | バッチグループの数 |
precision_config
|
省略可 PrecisionConfig
|
精度のレベルの列挙型 |
preferred_element_type
|
省略可 PrimitiveType
|
スカラー要素型の列挙型 |
ConvGeneralDilated
XlaBuilder::ConvGeneralDilated もご覧ください。
ConvGeneralDilated(lhs, rhs, window_strides, padding, lhs_dilation,
rhs_dilation, dimension_numbers, feature_group_count, batch_group_count,
precision_config, preferred_element_type, window_reversal)
パディング構成、拡張率、次元数が明示的な Conv と同じです。
| 引数 | タイプ | セマンティクス |
|---|---|---|
lhs
|
XlaOp
|
入力の (n+2) 次元配列 |
rhs
|
XlaOp
|
カーネル重みの (n+2) 次元配列 |
window_strides
|
ArraySlice<int64>
|
カーネル ストライドの n 次元配列 |
padding
|
ArraySlice<
pair<int64,int64>>
|
(low, high) パディングの n 次元配列 |
lhs_dilation
|
ArraySlice<int64>
|
n-d lhs 拡張係数配列 |
rhs_dilation
|
ArraySlice<int64>
|
n-d rhs 拡張係数配列 |
dimension_numbers
|
ConvolutionDimensionNumbers
|
ディメンションの数 |
feature_group_count
|
int64 | 特徴グループの数 |
batch_group_count
|
int64 | バッチグループの数 |
precision_config
|
省略可 PrecisionConfig
|
精度のレベルの列挙型 |
preferred_element_type
|
省略可 PrimitiveType
|
スカラー要素型の列挙型 |
window_reversal
|
省略可 vector<bool>
|
畳み込みを適用する前にディメンションを論理的に反転するために使用されるフラグ |
コピー
HloInstruction::CreateCopyStart もご覧ください。
Copy は内部的に 2 つの HLO 命令 CopyStart と CopyDone に分解されます。Copy は CopyStart および CopyDone とともに HLO のプリミティブとして機能します。これらのオペレーションは HLO ダンプに表示されることがありますが、エンドユーザーが手動で構築することを想定していません。
Cos
XlaBuilder::Cosもご覧ください。
要素単位のコサイン x -> cos(x)。
Cos(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Cos は、省略可能な result_accuracy 引数もサポートしています。
Cos(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
StableHLO の詳細については、StableHLO - cosine をご覧ください。
Cosh
XlaBuilder::Cosh もご覧ください。
要素ごとの双曲線余弦 x -> cosh(x)。
Cosh(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Cosh は、省略可能な result_accuracy 引数もサポートしています。
Cosh(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
CustomCall
XlaBuilder::CustomCall もご覧ください。
計算内でユーザー指定の関数を呼び出す。
CustomCall のドキュメントは、デベロッパーの詳細 - XLA カスタム呼び出しで提供されています。
StableHLO の情報については、StableHLO - custom_call をご覧ください。
Div
XlaBuilder::Div もご覧ください。
被除数 lhs と除数 rhs の要素ごとの除算を行います。
Div(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
整数除算のオーバーフロー(符号付き/符号なしの除算/ゼロによる剰余、または INT_SMIN と -1 の符号付き除算/剰余)は、実装定義の値を生成します。
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Div には、異なる次元のブロードキャストをサポートする別のバリアントがあります。
Div(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の詳細については、StableHLO - divide をご覧ください。
ドメイン
HloInstruction::CreateDomain もご覧ください。
Domain は HLO ダンプに表示されることがありますが、エンドユーザーが手動で構築することを意図したものではありません。
ドット
XlaBuilder::Dot もご覧ください。
Dot(lhs, rhs, precision_config, preferred_element_type)
| 引数 | タイプ | セマンティクス |
|---|---|---|
lhs |
XlaOp |
型 T の配列 |
rhs |
XlaOp |
型 T の配列 |
precision_config
|
省略可
PrecisionConfig |
精度のレベルの列挙型 |
preferred_element_type
|
省略可
PrimitiveType |
スカラー要素型の列挙型 |
このオペレーションの正確なセマンティクスは、オペランドのランクによって異なります。
| 入力 | 出力 | セマンティクス |
|---|---|---|
vector [n] dot vector [n] |
スカラー | ベクトルのドット積 |
行列 [m x k] dot ベクトル [k] |
ベクトル [m] | 行列とベクトルの乗算 |
行列 [m x k] dot 行列 [k x n] |
行列 [m x n] | 行列乗算 |
このオペレーションは、lhs の 2 番目のディメンション(1 つのディメンションしかない場合は 1 番目のディメンション)と rhs の 1 番目のディメンションの積の合計を計算します。これらは「縮小」ディメンションです。lhs と rhs の縮約されたディメンションは同じサイズである必要があります。実際には、ベクトル間のドット積、ベクトルと行列の乗算、行列と行列の乗算を実行するために使用できます。
precision_config は、精度構成を示すために使用されます。レベルは、必要に応じてより正確な dtype エミュレーションを提供するために、ハードウェアがより多くのマシンコード命令を生成しようとするかどうかを決定します(bf16 matmul のみをサポートする TPU で f32 をエミュレートするなど)。値は DEFAULT、HIGH、HIGHEST になります。詳細については、MXU セクションをご覧ください。
preferred_element_type は、累算に使用される高精度/低精度の出力型のスカラー要素です。preferred_element_type は、特定のオペレーションの累算型を推奨しますが、保証はされません。これにより、一部のハードウェア バックエンドでは、別の型で累算し、優先出力型に変換できます。
StableHLO の詳細については、StableHLO - dot をご覧ください。
DotGeneral
XlaBuilder::DotGeneral もご覧ください。
DotGeneral(lhs, rhs, dimension_numbers, precision_config,
preferred_element_type)
| 引数 | タイプ | セマンティクス |
|---|---|---|
lhs |
XlaOp |
型 T の配列 |
rhs |
XlaOp |
型 T の配列 |
dimension_numbers
|
DotDimensionNumbers
|
契約とバッチのディメンション番号 |
precision_config
|
省略可
PrecisionConfig |
精度のレベルの列挙型 |
preferred_element_type
|
省略可
PrimitiveType |
スカラー要素型の列挙型 |
Dot と同様ですが、lhs と rhs の両方で縮小とバッチの次元数を指定できます。
| DotDimensionNumbers フィールド | タイプ | セマンティクス |
|---|---|---|
lhs_contracting_dimensions
|
repeated int64 | lhs 個の契約ディメンション番号 |
rhs_contracting_dimensions
|
repeated int64 | rhs 個の契約ディメンション番号 |
lhs_batch_dimensions
|
repeated int64 | lhs バッチ ディメンション番号 |
rhs_batch_dimensions
|
repeated int64 | rhs バッチ ディメンション番号 |
DotGeneral は、dimension_numbers で指定された縮約ディメンションの積の合計を計算します。
lhs と rhs の関連する縮約ディメンション番号は同じである必要はありませんが、ディメンション サイズは同じである必要があります。
ディメンション番号を縮約する例:
lhs = { {1.0, 2.0, 3.0},
{4.0, 5.0, 6.0} }
rhs = { {1.0, 1.0, 1.0},
{2.0, 2.0, 2.0} }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(1);
dnums.add_rhs_contracting_dimensions(1);
DotGeneral(lhs, rhs, dnums) -> { { 6.0, 12.0},
{15.0, 30.0} }
lhs と rhs の関連するバッチ ディメンション番号は、同じディメンション サイズである必要があります。
バッチ ディメンション番号の例(バッチサイズ 2、2x2 行列):
lhs = { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
rhs = { { {1.0, 0.0},
{0.0, 1.0} },
{ {1.0, 0.0},
{0.0, 1.0} } }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(2);
dnums.add_rhs_contracting_dimensions(1);
dnums.add_lhs_batch_dimensions(0);
dnums.add_rhs_batch_dimensions(0);
DotGeneral(lhs, rhs, dnums) -> {
{ {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
| 入力 | 出力 | セマンティクス |
|---|---|---|
[b0, m, k] dot [b0, k, n] |
[b0, m, n] | バッチ matmul |
[b0, b1, m, k] dot [b0, b1, k, n] |
[b0, b1, m, n] | バッチ matmul |
結果として得られるディメンション番号は、バッチ ディメンション、lhs 非収縮/非バッチ ディメンション、rhs 非収縮/非バッチ ディメンションの順になります。
precision_config は、精度構成を示すために使用されます。レベルは、必要に応じてより正確な dtype エミュレーションを提供するために、ハードウェアがより多くのマシンコード命令を生成しようとするかどうかを決定します(bf16 matmuls のみをサポートする TPU で f32 をエミュレートするなど)。値は DEFAULT、HIGH、HIGHEST になります。詳細については、MXU セクションをご覧ください。
preferred_element_type は、累算に使用される高精度/低精度の出力型のスカラー要素です。preferred_element_type は、特定のオペレーションの累算型を推奨しますが、保証はされません。これにより、一部のハードウェア バックエンドでは、別の型で累算し、優先出力型に変換できます。
StableHLO の詳細については、StableHLO - dot_general をご覧ください。
ScaledDot
XlaBuilder::ScaledDot もご覧ください。
ScaledDot(lhs, lhs_scale, rhs, rhs_scale, dimension_number,
precision_config,preferred_element_type)
| 引数 | タイプ | セマンティクス |
|---|---|---|
lhs |
XlaOp |
型 T の配列 |
rhs |
XlaOp |
型 T の配列 |
lhs_scale |
XlaOp |
型 T の配列 |
rhs_scale |
XlaOp |
型 T の配列 |
dimension_number
|
ScatterDimensionNumbers
|
散布オペレーションのディメンション番号 |
precision_config
|
PrecisionConfig
|
精度のレベルの列挙型 |
preferred_element_type
|
省略可 PrimitiveType
|
スカラー要素型の列挙型 |
DotGeneral と同様です。
オペランド「lhs」、「lhs_scale」、「rhs」、「rhs_scale」を使用して、スケーリングされたドット演算を作成します。縮約ディメンションとバッチ ディメンションは「dimension_numbers」で指定します。
RaggedDot
XlaBuilder::RaggedDot もご覧ください。
RaggedDot 計算の内訳については、StableHLO - chlo.ragged_dot をご覧ください。
DynamicReshape
XlaBuilder::DynamicReshape もご覧ください。
このオペレーションは reshape と機能的に同じですが、結果の形状は output_shape を介して動的に指定されます。
DynamicReshape(operand, dim_sizes, new_size_bounds, dims_are_dynamic)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
型 T の N 次元配列 |
dim_sizes |
XlaOP のベクトル |
N 次元ベクトル サイズ |
new_size_bounds |
int63 のベクトル |
境界の N 次元ベクトル |
dims_are_dynamic |
bool のベクトル |
N 次元動的ディム |
StableHLO の詳細については、StableHLO - dynamic_reshape をご覧ください。
DynamicSlice
XlaBuilder::DynamicSlice もご覧ください。
DynamicSlice は、動的な start_indices で入力配列からサブ配列を抽出します。各ディメンションのスライスのサイズは size_indices で渡されます。これは、各ディメンションの排他的スライス間隔の終点を指定します([start, start + size))。start_indices の形状は 1 次元で、ディメンションのサイズは operand のディメンションの数と同じである必要があります。
DynamicSlice(operand, start_indices, slice_sizes)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
型 T の N 次元配列 |
start_indices
|
N 個の XlaOp のシーケンス |
各ディメンションのスライスの開始インデックスを含む N 個のスカラー整数のリスト。値は 0 以上である必要があります。 |
size_indices
|
ArraySlice<int64>
|
各ディメンションのスライスサイズを含む N 個の整数のリスト。各値は 0 より大きく、start + size はディメンションのサイズ以下である必要があります。これは、ディメンション サイズのモジュロ ラッピングを回避するためです。 |
有効なスライス インデックスは、スライスを実行する前に [1, N) の各インデックス i に次の変換を適用して計算されます。
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - slice_sizes[i])
これにより、抽出されたスライスは常にオペランド配列の範囲内になります。変換が適用される前にスライスが範囲内にある場合、変換は効果がありません。
1 次元の例:
let a = {0.0, 1.0, 2.0, 3.0, 4.0};
let s = {2};
DynamicSlice(a, s, {2});
// Result: {2.0, 3.0}
2 次元の例:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let s = {2, 1}
DynamicSlice(b, s, {2, 2});
//Result:
// { { 7.0, 8.0},
// {10.0, 11.0} }
StableHLO の詳細については、StableHLO - dynamic_slice をご覧ください。
DynamicUpdateSlice
XlaBuilder::DynamicUpdateSlice もご覧ください。
DynamicUpdateSlice は、入力配列 operand の値(スライス update が start_indices で上書きされたもの)を結果として生成します。update の形状によって、更新される結果のサブ配列の形状が決まります。start_indices の形状は 1 次元で、ディメンション サイズは operand のディメンション数と等しくなければなりません。
DynamicUpdateSlice(operand, update, start_indices)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
型 T の N 次元配列 |
update
|
XlaOp
|
