
La section suivante décrit la sémantique des opérations définies dans l'interface XlaBuilder. En règle générale, ces opérations correspondent à celles définies dans l'interface RPC de xla_data.proto.
Remarque sur la nomenclature : le type de données généralisé XLA traite d'un tableau N-dimensionnel contenant des éléments d'un type uniforme (tel que float 32 bits). Tout au long de la documentation, array est utilisé pour désigner un tableau de dimension arbitraire. Pour plus de commodité, les cas particuliers ont des noms plus spécifiques et plus familiers. Par exemple, un vecteur est un tableau à une dimension et une matrice est un tableau à deux dimensions.
Pour en savoir plus sur la structure d'une opération, consultez Formes et mise en page et Mise en page en mosaïque.
Abdos
Voir aussi XlaBuilder::Abs.
Valeur absolue par élément x -> |x|.
Abs(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Pour en savoir plus sur StableHLO, consultez StableHLO – abs.
Ajouter
Voir aussi XlaBuilder::Add.
Effectue une addition élément par élément de lhs et rhs.
Add(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion de différentes dimensions pour Add :
Add(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – Ajouter.
AddDependency
Voir aussi HloInstruction::AddDependency.
AddDependency peut apparaître dans les dumps HLO, mais les utilisateurs finaux ne sont pas censés les construire manuellement.
AfterAll
Voir aussi XlaBuilder::AfterAll.
AfterAll prend un nombre variable de jetons et produit un seul jeton. Les jetons sont des types primitifs qui peuvent être enfilés entre des opérations à effet secondaire pour appliquer un ordre. AfterAll peut être utilisé comme jointure de jetons pour ordonner une opération après un ensemble d'opérations.
AfterAll(tokens)
| Arguments | Type | Sémantique |
|---|---|---|
tokens |
vecteur de XlaOp |
nombre variable de jetons |
Pour en savoir plus sur StableHLO, consultez StableHLO – after_all.
AllGather
Voir aussi XlaBuilder::AllGather.
Effectue la concaténation sur les répliques.
AllGather(operand, all_gather_dimension, shard_count, replica_groups,
channel_id, layout, use_global_device_ids)
| Arguments | Type | Sémantique |
|---|---|---|
operand
|
XlaOp
|
Tableau à concaténer sur les répliques |
all_gather_dimension |
int64 |
Dimension de concaténation |
shard_count
|
int64
|
Taille de chaque groupe de réplicas |
replica_groups
|
vecteur de vecteurs de
int64 |
Groupes entre lesquels la concaténation est effectuée |
channel_id
|
facultatif
ChannelHandle |
ID de canal facultatif pour la communication entre modules |
layout
|
facultatif Layout
|
Crée un modèle de mise en page qui capture la mise en page correspondante dans l'argument. |
use_global_device_ids
|
facultatif bool
|
Renvoie la valeur "true" si les ID de la configuration ReplicaGroup représentent un ID global. |
replica_groupsest une liste de groupes de répliques entre lesquels la concaténation est effectuée (l'ID de réplique de la réplique actuelle peut être récupéré à l'aide deReplicaId). L'ordre des répliques dans chaque groupe détermine l'ordre dans lequel leurs entrées se trouvent dans le résultat.replica_groupsdoit être vide (dans ce cas, toutes les répliques appartiennent à un seul groupe, ordonné de0àN - 1) ou contenir le même nombre d'éléments que le nombre de répliques. Par exemple,replica_groups = {0, 2}, {1, 3}effectue une concaténation entre les répliques0et2, et1et3.shard_countcorrespond à la taille de chaque groupe de réplicas. Nous en avons besoin lorsquereplica_groupsest vide.channel_idest utilisé pour la communication intermodules : seules les opérationsall-gatheravec le mêmechannel_idpeuvent communiquer entre elles.use_global_device_idsRenvoie "true" si les ID de la configuration ReplicaGroup représentent un ID global (replica_id * partition_count + partition_id) au lieu d'un ID de réplica. Cela permet un regroupement plus flexible des appareils si cette réduction All-Reduce est à la fois inter-partition et inter-réplique.
La forme de sortie est la forme d'entrée avec le all_gather_dimension multiplié par shard_count. Par exemple, s'il existe deux répliques et que l'opérande a respectivement la valeur [1.0, 2.5] et [3.0, 5.25] sur les deux répliques, la valeur de sortie de cette opération où all_gather_dim est 0 sera [1.0, 2.5, 3.0,5.25] sur les deux répliques.
L'API de AllGather est décomposée en interne en deux instructions HLO (AllGatherStart et AllGatherDone).
Voir aussi HloInstruction::CreateAllGatherStart.
AllGatherStart et AllGatherDone servent de primitives dans HLO. Ces opérations peuvent apparaître dans les dumps HLO, mais elles ne sont pas destinées à être construites manuellement par les utilisateurs finaux.
Pour en savoir plus sur StableHLO, consultez StableHLO – all_gather.
AllReduce
Voir aussi XlaBuilder::AllReduce.
Effectue un calcul personnalisé sur les répliques.
AllReduce(operand, computation, replica_groups, channel_id,
shape_with_layout, use_global_device_ids)
| Arguments | Type | Sémantique |
|---|---|---|
operand
|
XlaOp
|
Tableau ou tuple non vide de tableaux à réduire sur les répliques |
computation |
XlaComputation |
Calcul de la réduction |
replica_groups
|
ReplicaGroup vector
|
Groupes entre lesquels les réductions sont effectuées |
channel_id
|
facultatif
ChannelHandle |
ID de canal facultatif pour la communication entre modules |
shape_with_layout
|
facultatif Shape
|
Définit la mise en page des données transférées. |
use_global_device_ids
|
facultatif bool
|
Renvoie la valeur "true" si les ID de la configuration ReplicaGroup représentent un ID global. |
- Lorsque
operandest un tuple de tableaux, l'opération all-reduce est effectuée sur chaque élément du tuple. replica_groupsest une liste de groupes de répliques entre lesquels la réduction est effectuée (l'ID de réplique de la réplique actuelle peut être récupéré à l'aide deReplicaId).replica_groupsdoit être vide (dans ce cas, toutes les répliques appartiennent à un seul groupe) ou contenir le même nombre d'éléments que le nombre de répliques. Par exemple,replica_groups = {0, 2}, {1, 3}effectue une réduction entre les répliques0et2, et1et3.channel_idest utilisé pour la communication intermodules : seules les opérationsall-reduceavec le mêmechannel_idpeuvent communiquer entre elles.shape_with_layout: force la mise en page d'AllReduce à la mise en page donnée. Cela permet de garantir la même mise en page pour un groupe d'opérations AllReduce compilées séparément.use_global_device_idsRenvoie "true" si les ID de la configuration ReplicaGroup représentent un ID global (replica_id * partition_count + partition_id) au lieu d'un ID de réplica. Cela permet un regroupement plus flexible des appareils si cette réduction All-Reduce est à la fois inter-partition et inter-réplique.
La forme de sortie est la même que celle de l'entrée. Par exemple, s'il existe deux répliques et que l'opérande a respectivement la valeur [1.0, 2.5] et [3.0, 5.25] sur les deux répliques, la valeur de sortie de cette opération et du calcul de la somme sera [4.0, 7.75] sur les deux répliques. Si l'entrée est un tuple, la sortie est également un tuple.
Pour calculer le résultat de AllReduce, il faut une entrée de chaque réplique. Par conséquent, si une réplique exécute un nœud AllReduce plus de fois qu'une autre, la première réplique attendra indéfiniment. Étant donné que les répliques exécutent toutes le même programme, il n'y a pas beaucoup de façons pour que cela se produise, mais c'est possible lorsque la condition d'une boucle while dépend des données de infeed et que les données qui sont infeed entraînent l'itération de la boucle while plus de fois sur une réplique que sur une autre.
L'API de AllReduce est décomposée en interne en deux instructions HLO (AllReduceStart et AllReduceDone).
Voir aussi HloInstruction::CreateAllReduceStart.
AllReduceStart et AllReduceDone servent de primitives dans HLO. Ces opérations peuvent apparaître dans les dumps HLO, mais elles ne sont pas destinées à être construites manuellement par les utilisateurs finaux.
CrossReplicaSum
Voir aussi XlaBuilder::CrossReplicaSum.
Effectue AllReduce avec un calcul de la somme.
CrossReplicaSum(operand, replica_groups)
| Arguments | Type | Sémantique |
|---|---|---|
operand
|
XlaOp | Tableau ou tuple non vide de tableaux à réduire sur les répliques |
replica_groups
|
vecteur de vecteurs de
int64 |
Groupes entre lesquels les réductions sont effectuées |
Renvoie la somme de la valeur de l'opérande dans chaque sous-groupe de réplicas. Toutes les répliques fournissent une entrée à la somme et toutes les répliques reçoivent la somme résultante pour chaque sous-groupe.
AllToAll
Voir aussi XlaBuilder::AllToAll.
AllToAll est une opération collective qui envoie des données de tous les cœurs à tous les cœurs. Il comporte deux phases :
- Phase de dispersion. Sur chaque cœur, l'opérande est divisé en
split_countblocs le long desplit_dimensions, et les blocs sont dispersés sur tous les cœurs (par exemple, le bloc i est envoyé au cœur i). - Phase de collecte : chaque cœur concatène les blocs reçus le long de
concat_dimension.
Les cœurs participants peuvent être configurés de la manière suivante :
replica_groups: chaque ReplicaGroup contient une liste d'ID de répliques participant au calcul (l'ID de réplique de la réplique actuelle peut être récupéré à l'aide deReplicaId). AllToAll sera appliqué dans les sous-groupes dans l'ordre spécifié. Par exemple,replica_groups = { {1,2,3}, {4,5,0} }signifie qu'un AllToAll sera appliqué dans les répliques{1, 2, 3}, et dans la phase de collecte, et que les blocs reçus seront concaténés dans le même ordre : 1, 2, 3. Ensuite, un autre AllToAll sera appliqué dans les répliques 4, 5 et 0, et l'ordre de concaténation sera également 4, 5 et 0. Sireplica_groupsest vide, toutes les répliques appartiennent à un seul groupe, dans l'ordre de concaténation de leur apparition.
Prérequis :
- La taille de la dimension de l'opérande sur
split_dimensionest divisible parsplit_count. - La forme de l'opérande n'est pas un tuple.
AllToAll(operand, split_dimension, concat_dimension, split_count,
replica_groups, layout, channel_id)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau d'entrée à n dimensions |
split_dimension
|
int64
|
Valeur dans l'intervalle [0,n) qui nomme la dimension selon laquelle l'opérande est fractionné |
concat_dimension
|
int64
|
Valeur dans l'intervalle [0,n) qui nomme la dimension le long de laquelle les blocs fractionnés sont concaténés |
split_count
|
int64
|
Nombre de cœurs participant à cette opération. Si replica_groups est vide, il doit s'agir du nombre de répliques. Sinon, il doit être égal au nombre de répliques dans chaque groupe. |
replica_groups
|
ReplicaGroupvector
|
Chaque groupe contient une liste d'ID de répliques. |
layout |
facultatif Layout |
disposition de la mémoire spécifiée par l'utilisateur |
channel_id
|
facultatif ChannelHandle
|
Identifiant unique pour chaque paire d'envoi/réception |
Pour en savoir plus sur les formes et les mises en page, consultez xla::shapes.
Pour en savoir plus sur StableHLO, consultez StableHLO – all_to_all.
AllToAll – Exemple 1.
XlaBuilder b("alltoall");
auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {4, 16}), "x");
AllToAll(
x,
/*split_dimension=*/ 1,
/*concat_dimension=*/ 0,
/*split_count=*/ 4);

Dans l'exemple ci-dessus, quatre cœurs participent à Alltoall. Sur chaque cœur, l'opérande est divisé en quatre parties le long de la dimension 1, de sorte que chaque partie a une forme f32[4,4]. Les quatre parties sont réparties sur tous les cœurs. Chaque cœur concatène ensuite les parties reçues le long de la dimension 0, dans l'ordre des cœurs 0 à 4. La forme de la sortie sur chaque cœur est donc f32[16,4].
AllToAll – Exemple 2 – StableHLO

Dans l'exemple ci-dessus, deux répliques participent à AllToAll. Sur chaque réplica, l'opérande a la forme f32[2,4]. L'opérande est divisé en deux parties le long de la dimension 1. Chaque partie a donc la forme f32[2,2]. Les deux parties sont ensuite échangées entre les réplicas en fonction de leur position dans le groupe de réplicas. Chaque réplique collecte la partie correspondante des deux opérandes et les concatène le long de la dimension 0. Par conséquent, le résultat sur chaque instance répliquée a la forme f32[4,2].
RaggedAllToAll
Voir aussi XlaBuilder::RaggedAllToAll.
RaggedAllToAll effectue une opération collective all-to-all, où l'entrée et la sortie sont des Tensors irréguliers.
RaggedAllToAll(input, input_offsets, send_sizes, output, output_offsets,
recv_sizes, replica_groups, channel_id)
| Arguments | Type | Sémantique |
|---|---|---|
input |
XlaOp |
Tableau N de type T |
input_offsets |
XlaOp |
Tableau N de type T |
send_sizes |
XlaOp |
Tableau N de type T |
output |
XlaOp |
Tableau N de type T |
output_offsets |
XlaOp |
Tableau N de type T |
recv_sizes |
XlaOp |
Tableau N de type T |
replica_groups
|
ReplicaGroup vector
|
Chaque groupe contient une liste d'ID de répliques. |
channel_id
|
facultatif ChannelHandle
|
Identifiant unique pour chaque paire d'envoi/réception |
Les Tensors irréguliers sont définis par un ensemble de trois Tensors :
data: le tenseurdataest "irrégulier" le long de sa dimension la plus externe, le long de laquelle chaque élément indexé a une taille variable.offsets: le tenseuroffsetsindexe la dimension la plus externe du tenseurdataet représente le décalage de début de chaque élément irrégulier du tenseurdata.sizes: le Tensorsizesreprésente la taille de chaque élément irrégulier du Tensordata, où la taille est spécifiée en unités de sous-éléments. Un sous-élément est défini comme le suffixe de la forme du Tensor "data" obtenu en supprimant la dimension "irrégulière" la plus externe.- Les tenseurs
offsetsetsizesdoivent avoir la même taille.
Exemple de Tensor irrégulier :
data: [8,3] =
{ {a,b,c},{d,e,f},{g,h,i},{j,k,l},{m,n,o},{p,q,r},{s,t,u},{v,w,x} }
offsets: [3] = {0, 1, 4}
sizes: [3] = {1, 3, 4}
// Index 'data' at 'offsets'[0], 'sizes'[0]' // {a,b,c}
// Index 'data' at 'offsets'[1], 'sizes'[1]' // {d,e,f},{g,h,i},{j,k,l}
// Index 'data' at 'offsets'[2], 'sizes'[2]' // {m,n,o},{p,q,r},{s,t,u},{v,w,x}
output_offsets doit être fragmenté de sorte que chaque réplica ait des décalages dans la perspective de sortie du réplica cible.
Pour le i-ème décalage de sortie, le réplica actuel enverra la mise à jour input[input_offsets[i]:input_offsets[i]+send_sizes[i]] au i-ème réplica, qui sera écrit dans output_i[output_offsets[i]:output_offsets[i]+send_sizes[i]] dans le i-ème réplica output.
Par exemple, si nous avons deux réplicas :
replica 0:
input: [1, 2, 2]
output:[0, 0, 0, 0]
input_offsets: [0, 1]
send_sizes: [1, 2]
output_offsets: [0, 0]
recv_sizes: [1, 1]
replica 1:
input: [3, 4, 0]
output: [0, 0, 0, 0]
input_offsets: [0, 1]
send_sizes: [1, 1]
output_offsets: [1, 2]
recv_sizes: [2, 1]
// replica 0's result will be: [1, 3, 0, 0]
// replica 1's result will be: [2, 2, 4, 0]
Le HLO ragged all-to-all comporte les arguments suivants :
input: Tensor de données d'entrée irrégulières.output: tenseur de données de sortie irrégulier.input_offsets: Tensor des décalages d'entrée irréguliers.send_sizes: Tensor des tailles d'envoi irrégulières.output_offsets: tableau des décalages irréguliers dans la sortie de la réplique cible.recv_sizes: Tensor des tailles de réception irrégulières.
Les Tensors *_offsets et *_sizes doivent tous avoir la même forme.
Deux formes sont acceptées pour les Tensors *_offsets et *_sizes :
[num_devices]où ragged-all-to-all peut envoyer au maximum une mise à jour à chaque appareil distant du groupe de répliques. Exemple :
for (remote_device_id : replica_group) {
SEND input[input_offsets[remote_device_id]],
output[output_offsets[remote_device_id]],
send_sizes[remote_device_id] }
[num_devices, num_updates]où ragged-all-to-all peut envoyer jusqu'ànum_updatesmises à jour au même appareil à distance (chacune à des décalages différents), pour chaque appareil à distance du groupe de répliques.
Exemple :
for (remote_device_id : replica_group) {
for (update_idx : num_updates) {
SEND input[input_offsets[remote_device_id][update_idx]],
output[output_offsets[remote_device_id][update_idx]]],
send_sizes[remote_device_id][update_idx] } }
et
Voir aussi XlaBuilder::And.
Effectue un AND par élément de deux Tensors lhs et rhs.
And(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour And :
And(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO.
Asynchrone
Voir aussi HloInstruction::CreateAsyncStart, HloInstruction::CreateAsyncUpdate, HloInstruction::CreateAsyncDone.
AsyncDone, AsyncStart et AsyncUpdate sont des instructions HLO internes utilisées pour les opérations asynchrones et servent de primitives dans HLO. Ces opérations peuvent apparaître dans les dumps HLO, mais elles ne sont pas destinées à être construites manuellement par les utilisateurs finaux.
Atan2
Voir aussi XlaBuilder::Atan2.
Effectue une opération atan2 au niveau des éléments sur lhs et rhs.
Atan2(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour Atan2 :
Atan2(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – atan2.
BatchNormGrad
Consultez également XlaBuilder::BatchNormGrad et l'article d'origine sur la normalisation des lots pour obtenir une description détaillée de l'algorithme.
Calcule les gradients de la normalisation par lot.
BatchNormGrad(operand, scale, batch_mean, batch_var, grad_output, epsilon,
feature_index)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp | Tableau à n dimensions à normaliser (x) |
scale |
XlaOp | Tableau à une dimension (\(\gamma\)) |
batch_mean |
XlaOp | Tableau à une dimension (\(\mu\)) |
batch_var |
XlaOp | Tableau à une dimension (\(\sigma^2\)) |
grad_output |
XlaOp | Dégradés transmis à BatchNormTraining (\(\nabla y\)) |
epsilon |
float |
Valeur epsilon (\(\epsilon\)) |
feature_index |
int64 |
Index de la dimension de caractéristique dans operand |
Pour chaque caractéristique de la dimension de caractéristique (feature_index est l'index de la dimension de caractéristique dans operand), l'opération calcule les gradients par rapport à operand, offset et scale dans toutes les autres dimensions. feature_index doit être un index valide pour la dimension de caractéristiques dans operand.
Les trois gradients sont définis par les formules suivantes (en supposant un tableau à quatre dimensions comme operand avec l'index de dimension de caractéristiques l, la taille du lot m et les tailles spatiales w et h) :
\[ \begin{split} c_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sigma^2_l+\epsilon} \right) \\\\ d_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \\\\ \nabla x_{ijkl} &= \frac{\gamma_{l} }{\sqrt{\sigma^2_{l}+\epsilon} } \left( \nabla y_{ijkl} - d_l - c_l (x_{ijkl} - \mu_{l}) \right) \\\\ \nabla \gamma_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sqrt{\sigma^2_{l}+\epsilon} } \right) \\\\\ \nabla \beta_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \end{split} \]
Les entrées batch_mean et batch_var représentent les valeurs des moments pour les dimensions spatiales et de lot.
Le type de sortie est un tuple de trois handles :
| Sorties | Type | Sémantique |
|---|---|---|
grad_operand
|
XlaOp | Gradient par rapport à l'entrée operand
(\(\nabla x\)) |
grad_scale
|
XlaOp | gradient par rapport à l'entrée **scale **
(\(\nabla\gamma\)) |
grad_offset
|
XlaOp | gradient par rapport à l'entrée
offset(\(\nabla\beta\)) |
Pour en savoir plus sur StableHLO, consultez StableHLO – batch_norm_grad.
BatchNormInference
Consultez également XlaBuilder::BatchNormInference et l'article d'origine sur la normalisation des lots pour obtenir une description détaillée de l'algorithme.
Normalise un tableau sur les dimensions de lot et spatiales.
