ต่อไปนี้อธิบายความหมายของการดำเนินการที่กําหนดไว้ในอินเตอร์เฟซ XlaBuilder โดยปกติแล้ว การดำเนินการเหล่านี้จะจับคู่แบบ 1:1 กับการดำเนินการที่กําหนดไว้ในอินเทอร์เฟซ RPC ใน xla_data.proto
หมายเหตุเกี่ยวกับชื่อ: ประเภทข้อมูลที่ทั่วไปที่ XLA จัดการคืออาร์เรย์ N มิติที่เก็บองค์ประกอบของประเภทแบบเดียวกัน (เช่น 32 บิต) ตลอดทั้งเอกสาร เราจะใช้คำว่า array เพื่อหมายถึงอาร์เรย์มิติใดก็ได้ เพื่อความสะดวก กรณีพิเศษจะมีชื่อที่เจาะจงและคุ้นเคยมากขึ้น เช่น เวกเตอร์ คืออาร์เรย์ 1 มิติ และเมทริกซ์เป็นอาร์เรย์ 2 มิติ
AfterAll
โปรดดูXlaBuilder::AfterAll
AfterAll จะรับโทเค็นจํานวนเท่าใดก็ได้และสร้างโทเค็นเดียว โทเค็นเป็นประเภทพื้นฐานที่สามารถใช้เทรดระหว่างการดำเนินการที่มีผลข้างเคียงเพื่อบังคับใช้ลําดับได้ AfterAll สามารถใช้เป็นโทเค็นที่เข้าร่วมเพื่อจัดลำดับการดำเนินการหลังจากการดำเนินการชุด
AfterAll(operands)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operands |
XlaOp |
จำนวนโทเค็นแบบผันแปร |
AllGather
โปรดดูXlaBuilder::AllGather
ดำเนินการเชื่อมต่อข้อมูลจำลอง
AllGather(operand, all_gather_dim, shard_count, replica_group_ids,
channel_id)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
operand
|
XlaOp
|
อาร์เรย์เพื่อเชื่อมข้อมูลใน ข้อมูลจำลอง |
all_gather_dim |
int64 |
มิติข้อมูลการต่อ |
replica_groups
|
เวกเตอร์ของเวกเตอร์ของ int64 |
กลุ่มที่จะใช้ต่อเชื่อม |
channel_id
|
ไม่บังคับ int64
|
รหัสแชแนลที่ไม่บังคับสําหรับการสื่อสารข้ามโมดูล |
replica_groupsคือรายการกลุ่มตัวจำลองที่มีการเชื่อมต่อ (รหัสตัวจำลองสำหรับตัวจำลองปัจจุบันเรียกดูได้โดยใช้ReplicaId) ลำดับของตัวจำลองในแต่ละกลุ่มจะเป็นตัวกำหนดลำดับอินพุตของตัวจำลองในผลลัพธ์replica_groupsต้องว่างเปล่า (ซึ่งในกรณีนี้ ข้อมูลจำลองทั้งหมดจะอยู่ในกลุ่มเดียว โดยเรียงจาก0ถึงN - 1) หรือมีจำนวนองค์ประกอบเท่ากับจำนวนข้อมูลจำลอง เช่นreplica_groups = {0, 2}, {1, 3}ดำเนินการต่อท้ายระหว่างข้อมูลจำลอง0กับ2และ1กับ3shard_countคือขนาดของกลุ่มตัวจำลองแต่ละกลุ่ม เราต้องใช้ข้อมูลนี้ในกรณีที่replica_groupsว่างเปล่าchannel_idใช้สำหรับการสื่อสารข้ามโมดูล: เฉพาะall-gatherการดำเนินการที่มีchannel_idเดียวกันเท่านั้นที่จะสื่อสารกันได้
รูปร่างเอาต์พุตคือรูปร่างอินพุตที่มี all_gather_dim ทำให้มีขนาดใหญ่ขึ้น shard_count เท่า ตัวอย่างเช่น หากมีรีเพลซิคา 2 รายการและโอเปอเรนด์มีค่า [1.0, 2.5] และ [3.0, 5.25] ในรีเพลซิคา 2 รายการดังกล่าวตามลำดับ ค่าเอาต์พุตจากการดำเนินการนี้เมื่อ all_gather_dim เป็น 0 จะเท่ากับ [1.0, 2.5, 3.0,
5.25] ในรีเพลซิคาทั้ง 2 รายการ
AllReduce
ดู XlaBuilder::AllReduce เพิ่มเติม
ดำเนินการคํานวณที่กําหนดเองในข้อมูลจำลอง
AllReduce(operand, computation, replica_group_ids, channel_id)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand
|
XlaOp
|
อาร์เรย์หรือทูเปิลของอาร์เรย์ที่ไม่ใช่ค่าว่างเพื่อลดจำนวนในข้อมูลจำลอง |
computation |
XlaComputation |
การคำนวณการลด |
replica_groups
|
เวกเตอร์ของเวกเตอร์ของ int64 |
กลุ่มที่มีการดำเนินการลดขนาด |
channel_id
|
ไม่บังคับ int64
|
รหัสแชแนลที่ไม่บังคับสําหรับการสื่อสารข้ามโมดูล |
- เมื่อ
operandเป็นอาร์เรย์ของ Tuple การลดลงทั้งหมดจะเกิดขึ้นกับองค์ประกอบแต่ละรายการของ Tuple replica_groupsคือรายการกลุ่มข้อมูลจำลองที่จะทำการลด (เรียกดูรหัสข้อมูลจำลองปัจจุบันได้โดยใช้ReplicaId)replica_groupsต้องว่างเปล่า (ในกรณีที่ข้อมูลจำลองทั้งหมดอยู่ในกลุ่มเดียว) หรือมีจำนวนองค์ประกอบเท่ากับจำนวนข้อมูลจำลอง เช่นreplica_groups = {0, 2}, {1, 3}จะลดข้อมูลของตัวจำลอง0และ2และ1และ3channel_idใช้สำหรับการสื่อสารข้ามโมดูล: เฉพาะall-reduceการดำเนินการที่มีchannel_idเดียวกันเท่านั้นที่จะสื่อสารกันได้
รูปร่างเอาต์พุตจะเหมือนกับรูปร่างอินพุต ตัวอย่างเช่น หากมีรีเพลซิคา 2 ชุดและโอเปอเรนด์มีค่า [1.0, 2.5] และ [3.0, 5.25] ตามลำดับในรีเพลซิคา 2 ชุด ค่าเอาต์พุตจากการดำเนินการนี้และการคํานวณผลรวมจะเป็น [4.0, 7.75] ในรีเพลซิคาทั้ง 2 ชุด หากอินพุตเป็นลิสต์ ผลลัพธ์ก็จะเป็นลิสต์ด้วย
การคํานวณผลลัพธ์ของ AllReduce ต้องใช้อินพุต 1 รายการจากรีพลิคาแต่ละรายการ ดังนั้นหากรีพลิคาหนึ่งเรียกใช้โหนด AllReduce มากกว่าอีกรีพลิคาหนึ่ง รีพลิคาแรกจะรอตลอดไป เนื่องจากรีเพลซิเคิลทั้งหมดทำงานบนโปรแกรมเดียวกัน จึงมีวิธีไม่มากนักที่เหตุการณ์นี้จะเกิดขึ้น แต่อาจเกิดขึ้นได้เมื่อเงื่อนไขของ while loop ขึ้นอยู่กับข้อมูลจากฟีดข้อมูล และข้อมูลฟีดข้อมูลทําให้ while loop วนซ้ำในรีเพลซิเคิลหนึ่งมากกว่าอีกรีเพลซิเคิลหนึ่ง
AllToAll
โปรดดูXlaBuilder::AllToAll
AllToAll เป็นการดำเนินการแบบรวมที่ส่งข้อมูลจากทุกแกนไปยังทุกแกน โดยแบ่งออกเป็น 2 ระยะ ดังนี้
- ระยะกระจาย ในแต่ละแกน ตัวถูกดำเนินการจะแบ่งออกเป็น
split_countจำนวนบล็อกตามsplit_dimensionsและบล็อกกระจายไปยังทุกแกน เช่น มีการส่งบล็อก Ith ไปยังแกน I/X - ขั้นตอนการรวบรวม แต่ละแกนจะต่อบล็อกที่ได้รับตาม
concat_dimension
แกนที่เข้าร่วมสามารถกำหนดค่าได้โดย:
replica_groups: กลุ่มจำลองแต่ละกลุ่มมีรายการรหัสตัวจำลองที่เข้าร่วมในการคำนวณ (คุณเรียกดูรหัสตัวจำลองปัจจุบันได้โดยใช้ReplicaId) ระบบจะใช้ AllToAll ภายในกลุ่มย่อยตามลำดับที่ระบุ เช่นreplica_groups = { {1,2,3}, {4,5,0} }หมายความว่าจะใช้ AllToAll ภายในแบบจำลอง{1, 2, 3}และในระยะรวบรวม และระบบจะต่อบล็อกที่ได้รับตามลําดับเดียวกัน 1, 2, 3 จากนั้นระบบจะใช้ AllToAll อื่นภายในการจำลอง 4, 5, 0 และลําดับการต่อท้ายจะเป็น 4, 5, 0 ด้วย หากreplica_groupsว่างเปล่า รีเพลซิกาทั้งหมดจะอยู่ในกลุ่มเดียวตามลําดับการต่อท้ายของลักษณะที่ปรากฏ
สิ่งที่ต้องมีก่อน
- ขนาดมิติข้อมูลของตัวถูกดำเนินการใน
split_dimensionหารด้วยsplit_count - รูปร่างของออพอเรนดไม่ใช่ทูเปิล
AllToAll(operand, split_dimension, concat_dimension, split_count,
replica_groups)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์อินพุต n มิติ |
split_dimension
|
int64
|
ค่าในช่วง [0,
n) ที่ใช้ตั้งชื่อมิติข้อมูลซึ่งจะแบ่งโอเปอเรนด |
concat_dimension
|
int64
|
ค่าในช่วง [0,
n) ที่ชื่อมิติข้อมูลพร้อมกับการแยกบล็อกที่เชื่อมต่อกัน |
split_count
|
int64
|
จำนวนแกนประมวลผลที่เข้าร่วมการดำเนินการนี้ หาก replica_groups ว่างเปล่า ค่านี้ควรเป็นจำนวนตัวจำลอง มิเช่นนั้น ค่านี้ควรเท่ากับจำนวนตัวจำลองในแต่ละกลุ่ม |
replica_groups
|
ReplicaGroup เวกเตอร์
|
แต่ละกลุ่มจะประกอบด้วยรายการ รหัสการจำลอง |
ด้านล่างแสดงตัวอย่าง Alltoall
XlaBuilder b("alltoall");
auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {4, 16}), "x");
AllToAll(x, /*split_dimension=*/1, /*concat_dimension=*/0, /*split_count=*/4);
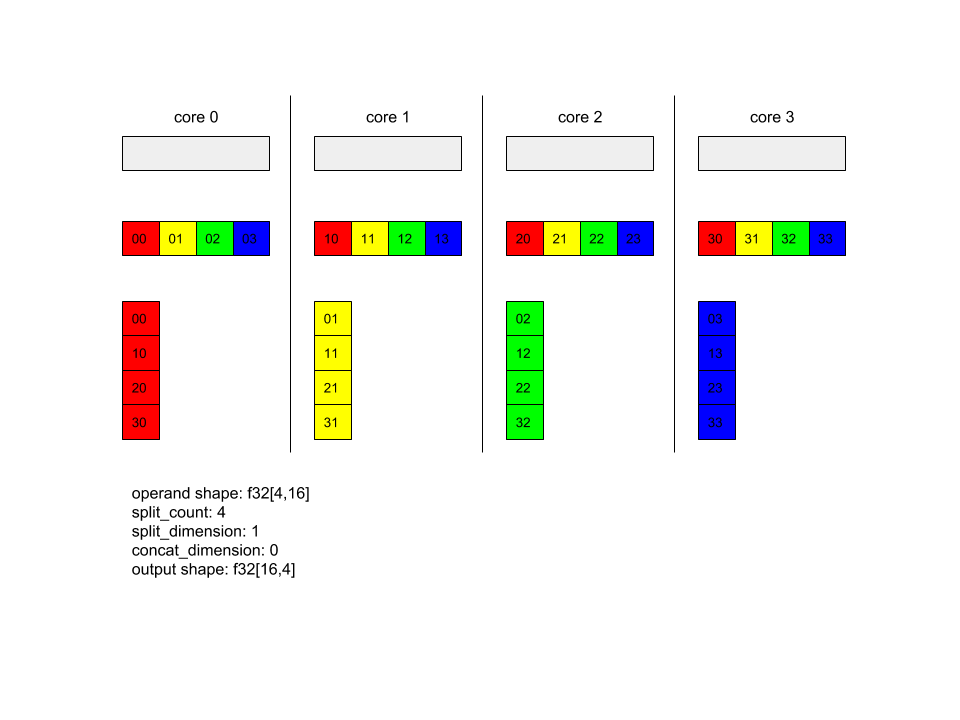
ในตัวอย่างนี้ มี 4 แกนประมวลผลที่เข้าร่วม Alltoall ในแต่ละแกน ตัวแปรจะแบ่งออกเป็น 4 ส่วนตามมิติข้อมูล 0 ดังนั้นแต่ละส่วนจะมีรูปร่างเป็น f32[4,4] โดยระบบจะกระจาย 4 ส่วนไปยังทุกแกน จากนั้นแต่ละแกนจะเชื่อมส่วนที่ได้รับเข้าด้วยกันตามมิติที่ 1 ตามลำดับของแกน 0-4 ดังนั้นเอาต์พุตในแต่ละแกนจะมีรูปร่างเป็น f32[16,4]
BatchNormGrad
ดูคำอธิบายโดยละเอียดของอัลกอริทึมได้ที่
XlaBuilder::BatchNormGrad
และบทความฉบับต้นฉบับเกี่ยวกับการปรับมาตรฐานกลุ่ม
คำนวณการไล่ระดับสีของบรรทัดฐานกลุ่ม
BatchNormGrad(operand, scale, mean, variance, grad_output, epsilon, feature_index)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ n มิติที่จะนอร์มาไลซ์ (x) |
scale |
XlaOp |
อาร์เรย์มิติข้อมูล 1 รายการ (γ) |
mean |
XlaOp |
อาร์เรย์ 1 มิติ (μ) |
variance |
XlaOp |
อาร์เรย์มิติข้อมูล 1 รายการ (σ2) |
grad_output |
XlaOp |
การไล่ระดับสีที่ส่งไปยัง BatchNormTraining (∇y) |
epsilon |
float |
ค่า Epsilon (ϵ) |
feature_index |
int64 |
ดัชนีไปยังมิติข้อมูลฟีเจอร์ใน operand |
สําหรับฟีเจอร์แต่ละรายการในมิติข้อมูลฟีเจอร์ (feature_index คือดัชนีสําหรับมิติข้อมูลฟีเจอร์ใน operand) การดำเนินการจะคํานวณอนุพันธ์ของ operand, offset และ scale ในมิติข้อมูลอื่นๆ ทั้งหมด feature_index ต้องเป็นดัชนีที่ถูกต้องของมิติข้อมูลฟีเจอร์ใน operand
สูตรต่อไปนี้จะกำหนดการเปลี่ยนแปลงเชิงกริด 3 รายการ (สมมติว่าอาร์เรย์ 4 มิติคือ operand และมีดัชนีมิติข้อมูลฟีเจอร์ l, ขนาดกลุ่ม m และขนาดเชิงพื้นที่ w และ h)
cl=1mwhm∑i=1w∑j=1h∑k=1(∇yijklxijkl−μlσ2l+ϵ)dl=1mwhm∑i=1w∑j=1h∑k=1∇yijkl∇xijkl=γl√σ2l+ϵ(∇yijkl−dl−cl(xijkl−μl))∇γl=m∑i=1w∑j=1h∑k=1(∇yijklxijkl−μl√σ2l+ϵ) ∇βl=m∑i=1w∑j=1h∑k=1∇yijkl
อินพุต mean และ variance แทนค่าช่วงเวลาในมิติข้อมูลแบบกลุ่มและพื้นที่
ประเภทเอาต์พุตคือทูเปิลของแฮนเดิล 3 รายการ ดังนี้
| เอาต์พุต | ประเภท | ความหมาย |
|---|---|---|
grad_operand
|
XlaOp
|
อนุพันธ์เทียบกับอินพุต operand (∇x) |
grad_scale
|
XlaOp
|
อนุพันธ์เทียบกับอินพุต scale (∇γ) |
grad_offset
|
XlaOp
|
การไล่ระดับสีตามอินพุต offset(∇β) |
BatchNormInference
ดูคำอธิบายโดยละเอียดของอัลกอริทึมได้ที่
XlaBuilder::BatchNormInference
และบทความฉบับต้นฉบับเกี่ยวกับการปรับมาตรฐานกลุ่ม
ปรับอาร์เรย์มาตรฐานในมิติข้อมูลแบบกลุ่มและพื้นที่เชิงพื้นที่
BatchNormInference(operand, scale, offset, mean, variance, epsilon, feature_index)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ n มิติที่จะปรับให้เป็นปกติ |
scale |
XlaOp |
อาร์เรย์มิติข้อมูล 1 รายการ |
offset |
XlaOp |
อาร์เรย์มิติข้อมูล 1 รายการ |
mean |
XlaOp |
อาร์เรย์มิติข้อมูล 1 รายการ |
variance |
XlaOp |
อาร์เรย์มิติข้อมูล 1 รายการ |
epsilon |
float |
ค่า Epsilon |
feature_index |
int64 |
ดัชนีไปยังมิติข้อมูลฟีเจอร์ใน operand |
สำหรับแต่ละฟีเจอร์ในมิติข้อมูลฟีเจอร์ (feature_index คือดัชนีสำหรับมิติข้อมูลฟีเจอร์ใน operand) การดำเนินการจะคำนวณค่าเฉลี่ยและความแปรปรวนสำหรับมิติข้อมูลอื่นๆ ทั้งหมดและใช้ค่าเฉลี่ยและความแปรปรวนเพื่อปรับองค์ประกอบแต่ละรายการใน operand ให้เป็นมาตรฐาน feature_index ต้องเป็นดัชนีที่ถูกต้องของมิติข้อมูลฟีเจอร์ใน operand
BatchNormInference เทียบเท่ากับการเรียกใช้ BatchNormTraining โดยไม่คำนวณ mean และ variance สำหรับแต่ละกลุ่ม แต่จะใช้เป็นค่าโดยประมาณแทนโดยจะใช้ค่าอินพุต mean และ
variance วัตถุประสงค์ของกระบวนการนี้คือการลดเวลาในการตอบสนองในการอนุมาน จึงมีชื่อว่า BatchNormInference
เอาต์พุตคืออาร์เรย์ n มิติที่แปลงเป็นรูปแบบมาตรฐานซึ่งมีรูปร่างเหมือนกับอินพุต
operand
BatchNormTraining
ดูคำอธิบายโดยละเอียดของอัลกอริทึมได้ที่ XlaBuilder::BatchNormTraining และ the original batch normalization paper
ปรับมาตรฐานอาร์เรย์ในมิติข้อมูลกลุ่มและมิติข้อมูลเชิงพื้นที่
BatchNormTraining(operand, scale, offset, epsilon, feature_index)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ n มิติที่จะนอร์มาไลซ์ (x) |
scale |
XlaOp |
อาร์เรย์ 1 มิติ (γ) |
offset |
XlaOp |
อาร์เรย์มิติข้อมูล 1 รายการ (β) |
epsilon |
float |
ค่า Epsilon (ϵ) |
feature_index |
int64 |
ดัชนีไปยังมิติข้อมูลฟีเจอร์ใน operand |
สําหรับฟีเจอร์แต่ละรายการในมิติข้อมูลฟีเจอร์ (feature_index คือดัชนีสําหรับมิติข้อมูลฟีเจอร์ใน operand) การดำเนินการจะคํานวณค่าเฉลี่ยและความแปรปรวนในมิติข้อมูลอื่นๆ ทั้งหมด และใช้ค่าเฉลี่ยและความแปรปรวนเพื่อทำให้องค์ประกอบแต่ละรายการใน operand เป็นมาตรฐาน feature_index ต้องเป็นดัชนีที่ถูกต้องสำหรับมิติข้อมูลฟีเจอร์ใน operand
อัลกอริทึมทำงานดังนี้สำหรับแต่ละกลุ่มใน operand x ที่มี m องค์ประกอบที่มี w และ h เป็นขนาดของมิติข้อมูลเชิงพื้นที่ (สมมติว่า operand เป็นอาร์เรย์ 4 มิติ)
คำนวณค่าเฉลี่ยแบบกลุ่ม μl สำหรับแต่ละฟีเจอร์
lในมิติข้อมูลฟีเจอร์ ดังนี้ μl=1mwh∑mi=1∑wj=1∑hk=1xijklคำนวณความแปรปรวนแบบกลุ่ม σ2l: $\sigma^2l=\frac{1}{mwh}\sum{i=1}^m\sum{j=1}^w\sum{k=1}^h (x_{ijkl} - \mu_l)^2$
ปรับให้เป็นมาตรฐาน ปรับขนาด และเลื่อนค่าต่อไปนี้ yijkl=γl(xijkl−μl)2√σ2l+ϵ+βl
ระบบจะเพิ่มค่า epsilon จำนวนน้อยเพื่อหลีกเลี่ยงข้อผิดพลาดการหารด้วยศูนย์
ประเภทเอาต์พุตคือ Tuple ที่มี XlaOps 3 รายการ ดังนี้
| เอาต์พุต | ประเภท | ความหมาย |
|---|---|---|
output
|
XlaOp
|
อาร์เรย์ n มิติที่มีรูปร่างเหมือนกับอินพุต
operand (y) |
batch_mean |
XlaOp |
อาร์เรย์ 1 มิติ (μ) |
batch_var |
XlaOp |
อาร์เรย์ 1 มิติ (σ2) |
batch_mean และ batch_var คือช่วงเวลาที่คำนวณจากมิติข้อมูลกลุ่มและมิติข้อมูลเชิงพื้นที่โดยใช้สูตรด้านบน
BitcastConvertType
โปรดดูXlaBuilder::BitcastConvertType
คล้ายกับ tf.bitcast ใน TensorFlow โดยจะดำเนินการบิตแคสต์ทีละองค์ประกอบจากรูปแบบข้อมูลไปยังรูปแบบเป้าหมาย ขนาดอินพุตและเอาต์พุตต้องตรงกัน เช่น องค์ประกอบ s32 กลายเป็นองค์ประกอบ f32 ผ่านกิจวัตรบิตแคสต์ และองค์ประกอบ s32 1 รายการจะกลายเป็นองค์ประกอบ s8 4 รายการ ระบบจะใช้การแคสต์แบบบิตเป็นแคสต์ระดับต่ำ ดังนั้นเครื่องที่มีการแสดงผลทศนิยมแบบต่างๆ จึงให้ผลลัพธ์ที่แตกต่างกัน
BitcastConvertType(operand, new_element_type)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ประเภท T ที่มีมิติข้อมูล D |
new_element_type |
PrimitiveType |
ประเภท U |
มิติข้อมูลของออพอเรนดและรูปร่างเป้าหมายต้องตรงกัน ยกเว้นมิติข้อมูลสุดท้ายที่จะเปลี่ยนแปลงตามสัดส่วนขนาดพื้นฐานก่อนและหลังการแปลง
ประเภทองค์ประกอบต้นทางและปลายทางต้องไม่ใช่ทูเพลต
การแปลงแบบบิตแคสต์เป็นประเภทพื้นฐานที่มีความกว้างต่างกัน
BitcastConvert คำสั่ง HLO รองรับกรณีที่ขนาดของประเภทองค์ประกอบเอาต์พุต T' ไม่เท่ากับขนาดขององค์ประกอบอินพุต T เนื่องจากการดำเนินการทั้งหมดเป็นแนวคิดเรื่องบิตแคสต์และจะไม่เปลี่ยนแปลงไบต์ที่อยู่เบื้องหลัง รูปร่างขององค์ประกอบเอาต์พุตจึงต้องเปลี่ยนแปลง สำหรับ B = sizeof(T), B' =
sizeof(T') อาจมี 2 กรณีดังนี้
ขั้นแรก เมื่อ B > B' รูปร่างเอาต์พุตจะได้รับมิติข้อมูลย่อยสุดใหม่ขนาด
B/B' เช่น
f16[10,2]{1,0} %output = f16[10,2]{1,0} bitcast-convert(f32[10]{0} %input)
กฎจะยังคงเหมือนเดิมสำหรับสเกลาร์ที่มีประสิทธิภาพ ดังนี้
f16[2]{0} %output = f16[2]{0} bitcast-convert(f32[] %input)
หรือสำหรับ B' > B คำสั่งกำหนดให้มิติข้อมูลเชิงตรรกะสุดท้ายของรูปแบบอินพุตต้องเท่ากับ B'/B และระบบจะทิ้งมิติข้อมูลนี้ระหว่างการเปลี่ยนรูปแบบ
f32[10]{0} %output = f32[10]{0} bitcast-convert(f16[10,2]{1,0} %input)
โปรดทราบว่าการแปลงระหว่างบิตความกว้างที่ต่างกันจะไม่ใช่องค์ประกอบ
ประกาศ
โปรดดูXlaBuilder::Broadcast
เพิ่มมิติข้อมูลลงในอาร์เรย์โดยการทําซ้ำข้อมูลในอาร์เรย์
Broadcast(operand, broadcast_sizes)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ที่จะทำซ้ำ |
broadcast_sizes |
ArraySlice<int64> |
ขนาดของมิติข้อมูลใหม่ |
ระบบจะแทรกมิติข้อมูลใหม่ทางด้านซ้าย เช่น หาก broadcast_sizes มีค่า {a0, ..., aN} และรูปร่างของโอเปอเรนด์มีขนาด {b0, ..., bM} รูปร่างของเอาต์พุตจะมีขนาด {a0, ..., aN, b0, ..., bM}
ดัชนีมิติข้อมูลใหม่เป็นสำเนาของตัวถูกดำเนินการ เช่น
output[i0, ..., iN, j0, ..., jM] = operand[j0, ..., jM]
เช่น หาก operand เป็น f32 สเกลาร์ที่มีค่า 2.0f และ broadcast_sizes คือ {2, 3} ผลลัพธ์จะเป็นอาร์เรย์ที่มีรูปร่าง f32[2, 3] และค่าทั้งหมดในผลลัพธ์จะเป็น 2.0f