スライス更新を含む型 T の N 次元配列。更新シェイプの各ディメンションは 0 より大きく、start + update は各ディメンションのオペランド サイズ以下である必要があります。これにより、範囲外の更新インデックスの生成を回避できます。 |
start_indices
|
N 個の XlaOp のシーケンス |
各ディメンションのスライスの開始インデックスを含む N 個のスカラー整数のリスト。値は 0 以上である必要があります。 |
有効なスライス インデックスは、スライスを実行する前に [1, N) の各インデックス i に次の変換を適用して計算されます。
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - update.dimension_size[i])
これにより、更新されたスライスは常にオペランド配列の範囲内になります。変換が適用される前にスライスが境界内にある場合、変換は効果がありません。
1 次元の例:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let u = {5.0, 6.0}
let s = {2}
DynamicUpdateSlice(a, u, s)
// Result: {0.0, 1.0, 5.0, 6.0, 4.0}
2 次元の例:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let u =
{ {12.0, 13.0},
{14.0, 15.0},
{16.0, 17.0} }
let s = {1, 1}
DynamicUpdateSlice(b, u, s)
// Result:
// { {0.0, 1.0, 2.0},
// {3.0, 12.0, 13.0},
// {6.0, 14.0, 15.0},
// {9.0, 16.0, 17.0} }
StableHLO の詳細については、StableHLO - dynamic_update_slice をご覧ください。
Erf
XlaBuilder::Erf もご覧ください。
要素ごとの誤差関数 x -> erf(x)。ここで、
\(\text{erf}(x) = \frac{2}{\sqrt{\pi} }\int_0^x e^{-t^2} \, dt\)。
Erf(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Erf は、省略可能な result_accuracy 引数もサポートしています。
Erf(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
Exp
XlaBuilder::Exp もご覧ください。
要素ごとの自然指数 x -> e^x。
Exp(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Exp は、オプションの result_accuracy 引数もサポートしています。
Exp(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
StableHLO の詳細については、StableHLO - 指数関数をご覧ください。
Expm1
XlaBuilder::Expm1 もご覧ください。
要素ごとの自然指数関数から 1 を引いた値 x -> e^x - 1。
Expm1(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Expm1 は、省略可能な result_accuracy 引数もサポートしています。
Expm1(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
StableHLO の詳細については、StableHLO - exponential_minus_one をご覧ください。
Fft
XlaBuilder::Fft もご覧ください。
XLA FFT 演算は、実数と複素数の入力/出力に対して順方向および逆方向のフーリエ変換を実装します。最大 3 軸の多次元 FFT がサポートされています。
Fft(operand, ftt_type, fft_length)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand
|
XlaOp
|
フーリエ変換する配列。 |
fft_type |
FftType |
下の表をご覧ください。 |
fft_length
|
ArraySlice<int64>
|
変換される軸の時間領域の長さ。RFFT(fft_length=[16]) は RFFT(fft_length=[17]) と同じ出力形状を持つため、IRFFT で最も内側の軸のサイズを適切に設定するために特に必要です。 |
FftType |
セマンティクス |
|---|---|
FFT |
複素数から複素数への順方向 FFT。形状は変更されません。 |
IFFT |
複素数から複素数への逆 FFT。形状は変更されません。 |
RFFT
|
実数から複素数への順方向 FFT。fft_length[-1] がゼロ以外の値の場合、最も内側の軸の形状は fft_length[-1] // 2 + 1 に縮小され、ナイキスト周波数を超える変換された信号の逆共役部分が省略されます。 |
IRFFT
|
実数から複素数への逆 FFT(複素数を取得して実数を返します)。fft_length[-1] がゼロ以外の値の場合、最も内側の軸の形状は fft_length[-1] に拡張され、1 から fft_length[-1] // 2 + 1 エントリの逆共役からナイキスト周波数を超える変換された信号の部分が推論されます。 |
StableHLO の詳細については、StableHLO - fft をご覧ください。
多次元 FFT
複数の fft_length が指定されている場合、これは、最も内側の各軸に FFT オペレーションのカスケードを適用することと同じです。実数から複素数への変換と複素数から実数への変換の場合、最も内側の軸の変換が(実質的に)最初に行われます(RFFT、IRFFT の場合は最後)。そのため、最も内側の軸のサイズが変更されます。他の軸変換は、複素数 -> 複素数になります。
実装の詳細
CPU FFT は Eigen の TensorFFT によってサポートされています。GPU FFT は cuFFT を使用します。
階
XlaBuilder::Floor もご覧ください。
要素ごとの床関数 x -> ⌊x⌋。
Floor(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
StableHLO の情報については、StableHLO - floor をご覧ください。
Fusion
HloInstruction::CreateFusion もご覧ください。
Fusion オペレーションは HLO 命令を表し、HLO のプリミティブとして機能します。このオペレーションは HLO ダンプに表示されることがありますが、エンドユーザーが手動で構築することを想定していません。
収集
XLA 収集演算は、入力配列の複数のスライス(各スライスは実行時のオフセットが異なる可能性があります)を結合します。
StableHLO の情報については、StableHLO - gather をご覧ください。
一般的なセマンティクス
XlaBuilder::Gatherもご覧ください。より直感的な説明については、以下の「非公式な説明」セクションをご覧ください。
gather(operand, start_indices, dimension_numbers, slice_sizes,
indices_are_sorted)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand
|
XlaOp
|
収集元の配列。 |
start_indices
|
XlaOp
|
収集するスライスの開始インデックスを含む配列。 |
dimension_numbers
|
GatherDimensionNumbers
|
開始インデックスを「含む」start_indices のディメンション。詳細については、以下をご覧ください。 |
slice_sizes
|
ArraySlice<int64>
|
slice_sizes[i] は、ディメンション i のスライスの境界です。 |
indices_are_sorted
|
bool
|
インデックスが呼び出し元によってソートされることが保証されているかどうか。 |
便宜上、offset_dims に含まれない出力配列のディメンションには batch_dims というラベルを付けます。
出力は batch_dims.size + offset_dims.size 個の次元を持つ配列です。
operand.rank は offset_dims.size と collapsed_slice_dims.size の合計と等しくなければなりません。また、slice_sizes.size は operand.rank と等しくなければなりません。
index_vector_dim が start_indices.rank と等しい場合、start_indices に末尾の 1 ディメンションがあると暗黙的に見なされます(つまり、start_indices の形状が [6,7] で、index_vector_dim が 2 の場合、start_indices の形状は [6,7,1] であると暗黙的に見なされます)。
ディメンション i に沿った出力配列の境界は、次のように計算されます。
iがbatch_dimsに存在する場合(つまり、あるkに対してbatch_dims[k]と等しい場合)、start_indices.shapeから対応するディメンションの境界を選択し、index_vector_dimをスキップします(つまり、k<index_vector_dimの場合はstart_indices.shape.dims[k] を選択し、それ以外の場合はstart_indices.shape.dims[k+1] を選択します)。iがoffset_dimsに存在する場合(つまり、あるkに対してoffset_dims[k] と等しい場合)、collapsed_slice_dimsを考慮した後で、slice_sizesから対応する境界を選択します(つまり、adjusted_slice_sizes[k] を選択します。ここで、adjusted_slice_sizesは、インデックスcollapsed_slice_dimsの境界が削除されたslice_sizesです)。
形式的には、特定の出力インデックス Out に対応するオペランド インデックス In は次のように計算されます。
G= {Out[k] forkinbatch_dims} とします。Gを使用して、S[i] =start_indices[Combine(G,i)] となるベクトルSを切り出します。ここで、Combine(A, b) は、位置index_vector_dimに b を A に挿入します。Gが空の場合でも、これは適切に定義されます。Gが空の場合、S=start_indicesとなります。start_index_mapを使用してSを分散し、Sを使用してoperandに開始インデックスSinを作成します。具体的には、次のようになります。Sin[start_index_map[k]] =S[k](k<start_index_map.sizeの場合)。それ以外の場合は、
Sin[_] =0。
collapsed_slice_dimsセットに従って、Outのオフセット ディメンションでインデックスを分散させることで、operandにインデックスOinを作成します。より正確には、次のようになります。Oin[remapped_offset_dims(k)] =Out[offset_dims[k]](k<offset_dims.sizeの場合)。 (remapped_offset_dimsは下記で定義されています)。それ以外の場合は、
Oin[_] =0。
InはOin+Sinです。ここで、+ は要素ごとの加算です。
remapped_offset_dims は、ドメイン [0, offset_dims.size) と範囲 [0, operand.rank) \ collapsed_slice_dims を持つ単調関数です。たとえば、offset_dims.size が 4、operand.rank が 6、collapsed_slice_dims が {0, 2} の場合、remapped_offset_dims は {0→1, 1→3, 2→4, 3→5} になります。
indices_are_sorted が true に設定されている場合、XLA は start_indices がユーザーによって(昇順で、start_index_map に従って値を分散した後に)並べ替えられていると想定できます。並べ替えられていない場合、セマンティクスは実装で定義されます。
非公式な説明と例
非公式には、出力配列のすべてのインデックス Out は、次のように計算されるオペランド配列の要素 E に対応します。
Outのバッチ ディメンションを使用して、start_indicesから開始インデックスをルックアップします。start_index_mapを使用して、開始インデックス(サイズが operand.rank より小さい場合がある)をoperandの「完全な」開始インデックスにマッピングします。完全な開始インデックスを使用して、サイズ
slice_sizesのスライスを動的にスライスします。collapsed_slice_dimsディメンションを折りたたんでスライスを再形成します。折りたたまれたスライス ディメンションはすべて境界が 1 でなければならないため、この再形成は常に有効です。Outのオフセット ディメンションを使用してこのスライスにインデックスを付け、出力インデックスOutに対応する入力要素Eを取得します。
以降のすべての例では、index_vector_dim は start_indices.rank - 1 に設定されています。index_vector_dim の値をより興味深いものにしても、オペレーションの根本的な変更はありませんが、視覚的な表現が煩雑になります。
上記のすべての要素がどのように連携しているかを理解するために、[16,11] 配列から形状 [8,6] の 5 つのスライスを収集する例を見てみましょう。[16,11] 配列内のスライスの位置は、形状 S64[2] のインデックス ベクトルとして表すことができます。したがって、5 つの位置のセットは S64[5,2] 配列として表すことができます。
収集オペレーションの動作は、[G,O0,O1] を受け取り、出力シェイプのインデックスを次のように入力配列の要素にマッピングするインデックス変換として表すことができます。

まず、G を使用して、収集インデックス配列から(X、Y)ベクトルを選択します。次に、インデックス [G、O0、O1] の出力配列の要素は、インデックス [X+O0、Y+O1] の入力配列の要素になります。
slice_sizes は [8,6] であり、O0 と O1 の範囲を決定します。これにより、スライスの境界が決定されます。
この収集オペレーションは、バッチ ディメンションとして G を使用するバッチ動的スライスとして機能します。
収集インデックスは多次元にできます。たとえば、上記の例のより一般的なバージョンで、形状 [4,5,2] の「収集インデックス」配列を使用すると、インデックスは次のように変換されます。

これも、バッチ ディメンションとしてバッチ動的スライス G0 と G1 として機能します。スライスサイズは [8,6] のままです。
XLA の gather オペレーションは、上記で説明した非公式のセマンティクスを次のように一般化します。
出力シェイプのどのディメンションがオフセット ディメンション(最後の例の
O0、O1を含むディメンション)であるかを構成できます。出力バッチ ディメンション(最後の例のG0、G1を含むディメンション)は、オフセット ディメンションではない出力ディメンションとして定義されます。出力シェイプに明示的に存在する出力オフセット ディメンションの数は、入力ディメンションの数よりも少なくなることがあります。
collapsed_slice_dimsとして明示的にリストされているこれらの「欠落」ディメンションは、スライスサイズが1である必要があります。スライスサイズが1であるため、有効なインデックスは0のみであり、省略しても曖昧さは生じません。「Gather Indices」配列から抽出されたスライス(最後の例では(
X、Y))の要素数は、入力配列のディメンション数よりも少ない場合があります。明示的なマッピングにより、入力と同じディメンション数になるようにインデックスを拡張する方法が指定されます。
最後の例として、(2) と (3) を使用して tf.gather_nd を実装します。

G0 と G1 は、通常どおり、収集インデックス配列から開始インデックスを切り出すために使用されます。ただし、開始インデックスには 1 つの要素 X のみがあります。同様に、値 O0 を持つ出力オフセット インデックスは 1 つだけです。ただし、これらは入力配列のインデックスとして使用される前に、「Gather Index Mapping」(正式な説明では start_index_map)と「Offset Mapping」(正式な説明では remapped_offset_dims)に従ってそれぞれ [X,0] と [0,O0] に拡張され、[X,O0] に加算されます。つまり、出力インデックス [G0,G1,O0] は入力インデックス [GatherIndices[G0,G1,0],O0] にマッピングされ、tf.gather_nd のセマンティクスが得られます。
この場合の slice_sizes は [1,11] です。直感的に言うと、gather インデックス配列のすべてのインデックス X が行全体を選択し、結果はこれらのすべての行の連結になります。
GetDimensionSize
XlaBuilder::GetDimensionSize もご覧ください。
オペランドの指定されたディメンションのサイズを返します。オペランドは配列の形状にする必要があります。
GetDimensionSize(operand, dimension)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
n 次元入力配列 |
dimension
|
int64
|
ディメンションを指定する間隔 [0, n) の値 |
StableHLO の情報については、StableHLO - get_dimension_size をご覧ください。
GetTupleElement
XlaBuilder::GetTupleElement もご覧ください。
コンパイル時定数値を持つタプルへのインデックス。
値はコンパイル時定数である必要があります。これにより、形状推論で結果の値の型を特定できます。
これは C++ の std::get<int N>(t) に類似しています。概念的には次のようになります。
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
let element_1: s32 = gettupleelement(t, 1); // Inferred shape matches s32.