BatchNormInference(operand, scale, offset, mean, variance, epsilon,
feature_index)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp | Tableau à N dimensions à normaliser |
scale |
XlaOp | Tableau à une dimension |
offset |
XlaOp | Tableau à une dimension |
mean |
XlaOp | Tableau à une dimension |
variance |
XlaOp | Tableau à une dimension |
epsilon |
float |
Valeur epsilon |
feature_index |
int64 |
Index de la dimension de la fonctionnalité dans operand |
Pour chaque caractéristique de la dimension de caractéristique (feature_index est l'index de la dimension de caractéristique dans operand), l'opération calcule la moyenne et la variance pour toutes les autres dimensions, puis les utilise pour normaliser chaque élément de operand. feature_index doit être un index valide pour la dimension de caractéristiques dans operand.
BatchNormInference équivaut à appeler BatchNormTraining sans calculer mean et variance pour chaque lot. Il utilise plutôt les entrées mean et variance comme valeurs estimées. L'objectif de cette opération est de réduire la latence lors de l'inférence, d'où le nom BatchNormInference.
Le résultat est un tableau normalisé à n dimensions ayant la même forme que l'entrée operand.
Pour en savoir plus sur StableHLO, consultez StableHLO – batch_norm_inference.
BatchNormTraining
Pour obtenir une description détaillée de l'algorithme, consultez également XlaBuilder::BatchNormTraining et the original batch normalization paper.
Normalise un tableau sur les dimensions de lot et spatiales.
BatchNormTraining(operand, scale, offset, epsilon, feature_index)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau à n dimensions à normaliser (x) |
scale |
XlaOp |
Tableau à une dimension (\(\gamma\)) |
offset |
XlaOp |
Tableau à une dimension (\(\beta\)) |
epsilon |
float |
Valeur epsilon (\(\epsilon\)) |
feature_index |
int64 |
Index de la dimension de caractéristique dans operand |
Pour chaque caractéristique de la dimension de caractéristique (feature_index est l'index de la dimension de caractéristique dans operand), l'opération calcule la moyenne et la variance pour toutes les autres dimensions, puis les utilise pour normaliser chaque élément de operand. feature_index doit être un index valide pour la dimension de caractéristiques dans operand.
L'algorithme se déroule comme suit pour chaque lot de operand \(x\) contenant m éléments avec w et h comme taille des dimensions spatiales (en supposant que operand est un tableau à quatre dimensions) :
Calcule la moyenne du lot \(\mu_l\) pour chaque caractéristique
ldans la dimension de la caractéristique : \(\mu_l=\frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h x_{ijkl}\)Calcule la variance du lot \(\sigma^2_l\) : $\sigma^2l=\frac{1}{mwh}\sum{i=1}^m\sum{j=1}^w\sum{k=1}^h (x_{ijkl} - \mu_l)^2$
Normalisation, mise à l'échelle et décalage : \(y_{ijkl}=\frac{\gamma_l(x_{ijkl}-\mu_l)}{\sqrt[2]{\sigma^2_l+\epsilon} }+\beta_l\)
La valeur epsilon, généralement un petit nombre, est ajoutée pour éviter les erreurs de division par zéro.
Le type de sortie est un tuple de trois XlaOp :
| Sorties | Type | Sémantique |
|---|---|---|
output
|
XlaOp
|
Tableau à n dimensions ayant la même forme que l'entrée operand (y) |
batch_mean |
XlaOp |
Tableau à une dimension (\(\mu\)) |
batch_var |
XlaOp |
Tableau à une dimension (\(\sigma^2\)) |
batch_mean et batch_var sont des moments calculés sur les dimensions de lot et spatiales à l'aide des formules ci-dessus.
Pour en savoir plus sur StableHLO, consultez StableHLO – batch_norm_training.
Bitcast
Voir aussi HloInstruction::CreateBitcast.
Bitcast peut apparaître dans les dumps HLO, mais n'est pas destiné à être construit manuellement par les utilisateurs finaux.
BitcastConvertType
Voir aussi XlaBuilder::BitcastConvertType.
Semblable à un tf.bitcast dans TensorFlow, effectue une opération bitcast élément par élément d'une forme de données vers une forme cible. La taille des entrées et des sorties doit correspondre : par exemple, s32 éléments deviennent f32 éléments via la routine bitcast, et un s32 élément deviendra quatre s8 éléments. Bitcast est implémenté en tant que cast de bas niveau. Par conséquent, les machines avec des représentations à virgule flottante différentes donneront des résultats différents.
BitcastConvertType(operand, new_element_type)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau de type T avec des dimensions D |
new_element_type |
PrimitiveType |
type U |
Les dimensions de l'opérande et de la forme cible doivent correspondre, à l'exception de la dernière dimension qui changera en fonction du rapport entre la taille primitive avant et après la conversion.
Les types d'éléments source et de destination ne doivent pas être des tuples.
Pour en savoir plus sur StableHLO, consultez StableHLO – bitcast_convert.
Conversion bitcast en type primitif de largeur différente
L'instruction HLO BitcastConvert est compatible avec le cas où la taille du type d'élément de sortie T' n'est pas égale à la taille de l'élément d'entrée T. Étant donné que l'opération entière est conceptuellement un bitcast et ne modifie pas les octets sous-jacents, la forme de l'élément de sortie doit changer. Pour B = sizeof(T), B' =
sizeof(T'), deux cas sont possibles.
Tout d'abord, lorsque B > B', la forme de sortie obtient une nouvelle dimension la moins importante de taille B/B'. Exemple :
f16[10,2]{1,0} %output = f16[10,2]{1,0} bitcast-convert(f32[10]{0} %input)
La règle reste la même pour les scalaires effectifs :
f16[2]{0} %output = f16[2]{0} bitcast-convert(f32[] %input)
Pour B' > B, l'instruction exige que la dernière dimension logique de la forme d'entrée soit égale à B'/B. Cette dimension est supprimée lors de la conversion :
f32[10]{0} %output = f32[10]{0} bitcast-convert(f16[10,2]{1,0} %input)
Notez que les conversions entre différentes largeurs de bits ne sont pas élément par élément.
Annoncer
Voir aussi XlaBuilder::Broadcast.
Ajoute des dimensions à un tableau en dupliquant les données qu'il contient.
Broadcast(operand, broadcast_sizes)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau à dupliquer |
broadcast_sizes |
ArraySlice<int64> |
Tailles des nouvelles dimensions |
Les nouvelles dimensions sont insérées à gauche. Par exemple, si broadcast_sizes a des valeurs {a0, ..., aN} et que la forme de l'opérande a des dimensions {b0, ..., bM}, la forme de la sortie a des dimensions {a0, ..., aN, b0, ..., bM}.
Les nouvelles dimensions sont indexées dans des copies de l'opérande, c'est-à-dire
output[i0, ..., iN, j0, ..., jM] = operand[j0, ..., jM]
Par exemple, si operand est un scalaire f32 avec la valeur 2.0f et que broadcast_sizes est {2, 3}, le résultat sera un tableau de forme f32[2, 3] et toutes les valeurs du résultat seront 2.0f.
Pour en savoir plus sur StableHLO, consultez StableHLO – diffusion.
BroadcastInDim
Voir aussi XlaBuilder::BroadcastInDim.
Augmente la taille et le nombre de dimensions d'un tableau en dupliquant les données du tableau.
BroadcastInDim(operand, out_dim_size, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau à dupliquer |
out_dim_size
|
ArraySlice<int64>
|
Tailles des dimensions de la forme cible |
broadcast_dimensions
|
ArraySlice<int64>
|
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Semblable à la diffusion, mais permet d'ajouter des dimensions n'importe où et d'étendre les dimensions existantes avec la taille 1.
operand est diffusé à la forme décrite par out_dim_size. broadcast_dimensions mappe les dimensions de operand aux dimensions de la forme cible, c'est-à-dire que la i-ième dimension de l'opérande est mappée à la dimension broadcast_dimension[i] de la forme de sortie. Les dimensions de operand doivent avoir une taille de 1 ou être de la même taille que la dimension de la forme de sortie à laquelle elles sont mappées. Les dimensions restantes sont remplies avec des dimensions de taille 1. La diffusion de dimension dégénérée est ensuite diffusée le long de ces dimensions dégénérées pour atteindre la forme de sortie. La sémantique est décrite en détail sur la page de diffusion.
Appeler
Voir aussi XlaBuilder::Call.
Appelle un calcul avec les arguments fournis.
Call(computation, operands...)
| Arguments | Type | Sémantique |
|---|---|---|
computation
|
XlaComputation
|
Calcul de type T_0, T_1, ...,
T_{N-1} -> S avec N paramètres de type arbitraire |
operands |
séquence de N XlaOp |
N arguments de type arbitraire |
L'arité et les types de operands doivent correspondre aux paramètres de computation. Il est autorisé de ne pas avoir de operands.
CompositeCall
Voir aussi XlaBuilder::CompositeCall.
Encapsule une opération composée d'autres opérations StableHLO, en prenant des entrées et des composite_attributes et en produisant des résultats. La sémantique de l'opération est implémentée par l'attribut de décomposition. L'opération composite peut être remplacée par sa décomposition sans modifier la sémantique du programme. Dans les cas où l'intégration de la décomposition ne fournit pas la même sémantique d'opération, préférez l'utilisation de custom_call.
Le champ de version (qui est défini sur 0 par défaut) est utilisé pour indiquer quand la sémantique d'un composite change.
Cette opération est implémentée en tant que kCall avec l'attribut is_composite=true. Le champ decomposition est spécifié par l'attribut computation. Les attributs frontend stockent les attributs restants précédés du préfixe composite..
Exemple d'opération CompositeCall :
f32[] call(f32[] %cst), to_apply=%computation, is_composite=true,
frontend_attributes = {
composite.name="foo.bar",
composite.attributes={n = 1 : i32, tensor = dense<1> : tensor<i32>},
composite.version="1"
}
CompositeCall(computation, operands..., name, attributes, version)
| Arguments | Type | Sémantique |
|---|---|---|
computation
|
XlaComputation
|
Calcul de type T_0, T_1, ...,
T_{N-1} -> S avec N paramètres de type arbitraire |
operands |
séquence de N XlaOp |
nombre variable de valeurs |
name |
string |
nom du composite |
attributes
|
facultatif string
|
dictionnaire facultatif d'attributs sous forme de chaîne |
version
|
facultatif int64
|
nombre de mises à jour de version vers la sémantique de l'opération composite. |
Le decomposition d'une opération n'est pas un champ appelé, mais apparaît plutôt comme un attribut to_apply qui pointe vers la fonction contenant l'implémentation de niveau inférieur, c'est-à-dire to_apply=%funcname.
Pour en savoir plus sur la composition et la décomposition, consultez la spécification StableHLO.
Cbrt
Voir aussi XlaBuilder::Cbrt.
Opération de racine cubique au niveau des éléments x -> cbrt(x).
Cbrt(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Cbrt accepte également l'argument facultatif result_accuracy :
Cbrt(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Pour en savoir plus sur StableHLO, consultez StableHLO – cbrt.
Ceil
Voir aussi XlaBuilder::Ceil.
Plafond par élément x -> ⌈x⌉.
Ceil(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Pour en savoir plus sur StableHLO, consultez StableHLO – ceil.
Cholesky
Voir aussi XlaBuilder::Cholesky.
Calcule la décomposition de Cholesky d'un lot de matrices définies positives symétriques (hermitiennes).
Cholesky(a, lower)
| Arguments | Type | Sémantique |
|---|---|---|
a
|
XlaOp
|
Tableau de type complexe ou à virgule flottante avec plus de deux dimensions. |
lower |
bool |
Indique s'il faut utiliser le triangle supérieur ou inférieur de a. |
Si lower est true, calcule les matrices triangulaires inférieures l telles que $a = l .
l^T$. Si lower est false, calcule les matrices triangulaires supérieures u telles que\(a = u^T . u\).
Les données d'entrée ne sont lues que dans le triangle inférieur/supérieur de a, en fonction de la valeur de lower. Les valeurs de l'autre triangle sont ignorées. Les données de sortie sont renvoyées dans le même triangle. Les valeurs de l'autre triangle sont définies par l'implémentation et peuvent être n'importe quoi.
Si a comporte plus de deux dimensions, a est traité comme un lot de matrices, où toutes les dimensions, à l'exception des deux dimensions mineures, sont des dimensions de lot.
Si a n'est pas une matrice définie positive symétrique (hermitienne), le résultat est défini par l'implémentation.
Pour en savoir plus sur StableHLO, consultez StableHLO – cholesky.
Limiter
Voir aussi XlaBuilder::Clamp.
Limite un opérande à une plage comprise entre une valeur minimale et une valeur maximale.
Clamp(min, operand, max)
| Arguments | Type | Sémantique |
|---|---|---|
min |
XlaOp |
tableau de type T |
operand |
XlaOp |
tableau de type T |
max |
XlaOp |
tableau de type T |
Étant donné un opérande et des valeurs minimale et maximale, renvoie l'opérande s'il se trouve dans la plage comprise entre le minimum et le maximum. Sinon, renvoie la valeur minimale si l'opérande est inférieur à cette plage ou la valeur maximale si l'opérande est supérieur à cette plage. Par exemple, clamp(a, x, b) = min(max(a, x), b).
Les trois tableaux doivent avoir la même forme. Par ailleurs, en tant que forme restreinte de diffusion, min et/ou max peuvent être un scalaire de type T.
Exemple avec min et max scalaires :
let operand: s32[3] = {-1, 5, 9};
let min: s32 = 0;
let max: s32 = 6;
==>
Clamp(min, operand, max) = s32[3]{0, 5, 6};
Pour en savoir plus sur StableHLO, consultez StableHLO – clamp.
Réduire
Voir aussi XlaBuilder::Collapse.
et l'opération tf.reshape.
Réduit les dimensions d'un tableau à une seule dimension.
Collapse(operand, dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
tableau de type T |
dimensions |
Vecteur int64 |
sous-ensemble consécutif et ordonné des dimensions de T. |
L'opération "Collapse" remplace le sous-ensemble donné des dimensions de l'opérande par une seule dimension. Les arguments d'entrée sont un tableau arbitraire de type T et un vecteur de constantes de compilation d'indices de dimension. Les indices de dimension doivent être un sous-ensemble consécutif (du plus petit au plus grand nombre de dimensions) des dimensions de T. Ainsi, {0, 1, 2}, {0, 1} ou {1, 2} sont tous des ensembles de dimensions valides, mais {1, 0} ou {0, 2} ne le sont pas. Ils sont remplacés par une seule nouvelle dimension, à la même position dans la séquence de dimensions que celles qu'ils remplacent, avec une taille de nouvelle dimension égale au produit des tailles de dimensions d'origine. Le plus petit nombre de dimensions dans dimensions est la dimension à variation la plus lente (la plus importante) dans la boucle imbriquée qui réduit ces dimensions, et le plus grand nombre de dimensions est la dimension à variation la plus rapide (la plus petite). Consultez l'opérateur tf.reshape si un ordre de réduction plus général est nécessaire.
Par exemple, supposons que v soit un tableau de 24 éléments :
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
// Collapse to a single dimension, leaving one dimension.
let v012 = Collapse(v, {0,1,2});
then v012 == f32[24] {10, 11, 12, 15, 16, 17,
20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37,
40, 41, 42, 45, 46, 47};
// Collapse the two lower dimensions, leaving two dimensions.
let v01 = Collapse(v, {0,1});
then v01 == f32[4x6] { {10, 11, 12, 15, 16, 17},
{20, 21, 22, 25, 26, 27},
{30, 31, 32, 35, 36, 37},
{40, 41, 42, 45, 46, 47} };
// Collapse the two higher dimensions, leaving two dimensions.
let v12 = Collapse(v, {1,2});
then v12 == f32[8x3] { {10, 11, 12},
{15, 16, 17},
{20, 21, 22},
{25, 26, 27},
{30, 31, 32},
{35, 36, 37},
{40, 41, 42},
{45, 46, 47} };
Clz
Voir aussi XlaBuilder::Clz.
Compte les zéros en début de nombre pour chaque élément.
Clz(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
CollectiveBroadcast
Voir aussi XlaBuilder::CollectiveBroadcast.
Diffuser des données sur les répliques. Les données sont envoyées du premier ID de réplique de chaque groupe aux autres ID du même groupe. Si un ID de réplique ne figure dans aucun groupe de répliques, la sortie sur cette réplique est un Tensor composé de 0 dans shape.
CollectiveBroadcast(operand, replica_groups, channel_id)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
replica_groups
|
ReplicaGroupvector
|
Chaque groupe contient une liste d'ID de répliques. |
channel_id
|
facultatif ChannelHandle
|
Identifiant unique pour chaque paire d'envoi/réception |
Pour en savoir plus sur StableHLO, consultez StableHLO – collective_broadcast.
CollectivePermute
Voir aussi XlaBuilder::CollectivePermute.
CollectivePermute est une opération collective qui envoie et reçoit des données entre les répliques.
CollectivePermute(operand, source_target_pairs, channel_id)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau d'entrée à n dimensions |
source_target_pairs
|
<int64, int64> vector
|
Liste de paires (source_replica_id, target_replica_id). Pour chaque paire, l'opérande est envoyé de la réplique source à la réplique cible. |
channel_id
|
facultatif ChannelHandle
|
ID de canal facultatif pour la communication intermodules |
Notez que les restrictions suivantes s'appliquent à source_target_pairs :
- Deux paires ne doivent pas avoir le même ID d'instance répliquée cible ni le même ID d'instance répliquée source.
- Si un ID de réplique n'est la cible d'aucune paire, la sortie sur cette réplique est un Tensor composé de 0(s) avec la même forme que l'entrée.
L'API de l'opération CollectivePermute est décomposée en interne en deux instructions HLO (CollectivePermuteStart et CollectivePermuteDone).
Voir aussi HloInstruction::CreateCollectivePermuteStart.
CollectivePermuteStart et CollectivePermuteDone servent de primitives dans HLO.
Ces opérations peuvent apparaître dans les dumps HLO, mais elles ne sont pas destinées à être construites manuellement par les utilisateurs finaux.
Pour en savoir plus sur StableHLO, consultez StableHLO – collective_permute.
Comparer
Voir aussi XlaBuilder::Compare.
Effectue une comparaison élément par élément de lhs et rhs des éléments suivants :
Eq
Voir aussi XlaBuilder::Eq.
Effectue une comparaison égal à élément par élément de lhs et rhs.
\(lhs = rhs\)
Eq(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Une variante alternative avec une prise en charge de la diffusion multidimensionnelle existe pour l'équation :
Eq(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Une commande totale sur les nombres à virgule flottante existe pour Eq, en appliquant :
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
EqTotalOrder(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Pour en savoir plus sur StableHLO, consultez StableHLO – Comparer.
Ne
Voir aussi XlaBuilder::Ne.
Effectue une comparaison not equal-to (différent de) au niveau des éléments de lhs et rhs.
\(lhs != rhs\)
Ne(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion de différentes dimensions pour Ne :
Ne(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Une commande totale sur les nombres à virgule flottante est prise en charge pour Ne, en appliquant :
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
NeTotalOrder(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Pour en savoir plus sur StableHLO, consultez StableHLO – Comparer.
Ge
Voir aussi XlaBuilder::Ge.
Effectue une comparaison greater-or-equal-than élément par élément de lhs et rhs.
\(lhs >= rhs\)
Ge(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Une variante alternative avec une prise en charge de la diffusion multidimensionnelle existe pour Ge :
Ge(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Une commande totale sur les nombres à virgule flottante existe pour Gt, en appliquant :
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
GtTotalOrder(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Pour en savoir plus sur StableHLO, consultez StableHLO – Comparer.
Gt
Voir aussi XlaBuilder::Gt.
Effectue une comparaison supérieure à élément par élément de lhs et rhs.
\(lhs > rhs\)
Gt(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion de différentes dimensions pour Gt :
Gt(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – Comparer.
Le
Voir aussi XlaBuilder::Le.
Effectue une comparaison less-or-equal-than élément par élément de lhs et rhs.
\(lhs <= rhs\)
Le(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour Le :
Le(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
La prise en charge d'un ordre total sur les nombres à virgule flottante existe pour Le, en appliquant :
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
LeTotalOrder(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Pour en savoir plus sur StableHLO, consultez StableHLO – Comparer.
Lt
Voir aussi XlaBuilder::Lt.
Effectue une comparaison inférieure à élément par élément de lhs et rhs.
\(lhs < rhs\)
Lt(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour Lt :
Lt(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Une commande totale sur les nombres à virgule flottante existe pour Lt, en appliquant :
\[-NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN.\]
LtTotalOrder(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Pour en savoir plus sur StableHLO, consultez StableHLO – Comparer.