BroadcastInDim
โปรดดูXlaBuilder::BroadcastInDim
ขยายขนาดและอันดับของอาร์เรย์โดยการทำซ้ำข้อมูลในอาร์เรย์
BroadcastInDim(operand, out_dim_size, broadcast_dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ที่จะทำซ้ำ |
out_dim_size |
ArraySlice<int64> |
ขนาดของมิติข้อมูลของรูปร่างเป้าหมาย |
broadcast_dimensions |
ArraySlice<int64> |
มิติข้อมูลในรูปร่างเป้าหมายที่สอดคล้องกับมิติข้อมูลแต่ละรายการของรูปร่างโอเปอเรนด์ |
คล้ายกับ "การออกอากาศ" แต่อนุญาตให้เพิ่มมิติข้อมูลได้ทุกที่และขยายมิติข้อมูลที่มีอยู่ซึ่งมีขนาด 1
ระบบจะออกอากาศ operand ไปยังรูปร่างที่อธิบายโดย out_dim_size
broadcast_dimensions จะจับคู่มิติข้อมูลของ operand กับมิติข้อมูลของรูปแบบเป้าหมาย กล่าวคือ ระบบจะจับคู่มิติข้อมูลลำดับที่ i ของโอเปอเรนด์กับมิติข้อมูลลำดับที่ broadcast_dimension[i] ของรูปแบบเอาต์พุต มิติข้อมูลของ operand ต้องมีขนาด 1 หรือมีขนาดเท่ากับมิติข้อมูลในรูปร่างเอาต์พุตที่แมปไว้ ขนาดที่เหลือจะแสดงด้วยมิติของขนาด 1 จากนั้นการออกอากาศมิติข้อมูลที่ยุบแล้วจะออกอากาศไปตามมิติข้อมูลที่ยุบเหล่านี้เพื่อเข้าถึงรูปร่างเอาต์พุต การอธิบายความหมายโดยละเอียดในหน้าการออกอากาศ
โทร
โปรดดูXlaBuilder::Call
เรียกใช้การคํานวณด้วยอาร์กิวเมนต์ที่ระบุ
Call(computation, args...)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
computation |
XlaComputation |
การคํานวณประเภท T_0, T_1, ..., T_{N-1} -> S ที่มีพารามิเตอร์ N ประเภทใดก็ได้ |
args |
ลำดับ XlaOp จำนวน N |
อาร์กิวเมนต์ N รายการของประเภทใดก็ได้ |
ความสมจริงและประเภทของ args ต้องตรงกับพารามิเตอร์ของ computation อนุญาตให้ไม่มี args
Cholesky
โปรดดูXlaBuilder::Cholesky
คํานวณการสลาย Cholesky ของเมทริกซ์สมมาตร (เฮอร์มิเทียน) ที่แน่นอนเชิงบวกหลายรายการ
Cholesky(a, lower)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
a |
XlaOp |
อาร์เรย์ที่มีลําดับมากกว่า 2 ประเภทจํานวนเชิงซ้อนหรือทศนิยม |
lower |
bool |
จะใช้สามเหลี่ยมด้านบนหรือด้านล่างของ a |
หาก lower คือ true ให้คำนวณเมทริกซ์สามเหลี่ยมด้านล่าง l จะได้ a=llT หาก lower คือ false ให้คำนวณเมทริกซ์สามเหลี่ยมด้านบน u โดยใช้ค่าที่ได้a=uT.u
ระบบจะอ่านข้อมูลอินพุตจากสามเหลี่ยมด้านล่าง/ด้านบนของ a เท่านั้น โดยขึ้นอยู่กับค่าของ lower ระบบจะไม่สนใจค่าจากรูปสามเหลี่ยมอื่น ระบบจะแสดงผลข้อมูลเอาต์พุตในสามเหลี่ยมเดียวกัน ส่วนค่าในสามเหลี่ยมอื่นจะกำหนดตามการใช้งานและอาจเป็นค่าใดก็ได้
หากอันดับของ a มากกว่า 2 ระบบจะถือว่า a เป็นกลุ่มเมทริกซ์ โดยทั้งหมดยกเว้นมิติข้อมูลย่อย 2 รายการจะเป็นมิติข้อมูลกลุ่ม
หาก a ไม่ใช่สมมาตร (เฮอร์มิเทียน) และแน่นอนเชิงบวก ผลลัพธ์จะขึ้นอยู่กับการใช้งาน
แบบมีตัวหนีบ
โปรดดูXlaBuilder::Clamp
จำกัดตัวดำเนินการให้อยู่ในช่วงระหว่างค่าต่ำสุดและสูงสุด
Clamp(min, operand, max)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
min |
XlaOp |
อาร์เรย์ประเภท T |
operand |
XlaOp |
อาร์เรย์ประเภท T |
max |
XlaOp |
อาร์เรย์ของประเภท T |
เมื่อได้รับโอเปอเรนดและค่าต่ำสุดและสูงสุด ระบบจะแสดงผลโอเปอเรนดหากอยู่ในช่วงระหว่างค่าต่ำสุดและสูงสุด มิเช่นนั้นระบบจะแสดงผลค่าต่ำสุดหากโอเปอเรนดอยู่ต่ำกว่าช่วงนี้ หรือแสดงผลค่าสูงสุดหากโอเปอเรนดอยู่สูงกว่าช่วงนี้ นั่นคือ clamp(a, x, b) = min(max(a, x), b)
อาร์เรย์ทั้ง 3 รายการต้องเป็นทรงเดียวกัน หรือในฐานะรูปแบบที่จำกัดของการออกอากาศ min และ/หรือ max อาจเป็นสเกลาร์ของประเภท T ก็ได้
ตัวอย่างที่ใช้ Scalar min และ max
let operand: s32[3] = {-1, 5, 9};
let min: s32 = 0;
let max: s32 = 6;
==>
Clamp(min, operand, max) = s32[3]{0, 5, 6};
ยุบ
โปรดดูหัวข้อ
XlaBuilder::Collapse
และการดำเนินการ tf.reshape ด้วย
ยุบมิติข้อมูลของอาร์เรย์เป็นมิติข้อมูลเดียว
Collapse(operand, dimensions)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ประเภท T |
dimensions |
int64 เวกเตอร์ |
ชุดย่อยตามลําดับของมิติข้อมูล T ที่เรียงต่อกัน |
การยุบจะแทนที่มิติข้อมูลย่อยของออพอเรนดด้วยมิติข้อมูลเดียว อาร์กิวเมนต์อินพุตคืออาร์เรย์ประเภท T ที่กำหนดเองและเวกเตอร์ของดัชนีมิติข้อมูลที่มีค่าคงที่ในเวลาคอมไพล์ ดัชนีมิติข้อมูลต้องเรียงตามลําดับ (ตัวเลขมิติข้อมูลจากต่ำไปสูง) ซึ่งเป็นชุดย่อยที่ต่อเนื่องกันของมิติข้อมูลของ T ดังนั้น {0, 1, 2}, {0, 1} หรือ {1, 2} คือชุดมิติข้อมูลที่ถูกต้องทั้งหมด แต่
{1, 0} หรือ {0, 2} ไม่ใช่ ระบบจะแทนที่มิติข้อมูลเหล่านั้นด้วยมิติข้อมูลใหม่รายการเดียวในตําแหน่งเดียวกันในลําดับมิติข้อมูลเดียวกับที่แทนที่ โดยขนาดมิติข้อมูลใหม่จะเท่ากับผลคูณของขนาดมิติข้อมูลเดิม ตัวเลขมิติข้อมูลต่ำสุดใน dimensions คือมิติข้อมูลที่เปลี่ยนแปลงช้าที่สุด (สำคัญที่สุด) ในเนสต์ลูปที่ยุบมิติข้อมูลเหล่านี้ และตัวเลขมิติข้อมูลสูงสุดคือมิติข้อมูลที่เปลี่ยนแปลงเร็วที่สุด (สำคัญน้อยที่สุด) ดูโอเปอเรเตอร์ tf.reshape หากต้องการการเรียงลําดับการยุบทั่วไปเพิ่มเติม
ตัวอย่างเช่น ให้ v เป็นอาร์เรย์ขององค์ประกอบ 24 ดังนี้
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
// Collapse to a single dimension, leaving one dimension.
let v012 = Collapse(v, {0,1,2});
then v012 == f32[24] {10, 11, 12, 15, 16, 17,
20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37,
40, 41, 42, 45, 46, 47};
// Collapse the two lower dimensions, leaving two dimensions.
let v01 = Collapse(v, {0,1});
then v01 == f32[4x6] { {10, 11, 12, 15, 16, 17},
{20, 21, 22, 25, 26, 27},
{30, 31, 32, 35, 36, 37},
{40, 41, 42, 45, 46, 47} };
// Collapse the two higher dimensions, leaving two dimensions.
let v12 = Collapse(v, {1,2});
then v12 == f32[8x3] { {10, 11, 12},
{15, 16, 17},
{20, 21, 22},
{25, 26, 27},
{30, 31, 32},
{35, 36, 37},
{40, 41, 42},
{45, 46, 47} };
CollectivePermute
ดู XlaBuilder::CollectivePermute เพิ่มเติม
CollectivePermute เป็นการดำเนินการแบบรวมที่ส่งและรับข้อมูลข้ามข้อมูลจำลอง
CollectivePermute(operand, source_target_pairs)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์อินพุต n มิติ |
source_target_pairs |
<int64, int64> เวกเตอร์ |
รายการคู่ (source_replica_id, target_replica_id) ระบบจะส่งโอเปอเรนด์จากรีพลิคาต้นทางไปยังรีพลิคาปลายทางสำหรับแต่ละคู่ |
โปรดทราบว่า source_target_pair มีข้อจำกัดดังต่อไปนี้
- คู่ใดคู่หนึ่งไม่ควรมีรหัสตัวจำลองเป้าหมายเดียวกัน และไม่ควรมีรหัสตัวจำลองต้นทางเดียวกัน
- หากรหัสของข้อมูลจำลองไม่ใช่เป้าหมายในคู่ใดๆ เอาต์พุตในข้อมูลจำลองนั้นจะเป็นเทนเซอร์ที่มีค่า 0 อยู่ในรูปแบบเดียวกับอินพุต
ต่อ
โปรดดูXlaBuilder::ConcatInDim
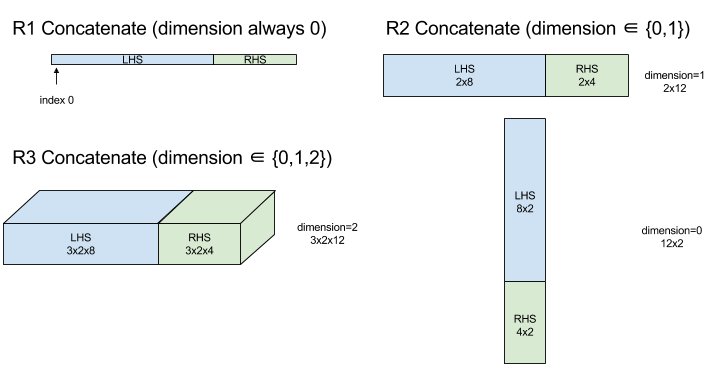
Concatenate จะสร้างอาร์เรย์จากอาร์เรย์ออบเจ็กต์หลายรายการ อาร์เรย์มีอันดับเดียวกับตัวถูกดำเนินการของอาร์เรย์อินพุตแต่ละรายการ (ซึ่งต้องมีอันดับเดียวกัน) และมีอาร์กิวเมนต์ตามลำดับที่ระบุไว้
Concatenate(operands..., dimension)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operands |
ลำดับ N XlaOp |
N อาร์เรย์ของประเภท T ที่มีขนาด [L0, L1, ...] ต้องระบุ N >= 1 |
dimension |
int64 |
ค่าในช่วง [0, N) ที่ชื่อมิติข้อมูลที่จะเชื่อมต่อกันระหว่าง operands |
มิติข้อมูลทั้งหมดต้องเหมือนกัน ยกเว้น dimension เนื่องจาก XLA ไม่รองรับอาร์เรย์ที่ "ไม่มีสัญญาณ" และโปรดทราบว่าค่าอันดับ 0 นั้นไม่สามารถต่อกัน (เนื่องจากตั้งชื่อมิติข้อมูลที่เกิดการเชื่อมต่อไม่ได้)
ตัวอย่างแบบ 1 มิติ
Concat({ {2, 3}, {4, 5}, {6, 7} }, 0)
>>> {2, 3, 4, 5, 6, 7}
ตัวอย่าง 2 มิติ
let a = {
{1, 2},
{3, 4},
{5, 6},
};
let b = {
{7, 8},
};
Concat({a, b}, 0)
>>> {
{1, 2},
{3, 4},
{5, 6},
{7, 8},
}
แผนภาพ:
มีเงื่อนไข
ดู XlaBuilder::Conditional เพิ่มเติม
Conditional(pred, true_operand, true_computation, false_operand,
false_computation)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
pred |
XlaOp |
สเกลาร์ประเภท PRED |
true_operand |
XlaOp |
อาร์กิวเมนต์ประเภท T0 |
true_computation |
XlaComputation |
XlaComputation ประเภท T0→S |
false_operand |
XlaOp |
อาร์กิวเมนต์ประเภท T1 |
false_computation |
XlaComputation |
XlaComputation ของประเภท T1→S |
ดำเนินการ true_computation หาก pred คือ true false_computation หาก pred เป็น false และแสดงผลลัพธ์
true_computation ต้องใช้อาร์กิวเมนต์ประเภท T0 เพียงรายการเดียว และจะเรียกใช้ด้วย true_operand ซึ่งต้องเป็นประเภทเดียวกัน false_computation ต้องรับอาร์กิวเมนต์ประเภท T1 รายการเดียว และจะเรียกใช้ด้วย false_operand ที่เป็นประเภทเดียวกัน ประเภทของค่าที่ส่งกลับของ true_computation และ false_computation ต้องเหมือนกัน
โปรดทราบว่าระบบจะเรียกใช้ true_computation และ false_computation เพียงรายการเดียวเท่านั้นโดยขึ้นอยู่กับค่าของ pred
Conditional(branch_index, branch_computations, branch_operands)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
branch_index |
XlaOp |
สเกลาร์ประเภท S32 |
branch_computations |
ลำดับของ N XlaComputation |
XlaComputations ของประเภท T0→S,T1→S,...,TN−1→S |
branch_operands |
ลำดับของ N XlaOp |
อาร์กิวเมนต์ของประเภท T0,T1,...,TN−1 |
เรียกใช้ branch_computations[branch_index] และแสดงผลลัพธ์ หาก branch_index เป็น S32 ที่น้อยกว่า 0 หรือมากกว่าหรือเท่ากับ N ระบบจะเรียกใช้ branch_computations[N-1] เป็นสาขาเริ่มต้น
branch_computations[b] แต่ละรายการต้องรับอาร์กิวเมนต์ประเภท Tb รายการเดียว และเรียกใช้ด้วย branch_operands[b] ที่เป็นประเภทเดียวกัน ประเภทของค่าที่แสดงผลของ branch_computations[b] แต่ละรายการต้องเหมือนกัน
โปรดทราบว่าระบบจะเรียกใช้ branch_computations เพียงรายการเดียวเท่านั้นโดยขึ้นอยู่กับค่าของ branch_index
Conv. (มูลค่า Conversion)
โปรดดูXlaBuilder::Conv
เหมือนกับ ConvWithGeneralPadding แต่มีการระบุการเติมเต็มด้วยวิธีสั้นๆ ว่า SAME หรือ VALID SAME padding จะเติมค่า 0 ลงในอินพุต (lhs) เพื่อให้เอาต์พุตมีรูปร่างเหมือนกับอินพุตเมื่อไม่คำนึงถึงการแบ่งกลุ่ม การป้อนข้อมูลข้างต้นที่ถูกต้องหมายความว่าไม่มีการป้อนข้อมูลข้างต้น
ConvWithGeneralPadding (Convolution)
ดู XlaBuilder::ConvWithGeneralPadding เพิ่มเติม
คํานวณการฟัซชันประเภทที่ใช้ในโครงข่ายประสาทเทียม ในที่นี้ การฟัซซิชันจะเปรียบเสมือนกรอบ n มิติที่เลื่อนไปทั่วพื้นที่ฐาน n มิติ และระบบจะดำเนินการคํานวณสําหรับตําแหน่งต่างๆ ที่เป็นไปได้ของกรอบ
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
lhs |
XlaOp |
จัดอันดับอินพุต n+2 ตามลำดับ |
rhs |
XlaOp |
อาร์เรย์น้ำหนักของ Kernel ระดับ n+2 |
window_strides |
ArraySlice<int64> |
อาร์เรย์ n-d ของระยะก้าวของเคอร์เนล |
padding |
ArraySlice< pair<int64,int64>> |
อาร์เรย์ n มิติของระยะห่างจากขอบ (ต่ำ, สูง) |
lhs_dilation |
ArraySlice<int64> |
อาร์เรย์ปัจจัยการขยาย lhs n-d |
rhs_dilation |
ArraySlice<int64> |
อาร์เรย์ค่าตัวคูณการขยาย rhs n มิติ |
feature_group_count |
int64 | จำนวนกลุ่มฟีเจอร์ |
batch_group_count |
int64 | จํานวนกลุ่มการประมวลผลเป็นกลุ่ม |
กำหนดให้ n เป็นจํานวนมิติข้อมูลเชิงพื้นที่ อาร์กิวเมนต์ lhs คืออาร์เรย์อันดับ n+2 ที่อธิบายพื้นที่ฐาน การดำเนินการนี้เรียกว่าอินพุต แม้ว่า rhs จะเป็นอินพุตด้วย ในโครงข่ายประสาทเทียม ข้อมูลเหล่านี้คือการเปิดใช้งานอินพุต
มิติข้อมูล n+2 มีลําดับดังนี้
batch: พิกัดแต่ละรายการในมิติข้อมูลนี้แสดงอินพุตอิสระที่ใช้ดำเนินการฟิวชันคอนโวลูชันz/depth/features: ตำแหน่ง (y,x) แต่ละตำแหน่งในพื้นที่ฐานจะมีเวกเตอร์ที่เชื่อมโยงอยู่ ซึ่งจะเข้าสู่มิติข้อมูลนี้spatial_dims: อธิบายมิติข้อมูลเชิงพื้นที่nที่กำหนดพื้นที่ฐานที่หน้าต่างเลื่อนผ่าน
อาร์กิวเมนต์ rhs คืออาร์เรย์อันดับ n+2 ที่อธิบายตัวกรอง/Kernel/Window ของการแปลงคอนโวลูชัน มิติข้อมูลจะเรียงตามลำดับดังนี้
output-z: มิติข้อมูลzของเอาต์พุตinput-z: ขนาดของมิติข้อมูลนี้คูณด้วยfeature_group_countควรเท่ากับขนาดของมิติข้อมูลzใน lhsspatial_dims: อธิบายมิติข้อมูลเชิงพื้นที่nที่กำหนดหน้าต่าง n-d ที่เคลื่อนผ่านพื้นที่ฐาน
อาร์กิวเมนต์ window_strides จะระบุระยะห่างของหน้าต่างการกรองเชิงซ้อนในมิติข้อมูลเชิงพื้นที่ เช่น หากระยะก้าวในมิติข้อมูลเชิงพื้นที่แรกคือ 3 หน้าต่างจะวางได้ที่พิกัดที่ดัชนีเชิงพื้นที่แรกหารด้วย 3 ได้เท่านั้น
อาร์กิวเมนต์ padding จะระบุจำนวนการเติม 0 ที่จะนำไปใช้กับพื้นที่ฐาน จำนวนการเติมอาจเป็นค่าลบได้ ค่าสัมบูรณ์ของการเติมค่าลบจะระบุจํานวนองค์ประกอบที่จะนําออกจากมิติข้อมูลที่ระบุก่อนทำการฟิวชันคอนโวลูชัน padding[0] ระบุการเว้นวรรคสำหรับมิติข้อมูล y และ padding[1] ระบุการเว้นวรรคสำหรับมิติข้อมูล x แต่ละคู่จะมีระยะห่างจากขอบต่ำเป็นองค์ประกอบแรกและระยะห่างจากขอบสูงเป็นองค์ประกอบที่ 2 ระยะห่างจากขอบต่ำจะใช้กับดัชนีที่ต่ำกว่า ส่วนระยะห่างจากขอบสูงจะใช้กับดัชนีที่สูงกว่า เช่น หาก padding[1] เป็น (2,3) ระบบจะเพิ่มค่า 0 ทางด้านซ้าย 2 ตัว และทางด้านขวา 3 ตัวในมิติข้อมูลเชิงพื้นที่ที่ 2 การใช้ระยะห่างจากขอบจะเทียบเท่ากับการแทรกค่าศูนย์เดียวกันนี้ลงในอินพุต (lhs) ก่อนทำการคอนโวลูชัน (Convolution)
อาร์กิวเมนต์ lhs_dilation และ rhs_dilation จะระบุปัจจัยการขยายที่จะใช้กับ lhs และ rhs ตามลำดับเชิงพื้นที่แต่ละมิติข้อมูล ถ้าตัวประกอบการขยายในมิติข้อมูลเชิงพื้นที่คือ d รู d-1 จะถูกวางโดยปริยายระหว่างแต่ละรายการในมิติข้อมูลนั้น ซึ่งเป็นการเพิ่มขนาดของอาร์เรย์ ระบบจะเติมค่า No-Op ซึ่งหมายถึงค่า 0 สำหรับการฟัซชัน
การขยาย rhs เรียกอีกอย่างว่า Atrous Convolution ดูรายละเอียดเพิ่มเติมได้ที่ tf.nn.atrous_conv2d การขยาย LH เรียกอีกอย่างว่า Convolution
แบบสลับตำแหน่ง ดูรายละเอียดเพิ่มเติมได้ที่ tf.nn.conv2d_transpose
คุณใช้อาร์กิวเมนต์ feature_group_count (ค่าเริ่มต้น 1) กับการฟัซชันแบบกลุ่มได้ feature_group_count ต้องเป็นตัวหารของทั้งมิติข้อมูลฟีเจอร์อินพุตและเอาต์พุต หาก feature_group_count มากกว่า 1 หมายความว่าในเชิงแนวคิด มิติข้อมูลฟีเจอร์อินพุตและเอาต์พุต รวมถึงมิติข้อมูลฟีเจอร์เอาต์พุต rhs จะถูกแยกออกเป็นfeature_group_count กลุ่มเท่าๆ กัน โดยแต่ละกลุ่มประกอบด้วยลําดับย่อยของฟีเจอร์ที่ต่อเนื่องกัน มิติข้อมูลฟีเจอร์อินพุตของ rhs จะต้องเท่ากับมิติข้อมูลฟีเจอร์อินพุต lhs หารด้วย feature_group_count (เพื่อให้มีขนาดของกลุ่มฟีเจอร์อินพุตอยู่แล้ว) กลุ่ม i จะใช้ร่วมกันเพื่อคำนวณ feature_group_count สำหรับ Convolution ที่แยกกันหลายรายการ ระบบจะต่อผลลัพธ์ของการฟัซซิชันเหล่านี้เข้าด้วยกันในมิติข้อมูลฟีเจอร์เอาต์พุต
สําหรับการกรองเชิงลึก ระบบจะตั้งค่าอาร์กิวเมนต์ feature_group_count เป็นมิติข้อมูลฟีเจอร์อินพุต และเปลี่ยนรูปร่างตัวกรองจาก [filter_height, filter_width, in_channels, channel_multiplier] เป็น [filter_height, filter_width, 1, in_channels * channel_multiplier] ดูรายละเอียดเพิ่มเติมได้ที่ tf.nn.depthwise_conv2d
คุณใช้อาร์กิวเมนต์ batch_group_count (ค่าเริ่มต้น 1) สำหรับตัวกรองที่จัดกลุ่มในระหว่างการทำ Backpropagation ได้ batch_group_count ต้องเป็นตัวหารของขนาดมิติข้อมูลกลุ่ม lhs (อินพุต) หาก batch_group_count มากกว่า 1 แสดงว่ามิติข้อมูลกลุ่มเอาต์พุตควรมีขนาด input batch