tf.tuple もご覧ください。
GetTupleElement(tuple_data, index)
| 引数 | タイプ | セマンティクス |
|---|---|---|
tuple_data |
XlaOP |
タプル |
index |
int64 |
タプル形状のインデックス |
StableHLO の詳細については、StableHLO - get_tuple_element をご覧ください。
Imag
XlaBuilder::Imag もご覧ください。
複素数(または実数)シェイプの要素ごとの虚数部。x -> imag(x)。オペランドが浮動小数点型の場合は 0 を返します。
Imag(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
StableHLO の詳細については、StableHLO - imag をご覧ください。
インフィード
XlaBuilder::Infeed もご覧ください。
Infeed(shape, config)
| 引数 | タイプ | セマンティクス |
|---|---|---|
shape
|
Shape
|
インフィード インターフェースから読み取られたデータの形状。形状のレイアウト フィールドは、デバイスに送信されるデータのレイアウトと一致するように設定する必要があります。そうしない場合、動作は未定義になります。 |
config |
省略可 string |
op の構成。 |
デバイスの暗黙的なインフィード ストリーミング インターフェースから単一のデータアイテムを読み取り、指定された形状とそのレイアウトとしてデータを解釈し、データの XlaOp を返します。計算では複数の Infeed オペレーションが許可されますが、Infeed オペレーション間には全順序が必要です。たとえば、次のコードの 2 つの Infeed には、while ループ間に依存関係があるため、全順序があります。
result1 = while (condition, init = init_value) {
Infeed(shape)
}
result2 = while (condition, init = result1) {
Infeed(shape)
}
ネストされたタプル形状はサポートされていません。空のタプル形状の場合、Infeed オペレーションは事実上 no-op であり、デバイスの Infeed からデータを読み取らずに続行します。
StableHLO の詳細については、StableHLO - インフィードをご覧ください。
Iota
XlaBuilder::Iota もご覧ください。
Iota(shape, iota_dimension)
潜在的に大きなホスト転送ではなく、デバイス上に定数リテラルを構築します。指定された形状を持ち、指定されたディメンションに沿って 0 から 1 ずつ増加する値を持つ配列を作成します。浮動小数点型の場合、生成される配列は ConvertElementType(Iota(...)) と同等です。ここで、Iota は整数型で、変換は浮動小数点型です。
| 引数 | タイプ | セマンティクス |
|---|---|---|
shape |
Shape |
Iota() によって作成された配列の形状 |
iota_dimension |
int64 |
増分するディメンション。 |
たとえば、Iota(s32[4, 8], 0) は
[[0, 0, 0, 0, 0, 0, 0, 0 ],
[1, 1, 1, 1, 1, 1, 1, 1 ],
[2, 2, 2, 2, 2, 2, 2, 2 ],
[3, 3, 3, 3, 3, 3, 3, 3 ]]
返品可能(返品手数料: Iota(s32[4, 8], 1))
[[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ]]
StableHLO の情報については、StableHLO - iota をご覧ください。
IsFinite
XlaBuilder::IsFinite もご覧ください。
operand の各要素が有限であるかどうか(正または負の無限大ではなく、NaN でもないかどうか)をテストします。入力と同じ形状の PRED 値の配列を返します。各要素は、対応する入力要素が有限である場合にのみ true になります。
IsFinite(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
StableHLO の情報については、StableHLO - is_finite をご覧ください。
ログ
XlaBuilder::Log もご覧ください。
要素ごとの自然対数 x -> ln(x)。
Log(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Log は、オプションの result_accuracy 引数もサポートしています。
Log(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
StableHLO の情報については、StableHLO - log をご覧ください。
Log1p
XlaBuilder::Log1p もご覧ください。
要素ごとのシフトされた自然対数 x -> ln(1+x)。
Log1p(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Log1p は、オプションの result_accuracy 引数もサポートしています。
Log1p(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
StableHLO の詳細については、StableHLO - log_plus_one をご覧ください。
ロジスティック
XlaBuilder::Logistic もご覧ください。
要素ごとのロジスティック関数計算 x -> logistic(x)。
Logistic(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Logistic は、オプションの result_accuracy 引数もサポートしています。
Logistic(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
StableHLO の詳細については、StableHLO - ロジスティックをご覧ください。
地図
XlaBuilder::Map もご覧ください。
Map(operands..., computation, dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operands |
N 個の XlaOp のシーケンス |
型 T0..T{N-1} の N 個の配列 |
computation
|
XlaComputation
|
型 T の N 個のパラメータと任意の型の M 個のパラメータを持つ型 T_0, T_1,
.., T_{N + M -1} -> S の計算。 |
dimensions |
int64 配列 |
地図のディメンションの配列 |
static_operands
|
N 個の XlaOp のシーケンス |
マップ オペレーションの静的オペレーション |
指定された operands 配列にスカラー関数を適用し、同じディメンションの配列を生成します。この配列の各要素は、入力配列の対応する要素に適用されたマッピング関数の結果です。
マッピングされた関数は任意の計算ですが、スカラー型 T の N 個の入力と、型 S の単一の出力があるという制限があります。出力のディメンションはオペランドと同じですが、要素型 T は S に置き換えられます。
たとえば、Map(op1, op2, op3, computation, par1) は、入力配列の各(多次元)インデックスで elem_out <-
computation(elem1, elem2, elem3, par1) をマッピングして、出力配列を生成します。
StableHLO の詳細については、StableHLO - map をご覧ください。
最大
XlaBuilder::Max もご覧ください。
テンソル lhs と rhs に対して要素ごとの最大演算を行います。
Max(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Max には、異なる次元のブロードキャストをサポートする別のバリアントがあります。
Max(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の情報については、StableHLO - 最大をご覧ください。
最小
XlaBuilder::Min もご覧ください。
lhs と rhs に対して要素ごとの最小値演算を実行します。
Min(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Min には、異なる次元のブロードキャストをサポートする代替バリアントがあります。
Min(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の情報については、StableHLO - 最小をご覧ください。
Mul
XlaBuilder::Mul もご覧ください。
lhs と rhs の要素ごとの積を計算します。
Mul(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Mul には、異なる次元のブロードキャストをサポートする別のバリアントがあります。
Mul(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の情報については、StableHLO - multiply をご覧ください。
Neg
XlaBuilder::Neg もご覧ください。
要素ごとの否定 x -> -x。
Neg(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
StableHLO の情報については、StableHLO - negate をご覧ください。
×
XlaBuilder::Not もご覧ください。
要素ごとの論理否定 x -> !(x)。
Not(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
StableHLO の情報については、StableHLO - not をご覧ください。
OptimizationBarrier
XlaBuilder::OptimizationBarrier もご覧ください。
最適化パスがバリアを越えて計算を移動することをブロックします。
OptimizationBarrier(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
バリアの出力に依存するオペレーターの前に、すべての入力が評価されるようにします。
StableHLO の情報については、StableHLO - optimization_barrier をご覧ください。
または
XlaBuilder::Or もご覧ください。
lhs と rhs の要素ごとの OR を実行します。
Or(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Or には、異なる次元のブロードキャストをサポートする代替バリアントがあります。
Or(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の詳細については、StableHLO - or をご覧ください。
アウトフィード
XlaBuilder::Outfeed もご覧ください。
入力をアウトフィードに書き込みます。
Outfeed(operand, shape_with_layout, outfeed_config)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
T 型の配列 |
shape_with_layout |
Shape |
転送されるデータのレイアウトを定義します。 |
outfeed_config |
string |
Outfeed 命令の構成の定数 |
shape_with_layout は、アウトフィードするレイアウトされたシェイプを伝えます。
StableHLO の情報については、StableHLO - アウトフィードをご覧ください。
パッド
XlaBuilder::Pad もご覧ください。
Pad(operand, padding_value, padding_config)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
T 型の配列 |
padding_value
|
XlaOp
|
追加されたパディングを埋める T 型のスカラー |
padding_config
|
PaddingConfig
|
両端のパディング量(低、高)と各ディメンションの要素間のパディング量 |
指定された padding_value を使用して、配列の周囲と配列の要素間のパディングを行うことで、指定された operand 配列を拡張します。padding_config は、各ディメンションのエッジ パディングと内部パディングの量を指定します。
PaddingConfig は PaddingConfigDimension の繰り返しフィールドで、各ディメンションの 3 つのフィールド(edge_padding_low、edge_padding_high、interior_padding)が含まれています。
edge_padding_low と edge_padding_high は、各ディメンションのローエンド(インデックス 0 の隣)とハイエンド(最大のインデックスの隣)に追加されるパディングの量をそれぞれ指定します。エッジ パディングの量は負の値にできます。負のパディングの絶対値は、指定されたディメンションから削除する要素の数を示します。
interior_padding は、各ディメンションの 2 つの要素間に追加されるパディングの量を指定します。負の値は指定できません。内部パディングはエッジ パディングの前に論理的に発生するため、エッジ パディングが負の場合、要素は内部パディングされたオペランドから削除されます。
エッジ パディングのペアがすべて(0, 0)で、内部パディングの値がすべて 0 の場合、このオペレーションは no-op です。次の図は、2 次元配列のさまざまな edge_padding 値と interior_padding 値の例を示しています。
StableHLO の詳細については、StableHLO - pad をご覧ください。
パラメータ
XlaBuilder::Parameter もご覧ください。
Parameter は、計算への引数入力を表します。
PartitionID
XlaBuilder::BuildPartitionId もご覧ください。
現在のプロセスの partition_id を生成します。
PartitionID(shape)
| 引数 | タイプ | セマンティクス |
|---|---|---|
shape |
Shape |
データの形状 |
PartitionID は HLO ダンプに表示されることがありますが、エンドユーザーが手動で構築することを意図したものではありません。
StableHLO の情報については、StableHLO - partition_id をご覧ください。
PopulationCount
XlaBuilder::PopulationCount もご覧ください。
operand の各要素に設定されているビット数を計算します。
PopulationCount(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
StableHLO の詳細については、StableHLO - popcnt をご覧ください。
Pow
XlaBuilder::Pow もご覧ください。
lhs の要素と rhs の要素の累乗を計算します。
Pow(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Pow には、異なる次元のブロードキャストをサポートする別のバリアントがあります。
Pow(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の詳細については、StableHLO - power をご覧ください。
実際
XlaBuilder::Real もご覧ください。
複素数(または実数)シェイプの要素ごとの実部。x -> real(x)。オペランドが浮動小数点型の場合、Real は同じ値を返します。
Real(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
StableHLO の情報については、StableHLO - real をご覧ください。
Recv
XlaBuilder::Recv もご覧ください。
Recv、RecvWithTokens、RecvToHost は、HLO で通信プリミティブとして機能するオペレーションです。これらのオペレーションは通常、低レベルの入出力またはデバイス間の転送の一部として HLO ダンプに表示されますが、エンドユーザーが手動で構築することを想定していません。
Recv(shape, handle)
| 引数 | タイプ | セマンティクス |
|---|---|---|
shape |
Shape |
受信するデータの形状 |
handle |
ChannelHandle |
各送受信ペアの一意の識別子 |
同じチャネル ハンドルを共有する別の計算の Send 命令から、指定された形状のデータを受け取ります。受信したデータの XlaOp を返します。
StableHLO の詳細については、StableHLO - recv をご覧ください。
RecvDone
HloInstruction::CreateRecv と HloInstruction::CreateRecvDone もご覧ください。
Send と同様に、Recv オペレーションのクライアント API は同期通信を表します。ただし、非同期データ転送を可能にするために、命令は内部的に 2 つの HLO 命令(Recv と RecvDone)に分解されます。
Recv(const Shape& shape, int64 channel_id)
同じ channel_id の Send 命令からデータを受信するために必要なリソースを割り当てます。割り当てられたリソースのコンテキストを返します。このコンテキストは、後続の RecvDone 命令でデータ転送の完了を待つために使用されます。コンテキストは {受信バッファ(形状)、リクエスト ID(U32)} のタプルであり、RecvDone 命令でのみ使用できます。
Recv 命令で作成されたコンテキストを指定して、データ転送が完了するまで待機し、受信したデータを返します。
リデュース
XlaBuilder::Reduce もご覧ください。
1 つ以上の配列にリダクション関数を並行して適用します。
Reduce(operands..., init_values..., computation, dimensions_to_reduce)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operands
|
N 個の XlaOp のシーケンス |
型 T_0,...,
T_{N-1} の N 個の配列。 |
init_values
|
N 個の XlaOp のシーケンス |
T_0,..., T_{N-1} 型の N 個のスカラー。 |
computation
|
XlaComputation
|
型 T_0,..., T_{N-1}, T_0,
...,T_{N-1} -> の計算
Collate(T_0,...,
T_{N-1})。 |
dimensions_to_reduce
|
int64 配列 |
削減するディメンションの順序なし配列。 |
ここで
- N は 1 以上である必要があります。
- 計算は「ほぼ」結合的である必要があります(下記を参照)。
- 入力配列はすべて同じディメンションである必要があります。
- すべての初期値は、
computationの下で ID を形成する必要があります。 N = 1の場合、Collate(T)はTです。N > 1、Collate(T_0, ..., T_{N-1})がT型のN要素のタプルの場合。
このオペレーションは、各入力配列の 1 つ以上のディメンションをスカラーに縮小します。返される各配列のディメンション数は number_of_dimensions(operand) - len(dimensions) です。オペレーションの出力は Collate(Q_0, ..., Q_N) です。ここで、Q_i は T_i 型の配列です。そのディメンションについては、以下で説明します。
異なるバックエンドで削減計算を再関連付けることができます。加算などの一部の削減関数は浮動小数点数に対して結合的ではないため、数値の差異が生じる可能性があります。ただし、データの範囲が制限されている場合、浮動小数点数の加算はほとんどの実用的な用途で結合的であると見なせるほど十分に近くなります。
StableHLO の詳細については、StableHLO - reduce をご覧ください。
例
値 [10, 11,
12, 13] を含む 1 つの 1 次元配列で 1 つのディメンションを削減する場合、削減関数 f(これは computation)を使用すると、次のように計算できます。
f(10, f(11, f(12, f(init_value, 13)))
他にも多くの可能性があります。
f(init_value, f(f(10, f(init_value, 11)), f(f(init_value, 12), f(init_value, 13))))