Complexe
Voir aussi XlaBuilder::Complex.
Effectue une conversion élément par élément en valeur complexe à partir d'une paire de valeurs réelles et imaginaires, lhs et rhs.
Complex(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour Complex :
Complex(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – complexe.
ConcatInDim (Concaténation)
Voir aussi XlaBuilder::ConcatInDim.
La concaténation compose un tableau à partir de plusieurs opérandes de tableau. Le tableau comporte le même nombre de dimensions que chacun des opérandes du tableau d'entrée (qui doivent avoir le même nombre de dimensions les uns que les autres) et contient les arguments dans l'ordre dans lequel ils ont été spécifiés.
Concatenate(operands..., dimension)
| Arguments | Type | Sémantique |
|---|---|---|
operands
|
séquence de N XlaOp
|
Tableaux N de type T avec des dimensions [L0, L1, ...]. N doit être supérieur ou égal à 1. |
dimension
|
int64
|
Valeur dans l'intervalle [0, N) qui nomme la dimension à concaténer entre operands. |
À l'exception de dimension, toutes les dimensions doivent être identiques. En effet, XLA n'est pas compatible avec les tableaux "irréguliers". Notez également que les valeurs de dimension 0 ne peuvent pas être concaténées (car il est impossible de nommer la dimension le long de laquelle la concaténation se produit).
Exemple unidimensionnel :
Concat({ {2, 3}, {4, 5}, {6, 7} }, 0)
//Output: {2, 3, 4, 5, 6, 7}
Exemple en deux dimensions :
let a = { {1, 2},
{3, 4},
{5, 6} };
let b = { {7, 8} };
Concat({a, b}, 0)
//Output: { {1, 2},
// {3, 4},
// {5, 6},
// {7, 8} }
Diagramme :
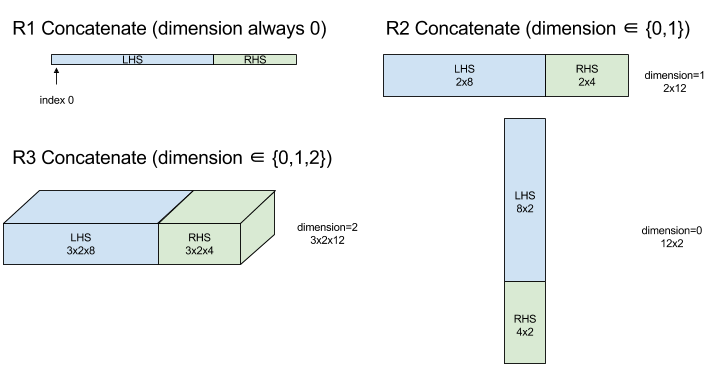
Pour en savoir plus sur StableHLO, consultez StableHLO – concatenate.
Conditionnel
Voir aussi XlaBuilder::Conditional.
Conditional(predicate, true_operand, true_computation, false_operand,
false_computation)
| Arguments | Type | Sémantique |
|---|---|---|
predicate |
XlaOp |
Scalaire de type PRED |
true_operand |
XlaOp |
Argument de type \(T_0\) |
true_computation |
XlaComputation |
XlaComputation de type \(T_0 \to S\) |
false_operand |
XlaOp |
Argument de type \(T_1\) |
false_computation |
XlaComputation |
XlaComputation de type \(T_1 \to S\) |
Exécute true_computation si predicate est true, false_computation si predicate est false, et renvoie le résultat.
true_computation doit accepter un seul argument de type \(T_0\) et sera appelé avec true_operand, qui doit être du même type. false_computation doit accepter un seul argument de type \(T_1\) et sera appelé avec false_operand, qui doit être du même type. Le type de la valeur renvoyée de true_computation et false_computation doit être le même.
Notez que seul l'un des éléments true_computation et false_computation sera exécuté en fonction de la valeur de predicate.
Conditional(branch_index, branch_computations, branch_operands)
| Arguments | Type | Sémantique |
|---|---|---|
branch_index |
XlaOp |
Scalaire de type S32 |
branch_computations |
séquence de N XlaComputation |
XlaComputations de type \(T_0 \to S , T_1 \to S , ..., T_{N-1} \to S\) |
branch_operands |
séquence de N XlaOp |
Arguments de type \(T_0 , T_1 , ..., T_{N-1}\) |
Exécute branch_computations[branch_index] et renvoie le résultat. Si branch_index est un S32 qui est < 0 ou >= N, alors branch_computations[N-1] est exécuté en tant que branche par défaut.
Chaque branch_computations[b] doit accepter un seul argument de type \(T_b\) et sera appelé avec branch_operands[b], qui doit être du même type. Le type de la valeur renvoyée de chaque branch_computations[b] doit être identique.
Notez qu'une seule des branch_computations sera exécutée en fonction de la valeur de branch_index.
Pour en savoir plus sur StableHLO, consultez StableHLO – if.
Constante
Voir aussi XlaBuilder::ConstantLiteral.
Génère un output à partir d'un literal constant.
Constant(literal)
| Arguments | Type | Sémantique |
|---|---|---|
literal |
LiteralSlice |
une vue constante d'un Literal existant. |
Pour en savoir plus sur StableHLO, consultez StableHLO – constant.
ConvertElementType
Voir aussi XlaBuilder::ConvertElementType.
Semblable à un static_cast élément par élément en C++, ConvertElementType effectue une opération de conversion élément par élément d'une forme de données vers une forme cible. Les dimensions doivent correspondre, et la conversion s'effectue élément par élément (par exemple, les éléments s32 deviennent des éléments f32 via une routine de conversion s32 vers f32).
ConvertElementType(operand, new_element_type)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau de type T avec des dimensions D |
new_element_type |
PrimitiveType |
type U |
Les dimensions de l'opérande et de la forme cible doivent correspondre. Les types d'éléments source et de destination ne doivent pas être des tuples.
Une conversion telle que T=s32 vers U=f32 effectuera une routine de conversion int-to-float normalisatrice telle que l'arrondi au nombre pair le plus proche.
let a: s32[3] = {0, 1, 2};
let b: f32[3] = convert(a, f32);
then b == f32[3]{0.0, 1.0, 2.0}
Pour en savoir plus sur StableHLO, consultez StableHLO – Convertir.
Conv (convolution)
Voir aussi XlaBuilder::Conv.
Calcule une convolution du type utilisé dans les réseaux de neurones. Ici, une convolution peut être considérée comme une fenêtre n-dimensionnelle se déplaçant sur une zone de base n-dimensionnelle, et un calcul est effectué pour chaque position possible de la fenêtre.
Conv Met en file d'attente une instruction de convolution dans le calcul, qui utilise les nombres de dimensions de convolution par défaut sans dilatation.
Le remplissage est spécifié de manière abrégée par SAME ou VALID. Le remplissage SAME ajoute des zéros à l'entrée (lhs) afin que la sortie ait la même forme que l'entrée sans tenir compte du pas. Le remplissage VALID signifie simplement qu'il n'y a pas de remplissage.
Conv(lhs, rhs, window_strides, padding, feature_group_count,
batch_group_count, precision_config, preferred_element_type)
| Arguments | Type | Sémantique |
|---|---|---|
lhs
|
XlaOp
|
Tableau d'entrées à (n+2) dimensions |
rhs
|
XlaOp
|
Tableau de pondérations du noyau à (n+2) dimensions |
window_strides |
ArraySlice<int64> |
Tableau n-d des foulées du noyau |
padding |
Padding |
Énumération de la marge intérieure |
feature_group_count
|
int64 | le nombre de groupes de caractéristiques ; |
batch_group_count |
int64 | le nombre de groupes de lots ; |
precision_config
|
facultatif
PrecisionConfig |
Énumération pour le niveau de précision. |
preferred_element_type
|
facultatif
PrimitiveType |
Énumération du type d'élément scalaire |
Différents niveaux de contrôle sont disponibles pour Conv :
Soit n le nombre de dimensions spatiales. L'argument lhs est un tableau à (n+2) dimensions décrivant la zone de base. C'est ce qu'on appelle l'entrée, même si, bien sûr, le rhs est également une entrée. Dans un réseau de neurones, il s'agit des activations d'entrée. Les dimensions n+2 sont, dans cet ordre :
batch: chaque coordonnée de cette dimension représente une entrée indépendante pour laquelle la convolution est effectuée.z/depth/features: chaque position (y,x) dans la zone de base est associée à un vecteur, qui est inclus dans cette dimension.spatial_dims: décrit les dimensions spatialesnqui définissent la zone de base sur laquelle la fenêtre se déplace.
L'argument rhs est un tableau à (n+2) dimensions décrivant le filtre/noyau/la fenêtre de convolution. Les dimensions sont, dans cet ordre :
output-z: dimensionzde la sortie.input-z: la taille de cette dimension multipliée parfeature_group_countdoit être égale à la taille de la dimensionzdans lhs.spatial_dims: décrit les dimensions spatialesnqui définissent la fenêtre n-d qui se déplace sur la zone de base.
L'argument window_strides spécifie le pas de la fenêtre de convolution dans les dimensions spatiales. Par exemple, si le pas dans la première dimension spatiale est de 3, la fenêtre ne peut être placée qu'à des coordonnées où le premier index spatial est divisible par 3.
L'argument padding spécifie la quantité de remplissage zéro à appliquer à la zone de base. La quantité de remplissage peut être négative. La valeur absolue du remplissage négatif indique le nombre d'éléments à supprimer de la dimension spécifiée avant d'effectuer la convolution. padding[0] spécifie le remplissage pour la dimension y et padding[1] spécifie le remplissage pour la dimension x. Chaque paire a le remplissage faible comme premier élément et le remplissage élevé comme deuxième élément. Le remplissage faible est appliqué dans le sens des indices inférieurs, tandis que le remplissage élevé est appliqué dans le sens des indices supérieurs. Par exemple, si padding[1] est (2,3), un remplissage de deux zéros sera appliqué à gauche et un remplissage de trois zéros à droite dans la deuxième dimension spatiale. L'utilisation du remplissage équivaut à insérer ces mêmes valeurs nulles dans l'entrée (lhs) avant d'effectuer la convolution.
Les arguments lhs_dilation et rhs_dilation spécifient le facteur de dilatation à appliquer respectivement aux côtés gauche et droit dans chaque dimension spatiale. Si le facteur de dilatation dans une dimension spatiale est d, alors d-1 trous sont implicitement placés entre chacune des entrées de cette dimension, ce qui augmente la taille du tableau. Les trous sont remplis avec une valeur no-op, qui pour la convolution signifie des zéros.
La dilatation du membre de droite est également appelée convolution à trous. Pour en savoir plus, consultez tf.nn.atrous_conv2d. La dilatation du côté gauche est également appelée convolution transposée. Pour en savoir plus, consultez tf.nn.conv2d_transpose.
L'argument feature_group_count (valeur par défaut 1) peut être utilisé pour les convolutions groupées. feature_group_count doit être un diviseur de la dimension de la caractéristique d'entrée et de sortie. Si feature_group_count est supérieur à 1, cela signifie que, conceptuellement, la dimension de la caractéristique d'entrée et de sortie et la dimension de la caractéristique de sortie rhs sont divisées de manière égale en plusieurs groupes feature_group_count, chaque groupe étant constitué d'une sous-séquence consécutive de caractéristiques. La dimension de la caractéristique d'entrée de rhs doit être égale à la dimension de la caractéristique d'entrée de lhs divisée par feature_group_count (elle a donc déjà la taille d'un groupe de caractéristiques d'entrée). Les groupes i-èmes sont utilisés ensemble pour calculer feature_group_count pour de nombreuses convolutions distinctes. Les résultats de ces convolutions sont concaténés dans la dimension de caractéristiques de sortie.
Pour la convolution depthwise, l'argument feature_group_count serait défini sur la dimension de la caractéristique d'entrée, et le filtre serait remodelé de [filter_height, filter_width, in_channels, channel_multiplier] à [filter_height, filter_width, 1, in_channels * channel_multiplier]. Pour en savoir plus, consultez tf.nn.depthwise_conv2d.
L'argument batch_group_count (valeur par défaut : 1) peut être utilisé pour les filtres groupés lors de la rétropropagation. batch_group_count doit être un diviseur de la taille de la dimension de lot lhs (entrée). Si batch_group_count est supérieur à 1, cela signifie que la dimension de lot de sortie doit être de taille input batch
/ batch_group_count. batch_group_count doit être un diviseur de la taille de la fonctionnalité de sortie.
La forme de sortie présente les dimensions suivantes, dans cet ordre :
batch: la taille de cette dimension multipliée parbatch_group_countdoit être égale à la taille de la dimensionbatchdans lhs.z: même taille queoutput-zsur le noyau (rhs).spatial_dims: une valeur pour chaque emplacement valide de la fenêtre de convolution.

La figure ci-dessus montre comment fonctionne le champ batch_group_count. En effet, nous découpons chaque lot lhs en batch_group_count groupes et faisons de même pour les caractéristiques de sortie. Ensuite, pour chacun de ces groupes, nous effectuons des convolutions par paires et concaténons la sortie le long de la dimension de la caractéristique de sortie. La sémantique opérationnelle de toutes les autres dimensions (caractéristiques et spatiales) reste la même.
Les emplacements valides de la fenêtre de convolution sont déterminés par les foulées et la taille de la zone de base après le remplissage.
Pour décrire ce qu'est une convolution, considérons une convolution 2D et choisissons des coordonnées batch, z, y, x fixes dans la sortie. (y,x) correspond à la position d'un angle de la fenêtre dans la zone de base (par exemple, l'angle supérieur gauche, selon votre interprétation des dimensions spatiales). Nous avons maintenant une fenêtre 2D, issue de la zone de base, où chaque point 2D est associé à un vecteur 1D, ce qui nous donne une boîte 3D. À partir du noyau de convolution, puisque nous avons fixé la coordonnée de sortie z, nous avons également une boîte 3D. Les deux boîtes ont les mêmes dimensions. Nous pouvons donc prendre la somme des produits élément par élément entre les deux boîtes (comme un produit scalaire). Il s'agit de la valeur de sortie.
Notez que si output-z est égal à 5, par exemple, chaque position de la fenêtre génère cinq valeurs dans la sortie, dans la dimension z de la sortie. Ces valeurs diffèrent selon la partie du noyau de convolution utilisée. Une boîte de valeurs 3D distincte est utilisée pour chaque coordonnée output-z. Vous pouvez donc considérer qu'il s'agit de cinq convolutions distinctes, chacune avec un filtre différent.
Voici un pseudo-code pour une convolution 2D avec remplissage et foulée :
for (b, oz, oy, ox) { // output coordinates
value = 0;
for (iz, ky, kx) { // kernel coordinates and input z
iy = oy*stride_y + ky - pad_low_y;
ix = ox*stride_x + kx - pad_low_x;
if ((iy, ix) inside the base area considered without padding) {
value += input(b, iz, iy, ix) * kernel(oz, iz, ky, kx);
}
}
output(b, oz, oy, ox) = value;
}
precision_config est utilisé pour indiquer la configuration de précision. Le niveau indique si le matériel doit tenter de générer davantage d'instructions de code machine pour fournir une émulation de type de données plus précise si nécessaire (par exemple, émuler f32 sur un TPU qui ne prend en charge que les matmuls bf16). Les valeurs peuvent être DEFAULT, HIGH ou HIGHEST. Pour en savoir plus, consultez les sections sur les MXU.
preferred_element_type est un élément scalaire des types de sortie de précision supérieure/inférieure utilisés pour l'accumulation. preferred_element_type recommande le type d'accumulation pour l'opération donnée, mais cela n'est pas garanti. Cela permet à certains backends matériels d'accumuler plutôt dans un type différent et de convertir au type de sortie préféré.
Pour en savoir plus sur StableHLO, consultez StableHLO – convolution.
ConvWithGeneralPadding
Voir aussi XlaBuilder::ConvWithGeneralPadding.
ConvWithGeneralPadding(lhs, rhs, window_strides, padding,
feature_group_count, batch_group_count, precision_config,
preferred_element_type)
Identique à Conv où la configuration de la marge intérieure est explicite.
| Arguments | Type | Sémantique |
|---|---|---|
lhs
|
XlaOp
|
Tableau d'entrées à (n+2) dimensions |
rhs
|
XlaOp
|
Tableau de pondérations du noyau à (n+2) dimensions |
window_strides |
ArraySlice<int64> |
Tableau n-d des foulées du noyau |
padding
|
ArraySlice<
pair<int64,int64>> |
Tableau n-d de marge intérieure (bas, haut) |
feature_group_count
|
int64 | le nombre de groupes de caractéristiques ; |
batch_group_count |
int64 | le nombre de groupes de lots ; |
precision_config
|
facultatif
PrecisionConfig |
Énumération pour le niveau de précision. |
preferred_element_type
|
facultatif
PrimitiveType |
Énumération du type d'élément scalaire |
ConvWithGeneralDimensions
Voir aussi XlaBuilder::ConvWithGeneralDimensions.
ConvWithGeneralDimensions(lhs, rhs, window_strides, padding,
dimension_numbers, feature_group_count, batch_group_count, precision_config,
preferred_element_type)
Identique à Conv où les numéros de dimension sont explicites.
| Arguments | Type | Sémantique |
|---|---|---|
lhs
|
XlaOp
|
Tableau d'entrées à (n+2) dimensions |
rhs
|
XlaOp
|
Tableau de pondérations du noyau de dimension (n+2) |
window_strides
|
ArraySlice<int64>
|
Tableau n-d des foulées du noyau |
padding |
Padding |
Énumération de la marge intérieure |
dimension_numbers
|
ConvolutionDimensionNumbers
|
le nombre de dimensions |
feature_group_count
|
int64 | le nombre de groupes de caractéristiques ; |
batch_group_count
|
int64 | le nombre de groupes de lots ; |
precision_config
|
facultatif PrecisionConfig
|
Énumération pour le niveau de précision |
preferred_element_type
|
facultatif PrimitiveType
|
Énumération du type d'élément scalaire |
ConvGeneral
Voir aussi XlaBuilder::ConvGeneral.
ConvGeneral(lhs, rhs, window_strides, padding, dimension_numbers,
feature_group_count, batch_group_count, precision_config,
preferred_element_type)
Identique à Conv où les numéros de dimension et la configuration du remplissage sont explicites
| Arguments | Type | Sémantique |
|---|---|---|
lhs
|
XlaOp
|
Tableau d'entrées à (n+2) dimensions |
rhs
|
XlaOp
|
Tableau de pondérations du noyau de dimension (n+2) |
window_strides
|
ArraySlice<int64>
|
Tableau n-d des foulées du noyau |
padding
|
ArraySlice<
pair<int64,int64>>
|
Tableau n-d de marge intérieure (basse, haute) |
dimension_numbers
|
ConvolutionDimensionNumbers
|
le nombre de dimensions |
feature_group_count
|
int64 | le nombre de groupes de caractéristiques ; |
batch_group_count
|
int64 | le nombre de groupes de lots ; |
precision_config
|
facultatif PrecisionConfig
|
Énumération pour le niveau de précision |
preferred_element_type
|
facultatif PrimitiveType
|
Énumération du type d'élément scalaire |
ConvGeneralDilated
Voir aussi XlaBuilder::ConvGeneralDilated.
ConvGeneralDilated(lhs, rhs, window_strides, padding, lhs_dilation,
rhs_dilation, dimension_numbers, feature_group_count, batch_group_count,
precision_config, preferred_element_type, window_reversal)
Identique à Conv où la configuration du remplissage, les facteurs de dilatation et les numéros de dimension sont explicites.
| Arguments | Type | Sémantique |
|---|---|---|
lhs
|
XlaOp
|
Tableau d'entrées à (n+2) dimensions |
rhs
|
XlaOp
|
Tableau de pondérations du noyau de dimension (n+2) |
window_strides
|
ArraySlice<int64>
|
Tableau n-d des foulées du noyau |
padding
|
ArraySlice<
pair<int64,int64>>
|
Tableau n-d de marge intérieure (basse, haute) |
lhs_dilation
|
ArraySlice<int64>
|
Tableau de facteurs de dilatation lhs n-d |
rhs_dilation
|
ArraySlice<int64>
|
Tableau de facteurs de dilatation du côté droit n-d |
dimension_numbers
|
ConvolutionDimensionNumbers
|
le nombre de dimensions |
feature_group_count
|
int64 | le nombre de groupes de caractéristiques ; |
batch_group_count
|
int64 | le nombre de groupes de lots ; |
precision_config
|
facultatif PrecisionConfig
|
Énumération pour le niveau de précision |
preferred_element_type
|
facultatif PrimitiveType
|
Énumération du type d'élément scalaire |
window_reversal
|
facultatif vector<bool>
|
Indicateur utilisé pour inverser logiquement la dimension avant d'appliquer la convolution. |
Copier
Voir aussi HloInstruction::CreateCopyStart.