/ batch_group_count batch_group_count ต้องเป็นตัวหารของขนาดฟีเจอร์เอาต์พุต
รูปร่างเอาต์พุตมีขนาดตามลำดับต่อไปนี้
batch: ขนาดของมิติข้อมูลนี้คูณด้วยbatch_group_countควรเท่ากับ ขนาดของมิติข้อมูลbatchใน lhsz: ขนาดเดียวกับoutput-zบนเคอร์เนล (rhs)spatial_dims: ค่า 1 ค่าสําหรับตําแหน่งหน้าต่างการกรองเชิงอนุมานที่ถูกต้องแต่ละรายการ

ภาพด้านบนแสดงการทำงานของฟิลด์ batch_group_count ในทางปฏิบัติแล้ว เราจะแบ่งกลุ่ม lhs แต่ละกลุ่มออกเป็น batch_group_count กลุ่ม และทําเช่นเดียวกันกับฟีเจอร์เอาต์พุต จากนั้นสําหรับแต่ละกลุ่ม เราจะใช้การฟัซซิชันแบบคู่และต่อเอาต์พุตตามมิติข้อมูลฟีเจอร์เอาต์พุต ความหมายเชิงปฏิบัติการของมิติข้อมูลอื่นๆ ทั้งหมด (องค์ประกอบและเชิงพื้นที่) จะยังคงเหมือนเดิม
ตําแหน่งที่ใช้ได้ของหน้าต่างการแปลงจะกําหนดโดยระยะห่างและขนาดของพื้นที่ฐานหลังจากการเติม
หากต้องการอธิบายสิ่งที่คอนโวลูชัน (Convolution) ทำ ให้พิจารณาคอนโวลูชัน 2 มิติ และเลือกพิกัด batch, z, y, x คงที่ในเอาต์พุต จากนั้น (y,x) คือตําแหน่งของมุมหน้าต่างภายในพื้นที่ฐาน (เช่น มุมซ้ายบน ทั้งนี้ขึ้นอยู่กับวิธีตีความมิติข้อมูลเชิงพื้นที่) ตอนนี้เรามีหน้าต่าง 2 มิติ
ซึ่งนำมาจากพื้นที่ฐาน ซึ่งจุด 2 มิติแต่ละจุดเชื่อมโยงกับเวกเตอร์ 1d เราจึงจะได้กล่อง 3 มิติ จาก Kernel การแปลงสัญญาณ เรามีกล่อง 3 มิติด้วยเนื่องจากเรากำหนดพิกัดเอาต์พุต z ไว้แล้ว กล่อง 2 กล่องมีขนาดมิติข้อมูลเดียวกัน เราจึงนำผลคูณตามองค์ประกอบระหว่างกล่อง 2 กล่องมารวมกัน (คล้ายกับผลคูณแบบดอท) ค่านี้คือค่าเอาต์พุต
โปรดทราบว่าหาก output-z เป็น 5 จากนั้นแต่ละตำแหน่งของหน้าต่างจะสร้างค่า 5 ค่าในเอาต์พุตลงในมิติข้อมูล z ของเอาต์พุต ค่าเหล่านี้แตกต่างกันในส่วนที่ใช้เคอร์เนลคอนโวลูชัน (Convolutional Kernel) ที่มีการใช้กล่องค่า 3 มิติแยกต่างหากสำหรับแต่ละพิกัด output-z คุณอาจมองว่าเป็น 5 Convolution
ที่แยกกันซึ่งมีตัวกรองต่างกันสำหรับแต่ละรายการ
โค้ดจำลองสำหรับการฟัซซิเนชัน 2 มิติที่มีการเติมและการเพิ่มระยะห่างมีดังนี้
for (b, oz, oy, ox) { // output coordinates
value = 0;
for (iz, ky, kx) { // kernel coordinates and input z
iy = oy*stride_y + ky - pad_low_y;
ix = ox*stride_x + kx - pad_low_x;
if ((iy, ix) inside the base area considered without padding) {
value += input(b, iz, iy, ix) * kernel(oz, iz, ky, kx);
}
}
output(b, oz, oy, ox) = value;
}
ConvertElementType
โปรดดูXlaBuilder::ConvertElementType
คล้ายกับ static_cast สำหรับระดับองค์ประกอบใน C++ โดยจะทำการแปลงตามองค์ประกอบจากรูปร่างข้อมูลไปเป็นรูปร่างเป้าหมาย มิติข้อมูลต้องตรงกันและการเปลี่ยนรูปแบบจะดำเนินการทีละองค์ประกอบ เช่น องค์ประกอบ s32 จะกลายเป็นองค์ประกอบ f32 ผ่านกิจวัตรการเปลี่ยนรูปแบบ s32 เป็น f32
ConvertElementType(operand, new_element_type)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ประเภท T ที่มีมิติข้อมูล D |
new_element_type |
PrimitiveType |
ประเภท U |
มิติข้อมูลของออพอเรนดและรูปร่างเป้าหมายต้องตรงกัน ประเภทองค์ประกอบต้นทางและปลายทางต้องไม่ใช่ประเภทองค์ประกอบ
Conversion เช่น T=s32 เป็น U=f32 จะทำกิจวัตร Conversion แบบจำนวนเต็มเป็นแบบลอยเป็นมาตรฐาน เช่น ปัดเศษไปใกล้ที่สุด
let a: s32[3] = {0, 1, 2};
let b: f32[3] = convert(a, f32);
then b == f32[3]{0.0, 1.0, 2.0}
CrossReplicaSum
ดำเนินการ AllReduce ด้วยการคำนวณผลรวม
CustomCall
ดู XlaBuilder::CustomCall เพิ่มเติม
เรียกใช้ฟังก์ชันที่ผู้ใช้ระบุภายในการคํานวณ
CustomCall(target_name, args..., shape)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
target_name |
string |
ชื่อของฟังก์ชัน ระบบจะแสดงคำสั่งการเรียกซึ่งกำหนดเป้าหมายไปยังชื่อสัญลักษณ์นี้ |
args |
ลำดับ XlaOp จำนวน N |
อาร์กิวเมนต์ N ประเภทที่กำหนดเอง ซึ่งจะส่งผ่านไปยังฟังก์ชัน |
shape |
Shape |
รูปร่างเอาต์พุตของฟังก์ชัน |
ลายเซ็นฟังก์ชันจะเหมือนกัน ไม่ว่าจำนวนอาร์กิวเมนต์หรือประเภทของอาร์กิวเมนต์จะเป็นแบบใดก็ตาม
extern "C" void target_name(void* out, void** in);
ตัวอย่างเช่น หากใช้ CustomCall ดังนี้
let x = f32[2] {1,2};
let y = f32[2x3] { {10, 20, 30}, {40, 50, 60} };
CustomCall("myfunc", {x, y}, f32[3x3])
ตัวอย่างการใช้งาน myfunc มีดังนี้
extern "C" void myfunc(void* out, void** in) {
float (&x)[2] = *static_cast<float(*)[2]>(in[0]);
float (&y)[2][3] = *static_cast<float(*)[2][3]>(in[1]);
EXPECT_EQ(1, x[0]);
EXPECT_EQ(2, x[1]);
EXPECT_EQ(10, y[0][0]);
EXPECT_EQ(20, y[0][1]);
EXPECT_EQ(30, y[0][2]);
EXPECT_EQ(40, y[1][0]);
EXPECT_EQ(50, y[1][1]);
EXPECT_EQ(60, y[1][2]);
float (&z)[3][3] = *static_cast<float(*)[3][3]>(out);
z[0][0] = x[1] + y[1][0];
// ...
}
ฟังก์ชันที่ผู้ใช้ระบุต้องไม่มีผลข้างเคียง และการเรียกใช้ฟังก์ชันต้องเป็นแบบ idempotent
จุด
โปรดดูXlaBuilder::Dot
Dot(lhs, rhs)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
lhs |
XlaOp |
อาร์เรย์ประเภท T |
rhs |
XlaOp |
อาร์เรย์ประเภท T |
ความหมายที่แน่นอนของการดำเนินการนี้ขึ้นอยู่กับอันดับของตัวถูกดำเนินการ
| อินพุต | เอาต์พุต | ความหมาย |
|---|---|---|
เวกเตอร์ [n] dot เวกเตอร์ [n] |
สเกลาร์ | ผลคูณเวกเตอร์ |
เมทริกซ์ [m x k] dot เวกเตอร์ [k] |
เวกเตอร์ [m] | การคูณเมทริกซ์กับเวกเตอร์ |
เมทริกซ์ [m x k] เมทริกซ์ dot [k x n] |
เมทริกซ์ [m x n] | การคูณเมทริกซ์กับเมทริกซ์ |
การดำเนินการนี้จะแสดงผลรวมของผลิตภัณฑ์ภายในมิติข้อมูลที่ 2 ของ lhs (หรือมิติข้อมูลแรกหากมีอันดับ 1) และมิติข้อมูลแรกของ rhs เหล่านี้คือมิติข้อมูล "แบบย่อ" มิติข้อมูลที่หดของ lhs และ rhs ต้องมีขนาดเท่ากัน ในทางปฏิบัติ สามารถใช้เพื่อดำเนินการคูณจุดระหว่างเวกเตอร์ การคูณเวกเตอร์/เมทริกซ์ หรือการคูณเมทริกซ์/เมทริกซ์
DotGeneral
โปรดดูXlaBuilder::DotGeneral
DotGeneral(lhs, rhs, dimension_numbers)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
lhs |
XlaOp |
อาร์เรย์ประเภท T |
rhs |
XlaOp |
อาร์เรย์ประเภท T |
dimension_numbers |
DotDimensionNumbers |
หมายเลขมิติข้อมูลการลดขนาดและกลุ่ม |
คล้ายกับจุด แต่อนุญาตให้ระบุหมายเลขมิติข้อมูลแบบย่อและแบบกลุ่มสำหรับทั้ง lhs และ rhs
| ฟิลด์ DotDimensionNumbers | ประเภท | ความหมาย |
|---|---|---|
lhs_contracting_dimensions
|
repeated int64 | หมายเลขมิติข้อมูลการทำสัญญา lhs รายการ |
rhs_contracting_dimensions
|
repeated int64 | rhs มิติข้อมูลที่มีการหดตัว
ตัวเลข |
lhs_batch_dimensions
|
repeated int64 | lhs มิติข้อมูลกลุ่ม
ตัวเลข |
rhs_batch_dimensions
|
repeated int64 | rhs มิติข้อมูลกลุ่ม
ตัวเลข |
DotGeneral ประมวลผลผลรวมของผลิตภัณฑ์มากกว่ามิติข้อมูลที่ทำสัญญาที่ระบุไว้ใน dimension_numbers
หมายเลขมิติข้อมูลที่ทำสัญญาที่เชื่อมโยงจาก lhs และ rhs ไม่จำเป็นต้องเหมือนกันแต่ต้องมีขนาดเดียวกัน
ตัวอย่างหมายเลขมิติข้อมูลตามสัญญา
lhs = { {1.0, 2.0, 3.0},
{4.0, 5.0, 6.0} }
rhs = { {1.0, 1.0, 1.0},
{2.0, 2.0, 2.0} }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(1);
dnums.add_rhs_contracting_dimensions(1);
DotGeneral(lhs, rhs, dnums) -> { {6.0, 12.0},
{15.0, 30.0} }
หมายเลขมิติข้อมูลกลุ่มที่เชื่อมโยงจาก lhs และ rhs ต้องมีขนาดมิติข้อมูลเดียวกัน
ตัวอย่างที่มีหมายเลขมิติข้อมูลกลุ่ม (ขนาดกลุ่ม 2, 2x2 เมทริกซ์)
lhs = { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
rhs = { { {1.0, 0.0},
{0.0, 1.0} },
{ {1.0, 0.0},
{0.0, 1.0} } }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(2);
dnums.add_rhs_contracting_dimensions(1);
dnums.add_lhs_batch_dimensions(0);
dnums.add_rhs_batch_dimensions(0);
DotGeneral(lhs, rhs, dnums) -> { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
| อินพุต | เอาต์พุต | ความหมาย |
|---|---|---|
[b0, m, k] dot [b0, k, n] |
[b0, m, n] | กลุ่ม Matmul |
[b0, b1, m, k] dot [b0, b1, k, n] |
[b0, b1, m, n] | การดำเนินการ matmul แบบเป็นกลุ่ม |
ดังนั้นหมายเลขมิติข้อมูลที่ได้จะขึ้นต้นด้วยมิติข้อมูลกลุ่ม จากนั้นก็lhsมิติข้อมูลที่ไม่ทำสัญญา/ไม่ใช่กลุ่ม และสุดท้ายrhsมิติข้อมูลที่ไม่ทำสัญญา/ไม่ใช่กลุ่ม
DynamicSlice
โปรดดูXlaBuilder::DynamicSlice
DynamicSlice จะดึงข้อมูลอาร์เรย์ย่อยจากอาร์เรย์อินพุตที่ dynamic
start_indices ระบบจะส่งขนาดของส่วนในแต่ละมิติข้อมูลใน size_indices ซึ่งระบุจุดสิ้นสุดของช่วงส่วนที่ไม่ทับซ้อนกันในแต่ละมิติข้อมูล: [start, start + size) รูปร่างของ start_indices ต้องมีค่าลําดับ ==
1 โดยมีขนาดมิติข้อมูลเท่ากับลําดับของ operand
DynamicSlice(operand, start_indices, size_indices)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ N มิติข้อมูลของประเภท T |
start_indices |
ลำดับของ N XlaOp |
รายการจำนวนเต็มสเกลาร์ N ที่มีดัชนีเริ่มต้นของส่วนสำหรับมิติข้อมูลแต่ละรายการ ค่าต้องมากกว่าหรือเท่ากับ 0 |
size_indices |
ArraySlice<int64> |
รายการจำนวนเต็ม N ที่มีขนาดชิ้นส่วนของมิติข้อมูลแต่ละรายการ แต่ละค่าต้องมากกว่า 0 อย่างแน่นอน และ start + size ต้องน้อยกว่าหรือเท่ากับขนาดของมิติข้อมูลเพื่อหลีกเลี่ยงการตัดทศนิยมตามขนาดมิติข้อมูล |
ระบบจะคำนวณดัชนีส่วนแบ่งที่มีประสิทธิภาพโดยใช้การเปลี่ยนรูปแบบต่อไปนี้สำหรับดัชนี i แต่ละรายการใน [1, N) ก่อนดำเนินการสไลซ์
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - size_indices[i])
วิธีนี้ช่วยให้มั่นใจว่าส่วนที่ถูกดึงออกมาจะอยู่ภายในขอบเขตของอาร์เรย์อ็อบเจ็กต์เสมอ หากส่วนแบ่งอยู่ในขอบเขตก่อนที่จะใช้การเปลี่ยนรูปแบบ การเปลี่ยนรูปแบบจะไม่มีผล
ตัวอย่างแบบ 1 มิติ
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let s = {2}
DynamicSlice(a, s, {2}) produces:
{2.0, 3.0}
ตัวอย่างแบบ 2 มิติ
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let s = {2, 1}
DynamicSlice(b, s, {2, 2}) produces:
{ { 7.0, 8.0},
{10.0, 11.0} }
DynamicUpdateSlice
โปรดดูXlaBuilder::DynamicUpdateSlice
DynamicUpdateSlice จะสร้างผลลัพธ์ซึ่งเป็นค่าของอาร์เรย์อินพุต operand โดยมีการเขียนทับส่วน update ที่ start_indices
รูปร่างของ update จะกำหนดรูปร่างของอาร์เรย์ย่อยของผลลัพธ์ที่จะอัปเดต
รูปร่างของ start_indices ต้องมีค่าลําดับ == 1 โดยมีขนาดมิติข้อมูลเท่ากับลําดับของ operand
DynamicUpdateSlice(operand, update, start_indices)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ N มิติของประเภท T |
update |
XlaOp |
อาร์เรย์มิติข้อมูล N ของประเภท T ที่มีการอัปเดตสไลซ์ มิติข้อมูลแต่ละรายการของรูปร่างการอัปเดตต้องมากกว่า 0 อย่างแน่นอน และ start + update ต้องน้อยกว่าหรือเท่ากับขนาดออบเจ็กต์สำหรับแต่ละมิติข้อมูลเพื่อหลีกเลี่ยงการสร้างอินเด็กซ์การอัปเดตที่อยู่นอกขอบเขต |
start_indices |
ลำดับ N XlaOp |
รายการจำนวนเต็มของ N สเกลาร์ที่มีดัชนีเริ่มต้นของสไลซ์สำหรับแต่ละมิติข้อมูล ค่าต้องมากกว่าหรือเท่ากับ 0 |
ระบบจะคำนวณดัชนีส่วนแบ่งที่มีประสิทธิภาพโดยใช้การเปลี่ยนรูปแบบต่อไปนี้สำหรับดัชนี i แต่ละรายการใน [1, N) ก่อนดำเนินการสไลซ์
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - update.dimension_size[i])
วิธีนี้ช่วยให้แน่ใจว่าสไลซ์ที่อัปเดตอยู่ในขอบเขตซึ่งเกี่ยวข้องกับอาร์เรย์ตัวถูกดำเนินการเสมอ หากส่วนอยู่ในขอบเขตก่อนที่จะใช้การเปลี่ยนรูปแบบ การเปลี่ยนรูปแบบจะไม่มีผล
ตัวอย่างแบบ 1 มิติ
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let u = {5.0, 6.0}
let s = {2}
DynamicUpdateSlice(a, u, s) produces:
{0.0, 1.0, 5.0, 6.0, 4.0}
ตัวอย่างแบบ 2 มิติ
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let u =
{ {12.0, 13.0},
{14.0, 15.0},
{16.0, 17.0} }
let s = {1, 1}
DynamicUpdateSlice(b, u, s) produces:
{ {0.0, 1.0, 2.0},
{3.0, 12.0, 13.0},
{6.0, 14.0, 15.0},
{9.0, 16.0, 17.0} }
การดำเนินการทางคณิตศาสตร์แบบไบนารีตามองค์ประกอบ
โปรดดูXlaBuilder::Add
รองรับชุดการดำเนินการทางคณิตศาสตร์แบบไบนารีตามองค์ประกอบ
Op(lhs, rhs)
โดย Op เป็นหนึ่งในAdd (การเพิ่ม), Sub(subtraction), Mul
(การคูณ), Div (division), Pow (กำลัง), Rem (ที่เหลือ), Max
(สูงสุด), Pow (กำลัง), Rem (ที่เหลือ), Sub(การหักลบ) และMul
(การคูณได้), Sub(การหักลบ), Mul
(การคูณ), Div (division), Pow (กำลัง), Rem (ที่เหลือ), Div (หน่วย), Pow (พลัง),Rem (ที่เหลือ), Max
(สูงสุด), Min (กำลัง), Rem (ที่เหลือ), Sub(การย่อย)Sub(การย่อย) และMul
(การคูณ,Div (division), Pow, (พลัง),Rem (ส่วนที่เหลือ), Max
(สูงสุด), Min (กำลัง)Rem (ที่เหลือ), Sub(การย่อย)Sub(การย่อย) และMul
(การคูณ, Div (ไดวิชัน), Pow, (พลัง),Rem (ส่วนที่เหลือ), Div
(สูงสุด) Pow,AndOrXorShiftLeftShiftRightArithmeticShiftRightLogicalAtan2Complex
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
lhs |
XlaOp |
ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
rhs |
XlaOp |
ตัวถูกดำเนินการด้านขวา: อาร์เรย์ของประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบเกี่ยวกับการออกอากาศว่ารูปร่างที่เข้ากันได้หมายความว่าอย่างไร ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลจากการออกอากาศอาร์เรย์อินพุต 2 รายการ ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีลําดับต่างกัน เว้นแต่ว่าหนึ่งในโอเปอเรนดจะเป็นสเกลาร์
เมื่อ Op คือ Rem เครื่องหมายของผลลัพธ์ที่ได้จะนำมาจากตัวปันผล และค่าสัมบูรณ์ของผลลัพธ์จะน้อยกว่าค่าสัมบูรณ์ของตัวหารเสมอ
การหารจำนวนเต็มที่มีค่าเกิน (การหาร/เศษเหลือที่มีค่า/ไม่มีค่าด้วย 0 หรือการหาร/เศษเหลือที่มีค่าของ INT_SMIN ด้วย -1) จะสร้างค่าที่การนำไปใช้งานกำหนด
มีตัวแปรอื่นที่รองรับการออกอากาศในอันดับที่ต่างกันสำหรับการดำเนินการต่อไปนี้
Op(lhs, rhs, broadcast_dimensions)
โดยที่ Op เหมือนกับด้านบน ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการทางคณิตศาสตร์ระหว่างอาร์เรย์ที่มีลําดับต่างกัน (เช่น การเพิ่มเมทริกซ์ลงในเวกเตอร์)
ออบเจ็กต์ broadcast_dimensions เพิ่มเติมคือส่วนของจำนวนเต็มที่ใช้เพื่อขยายอันดับของออบเจ็กต์ที่มีอันดับต่ำกว่าให้เท่ากับอันดับของออบเจ็กต์ที่มีอันดับสูงกว่า broadcast_dimensions จะจับคู่มิติข้อมูลของรูปร่างระดับล่างกับมิติข้อมูลของรูปร่างระดับสูง ขนาดที่ไม่ได้จับคู่ของรูปร่างที่ขยายแล้ว
จะเติมเป็นมิติของขนาด 1 การออกอากาศมิติข้อมูลที่เกิดจากการเสื่อมสภาพ จากนั้นจะออกอากาศรูปทรงตามมิติการเสื่อมสภาพนี้เพื่อปรับรูปทรงของตัวถูกดำเนินการทั้งสองให้เท่ากัน รายละเอียดเกี่ยวกับความหมายมีอยู่ในหน้าการออกอากาศ
การดำเนินการเปรียบเทียบแบบองค์ประกอบ
โปรดดูXlaBuilder::Eq
รองรับชุดการดำเนินการเปรียบเทียบไบนารีเชิงองค์ประกอบมาตรฐาน โปรดทราบว่านิพจน์เปรียบเทียบที่เป็นจุดทศนิยม IEEE 754 มาตรฐานจะมีผลเมื่อเปรียบเทียบประเภทที่เป็นจุดทศนิยม
Op(lhs, rhs)