次に、削減を実装する方法の疑似コードの例を示します。この例では、削減計算として合計を使用し、初期値を 0 に設定しています。
result_shape <- remove all dims in dimensions from operand_shape
# Iterate over all elements in result_shape. The number of r's here is equal
# to the number of dimensions of the result.
for r0 in range(result_shape[0]), r1 in range(result_shape[1]), ...:
# Initialize this result element
result[r0, r1...] <- 0
# Iterate over all the reduction dimensions
for d0 in range(dimensions[0]), d1 in range(dimensions[1]), ...:
# Increment the result element with the value of the operand's element.
# The index of the operand's element is constructed from all ri's and di's
# in the right order (by construction ri's and di's together index over the
# whole operand shape).
result[r0, r1...] += operand[ri... di]
2D 配列(行列)を削減する例を次に示します。形状には 2 つのディメンションがあり、サイズ 2 のディメンション 0 とサイズ 3 のディメンション 1 があります。
「add」関数を使用してディメンション 0 または 1 を削減した結果:
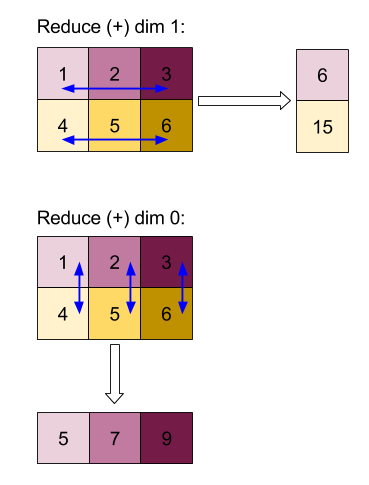
どちらの削減結果も 1 次元配列であることに注意してください。図では、視覚的な便宜のために、一方を列、もう一方を行として示しています。
より複雑な例として、3D 配列を示します。ディメンションの数は 3 で、ディメンション 0 のサイズは 4、ディメンション 1 のサイズは 2、ディメンション 2 のサイズは 3 です。簡略化のため、値 1 ~ 6 はディメンション 0 全体に複製されています。
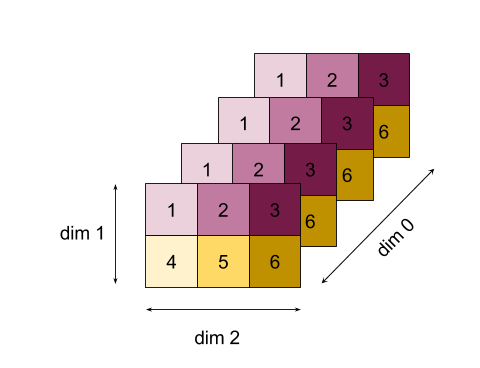
2D の例と同様に、1 つのディメンションのみを削減できます。たとえば、ディメンション 0 を削減すると、ディメンション 0 のすべての値がスカラーに折りたたまれた 2 次元配列が生成されます。
| 4 8 12 |
| 16 20 24 |
ディメンション 2 を削減すると、ディメンション 2 のすべての値がスカラーに折りたたまれた 2 次元配列も取得されます。
| 6 15 |
| 6 15 |
| 6 15 |
| 6 15 |
入力内の残りのディメンション間の相対順序は出力で保持されますが、一部のディメンションには新しい番号が割り当てられることがあります(ディメンションの数が変わるため)。
複数の次元を削減することもできます。ディメンション 0 と 1 を削減すると、1D 配列 [20, 28, 36] が生成されます。
3D 配列のすべての次元を縮小すると、スカラー 84 が生成されます。
Variadic Reduce
N > 1 の場合、関数適用はすべての入力に同時に適用されるため、やや複雑になります。オペランドは次の順序で計算に渡されます。
- 最初のオペランドの実行中の削減値
- ...
- N 番目のオペランドの値を減らして実行する
- 最初のオペランドの入力値
- ...
- N 番目のオペランドの入力値
たとえば、次の削減関数は、1 次元配列の最大値と argmax を並列で計算するために使用できます。
f: (Float, Int, Float, Int) -> Float, Int
f(max, argmax, value, index):
if value >= max:
return (value, index)
else:
return (max, argmax)
1 次元入力配列 V = Float[N], K = Int[N] と初期値 I_V = Float, I_K = Int の場合、唯一の入力ディメンションで縮小した結果 f_(N-1) は、次の再帰的アプリケーションと同等です。
f_0 = f(I_V, I_K, V_0, K_0)
f_1 = f(f_0.first, f_0.second, V_1, K_1)
...
f_(N-1) = f(f_(N-2).first, f_(N-2).second, V_(N-1), K_(N-1))
この削減を値の配列と連続したインデックスの配列(iota)に適用すると、配列が同時に反復処理され、最大値と一致するインデックスを含むタプルが返されます。
ReducePrecision
XlaBuilder::ReducePrecision もご覧ください。
浮動小数点値を低精度形式(IEEE-FP16 など)に変換し、元の形式に戻す効果をモデル化します。低精度形式の指数部と仮数部のビット数は任意に指定できますが、すべてのビットサイズがすべてのハードウェア実装でサポートされるとは限りません。
ReducePrecision(operand, exponent_bits, mantissa_bits)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
浮動小数点型 T の配列。 |
exponent_bits |
int32 |
低精度形式の指数ビット数 |
mantissa_bits |
int32 |
低精度形式の仮数部のビット数 |
結果は T 型の配列です。入力値は、指定された仮数部のビット数で表現可能な最も近い値に丸められ(「偶数への丸め」セマンティクスを使用)、指数部のビット数で指定された範囲を超える値は正または負の無限大にクランプされます。NaN 値は保持されますが、正規の NaN 値に変換されることがあります。
低精度形式には、少なくとも 1 つの指数ビットが必要です(両方とも仮数がゼロであるため、ゼロ値と無限大を区別するため)。また、仮数ビットの数は非負である必要があります。指数ビットまたは仮数ビットの数は、型 T の対応する値を超える場合があります。その場合、変換の対応する部分は単に no-op になります。
StableHLO については、StableHLO - reduce_precision をご覧ください。
ReduceScatter
XlaBuilder::ReduceScatter もご覧ください。
ReduceScatter は、AllReduce を効果的に実行し、結果を scatter_dimension に沿って shard_count ブロックに分割して分散する集団演算です。レプリカ グループのレプリカ i は ith シャードを受け取ります。
ReduceScatter(operand, computation, scatter_dimension, shard_count,
replica_groups, channel_id, layout, use_global_device_ids)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand
|
XlaOp
|
レプリカ間で削減する配列または配列の空でないタプル。 |
computation |
XlaComputation |
削減の計算 |
scatter_dimension |
int64 |
散布するディメンション。 |
shard_count
|
int64
|
scatter_dimension を分割するブロック数 |
replica_groups
|
ReplicaGroup ベクトル |
削減が実行されるグループ |
channel_id
|
省略可
ChannelHandle |
クロスモジュール通信用のオプションのチャンネル ID |
layout
|
省略可 Layout
|
ユーザー指定のメモリ レイアウト |
use_global_device_ids |
省略可 bool |
ユーザー指定のフラグ |
operandが配列のタプルの場合、タプルの各要素に対して reduce-scatter が実行されます。replica_groupsは、縮小が実行されるレプリカ グループのリストです(現在のレプリカのレプリカ ID はReplicaIdを使用して取得できます)。各グループ内のレプリカの順序によって、all-reduce 結果が分散される順序が決まります。replica_groupsは、空(すべてのレプリカが単一のグループに属している場合)であるか、レプリカの数と同じ数の要素を含む必要があります。レプリカ グループが複数ある場合は、すべて同じサイズにする必要があります。たとえば、replica_groups = {0, 2}, {1, 3}はレプリカ0と2、1と3の間で削減を実行し、結果を分散します。shard_countは各レプリカ グループのサイズです。これは、replica_groupsが空の場合に必要です。replica_groupsが空でない場合、shard_countは各レプリカ グループのサイズと等しくなければなりません。channel_idはモジュール間の通信に使用されます。同じchannel_idを持つreduce-scatterオペレーションのみが相互に通信できます。layoutレイアウトについて詳しくは、xla::shapes をご覧ください。use_global_device_idsはユーザー指定のフラグです。false(デフォルト)の場合、replica_groupsの数値はReplicaIdです。trueの場合、replica_groupsは(ReplicaID*partition_count+partition_id)のグローバル ID を表します。例:- 2 つのレプリカと 4 つのパーティションがある場合、
- replica_groups={ {0,1,4,5},{2,3,6,7} } and use_global_device_ids=true
- group[0] = (0,0), (0,1), (1,0), (1,1)
- group[1] = (0,2), (0,3), (1,2), (1,3)
- 各ペアは(replica_id、partition_id)です。
出力形状は、scatter_dimension が shard_count 倍小さくなった入力形状です。たとえば、2 つのレプリカがあり、オペランドの値が 2 つのレプリカでそれぞれ [1.0, 2.25] と [3.0, 5.25] の場合、scatter_dim が 0 のこの op からの出力値は、最初のレプリカでは [4.0]、2 番目のレプリカでは [7.5] になります。
StableHLO の詳細については、StableHLO - reduce_scatter をご覧ください。
ReduceScatter - 例 1 - StableHLO

上記の例では、ReduceScatter に 2 つのレプリカが参加しています。各レプリカのオペランドの形状は f32[2,4] です。レプリカ間で全削減(合計)が実行され、各レプリカで形状 f32[2,4] の削減値が生成されます。この削減値は、ディメンション 1 に沿って 2 つの部分に分割されるため、各部分の形状は f32[2,2] になります。プロセス グループ内の各レプリカは、グループ内の位置に対応する部分を受け取ります。その結果、各レプリカの出力の形状は f32[2,2] になります。
ReduceWindow
XlaBuilder::ReduceWindow もご覧ください。
N 個の多次元配列のシーケンスの各ウィンドウ内のすべての要素に削減関数を適用し、出力として 1 つまたは N 個の多次元配列のタプルを生成します。各出力配列には、ウィンドウの有効な位置の数と同じ数の要素があります。プーリング レイヤは ReduceWindow として表現できます。Reduce と同様に、適用される computation には常に左側の init_values が渡されます。
ReduceWindow(operands..., init_values..., computation, window_dimensions,
window_strides, padding)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operands
|
N XlaOps
|
型 T_0,..., T_{N-1} の N 個の多次元配列のシーケンス。それぞれがウィンドウが配置されるベース領域を表します。 |
init_values
|
N XlaOps
|
削減の N 個の開始値。N 個のオペランドごとに 1 つずつ。詳細については、削減をご覧ください。 |
computation
|
XlaComputation
|
すべての入力オペランドの各ウィンドウの要素に適用する、型 T_0,
..., T_{N-1}, T_0, ..., T_{N-1}
-> Collate(T_0, ..., T_{N-1}) の削減関数。 |
window_dimensions
|
ArraySlice<int64>
|
ウィンドウ ディメンション値の整数の配列 |
window_strides
|
ArraySlice<int64>
|
ウィンドウ ストライド値の整数の配列 |
base_dilations
|
ArraySlice<int64>
|
ベースの拡張値の整数の配列 |
window_dilations
|
ArraySlice<int64>
|
ウィンドウの拡張値の整数の配列 |
padding
|
Padding
|
ウィンドウのパディング タイプ(Padding::kSame。ストライドが 1 の場合、入力と同じ出力形状になるようにパディングします。Padding::kValid。パディングを使用せず、ウィンドウが収まらなくなると「停止」します)。 |
ここで
- N は 1 以上である必要があります。
- 入力配列はすべて同じディメンションである必要があります。
N = 1の場合、Collate(T)はTです。N > 1、Collate(T_0, ..., T_{N-1})が(T0,...T{N-1})型のN要素のタプルの場合。
StableHLO の情報については、StableHLO - reduce_window をご覧ください。
ReduceWindow - 例 1
入力は [4x6] のサイズの行列で、window_dimensions と window_stride_dimensions の両方が [2x3] です。
// Create a computation for the reduction (maximum).