Copy est décomposé en interne en deux instructions HLO : CopyStart et CopyDone. Copy, CopyStart et CopyDone servent de primitives dans HLO. Ces opérations peuvent apparaître dans les dumps HLO, mais elles ne sont pas destinées à être construites manuellement par les utilisateurs finaux.
COS
Voir aussiXlaBuilder::Cos.
Cosinus par élément x -> cos(x).
Cos(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Cos accepte également l'argument facultatif result_accuracy :
Cos(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Pour en savoir plus sur StableHLO, consultez StableHLO – cosinus.
Cosh
Voir aussi XlaBuilder::Cosh.
Cosinus hyperbolique élément par élément x -> cosh(x).
Cosh(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Cosh accepte également l'argument facultatif result_accuracy :
Cosh(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
CustomCall
Voir aussi XlaBuilder::CustomCall.
Appelez une fonction fournie par l'utilisateur dans un calcul.
La documentation CustomCall est disponible dans Informations pour les développeurs : appels personnalisés XLA.
Pour en savoir plus sur StableHLO, consultez StableHLO – custom_call.
Div
Voir aussi XlaBuilder::Div.
Effectue une division élément par élément du dividende lhs et du diviseur rhs.
Div(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Le dépassement de capacité de la division entière (division/reste signés/non signés par zéro ou division/reste signés de INT_SMIN avec -1) produit une valeur définie par l'implémentation.
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour Div :
Div(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – division.
Domaine
Voir aussi HloInstruction::CreateDomain.
Domain peut apparaître dans les dumps HLO, mais il n'est pas destiné à être construit manuellement par les utilisateurs finaux.
Point
Voir aussi XlaBuilder::Dot.
Dot(lhs, rhs, precision_config, preferred_element_type)
| Arguments | Type | Sémantique |
|---|---|---|
lhs |
XlaOp |
tableau de type T |
rhs |
XlaOp |
tableau de type T |
precision_config
|
facultatif
PrecisionConfig |
Énumération pour le niveau de précision. |
preferred_element_type
|
facultatif
PrimitiveType |
Énumération du type d'élément scalaire |
La sémantique exacte de cette opération dépend des rangs des opérandes :
| Entrée | Sortie | Sémantique |
|---|---|---|
vecteur [n] dot vecteur [n] |
scalaire | produit scalaire de vecteurs |
matrice [m x k] dot vecteur
[k] |
vecteur [m] | multiplication matrice-vecteur |
matrice [m x k] dot matrice [k x n] |
matrice [m x n] | multiplication matricielle |
L'opération effectue la somme des produits sur la deuxième dimension de lhs (ou la première si elle comporte une seule dimension) et la première dimension de rhs. Il s'agit des dimensions "contractées". Les dimensions contractées de lhs et rhs doivent être de la même taille. En pratique, elle peut être utilisée pour effectuer des produits scalaires entre des vecteurs, des multiplications vecteur/matrice ou des multiplications matrice/matrice.
precision_config est utilisé pour indiquer la configuration de précision. Le niveau indique si le matériel doit tenter de générer davantage d'instructions de code machine pour fournir une émulation de type de données plus précise si nécessaire (par exemple, émuler f32 sur un TPU qui ne prend en charge que les matmuls bf16). Les valeurs peuvent être DEFAULT, HIGH ou HIGHEST. Pour en savoir plus, consultez les sections sur les MXU.
preferred_element_type est un élément scalaire des types de sortie de précision supérieure/inférieure utilisés pour l'accumulation. preferred_element_type recommande le type d'accumulation pour l'opération donnée, mais cela n'est pas garanti. Cela permet à certains backends matériels d'accumuler plutôt dans un type différent et de convertir au type de sortie préféré.
Pour en savoir plus sur StableHLO, consultez StableHLO – dot.
DotGeneral
Voir aussi XlaBuilder::DotGeneral.
DotGeneral(lhs, rhs, dimension_numbers, precision_config,
preferred_element_type)
| Arguments | Type | Sémantique |
|---|---|---|
lhs |
XlaOp |
tableau de type T |
rhs |
XlaOp |
tableau de type T |
dimension_numbers
|
DotDimensionNumbers
|
Numéros de dimension de contraction et de lot |
precision_config
|
facultatif
PrecisionConfig |
Énumération pour le niveau de précision |
preferred_element_type
|
facultatif
PrimitiveType |
Énumération du type d'élément scalaire |
Semblable à Dot, mais permet de spécifier les nombres de dimensions de contraction et de lot pour lhs et rhs.
| Champs DotDimensionNumbers | Type | Sémantique |
|---|---|---|
lhs_contracting_dimensions
|
repeated int64 | lhs nombres de dimensions de contraction |
rhs_contracting_dimensions
|
repeated int64 | rhs nombres de dimensions de contraction |
lhs_batch_dimensions
|
repeated int64 | lhs nombres de dimensions de lot |
rhs_batch_dimensions
|
repeated int64 | rhs nombres de dimensions de lot |
DotGeneral effectue la somme des produits sur les dimensions de contraction spécifiées dans dimension_numbers.
Les numéros de dimension de contraction associés de lhs et rhs n'ont pas besoin d'être identiques, mais doivent avoir les mêmes tailles de dimension.
Exemple avec des nombres de dimensions contractés :
lhs = { {1.0, 2.0, 3.0},
{4.0, 5.0, 6.0} }
rhs = { {1.0, 1.0, 1.0},
{2.0, 2.0, 2.0} }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(1);
dnums.add_rhs_contracting_dimensions(1);
DotGeneral(lhs, rhs, dnums) -> { { 6.0, 12.0},
{15.0, 30.0} }
Les nombres de dimensions de lot associés de lhs et rhs doivent avoir les mêmes tailles de dimensions.
Exemple avec des nombres de dimensions de lot (taille de lot 2, matrices 2x2) :
lhs = { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
rhs = { { {1.0, 0.0},
{0.0, 1.0} },
{ {1.0, 0.0},
{0.0, 1.0} } }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(2);
dnums.add_rhs_contracting_dimensions(1);
dnums.add_lhs_batch_dimensions(0);
dnums.add_rhs_batch_dimensions(0);
DotGeneral(lhs, rhs, dnums) -> {
{ {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
| Entrée | Sortie | Sémantique |
|---|---|---|
[b0, m, k] dot [b0, k, n] |
[b0, m, n] | matmul par lot |
[b0, b1, m, k] dot [b0, b1, k, n] |
[b0, b1, m, n] | matmul par lot |
Il s'ensuit que le nombre de dimensions résultant commence par la dimension de lot, puis par la dimension lhs non contractante/non de lot, et enfin par la dimension rhs non contractante/non de lot.
precision_config est utilisé pour indiquer la configuration de précision. Le niveau indique si le matériel doit tenter de générer davantage d'instructions de code machine pour fournir une émulation de type de données plus précise si nécessaire (par exemple, émuler f32 sur un TPU qui ne prend en charge que les matmuls bf16). Les valeurs peuvent être DEFAULT, HIGH ou HIGHEST. Pour en savoir plus, consultez les sections sur les MXU.
preferred_element_type est un élément scalaire des types de sortie de précision supérieure/inférieure utilisés pour l'accumulation. preferred_element_type recommande le type d'accumulation pour l'opération donnée, mais cela n'est pas garanti. Cela permet à certains backends matériels d'accumuler plutôt dans un type différent et de convertir au type de sortie préféré.
Pour en savoir plus sur StableHLO, consultez StableHLO – dot_general.
ScaledDot
Voir aussi XlaBuilder::ScaledDot.
ScaledDot(lhs, lhs_scale, rhs, rhs_scale, dimension_number,
precision_config,preferred_element_type)
| Arguments | Type | Sémantique |
|---|---|---|
lhs |
XlaOp |
tableau de type T |
rhs |
XlaOp |
tableau de type T |
lhs_scale |
XlaOp |
tableau de type T |
rhs_scale |
XlaOp |
tableau de type T |
dimension_number
|
ScatterDimensionNumbers
|
Numéros de dimension pour l'opération de dispersion |
precision_config
|
PrecisionConfig
|
Énumération pour le niveau de précision |
preferred_element_type
|
facultatif PrimitiveType
|
Énumération du type d'élément scalaire |
Semblable à DotGeneral.
Crée une opération de produit scalaire avec les opérandes "lhs", "lhs_scale", "rhs" et "rhs_scale", avec les dimensions de contraction et de lot spécifiées dans "dimension_numbers".
RaggedDot
Voir aussi XlaBuilder::RaggedDot.
Pour une répartition du calcul RaggedDot, consultez StableHLO – chlo.ragged_dot.
DynamicReshape
Voir aussi XlaBuilder::DynamicReshape.
Cette opération est fonctionnellement identique à reshape, mais la forme du résultat est spécifiée de manière dynamique via output_shape.
DynamicReshape(operand, dim_sizes, new_size_bounds, dims_are_dynamic)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau à N dimensions de type T |
dim_sizes |
vecteur de XlaOP |
Tailles de vecteur N-dimensionnelles |
new_size_bounds |
vecteur de int63 |
Vecteur de limites à N dimensions |
dims_are_dynamic |
vecteur de bool |
Dimension dynamique N |
Pour en savoir plus sur StableHLO, consultez StableHLO – dynamic_reshape.
DynamicSlice
Voir aussi XlaBuilder::DynamicSlice.
DynamicSlice extrait un sous-tableau du tableau d'entrée à start_indices dynamique. La taille de la tranche dans chaque dimension est transmise dans size_indices, qui spécifie le point d'arrivée des intervalles de tranche exclusifs dans chaque dimension : [start, start + size). La forme de start_indices doit être unidimensionnelle, avec une taille de dimension égale au nombre de dimensions de operand.
DynamicSlice(operand, start_indices, slice_sizes)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau à N dimensions de type T |
start_indices
|
séquence de N XlaOp
|
Liste de N entiers scalaires contenant les indices de début de la tranche pour chaque dimension. La valeur doit être supérieure ou égale à zéro. |
size_indices
|
ArraySlice<int64>
|
Liste de N entiers contenant la taille du slice pour chaque dimension. Chaque valeur doit être strictement supérieure à zéro, et la somme de la valeur de début et de la taille doit être inférieure ou égale à la taille de la dimension pour éviter le retour à zéro modulo la taille de la dimension. |
Les indices de tranche effectifs sont calculés en appliquant la transformation suivante pour chaque indice i dans [1, N) avant d'effectuer le découpage :
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - slice_sizes[i])
Cela garantit que la tranche extraite est toujours dans les limites du tableau d'opérandes. Si la tranche est dans les limites avant l'application de la transformation, celle-ci n'a aucun effet.
Exemple unidimensionnel :
let a = {0.0, 1.0, 2.0, 3.0, 4.0};
let s = {2};
DynamicSlice(a, s, {2});
// Result: {2.0, 3.0}
Exemple en deux dimensions :
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let s = {2, 1}
DynamicSlice(b, s, {2, 2});
//Result:
// { { 7.0, 8.0},
// {10.0, 11.0} }
Pour en savoir plus sur StableHLO, consultez StableHLO – dynamic_slice.
DynamicUpdateSlice
Voir aussi XlaBuilder::DynamicUpdateSlice.
DynamicUpdateSlice génère un résultat qui correspond à la valeur du tableau d'entrée operand, avec une tranche update écrasée à start_indices.
La forme de update détermine la forme du sous-tableau du résultat qui est mis à jour.
La forme de start_indices doit être unidimensionnelle, avec une taille de dimension égale au nombre de dimensions de operand.
DynamicUpdateSlice(operand, update, start_indices)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau à N dimensions de type T |
update
|
XlaOp
|
Tableau à N dimensions de type T contenant la mise à jour du slice. Chaque dimension de la forme de mise à jour doit être strictement supérieure à zéro, et la somme de "start" et "update" doit être inférieure ou égale à la taille de l'opérande pour chaque dimension afin d'éviter de générer des indices de mise à jour hors limites. |
start_indices
|
séquence de N XlaOp
|
Liste de N entiers scalaires contenant les indices de début de la tranche pour chaque dimension. La valeur doit être supérieure ou égale à zéro. |
Les indices de tranche effectifs sont calculés en appliquant la transformation suivante pour chaque indice i dans [1, N) avant d'effectuer le découpage :
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - update.dimension_size[i])
Cela garantit que la tranche mise à jour est toujours dans les limites par rapport au tableau d'opérandes. Si la tranche est dans les limites avant l'application de la transformation, la transformation n'a aucun effet.
Exemple unidimensionnel :
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let u = {5.0, 6.0}
let s = {2}
DynamicUpdateSlice(a, u, s)
// Result: {0.0, 1.0, 5.0, 6.0, 4.0}
Exemple en deux dimensions :
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let u =
{ {12.0, 13.0},
{14.0, 15.0},
{16.0, 17.0} }
let s = {1, 1}
DynamicUpdateSlice(b, u, s)
// Result:
// { {0.0, 1.0, 2.0},
// {3.0, 12.0, 13.0},
// {6.0, 14.0, 15.0},
// {9.0, 16.0, 17.0} }
Pour en savoir plus sur StableHLO, consultez StableHLO – dynamic_update_slice.
Erf
Voir aussi XlaBuilder::Erf.
Fonction d'erreur au niveau des éléments x -> erf(x), où :
\(\text{erf}(x) = \frac{2}{\sqrt{\pi} }\int_0^x e^{-t^2} \, dt\).
Erf(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Erf accepte également l'argument facultatif result_accuracy :
Erf(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Exp.
Voir aussi XlaBuilder::Exp.
Exponentielle naturelle par élément x -> e^x.
Exp(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Exp accepte également l'argument facultatif result_accuracy :
Exp(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Pour en savoir plus sur StableHLO, consultez StableHLO – exponentiel.
Expm1
Voir aussi XlaBuilder::Expm1.
Exponentielle naturelle par élément moins un x -> e^x - 1.
Expm1(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Expm1 accepte également l'argument facultatif result_accuracy :
Expm1(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Pour en savoir plus sur StableHLO, consultez StableHLO – exponential_minus_one.
Fft
Voir aussi XlaBuilder::Fft.
L'opération FFT XLA implémente les transformées de Fourier directe et inverse pour les entrées/sorties réelles et complexes. Les FFT multidimensionnelles sont acceptées sur un maximum de trois axes.
Fft(operand, ftt_type, fft_length)
| Arguments | Type | Sémantique |
|---|---|---|
operand
|
XlaOp
|
Tableau que nous transformons à l'aide de la transformée de Fourier. |
fft_type |
FftType |
Consultez le tableau ci-dessous. |
fft_length
|
ArraySlice<int64>
|
Longueurs du domaine temporel des axes transformés. Cela est nécessaire en particulier pour que IRFFT dimensionne correctement l'axe le plus intérieur, car RFFT(fft_length=[16]) a la même forme de sortie que RFFT(fft_length=[17]). |
FftType |
Sémantique |
|---|---|
FFT |
FFT complexe-à-complexe directe. La forme reste inchangée. |
IFFT |
FFT complexe-à-complexe inverse. La forme reste inchangée. |
RFFT
|
FFT réelle à complexe. La forme de l'axe le plus intérieur est réduite à fft_length[-1] // 2 + 1 si fft_length[-1] est une valeur non nulle, en omettant la partie conjuguée inversée du signal transformé au-delà de la fréquence de Nyquist. |
IRFFT
|
FFT inverse réel-complexe (c'est-à-dire prend un nombre complexe et renvoie un nombre réel).
La forme de l'axe le plus intérieur est étendue à fft_length[-1] si fft_length[-1] est une valeur non nulle, ce qui infère la partie du signal transformé au-delà de la fréquence de Nyquist à partir du conjugué inverse des entrées 1 à fft_length[-1] // 2 + 1. |
Pour en savoir plus sur StableHLO, consultez StableHLO – fft.
FFT multidimensionnelle
Lorsque plusieurs fft_length sont fournis, cela équivaut à appliquer une cascade d'opérations FFT à chacun des axes les plus intérieurs. Notez que pour les cas réel->complexe et complexe->réel, la transformation de l'axe le plus intérieur est (effectivement) effectuée en premier (RFFT ; en dernier pour IRFFT), c'est pourquoi l'axe le plus intérieur est celui dont la taille change. Les autres transformations d'axe seront alors complexes->complexes.
Détails de mise en œuvre
La FFT du processeur est soutenue par TensorFFT d'Eigen. La FFT du GPU utilise cuFFT.
Étage
Voir aussi XlaBuilder::Floor.
Plancher par élément x -> ⌊x⌋.
Floor(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Pour en savoir plus sur StableHLO, consultez StableHLO – floor.
Fusion
Voir aussi HloInstruction::CreateFusion.
L'opération Fusion représente les instructions HLO et sert de primitive dans HLO.
Cette opération peut apparaître dans les dumps HLO, mais n'est pas destinée à être construite manuellement par les utilisateurs finaux.
Collecter
L'opération XLA gather rassemble plusieurs tranches (chacune à un décalage d'exécution potentiellement différent) d'un tableau d'entrée.
Pour en savoir plus sur StableHLO, consultez StableHLO – gather.
Sémantique générale
Voir aussi XlaBuilder::Gather.
Pour une description plus intuitive, consultez la section "Description informelle" ci-dessous.
gather(operand, start_indices, dimension_numbers, slice_sizes,
indices_are_sorted)
| Arguments | Type | Sémantique |
|---|---|---|
operand
|
XlaOp
|
Tableau à partir duquel nous collectons les données. |
start_indices
|
XlaOp
|
Tableau contenant les index de départ des tranches que nous collectons. |
dimension_numbers
|
GatherDimensionNumbers
|
Dimension dans start_indices qui "contient" les index de départ. Pour en savoir plus, consultez la description détaillée ci-dessous. |
slice_sizes
|
ArraySlice<int64>
|
slice_sizes[i] correspond aux limites de la tranche pour la dimension i. |
indices_are_sorted
|
bool
|
Indique si l'appelant garantit que les index sont triés. |
Pour plus de commodité, nous attribuons le libellé batch_dims aux dimensions du tableau de sortie qui ne figurent pas dans offset_dims.
La sortie est un tableau avec batch_dims.size + offset_dims.size dimensions.
operand.rank doit être égal à la somme de offset_dims.size et collapsed_slice_dims.size. De plus, slice_sizes.size doit être égal à operand.rank.
Si index_vector_dim est égal à start_indices.rank, nous considérons implicitement que start_indices a une dimension 1 de fin (c'est-à-dire que si start_indices était de forme [6,7] et que index_vector_dim est 2, nous considérons implicitement que la forme de start_indices est [6,7,1]).
Les limites du tableau de sortie le long de la dimension i sont calculées comme suit :
Si
iest présent dansbatch_dims(c'est-à-dire égal àbatch_dims[k]pour certainsk), nous sélectionnons les limites de dimension correspondantes dansstart_indices.shape, en ignorantindex_vector_dim(c'est-à-dire en sélectionnantstart_indices.shape.dims[k] sik<index_vector_dimetstart_indices.shape.dims[k+1] sinon).Si
iest présent dansoffset_dims(c'est-à-dire égal àoffset_dims[k] pour un certaink), nous choisissons la limite correspondante dansslice_sizesaprès avoir tenu compte decollapsed_slice_dims(c'est-à-dire que nous choisissonsadjusted_slice_sizes[k] oùadjusted_slice_sizesestslice_sizesavec les limites aux indicescollapsed_slice_dimssupprimées).
Formellement, l'index d'opérande In correspondant à un index de sortie donné Out est calculé comme suit :
Soit
G= {Out[k] pourkdansbatch_dims}. UtilisezGpour extraire un vecteurStel queS[i] =start_indices[Combine(G,i)] où Combine(A, b) insère b à la positionindex_vector_dimdans A. Notez que cela est bien défini même siGest vide : siGest vide, alorsS=start_indices.Créez un index de départ,
Sin, dansoperanden dispersantSà l'aide destart_index_map.SPlus précisément :Sin[start_index_map[k]] =S[k] sik<start_index_map.size.Sin[_] =0sinon.
Crée un index
Oindansoperanden dispersant les index au niveau des dimensions de décalage dansOutselon l'ensemblecollapsed_slice_dims. Plus précisément :Oin[remapped_offset_dims(k)] =Out[offset_dims[k]] sik<offset_dims.size(remapped_offset_dimsest défini ci-dessous).Oin[_] =0sinon.
InestOin+Sin, où + correspond à l'addition élément par élément.
remapped_offset_dims est une fonction monotone avec un domaine [0,offset_dims.size) et une plage [0, operand.rank) \ collapsed_slice_dims. Par exemple, si offset_dims.size est 4, operand.rank est 6 et collapsed_slice_dims est {0, 2}, alors remapped_offset_dims est {0→1, 1→3, 2→4, 3→5}.