โดยที่ Op เป็นหนึ่งใน Eq (เท่ากับ), Ne (ไม่เท่ากับ), Ge (มากกว่าหรือเท่ากับ), Gt (มากกว่า), Le (น้อยกว่าหรือเท่ากับ), Lt (น้อยกว่า) โอเปอเรเตอร์ชุดอื่นอย่าง EqTotalOrder, NeTotalOrder, GeTotalOrder, GtTotalOrder, LeTotalOrder และ LtTotalOrder มีฟังก์ชันการทำงานแบบเดียวกัน ยกเว้นว่ารองรับลําดับเชิงสมบูรณ์เพิ่มเติมสําหรับตัวเลขทศนิยม โดยบังคับใช้ -NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
lhs |
XlaOp |
ตัวถูกดำเนินการทางด้านซ้าย: อาร์เรย์ประเภท T |
rhs |
XlaOp |
ตัวถูกดำเนินการด้านขวา: อาร์เรย์ของประเภท T |
รูปร่างของอาร์กิวเมนต์ต้องคล้ายกันหรือเข้ากันได้ ดูเอกสารประกอบเกี่ยวกับการออกอากาศว่ารูปร่างที่เข้ากันได้หมายความว่าอย่างไร ผลลัพธ์ของการดำเนินการมีรูปร่างซึ่งเป็นผลจากการออกอากาศอาร์เรย์อินพุต 2 รายการที่มีประเภทองค์ประกอบ PRED ในตัวแปรนี้ ระบบไม่รองรับการดำเนินการระหว่างอาร์เรย์ที่มีลําดับต่างกัน เว้นแต่ว่าหนึ่งในตัวดำเนินการจะเป็นสเกลาร์
การดำเนินการเหล่านี้มีตัวแปรอื่นที่รองรับการออกอากาศในระดับต่างๆ
Op(lhs, rhs, broadcast_dimensions)
โดยที่ Op เหมือนกับด้านบน ควรใช้การดำเนินการรูปแบบนี้สำหรับการดำเนินการเปรียบเทียบระหว่างอาร์เรย์ที่มีลําดับต่างกัน (เช่น การเพิ่มเมทริกซ์ลงในเวกเตอร์)
ออบเจ็กต์ broadcast_dimensions เพิ่มเติมคือส่วนของจำนวนเต็มซึ่งระบุมิติข้อมูลที่จะใช้ในการออกอากาศออบเจ็กต์ รายละเอียดเกี่ยวกับความหมายมีอยู่ในหน้าการออกอากาศ
ฟังก์ชันเอกรูปตามองค์ประกอบ
XlaBuilder รองรับฟังก์ชันแบบแยกส่วนขององค์ประกอบเหล่านี้
Abs(operand) ผลลัพธ์ abs ตามองค์ประกอบ x -> |x|
Cbrt(operand) การดำเนินการหารากคิวบิกตามองค์ประกอบ x -> cbrt(x)
Ceil(operand) ฟังก์ชัน Ceil ตามองค์ประกอบ x -> ⌈x⌉
Clz(operand) ตามองค์ประกอบจะนับเลข 0 นำหน้า
Cos(operand) โคไซน์ตามองค์ประกอบ x -> cos(x)
Erf(operand) ฟังก์ชันค่าคลาดเคลื่อนระดับองค์ประกอบ x -> erf(x) โดยที่
erf(x)=2√π∫x0e−t2dt
Exp(operand) Exponential ธรรมชาติตามองค์ประกอบ x -> e^x
Expm1(operand) เลขชี้กำลังธรรมชาติที่อยู่เหนือองค์ประกอบ ลบ 1 x -> e^x - 1
Floor(operand) พื้นตามองค์ประกอบ x -> ⌊x⌋
Imag(operand) ส่วนจินตภาพตามองค์ประกอบของรูปเชิงซ้อน (หรือจริง) x -> imag(x) หากโอเปอเรนดเป็นประเภทตัวเลขทศนิยม ระบบจะแสดงผล 0
IsFinite(operand) ทดสอบว่าองค์ประกอบแต่ละรายการของ operand มีจำนวนจำกัดหรือไม่
กล่าวคือ ไม่ใช่ค่าบวกหรือค่าลบอนันต์ และไม่ใช่ NaN แสดงผลอาร์เรย์ของค่า PRED ที่มีรูปทรงเดียวกันกับอินพุต โดยที่องค์ประกอบแต่ละรายการคือ true หากองค์ประกอบอินพุตที่เกี่ยวข้องเป็นแบบจำกัดเท่านั้น
Log(operand) ลอการิทึมธรรมชาติตามองค์ประกอบ x -> ln(x)
Log1p(operand) ลอการิทึมธรรมชาติที่เลื่อนตามองค์ประกอบ x -> ln(1+x)
Logistic(operand) การคำนวณฟังก์ชันลอจิสติกส์ที่ระดับองค์ประกอบ x ->
logistic(x)
Neg(operand) นิเสธที่คำนึงถึงองค์ประกอบ x -> -x
Not(operand) ตรรกะสำหรับองค์ประกอบ ไม่ใช่ x -> !(x)
PopulationCount(operand) คำนวณจํานวนบิตที่ตั้งค่าไว้ในองค์ประกอบแต่ละรายการของ operand
Real(operand) ส่วนจริงขององค์ประกอบของรูปร่างเชิงซ้อน (หรือจริง)
x -> real(x) หากโอเปอเรนดเป็นประเภททศนิยม จะแสดงผลค่าเดียวกัน
Round(operand) การปัดเศษองค์ประกอบทีละรายการ โดยปัดเศษออกจาก 0
RoundNearestEven(operand) การปัดเศษองค์ประกอบตามลำดับ ปัดไปเป็นจำนวนคู่ที่ใกล้ที่สุด
Rsqrt(operand) ตัวผกผันการดำเนินการรากที่สองตามองค์ประกอบ
x -> 1.0 / sqrt(x)
Sign(operand) การดำเนินการเกี่ยวกับเครื่องหมายขององค์ประกอบ x -> sgn(x) โดยที่
sgn(x)={−1x<0−0x=−0NaNx=NaN+0x=+01x>0
โดยใช้โอเปอเรเตอร์การเปรียบเทียบขององค์ประกอบประเภท operand
Sin(operand) ไซน์ตามองค์ประกอบ x -> sin(x)
Sqrt(operand) การดำเนินการหารากที่สองตามองค์ประกอบ x -> sqrt(x)
Tan(operand) Tangens ตามองค์ประกอบ x -> tan(x)
Tanh(operand) ไฮเพอร์โบลิกแทนเจนต์ตามองค์ประกอบ x -> tanh(x)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ตัวถูกดำเนินการของฟังก์ชัน |
ระบบจะใช้ฟังก์ชันกับองค์ประกอบแต่ละรายการในอาร์เรย์ operand ซึ่งจะให้ผลลัพธ์เป็นอาร์เรย์ที่มีรูปร่างเหมือนกัน อนุญาตให้ operand เป็นค่าสเกลาร์ (ลําดับ 0)
Fft
การดำเนินการ FFT ของ XLA ใช้การแปลงฟูริเยแบบย้อนกลับและแบบตรงสําหรับอินพุต/เอาต์พุตจริงและเชิงซ้อน ระบบรองรับ FFT หลายมิติบนแกนสูงสุด 3 แกน
โปรดดูXlaBuilder::Fft
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ที่เรากำลังเปลี่ยนรูปแบบเป็นฟูรีเย |
fft_type |
FftType |
โปรดดูตารางด้านล่าง |
fft_length |
ArraySlice<int64> |
ความยาวโดเมนเวลาของแกนที่เปลี่ยนรูปแบบ ซึ่งจำเป็นอย่างยิ่งสำหรับ IRFFT เพื่อให้ปรับขนาดแกนด้านในสุดให้เหมาะสม เนื่องจาก RFFT(fft_length=[16]) มีรูปร่างเอาต์พุตเหมือนกับ RFFT(fft_length=[17]) |
FftType |
ความหมาย |
|---|---|
FFT |
FFT แบบเชิงซ้อนต่อเชิงซ้อนแบบส่งต่อ รูปร่างจะไม่มีการเปลี่ยนแปลง |
IFFT |
FFT แบบผกผันกับซับซ้อน รูปร่างไม่มีการเปลี่ยนแปลง |
RFFT |
FFT แบบเรียลไปเชิงซ้อนแบบส่งต่อ รูปร่างของแกนกลางสุดจะลดลงเป็น fft_length[-1] // 2 + 1 หาก fft_length[-1] เป็นค่าที่ไม่ใช่ 0 โดยละเว้นส่วนคู่ผสานย้อนกลับของสัญญาณที่เปลี่ยนรูปแบบซึ่งอยู่นอกความถี่ Nyquist |
IRFFT |
FFT แบบย้อนกลับจากจริงเป็นเชิงซ้อน (กล่าวคือ ใช้เชิงซ้อนแล้วแสดงผลเป็นจริง) รูปร่างของแกนด้านในสุดจะขยายเป็น fft_length[-1] หาก fft_length[-1] เป็นค่าที่ไม่ใช่ 0 โดยอนุมานส่วนของสัญญาณที่เปลี่ยนรูปแบบนอกเหนือจากความถี่ Nyquist จากสังยุคย้อนกลับของ 1 ถึง fft_length[-1] // 2 + 1 |
FFT หลายมิติ
เมื่อระบุ fft_length มากกว่า 1 รายการ การดำเนินการนี้จะเทียบเท่ากับการใช้การดำเนินการ FFT แบบซ้อนกันกับแต่ละแกนด้านในสุด โปรดทราบว่าสำหรับกรณีจริง->เชิงซ้อนและเชิงซ้อน->จริง ระบบจะดำเนินการเปลี่ยนรูปแบบแกนด้านในสุด (อย่างมีประสิทธิภาพ) ก่อน (RFFT; สุดท้ายสำหรับ IRFFT) ซึ่งเป็นเหตุผลที่แกนกลางสุดเป็นแกนที่จะเปลี่ยนขนาด จากนั้นการเปลี่ยนรูปแบบแกนอื่นๆ จะเปลี่ยนจากคอมเพล็กซ์เป็นคอมเพล็กซ์
รายละเอียดการติดตั้งใช้งาน
FFT ของ CPU ทำงานด้วย TensorFFT ของ Eigen FFT ของ GPU ใช้ cuFFT
รวบรวม
การดำเนินการรวบรวม XLA จะต่อชิ้นงานหลายชิ้น (แต่ละชิ้นที่ออฟเซตรันไทม์ที่ต่างกันได้) ของอาร์เรย์อินพุตเข้าด้วยกัน
ความหมายทั่วไป
ดู XlaBuilder::Gather เพิ่มเติม
ดูคำอธิบายที่เข้าใจง่ายขึ้นได้ในส่วน "คำอธิบายแบบไม่เป็นทางการ" ด้านล่าง
gather(operand, start_indices, offset_dims, collapsed_slice_dims, slice_sizes, start_index_map)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ที่เรากําลังรวบรวม |
start_indices |
XlaOp |
อาร์เรย์ที่มีดัชนีเริ่มต้นของชิ้นส่วนที่เรารวบรวม |
index_vector_dim |
int64 |
มิติข้อมูลใน start_indices ที่ "มี" ดัชนีเริ่มต้น โปรดดูคำอธิบายโดยละเอียดด้านล่าง |
offset_dims |
ArraySlice<int64> |
ชุดมิติข้อมูลในรูปร่างเอาต์พุตที่เลื่อนเข้าไปในอาร์เรย์ที่ตัดมาจากออบเจ็กต์ |
slice_sizes |
ArraySlice<int64> |
slice_sizes[i] คือขอบเขตของส่วนในมิติข้อมูล i |
collapsed_slice_dims |
ArraySlice<int64> |
ชุดมิติข้อมูลในแต่ละส่วนที่ถูกยุบ มิติข้อมูลเหล่านี้ต้องมีขนาด 1 |
start_index_map |
ArraySlice<int64> |
แผนที่อธิบายวิธีจับคู่ดัชนีใน start_indices กับดัชนีที่ถูกต้องในโอเปอเรนด์ |
indices_are_sorted |
bool |
กำหนดว่าจัดเรียงดัชนีตามผู้โทรหรือไม่ |
เราติดป้ายกำกับมิติข้อมูลในอาร์เรย์เอาต์พุตที่ไม่ใช่ใน offset_dims ว่าเป็น batch_dims เพื่อความสะดวก
เอาต์พุตคืออาร์เรย์ของอันดับ batch_dims.size + offset_dims.size
operand.rank ต้องเท่ากับผลรวมของ offset_dims.size และ
collapsed_slice_dims.size นอกจากนี้ slice_sizes.size ต้องเท่ากับ operand.rank
หาก index_vector_dim เท่ากับ start_indices.rank เราจะถือว่า start_indices มีมิติข้อมูล 1 ต่อท้าย (นั่นคือ ถ้า start_indices มีรูปร่าง [6,7] และ index_vector_dim เท่ากับ 2 เราจะถือว่ารูปร่างของ start_indices เป็น [6,7,1])
ขอบเขตของอาร์เรย์เอาต์พุตตามมิติข้อมูล i จะคำนวณดังนี้
หาก
iอยู่ในbatch_dims(นั่นคือเท่ากับbatch_dims[k]สำหรับkบางรายการ) เราจะเลือกขอบเขตมิติข้อมูลที่เกี่ยวข้องจากstart_indices.shapeโดยข้ามindex_vector_dim(นั่นคือเลือกstart_indices.shape.dims[k] หากk<index_vector_dimและstart_indices.shape.dims[k+1] ในกรณีอื่นๆ)หาก
iอยู่ในoffset_dims(เช่น เท่ากับoffset_dims[k] สำหรับkบางส่วน) เราจะเลือกขอบเขตที่ตรงกันจากslice_sizesหลังจากคำนวณcollapsed_slice_dims(นั่นคือ เราเลือกadjusted_slice_sizes[k] โดยที่adjusted_slice_sizesเป็นslice_sizesโดยขอบเขตที่ดัชนีcollapsed_slice_dimsถูกนำออก)
ดัชนีตัวถูกดำเนินการ In อย่างเป็นทางการที่ตรงกับดัชนีเอาต์พุต Out มีการคำนวณดังนี้
ให้
G= {Out[k] สำหรับkในbatch_dims} ใช้Gเพื่อตัดเวกเตอร์Sออกเพื่อให้S[i] =start_indices[รวม(G,i)] โดยที่ รวม(A, b) แทรก b ที่ตำแหน่งindex_vector_dimเข้าไปใน A โปรดทราบว่าการนิยามนี้ชัดเจนแม้ว่าGจะว่างเปล่าก็ตาม หากGว่างเปล่าS=start_indicesสร้างดัชนีเริ่มต้น
Sinลงในoperandโดยใช้SโดยการกระจายSโดยใช้start_index_mapกล่าวอย่างละเอียดคือSin[start_index_map[k]] =S[k] หากk<start_index_map.sizeSin[_] =0ในกรณีอื่น
สร้างดัชนี
Oinลงในoperandโดยกระจายดัชนี ที่มิติข้อมูลออฟเซ็ตในOutตาม ชุดcollapsed_slice_dimsแม่นยำยิ่งขึ้นOin[remapped_offset_dims(k)] =Out[offset_dims[k]] ifk<offset_dims.size(remapped_offset_dimsis defined below).Oin[_] =0ในกรณีอื่น
InคือOin+Sinโดยที่ + คือการเพิ่มตามองค์ประกอบ
remapped_offset_dims เป็นฟังก์ชันที่เพิ่มขึ้นเรื่อยๆ โดยมีโดเมน [0,
offset_dims.size) และช่วง [0, operand.rank) \ collapsed_slice_dims เช่น offset_dims.size คือ 4, operand.rank คือ 6 และ
collapsed_slice_dims เท่ากับ {0, 2} จากนั้น remapped_offset_dims เท่ากับ {0→1,
1→3, 2→4, 3→5}
หากตั้งค่า indices_are_sorted เป็น "จริง" แล้ว XLA จะถือว่าผู้ใช้จัดเรียง start_indices (ตามลําดับจากน้อยไปมาก หลังจากกระจายค่าตาม start_index_map) หากไม่มี ความหมายจะกำหนดโดยการใช้งาน
คำอธิบายและตัวอย่างอย่างไม่เป็นทางการ
อย่างไม่เป็นทางการ ดัชนี Out ทั้งหมดในอาร์เรย์เอาต์พุตจะสอดคล้องกับองค์ประกอบ E ในอาร์เรย์ออบเจ็กต์ ซึ่งคํานวณดังนี้
เราใช้มิติข้อมูลกลุ่มใน
Outเพื่อค้นหาดัชนีเริ่มต้นจากstart_indicesเราใช้
start_index_mapเพื่อจับคู่ดัชนีเริ่มต้น (ซึ่งมีขนาดอาจน้อยกว่า operand.rank) กับดัชนีเริ่มต้น "แบบเต็ม" ในoperandเราจะตัดข้อมูลขนาด
slice_sizesออกเป็นส่วนๆ แบบไดนามิกโดยใช้ดัชนีเริ่มต้นแบบเต็มเราปรับรูปร่างของส่วนข้อมูลโดยการยุบมิติข้อมูล
collapsed_slice_dimsเนื่องจากมิติข้อมูลส่วนที่ถูกยุบทั้งหมดต้องมีขอบเขต 1 การเปลี่ยนรูปแบบนี้จึงถูกต้องเสมอเราใช้มิติข้อมูลออฟเซตใน
Outเพื่อจัดทำดัชนีในข้อมูลส่วนนี้เพื่อรับองค์ประกอบอินพุตEซึ่งสอดคล้องกับดัชนีเอาต์พุตOut
index_vector_dim มีการตั้งค่าเป็น start_indices.rank - 1 ในตัวอย่างทั้งหมดต่อไปนี้ ค่าที่น่าสนใจยิ่งขึ้นสําหรับ index_vector_dim จะไม่ทําให้การดำเนินการเปลี่ยนแปลงไปโดยพื้นฐาน แต่ทําให้การแสดงภาพยุ่งยากมากขึ้น
เพื่อให้เข้าใจถึงความสอดคล้องกันของสิ่งต่างๆ ข้างต้น มาดูตัวอย่างที่รวบรวมรูปร่าง [8,6] จำนวน 5 ส่วนจากอาร์เรย์ [16,11] ตำแหน่งของส่วนในอาร์เรย์ [16,11] สามารถแสดงเป็นเวกเตอร์อินเด็กซ์ของรูปร่าง S64[2] ดังนั้นชุดตำแหน่ง 5 รายการจึงแสดงเป็นอาร์เรย์ S64[5,2] ได้
ลักษณะการทำงานของการดำเนินการรวบรวมอาจแสดงเป็นการเปลี่ยนรูปแบบดัชนีที่ใช้ [G,O0,O1] ดัชนีในรูปร่างเอาต์พุต และแมปกับองค์ประกอบในอาร์เรย์อินพุตด้วยวิธีต่อไปนี้

ก่อนอื่นเราเลือกเวกเตอร์ (X,Y) จากอาร์เรย์ดัชนีการรวบรวมโดยใช้ G
องค์ประกอบในอาร์เรย์เอาต์พุตที่ดัชนี [G,O0,O1] จึงเป็นองค์ประกอบในอาร์เรย์อินพุตที่ดัชนี [X+O0,Y+O1]
slice_sizes คือ [8,6] ซึ่งจะเป็นตัวกำหนดช่วงของ O0 และ O1 ซึ่งจะเป็นตัวกำหนดขอบเขตของส่วน
การดำเนินการรวบรวมนี้จะทำหน้าที่เป็นส่วนแบ่งแบบไดนามิกแบบกลุ่มที่มี G เป็นมิติข้อมูลแบบกลุ่ม
ดัชนีการรวบรวมอาจมีหลายมิติ ตัวอย่างเช่น ตัวอย่างที่กว้างขึ้นของตัวอย่างข้างต้นที่ใช้อาร์เรย์ "ดัชนีรวบรวม" ของรูปร่าง [4,5,2] จะแปลดัชนีในลักษณะนี้

อีกครั้ง ข้อมูลนี้ทําหน้าที่เป็นกลุ่มย่อยแบบไดนามิก G0 และ
G1 เป็นมิติข้อมูลกลุ่ม ขนาดของชิ้นส่วนยังคงเป็น [8,6]
การดำเนินการรวบรวมใน XLA ทำให้ความหมายของความหมายไม่เป็นทางการที่อธิบายไว้ข้างต้นมีวิธีการดังต่อไปนี้
เรากําหนดค่ามิติข้อมูลในรูปร่างเอาต์พุตที่เป็นมิติข้อมูลออฟเซตได้ (มิติข้อมูลที่มี
O0,O1ในตัวอย่างล่าสุด) มิติข้อมูลกลุ่มเอาต์พุต (มิติข้อมูลที่มีG0,G1ในตัวอย่างสุดท้าย) ได้รับการกำหนดให้เป็นมิติข้อมูลเอาต์พุตที่ไม่ใช่มิติข้อมูลออฟเซ็ตจํานวนมิติข้อมูลออฟเซ็ตเอาต์พุตที่แสดงอย่างชัดเจนในรูปร่างเอาต์พุตอาจน้อยกว่าลําดับอินพุต มิติข้อมูล "ที่ขาดหายไป" เหล่านี้ซึ่งแสดงเป็น
collapsed_slice_dimsอย่างชัดเจนต้องมีขนาดส่วนที่เป็น1เนื่องจากมีขนาดส่วนที่เป็น1ดัชนีที่ถูกต้องเพียงรายการเดียวสำหรับรายการเหล่านี้คือ0และการละเว้นรายการเหล่านี้จะไม่ทำให้เกิดความคลุมเครือชิ้นส่วนที่ดึงมาจากอาร์เรย์ "รวบรวมดัชนี" ((
X,Y) ในตัวอย่างสุดท้าย) อาจมีองค์ประกอบน้อยกว่าอันดับอาร์เรย์อินพุต และการแมปอย่างชัดแจ้งจะกำหนดวิธีขยายดัชนีให้มีอันดับเดียวกับอินพุต
ตัวอย่างสุดท้าย เราใช้ (2) และ (3) ในการติดตั้งใช้งาน tf.gather_nd

G0 และ G1 ใช้เพื่อตัดดัชนีเริ่มต้นออกจากอาร์เรย์ดัชนีการรวบรวมตามปกติ ยกเว้นดัชนีเริ่มต้นมีองค์ประกอบเพียงรายการเดียวเท่านั้น ซึ่งก็คือ X ในทำนองเดียวกัน ดัชนีออฟเซตเอาต์พุตมีเพียงรายการเดียวที่มีค่า O0 อย่างไรก็ตาม ก่อนที่จะใช้เป็นดัชนีในอาร์เรย์อินพุต ระบบจะขยายค่าเหล่านี้ตาม "การแมปดัชนีการรวบรวม" (start_index_map ในคำอธิบายอย่างเป็นทางการ) และ "การแมปออฟเซต" (remapped_offset_dims ในคำอธิบายอย่างเป็นทางการ) เป็น [X,0] และ [0,O0] ตามลำดับ ซึ่งรวมกันเป็น [X,O0] กล่าวคือ ดัชนีเอาต์พุต [G0,G1,O0] จะแมปกับดัชนีอินพุต [GatherIndices[G0,G1,0],O0] ซึ่งให้ความหมายสำหรับ tf.gather_nd
slice_sizes สำหรับเคสนี้คือ [1,11] ในแง่ที่เข้าใจง่าย หมายความว่าทุกดัชนี X ในอาร์เรย์ดัชนีการรวบรวมจะเลือกทั้งแถว และผลลัพธ์คือการเชื่อมต่อแถวทั้งหมดเหล่านี้
GetDimensionSize
ดู XlaBuilder::GetDimensionSize เพิ่มเติม
แสดงผลขนาดของมิติข้อมูลที่ระบุของออบเจ็กต์การดำเนินการ ออบเจ็กต์ต้องอยู่ในรูปแบบอาร์เรย์
GetDimensionSize(operand, dimension)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์อินพุต n มิติ |
dimension |
int64 |
ค่าในช่วง [0, n) ที่ระบุมิติข้อมูล |
SetDimensionSize
ดู XlaBuilder::SetDimensionSize เพิ่มเติม
กำหนดขนาดแบบไดนามิกของมิติข้อมูลที่ระบุของ XlaOp ออบเจ็กต์ต้องอยู่ในรูปแบบอาร์เรย์
SetDimensionSize(operand, size, dimension)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์อินพุต n มิติ |
size |
XlaOp |
int32 ที่แสดงขนาดแบบไดนามิกของรันไทม์ |
dimension |
int64 |
ค่าในช่วง [0, n) ที่ระบุมิติข้อมูล |
ส่งผ่านตัวถูกดำเนินการด้วยมิติข้อมูลแบบไดนามิกที่ติดตามโดยคอมไพเลอร์
การดำเนินการลดปลายทางจะไม่สนใจค่าที่เพิ่มการเติม
let v: f32[10] = f32[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
let five: s32 = 5;
let six: s32 = 6;
// Setting dynamic dimension size doesn't change the upper bound of the static
// shape.