XlaComputation max;
{
XlaBuilder builder(client_, "max");
auto y = builder.Parameter(0, ShapeUtil::MakeShape(F32, {}), "y");
auto x = builder.Parameter(1, ShapeUtil::MakeShape(F32, {}), "x");
builder.Max(y, x);
max = builder.Build().value();
}
// Create a ReduceWindow computation with the max reduction computation.
XlaBuilder builder(client_, "reduce_window_2x3");
auto shape = ShapeUtil::MakeShape(F32, {4, 6});
auto input = builder.Parameter(0, shape, "input");
builder.ReduceWindow(
input,
/*init_val=*/builder.ConstantLiteral(LiteralUtil::MinValue(F32)),
*max,
/*window_dimensions=*/{2, 3},
/*window_stride_dimensions=*/{2, 3},
Padding::kValid);
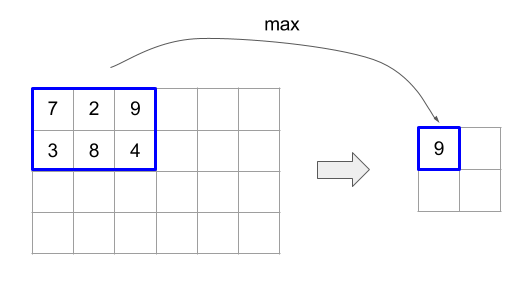
ディメンションのストライドが 1 の場合、そのディメンションのウィンドウの位置は隣接するウィンドウから 1 要素離れています。ウィンドウが互いに重複しないようにするには、window_stride_dimensions を window_dimensions と同じにする必要があります。次の図は、2 つの異なるストライド値の使用を示しています。パディングは入力の各ディメンションに適用され、入力がパディング後のディメンションで入ってきた場合と同じ計算が行われます。
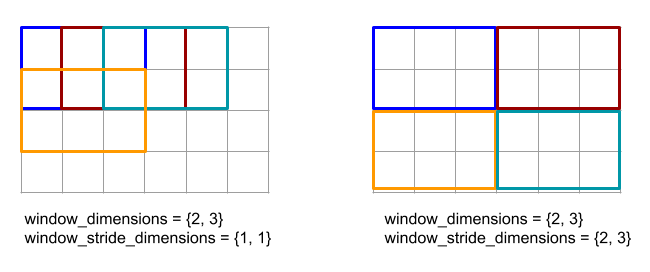
パディングの例として、入力配列 [10000, 1000, 100, 10, 1] に対して、次元 3 とストライド 2 を使用して、縮小ウィンドウの最小値(初期値は MAX_FLOAT)を計算することを考えます。パディング kValid は、2 つの有効なウィンドウ [10000, 1000, 100] と [100, 10, 1] の最小値を計算し、出力 [100, 1] を生成します。パディング kSame は、まず、縮小ウィンドウ後の形状がストライド 1 の入力と同じになるように、両側に初期要素を追加して配列をパディングし、[MAX_VALUE, 10000, 1000, 100, 10, 1,
MAX_VALUE] を取得します。パディングされた配列に対して reduce-window を実行すると、3 つのウィンドウ [MAX_VALUE, 10000, 1000]、[1000, 100, 10]、[10, 1, MAX_VALUE] が処理され、[1000, 10, 1] が生成されます。
リダクション関数の評価順序は任意であり、非決定的になる可能性があります。そのため、削減関数は再関連付けに過度に敏感であってはなりません。詳細については、Reduce のコンテキストでの結合性に関する説明をご覧ください。
ReduceWindow - 例 2 - StableHLO

上の例では、
入力)オペランドの入力形状は S32[3,2] です。値が [[1,2],[3,4],[5,6]] の場合
ステップ 1)行ディメンションに沿って係数 2 で基本拡張を行うと、オペランドの各行の間に穴が挿入されます。拡張後に、上部に 2 行、下部に 1 行のパディングが適用されます。その結果、テンソルが高くなります。
ステップ 2)形状 [2,1] のウィンドウが定義され、ウィンドウ拡張 [3,1] が設定されます。つまり、各ウィンドウは同じ列から 2 つの要素を選択しますが、2 番目の要素は最初の要素の直下ではなく、3 行下の要素が選択されます。
ステップ 3)次に、ウィンドウはオペランド上をストライド [4,1] でスライドします。これにより、ウィンドウは一度に 4 行下に移動し、一度に 1 列ずつ水平方向にシフトします。パディング セルは init_value(この場合は init_value = 0)で埋められます。拡張セルに「入る」値は無視されます。ストライドとパディングにより、一部のウィンドウはゼロと穴のみをオーバーラップしますが、他のウィンドウは実際の入力値をオーバーラップします。
ステップ 4)各ウィンドウ内で、要素は削減関数(a, b)→ a + b を使用して結合されます。初期値は 0 です。上位 2 つのウィンドウにはパディングと穴のみが表示されるため、結果は 0 になります。下のウィンドウは入力から値 3 と 4 を取得し、それらを結果として返します。
結果)最終出力の形状は S32[2,2] で、値は [[0,0],[3,4]] です。
Rem
XlaBuilder::Rem もご覧ください。
被除数 lhs と除数 rhs の要素ごとの余りを計算します。
結果の符号は被除数から取得され、結果の絶対値は常に除数の絶対値よりも小さくなります。
Rem(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Rem には、異なる次元のブロードキャストをサポートする代替バリアントがあります。
Rem(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の詳細については、StableHLO - 剰余をご覧ください。
ReplicaId
XlaBuilder::ReplicaId もご覧ください。
レプリカの一意の ID(U32 スカラー)を返します。
ReplicaId()
各レプリカの固有 ID は、[0, N) の範囲の符号なし整数です。ここで、N はレプリカの数です。すべてのレプリカが同じプログラムを実行しているため、プログラム内の ReplicaId() 呼び出しは、各レプリカで異なる値を返します。
StableHLO の情報については、StableHLO - replica_id をご覧ください。
Reshape
XlaBuilder::Reshapeもご覧ください。Collapse オペレーション。
配列のディメンションを新しい構成に再形成します。
Reshape(operand, dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
型 T の配列 |
dimensions |
int64 ベクトル |
新しいディメンションのサイズのベクトル |
概念的には、reshape はまず配列をデータ値の 1 次元ベクトルに平坦化し、次にこのベクトルを新しい形状に調整します。入力引数は、型 T の任意の配列、ディメンション インデックスのコンパイル時定数ベクトル、結果のディメンション サイズのコンパイル時定数ベクトルです。dimensions ベクトルは、出力配列のサイズを決定します。dimensions のインデックス 0 の値はディメンション 0 のサイズ、インデックス 1 の値はディメンション 1 のサイズです。dimensions ディメンションの積は、オペランドのディメンション サイズの積と等しくなければなりません。折りたたまれた配列を dimensions で定義された多次元配列に絞り込む場合、dimensions のディメンションは、変化が最も遅い(最も大きい)ものから変化が最も速い(最も小さい)ものまで順に並べられます。
たとえば、v を 24 個の要素の配列とします。
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
let v012_24 = Reshape(v, {24});
then v012_24 == f32[24] {10, 11, 12, 15, 16, 17, 20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37, 40, 41, 42, 45, 46, 47};
let v012_83 = Reshape(v, {8,3});
then v012_83 == f32[8x3] { {10, 11, 12}, {15, 16, 17},
{20, 21, 22}, {25, 26, 27},
{30, 31, 32}, {35, 36, 37},
{40, 41, 42}, {45, 46, 47} };
特殊なケースとして、reshape は単一要素の配列をスカラーに変換したり、その逆の変換を行うことができます。次に例を示します。
Reshape(f32[1x1] { {5} }, {}) == 5;
Reshape(5, {1,1}) == f32[1x1] { {5} };
StableHLO の詳細については、StableHLO - reshape をご覧ください。
Reshape(明示的)
XlaBuilder::Reshape もご覧ください。
Reshape(shape, operand)
明示的なターゲット形状を使用する Reshape オペレーション。
| 引数 | タイプ | セマンティクス |
|---|---|---|
shape |
Shape |
型 T の出力シェイプ |
operand |
XlaOp |
型 T の配列 |
Rev(逆)
XlaBuilder::Rev もご覧ください。
Rev(operand, dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
型 T の配列 |
dimensions |
ArraySlice<int64> |
反転するディメンション |
指定された dimensions に沿って operand 配列内の要素の順序を逆にして、同じ形状の出力配列を生成します。多次元インデックスのオペランド配列の各要素は、変換されたインデックスの出力配列に格納されます。多次元インデックスは、反転される各ディメンションのインデックスを反転することで変換されます(つまり、サイズ N のディメンションが反転されるディメンションの 1 つである場合、そのインデックス i は N - 1 - i に変換されます)。
Rev 演算の用途の 1 つは、ニューラル ネットワークの勾配計算中に 2 つのウィンドウ ディメンションに沿って畳み込み重み配列を反転することです。
StableHLO の情報については、StableHLO - reverse をご覧ください。
RngNormal
XlaBuilder::RngNormal もご覧ください。
\(N(\mu, \sigma)\) 正規分布に従って生成された乱数を使用して、指定された形状の出力を構築します。パラメータ \(\mu\) と \(\sigma\)、および出力形状は、浮動小数点要素型である必要があります。また、パラメータはスカラー値である必要があります。
RngNormal(mu, sigma, shape)
| 引数 | タイプ | セマンティクス |
|---|---|---|
mu |
XlaOp |
生成された数値の平均を指定する型 T のスカラー |
sigma
|
XlaOp
|
生成された標準偏差を指定する型 T のスカラー |
shape |
Shape |
型 T の出力シェイプ |
StableHLO の情報については、StableHLO - rng をご覧ください。
RngUniform
XlaBuilder::RngUniform もご覧ください。
間隔 \([a,b)\)で一様分布に従って生成された乱数を使用して、指定された形状の出力を構築します。パラメータと出力要素の型は、ブール型、整数型、浮動小数点型のいずれかである必要があり、型は一貫している必要があります。現在、CPU バックエンドと GPU バックエンドは F64、F32、F16、BF16、S64、U64、S32、U32 のみをサポートしています。さらに、パラメータはスカラー値である必要があります。 \(b <= a\) の場合、結果は実装定義です。
RngUniform(a, b, shape)
| 引数 | タイプ | セマンティクス |
|---|---|---|
a |
XlaOp |
区間の下限を指定する型 T のスカラー |
b |
XlaOp |
間隔の上限を指定する型 T のスカラー |
shape |
Shape |
型 T の出力シェイプ |
StableHLO の情報については、StableHLO - rng をご覧ください。
RngBitGenerator
XlaBuilder::RngBitGenerator もご覧ください。
指定されたアルゴリズム(またはバックエンドのデフォルト)を使用して、指定された形状の均一なランダムビットで埋められた出力を生成し、更新された状態(初期状態と同じ形状)と生成されたランダムデータを返します。
初期状態は、現在の乱数生成の初期状態です。必要な形状と有効な値は、使用されるアルゴリズムによって異なります。
出力は初期状態の決定論的関数であることが保証されますが、バックエンドとコンパイラのバージョン間で決定論的であることは保証されません。
RngBitGenerator(algorithm, initial_state, shape)
| 引数 | タイプ | セマンティクス |
|---|---|---|
algorithm |
RandomAlgorithm |
使用する PRNG アルゴリズム。 |
initial_state |
XlaOp |
PRNG アルゴリズムの初期状態。 |
shape |
Shape |
生成されたデータの出力シェイプ。 |
algorithm に指定できる値:
rng_default: バックエンド固有の形状要件を持つバックエンド固有のアルゴリズム。rng_three_fry: ThreeFry カウンタベースの PRNG アルゴリズム。initial_stateの形状はu64[2]で、任意の値です。Salmon et al. SC 2011. Parallel random numbers: as easy as 1, 2, 3.rng_philox: 乱数を並列で生成する Philox アルゴリズム。initial_stateシェイプは、任意の値を持つu64[3]です。Salmon et al. SC 2011. 並列乱数: 1、2、3 のように簡単です。
StableHLO の詳細については、StableHLO - rng_bit_generator をご覧ください。
RngGetAndUpdateState
HloInstruction::CreateRngGetAndUpdateState もご覧ください。
さまざまな Rng オペレーションの API は、内部的に RngGetAndUpdateState を含む HLO 命令に分解されます。