Si indices_are_sorted est défini sur "true", XLA peut supposer que start_indices sont triés (par ordre croissant, après la dispersion de leurs valeurs selon start_index_map) par l'utilisateur. Si ce n'est pas le cas, la sémantique est définie par l'implémentation.
Description informelle et exemples
De manière informelle, chaque index Out du tableau de sortie correspond à un élément E du tableau d'opérandes, calculé comme suit :
Nous utilisons les dimensions de lot dans
Outpour rechercher un index de départ à partir destart_indices.Nous utilisons
start_index_mappour mapper l'index de départ (dont la taille peut être inférieure à operand.rank) à un index de départ "complet" dansoperand.Nous découpons dynamiquement un slice de taille
slice_sizesen utilisant l'index de début complet.Nous remodelons le slice en réduisant les dimensions
collapsed_slice_dims. Étant donné que toutes les dimensions de tranche réduites doivent avoir une limite de 1, cette redimension est toujours légale.Nous utilisons les dimensions de décalage dans
Outpour indexer cette tranche afin d'obtenir l'élément d'entrée,E, correspondant à l'index de sortieOut.
index_vector_dim est défini sur start_indices.rank – 1 dans tous les exemples suivants. Des valeurs plus intéressantes pour index_vector_dim ne modifient pas fondamentalement l'opération, mais rendent la représentation visuelle plus complexe.
Pour mieux comprendre comment tout cela s'articule, examinons un exemple qui rassemble cinq tranches de forme [8,6] à partir d'un tableau [16,11]. La position d'une tranche dans le tableau [16,11] peut être représentée sous la forme d'un vecteur d'index de forme S64[2]. L'ensemble de cinq positions peut donc être représenté sous la forme d'un tableau S64[5,2].
Le comportement de l'opération de collecte peut ensuite être représenté comme une transformation d'index qui prend [G,O0,O1], un index dans la forme de sortie, et le mappe à un élément du tableau d'entrée de la manière suivante :

Nous sélectionnons d'abord un vecteur (X,Y) à partir du tableau d'indices de collecte à l'aide de G.
L'élément du tableau de sortie à l'index [G,O0,O1] est alors l'élément du tableau d'entrée à l'index [X+O0,Y+O1].
slice_sizes est [8,6], ce qui détermine la plage de O0 et O1, qui à son tour détermine les limites de la tranche.
Cette opération de collecte agit comme une tranche dynamique par lot avec G comme dimension de lot.
Les index de collecte peuvent être multidimensionnels. Par exemple, une version plus générale de l'exemple ci-dessus utilisant un tableau "gather indices" de forme [4,5,2] traduirait les indices comme suit :

Ici encore, il s'agit d'une tranche dynamique de lot G0 et G1 en tant que dimensions de lot. La taille de la tranche est toujours [8,6].
L'opération de collecte dans XLA généralise la sémantique informelle décrite ci-dessus de la manière suivante :
Nous pouvons configurer les dimensions de la forme de sortie qui sont les dimensions de décalage (dimensions contenant
O0,O1dans le dernier exemple). Les dimensions de lot de sortie (dimensions contenantG0,G1dans le dernier exemple) sont définies comme les dimensions de sortie qui ne sont pas des dimensions de décalage.Le nombre de dimensions de décalage de sortie explicitement présentes dans la forme de sortie peut être inférieur au nombre de dimensions d'entrée. Ces dimensions "manquantes", qui sont listées explicitement comme
collapsed_slice_dims, doivent avoir une taille de tranche de1. Comme leur taille de tranche est de1, le seul index valide pour elles est0. Leur élision n'introduit aucune ambiguïté.La tranche extraite du tableau "Gather Indices" ((
X,Y) dans le dernier exemple) peut comporter moins d'éléments que le nombre de dimensions du tableau d'entrée. Un mappage explicite indique comment l'index doit être étendu pour avoir le même nombre de dimensions que l'entrée.
Pour le dernier exemple, nous utilisons (2) et (3) pour implémenter tf.gather_nd :

G0 et G1 sont utilisés pour extraire un index de départ du tableau d'index de collecte comme d'habitude, sauf que l'index de départ ne comporte qu'un seul élément, X. De même, il n'existe qu'un seul index de décalage de sortie avec la valeur O0. Toutefois, avant d'être utilisés comme index dans le tableau d'entrée, ils sont développés conformément à "Gather Index Mapping" (start_index_map dans la description formelle) et "Offset Mapping" (remapped_offset_dims dans la description formelle) en [X,0] et [0,O0] respectivement, ce qui donne [X,O0]. En d'autres termes, l'index de sortie [G0,G1,O0] correspond à l'index d'entrée [GatherIndices[G0,G1,0],O0], ce qui nous donne la sémantique pour tf.gather_nd.
Le slice_sizes pour cette demande est [1,11]. Intuitivement, cela signifie que chaque index X du tableau d'index de collecte sélectionne une ligne entière, et que le résultat est la concaténation de toutes ces lignes.
GetDimensionSize
Voir aussi XlaBuilder::GetDimensionSize.
Renvoie la taille de la dimension donnée de l'opérande. L'opérande doit être de forme matricielle.
GetDimensionSize(operand, dimension)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau d'entrée à n dimensions |
dimension
|
int64
|
Valeur dans l'intervalle [0, n) qui spécifie la dimension. |
Pour en savoir plus sur StableHLO, consultez StableHLO – get_dimension_size.
GetTupleElement
Voir aussi XlaBuilder::GetTupleElement.
Index dans un tuple avec une valeur constante au moment de la compilation.
La valeur doit être une constante de compilation afin que l'inférence de forme puisse déterminer le type de la valeur résultante.
Cela est analogue à std::get<int N>(t) en C++. Conceptuellement :
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
let element_1: s32 = gettupleelement(t, 1); // Inferred shape matches s32.
Voir aussi tf.tuple.
GetTupleElement(tuple_data, index)
| Argument | Type | Sémantique |
|---|---|---|
tuple_data |
XlaOP |
Le tuple |
index |
int64 |
Index de la forme du tuple |
Pour en savoir plus sur StableHLO, consultez StableHLO – get_tuple_element.
Imag
Voir aussi XlaBuilder::Imag.
Partie imaginaire élément par élément d'une forme complexe (ou réelle). x -> imag(x). Si l'opérande est de type à virgule flottante, renvoie 0.
Imag(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Pour en savoir plus sur StableHLO, consultez StableHLO – imag.
In-Feed
Voir aussi XlaBuilder::Infeed.
Infeed(shape, config)
| Argument | Type | Sémantique |
|---|---|---|
shape
|
Shape
|
Forme des données lues à partir de l'interface Infeed. Le champ de mise en page de la forme doit être défini pour correspondre à la mise en page des données envoyées à l'appareil. Sinon, son comportement est indéfini. |
config |
facultatif string |
Configuration de l'opération. |
Lit un seul élément de données à partir de l'interface de streaming Infeed implicite de l'appareil, interprète les données comme la forme et la mise en page données, et renvoie un XlaOp des données. Plusieurs opérations Infeed sont autorisées dans un calcul, mais il doit y avoir un ordre total entre les opérations Infeed. Par exemple, deux Infeed dans le code ci-dessous ont un ordre total, car il existe une dépendance entre les boucles while.
result1 = while (condition, init = init_value) {
Infeed(shape)
}
result2 = while (condition, init = result1) {
Infeed(shape)
}
Les formes de tuples imbriquées ne sont pas acceptées. Pour une forme de tuple vide, l'opération Infeed est effectivement une no-op et se poursuit sans lire aucune donnée à partir de l'Infeed de l'appareil.
Pour en savoir plus sur StableHLO, consultez StableHLO – Infeed.
Iota
Voir aussi XlaBuilder::Iota.
Iota(shape, iota_dimension)
Crée un littéral constant sur l'appareil plutôt qu'un transfert d'hôte potentiellement volumineux. Crée un tableau ayant la forme spécifiée et contenant des valeurs commençant à zéro et augmentant d'une unité le long de la dimension spécifiée. Pour les types à virgule flottante, le tableau produit est équivalent à ConvertElementType(Iota(...)) où Iota est de type entier et la conversion est de type à virgule flottante.
| Arguments | Type | Sémantique |
|---|---|---|
shape |
Shape |
Forme du tableau créé par Iota() |
iota_dimension |
int64 |
Dimension à incrémenter. |
Par exemple, Iota(s32[4, 8], 0) renvoie
[[0, 0, 0, 0, 0, 0, 0, 0 ],
[1, 1, 1, 1, 1, 1, 1, 1 ],
[2, 2, 2, 2, 2, 2, 2, 2 ],
[3, 3, 3, 3, 3, 3, 3, 3 ]]
Retours pour Iota(s32[4, 8], 1)
[[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ]]
Pour en savoir plus sur StableHLO, consultez StableHLO – iota.
IsFinite
Voir aussi XlaBuilder::IsFinite.
Teste si chaque élément de operand est fini, c'est-à-dire s'il n'est pas une infinité positive ou négative, et s'il n'est pas NaN. Renvoie un tableau de valeurs PRED de même forme que l'entrée, où chaque élément est true si et seulement si l'élément d'entrée correspondant est fini.
IsFinite(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Pour en savoir plus sur StableHLO, consultez StableHLO – is_finite.
Journal
Voir aussi XlaBuilder::Log.
Logarithme naturel par élément x -> ln(x).
Log(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Log accepte également l'argument facultatif result_accuracy :
Log(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Pour en savoir plus sur StableHLO, consultez StableHLO – journal.
Log1p
Voir aussi XlaBuilder::Log1p.
Logarithme naturel décalé par élément x -> ln(1+x).
Log1p(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Log1p accepte également l'argument facultatif result_accuracy :
Log1p(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Pour en savoir plus sur StableHLO, consultez StableHLO – log_plus_one.
Logistique
Voir aussi XlaBuilder::Logistic.
Calcul de la fonction logistique par élément x -> logistic(x).
Logistic(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
La fonction logistique accepte également l'argument facultatif result_accuracy :
Logistic(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Pour en savoir plus sur StableHLO, consultez StableHLO – Logistique.
Carte
Voir aussi XlaBuilder::Map.
Map(operands..., computation, dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
operands |
séquence de N XlaOp |
N tableaux de types T0..T{N-1} |
computation
|
XlaComputation
|
Calcul de type T_0, T_1,
.., T_{N + M -1} -> S avec N paramètres de type T et M de type arbitraire. |
dimensions |
Tableau int64 |
Tableau des dimensions de la carte |
static_operands
|
séquence de N XlaOp |
Opérations statiques pour l'opération de carte |
Applique une fonction scalaire aux tableaux operands donnés, ce qui produit un tableau de mêmes dimensions où chaque élément est le résultat de la fonction mappée appliquée aux éléments correspondants des tableaux d'entrée.
La fonction mappée est un calcul arbitraire avec la restriction qu'elle comporte N entrées de type scalaire T et une seule sortie de type S. La sortie a les mêmes dimensions que les opérandes, sauf que le type d'élément T est remplacé par S.
Par exemple, Map(op1, op2, op3, computation, par1) mappe elem_out <-
computation(elem1, elem2, elem3, par1) à chaque index (multidimensionnel) des tableaux d'entrée pour générer le tableau de sortie.
Pour en savoir plus sur StableHLO, consultez StableHLO – map.
Max
Voir aussi XlaBuilder::Max.
Effectue une opération max au niveau des éléments sur les Tensors lhs et rhs.
Max(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour Max :
Max(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – maximum.
Min
Voir aussi XlaBuilder::Min.
Effectue une opération min au niveau des éléments sur lhs et rhs.
Min(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour Min :
Min(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – minimum.
Mul
Voir aussi XlaBuilder::Mul.
Effectue le produit élément par élément de lhs et rhs.
Mul(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour Mul :
Mul(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – multiply.
Neg
Voir aussi XlaBuilder::Neg.
Négation par élément x -> -x.
Neg(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Pour en savoir plus sur StableHLO, consultez StableHLO – négation.
Non
Voir aussi XlaBuilder::Not.
Non logique par élément x -> !(x).
Not(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Pour en savoir plus sur StableHLO, consultez StableHLO – not.
OptimizationBarrier
Voir aussi XlaBuilder::OptimizationBarrier.
Empêche tout pass d'optimisation de déplacer des calculs au-delà de la barrière.
OptimizationBarrier(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Garantit que toutes les entrées sont évaluées avant tout opérateur qui dépend des sorties de la barrière.
Pour en savoir plus sur StableHLO, consultez StableHLO – optimization_barrier.
Ou
Voir aussi XlaBuilder::Or.
Effectue un OR par élément de lhs et rhs .
Or(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour Or :
Or(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO.
Outfeed
Voir aussi XlaBuilder::Outfeed.
Écrit les entrées dans le flux de sortie.
Outfeed(operand, shape_with_layout, outfeed_config)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau de type T |
shape_with_layout |
Shape |
Définit la mise en page des données transférées |
outfeed_config |
string |
Constante de configuration pour l'instruction Outfeed |
shape_with_layout indique la forme que nous souhaitons extraire.
Pour en savoir plus sur StableHLO, consultez StableHLO – Outfeed.
Pad
Voir aussi XlaBuilder::Pad.
Pad(operand, padding_value, padding_config)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau de type T |
padding_value
|
XlaOp
|
scalaire de type T pour remplir le padding ajouté. |
padding_config
|
PaddingConfig
|
Quantité de marge intérieure sur les deux bords (faible, élevé) et entre les éléments de chaque dimension |
Développe le tableau operand donné en ajoutant une marge intérieure autour du tableau ainsi qu'entre les éléments du tableau avec le padding_value donné. padding_config spécifie la quantité de marge intérieure extérieure et intérieure pour chaque dimension.
PaddingConfig est un champ répété de PaddingConfigDimension, qui contient trois champs pour chaque dimension : edge_padding_low, edge_padding_high et interior_padding.
edge_padding_low et edge_padding_high spécifient la quantité de marge intérieure ajoutée respectivement à l'extrémité inférieure (à côté de l'index 0) et à l'extrémité supérieure (à côté de l'index le plus élevé) de chaque dimension. La quantité de marge intérieure peut être négative. La valeur absolue de la marge intérieure négative indique le nombre d'éléments à supprimer de la dimension spécifiée.
interior_padding spécifie la quantité de marge intérieure ajoutée entre deux éléments dans chaque dimension. Elle ne peut pas être négative. La marge intérieure se produit logiquement avant la marge extérieure. Par conséquent, en cas de marge extérieure négative, les éléments sont supprimés de l'opérande avec marge intérieure.
Cette opération est une opération sans effet si les paires de marge intérieure sont toutes (0, 0) et que les valeurs de marge intérieure sont toutes égales à 0. La figure ci-dessous montre des exemples de différentes valeurs edge_padding et interior_padding pour un tableau bidimensionnel.
Pour en savoir plus sur StableHLO, consultez StableHLO – pad.
Paramètre
Voir aussi XlaBuilder::Parameter.
Parameter représente une entrée d'argument pour un calcul.
PartitionID
Voir aussi XlaBuilder::BuildPartitionId.
Produit partition_id du processus actuel.
PartitionID(shape)
| Arguments | Type | Sémantique |
|---|---|---|
shape |
Shape |
Forme des données |
PartitionID peut apparaître dans les dumps HLO, mais il n'est pas destiné à être construit manuellement par les utilisateurs finaux.
Pour en savoir plus sur StableHLO, consultez StableHLO – partition_id.
PopulationCount
Voir aussi XlaBuilder::PopulationCount.
Calcule le nombre de bits définis dans chaque élément de operand.
PopulationCount(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Pour en savoir plus sur StableHLO, consultez StableHLO – popcnt.
Pow
Voir aussi XlaBuilder::Pow.
Effectue une exponentiation élément par élément de lhs par rhs.
Pow(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion de différentes dimensions pour Pow :
Pow(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – power.
Réel
Voir aussi XlaBuilder::Real.
Partie réelle élément par élément d'une forme complexe (ou réelle). x -> real(x). Si l'opérande est de type à virgule flottante, Real renvoie la même valeur.
Real(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Pour en savoir plus sur StableHLO, consultez StableHLO – réel.
Recv
Voir aussi XlaBuilder::Recv.
Recv, RecvWithTokens et RecvToHost sont des opérations qui servent de primitives de communication dans HLO. Ces opérations apparaissent généralement dans les dumps HLO en tant que partie des transferts d'entrée/sortie de bas niveau ou inter-appareils, mais elles ne sont pas destinées à être construites manuellement par les utilisateurs finaux.
Recv(shape, handle)
| Arguments | Type | Sémantique |
|---|---|---|
shape |
Shape |
forme des données à recevoir |
handle |
ChannelHandle |
Identifiant unique pour chaque paire d'envoi/réception |
Reçoit les données de la forme donnée à partir d'une instruction Send dans un autre calcul qui partage le même handle de canal. Renvoie un XlaOp pour les données reçues.
Pour en savoir plus sur StableHLO, consultez StableHLO – recv.
RecvDone
Voir aussi HloInstruction::CreateRecv et HloInstruction::CreateRecvDone.
Comme Send, l'API cliente de l'opération Recv représente une communication synchrone. Toutefois, l'instruction est décomposée en interne en deux instructions HLO (Recv et RecvDone) pour permettre les transferts de données asynchrones.
Recv(const Shape& shape, int64 channel_id)
Alloue les ressources nécessaires pour recevoir des données à partir d'une instruction Send avec le même channel_id. Renvoie un contexte pour les ressources allouées, qui est utilisé par une instruction RecvDone suivante pour attendre la fin du transfert de données. Le contexte est un tuple de {forme du tampon de réception, identifiant de la requête (U32)}. Il ne peut être utilisé que par une instruction RecvDone.
Étant donné un contexte créé par une instruction Recv, attend la fin du transfert de données et renvoie les données reçues.
Réduire
Voir aussi XlaBuilder::Reduce.
Applique une fonction de réduction à un ou plusieurs tableaux en parallèle.
Reduce(operands..., init_values..., computation, dimensions_to_reduce)
| Arguments | Type | Sémantique |
|---|---|---|
operands
|
Séquence de N XlaOp
|
N tableaux de types T_0,...,
T_{N-1}. |
init_values
|
Séquence de N XlaOp
|
N scalaires de types
T_0,..., T_{N-1}. |
computation
|
XlaComputation
|
Calcul de type
T_0,..., T_{N-1}, T_0,
...,T_{N-1} ->
Collate(T_0,...,
T_{N-1}). |
dimensions_to_reduce
|
Tableau int64
|
Tableau non ordonné de dimensions à réduire. |
Où :
- N doit être supérieur ou égal à 1.
- Le calcul doit être "à peu près" associatif (voir ci-dessous).
- Toutes les matrices d'entrée doivent avoir les mêmes dimensions.
- Toutes les valeurs initiales doivent former une identité sous
computation. - Si
N = 1,Collate(T)estT. - Si
N > 1,Collate(T_0, ..., T_{N-1})est un tuple d'élémentsNde typeT.
Cette opération réduit une ou plusieurs dimensions de chaque tableau d'entrée en scalaires.
Le nombre de dimensions de chaque tableau renvoyé est de number_of_dimensions(operand) - len(dimensions). Le résultat de l'opération est Collate(Q_0, ..., Q_N), où Q_i est un tableau de type T_i dont les dimensions sont décrites ci-dessous.
Différents backends sont autorisés à réassocier le calcul de la réduction. Cela peut entraîner des différences numériques, car certaines fonctions de réduction telles que l'addition ne sont pas associatives pour les floats. Toutefois, si la plage de données est limitée, l'addition à virgule flottante est suffisamment associative pour la plupart des utilisations pratiques.
Pour en savoir plus sur StableHLO, consultez StableHLO – reduce.
Exemples
Lorsque vous réduisez une dimension dans un tableau 1D unique avec des valeurs [10, 11,
12, 13], avec la fonction de réduction f (qui est computation), le résultat peut être calculé comme suit :
f(10, f(11, f(12, f(init_value, 13)))
mais il existe également de nombreuses autres possibilités, par exemple :
f(init_value, f(f(10, f(init_value, 11)), f(f(init_value, 12), f(init_value, 13))))
Voici un exemple de pseudo-code approximatif montrant comment la réduction peut être implémentée, en utilisant la somme comme calcul de réduction avec une valeur initiale de 0.
result_shape <- remove all dims in dimensions from operand_shape
# Iterate over all elements in result_shape. The number of r's here is equal
# to the number of dimensions of the result.
for r0 in range(result_shape[0]), r1 in range(result_shape[1]), ...:
# Initialize this result element
result[r0, r1...] <- 0
# Iterate over all the reduction dimensions
for d0 in range(dimensions[0]), d1 in range(dimensions[1]), ...:
# Increment the result element with the value of the operand's element.
# The index of the operand's element is constructed from all ri's and di's
# in the right order (by construction ri's and di's together index over the
# whole operand shape).
result[r0, r1...] += operand[ri... di]
Voici un exemple de réduction d'un tableau 2D (matrice). La forme comporte deux dimensions : la dimension 0 de taille 2 et la dimension 1 de taille 3 :
Résultats de la réduction des dimensions 0 ou 1 avec une fonction "add" :
Notez que les deux résultats de réduction sont des tableaux à une dimension. Le diagramme montre l'un sous forme de colonne et l'autre sous forme de ligne, uniquement pour des raisons de commodité visuelle.