let padded_v_five: f32[10] = set_dimension_size(v, five, /*dimension=*/0);
let padded_v_six: f32[10] = set_dimension_size(v, six, /*dimension=*/0);
// sum == 1 + 2 + 3 + 4 + 5
let sum:f32[] = reduce_sum(padded_v_five);
// product == 1 * 2 * 3 * 4 * 5
let product:f32[] = reduce_product(padded_v_five);
// Changing padding size will yield different result.
// sum == 1 + 2 + 3 + 4 + 5 + 6
let sum:f32[] = reduce_sum(padded_v_six);
GetTupleElement
ดู XlaBuilder::GetTupleElement เพิ่มเติม
จัดทำดัชนีลงในทูเปิลที่มีค่าคงที่เวลาคอมไพล์
ค่าต้องเป็นค่าคงที่เวลาคอมไพล์เพื่อให้การอนุมานรูปร่างระบุประเภทของค่าที่ได้
คล้ายกับ std::get<int N>(t) ใน C++
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
let element_1: s32 = gettupleelement(t, 1); // Inferred shape matches s32.
โปรดดูtf.tuple
ในสตรีม
โปรดดูXlaBuilder::Infeed
Infeed(shape)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
shape |
Shape |
รูปแบบข้อมูลที่อ่านจากอินเทอร์เฟซในฟีด ช่องสำหรับเลย์เอาต์ของรูปร่างจะต้องตั้งค่าให้ตรงกับเลย์เอาต์ของข้อมูลที่ส่งไปยังอุปกรณ์ มิฉะนั้นจะไม่มีการกำหนดลักษณะการทำงานของรูปร่างนั้น |
อ่านรายการข้อมูลรายการเดียวจากอินเทอร์เฟซสตรีมมิงในฟีดโดยนัยของอุปกรณ์ ตีความข้อมูลเป็นรูปร่างและเลย์เอาต์ที่ระบุ และแสดงXlaOpของข้อมูล ระบบอนุญาตให้มีการดำเนินการกับอินฟีดหลายรายการในการคํานวณ แต่ต้องเรียงลําดับการดำเนินการกับอินฟีดทั้งหมด ตัวอย่างเช่น Infeed 2 รายการในโค้ดด้านล่างมีลําดับทั้งหมดเนื่องจากมีความสัมพันธ์ระหว่างลูป while
result1 = while (condition, init = init_value) {
Infeed(shape)
}
result2 = while (condition, init = result1) {
Infeed(shape)
}
ระบบไม่รองรับรูปร่างทูเปิลที่ซ้อนกัน สำหรับรูปแบบทูเปิลว่าง การดำเนินการกับฟีดข้อมูลจะถือว่าไม่มีการดำเนินการใดๆ และดำเนินการต่อโดยไม่อ่านข้อมูลจากฟีดข้อมูลของอุปกรณ์
Iota
โปรดดูXlaBuilder::Iota
Iota(shape, iota_dimension)
สร้างลิเทอรัลคงที่ในอุปกรณ์แทนที่จะเป็นการโอนโฮสต์ขนาดใหญ่ สร้างอาร์เรย์ที่มีรูปร่างที่ระบุและเก็บค่าที่เริ่มต้นที่ 0 และเพิ่มขึ้นทีละ 1 ตามมิติข้อมูลที่ระบุ สำหรับประเภทจุดลอยตัว อาร์เรย์ที่สร้างขึ้นมีค่าเท่ากับ ConvertElementType(Iota(...)) โดยที่ Iota เป็นประเภทปริพันธ์และ Conversion เป็นประเภทจุดลอยตัว
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
shape |
Shape |
รูปร่างของอาร์เรย์ที่สร้างโดย Iota() |
iota_dimension |
int64 |
มิติข้อมูลที่เพิ่มขึ้นตาม |
เช่น Iota(s32[4, 8], 0) จะแสดงผลเป็น
[[0, 0, 0, 0, 0, 0, 0, 0 ],
[1, 1, 1, 1, 1, 1, 1, 1 ],
[2, 2, 2, 2, 2, 2, 2, 2 ],
[3, 3, 3, 3, 3, 3, 3, 3 ]]
ส่งคืนสินค้า Iota(s32[4, 8], 1)
[[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ]]
แผนที่
โปรดดูXlaBuilder::Map
Map(operands..., computation)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
operands |
ลำดับ XlaOp จำนวน N |
อาร์เรย์ N รายการประเภท T0..T{N-1} |
computation |
XlaComputation |
การคํานวณประเภท T_0, T_1, .., T_{N + M -1} -> S ที่มีพารามิเตอร์ N ประเภท T และ M ประเภทใดก็ได้ |
dimensions |
int64 อาร์เรย์ |
อาร์เรย์ของมิติข้อมูลแผนที่ |
ใช้ฟังก์ชันสเกลาร์กับอาร์เรย์ operands ที่ระบุ ซึ่งจะสร้างอาร์เรย์ที่มีมิติข้อมูลเดียวกัน โดยแต่ละองค์ประกอบเป็นผลลัพธ์ของฟังก์ชันที่แมปซึ่งใช้กับองค์ประกอบที่เกี่ยวข้องในอาร์เรย์อินพุต
ฟังก์ชันที่แมปคือการคํานวณแบบไม่เจาะจงโดยมีข้อจํากัดว่าต้องมีอินพุต N รายการที่เป็นสเกลาร์ประเภท T และเอาต์พุตรายการเดียวที่เป็นประเภท S เอาต์พุตจะมีมิติข้อมูลเดียวกับโอเปอเรนด์ ยกเว้นว่าจะมีการเปลี่ยนประเภทองค์ประกอบ T เป็น S
เช่น Map(op1, op2, op3, computation, par1) จะจับคู่ elem_out <-
computation(elem1, elem2, elem3, par1) ที่แต่ละดัชนี (มิติข้อมูลหลายมิติ) ในอาร์เรย์อินพุตเพื่อสร้างอาร์เรย์เอาต์พุต
OptimizationBarrier
บล็อกการเพิ่มประสิทธิภาพไม่ให้ย้ายการคำนวณข้ามสิ่งกีดขวาง
ตรวจสอบว่าระบบประเมินอินพุตทั้งหมดก่อนโอเปอเรเตอร์ที่ขึ้นอยู่กับเอาต์พุตของบัวเรีย
แผ่น
โปรดดูXlaBuilder::Pad
Pad(operand, padding_value, padding_config)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ของประเภท T |
padding_value |
XlaOp |
สเกลาร์ประเภท T เพื่อเติมช่องว่างที่เพิ่มขึ้น |
padding_config |
PaddingConfig |
จำนวนระยะห่างจากเส้นขอบทั้ง 2 ด้าน (ต่ำ สูง) และระหว่างองค์ประกอบของมิติข้อมูลแต่ละรายการ |
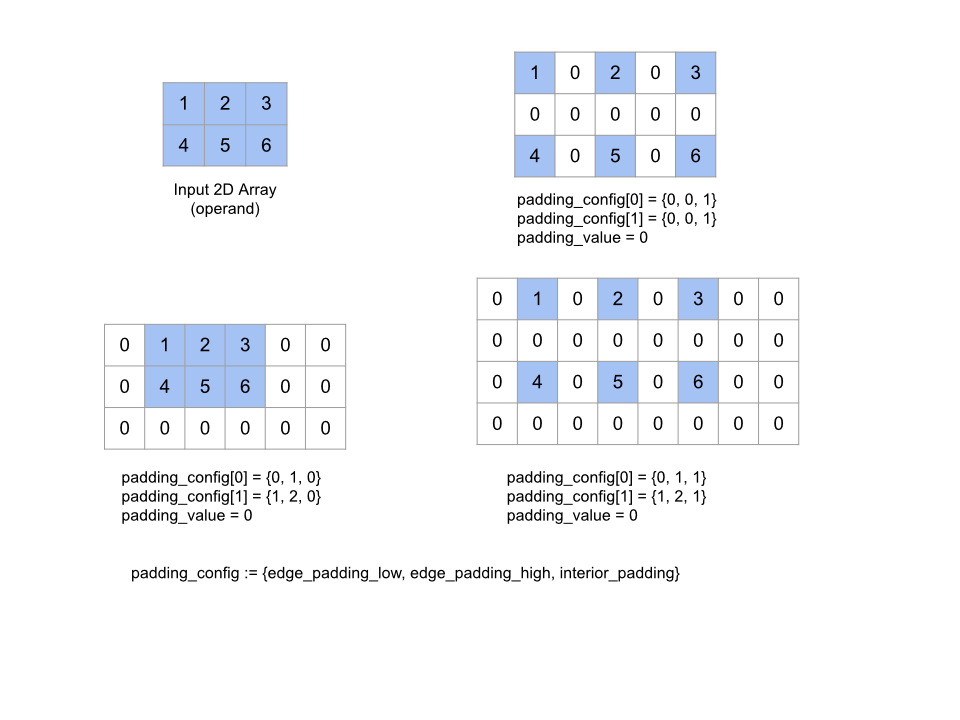
ขยายอาร์เรย์ operand ที่ระบุโดยระยะห่างจากขอบรอบๆ อาร์เรย์ รวมถึงระหว่างองค์ประกอบของอาร์เรย์ที่มี padding_value ที่ระบุ padding_config จะระบุระยะห่างจากขอบและระยะห่างจากขอบด้านในสำหรับแต่ละมิติข้อมูล
PaddingConfig เป็นช่องที่ซ้ำกันของ PaddingConfigDimension ซึ่งมี 3 ช่องสําหรับมิติข้อมูลแต่ละรายการ ได้แก่ edge_padding_low, edge_padding_high และ interior_padding
edge_padding_low และ edge_padding_high ระบุระยะห่างจากขอบที่เพิ่มในส่วนล่างสุด (ถัดจากดัชนี 0) และระดับไฮเอนด์ (ถัดจากดัชนีสูงสุด) ของมิติข้อมูลแต่ละรายการตามลำดับ จำนวนการเว้นขอบอาจเป็นค่าลบได้ โดยค่าสัมบูรณ์ของการเว้นขอบเชิงลบจะระบุจํานวนองค์ประกอบที่จะนําออกจากมิติข้อมูลที่ระบุ
interior_padding ระบุจำนวนระยะห่างจากเส้นขอบที่เพิ่มระหว่างองค์ประกอบ 2 รายการในแต่ละมิติข้อมูล โดยต้องไม่เป็นค่าลบ ระยะห่างจากขอบด้านในเกิดขึ้นก่อนระยะห่างจากขอบด้านนอกตามหลักตรรกะ ดังนั้นในกรณีที่ระยะห่างจากขอบด้านนอกเป็นลบ ระบบจะนำองค์ประกอบออกจากโอเปอเรนด์ที่มีระยะห่างจากขอบด้านใน
การดำเนินการนี้จะใช้งานไม่ได้หากคู่การเว้นขอบเป็น (0, 0) ทั้งหมด และค่าการเว้นขอบภายในเป็น 0 ทั้งหมด รูปภาพด้านล่างแสดงตัวอย่างค่า edge_padding และ interior_padding ที่แตกต่างกันสําหรับอาร์เรย์ 2 มิติ
Recv
ดู XlaBuilder::Recv เพิ่มเติม
Recv(shape, channel_handle)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
shape |
Shape |
รูปร่างของข้อมูลที่จะรับ |
channel_handle |
ChannelHandle |
ตัวระบุที่ไม่ซ้ำกันสำหรับคู่ส่ง/รับแต่ละคู่ |
รับข้อมูลของรูปร่างที่ระบุจากคำสั่ง Send ในการคำนวณอื่นที่ใช้แฮนเดิลช่องทางเดียวกัน ส่งคืน
XlaOp สำหรับข้อมูลที่รับ
API ของไคลเอ็นต์สําหรับการดําเนินการ Recv แสดงถึงการสื่อสารแบบซิงค์
แต่ระบบจะแยกวิธีการดังกล่าวเป็นการภายในเป็นคำสั่ง HLO 2 รายการ (Recv และ RecvDone) เพื่อเปิดใช้การโอนข้อมูลแบบไม่พร้อมกัน ดู HloInstruction::CreateRecv และ HloInstruction::CreateRecvDone เพิ่มเติม
Recv(const Shape& shape, int64 channel_id)
จัดสรรทรัพยากรที่จำเป็นต่อการรับข้อมูลจากคำสั่ง Send ด้วย channel_id เดียวกัน แสดงผลบริบทสำหรับทรัพยากรที่จัดสรร ซึ่งจะใช้โดยคำสั่ง RecvDone ต่อไปนี้เพื่อรอให้การโอนข้อมูลเสร็จสมบูรณ์ บริบทคือทูเปิลของ {receive buffer (shape), request identifier (U32)} และสามารถใช้ได้เฉพาะกับคำสั่ง RecvDone เท่านั้น
RecvDone(HloInstruction context)
รอให้การโอนข้อมูลเสร็จสมบูรณ์และแสดงผลข้อมูลที่ได้รับตามบริบทที่สร้างโดยคำสั่ง Recv
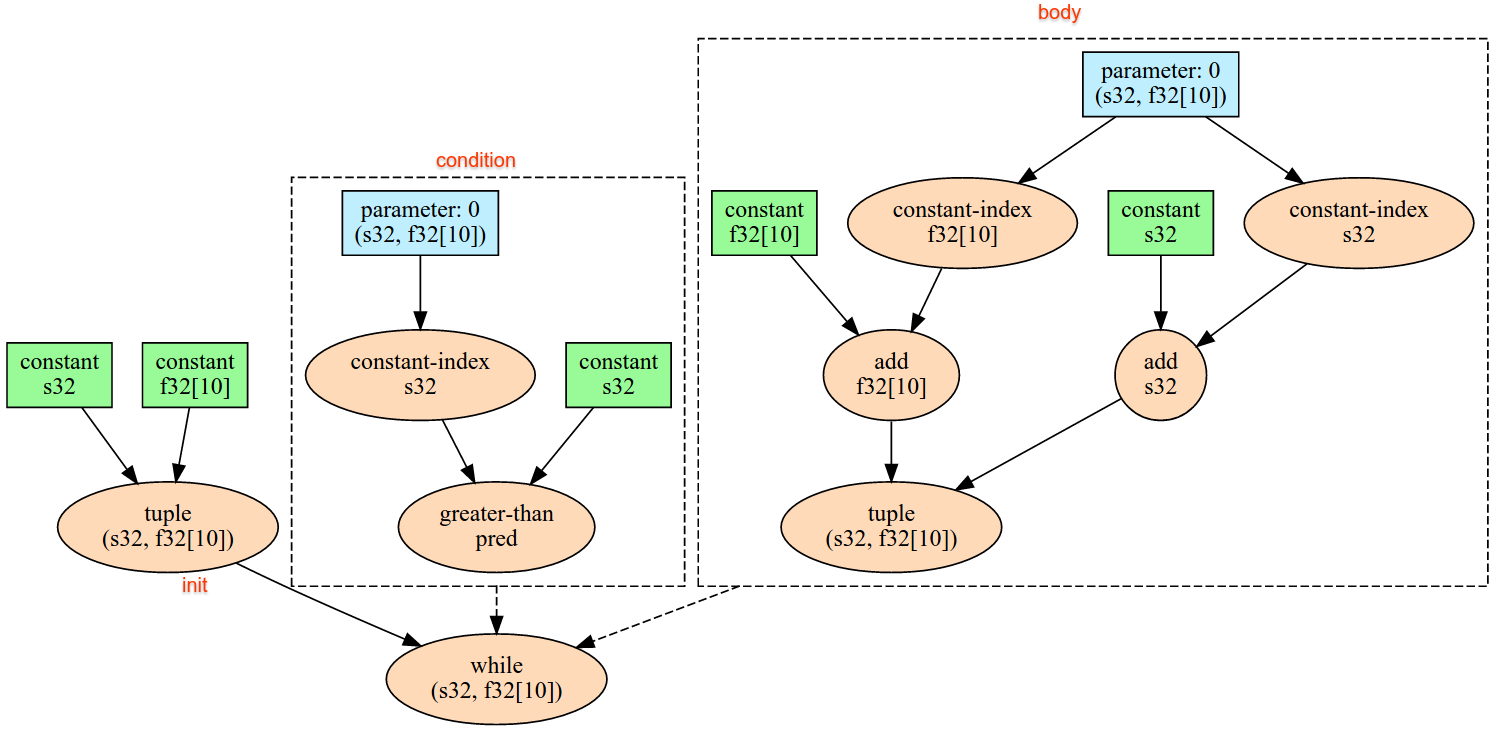
ลด (Reduce)
โปรดดูXlaBuilder::Reduce
ใช้ฟังก์ชันการลดกับอาร์เรย์อย่างน้อย 1 รายการพร้อมกัน
Reduce(operands..., init_values..., computation, dimensions)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operands |
ลำดับของ N XlaOp |
อาร์เรย์ N ประเภท T_0, ..., T_{N-1} |
init_values |
ลำดับของ N XlaOp |
เวกเตอร์สเกลาร์ N รายการของประเภท T_0, ..., T_{N-1} |
computation |
XlaComputation |
การคำนวณประเภท T_0, ..., T_{N-1}, T_0, ..., T_{N-1} -> Collate(T_0, ..., T_{N-1}) |
dimensions |
int64 อาร์เรย์ |
อาร์เรย์มิติข้อมูลที่ไม่มีการเรียงลําดับที่จะลด |
สถานที่:
- N ต้องมากกว่าหรือเท่ากับ 1
- การคํานวณต้องเชื่อมโยงกัน "โดยประมาณ" (ดูด้านล่าง)
- อาร์เรย์อินพุตทั้งหมดต้องมีขนาดเท่ากัน
- ค่าเริ่มต้นทั้งหมดต้องสร้างตัวระบุภายใต้
computation - หากเป็น
N = 1Collate(T)จะเป็นT - หากเป็น
N > 1Collate(T_0, ..., T_{N-1})คือทูเปิลขององค์ประกอบNประเภทT
การดำเนินการนี้จะลดมิติข้อมูลอย่างน้อย 1 รายการของอาร์เรย์อินพุตแต่ละรายการให้เป็นสเกลาร์
อันดับของอาร์เรย์ที่แสดงผลแต่ละรายการคือ rank(operand) - len(dimensions) เอาต์พุตของการดำเนินการคือ Collate(Q_0, ..., Q_N) โดยที่ Q_i คืออาร์เรย์ประเภท T_i ซึ่งอธิบายมิติข้อมูลไว้ด้านล่าง
แบ็กเอนด์ที่แตกต่างกันจะเชื่อมโยงการคํานวณการลดอีกครั้งได้ ซึ่งอาจทําให้ตัวเลขแตกต่างกัน เนื่องจากฟังก์ชันการลดบางรายการ เช่น การเพิ่ม จะไม่เชื่อมโยงกับตัวเลขทศนิยม อย่างไรก็ตาม หากช่วงของข้อมูลถูกจํากัด การบวกแบบทศนิยมก็ใกล้เคียงกับการเชื่อมโยงสําหรับการใช้งานจริงส่วนใหญ่
ตัวอย่าง
เมื่อลดขนาดตามมิติข้อมูลหนึ่งในอาร์เรย์ 1D เดี่ยวที่มีค่า [10, 11,
12, 13] ด้วยฟังก์ชันการลด f (นี่คือ computation) จะคำนวณเป็น
f(10, f(11, f(12, f(init_value, 13)))
แต่ก็ยังมีโอกาสอื่นๆ อีกมากมาย เช่น
f(init_value, f(f(10, f(init_value, 11)), f(f(init_value, 12), f(init_value, 13))))
ต่อไปนี้เป็นตัวอย่างรหัสเทียมคร่าวๆ ของวิธีนำการลดลงโดยใช้ผลรวมเป็นการคำนวณการลดด้วยค่าเริ่มต้นเป็น 0
result_shape <- remove all dims in dimensions from operand_shape
# Iterate over all elements in result_shape. The number of r's here is equal
# to the rank of the result
for r0 in range(result_shape[0]), r1 in range(result_shape[1]), ...:
# Initialize this result element
result[r0, r1...] <- 0
# Iterate over all the reduction dimensions
for d0 in range(dimensions[0]), d1 in range(dimensions[1]), ...:
# Increment the result element with the value of the operand's element.
# The index of the operand's element is constructed from all ri's and di's
# in the right order (by construction ri's and di's together index over the
# whole operand shape).
result[r0, r1...] += operand[ri... di]
ต่อไปนี้คือตัวอย่างการลดอาร์เรย์ 2 มิติ (เมทริกซ์) รูปร่างมีลําดับ 2, มิติข้อมูล 0 ขนาด 2 และมิติข้อมูล 1 ขนาด 3
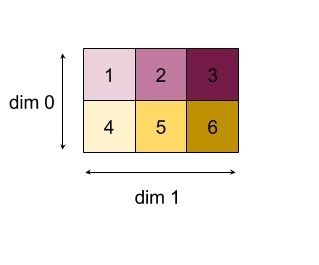
ผลลัพธ์ของการลดมิติข้อมูล 0 หรือ 1 ด้วยฟังก์ชัน "เพิ่ม"
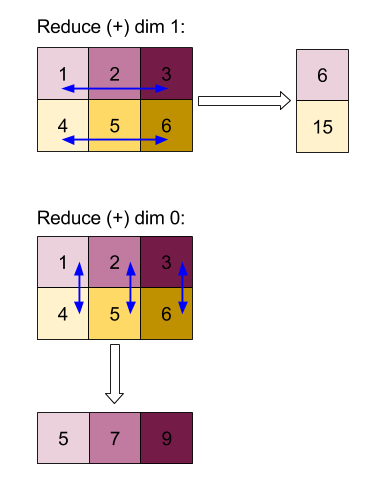
โปรดทราบว่าผลลัพธ์การลดทั้งคู่เป็นอาร์เรย์ 1D แผนภาพแสดงรายการหนึ่งเป็นคอลัมน์และอีกรายการหนึ่งเป็นแถวเพื่อความสะดวกในการมองเห็นเท่านั้น
ตัวอย่างที่ซับซ้อนมากขึ้นคืออาร์เรย์ 3 มิติ อันดับคือ 3, ขนาด 0 ของขนาด 4, ขนาด 1 ของขนาด 2 และมิติข้อมูล 2 ของขนาด 3 เพื่อความง่าย ระบบจะจำลองค่า 1 ถึง 6 ในมิติข้อมูล 0
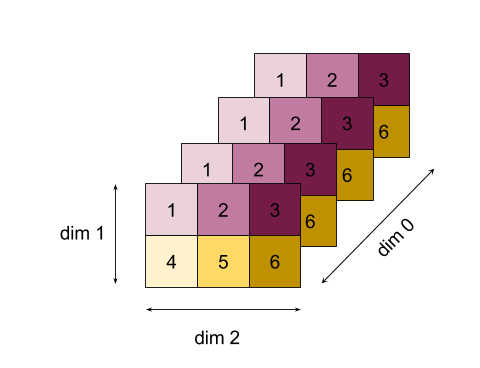
เช่นเดียวกับตัวอย่าง 2 มิติ เราสามารถลดมิติข้อมูลได้เพียงรายการเดียว ตัวอย่างเช่น หากเราลดมิติข้อมูล 0 เราจะได้อาร์เรย์อันดับ 2 โดยที่ค่าทั้งหมดในมิติข้อมูล 0 ถูกพับเป็นสเกลาร์
| 4 8 12 |
| 16 20 24 |
หากลดมิติข้อมูล 2 เราจะได้อาร์เรย์อันดับ 2 ที่ค่าทั้งหมดในมิติข้อมูล 2 ถูกรวมเป็นค่าสเกลาร์
| 6 15 |
| 6 15 |
| 6 15 |
| 6 15 |
โปรดทราบว่าลําดับสัมพัทธ์ระหว่างมิติข้อมูลที่เหลือในอินพุตจะยังคงอยู่ในเอาต์พุต แต่มิติข้อมูลบางรายการอาจได้รับการกําหนดหมายเลขใหม่ (เนื่องจากลําดับมีการเปลี่ยนแปลง)
นอกจากนี้ เรายังลดมิติข้อมูลหลายรายการได้ด้วย การเพิ่มมิติข้อมูลการลด 0 และ 1 จะสร้างอาร์เรย์ 1 มิติ [20, 28, 36]
การลดขนาดอาร์เรย์ 3 มิติในมิติข้อมูลทั้งหมดจะสร้างสเกลาร์ 84
การลดแบบ Variadic
เมื่อเป็น N > 1 การใช้งานฟังก์ชัน reduce จะซับซ้อนขึ้นเล็กน้อย เนื่องจากมีการใช้กับอินพุตทั้งหมดพร้อมกัน ระบบจะส่งตัวดำเนินการไปยังการคำนวณตามลําดับต่อไปนี้
- เรียกใช้ค่าที่ลดลงสำหรับตัวถูกดำเนินการแรก
- ...
- กำลังลดค่าสำหรับโอเปอเรนด์ที่ N
- ค่าที่ป้อนสำหรับตัวถูกดำเนินการแรก
- ...
- ค่าอินพุตสำหรับโอเปอเรนด์ที่ n
เช่น ลองพิจารณาฟังก์ชันการลดทอนต่อไปนี้ ซึ่งใช้ในการคำนวณค่าสูงสุดและ ARPMax ของอาร์เรย์ 1-D แบบขนานได้
f: (Float, Int, Float, Int) -> Float, Int
f(max, argmax, value, index):
if value >= max:
return (value, index)
else:
return (max, argmax)
สําหรับอาร์เรย์อินพุต 1 มิติ V = Float[N], K = Int[N] และค่าเริ่มต้น I_V = Float, I_K = Int ผลลัพธ์ f_(N-1) ของการลดมิติข้อมูลอินพุตเพียงมิติเดียวจะเทียบเท่ากับการใช้งานแบบซ้ำซ้อนต่อไปนี้
f_0 = f(I_V, I_K, V_0, K_0)
f_1 = f(f_0.first, f_0.second, V_1, K_1)
...
f_(N-1) = f(f_(N-2).first, f_(N-2).second, V_(N-1), K_(N-1))
การใช้การลดนี้กับอาร์เรย์ของค่า และอาร์เรย์ของดัชนีตามลำดับ (เช่น iota) จะทำซ้ำกับอาร์เรย์ และแสดงผล Tuple ที่มีค่าสูงสุดและดัชนีที่ตรงกัน
ReducePrecision
ดู XlaBuilder::ReducePrecision เพิ่มเติม
จำลองผลของการแปลงค่าทศนิยมเป็นรูปแบบที่มีความละเอียดต่ำลง (เช่น IEEE-FP16) และกลับไปยังรูปแบบเดิม คุณระบุจำนวนบิตของเลขชี้กำลังและเศษทศนิยมในรูปแบบความแม่นยำต่ำได้ตามต้องการ แต่การใช้งานฮาร์ดแวร์บางรุ่นอาจไม่รองรับขนาดบิตทั้งหมด
ReducePrecision(operand, mantissa_bits, exponent_bits)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ประเภทจุดลอยตัว T |
exponent_bits |
int32 |
จำนวนบิตเลขชี้กำลังในรูปแบบความแม่นยำต่ำ |
mantissa_bits |
int32 |
จำนวนบิตแมนทิสซาในรูปแบบที่มีความแม่นยำต่ำ |
ผลลัพธ์ที่ได้คืออาร์เรย์ประเภท T ระบบจะปัดเศษค่าอินพุตเป็นค่าที่ใกล้เคียงที่สุดซึ่งแสดงได้ด้วยจำนวนบิตส่วนทศนิยมที่ระบุ (โดยใช้ความหมาย "ปัดเศษให้ลงท้ายด้วยเลขคู่") และค่าที่เกินช่วงที่กำหนดโดยจำนวนบิตส่วนนัยสำคัญจะถูกจำกัดไว้ที่ค่าบวกหรือค่าลบอนันต์ ระบบจะเก็บค่า NaN ไว้ แม้ว่าจะแปลงเป็นค่า NaN ที่เป็นมาตรฐานก็ตาม
รูปแบบที่มีความละเอียดต่ำกว่าต้องมีบิตตัวคูณอย่างน้อย 1 บิต (เพื่อแยกค่า 0 ออกจากค่าอนันต์ เนื่องจากทั้ง 2 ค่ามีเศษทศนิยมเป็น 0) และต้องมีจำนวนบิตเศษทศนิยมที่ไม่เป็นลบ จำนวนบิตเลขยกกำลังหรือส่วนทศนิยมอาจมากกว่าค่าที่เกี่ยวข้องสำหรับประเภท T จากนั้นส่วนที่เกี่ยวข้องของการเปลี่ยนรูปแบบจะใช้งานไม่ได้
ReduceScatter
โปรดดูXlaBuilder::ReduceScatter
ReduceScatter เป็นการดำเนินการแบบรวมที่ทํา AllReduce อย่างมีประสิทธิภาพ แล้วกระจายผลลัพธ์โดยแบ่งออกเป็นบล็อก shard_count ตาม scatter_dimension และรีพลิคา i ในกลุ่มรีพลิคาจะได้รับข้อมูล ith ของกลุ่ม
ReduceScatter(operand, computation, scatter_dim, shard_count,
replica_group_ids, channel_id)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์หรือ Tuple ของอาร์เรย์ที่ไม่ว่างเปล่าเพื่อลดในหลายตัวจำลอง |
computation |
XlaComputation |
การคำนวณการลด |
scatter_dimension |
int64 |
มิติข้อมูลที่จะกระจาย |
shard_count |
int64 |
จำนวนบล็อกที่จะแยก scatter_dimension |
replica_groups |
เวกเตอร์ของเวกเตอร์ของ int64 |
กลุ่มที่ใช้การลด |
channel_id |
ไม่บังคับ int64 |
รหัสแชแนลที่ไม่บังคับสําหรับการสื่อสารข้ามโมดูล |
- เมื่อ
operandเป็นทูเปิลของอาร์เรย์ ระบบจะดำเนินการลดการกระจายกับองค์ประกอบแต่ละรายการของทูเปิล replica_groupsคือรายการของกลุ่มการจำลองซึ่งมีการดำเนินการลด (รหัสการจำลองสำหรับตัวจำลองปัจจุบันจะดึงได้โดยใช้ReplicaId) ลำดับของตัวจำลองในแต่ละกลุ่มจะเป็นตัวกำหนดลำดับที่ผลลัพธ์ที่ลดลงทั้งหมดจะกระจัดกระจายreplica_groupsต้องว่างเปล่า (ในกรณีที่ตัวจำลองทั้งหมดอยู่ในกลุ่มเดียว) หรือมีจำนวนองค์ประกอบเท่ากับจำนวนตัวจำลอง เมื่อมีกลุ่มรีพลิคามากกว่า 1 กลุ่ม กลุ่มทั้งหมดต้องมีขนาดเท่ากัน ตัวอย่างเช่นreplica_groups = {0, 2}, {1, 3}จะลดระหว่างข้อมูลจำลอง0และ2รวมถึง1และ3จากนั้นจึงกระจายผลลัพธ์shard_countคือขนาดของกลุ่มข้อมูลจำลองแต่ละกลุ่ม เราต้องการข้อมูลนี้ในกรณีที่replica_groupsว่างเปล่า หากreplica_groupsไม่ว่างเปล่าshard_countต้องเท่ากับขนาดของกลุ่มสําเนาแต่ละกลุ่มchannel_idใช้สำหรับการสื่อสารข้ามโมดูล: เฉพาะreduce-scatterการดำเนินการที่มีchannel_idเดียวกันเท่านั้นที่จะสื่อสารกันได้
รูปร่างเอาต์พุตคือรูปร่างอินพุตที่เล็กลง scatter_dimension เท่า เช่น หากมีตัวจำลอง 2 ตัว และตัวถูกดำเนินการมีค่า [1.0, 2.25] และ [3.0, 5.25] ในการจำลองทั้ง 2 ตามลำดับ ค่าเอาต์พุตจากการดำเนินการนี้ที่ scatter_dim คือ 0 จะเป็น [4.0] สำหรับตัวจำลองแรกและ [7.5] สำหรับตัวจำลองที่ 2
ReduceWindow
ดู XlaBuilder::ReduceWindow เพิ่มเติม
ใช้ฟังก์ชันการลดกับองค์ประกอบทั้งหมดในกรอบเวลาแต่ละเฟรมของอาร์เรย์หลายมิติ N รายการ ซึ่งจะสร้างอาร์เรย์หลายมิติ N รายการเดียวหรือหลายรายการเป็นเอาต์พุต อาร์เรย์เอาต์พุตแต่ละรายการมีจำนวนองค์ประกอบเท่ากับจำนวนตำแหน่งที่ถูกต้องของกรอบเวลา เลเยอร์ร่วมอาจแสดงเป็น ReduceWindow เช่นเดียวกับ Reduce computation ที่ใช้จะส่งผ่าน init_values ทางด้านซ้ายเสมอ
ReduceWindow(operands..., init_values..., computation, window_dimensions,
window_strides, padding)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operands |
N XlaOps |
ลำดับของอาร์เรย์หลายมิติของประเภท T_0,..., T_{N-1} จำนวน N รายการ โดยแต่ละชุดแสดงพื้นที่ฐานที่วางหน้าต่างไว้ |
init_values |
N XlaOps |
ค่าเริ่มต้น N ค่าสำหรับการลด ซึ่งจะมี 1 ค่าสําหรับแต่ละตัวดำเนินการ N รายการ ดูรายละเอียดได้ที่ลด |
computation |
XlaComputation |
ฟังก์ชันการลดประเภท T_0, ..., T_{N-1}, T_0, ..., T_{N-1} -> Collate(T_0, ..., T_{N-1}) เพื่อใช้กับองค์ประกอบในแต่ละกรอบเวลาของโอเปอเรนด์อินพุตทั้งหมด |
window_dimensions |
ArraySlice<int64> |
อาร์เรย์ของจำนวนเต็มสำหรับค่ามิติข้อมูลกรอบเวลา |
window_strides |
ArraySlice<int64> |
อาร์เรย์ของจำนวนเต็มสำหรับค่าระยะห่างระหว่างกรอบเวลา |
base_dilations |
ArraySlice<int64> |
อาร์เรย์ของจำนวนเต็มสำหรับค่าการขยายฐาน |
window_dilations |
ArraySlice<int64> |
อาร์เรย์ของจำนวนเต็มสำหรับค่าการขยายหน้าต่าง |
padding |
Padding |
ประเภทการเติมสำหรับกรอบ (Padding::kSame ซึ่งเติมเพื่อให้เอาต์พุตมีรูปร่างเหมือนกับอินพุตหากระยะห่างระหว่างองค์ประกอบคือ 1 หรือ Padding::kValid ซึ่งไม่ใช้การเติมและ "หยุด" กรอบเมื่อไม่พอดีอีกต่อไป) |
สถานที่:
- N ต้องมากกว่าหรือเท่ากับ 1
- อาร์เรย์อินพุตทั้งหมดต้องมีขนาดเท่ากัน
- หาก
N = 1Collate(T)คือT - หาก
N > 1Collate(T_0, ..., T_{N-1})จะเป็น Tuple ของNองค์ประกอบประเภท(T0,...T{N-1})
ด้านล่างโค้ดและรูปตัวอย่างการใช้ ReduceWindow อินพุตคือเมทริกซ์ขนาด [4x6] และทั้ง window_dimensions และ window_stride_dimensions คือ
[2x3]
// Create a computation for the reduction (maximum).
XlaComputation max;
{
XlaBuilder builder(client_, "max");
auto y = builder.Parameter(0, ShapeUtil::MakeShape(F32, {}), "y");
auto x = builder.Parameter(1, ShapeUtil::MakeShape(F32, {}), "x");
builder.Max(y, x);
max = builder.Build().value();
}
// Create a ReduceWindow computation with the max reduction computation.