RngGetAndUpdateState は HLO のプリミティブとして機能します。このオペレーションは HLO ダンプに表示されることがありますが、エンドユーザーが手動で構築することを想定していません。
ラウンド
XlaBuilder::Round もご覧ください。
要素ごとの丸め、ゼロから遠ざかるように丸めます。
Round(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
RoundNearestAfz
XlaBuilder::RoundNearestAfz もご覧ください。
要素ごとに最も近い整数に丸め、ゼロから離れるように同値を処理します。
RoundNearestAfz(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
StableHLO の詳細については、StableHLO - round_nearest_afz をご覧ください。
RoundNearestEven
XlaBuilder::RoundNearestEven もご覧ください。
要素ごとの丸め。最近接偶数に丸めます。
RoundNearestEven(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
StableHLO の情報については、StableHLO - round_nearest_even をご覧ください。
Rsqrt
XlaBuilder::Rsqrt もご覧ください。
平方根の逆数演算 x -> 1.0 / sqrt(x) の要素ごと。
Rsqrt(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Rsqrt は、オプションの result_accuracy 引数もサポートしています。
Rsqrt(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
StableHLO の詳細については、StableHLO - rsqrt をご覧ください。
スキャン
XlaBuilder::Scan もご覧ください。
指定されたディメンションに沿って配列に削減関数を適用し、最終状態と中間値の配列を生成します。
Scan(inputs..., inits..., to_apply, scan_dimension,
is_reverse, is_associative)
| 引数 | タイプ | セマンティクス |
|---|---|---|
inputs |
m XlaOp のシーケンス |
スキャンする配列。 |
inits |
k XlaOp のシーケンス |
初期の持ち越し。 |
to_apply |
XlaComputation |
型 i_0, ..., i_{m-1}, c_0, ..., c_{k-1} -> (o_0, ..., o_{n-1}, c'_0, ..., c'_{k-1}) の計算。 |
scan_dimension |
int64 |
スキャンするディメンション。 |
is_reverse |
bool |
true の場合、逆順でスキャンします。 |
is_associative |
bool(トライステート) |
true の場合、オペレーションは結合的です。 |
関数 to_apply は、scan_dimension に沿って inputs の要素に順番に適用されます。is_reverse が false の場合、要素は 0 から N-1 の順に処理されます。ここで、N は scan_dimension のサイズです。is_reverse が true の場合、要素は N-1 から 0 の順に処理されます。
to_apply 関数は m + k オペランドを受け取ります。
inputsの現在の要素m個。kは、前のステップの値を保持します(最初の要素の場合はinits)。
to_apply 関数は、n + k 値のタプルを返します。
outputsのn要素。k新しい持ち越し値。
スキャン オペレーションは、n + k 値のタプルを生成します。
- 各ステップの出力値を含む
n出力配列。 - すべての要素を処理した後の最終的な
k繰り上げ値。
m 入力の型は、追加のスキャン ディメンションを含む to_apply の最初の m パラメータの型と一致する必要があります。n 出力の型は、追加のスキャン ディメンションを含む to_apply の最初の n 戻り値の型と一致する必要があります。すべての入力と出力の追加のスキャン ディメンションのサイズは N と同じである必要があります。to_apply の最後の k パラメータと戻り値の型、および k init の型は一致する必要があります。
たとえば、初期キャリー i、入力 [a, b, c]、関数 f(x, c) -> (y, c')、scan_dimension=0、is_reverse=false の場合(m, n, k == 1, N == 3):
- ステップ 0:
f(a, i) -> (y0, c0) - ステップ 1:
f(b, c0) -> (y1, c1) - ステップ 2:
f(c, c1) -> (y2, c2)
Scan の出力は ([y0, y1, y2], c2) です。
散布
XlaBuilder::Scatter もご覧ください。
XLA スキャッター オペレーションは、入力配列 operands の値である結果のシーケンスを生成します。このシーケンスでは、update_computation を使用して、updates の値のシーケンスで複数のスライス(scatter_indices で指定されたインデックス)が更新されます。
Scatter(operands..., scatter_indices, updates..., update_computation,
dimension_numbers, indices_are_sorted, unique_indices)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operands |
N 個の XlaOp のシーケンス |
分散する T_0, ..., T_N 型の N 個の配列。 |
scatter_indices |
XlaOp |
分散する必要があるスライスの開始インデックスを含む配列。 |
updates |
N 個の XlaOp のシーケンス |
T_0, ..., T_N 型の N 個の配列。updates[i] には、operands[i] の分散に使用する必要がある値が含まれます。 |
update_computation |
XlaComputation |
入力配列内の既存の値とスキャッター中の更新を結合するために使用される計算。この計算は T_0, ..., T_N, T_0, ..., T_N -> Collate(T_0, ..., T_N) 型にする必要があります。 |
index_vector_dim |
int64 |
開始インデックスを含む scatter_indices のディメンション。 |
update_window_dims |
ArraySlice<int64> |
updates シェイプのディメンションのセット。ウィンドウのディメンションです。 |
inserted_window_dims |
ArraySlice<int64> |
updates シェイプに挿入する必要があるウィンドウ ディメンションのセット。 |
scatter_dims_to_operand_dims |
ArraySlice<int64> |
散布インデックスからオペランド インデックス空間へのディメンション マップ。この配列は i から scatter_dims_to_operand_dims[i] へのマッピングとして解釈されます。これは一対一でなければなりません。 |
dimension_number |
ScatterDimensionNumbers |
散布オペレーションのディメンション番号 |
indices_are_sorted |
bool |
インデックスが呼び出し元によってソートされることが保証されているかどうか。 |
unique_indices |
bool |
インデックスが一意であることが呼び出し元によって保証されているかどうか。 |
ここで
- N は 1 以上である必要があります。
operands[0]、...、operands[N-1] はすべて同じディメンションにする必要があります。updates[0]、...、updates[N-1] はすべて同じディメンションにする必要があります。N = 1の場合、Collate(T)はTです。N > 1、Collate(T_0, ..., T_N)がT型のN要素のタプルである場合。
index_vector_dim が scatter_indices.rank と等しい場合、scatter_indices に末尾の 1 ディメンションがあると暗黙的にみなします。
型 ArraySlice<int64> の update_scatter_dims は、update_window_dims に含まれない updates シェイプのディメンションのセットとして昇順で定義します。
scatter の引数は次の制約に従う必要があります。
各
updates配列にはupdate_window_dims.size + scatter_indices.rank - 1ディメンションが必要です。各
updates配列のディメンションiの境界は、次の条件を満たしている必要があります。iがupdate_window_dimsに存在する場合(つまり、あるkに対してupdate_window_dims[k] と等しい場合)、updates内のディメンションiの境界は、inserted_window_dimsを考慮した後、operandの対応する境界を超えてはなりません(つまり、adjusted_window_bounds[k]、ここでadjusted_window_boundsには、インデックスinserted_window_dimsの境界が削除されたoperandの境界が含まれます)。iがupdate_scatter_dimsに存在する場合(つまり、kのupdate_scatter_dims[k] に等しい場合)、updatesのディメンションiの境界は、scatter_indicesの対応する境界に等しく、index_vector_dimをスキップする必要があります(つまり、k<index_vector_dimの場合はscatter_indices.shape.dims[k]、それ以外の場合はscatter_indices.shape.dims[k+1])。
update_window_dimsは昇順で、ディメンション番号の重複がなく、[0, updates.rank)の範囲内である必要があります。inserted_window_dimsは昇順で、ディメンション番号の重複がなく、[0, operand.rank)の範囲内である必要があります。operand.rankはupdate_window_dims.sizeとinserted_window_dims.sizeの合計と等しくなければなりません。scatter_dims_to_operand_dims.sizeはscatter_indices.shape.dims[index_vector_dim] と等しく、値は[0, operand.rank)の範囲内である必要があります。
各 updates 配列の指定されたインデックス U について、この更新を適用する必要がある対応する operands 配列の対応するインデックス I は次のように計算されます。
G= {U[k] forkinupdate_scatter_dims} とします。Gを使用して、S[i] =scatter_indices[Combine(G,i)] となるようにscatter_indices配列内のインデックス ベクトルSをルックアップします。ここで、Combine(A, b) は、位置index_vector_dimに b を A に挿入します。scatter_dims_to_operand_dimsマップを使用してSを分散し、Sを使用してoperandにインデックスSinを作成します。より正式には、次のようになります。Sin[scatter_dims_to_operand_dims[k]] =S[k](k<scatter_dims_to_operand_dims.sizeの場合)。- それ以外の場合は、
Sin[_] =0。
inserted_window_dimsに従ってUのupdate_window_dimsにあるインデックスを分散させることで、各operands配列にインデックスWinを作成します。より正式には、次のようになります。kがupdate_window_dimsにある場合、Win[window_dims_to_operand_dims(k)] =U[k]。ここで、window_dims_to_operand_dimsはドメイン [0,update_window_dims.size) と範囲 [0,operand.rank) \inserted_window_dimsを持つ単調関数です。(たとえば、update_window_dims.sizeが4、operand.rankが6、inserted_window_dimsが {0,2} の場合、window_dims_to_operand_dimsは {0→1,1→3,2→4,3→5} になります)。- それ以外の場合は、
Win[_] =0。
IはWin+Sinです。ここで、+ は要素ごとの加算です。
要約すると、スキャッター オペレーションは次のように定義できます。
outputをoperandsで初期化します。つまり、すべてのインデックスJ、operands[J] 配列内のすべてのインデックスOに対して、
output[J][O] =operands[J][O]updates[J] 配列のすべてのインデックスUと、operand[J] 配列の対応するインデックスOについて、Oがoutputの有効なインデックスである場合:
(output[0][O], ...,output[N-1][O]) =update_computation(output[0][O], ..., ,output[N-1][O],updates[0][U], ...,updates[N-1][U])
更新が適用される順序は非決定的です。そのため、updates の複数のインデックスが operands の同じインデックスを参照している場合、output の対応する値は非決定的になります。
update_computation に渡される最初のパラメータは常に output 配列の現在の値になり、2 番目のパラメータは常に updates 配列の値になります。これは、update_computation が可換でない場合に特に重要です。
indices_are_sorted が true に設定されている場合、XLA は scatter_indices がユーザーによって(昇順で、scatter_dims_to_operand_dims に従って値を分散した後に)並べ替えられていると想定できます。そうでない場合、セマンティクスは実装定義です。