Voici un exemple plus complexe avec un tableau 3D. Il comporte trois dimensions : la dimension 0 de taille 4, la dimension 1 de taille 2 et la dimension 2 de taille 3. Pour plus de simplicité, les valeurs de 1 à 6 sont répliquées dans la dimension 0.
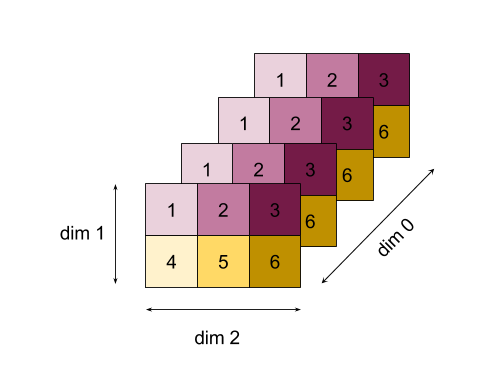
Comme dans l'exemple en 2D, nous pouvons réduire une seule dimension. Si nous réduisons la dimension 0, par exemple, nous obtenons un tableau à deux dimensions dans lequel toutes les valeurs de la dimension 0 ont été réduites en un scalaire :
| 4 8 12 |
| 16 20 24 |
Si nous réduisons la dimension 2, nous obtenons également un tableau à deux dimensions où toutes les valeurs de la dimension 2 ont été réduites à un scalaire :
| 6 15 |
| 6 15 |
| 6 15 |
| 6 15 |
Notez que l'ordre relatif entre les dimensions restantes dans l'entrée est conservé dans la sortie, mais que de nouveaux numéros peuvent être attribués à certaines dimensions (puisque le nombre de dimensions change).
Nous pouvons également réduire plusieurs dimensions. L'ajout de dimensions de réduction 0 et 1 produit le tableau 1D [20, 28, 36].
La réduction du tableau 3D sur toutes ses dimensions produit le scalaire 84.
Réduction variadique
Lorsque N > 1, l'application de la fonction de réduction est légèrement plus complexe, car elle est appliquée simultanément à toutes les entrées. Les opérandes sont fournis au calcul dans l'ordre suivant :
- Valeur réduite en cours pour le premier opérande
- …
- Exécution de la valeur réduite pour le N-ième opérande
- Valeur d'entrée du premier opérande
- …
- Valeur d'entrée du Nième opérande
Par exemple, considérez la fonction de réduction suivante, qui peut être utilisée pour calculer le max et l'argmax d'un tableau à une dimension en parallèle :
f: (Float, Int, Float, Int) -> Float, Int
f(max, argmax, value, index):
if value >= max:
return (value, index)
else:
return (max, argmax)
Pour les tableaux d'entrée 1D V = Float[N], K = Int[N] et les valeurs d'initialisation I_V = Float, I_K = Int, le résultat f_(N-1) de la réduction sur la seule dimension d'entrée équivaut à l'application récursive suivante :
f_0 = f(I_V, I_K, V_0, K_0)
f_1 = f(f_0.first, f_0.second, V_1, K_1)
...
f_(N-1) = f(f_(N-2).first, f_(N-2).second, V_(N-1), K_(N-1))
L'application de cette réduction à un tableau de valeurs et à un tableau d'indices séquentiels (c'est-à-dire iota) co-itérera sur les tableaux et renverra un tuple contenant la valeur maximale et l'index correspondant.
ReducePrecision
Voir aussi XlaBuilder::ReducePrecision.
Modélise l'effet de la conversion de valeurs à virgule flottante dans un format de précision inférieure (tel que IEEE-FP16) et de leur reconversion dans le format d'origine. Le nombre de bits de l'exposant et de la mantisse dans le format de précision inférieure peut être spécifié de manière arbitraire, bien que toutes les tailles de bits ne soient pas compatibles avec toutes les implémentations matérielles.
ReducePrecision(operand, exponent_bits, mantissa_bits)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau de type à virgule flottante T. |
exponent_bits |
int32 |
nombre de bits d'exposant au format de précision inférieure |
mantissa_bits |
int32 |
Nombre de bits de mantisse au format de précision inférieure |
Le résultat est un tableau de type T. Les valeurs d'entrée sont arrondies à la valeur représentable la plus proche avec le nombre de bits de mantisse donné (en utilisant la sémantique "ties to even"), et toutes les valeurs qui dépassent la plage spécifiée par le nombre de bits d'exposant sont ramenées à l'infini positif ou négatif. Les valeurs NaN sont conservées, mais elles peuvent être converties en valeurs NaN canoniques.
Le format de précision inférieure doit comporter au moins un bit d'exposant (afin de distinguer une valeur nulle d'une valeur infinie, car les deux ont une mantisse nulle) et doit comporter un nombre non négatif de bits de mantisse. Le nombre de bits d'exposant ou de mantisse peut dépasser la valeur correspondante pour le type T. La partie correspondante de la conversion est alors simplement une opération nulle.
Pour en savoir plus sur StableHLO, consultez StableHLO – reduce_precision.
ReduceScatter
Voir aussi XlaBuilder::ReduceScatter.
ReduceScatter est une opération collective qui effectue efficacement un AllReduce, puis répartit le résultat en le divisant en blocs shard_count le long de scatter_dimension. La réplique i du groupe de répliques reçoit le shard ith.
ReduceScatter(operand, computation, scatter_dimension, shard_count,
replica_groups, channel_id, layout, use_global_device_ids)
| Arguments | Type | Sémantique |
|---|---|---|
operand
|
XlaOp
|
Tableau ou tuple non vide de tableaux à réduire dans les répliques. |
computation |
XlaComputation |
Calcul de la réduction |
scatter_dimension |
int64 |
Dimension à disperser. |
shard_count
|
int64
|
Nombre de blocs à fractionner
scatter_dimension |
replica_groups
|
ReplicaGroup vector
|
Groupes entre lesquels les réductions sont effectuées |
channel_id
|
facultatif
ChannelHandle |
ID de canal facultatif pour la communication entre modules |
layout
|
facultatif Layout
|
Disposition de la mémoire spécifiée par l'utilisateur |
use_global_device_ids |
facultatif bool |
indicateur spécifié par l'utilisateur |
- Lorsque
operandest un tuple de tableaux, la réduction et la dispersion sont effectuées sur chaque élément du tuple. replica_groupsest une liste de groupes de répliques entre lesquels la réduction est effectuée (l'ID de réplique de la réplique actuelle peut être récupéré à l'aide deReplicaId). L'ordre des répliques dans chaque groupe détermine l'ordre dans lequel le résultat de l'opération All-Reduce sera dispersé.replica_groupsdoit être vide (dans ce cas, toutes les répliques appartiennent à un seul groupe) ou contenir le même nombre d'éléments que le nombre de répliques. Lorsqu'il existe plusieurs groupes de répliques, ils doivent tous être de la même taille. Par exemple,replica_groups = {0, 2}, {1, 3}effectue une réduction entre les répliques0et2, et1et3, puis disperse le résultat.shard_countcorrespond à la taille de chaque groupe de réplicas. Nous en avons besoin lorsquereplica_groupsest vide. Sireplica_groupsn'est pas vide,shard_countdoit être égal à la taille de chaque groupe de réplicas.channel_idest utilisé pour la communication entre les modules : seules les opérationsreduce-scatteravec le mêmechannel_idpeuvent communiquer entre elles.layoutPour en savoir plus sur les mises en page, consultez xla::shapes.use_global_device_idsest une option spécifiée par l'utilisateur. Lorsquefalse(par défaut), les nombres dansreplica_groupssontReplicaId. Lorsquetrue, lesreplica_groupsreprésentent un ID global de (ReplicaID*partition_count+partition_id). Par exemple :- Avec deux réplicas et quatre partitions,
- replica_groups={ {0,1,4,5},{2,3,6,7} } and use_global_device_ids=true
- group[0] = (0,0), (0,1), (1,0), (1,1)
- group[1] = (0,2), (0,3), (1,2), (1,3)
- où chaque paire est (replica_id, partition_id).
La forme de sortie est la forme d'entrée avec le scatter_dimension rendu shard_count fois plus petit. Par exemple, s'il y a deux répliques et que l'opérande a respectivement la valeur [1.0, 2.25] et [3.0, 5.25] sur les deux répliques, la valeur de sortie de cette opération où scatter_dim est 0 sera [4.0] pour la première réplique et [7.5] pour la seconde.
Pour en savoir plus sur StableHLO, consultez StableHLO : reduce_scatter.
ReduceScatter - Exemple 1 - StableHLO

Dans l'exemple ci-dessus, deux répliques participent à ReduceScatter. Sur chaque réplique, l'opérande a la forme f32[2,4]. Une opération all-reduce (somme) est effectuée sur les répliques, ce qui produit une valeur réduite de forme f32[2,4] sur chaque réplique. Cette valeur réduite est ensuite divisée en deux parties le long de la dimension 1, de sorte que chaque partie a une forme f32[2,2]. Chaque réplica du groupe de processus reçoit la partie correspondant à sa position dans le groupe. Par conséquent, la sortie de chaque réplique a la forme f32[2,2].
ReduceWindow
Voir aussi XlaBuilder::ReduceWindow.
Applique une fonction de réduction à tous les éléments de chaque fenêtre d'une séquence de N tableaux multidimensionnels, produisant un ou un tuple de N tableaux multidimensionnels en sortie. Chaque tableau de sortie comporte le même nombre d'éléments que le nombre de positions valides de la fenêtre. Une couche de pooling peut être exprimée sous la forme d'un ReduceWindow. Comme pour Reduce, le computation appliqué est toujours transmis au init_values sur le côté gauche.
ReduceWindow(operands..., init_values..., computation, window_dimensions,
window_strides, padding)
| Arguments | Type | Sémantique |
|---|---|---|
operands
|
N XlaOps
|
Séquence de N tableaux multidimensionnels de types T_0,..., T_{N-1}, chacun représentant la zone de base sur laquelle la fenêtre est placée. |
init_values
|
N XlaOps
|
Les valeurs de départ N pour la réduction, une pour chacun des opérandes N. Pour en savoir plus, consultez Réduire. |
computation
|
XlaComputation
|
Fonction de réduction de type T_0,
..., T_{N-1}, T_0, ..., T_{N-1}
-> Collate(T_0, ..., T_{N-1}) à appliquer aux éléments de chaque fenêtre de tous les opérandes d'entrée. |
window_dimensions
|
ArraySlice<int64>
|
Tableau d'entiers pour les valeurs de dimension de la fenêtre |
window_strides
|
ArraySlice<int64>
|
Tableau d'entiers pour les valeurs de pas de fenêtre |
base_dilations
|
ArraySlice<int64>
|
Tableau d'entiers pour les valeurs de dilatation de base |
window_dilations
|
ArraySlice<int64>
|
Tableau d'entiers pour les valeurs de dilatation de la fenêtre |
padding
|
Padding
|
Type de marge intérieure pour la fenêtre (Padding::kSame, qui ajoute une marge intérieure de manière à ce que la forme de sortie soit la même que celle de l'entrée si le pas est de 1, ou Padding::kValid, qui n'utilise aucune marge intérieure et "arrête" la fenêtre une fois qu'elle ne tient plus) |
Où :
- N doit être supérieur ou égal à 1.
- Toutes les matrices d'entrée doivent avoir les mêmes dimensions.
- Si
N = 1,Collate(T)estT. - Si
N > 1,Collate(T_0, ..., T_{N-1})est un tuple d'élémentsNde type(T0,...T{N-1}).
Pour en savoir plus sur StableHLO, consultez StableHLO – reduce_window.
ReduceWindow - Exemple 1
L'entrée est une matrice de taille [4x6], et window_dimensions et window_stride_dimensions sont tous deux [2x3].
// Create a computation for the reduction (maximum).
XlaComputation max;
{
XlaBuilder builder(client_, "max");
auto y = builder.Parameter(0, ShapeUtil::MakeShape(F32, {}), "y");
auto x = builder.Parameter(1, ShapeUtil::MakeShape(F32, {}), "x");
builder.Max(y, x);
max = builder.Build().value();
}
// Create a ReduceWindow computation with the max reduction computation.
XlaBuilder builder(client_, "reduce_window_2x3");
auto shape = ShapeUtil::MakeShape(F32, {4, 6});
auto input = builder.Parameter(0, shape, "input");
builder.ReduceWindow(
input,
/*init_val=*/builder.ConstantLiteral(LiteralUtil::MinValue(F32)),
*max,
/*window_dimensions=*/{2, 3},
/*window_stride_dimensions=*/{2, 3},
Padding::kValid);
Un pas de 1 dans une dimension indique que la position d'une fenêtre dans la dimension est à un élément de sa fenêtre adjacente. Pour spécifier qu'aucune fenêtre ne se chevauche, window_stride_dimensions doit être égal à window_dimensions. La figure ci-dessous illustre l'utilisation de deux valeurs de foulée différentes. La marge intérieure est appliquée à chaque dimension de l'entrée, et les calculs sont les mêmes que si l'entrée était arrivée avec les dimensions qu'elle a après la marge intérieure.
Pour un exemple de remplissage non trivial, considérons le calcul du minimum de la fenêtre de réduction (valeur initiale MAX_FLOAT) avec la dimension 3 et le pas 2 sur le tableau d'entrée [10000, 1000, 100, 10, 1]. Le remplissage kValid calcule les minimums sur deux fenêtres valides : [10000, 1000, 100] et [100, 10, 1], ce qui donne la sortie [100, 1]. Le remplissage kSame remplit d'abord le tableau de sorte que la forme après la fenêtre de réduction soit la même que l'entrée pour un pas de 1 en ajoutant des éléments initiaux des deux côtés, ce qui donne [MAX_VALUE, 10000, 1000, 100, 10, 1,
MAX_VALUE]. L'exécution de reduce-window sur le tableau avec marge intérieure fonctionne sur trois fenêtres [MAX_VALUE, 10000, 1000], [1000, 100, 10], [10, 1, MAX_VALUE] et génère [1000, 10, 1].
L'ordre d'évaluation de la fonction de réduction est arbitraire et peut être non déterministe. Par conséquent, la fonction de réduction ne doit pas être trop sensible à la réassociation. Pour en savoir plus, consultez la discussion sur l'associativité dans le contexte de Reduce.
ReduceWindow – Exemple 2 – StableHLO

Dans l'exemple ci-dessus :
Entrée) L'opérande a une forme d'entrée S32[3,2]. Avec une valeur de
[[1,2],[3,4],[5,6]]
Étape 1) La dilatation de base avec un facteur 2 le long de la dimension des lignes insère des trous entre chaque ligne de l'opérande. Un remplissage de deux lignes en haut et d'une ligne en bas est appliqué après la dilatation. Le Tensor devient donc plus haut.
Étape 2) Une fenêtre de forme [2,1] est définie, avec une dilatation de fenêtre [3,1]. Cela signifie que chaque fenêtre sélectionne deux éléments de la même colonne, mais que le deuxième élément est extrait trois lignes en dessous du premier, et non directement en dessous.
Étape 3) Les fenêtres sont ensuite déplacées sur l'opérande avec un pas de [4,1]. La fenêtre se déplace ainsi de quatre lignes à la fois, tout en se décalant d'une colonne à la fois horizontalement. Les cellules de marge intérieure sont remplies avec init_value (dans ce cas, init_value = 0). Les valeurs "entrant" dans les cellules de dilatation sont ignorées. En raison du pas et de la marge intérieure, certaines fenêtres ne chevauchent que des zéros et des trous, tandis que d'autres chevauchent des valeurs d'entrée réelles.
Étape 4) Dans chaque fenêtre, les éléments sont combinés à l'aide de la fonction de réduction (a, b) → a + b, en commençant par une valeur initiale de 0. Les deux fenêtres du haut ne voient que des marges intérieures et des trous, donc leurs résultats sont de 0. Les fenêtres du bas capturent les valeurs 3 et 4 de l'entrée et les renvoient en tant que résultats.
Résultats) La sortie finale a la forme S32[2,2], avec les valeurs suivantes : [[0,0],[3,4]]
Rem
Voir aussi XlaBuilder::Rem.
Effectue le reste élément par élément du dividende lhs et du diviseur rhs.
Le signe du résultat est celui du dividende, et la valeur absolue du résultat est toujours inférieure à la valeur absolue du diviseur.
Rem(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Une variante alternative avec une prise en charge de la diffusion multidimensionnelle existe pour Rem :
Rem(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – reste.
ReplicaId
Voir aussi XlaBuilder::ReplicaId.
Renvoie l'ID unique (scalaire U32) de la réplique.
ReplicaId()
L'ID unique de chaque réplica est un entier non signé dans l'intervalle [0, N), où N est le nombre de réplicas. Étant donné que tous les réplicas exécutent le même programme, un appel ReplicaId() dans le programme renverra une valeur différente sur chaque réplica.
Pour en savoir plus sur StableHLO, consultez StableHLO – replica_id.
Remodeler
Voir aussi XlaBuilder::Reshape.
et l'opération Collapse.
Remanie les dimensions d'un tableau dans une nouvelle configuration.
Reshape(operand, dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
tableau de type T |
dimensions |
Vecteur int64 |
Vecteur des tailles des nouvelles dimensions |
Conceptuellement, la fonction reshape aplatit d'abord un tableau en un vecteur unidimensionnel de valeurs de données, puis affine ce vecteur en une nouvelle forme. Les arguments d'entrée sont un tableau arbitraire de type T, un vecteur de constantes de compilation d'indices de dimension et un vecteur de constantes de compilation de tailles de dimension pour le résultat.
Le vecteur dimensions détermine la taille du tableau de sortie. La valeur à l'index 0 de dimensions correspond à la taille de la dimension 0, la valeur à l'index 1 correspond à la taille de la dimension 1, et ainsi de suite. Le produit des dimensions dimensions doit être égal au produit des tailles de dimension de l'opérande. Lorsque vous affinez le tableau réduit en tableau multidimensionnel défini par dimensions, les dimensions de dimensions sont classées de la variation la plus lente (la plus importante) à la variation la plus rapide (la moins importante).
Par exemple, supposons que v soit un tableau de 24 éléments :
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
let v012_24 = Reshape(v, {24});
then v012_24 == f32[24] {10, 11, 12, 15, 16, 17, 20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37, 40, 41, 42, 45, 46, 47};
let v012_83 = Reshape(v, {8,3});
then v012_83 == f32[8x3] { {10, 11, 12}, {15, 16, 17},
{20, 21, 22}, {25, 26, 27},
{30, 31, 32}, {35, 36, 37},
{40, 41, 42}, {45, 46, 47} };
Dans un cas particulier, reshape peut transformer un tableau à un seul élément en scalaire et inversement. Par exemple,
Reshape(f32[1x1] { {5} }, {}) == 5;
Reshape(5, {1,1}) == f32[1x1] { {5} };
Pour en savoir plus sur StableHLO, consultez StableHLO – reshape.
Reshape (explicite)
Voir aussi XlaBuilder::Reshape.
Reshape(shape, operand)
Opération Reshape qui utilise une forme cible explicite.
| Arguments | Type | Sémantique |
|---|---|---|
shape |
Shape |
Forme de sortie de type T |
operand |
XlaOp |
tableau de type T |
Rev (inversé)
Voir aussi XlaBuilder::Rev.
Rev(operand, dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
tableau de type T |
dimensions |
ArraySlice<int64> |
dimensions à inverser |
Inverse l'ordre des éléments du tableau operand le long de l'dimensions spécifié, générant un tableau de sortie de même forme. Chaque élément du tableau d'opérandes à un index multidimensionnel est stocké dans le tableau de sortie à un index transformé. L'index multidimensionnel est transformé en inversant l'index dans chaque dimension à inverser (c'est-à-dire que si une dimension de taille N est l'une des dimensions d'inversion, son index i est transformé en N - 1 - i).
L'opération Rev peut être utilisée pour inverser le tableau de pondération de convolution le long des deux dimensions de la fenêtre lors du calcul du gradient dans les réseaux de neurones.