XlaBuilder builder(client_, "reduce_window_2x3");
auto shape = ShapeUtil::MakeShape(F32, {4, 6});
auto input = builder.Parameter(0, shape, "input");
builder.ReduceWindow(
input,
/*init_val=*/builder.ConstantLiteral(LiteralUtil::MinValue(F32)),
*max,
/*window_dimensions=*/{2, 3},
/*window_stride_dimensions=*/{2, 3},
Padding::kValid);
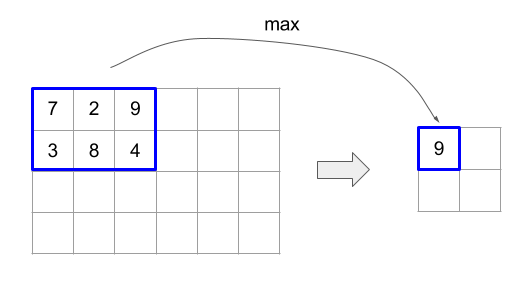
ระยะห่าง 1 ในมิติข้อมูลจะระบุว่าตําแหน่งของกรอบเวลาในมิติข้อมูลอยู่ห่างจากกรอบเวลาข้างเคียง 1 องค์ประกอบ หากต้องการระบุว่าไม่มีกรอบเวลาใดทับซ้อนกัน window_stride_dimensions ควรเท่ากับ window_dimensions รูปภาพด้านล่างแสดงการใช้ค่า Stride 2 ค่าที่แตกต่างกัน ระบบจะใช้การเติมให้กับมิติข้อมูลแต่ละรายการของอินพุต และการคำนวณจะเหมือนกับว่าอินพุตมีมิติข้อมูลหลังจากการเติม
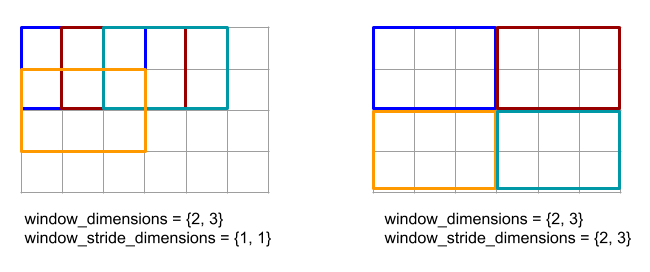
สําหรับตัวอย่างการเติมที่ไม่ซับซ้อน ให้พิจารณาคํานวณค่าต่ำสุดของกรอบเวลาการลด (ค่าเริ่มต้นคือ MAX_FLOAT) ที่มีมิติข้อมูล 3 และระยะห่าง 2 ในอาร์เรย์อินพุต [10000, 1000, 100, 10, 1] การป้อนค่าเพิ่ม kValid จะคํานวณค่าต่ำสุดในกรอบเวลา 2 กรอบที่ถูกต้อง ได้แก่ [10000, 1000, 100] และ [100, 10, 1] ซึ่งจะให้ผลลัพธ์เป็น [100, 1] การเพิ่ม kSame จะป้องกันอาร์เรย์รายการแรกเพื่อให้รูปร่างหลังหน้าต่างการลดเป็นเดียวกันกับอินพุตของระยะก้าว 1 โดยการเพิ่มองค์ประกอบเริ่มต้นทั้งสองด้าน จะได้ [MAX_VALUE, 10000, 1000, 100, 10, 1,
MAX_VALUE] การเรียกใช้หน้าต่างลดผ่านอาร์เรย์ที่เพิ่มทำงานใน 3 หน้าต่าง ได้แก่ [MAX_VALUE, 10000, 1000], [1000, 100, 10], [10, 1, MAX_VALUE] และผลตอบแทน [1000, 10, 1]
ลำดับการประเมินของฟังก์ชันการลดจะกำหนดเองและอาจไม่แน่นอน ดังนั้น ฟังก์ชันการลดไม่ควรมีความละเอียดอ่อนมากเกินไปต่อการเชื่อมโยงใหม่ ดูรายละเอียดเพิ่มเติมได้ในการสนทนาเกี่ยวกับความเชื่อมโยงในบริบทของ Reduce
ReplicaId
ดู XlaBuilder::ReplicaId เพิ่มเติม
แสดงผลรหัสที่ไม่ซ้ำกัน (สเกลาร์ U32) ของข้อมูลจำลอง
ReplicaId()
รหัสที่ไม่ซ้ำกันของรีพลิคาแต่ละรายการคือจำนวนเต็มแบบไม่ลงนามในช่วง [0, N) โดยที่ N คือจํานวนรีพลิคา เนื่องจากตัวจำลองทั้งหมดเรียกใช้โปรแกรมเดียวกัน การเรียก ReplicaId() ในโปรแกรมจะแสดงผลค่าที่ต่างกันในตัวจำลองแต่ละรายการ
ปรับรูปร่าง
ดูการดำเนินการ XlaBuilder::Reshape และการดำเนินการ Collapse เพิ่มเติม
เปลี่ยนรูปร่างของมิติข้อมูลของอาร์เรย์เป็นการกําหนดค่าใหม่
Reshape(operand, new_sizes)
Reshape(operand, dimensions, new_sizes)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ประเภท T |
dimensions |
int64 เวกเตอร์ |
ลำดับการยุบมิติข้อมูล |
new_sizes |
int64 เวกเตอร์ |
เวกเตอร์ของขนาดของมิติข้อมูลใหม่ |
โดยหลักการแล้ว ให้ปรับรูปร่างของอาร์เรย์ให้เป็นเวกเตอร์แบบหนึ่งมิติของค่าข้อมูล จากนั้นจึงปรับแต่งเวกเตอร์นี้เป็นรูปร่างใหม่ อาร์กิวเมนต์อินพุตคืออาร์เรย์ที่กำหนดเองของประเภท T, เวกเตอร์เวลาคอมไพล์คงที่ของดัชนีมิติข้อมูล และเวกเตอร์คงที่ของเวลาคอมไพล์ของขนาดมิติข้อมูลสำหรับผลลัพธ์
ค่าในเวกเตอร์ dimension (หากระบุ) ต้องเป็นการเปลี่ยนลําดับของมิติข้อมูลทั้งหมดของ T ค่าเริ่มต้นจะเป็น {0, ..., rank - 1} หากไม่ได้ระบุ ลําดับของมิติข้อมูลใน dimensions อยู่ในช่วงจากมิติข้อมูลที่ผันแปรช้าที่สุด (สำคัญที่สุด) ไปจนถึงมิติข้อมูลที่ผันแปรเร็วที่สุด (สำคัญน้อยที่สุด) ในเนสต์ลูปซึ่งยุบอาร์เรย์อินพุตเป็นมิติข้อมูลเดียว เวกเตอร์ new_sizes จะกำหนดขนาดของอาร์เรย์เอาต์พุต ค่าที่ดัชนี 0 ใน new_sizes คือขนาดของมิติข้อมูล 0 ค่าที่ดัชนี 1 คือขนาดของมิติข้อมูล 1 และอื่นๆ ผลคูณของมิติข้อมูล new_size ต้องเท่ากับผลคูณของขนาดมิติข้อมูลของออพเพอร์แซนด์ เมื่อปรับแต่งอาร์เรย์แบบยุบเป็นอาร์เรย์มิติข้อมูลที่กําหนดโดย new_sizes ระบบจะจัดลําดับมิติข้อมูลใน new_sizes โดยเริ่มจากมิติข้อมูลที่เปลี่ยนแปลงช้าที่สุด (สำคัญที่สุด) ไปจนถึงมิติข้อมูลที่เปลี่ยนแปลงเร็วที่สุด (สำคัญน้อยที่สุด)
ตัวอย่างเช่น สมมติให้ v เป็นอาร์เรย์ที่มีองค์ประกอบ 24 รายการ
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
In-order collapse:
let v012_24 = Reshape(v, {0,1,2}, {24});
then v012_24 == f32[24] {10, 11, 12, 15, 16, 17, 20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37, 40, 41, 42, 45, 46, 47};
let v012_83 = Reshape(v, {0,1,2}, {8,3});
then v012_83 == f32[8x3] { {10, 11, 12}, {15, 16, 17},
{20, 21, 22}, {25, 26, 27},
{30, 31, 32}, {35, 36, 37},
{40, 41, 42}, {45, 46, 47} };
Out-of-order collapse:
let v021_24 = Reshape(v, {1,2,0}, {24});
then v012_24 == f32[24] {10, 20, 30, 40, 11, 21, 31, 41, 12, 22, 32, 42,
15, 25, 35, 45, 16, 26, 36, 46, 17, 27, 37, 47};
let v021_83 = Reshape(v, {1,2,0}, {8,3});
then v021_83 == f32[8x3] { {10, 20, 30}, {40, 11, 21},
{31, 41, 12}, {22, 32, 42},
{15, 25, 35}, {45, 16, 26},
{36, 46, 17}, {27, 37, 47} };
let v021_262 = Reshape(v, {1,2,0}, {2,6,2});
then v021_262 == f32[2x6x2] { { {10, 20}, {30, 40},
{11, 21}, {31, 41},
{12, 22}, {32, 42} },
{ {15, 25}, {35, 45},
{16, 26}, {36, 46},
{17, 27}, {37, 47} } };
ในกรณีพิเศษ reshape สามารถเปลี่ยนอาร์เรย์องค์ประกอบเดียวเป็นสกัลาร์และในทางกลับกัน ตัวอย่างเช่น
Reshape(f32[1x1] { {5} }, {0,1}, {}) == 5;
Reshape(5, {}, {1,1}) == f32[1x1] { {5} };
Rev (ย้อนกลับ)
ดู XlaBuilder::Rev เพิ่มเติม
Rev(operand, dimensions)
| อาร์กิวเมนต์ | ประเภท | อรรถศาสตร์ |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ประเภท T |
dimensions |
ArraySlice<int64> |
มิติข้อมูลที่จะให้เปลี่ยน |
กลับลําดับองค์ประกอบในอาร์เรย์ operand ตาม dimensions ที่ระบุ ซึ่งจะสร้างอาร์เรย์เอาต์พุตที่มีรูปร่างเดียวกัน ระบบจะจัดเก็บองค์ประกอบแต่ละรายการของอาร์เรย์โอเปอเรนด์ที่ดัชนีมัลติไดเมนชันไว้ในอาร์เรย์เอาต์พุตที่ดัชนีที่เปลี่ยนรูปแบบ ดัชนีมิติข้อมูลหลายมิติจะเปลี่ยนรูปแบบโดยการกลับดัชนีในแต่ละมิติข้อมูลที่จะเปลี่ยน (กล่าวคือ หากมิติข้อมูลขนาด N เป็นหนึ่งในมิติข้อมูลที่เปลี่ยนรูปแบบ ดัชนี i ของมิติข้อมูลดังกล่าวจะเปลี่ยนรูปแบบเป็น N - 1 - i)
การใช้งานอย่างหนึ่งของการดำเนินการ Rev คือการเปลี่ยนลําดับอาร์เรย์น้ำหนักการกรองตามขนาดของกรอบเวลา 2 รายการในระหว่างการคํานวณอนุพันธ์ในเครือข่ายประสาทเทียม
RngNormal
โปรดดูXlaBuilder::RngNormal
สร้างเอาต์พุตของรูปร่างหนึ่งๆ ด้วยตัวเลขสุ่มที่สร้างขึ้นตาม N(μ,σ) การแจกแจงแบบปกติ พารามิเตอร์ μ และ σรวมถึงรูปแบบเอาต์พุตต้องมีประเภทองค์ประกอบจำนวนจุดลอยตัว นอกจากนี้ พารามิเตอร์จะต้องมีค่าสเกลาร์
RngNormal(mu, sigma, shape)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
mu |
XlaOp |
สเกลาร์ประเภท T ที่ระบุค่าเฉลี่ยของตัวเลขที่สร้างขึ้น |
sigma |
XlaOp |
สเกลาร์ประเภท T ที่ระบุค่าเบี่ยงเบนมาตรฐานของข้อมูลที่สร้างขึ้น |
shape |
Shape |
รูปร่างเอาต์พุตประเภท T |
RngUniform
ดู XlaBuilder::RngUniform เพิ่มเติม
สร้างเอาต์พุตของรูปร่างหนึ่งๆ ด้วยตัวเลขสุ่มที่สร้างขึ้นตามการแจกแจงแบบสม่ำเสมอในช่วง [a,b)พารามิเตอร์และประเภทองค์ประกอบเอาต์พุตต้องเป็นประเภทบูลีน ประเภทจำนวนเต็ม หรือประเภททศนิยม และประเภทต้องสอดคล้องกัน ปัจจุบันแบ็กเอนด์ของ CPU และ GPU รองรับเฉพาะ F64, F32, F16, BF16, S64, U64, S32 และ U32 นอกจากนี้ พารามิเตอร์ต้องเป็นค่าสเกลาร์ หาก b<=a ผลลัพธ์คือ มีการระบุการใช้งาน
RngUniform(a, b, shape)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
a |
XlaOp |
สเกลาร์ของประเภท T ที่ระบุขีดจำกัดล่างของช่วง |
b |
XlaOp |
สเกลาร์ของประเภท T ที่ระบุขีดจำกัดสูงสุดของช่วง |
shape |
Shape |
รูปร่างเอาต์พุตประเภท T |
RngBitGenerator
สร้างเอาต์พุตที่มีรูปร่างที่กำหนดซึ่งเต็มไปด้วยบิตแบบสุ่มแบบสม่ำเสมอโดยใช้อัลกอริทึมที่ระบุ (หรือค่าเริ่มต้นของแบ็กเอนด์) และแสดงผลสถานะที่อัปเดตแล้ว (ซึ่งมีรูปร่างเหมือนกับสถานะเริ่มต้น) และข้อมูลแบบสุ่มที่สร้างขึ้น
สถานะเริ่มต้นคือสถานะเริ่มต้นของการสร้างตัวเลขสุ่มปัจจุบัน ความยาวของรหัส รวมถึงรูปร่างและค่าที่ใช้ได้จะขึ้นอยู่กับอัลกอริทึมที่ใช้งาน
เรารับประกันว่าเอาต์พุตจะเป็นฟังก์ชันเชิงกำหนดของสถานะเริ่มต้น แต่ไม่รับประกันว่าจะมีการกำหนดสถานะระหว่างแบ็กเอนด์กับคอมไพเลอร์เวอร์ชันต่างๆ
RngBitGenerator(algorithm, key, shape)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
algorithm |
RandomAlgorithm |
อัลกอริทึม PRNG ที่จะใช้ |
initial_state |
XlaOp |
สถานะเริ่มต้นสำหรับอัลกอริทึม PRNG |
shape |
Shape |
รูปร่างเอาต์พุตสำหรับข้อมูลที่สร้างขึ้น |
ค่าที่ใช้ได้กับ algorithm:
rng_default: อัลกอริทึมเฉพาะแบ็กเอนด์ที่มีข้อกำหนดเฉพาะสำหรับรูปร่างของแบ็กเอนด์rng_three_fry: อัลกอริทึม PRNG ที่อิงตามตัวนับ ThreeFryinitial_stateรูปร่างคือu64[2]ที่มีค่าใดก็ได้ Salmon et al. SC 2011. สุ่มเลขคู่ขนานได้ง่ายๆ เหมือน 1, 2, 3rng_philox: อัลกอริทึม Philox เพื่อสร้างตัวเลขสุ่มแบบขนาน รูปร่างinitial_stateคือu64[3]ที่มีค่าที่กำหนดเอง Salmon et al. SC 2011. ตัวเลขสุ่มแบบขนาน: ง่ายเหมือนนับ 1 2 3
แผนภูมิกระจาย
การดำเนินการกระจาย XLA จะสร้างลำดับผลลัพธ์ซึ่งเป็นค่าของอาร์เรย์อินพุต operands โดยมีหลายส่วน (ที่ดัชนีที่ระบุโดย scatter_indices) ที่อัปเดตด้วยลำดับค่าใน updates โดยใช้ update_computation
ดู XlaBuilder::Scatter เพิ่มเติม
scatter(operands..., scatter_indices, updates..., update_computation,
index_vector_dim, update_window_dims, inserted_window_dims,
scatter_dims_to_operand_dims)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operands |
ลำดับของ N XlaOp |
อาร์เรย์ N ประเภท T_0, ..., T_N ที่จะกระจาย |
scatter_indices |
XlaOp |
อาร์เรย์ที่มีดัชนีเริ่มต้นของสไลซ์ที่ต้องกระจายไป |
updates |
ลำดับของ N XlaOp |
อาร์เรย์ N ประเภท T_0, ..., T_N updates[i] มีค่าที่ต้องใช้สําหรับการกระจาย operands[i] |
update_computation |
XlaComputation |
การคํานวณที่จะใช้รวมค่าที่มีอยู่ในอาร์เรย์อินพุตและการอัปเดตระหว่างการกระจาย การคํานวณนี้ควรเป็นประเภท T_0, ..., T_N, T_0, ..., T_N -> Collate(T_0, ..., T_N) |
index_vector_dim |
int64 |
มิติข้อมูลใน scatter_indices ที่มีดัชนีเริ่มต้น |
update_window_dims |
ArraySlice<int64> |
ชุดของมิติข้อมูลในรูปร่าง updates ที่เป็นขนาดหน้าต่าง |
inserted_window_dims |
ArraySlice<int64> |
ชุดขนาดหน้าต่างที่ต้องแทรกลงในรูปร่าง updates |
scatter_dims_to_operand_dims |
ArraySlice<int64> |
การแมปมิติข้อมูลจากดัชนีการกระจายไปยังพื้นที่ดัชนีออบเจ็กต์ ระบบจะตีความอาร์เรย์นี้เป็นการแมป i กับ scatter_dims_to_operand_dims[i] ซึ่งจะต้องเป็นแบบหนึ่งต่อหนึ่งและรวมทั้งหมด |
indices_are_sorted |
bool |
มีการรับประกันว่าผู้เรียกจะจัดเรียงดัชนีหรือไม่ |
unique_indices |
bool |
ผู้เรียกใช้รับประกันว่าดัชนีจะไม่ซ้ำกันหรือไม่ |
สถานที่:
- N ต้องมากกว่าหรือเท่ากับ 1
operands[0], ...,operands[N-1] ทั้งหมดต้องมีมิติข้อมูลเดียวกันupdates[0], ...,updates[N-1] ทั้งหมดต้องมีมิติข้อมูลเดียวกัน- หาก
N = 1Collate(T)คือT - หากเป็น
N > 1Collate(T_0, ..., T_N)คือทูเปิลขององค์ประกอบNประเภทT
หาก index_vector_dim เท่ากับ scatter_indices.rank เราจะถือว่า scatter_indices มีค่ามิติข้อมูล 1 ต่อท้ายโดยปริยาย
เรากําหนด update_scatter_dims ประเภท ArraySlice<int64> เป็นชุดมิติข้อมูลในรูปทรง updates ที่ไม่ได้อยู่ใน update_window_dims โดยเรียงตามลําดับจากน้อยไปมาก
อาร์กิวเมนต์ของการกระจายควรเป็นไปตามข้อจำกัดเหล่านี้
อาร์เรย์
updatesแต่ละรายการต้องมีอันดับupdate_window_dims.size + scatter_indices.rank - 1ขอบเขตของมิติข้อมูล
iในอาร์เรย์updatesแต่ละรายการต้องเป็นไปตามข้อกำหนดต่อไปนี้- หาก
iอยู่ในupdate_window_dims(นั่นคือ เท่ากับupdate_window_dims[k] สำหรับkบางรายการ) ขอบเขตของมิติข้อมูลiในupdatesต้องไม่เกินขอบเขตที่สอดคล้องกันของoperandหลังจากพิจารณาinserted_window_dimsแล้ว (นั่นคือadjusted_window_bounds[k] โดยที่adjusted_window_boundsมีขอบเขตของoperandโดยนำขอบเขตที่อยู่ที่อินเด็กซ์inserted_window_dimsออก) - หาก
iอยู่ในupdate_scatter_dims(นั่นคือ เท่ากับupdate_scatter_dims[k] สำหรับkบางรายการ) ขอบเขตของมิติข้อมูลiในupdatesจะต้องเท่ากับขอบเขตที่สอดคล้องกันของscatter_indicesโดยข้ามindex_vector_dim(นั่นคือscatter_indices.shape.dims[k] หากk<index_vector_dimและscatter_indices.shape.dims[k+1] ในกรณีอื่นๆ)
- หาก
update_window_dimsต้องเรียงลำดับจากน้อยไปมาก ไม่มีตัวเลขมิติข้อมูลที่ซ้ำกัน และอยู่ในช่วง[0, updates.rank)inserted_window_dimsต้องเรียงตามลําดับจากน้อยไปมาก ไม่มีหมายเลขมิติข้อมูลที่ซ้ำกัน และอยู่ในช่วง[0, operand.rank)operand.rankต้องเท่ากับผลรวมของupdate_window_dims.sizeและinserted_window_dims.sizescatter_dims_to_operand_dims.sizeต้องเท่ากับscatter_indices.shape.dims[index_vector_dim] และค่าต้องอยู่ในช่วง[0, operand.rank)
สําหรับดัชนี U หนึ่งๆ ในอาร์เรย์ updates แต่ละรายการ ระบบจะคํานวณดัชนี I ที่สอดคล้องกันในอาร์เรย์ operands ที่สอดคล้องกันซึ่งต้องนําการอัปเดตนี้ไปใช้ดังนี้
- สมมติให้
G= {U[k] สำหรับkในupdate_scatter_dims} ใช้Gเพื่อค้นหาเวกเตอร์อินเด็กซ์Sในอาร์เรย์scatter_indicesโดยที่S[i] =scatter_indices[Combine(G,i)] โดยที่ Combine(A, b) จะแทรก b ที่ตําแหน่งindex_vector_dimลงใน A - สร้างดัชนี
Sinลงในoperandโดยใช้SโดยการกระจายSโดยใช้แผนที่scatter_dims_to_operand_dimsรูปแบบที่เป็นทางการคือSin[scatter_dims_to_operand_dims[k]] =S[k] หากk<scatter_dims_to_operand_dims.sizeSin[_] = หากไม่ใช่0
- สร้างดัชนี
Winลงในอาร์เรย์operandsแต่ละรายการโดยการกระจายดัชนีที่update_window_dimsในUตามinserted_window_dimsอย่างเป็นทางการเพิ่มเติมWin[window_dims_to_operand_dims(k)] =U[k] หากkอยู่ในupdate_window_dimsโดยที่window_dims_to_operand_dimsเป็นฟังก์ชันแบบ Monotonic ที่มีโดเมน [0,update_window_dims.size) และช่วง [0,operand.rank) \inserted_window_dims(เช่น หากupdate_window_dims.sizeคือ4,operand.rankคือ6และinserted_window_dimsคือ {0,2}window_dims_to_operand_dimsจะเป็น {0→1,1→3,2→4,3→5})Win[_] = หากไม่ใช่0
IคือWin+Sinโดยที่ + คือการบวกทีละองค์ประกอบ
โดยสรุปแล้ว การดำเนินการ Scatter สามารถกำหนดได้ดังนี้
- เริ่มต้น
outputด้วยoperandsกล่าวคือ สําหรับดัชนีJทั้งหมด สําหรับดัชนีOทั้งหมดในอาร์เรย์operands[J]:
output[J][O] =operands[J][O] - สำหรับทุกดัชนี
Uในอาร์เรย์updates[J] และดัชนีที่เกี่ยวข้องOในอาร์เรย์operand[J] หากOเป็นดัชนีที่ถูกต้องสำหรับoutput:
(output[0][O], ...,output[N-1][O]) =update_computation(output[0][O], ..., ,output[N-1][O],updates[0][U], ...,updates[N-1][U])
ลำดับการใช้การอัปเดตนั้นไม่แน่นอน ดังนั้นเมื่อหลายดัชนีใน updates อ้างอิงดัชนีเดียวกันใน operands ค่าที่สัมพันธ์กันใน output จะเป็นแบบกำหนดไม่ได้
โปรดทราบว่าพารามิเตอร์แรกที่ส่งไปยัง update_computation จะถือเป็นค่าปัจจุบันจากอาร์เรย์ output เสมอ และพารามิเตอร์ที่ 2 จะถือเป็นค่าจากอาร์เรย์ updates เสมอ ซึ่งสำคัญอย่างยิ่งสำหรับกรณีที่ update_computation ไม่ใช่แบบเปลี่ยนตำแหน่งได้
หากตั้งค่า indices_are_sorted เป็น "จริง" XLA จะถือว่ามีการจัดเรียง scatter_indices (ตามลำดับจากน้อยไปมาก หลังการกระจายค่าตาม scatter_dims_to_operand_dims) โดยผู้ใช้ หากไม่มี ความหมายจะกำหนดโดยการใช้งาน