unique_indices が true に設定されている場合、XLA は、分散されたすべての要素が一意であると想定できます。そのため、XLA は非アトミック オペレーションを使用できます。unique_indices が true に設定されていて、分散先のインデックスが一意でない場合、セマンティクスは実装で定義されます。
非公式には、スキャッター オペレーションはギャザー オペレーションの逆と見なすことができます。つまり、スキャッター オペレーションは、対応するギャザー オペレーションによって抽出された入力の要素を更新します。
詳細な非公式の説明と例については、Gather の「非公式の説明」セクションを参照してください。
StableHLO の詳細については、StableHLO - scatter をご覧ください。
Scatter - 例 1 - StableHLO

上の図では、テーブルの各行が 1 つの更新インデックスの例です。左(更新インデックス)から右(結果インデックス)まで、段階的に確認しましょう。
入力)input の形状は S32[2,3,4,2] です。scatter_indices の形状は S64[2,2,3,2] です。updates の形状は S32[2,2,3,1,2] です。
インデックスを更新)入力の一部として update_window_dims:[3,4] が与えられます。これは、updates の dim 3 と dim 4 がウィンドウのディメンションであることを示しています(黄色でハイライト表示)。これにより、update_scatter_dims = [0,1,2] を導出できます。
Update Scatter Index)各抽出された updated_scatter_dims を示します。(列 Update Index の黄色以外の部分)
開始インデックス)scatter_indices テンソル画像を見ると、前の手順(Update scatter Index)の値から開始インデックスの位置がわかります。また、index_vector_dim から、開始インデックスを含む starting_indices のディメンションもわかります。scatter_indices の場合、サイズ 2 のディメンション 3 です。
Full Start Index)scatter_dims_to_operand_dims = [2,1] は、インデックス ベクトルの最初の要素がオペランドの次元 2 に移動することを示します。インデックス ベクトルの 2 番目の要素は、オペランドの dim 1 に移動します。残りのオペランドのディメンションは 0 で埋められます。
完全バッチ処理インデックス)この列(完全バッチ処理インデックス)、更新散布図インデックス列、更新インデックス列に、紫色のハイライト表示された領域が表示されます。
Full Window Index)は update_window_dimensions [3,4] から計算されます。
結果インデックス)operand テンソル内のフル開始インデックス、フル バッチ処理インデックス、フル ウィンドウ インデックスの合計。緑色のハイライト表示された領域が operand の図にも対応していることに注目してください。最後の行は operand テンソルの範囲外であるためスキップされます。
選択
XlaBuilder::Select もご覧ください。
述語配列の値に基づいて、2 つの入力配列の要素から出力配列を作成します。
Select(pred, on_true, on_false)
| 引数 | タイプ | セマンティクス |
|---|---|---|
pred |
XlaOp |
PRED 型の配列 |
on_true |
XlaOp |
型 T の配列 |
on_false |
XlaOp |
型 T の配列 |
配列 on_true と on_false は同じ形状である必要があります。これは出力配列の形状でもあります。配列 pred は、on_true および on_false と同じ次元を持ち、PRED 要素型である必要があります。
pred の各要素 P について、P の値が true の場合は on_true から、P の値が false の場合は on_false から、出力配列の対応する要素が取得されます。pred は、ブロードキャストの制限付き形式として、PRED 型のスカラーにすることができます。この場合、pred が true の場合は出力配列は on_true から、pred が false の場合は on_false から完全に取得されます。
非スカラー pred を使用した例:
let pred: PRED[4] = {true, false, false, true};
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 200, 300, 4};
スカラー pred を使用した例:
let pred: PRED = true;
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 2, 3, 4};
タプル間の選択がサポートされています。この目的では、タプルはスカラー型と見なされます。on_true と on_false がタプル(同じ形状である必要があります)の場合、pred は PRED 型のスカラーである必要があります。
StableHLO の情報については、StableHLO - select をご覧ください。
SelectAndScatter
XlaBuilder::SelectAndScatter もご覧ください。
このオペレーションは、最初に operand 配列で ReduceWindow を計算して各ウィンドウから要素を選択し、次に source 配列を選択した要素のインデックスに分散して、オペランド配列と同じ形状の出力配列を構築する複合オペレーションと見なすことができます。バイナリ select 関数は、各ウィンドウに適用して各ウィンドウから要素を選択するために使用されます。この関数は、最初のパラメータのインデックス ベクトルが 2 番目のパラメータのインデックス ベクトルよりも辞書式順序で小さいというプロパティで呼び出されます。select 関数は、最初のパラメータが選択された場合は true を返し、2 番目のパラメータが選択された場合は false を返します。また、選択された要素が特定のウィンドウでトラバースされた要素の順序に依存しないように、この関数は推移性(select(a, b) と select(b, c) が true の場合、select(a, c) も true)を保持する必要があります。
関数 scatter は、出力配列内の選択された各インデックスに適用されます。2 つのスカラー パラメータを受け取ります。
- 出力配列の選択されたインデックスの現在値
- 選択したインデックスに適用される
sourceの散布値
2 つのパラメータを組み合わせて、出力配列の選択したインデックスの値を更新するために使用されるスカラー値を返します。最初、出力配列のすべてのインデックスは init_value に設定されます。
出力配列は operand 配列と同じ形状になり、source 配列は operand 配列に ReduceWindow 演算を適用した結果と同じ形状になります。SelectAndScatter は、ニューラル ネットワークのプーリング レイヤのグラデーション値をバックプロパゲートするために使用できます。
SelectAndScatter(operand, select, window_dimensions, window_strides, padding,
source, init_value, scatter)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand
|
XlaOp
|
ウィンドウがスライドする型 T の配列 |
select
|
XlaComputation
|
T, T
-> PRED タイプのバイナリ計算。各ウィンドウのすべての要素に適用します。最初のパラメータが選択されている場合は true を返し、2 番目のパラメータが選択されている場合は false を返します。 |
window_dimensions
|
ArraySlice<int64>
|
ウィンドウ ディメンション値の整数の配列 |
window_strides
|
ArraySlice<int64>
|
ウィンドウ ストライド値の整数の配列 |
padding
|
Padding
|
ウィンドウのパディング タイプ(Padding::kSame または Padding::kValid) |
source
|
XlaOp
|
散布する値を含む型 T の配列 |
init_value
|
XlaOp
|
出力配列の初期値の型 T のスカラー値 |
scatter
|
XlaComputation
|
T, T
-> T 型のバイナリ計算。各スキャッター ソース要素をその宛先要素に適用します。 |
次の図は、SelectAndScatter の使用例を示しています。select 関数は、パラメータの最大値を計算します。下の図(2)のようにウィンドウが重なっている場合、operand 配列のインデックスが異なるウィンドウによって複数回選択されることがあります。図では、値 9 の要素が両方の最上位ウィンドウ(青と赤)で選択され、バイナリ加算 scatter 関数によって値 8(2 + 6)の出力要素が生成されます。
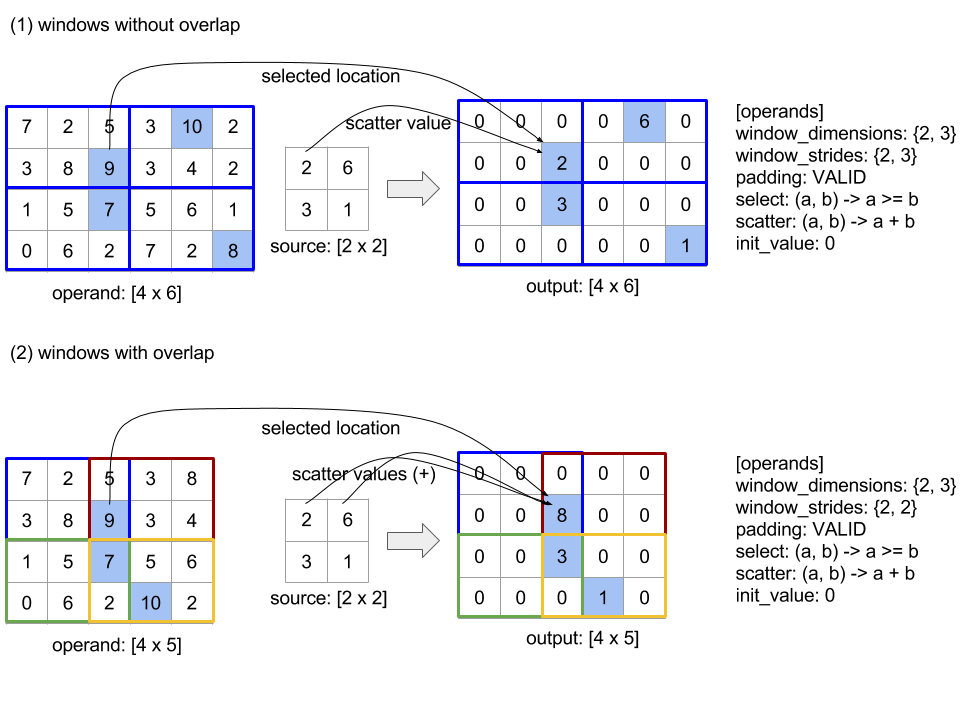
scatter 関数の評価順序は任意であり、非決定的になる可能性があります。したがって、scatter 関数は再関連付けに過敏に反応しないようにする必要があります。詳細については、Reduce のコンテキストでの結合性に関する説明をご覧ください。
StableHLO の詳細については、StableHLO - select_and_scatter をご覧ください。
送信
XlaBuilder::Send もご覧ください。
Send、SendWithTokens、SendToHost は、HLO で通信プリミティブとして機能するオペレーションです。これらのオペレーションは通常、低レベルの入出力またはデバイス間の転送の一部として HLO ダンプに表示されますが、エンドユーザーが手動で構築することを想定していません。
Send(operand, handle)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
送信するデータ(型 T の配列) |
handle |
ChannelHandle |
各送受信ペアの一意の識別子 |
同じチャンネル ハンドルを共有する別の計算の Recv 命令に、指定されたオペランド データを送信します。データを返しません。
Recv オペレーションと同様に、Send オペレーションのクライアント API は同期通信を表し、非同期データ転送を可能にするために内部的に 2 つの HLO 命令(Send と SendDone)に分解されます。HloInstruction::CreateSend と HloInstruction::CreateSendDone もご覧ください。
Send(HloInstruction operand, int64 channel_id)
同じチャネル ID を持つ Recv 命令によって割り当てられたリソースへのオペランドの非同期転送を開始します。コンテキストを返します。このコンテキストは、後続の SendDone 命令でデータ転送の完了を待つために使用されます。コンテキストは {オペランド(形状)、リクエスト ID(U32)} のタプルであり、SendDone 命令でのみ使用できます。
StableHLO の情報については、StableHLO - 送信をご覧ください。
SendDone
HloInstruction::CreateSendDone もご覧ください。
SendDone(HloInstruction context)
Send 命令によって作成されたコンテキストを指定して、データ転送の完了を待ちます。この命令はデータを返しません。
チャンネルの説明のスケジュール設定
各チャネル(Recv、RecvDone、Send、SendDone)の 4 つの命令の実行順序は次のとおりです。
RecvはSendの前に発生しますSendはRecvDoneの前に発生しますRecvはRecvDoneの前に発生しますSendはSendDoneの前に発生します
バックエンド コンパイラがチャネル命令を介して通信する各計算の線形スケジュールを生成する場合、計算間でサイクルが発生してはなりません。たとえば、次のスケジュールはデッドロックにつながります。
SetDimensionSize
XlaBuilder::SetDimensionSize もご覧ください。
XlaOp の指定されたディメンションの動的サイズを設定します。オペランドは配列の形状である必要があります。
SetDimensionSize(operand, val, dimension)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
n 次元の入力配列。 |
val |
XlaOp |
実行時の動的サイズを表す int32。 |
dimension
|
int64
|
ディメンションを指定する [0, n) の範囲内の値。 |
オペランドを結果として渡し、コンパイラによって追跡される動的ディメンションを使用します。
パディングされた値は、ダウンストリームの削減オペレーションで無視されます。
let v: f32[10] = f32[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
let five: s32 = 5;
let six: s32 = 6;
// Setting dynamic dimension size doesn't change the upper bound of the static
// shape.
let padded_v_five: f32[10] = set_dimension_size(v, five, /*dimension=*/0);
let padded_v_six: f32[10] = set_dimension_size(v, six, /*dimension=*/0);
// sum == 1 + 2 + 3 + 4 + 5
let sum:f32[] = reduce_sum(padded_v_five);
// product == 1 * 2 * 3 * 4 * 5
let product:f32[] = reduce_product(padded_v_five);
// Changing padding size will yield different result.