Pour en savoir plus sur StableHLO, consultez StableHLO – Reverse.
RngNormal
Voir aussi XlaBuilder::RngNormal.
Construit une sortie d'une forme donnée avec des nombres aléatoires générés selon la distribution normale \(N(\mu, \sigma)\) . Les paramètres \(\mu\) et \(\sigma\), ainsi que la forme de sortie, doivent avoir un type élémentaire à virgule flottante. De plus, les paramètres doivent être des valeurs scalaires.
RngNormal(mu, sigma, shape)
| Arguments | Type | Sémantique |
|---|---|---|
mu |
XlaOp |
Scalaire de type T spécifiant la moyenne des nombres générés |
sigma
|
XlaOp
|
Scalaire de type T spécifiant l'écart-type de la valeur générée. |
shape |
Shape |
Forme de sortie de type T |
Pour en savoir plus sur StableHLO, consultez StableHLO – rng.
RngUniform
Voir aussi XlaBuilder::RngUniform.
Construit une sortie d'une forme donnée avec des nombres aléatoires générés suivant la distribution uniforme sur l'intervalle \([a,b)\). Les paramètres et le type d'élément de sortie doivent être de type booléen, entier ou à virgule flottante, et les types doivent être cohérents. Les backends CPU et GPU ne prennent actuellement en charge que F64, F32, F16, BF16, S64, U64, S32 et U32. De plus, les paramètres doivent être des valeurs scalaires. Si \(b <= a\) , le résultat est défini par l'implémentation.
RngUniform(a, b, shape)
| Arguments | Type | Sémantique |
|---|---|---|
a |
XlaOp |
Scalaire de type T spécifiant la limite inférieure de l'intervalle |
b |
XlaOp |
Scalaire de type T spécifiant la limite supérieure de l'intervalle |
shape |
Shape |
Forme de sortie de type T |
Pour en savoir plus sur StableHLO, consultez StableHLO – rng.
RngBitGenerator
Voir aussi XlaBuilder::RngBitGenerator.
Génère une sortie avec une forme donnée remplie de bits aléatoires uniformes à l'aide de l'algorithme spécifié (ou de la valeur par défaut du backend), puis renvoie un état mis à jour (avec la même forme que l'état initial) et les données aléatoires générées.
L'état initial est l'état initial de la génération actuelle de nombres aléatoires. Il dépend de l'algorithme utilisé, tout comme la forme requise et les valeurs valides.
La sortie est garantie d'être une fonction déterministe de l'état initial, mais elle n'est pas garantie d'être déterministe entre les backends et les différentes versions du compilateur.
RngBitGenerator(algorithm, initial_state, shape)
| Arguments | Type | Sémantique |
|---|---|---|
algorithm |
RandomAlgorithm |
Algorithme PRNG à utiliser. |
initial_state |
XlaOp |
État initial de l'algorithme PRNG. |
shape |
Shape |
Forme de sortie pour les données générées. |
Valeurs disponibles pour algorithm :
rng_default: algorithme spécifique au backend avec des exigences de forme spécifiques au backend.rng_three_fry: algorithme PRNG basé sur le compteur ThreeFry. La formeinitial_stateestu64[2]avec des valeurs arbitraires. Salmon et al. SC 2011. Nombres aléatoires parallèles : un jeu d'enfant.rng_philox: algorithme Philox permettant de générer des nombres aléatoires en parallèle. La formeinitial_stateestu64[3]avec des valeurs arbitraires. Salmon et al. SC 2011. Nombres aléatoires parallèles : un jeu d'enfant.
Pour en savoir plus sur StableHLO, consultez StableHLO – rng_bit_generator.
RngGetAndUpdateState
Voir aussi HloInstruction::CreateRngGetAndUpdateState.
L'API des différentes opérations Rng est décomposée en interne en instructions HLO, y compris RngGetAndUpdateState.
RngGetAndUpdateState sert de primitive dans HLO. Cette opération peut apparaître dans les dumps HLO, mais elle n'est pas destinée à être construite manuellement par les utilisateurs finaux.
Manche
Voir aussi XlaBuilder::Round.
Arrondi élément par élément, les valeurs à mi-chemin sont arrondies à la valeur la plus éloignée de zéro.
Round(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
RoundNearestAfz
Voir aussi XlaBuilder::RoundNearestAfz.
Effectue un arrondi élément par élément à l'entier le plus proche, en cassant les liens loin de zéro.
RoundNearestAfz(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Pour en savoir plus sur StableHLO, consultez StableHLO – round_nearest_afz.
RoundNearestEven
Voir aussi XlaBuilder::RoundNearestEven.
Arrondi élément par élément, avec égalité au pair le plus proche.
RoundNearestEven(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Pour en savoir plus sur StableHLO, consultez StableHLO – round_nearest_even.
Rsqrt
Voir aussi XlaBuilder::Rsqrt.
Opération de racine carrée réciproque au niveau des éléments x -> 1.0 / sqrt(x).
Rsqrt(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Rsqrt accepte également l'argument facultatif result_accuracy :
Rsqrt(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Pour en savoir plus sur StableHLO, consultez StableHLO – rsqrt.
Rechercher
Voir aussi XlaBuilder::Scan.
Applique une fonction de réduction à un tableau selon une dimension donnée, ce qui génère un état final et un tableau de valeurs intermédiaires.
Scan(inputs..., inits..., to_apply, scan_dimension,
is_reverse, is_associative)
| Arguments | Type | Sémantique |
|---|---|---|
inputs |
Séquence de m XlaOp |
Tableaux à analyser. |
inits |
Séquence de k XlaOp |
Les premières contributions |
to_apply |
XlaComputation |
Calcul de type i_0, ..., i_{m-1}, c_0, ..., c_{k-1} -> (o_0, ..., o_{n-1}, c'_0, ..., c'_{k-1}). |
scan_dimension |
int64 |
Dimension à analyser. |
is_reverse |
bool |
Si la valeur est "true", la recherche s'effectue dans l'ordre inverse. |
is_associative |
bool (trois États) |
Si la valeur est "true", l'opération est associative. |
La fonction to_apply est appliquée séquentiellement aux éléments de inputs le long de scan_dimension. Si is_reverse est défini sur "false", les éléments sont traités dans l'ordre 0 à N-1, où N correspond à la taille de scan_dimension. Si is_reverse est défini sur "true", les éléments sont traités de N-1 à 0.
La fonction to_apply prend m + k opérandes :
méléments actuels deinputs.kcontient les valeurs de l'étape précédente (ouinitspour le premier élément).
La fonction to_apply renvoie un tuple de valeurs n + k :
- Éléments
ndeoutputs. knouvelles valeurs de report.
L'opération Scan génère un tuple de valeurs n + k :
- Tableaux de sortie
n, contenant les valeurs de sortie pour chaque étape. - Les valeurs de report
kfinales après le traitement de tous les éléments.
Les types des entrées m doivent correspondre aux types des premiers paramètres m de to_apply avec une dimension de balayage supplémentaire. Les types des sorties n doivent correspondre aux types des premières valeurs de retour n de to_apply avec une dimension de balayage supplémentaire. La dimension de balayage supplémentaire parmi toutes les entrées et sorties doit avoir la même taille N. Les types des derniers paramètres k et des valeurs de retour de to_apply, ainsi que les inits k, doivent correspondre.
Par exemple (m, n, k == 1, N == 3), pour le report initial i, saisissez [a, b, c], la fonction f(x, c) -> (y, c') et scan_dimension=0, is_reverse=false :
- Étape 0 :
f(a, i) -> (y0, c0) - Étape 1 :
f(b, c0) -> (y1, c1) - Étape 2 :
f(c, c1) -> (y2, c2)
La sortie de Scan est ([y0, y1, y2], c2).
Nuage de points
Voir aussi XlaBuilder::Scatter.
L'opération de dispersion XLA génère une séquence de résultats qui sont les valeurs du tableau d'entrée operands, avec plusieurs tranches (aux index spécifiés par scatter_indices) mises à jour avec la séquence de valeurs dans updates à l'aide de update_computation.
Scatter(operands..., scatter_indices, updates..., update_computation,
dimension_numbers, indices_are_sorted, unique_indices)
| Arguments | Type | Sémantique |
|---|---|---|
operands |
Séquence de N XlaOp |
N tableaux de types T_0, ..., T_N à disperser. |
scatter_indices |
XlaOp |
Tableau contenant les index de début des tranches à disperser. |
updates |
Séquence de N XlaOp |
N tableaux de types T_0, ..., T_N. updates[i] contient les valeurs à utiliser pour la diffusion operands[i]. |
update_computation |
XlaComputation |
Calcul à utiliser pour combiner les valeurs existantes dans le tableau d'entrée et les mises à jour lors de la dispersion. Ce calcul doit être de type T_0, ..., T_N, T_0, ..., T_N -> Collate(T_0, ..., T_N). |
index_vector_dim |
int64 |
Dimension dans scatter_indices qui contient les index de début. |
update_window_dims |
ArraySlice<int64> |
Ensemble de dimensions de forme updates qui sont des dimensions de fenêtre. |
inserted_window_dims |
ArraySlice<int64> |
Ensemble de dimensions de fenêtre à insérer dans la forme updates. |
scatter_dims_to_operand_dims |
ArraySlice<int64> |
Mappage des dimensions des indices de dispersion à l'espace d'index des opérandes. Ce tableau est interprété comme un mappage de i à scatter_dims_to_operand_dims[i] . Elle doit être totale et bijective. |
dimension_number |
ScatterDimensionNumbers |
Numéros de dimension pour l'opération de dispersion |
indices_are_sorted |
bool |
Indique si l'appelant garantit que les index sont triés. |
unique_indices |
bool |
Indique si l'unicité des index est garantie par l'appelant. |
Où :
- N doit être supérieur ou égal à 1.
operands[0], ...,operands[N-1] doivent tous avoir les mêmes dimensions.updates[0], ...,updates[N-1] doivent tous avoir les mêmes dimensions.- Si
N = 1,Collate(T)estT. - Si
N > 1,Collate(T_0, ..., T_N)est un tuple deNéléments de typeT.
Si index_vector_dim est égal à scatter_indices.rank, nous considérons implicitement que scatter_indices comporte une dimension 1 de fin.
Nous définissons update_scatter_dims de type ArraySlice<int64> comme l'ensemble des dimensions de la forme updates qui ne sont pas dans update_window_dims, par ordre croissant.
Les arguments de la dispersion doivent respecter les contraintes suivantes :
Chaque tableau
updatesdoit comporterupdate_window_dims.size + scatter_indices.rank - 1dimensions.Les limites de la dimension
idans chaque tableauupdatesdoivent respecter les règles suivantes :- Si
iest présent dansupdate_window_dims(c'est-à-dire égal àupdate_window_dims[k] pour un certaink), la limite de la dimensionidansupdatesne doit pas dépasser la limite correspondante deoperandaprès prise en compte deinserted_window_dims(c'est-à-direadjusted_window_bounds[k], oùadjusted_window_boundscontient les limites deoperandavec les limites aux indexinserted_window_dimssupprimées). - Si
iest présent dansupdate_scatter_dims(c'est-à-dire égal àupdate_scatter_dims[k] pour certainsk), la limite de la dimensionidansupdatesdoit être égale à la limite correspondante descatter_indices, en ignorantindex_vector_dim(c'est-à-direscatter_indices.shape.dims[k], sik<index_vector_dimetscatter_indices.shape.dims[k+1] sinon).
- Si
update_window_dimsdoit être trié par ordre croissant, ne pas comporter de numéros de dimensions en double et être compris dans la plage[0, updates.rank).inserted_window_dimsdoit être trié par ordre croissant, ne pas comporter de numéros de dimensions en double et être compris dans la plage[0, operand.rank).operand.rankdoit être égal à la somme deupdate_window_dims.sizeetinserted_window_dims.size.scatter_dims_to_operand_dims.sizedoit être égal àscatter_indices.shape.dims[index_vector_dim], et ses valeurs doivent être comprises dans la plage[0, operand.rank).
Pour un index U donné dans chaque tableau updates, l'index I correspondant dans le tableau operands correspondant auquel cette mise à jour doit être appliquée est calculé comme suit :
- Soit
G= {U[k] pourkdansupdate_scatter_dims}. UtilisezGpour rechercher un vecteur d'indexSdans le tableauscatter_indicestel queS[i] =scatter_indices[Combine(G,i)] où Combine(A, b) insère b aux positionsindex_vector_dimdans A. - Créez un index
Sindansoperandà l'aide deSen dispersantSà l'aide de la cartescatter_dims_to_operand_dims. Plus formellement :Sin[scatter_dims_to_operand_dims[k]] =S[k] sik<scatter_dims_to_operand_dims.size.Sin[_] =0sinon.
- Créez un index
Windans chaque tableauoperandsen dispersant les index àupdate_window_dimsdansUseloninserted_window_dims. Plus formellement :Win[window_dims_to_operand_dims(k)] =U[k] sikest dansupdate_window_dims, oùwindow_dims_to_operand_dimsest la fonction monotone avec le domaine [0,update_window_dims.size) et la plage [0,operand.rank) \inserted_window_dims. (Par exemple, siupdate_window_dims.sizeest4,operand.rankest6etinserted_window_dimsest {0,2}, alorswindow_dims_to_operand_dimsest {0→1,1→3,2→4,3→5}).Win[_] =0sinon.
IestWin+Sin, où + correspond à l'addition élément par élément.
En résumé, l'opération de dispersion peut être définie comme suit.
- Initialisez
outputavecoperands, c'est-à-dire pour tous les indicesJ, pour tous les indicesOdans le tableauoperands[J] :
output[J][O] =operands[J][O] - Pour chaque index
Udu tableauupdates[J] et l'indexOcorrespondant du tableauoperand[J], siOest un index valide pouroutput:
(output[0][O], ...,output[N-1][O]) =update_computation(output[0][O], ..., ,output[N-1][O],updates[0][U], ...,updates[N-1][U])
L'ordre dans lequel les mises à jour sont appliquées n'est pas déterministe. Ainsi, lorsque plusieurs index dans updates font référence au même index dans operands, la valeur correspondante dans output sera non déterministe.
Notez que le premier paramètre transmis à update_computation sera toujours la valeur actuelle du tableau output et que le deuxième paramètre sera toujours la valeur du tableau updates. Cela est particulièrement important lorsque update_computation n'est pas commutatif.
Si indices_are_sorted est défini sur "true", XLA peut supposer que scatter_indices est trié (par ordre croissant, après la dispersion de ses valeurs selon scatter_dims_to_operand_dims) par l'utilisateur. Si ce n'est pas le cas, la sémantique est définie par l'implémentation.
Si unique_indices est défini sur "true", XLA peut supposer que tous les éléments dispersés sont uniques. XLA peut donc utiliser des opérations non atomiques. Si unique_indices est défini sur "true" et que les indices vers lesquels les valeurs sont dispersées ne sont pas uniques, la sémantique est définie par l'implémentation.
De manière informelle, l'opération scatter peut être considérée comme l'inverse de l'opération gather, c'est-à-dire que l'opération scatter met à jour les éléments de l'entrée qui sont extraits par l'opération gather correspondante.
Pour obtenir une description informelle détaillée et des exemples, consultez la section "Description informelle" sous Gather.
Pour en savoir plus sur StableHLO, consultez StableHLO – scatter.
Scatter – Exemple 1 – StableHLO

Dans l'image ci-dessus, chaque ligne du tableau est un exemple de mise à jour d'index. Examinons-les étape par étape, de gauche(mise à jour de l'index) à droite(index de résultat) :
L'entrée input a la forme S32[2,3,4,2]. scatter_indices a la forme S64[2,2,3,2]. updates a la forme S32[2,2,3,1,2].
Mettre à jour l'index) : update_window_dims:[3,4] fait partie de l'entrée. Cela nous indique que les dimensions 3 et 4 de updates sont des dimensions de fenêtre, mises en évidence en jaune. Cela nous permet de déduire que update_scatter_dims = [0,1,2].
Mettre à jour l'index de dispersion) nous montre le updated_scatter_dims extrait pour chacun.
(La partie non jaune de la colonne "Mettre à jour l'index")
Index de départ) En examinant l'image du Tensor scatter_indices, nous pouvons voir que nos valeurs de l'étape précédente (index de dispersion de la mise à jour) nous donnent l'emplacement de l'index de départ. À partir de index_vector_dim, nous obtenons également la dimension de starting_indices qui contient les indices de départ, qui pour scatter_indices est la dimension 3 avec une taille de 2.
L'index de début complet scatter_dims_to_operand_dims = [2,1] nous indique que le premier élément du vecteur d'index va à la dimension de l'opérande 2. Le deuxième élément du vecteur d'index est associé à la dimension 1 de l'opérande. Les dimensions d'opérande restantes sont remplies avec la valeur 0.
Index de regroupement complet) La zone violette en surbrillance est affichée dans cette colonne(index de regroupement complet), la colonne "Mettre à jour l'index de dispersion" et la colonne "Mettre à jour l'index".
(Full Window Index) Calculé à partir de update_window_dimensions [3,4].
Index des résultats) : addition de l'index de début complet, de l'index de batch complet et de l'index de fenêtre complet dans le Tensor operand. Notez que les régions vertes mises en évidence correspondent également à la figure operand. La dernière ligne est ignorée, car elle se trouve en dehors du Tensor operand.
Sélectionner
Voir aussi XlaBuilder::Select.
Construit un tableau de sortie à partir des éléments de deux tableaux d'entrée, en fonction des valeurs d'un tableau de prédicats.
Select(pred, on_true, on_false)
| Arguments | Type | Sémantique |
|---|---|---|
pred |
XlaOp |
Tableau de type PRED |
on_true |
XlaOp |
tableau de type T |
on_false |
XlaOp |
tableau de type T |
Les tableaux on_true et on_false doivent avoir la même forme. Il s'agit également de la forme du tableau de sortie. Le tableau pred doit avoir la même dimensionnalité que on_true et on_false, avec le type d'élément PRED.
Pour chaque élément P de pred, l'élément correspondant du tableau de sortie est extrait de on_true si la valeur de P est true, et de on_false si la valeur de P est false. En tant que forme restreinte de diffusion, pred peut être un scalaire de type PRED. Dans ce cas, le tableau de sortie est entièrement extrait de on_true si pred est défini sur true, et de on_false si pred est défini sur false.
Exemple avec pred non scalaire :
let pred: PRED[4] = {true, false, false, true};
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 200, 300, 4};
Exemple avec pred scalaire :
let pred: PRED = true;
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 2, 3, 4};
Les sélections entre les tuples sont acceptées. Les tuples sont considérés comme des types scalaires à cet effet. Si on_true et on_false sont des tuples (qui doivent avoir la même forme), pred doit être un scalaire de type PRED.
Pour en savoir plus sur StableHLO, consultez StableHLO – select.
SelectAndScatter
Voir aussi XlaBuilder::SelectAndScatter.
Cette opération peut être considérée comme une opération composite qui calcule d'abord ReduceWindow sur le tableau operand pour sélectionner un élément de chaque fenêtre, puis disperse le tableau source aux index des éléments sélectionnés pour construire un tableau de sortie ayant la même forme que le tableau d'opérandes. La fonction binaire select est utilisée pour sélectionner un élément de chaque fenêtre en l'appliquant à chaque fenêtre. Elle est appelée avec la propriété selon laquelle le vecteur d'index du premier paramètre est lexicographiquement inférieur à celui du deuxième paramètre.La fonction select renvoie true si le premier paramètre est sélectionné et false si le deuxième paramètre est sélectionné. La fonction doit respecter la transitivité (c'est-à-dire que si select(a, b) et select(b, c) sont true, alors select(a, c) est également true) afin que l'élément sélectionné ne dépende pas de l'ordre des éléments parcourus pour une fenêtre donnée.
La fonction scatter est appliquée à chaque index sélectionné dans le tableau de sortie. Il accepte deux paramètres scalaires :
- Valeur actuelle à l'index sélectionné dans le tableau de sortie
- Valeur de dispersion de
sourcequi s'applique à l'index sélectionné
Il combine les deux paramètres et renvoie une valeur scalaire utilisée pour mettre à jour la valeur à l'index sélectionné dans le tableau de sortie. Initialement, tous les indices du tableau de sortie sont définis sur init_value.
Le tableau de sortie a la même forme que le tableau operand, et le tableau source doit avoir la même forme que le résultat de l'application d'une opération ReduceWindow sur le tableau operand. SelectAndScatter peut être utilisé pour rétropropager les valeurs de gradient d'un calque de pooling dans un réseau de neurones.