หากตั้งค่า unique_indices เป็น "จริง" แล้ว XLA จะถือว่าองค์ประกอบทั้งหมดที่กระจัดกระจายไปนั้นไม่ซ้ำกัน ดังนั้น XLA จึงใช้การดำเนินการแบบไม่สมบูรณ์ได้ หากตั้งค่า unique_indices เป็น "จริง" และอินเด็กซ์ที่กระจายไปไม่ซ้ำกัน ความหมายจะกำหนดโดยการใช้งาน
ในทางเทคนิค คุณสามารถมองการดำเนินการ Scatter เป็นการดำเนินการผกผันของการดำเนินการ Gather กล่าวคือ การดำเนินการ Scatter จะอัปเดตองค์ประกอบในอินพุตที่ดึงมาจากการดำเนินการ Gather ที่เกี่ยวข้อง
ดูคำอธิบายและตัวอย่างแบบไม่เป็นทางการโดยละเอียดได้ที่ส่วน "คำอธิบายแบบไม่เป็นทางการ" ในส่วน Gather
เลือก
โปรดดูXlaBuilder::Select
สร้างอาร์เรย์เอาต์พุตจากองค์ประกอบของอาร์เรย์อินพุต 2 รายการ โดยอิงตามค่าของอาร์เรย์พริเนกต์
Select(pred, on_true, on_false)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
pred |
XlaOp |
อาร์เรย์ของประเภท PRED |
on_true |
XlaOp |
อาร์เรย์ประเภท T |
on_false |
XlaOp |
อาร์เรย์ประเภท T |
อาร์เรย์ on_true และ on_false ต้องมีรูปร่างเหมือนกัน ซึ่งก็คือรูปแบบของอาร์เรย์เอาต์พุตด้วย อาร์เรย์ pred ต้องมีมิติข้อมูลเดียวกันกับ on_true และ on_false โดยมีประเภทองค์ประกอบ PRED
สําหรับองค์ประกอบ P แต่ละรายการของ pred ระบบจะนําองค์ประกอบที่สอดคล้องกันของอาร์เรย์เอาต์พุตจาก on_true หากค่าของ P เป็น true และจาก on_false หากค่าของ P เป็น false pred อาจเป็นสเกลาร์ประเภท PRED เนื่องจากเป็นรูปแบบการออกอากาศแบบจํากัด ในกรณีนี้ ระบบจะนำอาร์เรย์เอาต์พุตทั้งหมดจาก on_true หาก pred เป็น true และจาก on_false หาก pred เป็น false
ตัวอย่างที่มี pred ที่ไม่ใช่สเกลาร์
let pred: PRED[4] = {true, false, false, true};
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 200, 300, 4};
ตัวอย่างที่มีสเกลาร์ pred
let pred: PRED = true;
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 2, 3, 4};
รองรับการเลือกเตียงเดี่ยว Tuple ถือเป็นประเภทสเกลาร์
สำหรับวัตถุประสงค์นี้ หาก on_true และ on_false เป็นทูเพล (ซึ่งต้องมีรูปร่างเหมือนกัน) pred ต้องเป็นสเกลาร์ประเภท PRED
SelectAndScatter
โปรดดูXlaBuilder::SelectAndScatter
การดำเนินการนี้ถือได้ว่าเป็นการดำเนินการแบบคอมโพสิทที่เริ่มด้วยการคำนวณ ReduceWindow ในอาร์เรย์ operand เพื่อเลือกองค์ประกอบจากแต่ละกรอบเวลา แล้วกระจายอาร์เรย์ source ไปยังอินเด็กซ์ขององค์ประกอบที่เลือกเพื่อสร้างอาร์เรย์เอาต์พุตที่มีรูปร่างเหมือนกับอาร์เรย์ออบเจ็กต์ ฟังก์ชันไบนารี select ใช้เพื่อเลือกองค์ประกอบจากแต่ละกรอบเวลาโดยใช้กับแต่ละกรอบเวลา และเรียกใช้ด้วยพร็อพเพอร์ตี้ที่เวกเตอร์อินเด็กซ์ของพารามิเตอร์แรกมีค่าน้อยกว่าเวกเตอร์อินเด็กซ์ของพารามิเตอร์ที่ 2 ตามลําดับตัวอักษร ฟังก์ชัน select จะแสดงผล true หากเลือกพารามิเตอร์แรกและแสดงผล false หากเลือกพารามิเตอร์ที่ 2 และฟังก์ชันจะต้องเก็บทรานซิชัน (เช่น หาก select(a, b) และ select(b, c) เป็น true แล้ว select(a, c) จะเป็น true ด้วย) เพื่อที่องค์ประกอบที่เลือกจะไม่ขึ้นอยู่กับลำดับขององค์ประกอบข้ามผ่านหน้าต่างที่กำหนด
ฟังก์ชัน scatter จะถูกนำไปใช้กับดัชนีที่เลือกแต่ละรายการในอาร์เรย์เอาต์พุต โดยใช้พารามิเตอร์สเกลาร์ 2 รายการดังนี้
- ค่าปัจจุบันที่ดัชนีที่เลือกในอาร์เรย์เอาต์พุต
- ค่ากระจายจาก
sourceที่ใช้กับดัชนีที่เลือก
โดยจะรวมพารามิเตอร์ 2 รายการเข้าด้วยกันและแสดงผลค่าสเกลาร์ที่ใช้เพื่ออัปเดตค่าที่อินเด็กซ์ที่เลือกในอาร์เรย์เอาต์พุต ในช่วงแรก ดัชนีทั้งหมดของอาร์เรย์เอาต์พุตตั้งค่าเป็น init_value
อาร์เรย์เอาต์พุตมีรูปร่างเหมือนกับอาร์เรย์ operand และอาร์เรย์ source ต้องมีรูปร่างเหมือนกับผลลัพธ์จากการใช้การดำเนินการ ReduceWindow กับอาร์เรย์ operand SelectAndScatter สามารถใช้เพื่อย้อนกลับค่าอนุพันธ์ของชั้นการรวมข้อมูลในเครือข่ายประสาทได้
SelectAndScatter(operand, select, window_dimensions, window_strides,
padding, source, init_value, scatter)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ประเภท T ที่หน้าต่างเลื่อนผ่าน |
select |
XlaComputation |
การคํานวณแบบไบนารีของประเภท T, T -> PRED เพื่อใช้กับองค์ประกอบทั้งหมดในหน้าต่างแต่ละหน้าต่าง แสดงผล true หากเลือกพารามิเตอร์แรก และแสดงผล false หากเลือกพารามิเตอร์ที่ 2 |
window_dimensions |
ArraySlice<int64> |
อาร์เรย์ของจำนวนเต็มสำหรับค่ามิติข้อมูลกรอบเวลา |
window_strides |
ArraySlice<int64> |
อาร์เรย์ของจำนวนเต็มสำหรับค่าระยะห่างระหว่างกรอบเวลา |
padding |
Padding |
ประเภทการเว้นวรรคสำหรับกรอบเวลา (Padding::kSame หรือ Padding::kValid) |
source |
XlaOp |
อาร์เรย์ประเภท T ที่มีค่าที่จะกระจาย |
init_value |
XlaOp |
ค่าสเกลาร์ของประเภท T สำหรับค่าเริ่มต้นของอาร์เรย์เอาต์พุต |
scatter |
XlaComputation |
การคำนวณไบนารีประเภท T, T -> T เพื่อใช้องค์ประกอบต้นทางแบบกระจายแต่ละรายการกับองค์ประกอบปลายทาง |
รูปภาพด้านล่างแสดงตัวอย่างการใช้ SelectAndScatter โดยฟังก์ชัน select จะคํานวณค่าสูงสุดจากพารามิเตอร์ โปรดทราบว่าเมื่อหน้าต่างทับซ้อนกันดังในรูปที่ (2) ด้านล่าง ระบบอาจเลือกดัชนีของอาร์เรย์ operand หลายครั้งโดยใช้หน้าต่างที่ต่างกัน ในรูปนี้ หน้าต่างด้านบนทั้ง 2 หน้าต่าง (สีฟ้าและสีแดง) จะเลือกองค์ประกอบของค่า 9 และฟังก์ชันการบวกไบนารี scatter จะสร้างองค์ประกอบเอาต์พุตของค่า 8 (2 + 6)
ลำดับการประเมินของฟังก์ชัน scatter เป็นแบบกำหนดเองและอาจไม่ใช่แบบกำหนดได้ ดังนั้น ฟังก์ชัน scatter ไม่ควรมีความละเอียดอ่อนมากเกินไปต่อการเชื่อมโยงใหม่ ดูรายละเอียดเพิ่มเติมได้ในการสนทนาเกี่ยวกับความเชื่อมโยงในบริบทของ Reduce
ส่ง
โปรดดูXlaBuilder::Send
Send(operand, channel_handle)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ข้อมูลที่จะส่ง (อาร์เรย์ประเภท T) |
channel_handle |
ChannelHandle |
ตัวระบุที่ไม่ซ้ำกันสำหรับคู่การส่ง/รับแต่ละคู่ |
ส่งข้อมูลโอเปอเรนด์ที่ระบุไปยังคำสั่ง Recv ในการคำนวณอื่นที่ใช้แฮนเดิลแชแนลเดียวกัน ไม่แสดงข้อมูลใดๆ
เช่นเดียวกับการดำเนินการ Recv API ของไคลเอ็นต์สำหรับการดำเนินการ Send จะแสดงการสื่อสารแบบซิงค์ และแยกออกเป็นคำสั่ง HLO 2 รายการ (Send และ SendDone) ภายในเพื่อให้โอนข้อมูลแบบแอซิงค์ได้ ดู HloInstruction::CreateSend และ HloInstruction::CreateSendDone เพิ่มเติม
Send(HloInstruction operand, int64 channel_id)
เริ่มการโอนแบบไม่พร้อมกันของออพอเรนดไปยังทรัพยากรที่จัดสรรโดยคำสั่ง Recv ที่มีรหัสแชแนลเดียวกัน แสดงผลบริบท ซึ่งSendDoneคำสั่งต่อไปนี้จะใช้เพื่อรอการโอนข้อมูลให้เสร็จสมบูรณ์ บริบทคือทูเปิลของ {operand (shape), request identifier (U32)} และสามารถใช้ได้กับคำสั่ง SendDone เท่านั้น
SendDone(HloInstruction context)
เมื่อได้รับบริบทที่สร้างโดยคำสั่ง Send จะรอให้โอนข้อมูลเสร็จสมบูรณ์ คำสั่งไม่แสดงข้อมูลใดๆ
การกำหนดเวลาของวิธีการในช่อง
ลำดับการดำเนินการตามวิธีการ 4 รายการสำหรับแต่ละช่องทาง (Recv, RecvDone, Send, SendDone) มีดังนี้
Recvเกิดขึ้นก่อนSendSendเกิดขึ้นก่อนRecvDoneRecvเกิดขึ้นก่อนRecvDoneSendเกิดขึ้นก่อนSendDone
เมื่อคอมไพเลอร์แบ็กเอนด์สร้างกำหนดการเชิงเส้นสำหรับการประมวลผลแต่ละรายการที่สื่อสารผ่านคำสั่งของแชแนล ต้องไม่มีรอบการประมวลผล ตัวอย่างเช่น กําหนดการด้านล่างทําให้เกิดการล็อกตาย
Slice
โปรดดูXlaBuilder::Slice
การแบ่งส่วนจะดึงอาร์เรย์ย่อยจากอาร์เรย์อินพุต อาร์เรย์ย่อยมีลําดับชั้นเดียวกับอินพุตและมีค่าภายในกล่องขอบเขตภายในอาร์เรย์อินพุต โดยที่มิติข้อมูลและดัชนีของกล่องขอบเขตจะใช้เป็นอาร์กิวเมนต์สําหรับการดำเนินการตัด
Slice(operand, start_indices, limit_indices, strides)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
อาร์เรย์ N มิติข้อมูลของประเภท T |
start_indices |
ArraySlice<int64> |
รายการจำนวนเต็ม N ที่มีดัชนีเริ่มต้นของสไลซ์สำหรับแต่ละมิติข้อมูล ค่าต้องมากกว่าหรือเท่ากับ 0 |
limit_indices |
ArraySlice<int64> |
รายการจำนวนเต็ม N ที่มีดัชนีสิ้นสุด (ไม่รวม) ของส่วนสำหรับแต่ละมิติข้อมูล แต่ละค่าต้องมากกว่าหรือเท่ากับค่า start_indices ที่เกี่ยวข้องสําหรับมิติข้อมูล และน้อยกว่าหรือเท่ากับขนาดของมิติข้อมูล |
strides |
ArraySlice<int64> |
รายการจำนวนเต็ม N ที่กําหนดระยะห่างของข้อมูลอินพุตของส่วน ส่วนเลือกจะเลือกองค์ประกอบ strides[d] รายการในทุกมิติข้อมูล d |
ตัวอย่างแบบ 1 มิติ
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
Slice(a, {2}, {4}) produces:
{2.0, 3.0}
ตัวอย่างแบบ 2 มิติ
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
Slice(b, {2, 1}, {4, 3}) produces:
{ { 7.0, 8.0},
{10.0, 11.0} }
จัดเรียง
ดู XlaBuilder::Sort เพิ่มเติม
Sort(operands, comparator, dimension, is_stable)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operands |
ArraySlice<XlaOp> |
ออบเจ็กต์ที่จะจัดเรียง |
comparator |
XlaComputation |
การคำนวณตัวเปรียบเทียบที่จะใช้ |
dimension |
int64 |
มิติข้อมูลที่จะจัดเรียง |
is_stable |
bool |
ควรใช้การจัดเรียงแบบคงที่หรือไม่ |
หากระบุตัวถูกดำเนินการเพียงรายการเดียว
ถ้าตัวถูกดำเนินการคือ tensor อันดับ 1 (อาร์เรย์) ผลลัพธ์จะเป็นอาร์เรย์ที่มีการจัดเรียง หากต้องการจัดเรียงอาร์เรย์ตามลําดับจากน้อยไปมาก ตัวเปรียบเทียบควรทําการเปรียบเทียบน้อยกว่า ในทางเทคนิคแล้ว หลังจากจัดเรียงอาร์เรย์แล้ว อาร์เรย์จะถือค่าไว้สำหรับตำแหน่งดัชนี
i, jทั้งหมดที่มีi < jซึ่งมีค่าเป็นcomparator(value[i], value[j]) = comparator(value[j], value[i]) = falseหรือcomparator(value[i], value[j]) = trueหากโอเปอเรนดมีลําดับสูงกว่า ระบบจะจัดเรียงโอเปอเรนดตามมิติข้อมูลที่ระบุ ตัวอย่างเช่น สำหรับเทนเซอร์อันดับ 2 (เมทริกซ์) ค่ามิติข้อมูล
0จะจัดเรียงทุกคอลัมน์แยกกัน และค่ามิติข้อมูล1จะจัดเรียงแต่ละแถวแยกกัน หากไม่ได้ระบุหมายเลขมิติข้อมูลไว้ ระบบจะเลือกมิติข้อมูลสุดท้ายโดยค่าเริ่มต้น สําหรับมิติข้อมูลที่จัดเรียง ระบบจะใช้ลําดับการจัดเรียงเดียวกับในกรณีอันดับ 1
หากระบุโอเปอเรนด์ n > 1 รายการ
ตัวถูกดำเนินการ
nทั้งหมดต้องเป็น Tensor ที่มีขนาดเดียวกัน ประเภทเอลิเมนต์ของ Tensor อาจแตกต่างกันระบบจะจัดเรียงโอเปอเรนดทั้งหมดพร้อมกัน ไม่ใช่แยกกัน ในทางแนวคิดแล้ว ระบบจะถือว่าโอเปอเรนดคือทูเปิล เมื่อตรวจสอบว่าต้องสลับองค์ประกอบของโอเปอเรนดแต่ละรายการที่ตําแหน่งอินเด็กซ์
iและjหรือไม่ ระบบจะเรียกใช้ตัวเปรียบเทียบด้วยพารามิเตอร์สเกลาร์2 * nโดยที่พารามิเตอร์2 * kสอดคล้องกับค่าที่ตําแหน่งiจากโอเปอเรนดk-thและพารามิเตอร์2 * k + 1สอดคล้องกับค่าที่ตําแหน่งjจากโอเปอเรนดk-thโดยปกติแล้ว ตัวเปรียบเทียบจะเปรียบเทียบพารามิเตอร์2 * kและ2 * k + 1ระหว่างกัน และอาจใช้คู่พารามิเตอร์อื่นเป็นเบรกเกอร์ผลลัพธ์คือทูเปิลที่ประกอบด้วยออบเจ็กต์การดำเนินการตามลําดับที่เรียงลําดับ (ตามมิติข้อมูลที่ระบุไว้ดังที่กล่าวไว้ข้างต้น) ออบเจ็กต์
i-thของทูเปิลจะสอดคล้องกับออบเจ็กต์i-thของ Sort
เช่น หากมีออบเจ็กต์ 3 รายการ ได้แก่ operand0 = [3, 1], operand1 = [42, 50] และ operand2 = [-3.0, 1.1] และตัวเปรียบเทียบจะเปรียบเทียบเฉพาะค่าของ operand0 กับ "น้อยกว่า" ผลลัพธ์ของการเรียงลําดับคือ ([1, 3], [50, 42], [1.1, -3.0])
หากตั้งค่า is_stable เป็น "จริง" ระบบจะรับประกันว่าการจัดเรียงจะมีความเสถียร กล่าวคือหากมีองค์ประกอบที่ตัวเปรียบเทียบถือว่าเท่ากัน ระบบจะคงลำดับสัมพัทธ์ของค่าที่เท่ากันไว้ องค์ประกอบ 2 รายการ ได้แก่ e1 และ e2
จะเท่ากันหากและเฉพาะในกรณีที่เป็น comparator(e1, e2) = comparator(e2, e1) = false โดยค่าเริ่มต้น ระบบจะตั้งค่า is_stable เป็น "เท็จ"
สลับตำแหน่ง
โปรดดูการดำเนินการ tf.reshape ด้วย
Transpose(operand)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
operand |
XlaOp |
ออบเจ็กต์ที่จะเปลี่ยนรูปแบบ |
permutation |
ArraySlice<int64> |
วิธีสับเปลี่ยนมิติข้อมูล |
เปลี่ยนลําดับมิติข้อมูลออบเจ็กต์ด้วยการเปลี่ยนลําดับที่ระบุ ดังนี้
∀ i . 0 ≤ i < rank ⇒ input_dimensions[permutation[i]] = output_dimensions[i]
ซึ่งเหมือนกับ Reshape(operand, permutation, Permute(permutation, operand.shape.dimensions))
TriangularSolve
ดู XlaBuilder::TriangularSolve เพิ่มเติม
แก้ระบบสมการเชิงเส้นที่มีเมทริกซ์สัมประสิทธิ์สามเหลี่ยมล่างหรือบนด้วยการแทนค่าไปข้างหน้าหรือย้อนกลับ กิจวัตรนี้จะแก้ปัญหาระบบเมทริกซ์ op(a) * x =
b หรือ x * op(a) = b รายการใดรายการหนึ่งสําหรับตัวแปร x โดยให้ a และ b โดยที่ op(a) อาจเป็น op(a) = a, op(a) = Transpose(a) หรือ op(a) = Conj(Transpose(a))
TriangularSolve(a, b, left_side, lower, unit_diagonal, transpose_a)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
a |
XlaOp |
a rank > 2 อาร์เรย์ของประเภทเชิงซ้อนหรือจุดลอยตัวที่มีรูปร่าง [..., M, M] |
b |
XlaOp |
อาร์เรย์ที่มีลําดับมากกว่า 2 รายการของประเภทเดียวกันที่มีรูปร่าง [..., M, K] หาก left_side เป็นจริง หรือ [..., K, M] หากเป็นอย่างอื่น |
left_side |
bool |
ระบุว่าจะแก้โจทย์จากระบบในรูปแบบ op(a) * x = b (true) หรือ x * op(a) = b (false) |
lower |
bool |
จะใช้สามเหลี่ยมด้านบนหรือด้านล่างของ a |
unit_diagonal |
bool |
หากเป็น true องค์ประกอบแนวทแยงมุมของ a จะถือว่าเป็น 1 และไม่มีการเข้าถึง |
transpose_a |
Transpose |
จะใช้ a ตามที่แสดง เปลี่ยนรูปแบบ หรือเปลี่ยนรูปแบบเชิงซ้อนผสาน |
อินพุตจะอ่านได้จากสามเหลี่ยมด้านล่าง/บนของ a เท่านั้น โดยขึ้นอยู่กับค่าของ lower ระบบจะไม่สนใจค่าจากรูปสามเหลี่ยมอื่น ระบบจะแสดงผลข้อมูลเอาต์พุตในสามเหลี่ยมเดียวกัน ส่วนค่าในสามเหลี่ยมอื่นจะกำหนดตามการใช้งานและอาจเป็นค่าใดก็ได้
หากอันดับของ a และ b มากกว่า 2 ระบบจะถือว่ารายการดังกล่าวเป็นกลุ่มของเมทริกซ์ โดยที่มิติข้อมูลทั้งหมดยกเว้นมิติข้อมูลรอง 2 รายการจะเป็นมิติข้อมูลกลุ่ม a และ b ต้องมีมิติข้อมูลกลุ่มเท่ากัน
Tuple
โปรดดูXlaBuilder::Tuple
มัดข้อมูลที่มีตัวแฮนเดิลข้อมูลจํานวนไม่คงที่ โดยแต่ละรายการมีรูปร่างเป็นของตัวเอง
ซึ่งคล้ายกับ std::tuple ใน C++ แนวคิดคือ
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
คุณสามารถแยกโครงสร้าง (เข้าถึง) Tuple ได้ผ่านการดำเนินการ GetTupleElement
ในขณะที่
โปรดดูXlaBuilder::While
While(condition, body, init)
| อาร์กิวเมนต์ | ประเภท | ความหมาย |
|---|---|---|
condition |
XlaComputation |
XlaComputation ของประเภท T -> PRED ซึ่งกำหนดเงื่อนไขการสิ้นสุดของ Theloop |
body |
XlaComputation |
XlaComputation ประเภท T -> T ซึ่งกําหนดเนื้อหาของลูป |
init |
T |
ค่าเริ่มต้นสำหรับพารามิเตอร์ของ condition และ body |
ดำเนินการ body ตามลำดับจนกว่า condition จะดำเนินการไม่สำเร็จ ซึ่งคล้ายกับ while loop ทั่วไปในภาษาอื่นๆ หลายภาษา ยกเว้นความแตกต่างและข้อจำกัดที่ระบุไว้ด้านล่าง
- โหนด
Whileจะแสดงผลค่าประเภทTซึ่งเป็นผลลัพธ์จากการดำเนินการbodyครั้งล่าสุด - รูปร่างของประเภท
Tได้รับการกำหนดแบบคงที่และต้องเหมือนกันในทุกการทำซ้ำ
ระบบจะเริ่มต้นพารามิเตอร์ T ของการคํานวณด้วยค่า init ในรอบแรก และจะอัปเดตเป็นผลลัพธ์ใหม่จาก body โดยอัตโนมัติในการวนซ้ำแต่ละครั้งต่อจากนี้
Use Case หลักอย่างหนึ่งของโหนด While คือการใช้การฝึกซ้ำในเครือข่ายประสาทเทียม รหัสจำลองแบบง่ายแสดงอยู่ด้านล่างพร้อมกราฟที่แสดงการคำนวณ คุณดูรหัสได้ใน while_test.cc
ประเภท T ในตัวอย่างนี้คือ Tuple ที่ประกอบด้วย int32 สำหรับจำนวนการทำซ้ำ และ vector[10] สำหรับ Accumulator สำหรับการวนซ้ำ 1,000 ครั้ง ลูปจะเพิ่มเวกเตอร์คงที่ลงในตัวสะสมอย่างต่อเนื่อง
// Pseudocode for the computation.
init = {0, zero_vector[10]} // Tuple of int32 and float[10].
result = init;
while (result(0) < 1000) {
iteration = result(0) + 1;
new_vector = result(1) + constant_vector[10];
result = {iteration, new_vector};
}