// sum == 1 + 2 + 3 + 4 + 5 + 6
let sum:f32[] = reduce_sum(padded_v_six);
ShiftLeft
XlaBuilder::ShiftLeft もご覧ください。
lhs に対して rhs ビット数だけ要素ごとの左シフト演算を行います。
ShiftLeft(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
ShiftLeft には、異なる次元のブロードキャストをサポートする別のバリアントがあります。
ShiftLeft(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の情報については、StableHLO - shift_left をご覧ください。
ShiftRightArithmetic
XlaBuilder::ShiftRightArithmetic もご覧ください。
lhs に対して、rhs ビット数だけ要素ごとの算術右シフト演算を行います。
ShiftRightArithmetic(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
ShiftRightArithmetic には、異なる次元のブロードキャストをサポートする別のバリアントがあります。
ShiftRightArithmetic(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の詳細については、StableHLO - shift_right_arithmetic をご覧ください。
ShiftRightLogical
XlaBuilder::ShiftRightLogical もご覧ください。
lhs に対して、rhs ビット数だけ要素ごとの論理右シフト演算を行います。
ShiftRightLogical(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
ShiftRightLogical には、異なる次元のブロードキャストをサポートする別のバリアントがあります。
ShiftRightLogical(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の情報については、StableHLO - shift_right_logical をご覧ください。
署名
XlaBuilder::Sign もご覧ください。
Sign(operand) 要素ごとの符号演算 x -> sgn(x)。ここで、
\[\text{sgn}(x) = \begin{cases} -1 & x < 0\\ -0 & x = -0\\ NaN & x = NaN\\ +0 & x = +0\\ 1 & x > 0 \end{cases}\]
operand の要素型の比較演算子を使用します。
Sign(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
StableHLO の詳細については、StableHLO - sign をご覧ください。
Sin
Sin(operand) 要素単位の正弦 x -> sin(x)。
XlaBuilder::Sin もご覧ください。
Sin(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Sin は、省略可能な result_accuracy 引数もサポートしています。
Sin(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
StableHLO の情報については、StableHLO - sine をご覧ください。
スライス
XlaBuilder::Slice もご覧ください。
スライスは、入力配列からサブ配列を抽出します。サブ配列の次元数は入力と同じで、入力配列内の境界ボックス内の値が含まれます。境界ボックスの次元とインデックスは、スライス オペレーションの引数として指定されます。
Slice(operand, start_indices, limit_indices, strides)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
型 T の N 次元配列 |
start_indices
|
ArraySlice<int64>
|
各ディメンションのスライスの開始インデックスを含む N 個の整数のリスト。値は 0 以上にする必要があります。 |
limit_indices
|
ArraySlice<int64>
|
各ディメンションのスライスの終了インデックス(排他的)を含む N 個の整数のリスト。各値は、ディメンションの対応する start_indices 値以上で、ディメンションのサイズ以下である必要があります。 |
strides
|
ArraySlice<int64>
|
スライスの入力ストライドを決定する N 個の整数のリスト。スライスは、ディメンション d のすべての strides[d] 要素を選択します。 |
1 次元の例:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
Slice(a, {2}, {4})
// Result: {2.0, 3.0}
2 次元の例:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
Slice(b, {2, 1}, {4, 3})
// Result:
// { { 7.0, 8.0},
// {10.0, 11.0} }
StableHLO の詳細については、StableHLO - スライスをご覧ください。
並べ替え
XlaBuilder::Sort もご覧ください。
Sort(operands, comparator, dimension, is_stable)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operands |
ArraySlice<XlaOp> |
並べ替えるオペランド。 |
comparator |
XlaComputation |
使用する比較演算子の計算。 |
dimension |
int64 |
並べ替えの基準となるディメンション。 |
is_stable |
bool |
安定した並べ替えを使用するかどうか。 |
オペランドが 1 つだけ指定されている場合:
オペランドが 1 次元テンソル(配列)の場合、結果はソートされた配列になります。配列を昇順で並べ替える場合は、比較関数で小なり比較を行う必要があります。形式的には、配列がソートされた後、すべてのインデックス位置
i, j(i < j)でcomparator(value[i], value[j]) = comparator(value[j], value[i]) = falseまたはcomparator(value[i], value[j]) = trueが保持されます。オペランドの次元数が多い場合、オペランドは指定された次元に沿って並べ替えられます。たとえば、2 次元テンソル(行列)の場合、次元値
0は各列を個別に並べ替え、次元値1は各行を個別に並べ替えます。次元番号が指定されていない場合、デフォルトで最後の次元が選択されます。並べ替えられる次元には、1 次元の場合と同じ並べ替え順序が適用されます。
n > 1 オペランドが指定されている場合:
すべての
nオペランドは、同じディメンションのテンソルである必要があります。テンソルの要素型は異なってもかまいません。オペランドは個別にではなく、まとめて並べ替えられます。概念的には、オペランドはタプルとして扱われます。インデックス位置
iとjの各オペランドの要素を入れ替える必要があるかどうかを確認するときに、コンパレータは2 * nスカラー パラメータで呼び出されます。ここで、パラメータ2 * kはk-thオペランドのi位置の値に対応し、パラメータ2 * k + 1はk-thオペランドのj位置の値に対応します。通常、コンパレータはパラメータ2 * kと2 * k + 1を互いに比較し、必要に応じて他のパラメータ ペアをタイブレーカーとして使用します。結果は、ソートされた順序のオペランド(上記のように、指定されたディメンションに沿って)で構成されるタプルです。タプルの
i-thオペランドは、Sort のi-thオペランドに対応します。
たとえば、3 つのオペランド operand0 = [3, 1]、operand1 = [42, 50]、operand2 = [-3.0, 1.1] があり、比較演算子が operand0 の値のみを小なりで比較する場合、ソートの出力はタプル ([1, 3], [50, 42], [1.1, -3.0]) になります。
is_stable が true に設定されている場合、ソートは安定していることが保証されます。つまり、コンパレータによって等しいと見なされる要素がある場合、等しい値の相対順序が保持されます。2 つの要素 e1 と e2 は、comparator(e1, e2) = comparator(e2, e1) = false の場合にのみ等しくなります。デフォルトでは、is_stable は false に設定されています。
StableHLO の情報については、StableHLO - sort をご覧ください。
Sqrt
XlaBuilder::Sqrt もご覧ください。
要素ごとの平方根演算 x -> sqrt(x)。
Sqrt(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Sqrt は、オプションの result_accuracy 引数もサポートしています。
Sqrt(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
StableHLO の情報については、StableHLO - sqrt をご覧ください。
サブ
XlaBuilder::Sub もご覧ください。
lhs と rhs の要素ごとの減算を行います。
Sub(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Sub には、異なる次元のブロードキャストをサポートする代替バリアントがあります。
Sub(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の詳細については、StableHLO - 減算をご覧ください。
タン
XlaBuilder::Tan もご覧ください。
要素単位の正接 x -> tan(x)。
Tan(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Tan は、オプションの result_accuracy 引数もサポートしています。
Tan(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
StableHLO の情報については、StableHLO - tan をご覧ください。
Tanh
XlaBuilder::Tanh もご覧ください。
要素ごとの双曲線正接 x -> tanh(x)。
Tanh(operand)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
Tanh は、オプションの result_accuracy 引数もサポートしています。
Tanh(operand, result_accuracy)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
関数へのオペランド |
result_accuracy
|
省略可 ResultAccuracy
|
複数の実装を持つ単項演算でユーザーがリクエストできる精度の種類 |
result_accuracy の詳細については、結果の精度をご覧ください。
StableHLO の詳細については、StableHLO - tanh をご覧ください。
トップ K
XlaBuilder::TopK もご覧ください。
TopK は、指定されたテンソルの最後のディメンションの k 個の最大要素または最小要素の値とインデックスを検索します。
TopK(operand, k, largest)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand
|
XlaOp
|
上位 k 個の要素を抽出するテンソル。テンソルの次元は 1 以上でなければなりません。テンソルの最後のディメンションのサイズは k 以上にする必要があります。 |
k |
int64 |
抽出する要素の数。 |
largest
|
bool
|
最大または最小の k 要素を抽出するかどうか。 |
1 次元入力テンソル(配列)の場合、配列内の k 個の最大値または最小値を見つけ、2 つの配列のタプル (values, indices) を出力します。したがって、values[j] は operand の j 番目に大きい/小さいエントリであり、そのインデックスは indices[j] です。
1 つ以上のディメンションを持つ入力テンソルについて、最後のディメンションに沿って上位 k エントリを計算し、出力内の他のすべてのディメンション(行)を保持します。したがって、Q >= k の [A, B, ..., P, Q] シェイプのオペランドの場合、出力はタプル (values, indices) になります。
values.shape = indices.shape = [A, B, ..., P, k]
行内の 2 つの要素が等しい場合、インデックスの小さい要素が先に表示されます。
行 / 列の入れ替え
tf.reshape オペレーションもご覧ください。
Transpose(operand, permutation)
| 引数 | タイプ | セマンティクス |
|---|---|---|
operand |
XlaOp |
転置するオペランド。 |
permutation |
ArraySlice<int64> |
ディメンションを置換する方法。 |
指定された順列でオペランドのディメンションを並べ替えます(∀ i . 0 ≤ i < number of dimensions ⇒
input_dimensions[permutation[i]] = output_dimensions[i])。
これは、Reshape(オペランド, 順列, Permute(順列, オペランド.shape.dimensions)) と同じです。
StableHLO の詳細については、StableHLO - 転置をご覧ください。
TriangularSolve
XlaBuilder::TriangularSolve もご覧ください。
前進代入または後退代入によって、下三角または上三角の係数行列を持つ連立一次方程式を解きます。先頭の次元に沿ってブロードキャストし、このルーティンは、a と b が与えられた場合に、変数 x について行列システム op(a) * x =
b または x * op(a) = b のいずれかを解きます。ここで、op(a) は op(a) = a、op(a) = Transpose(a)、または op(a) = Conj(Transpose(a)) のいずれかです。
TriangularSolve(a, b, left_side, lower, unit_diagonal, transpose_a)
| 引数 | タイプ | セマンティクス |
|---|---|---|
a
|
XlaOp
|
形状 [..., M,
M] の複素数型または浮動小数点型の 2 次元以上の配列。 |
b
|
XlaOp
|
left_side が true の場合は形状 [..., M, K]、それ以外の場合は [..., K, M] の同じ型の 2 次元以上の配列。 |
left_side
|
bool
|
op(a) * x = b(true)または x *
op(a) = b(false)の形式のシステムを解くかどうかを示します。 |
lower
|
bool
|
a の上向きまたは下向きの三角形を使用するかどうか。 |
unit_diagonal
|
bool
|
true の場合、a の対角要素は 1 とみなされ、アクセスされません。 |
transpose_a
|
Transpose
|
a をそのまま使用するか、転置するか、共役転置するか。 |
入力データは、lower の値に応じて a の下三角または上三角からのみ読み取られます。もう一方の三角形の値は無視されます。出力データは同じ三角形で返されます。もう一方の三角形の値は実装定義であり、任意の値にすることができます。
a と b の次元数が 2 より大きい場合、それらは行列のバッチとして扱われます。ここで、下位 2 次元を除くすべての次元がバッチ ディメンションになります。a と b のバッチ ディメンションは同じである必要があります。
StableHLO の情報については、StableHLO - triangular_solve をご覧ください。
Tuple
XlaBuilder::Tuple もご覧ください。
可変数のデータハンドルを含むタプル。各データハンドルには独自の形状があります。
Tuple(elements)
| 引数 | タイプ | セマンティクス |
|---|---|---|
elements |
XlaOp のベクトル |
型 T の N 配列 |
これは C++ の std::tuple に類似しています。概念的には次のようになります。
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
タプルは、GetTupleElement オペレーションで分解(アクセス)できます。
StableHLO の情報については、StableHLO - タプルをご覧ください。
ただし、
XlaBuilder::While もご覧ください。
While(condition, body, init)
| 引数 | タイプ | セマンティクス |
|---|---|---|
condition
|
XlaComputation
|
ループの終了条件を定義する T -> PRED タイプの XlaComputation。 |
body
|
XlaComputation
|
ループの本体を定義する T -> T 型の XlaComputation。 |
init
|
T
|
condition と body のパラメータの初期値。 |
condition が失敗するまで body を順次実行します。これは、以下の違いと制限を除き、他の多くの言語の一般的な while ループに似ています。
WhileノードはT型の値を返します。これは、bodyの最後の実行の結果です。- 型
Tの形状は静的に決定され、すべてのイテレーションで同じである必要があります。
計算の T パラメータは、最初の反復で init 値で初期化され、後続の各反復で body の新しい結果に自動的に更新されます。
While ノードの主なユースケースの 1 つは、ニューラル ネットワークでのトレーニングの繰り返し実行を実装することです。計算を表すグラフとともに、簡略化された疑似コードを以下に示します。コードは while_test.cc にあります。この例の型 T は、反復回数の int32 とアキュムレータの vector[10] で構成される Tuple です。1, 000 回の反復処理では、ループは定数ベクトルをアキュムレータに繰り返し追加します。
// Pseudocode for the computation.
init = {0, zero_vector[10]} // Tuple of int32 and float[10].
result = init;
while (result(0) < 1000) {
iteration = result(0) + 1;
new_vector = result(1) + constant_vector[10];
result = {iteration, new_vector};
}
StableHLO の詳細については、StableHLO - while をご覧ください。
Xor
XlaBuilder::Xor もご覧ください。
lhs と rhs の要素ごとの XOR を実行します。
Xor(lhs, rhs)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左辺のオペランド: 型 T の配列 |
| rhs | XlaOp | 左辺のオペランド: 型 T の配列 |
引数の形状は類似しているか、互換性がある必要があります。形状の互換性の意味については、ブロードキャストのドキュメントをご覧ください。オペレーションの結果の形状は、2 つの入力配列をブロードキャストした結果の形状になります。このバリアントでは、オペランドの 1 つがスカラーでない限り、ランクの異なる配列間のオペレーションはサポートされていません。
Xor には、異なる次元のブロードキャストをサポートする別のバリアントがあります。
Xor(lhs,rhs, broadcast_dimensions)
| 引数 | タイプ | セマンティクス |
|---|---|---|
| lhs | XlaOp | 左側のオペランド: 型 T の配列 |
| rhs | XlaOp | 左側のオペランド: 型 T の配列 |
| broadcast_dimension | ArraySlice |
オペランド シェイプの各ディメンションがターゲット シェイプのどのディメンションに対応するか |
このオペレーションのバリアントは、ランクの異なる配列間の算術演算(行列とベクトルの加算など)に使用する必要があります。
追加の broadcast_dimensions オペランドは、オペランドのブロードキャストに使用するディメンションを指定する整数のスライスです。セマンティクスについては、ブロードキャスト ページで詳しく説明しています。
StableHLO の詳細については、StableHLO - xor をご覧ください。