SelectAndScatter(operand, select, window_dimensions, window_strides, padding,
source, init_value, scatter)
| Arguments | Type | Sémantique |
|---|---|---|
operand
|
XlaOp
|
Tableau de type T sur lequel les fenêtres glissent |
select
|
XlaComputation
|
Calcul binaire de type T, T
-> PRED à appliquer à tous les éléments de chaque fenêtre. Renvoie true si le premier paramètre est sélectionné et false si le deuxième paramètre est sélectionné. |
window_dimensions
|
ArraySlice<int64>
|
Tableau d'entiers pour les valeurs de dimension de la fenêtre |
window_strides
|
ArraySlice<int64>
|
Tableau d'entiers pour les valeurs de pas de fenêtre |
padding
|
Padding
|
Type de marge intérieure pour la fenêtre (Padding::kSame ou Padding::kValid) |
source
|
XlaOp
|
Tableau de type T avec les valeurs à disperser |
init_value
|
XlaOp
|
Valeur scalaire de type T pour la valeur initiale du tableau de résultat |
scatter
|
XlaComputation
|
Calcul binaire de type T, T
-> T, pour appliquer chaque élément source de dispersion avec son élément de destination |
La figure ci-dessous montre des exemples d'utilisation de SelectAndScatter, avec la fonction select qui calcule la valeur maximale parmi ses paramètres. Notez que lorsque les fenêtres se chevauchent, comme dans la figure (2) ci-dessous, un index du tableau operand peut être sélectionné plusieurs fois par différentes fenêtres. Dans la figure, l'élément de valeur 9 est sélectionné par les deux fenêtres supérieures (bleue et rouge), et la fonction d'addition binaire scatter produit l'élément de sortie de valeur 8 (2 + 6).
L'ordre d'évaluation de la fonction scatter est arbitraire et peut être non déterministe. Par conséquent, la fonction scatter ne doit pas être trop sensible à la réassociation. Pour en savoir plus, consultez la discussion sur l'associativité dans le contexte de Reduce.
Pour en savoir plus sur StableHLO, consultez StableHLO – select_and_scatter.
Envoyer
Voir aussi XlaBuilder::Send.
Send, SendWithTokens et SendToHost sont des opérations qui servent de primitives de communication dans HLO. Ces opérations apparaissent généralement dans les dumps HLO en tant que partie des transferts d'entrée/sortie de bas niveau ou inter-appareils, mais elles ne sont pas destinées à être construites manuellement par les utilisateurs finaux.
Send(operand, handle)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Données à envoyer (tableau de type T) |
handle |
ChannelHandle |
Identifiant unique pour chaque paire d'envoi/réception |
Envoie les données de l'opérande donné à une instruction Recv dans un autre calcul qui partage le même handle de canal. Ne renvoie aucune donnée.
À l'instar de l'opération Recv, l'API cliente de l'opération Send représente une communication synchrone et est décomposée en interne en deux instructions HLO (Send et SendDone) pour permettre les transferts de données asynchrones. Voir aussi HloInstruction::CreateSend et HloInstruction::CreateSendDone.
Send(HloInstruction operand, int64 channel_id)
Lance un transfert asynchrone de l'opérande vers les ressources allouées par l'instruction Recv avec le même ID de canal. Renvoie un contexte, qui est utilisé par une instruction SendDone suivante pour attendre la fin du transfert de données. Le contexte est un tuple {opérande (forme), identifiant de la requête (U32)} et ne peut être utilisé que par une instruction SendDone.
Pour en savoir plus sur StableHLO, consultez StableHLO – Envoyer.
SendDone
Voir aussi HloInstruction::CreateSendDone.
SendDone(HloInstruction context)
Étant donné un contexte créé par une instruction Send, attend la fin du transfert de données. L'instruction ne renvoie aucune donnée.
Programmer les instructions de la chaîne
L'ordre d'exécution des quatre instructions pour chaque canal (Recv, RecvDone, Send, SendDone) est le suivant.
Recvest antérieur àSendSendest antérieur àRecvDoneRecvest antérieur àRecvDoneSendest antérieur àSendDone
Lorsque les compilateurs de backend génèrent un calendrier linéaire pour chaque calcul qui communique via des instructions de canal, il ne doit pas y avoir de cycles entre les calculs. Par exemple, les planifications ci-dessous entraînent des blocages.
SetDimensionSize
Voir aussi XlaBuilder::SetDimensionSize.
Définit la taille dynamique de la dimension donnée de XlaOp. L'opérande doit être de forme matricielle.
SetDimensionSize(operand, val, dimension)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau d'entrée à n dimensions. |
val |
XlaOp |
int32 représentant la taille dynamique du runtime. |
dimension
|
int64
|
Valeur dans l'intervalle [0, n) qui spécifie la dimension. |
Transmettez l'opérande en tant que résultat, avec la dimension dynamique suivie par le compilateur.
Les valeurs de remplissage seront ignorées par les opérations de réduction en aval.
let v: f32[10] = f32[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
let five: s32 = 5;
let six: s32 = 6;
// Setting dynamic dimension size doesn't change the upper bound of the static
// shape.
let padded_v_five: f32[10] = set_dimension_size(v, five, /*dimension=*/0);
let padded_v_six: f32[10] = set_dimension_size(v, six, /*dimension=*/0);
// sum == 1 + 2 + 3 + 4 + 5
let sum:f32[] = reduce_sum(padded_v_five);
// product == 1 * 2 * 3 * 4 * 5
let product:f32[] = reduce_product(padded_v_five);
// Changing padding size will yield different result.
// sum == 1 + 2 + 3 + 4 + 5 + 6
let sum:f32[] = reduce_sum(padded_v_six);
ShiftLeft
Voir aussi XlaBuilder::ShiftLeft.
Effectue une opération de décalage à gauche au niveau des éléments sur lhs du nombre de bits rhs.
ShiftLeft(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour ShiftLeft :
ShiftLeft(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – shift_left.
ShiftRightArithmetic
Voir aussi XlaBuilder::ShiftRightArithmetic.
Effectue une opération de décalage arithmétique vers la droite au niveau des éléments sur lhs par rhs bits.
ShiftRightArithmetic(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour ShiftRightArithmetic :
ShiftRightArithmetic(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – shift_right_arithmetic.
ShiftRightLogical
Voir aussi XlaBuilder::ShiftRightLogical.
Effectue une opération de décalage logique vers la droite au niveau des éléments sur lhs par rhs bits.
ShiftRightLogical(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour ShiftRightLogical :
ShiftRightLogical(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – shift_right_logical.
Signer
Voir aussi XlaBuilder::Sign.
Sign(operand) Opération de signe au niveau des éléments x -> sgn(x) où
\[\text{sgn}(x) = \begin{cases} -1 & x < 0\\ -0 & x = -0\\ NaN & x = NaN\\ +0 & x = +0\\ 1 & x > 0 \end{cases}\]
en utilisant l'opérateur de comparaison du type d'élément de operand.
Sign(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Pour en savoir plus sur StableHLO, consultez StableHLO – sign.
Sin
Sin(operand) Sinus élément par élément x -> sin(x).
Voir aussi XlaBuilder::Sin.
Sin(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Sin accepte également l'argument facultatif result_accuracy :
Sin(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Pour en savoir plus sur StableHLO, consultez StableHLO – sinus.
Tranche
Voir aussi XlaBuilder::Slice.
Le découpage extrait un sous-tableau du tableau d'entrée. Le sous-tableau comporte le même nombre de dimensions que l'entrée et contient les valeurs à l'intérieur d'un cadre de délimitation dans le tableau d'entrée, où les dimensions et les index du cadre de délimitation sont fournis en tant qu'arguments à l'opération de tranche.
Slice(operand, start_indices, limit_indices, strides)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Tableau à N dimensions de type T |
start_indices
|
ArraySlice<int64>
|
Liste de N entiers contenant les indices de début de la tranche pour chaque dimension. Les valeurs doivent être supérieures ou égales à zéro. |
limit_indices
|
ArraySlice<int64>
|
Liste de N entiers contenant les indices de fin (exclusifs) de la tranche pour chaque dimension. Chaque valeur doit être supérieure ou égale à la valeur start_indices respective pour la dimension et inférieure ou égale à la taille de la dimension. |
strides
|
ArraySlice<int64>
|
Liste de N entiers qui détermine le pas d'entrée de la tranche. Le slice sélectionne chaque élément strides[d] dans la dimension d. |
Exemple unidimensionnel :
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
Slice(a, {2}, {4})
// Result: {2.0, 3.0}
Exemple en deux dimensions :
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
Slice(b, {2, 1}, {4, 3})
// Result:
// { { 7.0, 8.0},
// {10.0, 11.0} }
Pour en savoir plus sur StableHLO, consultez StableHLO – slice.
Trier
Voir aussi XlaBuilder::Sort.
Sort(operands, comparator, dimension, is_stable)
| Arguments | Type | Sémantique |
|---|---|---|
operands |
ArraySlice<XlaOp> |
Opérandes à trier. |
comparator |
XlaComputation |
Calcul du comparateur à utiliser. |
dimension |
int64 |
Dimension selon laquelle trier. |
is_stable |
bool |
Indique si le tri stable doit être utilisé. |
Si un seul opérande est fourni :
Si l'opérande est un tenseur à une dimension (un tableau), le résultat est un tableau trié. Si vous souhaitez trier le tableau par ordre croissant, le comparateur doit effectuer une comparaison "inférieur à". Formellement, une fois le tableau trié, il contient toutes les positions d'index
i, javeci < jqui sont soitcomparator(value[i], value[j]) = comparator(value[j], value[i]) = false, soitcomparator(value[i], value[j]) = true.Si l'opérande comporte un nombre de dimensions plus élevé, il est trié selon la dimension fournie. Par exemple, pour un Tensor à deux dimensions (une matrice), une valeur de dimension de
0triera indépendamment chaque colonne, et une valeur de dimension de1triera indépendamment chaque ligne. Si aucun numéro de dimension n'est fourni, la dernière dimension est choisie par défaut. Pour la dimension triée, le même ordre de tri s'applique que dans le cas unidimensionnel.
Si des opérandes n > 1 sont fournis :
Tous les opérandes
ndoivent être des Tensors de mêmes dimensions. Les types d'éléments des Tensors peuvent être différents.Tous les opérandes sont triés ensemble, et non individuellement. Conceptuellement, les opérandes sont traités comme un tuple. Lorsque vous vérifiez si les éléments de chaque opérande aux positions d'index
ietjdoivent être permutés, le comparateur est appelé avec des paramètres scalaires2 * n, où le paramètre2 * kcorrespond à la valeur à la positionide l'opérandek-th, et le paramètre2 * k + 1correspond à la valeur à la positionjde l'opérandek-th. En général, le comparateur compare les paramètres2 * ket2 * k + 1entre eux, et peut utiliser d'autres paires de paramètres comme départage.Le résultat est un tuple composé des opérandes triés (selon la dimension fournie, comme ci-dessus). L'opérande
i-thdu tuple correspond à l'opérandei-thde Sort.
Par exemple, s'il existe trois opérandes operand0 = [3, 1], operand1 = [42, 50] et operand2 = [-3.0, 1.1], et que le comparateur compare uniquement les valeurs de operand0 avec "inférieur à", le résultat du tri est le tuple ([1, 3], [50, 42], [1.1, -3.0]).
Si is_stable est défini sur "true", le tri est garanti stable. Autrement dit, si des éléments sont considérés comme égaux par le comparateur, l'ordre relatif des valeurs égales est conservé. Deux éléments e1 et e2 sont égaux si et seulement si comparator(e1, e2) = comparator(e2, e1) = false. Par défaut, is_stable est défini sur "false".
Pour en savoir plus sur StableHLO, consultez StableHLO – sort.
Sqrt
Voir aussi XlaBuilder::Sqrt.
Opération de racine carrée au niveau des éléments x -> sqrt(x).
Sqrt(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Sqrt accepte également l'argument facultatif result_accuracy :
Sqrt(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Pour en savoir plus sur StableHLO, consultez StableHLO – sqrt.
Sous-propriété
Voir aussi XlaBuilder::Sub.
Effectue une soustraction élément par élément de lhs et rhs.
Sub(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une autre variante avec une prise en charge de la diffusion multidimensionnelle pour Sub :
Sub(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – soustraction.
Brun clair
Voir aussi XlaBuilder::Tan.
Tangente par élément x -> tan(x).
Tan(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Tan accepte également l'argument facultatif result_accuracy :
Tan(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Pour en savoir plus sur StableHLO, consultez StableHLO – tan.
Tanh
Voir aussi XlaBuilder::Tanh.
Tangente hyperbolique élément par élément x -> tanh(x).
Tanh(operand)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
Tanh accepte également l'argument facultatif result_accuracy :
Tanh(operand, result_accuracy)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande de la fonction |
result_accuracy
|
facultatif ResultAccuracy
|
Types de précision que l'utilisateur peut demander pour les opérations unaires avec plusieurs implémentations |
Pour en savoir plus sur result_accuracy, consultez Précision des résultats.
Pour en savoir plus sur StableHLO, consultez StableHLO – tanh.
TopK
Voir aussi XlaBuilder::TopK.
TopK trouve les valeurs et les index des k éléments les plus grands ou les plus petits pour la dernière dimension du Tensor donné.
TopK(operand, k, largest)
| Arguments | Type | Sémantique |
|---|---|---|
operand
|
XlaOp
|
Tensor à partir duquel extraire les k premiers éléments.
Le Tensor doit avoir une ou plusieurs dimensions. La taille de la dernière dimension du Tensor doit être supérieure ou égale à k. |
k |
int64 |
Nombre d'éléments à extraire. |
largest
|
bool
|
Indique s'il faut extraire les k éléments les plus grands ou les plus petits. |
Pour un Tensor d'entrée à une dimension (un tableau), trouve les k entrées les plus grandes ou les plus petites du tableau et génère un tuple de deux tableaux (values, indices). Ainsi, values[j] est la j-ième entrée la plus grande/petite de operand, et son index est indices[j].
Pour un Tensor d'entrée comportant plus d'une dimension, calcule les k premières entrées le long de la dernière dimension, en conservant toutes les autres dimensions (lignes) dans la sortie.
Ainsi, pour un opérande de forme [A, B, ..., P, Q] où Q >= k, la sortie est un tuple (values, indices) où :
values.shape = indices.shape = [A, B, ..., P, k]
Si deux éléments d'une même ligne sont égaux, celui dont l'index est le plus faible apparaît en premier.
Transposer
Consultez également l'opération tf.reshape.
Transpose(operand, permutation)
| Arguments | Type | Sémantique |
|---|---|---|
operand |
XlaOp |
Opérande à transposer. |
permutation |
ArraySlice<int64> |
Comment permuter les dimensions. |
Permute les dimensions de l'opérande avec la permutation donnée, donc ∀ i . 0 ≤ i < number of dimensions ⇒
input_dimensions[permutation[i]] = output_dimensions[i].
Cela revient à Reshape(operand, permutation, Permute(permutation, operand.shape.dimensions)).
Pour en savoir plus sur StableHLO, consultez StableHLO – transpose.
TriangularSolve
Voir aussi XlaBuilder::TriangularSolve.
Résout les systèmes d'équations linéaires avec des matrices de coefficients triangulaires inférieures ou supérieures par substitution avant ou arrière. Cette routine, qui diffuse le long des principales dimensions, résout l'un des systèmes matriciels op(a) * x =
b ou x * op(a) = b pour la variable x, étant donné a et b, où op(a) est op(a) = a, op(a) = Transpose(a) ou op(a) = Conj(Transpose(a)).
TriangularSolve(a, b, left_side, lower, unit_diagonal, transpose_a)
| Arguments | Type | Sémantique |
|---|---|---|
a
|
XlaOp
|
Tableau à plus de deux dimensions de type complexe ou à virgule flottante avec une forme [..., M,
M]. |
b
|
XlaOp
|
Tableau à plus de deux dimensions du même type avec la forme [..., M, K] si left_side est défini sur "true", [..., K, M] dans le cas contraire. |
left_side
|
bool
|
indique s'il faut résoudre un système de la forme op(a) * x = b (true) ou x *
op(a) = b (false). |
lower
|
bool
|
Indique s'il faut utiliser le triangle supérieur ou inférieur de a. |
unit_diagonal
|
bool
|
Si la valeur est true, les éléments diagonaux de a sont supposés être 1 et ne sont pas accessibles. |
transpose_a
|
Transpose
|
Indique si a doit être utilisé tel quel, transposé ou transposé conjugué. |
Les données d'entrée ne sont lues que dans le triangle inférieur/supérieur de a, en fonction de la valeur de lower. Les valeurs de l'autre triangle sont ignorées. Les données de sortie sont renvoyées dans le même triangle. Les valeurs de l'autre triangle sont définies par l'implémentation et peuvent être n'importe quoi.
Si le nombre de dimensions de a et b est supérieur à 2, elles sont traitées comme des lots de matrices, où toutes les dimensions, à l'exception des deux dimensions mineures, sont des dimensions de lot. a et b doivent avoir des dimensions de lot égales.
Pour en savoir plus sur StableHLO, consultez StableHLO – triangular_solve.
Tuple
Voir aussi XlaBuilder::Tuple.
Tuple contenant un nombre variable de gestionnaires de données, chacun ayant sa propre forme.
Tuple(elements)
| Arguments | Type | Sémantique |
|---|---|---|
elements |
vecteur de XlaOp |
Tableau N de type T |
Cela est analogue à std::tuple en C++. Conceptuellement :
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
Les tuples peuvent être déconstruits (accessibles) via l'opération GetTupleElement.
Pour en savoir plus sur StableHLO, consultez StableHLO – tuple.
Bien que
Voir aussi XlaBuilder::While.
While(condition, body, init)
| Arguments | Type | Sémantique |
|---|---|---|
condition
|
XlaComputation
|
XlaComputation de type T -> PRED qui définit la condition d'arrêt de la boucle. |
body
|
XlaComputation
|
XlaComputation de type T -> T qui définit le corps de la boucle. |
init
|
T
|
Valeur initiale du paramètre de condition et body. |
Exécute séquentiellement le body jusqu'à ce que le condition échoue. Cela ressemble à une boucle while typique dans de nombreux autres langages, à l'exception des différences et des restrictions listées ci-dessous.
- Un nœud
Whilerenvoie une valeur de typeT, qui correspond au résultat de la dernière exécution debody. - La forme du type
Test déterminée de manière statique et doit être la même pour toutes les itérations.
Les paramètres T des calculs sont initialisés avec la valeur init lors de la première itération et sont automatiquement mis à jour avec le nouveau résultat de body lors de chaque itération suivante.
L'un des principaux cas d'utilisation du nœud While est d'implémenter l'exécution répétée de l'entraînement dans les réseaux de neurones. Le pseudo-code simplifié est présenté ci-dessous avec un graphique représentant le calcul. Le code se trouve dans while_test.cc.
Dans cet exemple, le type T est un Tuple composé d'un int32 pour le nombre d'itérations et d'un vector[10] pour l'accumulateur. Pour 1 000 itérations, la boucle continue d'ajouter un vecteur constant à l'accumulateur.
// Pseudocode for the computation.
init = {0, zero_vector[10]} // Tuple of int32 and float[10].
result = init;
while (result(0) < 1000) {
iteration = result(0) + 1;
new_vector = result(1) + constant_vector[10];
result = {iteration, new_vector};
}
Pour en savoir plus sur StableHLO, consultez StableHLO – while.
Xor
Voir aussi XlaBuilder::Xor.
Effectue une opération XOR (OU exclusif) élément par élément sur lhs et rhs.
Xor(lhs, rhs)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
Les formes des arguments doivent être similaires ou compatibles. Consultez la documentation sur la diffusion pour savoir ce que signifie la compatibilité des formes. La forme du résultat d'une opération est celle obtenue après la diffusion des deux tableaux d'entrée. Dans cette variante, les opérations entre des tableaux de rangs différents ne sont pas acceptées, sauf si l'un des opérandes est un scalaire.
Il existe une variante alternative avec une prise en charge de la diffusion multidimensionnelle pour Xor :
Xor(lhs,rhs, broadcast_dimensions)
| Arguments | Type | Sémantique |
|---|---|---|
| lhs | XlaOp | Opérande de gauche : tableau de type T |
| rhs | XlaOp | Opérande de gauche : tableau de type T |
| broadcast_dimension | ArraySlice |
Dimension de la forme cible à laquelle correspond chaque dimension de la forme de l'opérande |
Cette variante de l'opération doit être utilisée pour les opérations arithmétiques entre des tableaux de rangs différents (par exemple, l'ajout d'une matrice à un vecteur).
L'opérande broadcast_dimensions supplémentaire est une tranche d'entiers spécifiant les dimensions à utiliser pour la diffusion des opérandes. La sémantique est décrite en détail sur la page de diffusion.
Pour en savoir plus sur StableHLO, consultez StableHLO – xor.